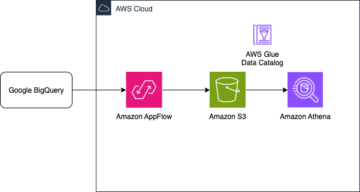
Organisasi telah memilih untuk membangun data lake di atasnya Layanan Penyimpanan Sederhana Amazon (Amazon S3) selama bertahun-tahun. Sebuah data lake adalah pilihan paling populer bagi organisasi untuk menyimpan semua data organisasi mereka yang dihasilkan oleh tim yang berbeda, di seluruh domain bisnis, dari semua format yang berbeda, dan bahkan sepanjang riwayat. Berdasarkan sebuah pelajaran, rata-rata perusahaan melihat volume data mereka tumbuh dengan kecepatan melebihi 50% per tahun, biasanya mengelola rata-rata 33 sumber data unik untuk dianalisis.
Tim sering kali mencoba mereplikasi ribuan pekerjaan dari database relasional dengan pola ekstrak, transformasi, dan muat (ETL) yang sama. Ada banyak upaya dalam mempertahankan status pekerjaan dan menjadwalkan pekerjaan individual ini. Pendekatan ini membantu tim menambahkan tabel dengan sedikit perubahan dan juga mempertahankan status pekerjaan dengan sedikit usaha. Ini dapat menghasilkan peningkatan besar dalam garis waktu pengembangan dan melacak pekerjaan dengan mudah.
Dalam posting ini, kami menunjukkan kepada Anda bagaimana dengan mudah mereplikasi semua penyimpanan data relasional Anda ke dalam danau data transaksional secara otomatis dengan satu pekerjaan ETL menggunakan Apache Iceberg dan Lem AWS.
Arsitektur solusi
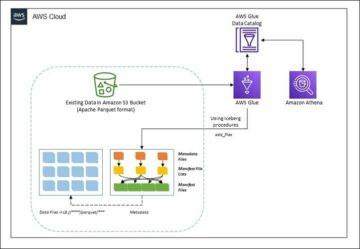
Danau data adalah biasanya terorganisir menggunakan bucket S3 terpisah untuk tiga lapisan data: lapisan mentah berisi data dalam bentuk aslinya, lapisan tahap berisi data proses menengah yang dioptimalkan untuk konsumsi, dan lapisan analitik berisi data gabungan untuk kasus penggunaan tertentu. Di lapisan mentah, tabel biasanya diatur berdasarkan sumber datanya, sedangkan tabel di lapisan tahap diatur berdasarkan domain bisnis tempat mereka berada.
Postingan ini memberikan Formasi AWS Cloud template yang menerapkan tugas AWS Glue yang membaca jalur Amazon S3 untuk satu sumber data dari lapisan mentah data lake, dan menyerap data ke dalam tabel Apache Iceberg pada lapisan stage menggunakan Dukungan AWS Glue untuk kerangka data lake. Pekerjaan mengharapkan tabel di lapisan mentah untuk disusun di jalan Layanan Migrasi Database AWS (AWS DMS) mencernanya: skema, lalu tabel, lalu file data.
Solusi ini menggunakan Penyimpanan Parameter Manajer Sistem AWS untuk konfigurasi tabel. Anda harus mengubah parameter ini dengan menentukan tabel yang ingin Anda proses dan caranya, termasuk informasi seperti kunci utama, partisi, dan domain bisnis yang terkait. Pekerjaan menggunakan informasi ini untuk membuat database secara otomatis (jika belum ada) untuk setiap domain bisnis, membuat tabel Gunung Es, dan melakukan pemuatan data.
Akhirnya, bisa kita gunakan Amazon Athena untuk menanyakan data di tabel gunung es.
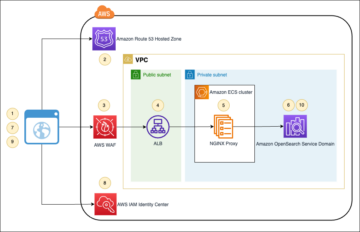
Diagram berikut menggambarkan arsitektur ini.

