Ini adalah posting tamu yang ditulis bersama Antony Vance dari Intel.
Pelanggan selalu mencari cara untuk meningkatkan kinerja dan waktu respons beban kerja inferensi pembelajaran mesin (ML) mereka tanpa meningkatkan biaya per transaksi dan tanpa mengorbankan keakuratan hasil. Menjalankan beban kerja ML aktif Amazon SageMaker berjalan Cloud komputasi elastis Amazon (Amazon EC2) C6i contoh dengan Intel Penerapan inferensi INT8 dapat membantu meningkatkan kinerja keseluruhan hingga empat kali lipat dari setiap dolar yang dihabiskan sekaligus menjaga kerugian dalam akurasi inferensi kurang dari 1% dibandingkan dengan FP32 saat diterapkan pada beban kerja ML tertentu. Ketika datang untuk menjalankan model di perangkat yang disematkan di mana faktor bentuk dan ukuran model itu penting, kuantisasi dapat membantu.
Kuantisasi adalah teknik untuk mengurangi biaya komputasi dan memori dalam menjalankan inferensi dengan merepresentasikan bobot dan aktivasi dengan tipe data presisi rendah seperti integer 8-bit (INT8), bukan floating point 32-bit biasa (FP32). Dalam gambar contoh berikut, kami menunjukkan kinerja inferensi INT8 di C6i untuk model berbasis BERT.
Basis BERT disesuaikan dengan SQuAD v1.1, dengan PyTorch (v1.11) sebagai kerangka kerja ML yang digunakan dengan Intel® Extension untuk PyTorch. Ukuran batch 1 digunakan untuk perbandingan. Ukuran batch yang lebih tinggi akan memberikan biaya yang berbeda per 1 juta inferensi.
Dalam posting ini, kami menunjukkan kepada Anda bagaimana membangun dan menggunakan inferensi INT8 dengan Anda wadah pengolahan sendiri untuk PyTorch. Kami menggunakan ekstensi Intel untuk PyTorch untuk alur kerja penerapan INT8 yang efektif.
Sekilas tentang teknologi
instans EC2 C6i ditenagai oleh prosesor Intel Xeon Scalable generasi ketiga (juga disebut Ice Lake) dengan frekuensi turbo all-core 3.5 GHz.
Dalam konteks pembelajaran mendalam, format numerik dominan yang digunakan untuk penelitian dan penerapan sejauh ini adalah 32-bit floating point, atau FP32. Namun, kebutuhan bandwidth yang dikurangi dan persyaratan komputasi model deep learning telah mendorong penelitian untuk menggunakan format numerik dengan presisi lebih rendah. Telah dibuktikan bahwa bobot dan aktivasi dapat direpresentasikan menggunakan bilangan bulat 8-bit (atau INT8) tanpa menimbulkan kerugian yang signifikan dalam akurasi.
Instans EC2 C6i menawarkan banyak kemampuan baru yang menghasilkan peningkatan kinerja untuk beban kerja AI dan ML. Instans C6i memberikan keunggulan kinerja dalam penerapan model FP32 dan INT8. Inferensi FP32 diaktifkan dengan peningkatan AVX-512, dan inferensi INT8 diaktifkan dengan instruksi VNNI AVX-512.
C6i sekarang tersedia di titik akhir SageMaker, dan pengembang diharapkan dapat memberikan peningkatan kinerja harga lebih dari dua kali lipat untuk inferensi INT8 dibandingkan inferensi FP32 dan peningkatan kinerja hingga empat kali lipat jika dibandingkan dengan inferensi FP5 instans C32. Lihat lampiran untuk detail instance dan data tolok ukur.
Penyebaran pembelajaran mendalam di edge untuk inferensi real-time adalah kunci untuk banyak area aplikasi. Ini secara signifikan mengurangi biaya komunikasi dengan cloud dalam hal bandwidth jaringan, latensi jaringan, dan konsumsi daya. Namun, perangkat edge memiliki memori, sumber daya komputasi, dan daya yang terbatas. Artinya, jaringan deep learning harus dioptimalkan untuk penerapan tersemat. Kuantisasi INT8 telah menjadi pendekatan populer untuk pengoptimalan semacam itu untuk kerangka kerja ML seperti TensorFlow dan PyTorch. SageMaker memberi Anda pendekatan bawa wadah Anda sendiri (BYOC) dan alat terintegrasi sehingga Anda dapat menjalankan kuantisasi.
Untuk informasi lebih lanjut, lihat Inferensi dan Pelatihan Deep Learning Presisi Numerik Rendah.
