Bruce Warrington az Unsplash segítségével
A gépi tanulási modellek általában véve intelligensebbé válnak, mert attól függnek, hogy címkézett adatokat használnak, hogy segítsenek megkülönböztetni két hasonló objektumot.
E címkézett adatkészletek nélkül azonban komoly akadályokba ütközhet a leghatékonyabb és legmegbízhatóbb gépi tanulási modell létrehozása során. A modell betanítási szakaszában a címkézett adatkészletek fontosak.
A mély tanulást széles körben alkalmazzák olyan feladatok megoldására, mint a számítógépes látás felügyelt tanulással. Azonban, mint sok más dolog az életben, ez is korlátozásokkal jár. A felügyelt osztályozáshoz nagy mennyiségű és minőségű címkézett képzési adatra van szükség ahhoz, hogy robusztus modellt hozzon létre. Ez azt jelenti, hogy az osztályozó modell nem tudja kezelni a nem látott osztályokat.
És mindannyian tudjuk, mennyi számítási teljesítmény, újraképzés, idő és pénz szükséges egy mély tanulási modell betanításához.
De vajon egy modell képes-e megkülönböztetni két objektumot anélkül, hogy betanítási adatokat használna? Igen, ezt úgy hívják, hogy nullapontos tanulás. A nullapontos tanulás a modell azon képessége, hogy képes végrehajtani egy feladatot anélkül, hogy bármilyen oktatási példát kapott vagy felhasználna.
Az emberek természetesen képesek nullapontos tanulásra anélkül, hogy különösebb erőfeszítést kellene tenniük. Agyunk már tárol szótárakat, és lehetővé teszi számunkra, hogy fizikai tulajdonságaik alapján megkülönböztessük a tárgyakat jelenlegi tudásbázisunknak köszönhetően. Ennek a tudásbázisnak a segítségével megláthatjuk az objektumok közötti hasonlóságokat és különbségeket, és megtalálhatjuk a köztük lévő kapcsolatot.
Tegyük fel például, hogy állatfajokra próbálunk osztályozási modellt építeni. Alapján OurWorldInData2.13-ben 2021 millió fajt számoltak. Ezért, ha az állatfajok leghatékonyabb osztályozási modelljét akarjuk létrehozni, 2.13 millió különböző osztályra lenne szükségünk. Szintén sok adatra lesz szükség. A nagy mennyiségű és minőségű adatokhoz nehéz hozzáférni.
Tehát hogyan oldja meg ezt a problémát a nullapontos tanulás?
Mivel a nullapontos tanuláshoz nem szükséges, hogy a modell megtanulja a képzési adatokat és az osztályok osztályozását, lehetővé teszi számunkra, hogy kevésbé támaszkodjunk a modell címkézett adatok iránti igényére.
Az alábbiakban bemutatjuk, hogy az adatoknak miből kell állniuk ahhoz, hogy folytathassuk a nulla-shot tanulást.
Látott osztályok
Ez azokból az adatosztályokból áll, amelyeket korábban egy modell betanításához használtak.
Láthatatlan osztályok
Ez azokból az adatosztályokból áll, amelyeket NEM használtak fel egy modell betanításához, és az új, nullapontos tanulási modell általánosítani fog.
Kiegészítő információk
Mivel a nem látott osztályokban lévő adatok nincsenek címkézve, a nullapontos tanuláshoz kiegészítő információkra lesz szükség a tanuláshoz, valamint az összefüggések, hivatkozások és tulajdonságok megtalálásához. Ez történhet szóbeágyazások, leírások és szemantikai információk formájában.
Zero-shot tanulási módszerek
A nullapontos tanulást általában a következőkben használják:
- Osztályozó alapú módszerek
- Példány alapú módszerek
Szakmai
A nullapontos tanulást olyan osztályok modelljének felépítésére használják, amelyek nem címkézett adatok felhasználásával edzenek, ezért ehhez a következő két szakaszra van szükség:
1. Kiképzés
A képzési szakasz a tanulási módszer folyamata, amely a lehető legtöbb tudást próbálja megragadni az adatok minőségéről. Ezt tekinthetjük tanulási szakasznak.
2. Következtetés
A következtetési szakaszban a képzési szakaszból tanult összes tudást alkalmazzák és felhasználják annak érdekében, hogy a példákat új osztályokba sorolják. Ezt tekinthetjük az előrejelzések készítésének fázisának.
Hogyan működik?
A látott osztályokból származó tudás egy nagy dimenziós vektortérben átkerül a nem látott osztályokba; ezt nevezzük szemantikai térnek. Például a képosztályozás során a szemantikai tér a képpel együtt két lépésen megy keresztül:
1. Közös beágyazási hely
Ide vetítődnek a szemantikai vektorok és a vizuális jellemző vektorai.