Implementasi ini memiliki pertimbangan sebagai berikut:
- Semua tabel dari sumber data harus memiliki kunci utama untuk direplikasi menggunakan solusi ini. Kunci utama dapat berupa satu kolom atau kunci komposit dengan lebih dari satu kolom.
- Jika data lake berisi tabel yang tidak memerlukan upsert atau tidak memiliki kunci utama, Anda dapat mengecualikannya dari konfigurasi parameter dan menerapkan proses ETL tradisional untuk menyerapnya ke dalam data lake. Itu di luar cakupan posting ini.
- Jika ada sumber data tambahan yang perlu diserap, Anda dapat menerapkan beberapa tumpukan CloudFormation, satu tumpukan untuk menangani setiap sumber data.
- Pekerjaan AWS Glue dirancang untuk memproses data dalam dua fase: pemuatan awal yang berjalan setelah AWS DMS menyelesaikan tugas pemuatan penuh, dan pemuatan tambahan yang berjalan sesuai jadwal yang menerapkan file pengambilan data perubahan (CDC) yang ditangkap oleh AWS DMS. Pemrosesan bertahap dilakukan dengan menggunakan an Penanda pekerjaan AWS Glue.
Ada sembilan langkah untuk menyelesaikan tutorial ini:
- Siapkan titik akhir sumber untuk AWS DMS.
- Menerapkan solusi menggunakan AWS CloudFormation.
- Tinjau tugas replikasi AWS DMS.
- Secara opsional, tambahkan izin untuk enkripsi dan dekripsi atau Formasi Danau AWS.
- Tinjau konfigurasi tabel di Parameter Store.
- Lakukan pemuatan data awal.
- Lakukan pemuatan data tambahan.
- Pantau konsumsi tabel.
- Jadwalkan pemuatan data batch tambahan.
Prasyarat
Sebelum memulai tutorial ini, sebaiknya Anda sudah familiar dengan Iceberg. Jika tidak, Anda dapat memulai dengan mereplikasi satu tabel dengan mengikuti petunjuk di dalamnya Menerapkan UPSERT berbasis CDC di data lake menggunakan Apache Iceberg dan AWS Glue. Selain itu, atur yang berikut ini:
Siapkan titik akhir sumber untuk AWS DMS
Sebelum membuat tugas AWS DMS, kita perlu menyiapkan titik akhir sumber untuk terhubung ke database sumber:
- Di konsol AWS DMS, pilih Titik akhir di panel navigasi.
- Pilih Buat titik akhir.
- Jika database Anda berjalan di Amazon RDS, pilih Pilih instans DB RDS, lalu pilih instance dari daftar. Jika tidak, pilih mesin sumber dan berikan informasi koneksi melalui Manajer Rahasia AWS atau secara manual.
- Untuk Pengidentifikasi titik akhir, masukkan nama untuk titik akhir; misalnya, sumber-postgresql.
- Pilih Buat titik akhir.
Terapkan solusi menggunakan AWS CloudFormation
Buat tumpukan CloudFormation menggunakan templat yang disediakan. Selesaikan langkah-langkah berikut:
- Pilih Luncurkan Tumpukan:

- Pilih Selanjutnya.
- Berikan nama tumpukan, seperti
transactionaldl-postgresql. - Masukkan parameter yang diperlukan:
- DMSS3EndpointIAMRolARN – Peran IAM ARN untuk AWS DMS untuk menulis data ke Amazon S3.
- ReplikasiInstanceArn – Contoh replikasi AWS DMS ARN.
- S3BucketStage – Nama bucket yang ada digunakan untuk lapisan tahapan data lake.
- S3EmberLem – Nama bucket S3 yang ada untuk menyimpan skrip AWS Glue.
- S3BucketMentah – Nama bucket yang ada yang digunakan untuk lapisan mentah data lake.
- SumberEndpointArn – ARN titik akhir AWS DMS yang Anda buat sebelumnya.
- Nama asal – Pengidentifikasi sewenang-wenang dari sumber data untuk direplikasi (misalnya,
postgres). Ini digunakan untuk menentukan jalur S3 data lake (lapisan mentah) tempat data akan disimpan.
- Jangan ubah parameter berikut:
- SumberS3BucketBlog – Nama bucket tempat skrip AWS Glue yang disediakan disimpan.
- SumberS3BucketPrefix – Nama awalan bucket tempat skrip AWS Glue yang disediakan disimpan.
- Pilih Selanjutnya dua kali.
- Pilih Saya mengakui bahwa AWS CloudFormation dapat membuat sumber daya IAM dengan nama khusus.
- Pilih Buat tumpukan.
Setelah kira-kira 5 menit, tumpukan CloudFormation diterapkan.
Tinjau tugas replikasi AWS DMS
Penerapan AWS CloudFormation membuat titik akhir target AWS DMS untuk Anda. Karena dua pengaturan titik akhir tertentu, data akan diserap sesuai kebutuhan di Amazon S3.
- Di konsol AWS DMS, pilih Titik akhir di panel navigasi.
- Cari dan pilih titik akhir yang dimulai dengan
dmsIcebergs3endpoint. - Tinjau pengaturan titik akhir:
DataFormatditentukan sebagaiparquet.TimestampColumnNameakan menambahkan kolomlast_update_timedengan tanggal pembuatan catatan di Amazon S3.