Ikhtisar solusi
Langkah-langkah untuk mengimplementasikan solusi tersebut adalah sebagai berikut:
- Sediakan instans EC2 C6i untuk mengukur dan membuat model ML.
- Gunakan skrip Python yang disediakan untuk kuantisasi.
- Buat image Docker untuk menerapkan model di SageMaker menggunakan pendekatan BYOC.
- Gunakan sebuah Layanan Penyimpanan Sederhana Amazon (Amazon S3) untuk menyalin model dan kode untuk akses SageMaker.
- penggunaan Registry Kontainer Elastis Amazon (Amazon ECR) untuk menghosting gambar Docker.
- Gunakan Antarmuka Baris Perintah AWS (AWS CLI) untuk membuat titik akhir inferensi di SageMaker.
- Jalankan skrip pengujian Python yang disediakan untuk memanggil titik akhir SageMaker untuk versi INT8 dan FP32.
Pengaturan penerapan inferensi ini menggunakan model BERT-base dari repositori transformer Hugging Face (csarron/bert-base-uncased-squad-v1).
Prasyarat
Berikut adalah prasyarat untuk membuat penyiapan penerapan:
- Terminal shell Linux dengan AWS CLI terpasang
- Akun AWS dengan akses ke pembuatan instans EC2 (tipe instans C6i)
- Akses SageMaker untuk menerapkan model SageMaker, konfigurasi titik akhir, titik akhir
- Identitas AWS dan Manajemen Akses (IAM) untuk mengonfigurasi peran dan kebijakan IAM
- Akses ke Amazon ECR
- Akses SageMaker untuk membuat buku catatan dengan instruksi untuk meluncurkan titik akhir
Buat dan terapkan model INT8 terkuantisasi di SageMaker
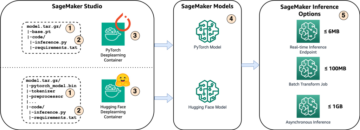
Buka instans EC2 untuk membuat model terkuantisasi Anda dan dorong artefak model ke Amazon S3. Untuk penyebaran titik akhir, buat wadah khusus dengan PyTorch dan Intel® Extension untuk PyTorch untuk menerapkan model INT8 yang dioptimalkan. Kontainer didorong ke Amazon ECR dan titik akhir berbasis C6i dibuat untuk melayani model FP32 dan INT8.
Diagram berikut mengilustrasikan aliran tingkat tinggi.

Untuk mengakses kode dan dokumentasi, lihat GitHub repo.
Contoh kasus penggunaan
Stanford Question Answering Dataset (SQuAD) adalah kumpulan data pemahaman bacaan yang terdiri dari pertanyaan yang diajukan oleh crowdworker pada serangkaian artikel Wikipedia, di mana jawaban untuk setiap pertanyaan adalah segmen teks, atau merentang, dari bagian bacaan yang sesuai, atau pertanyaannya mungkin tidak terjawab.
Contoh berikut adalah algoritma penjawab pertanyaan menggunakan model berbasis BERT. Diberikan dokumen sebagai input, model akan menjawab pertanyaan sederhana berdasarkan pembelajaran dan konteks dari dokumen input.
Berikut ini adalah contoh dokumen masukan:
Hutan hujan Amazon (Portugis: Floresta Amazônica atau Amazonia; Spanyol: Selva Amazónica, Amazonía atau biasanya Amazonia; Prancis: Forêt amazonienne; Belanda: Amazoneregenwoud), juga dikenal dalam bahasa Inggris sebagai Amazonia atau Amazon Jungle, adalah hutan berdaun lebar lembab yang menutupi sebagian besar lembah Amazon di Amerika Selatan. Cekungan ini mencakup 7,000,000 kilometer persegi (2,700,000 sq mi), dimana 5,500,000 kilometer persegi (2,100,000 sq mi) ditutupi oleh hutan hujan.
Untuk pertanyaan “Nama apa yang juga digunakan untuk mendeskripsikan hutan hujan Amazon dalam bahasa Inggris?” kita mendapatkan jawabannya:
Untuk pertanyaan “Berapa kilometer persegi hutan hujan yang tercakup dalam cekungan?” kita mendapatkan jawabannya:
Mengkuantisasi model di PyTorch
Bagian ini memberikan ikhtisar singkat tentang langkah-langkah kuantisasi model dengan ekstensi PyTorch dan Intel.
Cuplikan kode berasal dari contoh SageMaker.
Mari kita bahas perubahan secara mendetail untuk fungsi IPEX_quantize di file quantize.py.