2. Legnagyobb hasonlóság
Ez az a hely, ahol a funkciókat egy nem látott osztály jellemzőivel párosítják.
A két szakasz (képzés és következtetés) folyamatának megértése érdekében alkalmazzuk őket a képosztályozás használatában.
Képzések

Jari Hytönen az Unsplash segítségével
Emberként, ha elolvasnád a fenti kép jobb oldali szövegét, azonnal azt feltételeznéd, hogy 4 cica van egy barna kosárban. De tegyük fel, hogy fogalmad sincs, mi az a „cica”. Feltételezheti, hogy van egy barna kosár, benne 4 dologgal, amelyeket „cicáknak” neveznek. Ha több olyan képpel találkozik, amelyek „cicának” látszó valamit tartalmaznak, meg tudja majd különböztetni a „cicát” más állatoktól.
Ez történik, amikor használod Kontrasztív nyelv-kép előképzés (CLIP) az OpenAI-tól a képosztályozás zéró felvételek tanulásához. Kiegészítő információként ismert.
Lehet, hogy azt gondolja, „hát ezek csak címkézett adatok”. Megértem, miért gondolja ezt, de nem így van. A segédinformáció nem az adatok címkéi, hanem egyfajta felügyelet, amely segíti a modell tanulását a képzési szakaszban.
Ha egy zero-shot tanulási modell elegendő mennyiségű kép-szöveg párosítást lát, képes lesz megkülönböztetni és megérteni a kifejezéseket, valamint azt, hogy ezek hogyan kapcsolódnak a képek bizonyos mintáihoz. A „kontrasztív tanulás” CLIP technikáját alkalmazva a nullapontos tanulási modell jó tudásbázist tudott felhalmozni ahhoz, hogy előrejelzéseket tudjon készíteni az osztályozási feladatokról.
Ez a CLIP-megközelítés összefoglalása, ahol egy képkódolót és egy szövegkódolót együtt tanítanak meg annak érdekében, hogy megjósolják a (kép, szöveg) betanítási példák kötegének helyes párosítását. Kérjük, nézze meg az alábbi képet:

Átvihető vizuális modellek tanulása természetes nyelvi felügyeletből
Következtetés
Miután a modell átment a betanítási szakaszon, jó tudásbázissal rendelkezik a kép-szöveg párosításhoz, és most már használható előrejelzések készítésére. Mielőtt azonban belevághatnánk az előrejelzésekbe, be kell állítanunk az osztályozási feladatot úgy, hogy létrehozunk egy listát a modell által kiadható összes lehetséges címkéről.
Például, ha maradunk az állatfajokra vonatkozó képosztályozási feladatnál, szükségünk lesz egy listára az összes állatfajtáról. Ezek a címkék mindegyike kódolva lesz, T? T-nek? a betanítási szakaszban előforduló előképzett szövegkódoló használatával.
A címkék kódolása után képeket vihetünk be az előre betanított képkódolón keresztül. A távolságmetrikus koszinusz hasonlóságot fogjuk használni a képkódolás és az egyes szövegcímkekódolások közötti hasonlóságok kiszámításához.
A kép besorolása a képhez a legnagyobb hasonlóságot mutató címke alapján történik. És így érhető el a nullapontos tanulás, különösen a képosztályozásban.
Az adatok szűkössége
Amint azt korábban említettük, a nagy mennyiségű és minőségű adatot nehéz megszerezni. Ellentétben az emberekkel, akik már rendelkeznek a nullapontos tanulási képességgel, a gépeknek megjelölt adatokra van szükségük a tanuláshoz, majd alkalmazkodni tudjanak a természetesen előforduló eltérésekhez.
Ha megnézzük az állatfajok példáját, nagyon sok volt. És mivel a kategóriák száma folyamatosan növekszik a különböző tartományokban, sok munkára lesz szükség ahhoz, hogy lépést tartsunk a megjegyzésekkel ellátott adatok gyűjtésével.
Ennek köszönhetően felértékelődött számunkra a zero-shot tanulás. Egyre több kutató érdeklődik az automatikus attribútumfelismerés iránt, hogy kompenzálja a rendelkezésre álló adatok hiányát.
Adatok címkézése
A zero-shot tanulás másik előnye az adatcímkézési tulajdonságai. Az adatcímkézés munkaigényes és nagyon fárasztó lehet, emiatt a folyamat során hibákhoz vezethet. Az adatok címkézéséhez szakértőkre van szükség, például egészségügyi szakemberekre, akik egy orvosbiológiai adatkészleten dolgoznak, ami rendkívül költséges és időigényes.