Penerapan juga membuat tugas replikasi DMS AWS yang dimulai dengan dmsicebergtask.
- Pilih Tugas replikasi di panel navigasi dan cari tugas.
Anda akan melihat bahwa Jenis Tugas ditandai sebagai Muatan penuh, replikasi berkelanjutan. AWS DMS akan melakukan pemuatan penuh awal dari data yang ada, lalu membuat file inkremental dengan perubahan yang dilakukan pada database sumber.
pada Aturan Pemetaan tab, ada dua jenis aturan:
- Aturan pemilihan dengan nama skema sumber dan tabel yang akan diserap dari database sumber. Secara default, ini menggunakan database sampel yang disediakan di prasyarat,
dms_sample, dan semua tabel dengan kata kunci %. - Dua aturan transformasi yang menyertakan dalam file target di Amazon S3 nama skema dan nama tabel sebagai kolom. Ini digunakan oleh tugas AWS Glue kami untuk mengetahui tabel mana yang sesuai dengan file di data lake.
Untuk mempelajari selengkapnya tentang cara menyesuaikan ini untuk sumber data Anda sendiri, lihat Aturan dan tindakan seleksi.

Mari ubah beberapa konfigurasi untuk menyelesaikan persiapan tugas kita.
- pada tindakan menu, pilih memodifikasi.
- Dalam majalah Pengaturan Tugas bagian, di bawah Hentikan tugas setelah beban penuh selesai, pilih Berhenti setelah menerapkan perubahan yang di-cache.
Dengan cara ini, kita dapat mengontrol pemuatan awal dan pembuatan file tambahan sebagai dua langkah berbeda. Kami menggunakan pendekatan dua langkah ini untuk menjalankan tugas AWS Glue satu kali per setiap langkah.
- Bawah Log tugas, pilih Aktifkan log CloudWatch.
- Pilih Save.
- Tunggu sekitar 1 menit hingga status tugas migrasi database ditampilkan sebagai Siap.
Tambahkan izin untuk enkripsi dan dekripsi atau Lake Formation
Secara opsional, Anda dapat menambahkan izin untuk enkripsi dan dekripsi atau Formasi Danau.
Tambahkan izin enkripsi dan dekripsi
Jika bucket S3 Anda yang digunakan untuk lapisan mentah dan tahap dienkripsi menggunakan Layanan Manajemen Kunci AWS (AWS KMS) kunci yang dikelola pelanggan, Anda perlu menambahkan izin untuk mengizinkan pekerjaan AWS Glue mengakses data:
Tambahkan izin Formasi Danau
Jika Anda mengelola izin menggunakan Lake Formation, Anda harus mengizinkan pekerjaan AWS Glue Anda untuk membuat database dan tabel domain Anda melalui peran IAM GlueJobRole.
- Berikan izin untuk membuat database (untuk instruksi, lihat Membuat Basis Data).
- Berikan izin SUPER ke
defaultdatabase. - Berikan izin lokasi data.
- Jika Anda membuat database secara manual, berikan izin pada semua database untuk membuat tabel. Mengacu pada Pemberian izin tabel menggunakan konsol Lake Formation dan metode sumber daya bernama or Pemberian izin Katalog Data menggunakan metode LF-TBAC sesuai dengan kasus penggunaan Anda.
Setelah Anda menyelesaikan langkah selanjutnya untuk melakukan pemuatan data awal, pastikan juga menambahkan izin bagi konsumen untuk membuat kueri tabel. Peran pekerjaan akan menjadi pemilik semua tabel yang dibuat, dan admin data lake kemudian dapat memberikan hibah kepada pengguna tambahan.
Tinjau konfigurasi tabel di Parameter Store
Tugas AWS Glue yang melakukan penyerapan data ke dalam tabel Iceberg menggunakan spesifikasi tabel yang disediakan di Parameter Store. Selesaikan langkah-langkah berikut untuk meninjau penyimpanan parameter yang telah dikonfigurasi secara otomatis untuk Anda. Jika perlu, modifikasi sesuai dengan kebutuhan Anda sendiri.
- Di konsol Parameter Store, pilih Parameter saya di panel navigasi.
Tumpukan CloudFormation membuat dua parameter:
iceberg-configuntuk konfigurasi pekerjaaniceberg-tablesuntuk konfigurasi tabel
- Pilih parameternya meja gunung es.
Struktur JSON berisi informasi yang digunakan AWS Glue untuk membaca data dan menulis tabel Gunung Es di domain target:
- Satu objek per meja – Nama objek dibuat menggunakan nama skema, titik, dan nama tabel; Misalnya,
schema.table. - kunci utama – Ini harus ditentukan untuk setiap tabel sumber. Anda dapat memberikan satu kolom atau daftar kolom yang dipisahkan koma (tanpa spasi).
- partisiCols – Ini secara opsional mempartisi kolom untuk tabel target. Jika Anda tidak ingin membuat tabel terpartisi, berikan string kosong. Jika tidak, berikan satu kolom atau daftar kolom yang dipisahkan koma untuk digunakan (tanpa spasi).
- Jika Anda ingin menggunakan sumber data Anda sendiri, gunakan kode JSON berikut dan ganti teks dalam CAPS dari template yang disediakan. Jika Anda menggunakan contoh sumber data yang disediakan, pertahankan setelan default:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Pilih Simpan perubahan.
Lakukan pemuatan data awal
Sekarang setelah konfigurasi yang diperlukan selesai, kami menyerap data awal. Langkah ini mencakup tiga bagian: menyerap data dari database relasional sumber ke dalam lapisan mentah data lake, membuat tabel Gunung Es pada lapisan tahap data lake, dan memverifikasi hasil menggunakan Athena.
Serap data ke dalam lapisan mentah data lake
Untuk menyerap data dari sumber data relasional (PostgreSQL jika Anda menggunakan sampel yang disediakan) ke data lake transaksional kami menggunakan Iceberg, selesaikan langkah-langkah berikut:
- Di konsol AWS DMS, pilih Tugas migrasi basis data di panel navigasi.
- Pilih tugas replikasi yang Anda buat dan pada tindakan menu, pilih Mulai ulang/Lanjutkan.
- Tunggu sekitar 5 menit hingga tugas replikasi selesai. Anda dapat memantau tabel yang diserap di statistika tab tugas replikasi.