- Impor ekstensi intel untuk PyTorch untuk membantu kuantisasi dan pengoptimalan dan impor obor untuk manipulasi array:
- Terapkan kalibrasi model untuk 100 iterasi. Dalam hal ini, Anda mengkalibrasi model dengan set data SQuAD:
- Siapkan input sampel:
- Ubah model menjadi model INT8 menggunakan konfigurasi berikut:
- Jalankan dua iterasi forward pass untuk mengaktifkan fusi:
- Sebagai langkah terakhir, simpan model TorchScript:
Membersihkan
Mengacu kepada Repo Github untuk langkah-langkah membersihkan sumber daya AWS yang dibuat.
Kesimpulan
Instans C2i EC6 baru di titik akhir SageMaker dapat mempercepat penerapan inferensi hingga 2.5 kali lebih besar dengan kuantisasi INT8. Mengukur model di PyTorch dimungkinkan dengan beberapa API dari ekstensi Intel PyTorch. Direkomendasikan untuk mengkuantisasi model dalam instans C6i agar akurasi model dipertahankan dalam penerapan titik akhir. Contoh SageMaker GitHub repo sekarang menyediakan pipa contoh penerapan end-to-end untuk mengkuantisasi dan menghosting model INT8.
Kami mendorong Anda untuk membuat model baru atau memigrasikan model yang sudah ada menggunakan kuantisasi INT8 menggunakan jenis instans EC2 C6i dan lihat peningkatan performanya sendiri.
Pemberitahuan dan penafian
Tidak ada lisensi (tersurat maupun tersirat, dengan estoppel atau lainnya) untuk hak kekayaan intelektual apa pun yang diberikan oleh dokumen ini, dengan satu-satunya pengecualian bahwa kode yang disertakan dalam dokumen ini dilisensikan dengan tunduk pada Lisensi sumber terbuka Zero-Clause BSD (0BSD)
Lampiran
Instans AWS baru di SageMaker dengan dukungan penerapan INT8
Tabel berikut mencantumkan instans SageMaker dengan dan tanpa Peningkatan DL Dukungan.
| Nama instansi | Nama kode Xeon Gen | INT8 Diaktifkan? | Peningkatan DL Diaktifkan? |
| ml.c5. xbesar – ml.c5.9xbesar | Danau langit/1st | Yes | Tidak |
| ml.c5.18xbesar | Danau langit/1st | Yes | Tidak |
| ml.c6i.1x – 32xbesar | Danau Es/3rd | Yes | Yes |
Singkatnya, INT8 diaktifkan mendukung tipe data dan perhitungan INT8; DL Boost diaktifkan mendukung Deep Learning Boost.
Data tolok ukur
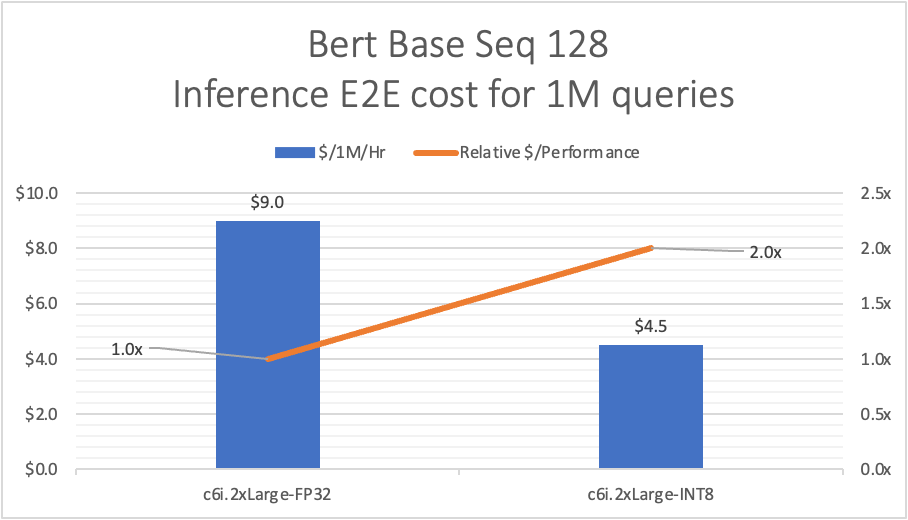
Tabel berikut membandingkan biaya dan performa relatif antara instans c5 dan c6.