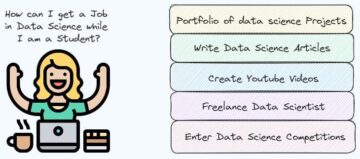
A nullapontos tanulás egyre népszerűbb az adatok fenti korlátai miatt. Javaslom, hogy olvasson el néhány cikket, ha érdekli a képességei:
Nisha Arya adattudós és szabadúszó műszaki író. Különösen érdekli az adattudományi karriertanácsadás vagy oktatóanyagok, valamint elméleti alapú ismeretek nyújtása a Data Science területén. Azt is szeretné feltárni, hogy a mesterséges intelligencia milyen különböző módokon járulhat hozzá az emberi élet hosszú élettartamához. Szívesen tanuló, aki igyekszik bővíteni műszaki ismereteit és íráskészségét, miközben segít másoknak.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- képességek
- képesség
- Képes
- Rólunk
- felett
- Szerint
- felhalmozásra
- elért
- át
- alkalmazkodni
- tanács
- ellen
- Minden termék
- lehetővé teszi, hogy
- már
- összeg
- és a
- állat
- állatok
- alkalmazott
- alkalmaz
- megközelítés
- körül
- mesterséges
- mesterséges intelligencia
- Automatikus
- elérhető
- bázis
- alapján
- kosár
- válik
- egyre
- előtt
- hogy
- lent
- haszon
- között
- orvosbiológiai
- bővül
- épít
- számított
- hívott
- Kaphat
- nem tud
- képes
- elfog
- Karrier
- kategóriák
- bizonyos
- osztály
- osztályok
- besorolás
- osztályoz
- Gyűjtő
- hogyan
- teljes
- számítási teljesítmény
- Kiszámít
- számítógép
- Számítógépes látás
- tovább
- tudott
- teremt
- létrehozása
- Jelenlegi
- dátum
- adat-tudomány
- adattudós
- adatkészletek
- mély
- mély tanulás
- Függőség
- különbségek
- különböző
- különbséget
- távolság
- domainek
- alatt
- minden
- Hatékony
- erőfeszítés
- hibák
- példa
- példák
- drága
- szakértők
- magyarázható
- feltárása
- Funkció
- Jellemzők
- kevés
- Találjon
- következő
- forma
- szabadúszó
- ból ből
- általános
- kap
- jó
- legnagyobb
- Nő
- útmutató
- fogantyú
- kezek
- megtörténik
- Kemény
- tekintettel
- segít
- segít
- Magas
- legnagyobb
- nagyon
- Hogyan
- How To
- azonban
- HTTPS
- emberi
- Az emberek
- ötlet
- kép
- Képosztályozás
- képek
- fontos
- in
- információ
- bemenet
- Intelligencia
- érdekelt
- IT
- Lelkes
- Tart
- Ismer
- tudás
- ismert
- Címke
- címkézés
- Címkék
- hiány
- nyelv
- vezet
- TANUL
- tanult
- tanulás
- élet
- korlátozások
- LINK
- linkek
- Lista
- hosszú élet
- néz
- keres
- MEGJELENÉS
- Sok
- gép
- gépi tanulás
- gép
- fontos
- csinál
- Gyártás
- sok
- eszközök
- orvosi
- említett
- módszer
- mód
- metrikus
- esetleg
- millió
- modell
- modellek
- pénz
- több
- a legtöbb
- Természetes
- Szükség
- Új
- szám
- objektumok
- akadályok
- történt
- ONE
- OpenAI
- érdekében
- Más
- Egyéb
- párosítás
- párosítások
- papírok
- különösen
- minták
- fázis
- kifejezés
- fizikai
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- Népszerű
- lehetséges
- hatalom
- előre
- Tippek
- korábban
- Probléma
- folyamat
- gyárt
- tehetséges alkalmazottal
- tervezett
- ingatlanait
- amely
- tesz
- tulajdonságok
- világítás
- mennyiség
- Olvass
- ok
- kapott
- elismerés
- ajánl
- szükség
- megköveteli,
- kutatók
- korlátozások
- erős
- Tudomány
- Tudós
- keres
- lát
- készlet
- hasonló
- hasonlóságok
- készségek
- intelligensebb
- So
- SOLVE
- valami
- Hely
- kifejezetten
- Színpad
- állapota
- Lépései
- ragasztás
- Még mindig
- tárolni
- ilyen
- elegendő
- ÖSSZEFOGLALÓ
- felügyelet
- Vesz
- tart
- Feladat
- feladatok
- tech
- Műszaki
- A
- azok
- ebből adódóan
- dolgok
- Gondolkodás
- Keresztül
- idő
- időigényes
- nak nek
- együtt
- Vonat
- Képzések
- átment
- megbízható
- oktatóanyagok
- jellemzően
- megért
- us
- használ
- hasznosított
- Értékes
- keresztül
- Megnézem
- látomás
- módon
- Mit
- ami
- Míg
- WHO
- széles körben
- lesz
- nélkül
- szó
- Munka
- dolgozó
- lenne
- író
- írás
- A te
- zephyrnet
- Zero-Shot Learning