Latensi dan throughput diukur dengan 10000 kueri Inferensi ke titik akhir pembuat Sage.
| Latensi E2E dari Titik Akhir Inferensi dan analisis Biaya | |||||
| P50(md) | P90(md) | Kueri/Detik | Kueri $/1 juta | Relatif $/Kinerja | |
| C5.2xBesar-FP32 | 76.6 | 125.3 | 11.5 | $10.2 | 1.0x |
| c6i.2xBesar-FP32 | 70 | 110.8 | 13 | $9.0 | 1.1x |
| c6i.2xBesar-INT8 | 35.7 | 48.9 | 25.56 | $4.5 | 2.3x |
Model INT8 diharapkan memberikan peningkatan kinerja praktis 2-4 kali dengan kehilangan akurasi kurang dari 1% untuk sebagian besar model. Tabel di atas mencakup latensi overhead (aplikasi NW dan demo)
Akurasi untuk model berbasis BERT
Tabel berikut merangkum keakuratan model INT8 dengan set data SQUaD v1.1.
| metrik | FP32 | INT8 |
| Benar-benar cocok | 85.8751 | 85.5061 |
| F1 | 92.0807 | 91.8728 |
Grafik GitHub repo dilengkapi dengan skrip untuk memeriksa keakuratan dataset SQuAD. Mengacu pada panggil-INT8.py dan panggil-FP32.py skrip untuk pengujian.
Ekstensi Intel untuk PyTorch
Intel® Extension for PyTorch* (proyek sumber terbuka di GitHub) memperluas PyTorch dengan pengoptimalan untuk peningkatan kinerja ekstra pada perangkat keras Intel. Sebagian besar pengoptimalan pada akhirnya akan disertakan dalam stok rilis PyTorch, dan maksud dari ekstensi ini adalah untuk memberikan fitur dan pengoptimalan terkini untuk PyTorch pada perangkat keras Intel. Contohnya termasuk AVX-512 Vector Neural Network Instructions (AVX512 VNNI) dan Intel® Advanced Matrix Extensions (Intel® AMX).
Gambar berikut mengilustrasikan Ekstensi Intel untuk arsitektur PyTorch.

Untuk panduan pengguna yang lebih mendetail (fitur, penyetelan kinerja, dan lainnya) untuk Intel® Extension for PyTorch, lihat Panduan pengguna Ekstensi Intel® untuk PyTorch*.
Tentang Penulis
 Rohit Chowdhary adalah Sr. Solutions Architect di tim Strategic Accounts di AWS.
Rohit Chowdhary adalah Sr. Solutions Architect di tim Strategic Accounts di AWS.
 Aniruddha Kappagantu adalah Insinyur Pengembangan Perangkat Lunak di tim AI Platforms di AWS.
Aniruddha Kappagantu adalah Insinyur Pengembangan Perangkat Lunak di tim AI Platforms di AWS.
 Antony Vanes adalah Arsitek AI di Intel dengan pengalaman 19 tahun dalam visi komputer, pembelajaran mesin, pembelajaran mendalam, perangkat lunak tersemat, GPU, dan FPGA.
Antony Vanes adalah Arsitek AI di Intel dengan pengalaman 19 tahun dalam visi komputer, pembelajaran mesin, pembelajaran mendalam, perangkat lunak tersemat, GPU, dan FPGA.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/accelerate-amazon-sagemaker-inference-with-c6i-intel-based-amazon-ec2-instances/
- :adalah
- $NAIK
- 000
- 1
- 100
- 11
- 110
- 7
- 8
- 9
- a
- atas
- mempercepat
- mengakses
- Akun
- Akun
- ketepatan
- aktivasi
- maju
- keuntungan
- AI
- algoritma
- selalu
- Amazon
- Amazon EC2
- Amazon SageMaker
- Amerika
- dan
- menjawab
- Lebah
- Aplikasi
- terapan
- pendekatan
- arsitektur
- ADALAH
- daerah
- susunan
- artikel
- AS
- At
- tersedia
- AWS
- Bandwidth
- berdasarkan
- BE
- menjadi
- makhluk
- patokan
- antara
- mendorong
- membawa
- membangun
- by
- bernama
- CAN
- kemampuan
- kasus
- tertentu
- Perubahan
- memeriksa
- awan
- kode
- berkomunikasi
- dibandingkan
- perbandingan
- komputasi
- menghitung
- komputer
- Visi Komputer
- komputasi
- konfigurasi
- Terdiri dari
- konsumsi
- Wadah
- konteks
- Konteks
- Sesuai
- Biaya
- Biaya
- tercakup
- meliputi
- membuat
- dibuat
- membuat
- penciptaan
- adat
- data
- mendalam
- belajar mendalam
- menyampaikan
- Demo
- menunjukkan
- menyebarkan
- penyebaran
- penyebaran
- Berasal
- menggambarkan
- rinci
- terperinci
- rincian
- pengembang
- Pengembangan
- Devices
- berbeda
- Buruh pelabuhan
- dokumen
- dokumentasi
- melakukan
- Dolar
- didorong
- Dutch
- Tepi
- Efektif
- tertanam
- aktif
- diaktifkan
- meliputi
- mendorong
- ujung ke ujung
- Titik akhir
- insinyur
- Inggris
- Eter (ETH)
- akhirnya
- Setiap
- contoh
- contoh
- pengecualian
- ada
- mengharapkan
- diharapkan
- pengalaman
- ekspres
- perpanjangan
- ekstensi
- tambahan
- Menghadapi
- jauh
- Fitur
- beberapa
- Angka
- File
- mengambang
- aliran
- berikut
- berikut
- Untuk
- hutan
- bentuk
- format
- Depan
- FPGA
- Kerangka
- kerangka
- Perancis
- Frekuensi
- dari
- fungsi
- Keuntungan
- Gen
- mendapatkan
- GitHub
- diberikan
- memberikan
- Go
- GPU
- diberikan
- lebih besar
- Tamu
- tamu Post
- bimbingan
- Perangkat keras
- Memiliki
- membantu
- tingkat tinggi
- lebih tinggi
- tuan rumah
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- IAM
- ES
- identitas
- gambar
- melaksanakan
- tersirat
- mengimpor
- penting
- memperbaiki
- perbaikan
- perbaikan
- in
- memasukkan
- termasuk
- meningkatkan
- informasi
- memasukkan
- contoh
- sebagai gantinya
- instruksi
- terpadu
- Intel
- cendekiawan
- kekayaan intelektual
- Niat
- IT
- iterasi
- jpg
- pemeliharaan
- kunci
- dikenal
- danau
- Terakhir
- Latensi
- jalankan
- pengetahuan
- Lisensi
- Izin
- 'like'
- Terbatas
- baris
- linux
- daftar
- mencari
- lepas
- mesin
- Mesin belajar
- pembuat
- banyak
- Matriks
- cara
- Memori
- mungkin
- bermigrasi
- juta
- ML
- model
- model
- lebih
- paling
- MS
- nama
- Perlu
- jaringan
- saraf
- saraf jaringan
- New
- buku catatan
- of
- menawarkan
- on
- Buka
- open source
- optimasi
- dioptimalkan
- OS
- jika tidak
- secara keseluruhan
- ikhtisar
- sendiri
- path
- prestasi
- pipa saluran
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- Populer
- Portugis
- mungkin
- Pos
- kekuasaan
- didukung
- Praktis
- Ketelitian
- prasyarat
- pengolahan
- prosesor
- proyek
- milik
- Hak Properti
- memberikan
- disediakan
- menyediakan
- Dorong
- terdorong
- Ular sanca
- pytorch
- pertanyaan
- Pertanyaan
- Cepat
- Bacaan
- real-time
- direkomendasikan
- menurunkan
- mengurangi
- mengurangi
- Pers
- gudang
- diwakili
- mewakili
- Persyaratan
- penelitian
- Sumber
- tanggapan
- mengakibatkan
- Hasil
- hak
- Peran
- Run
- berjalan
- berkorban
- pembuat bijak
- Inferensi SageMaker
- Save
- terukur
- script
- Bagian
- ruas
- melayani
- set
- penyiapan
- Kulit
- harus
- Menunjukkan
- penting
- signifikan
- Sederhana
- Ukuran
- ukuran
- So
- sejauh ini
- Perangkat lunak
- pengembangan perangkat lunak
- larutan
- Solusi
- sumber
- Selatan
- Amerika Selatan
- Spanyol
- menghabiskan
- SQ
- kotak
- Stanford
- Langkah
- Tangga
- saham
- penyimpanan
- Strategis
- subyek
- seperti itu
- meringkaskan
- dipasok
- mendukung
- Mendukung
- tabel
- tim
- tensorflow
- terminal
- istilah
- uji
- pengujian
- bahwa
- Grafik
- mereka
- keluaran
- kali
- untuk
- alat
- obor
- .
- transformer
- jenis
- mutakhir
- menggunakan
- Pengguna
- biasanya
- v1
- penglihatan
- cara
- yang
- sementara
- Wikipedia
- akan
- dengan
- tanpa
- alur kerja
- tahun
- Anda
- diri
- zephyrnet.dll