Setelah beberapa menit, tugas selesai dengan pesan tersebut Beban penuh selesai.
- Di konsol Amazon S3, pilih bucket yang Anda tetapkan sebagai lapisan mentah.
Di bawah awalan S3 yang ditentukan di AWS DMS (misalnya, postgres), Anda akan melihat hierarki folder dengan struktur berikut:
- Skema
- Nama tabel
LOAD00000001.parquetLOAD0000000N.parquet
- Nama tabel

Jika bucket S3 Anda kosong, tinjau Memecahkan masalah tugas migrasi di AWS Database Migration Service sebelum menjalankan pekerjaan AWS Glue.
Membuat dan menyerap data ke dalam tabel Gunung Es
Sebelum menjalankan tugas, mari buka skrip tugas AWS Glue yang disediakan sebagai bagian dari tumpukan CloudFormation untuk memahami perilakunya.
- Di konsol AWS Glue Studio, pilih Jobs di panel navigasi.
- Cari pekerjaan yang dimulai dengan
IcebergJob-dan akhiran nama tumpukan CloudFormation Anda (misalnya,IcebergJob-transactionaldl-postgresql). - Pilih pekerjaan.

Skrip pekerjaan mendapatkan konfigurasi yang diperlukan dari Parameter Store. Fungsi getConfigFromSSM() mengembalikan konfigurasi terkait pekerjaan seperti bucket sumber dan target tempat data perlu dibaca dan ditulis. Variabel ssmparam_table_values berisi informasi terkait tabel seperti domain data, nama tabel, kolom partisi, dan kunci utama dari tabel yang perlu dicerna. Lihat kode Python berikut:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Skrip menggunakan nama katalog arbitrer untuk Iceberg yang didefinisikan sebagai my_catalog. Ini diterapkan pada Katalog Data AWS Glue menggunakan konfigurasi Spark, sehingga operasi SQL yang menunjuk ke my_catalog akan diterapkan pada Katalog Data. Lihat kode berikut:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Skrip mengulang tabel yang ditentukan di Parameter Store dan menjalankan logika untuk mendeteksi jika tabel ada dan jika data yang masuk adalah beban awal atau upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Grafik initialLoadRecordsSparkSQL() fungsi memuat data awal saat tidak ada kolom operasi di file S3. AWS DMS menambahkan kolom ini hanya ke file data Parket yang dihasilkan oleh replikasi berkelanjutan (CDC). Pemuatan data dilakukan menggunakan perintah INSERT INTO dengan SparkSQL. Lihat kode berikut:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Sekarang kami menjalankan tugas AWS Glue untuk menyerap data awal ke dalam tabel Gunung Es. Tumpukan CloudFormation menambahkan --datalake-formats parameter, menambahkan pustaka Iceberg yang diperlukan ke pekerjaan.
- Pilih Jalankan pekerjaan.
- Pilih Pekerjaan Berjalan untuk memantau statusnya. Tunggu sampai statusnya Jalankan Berhasil.
Verifikasi data yang dimuat
Untuk mengonfirmasi bahwa pekerjaan memproses data seperti yang diharapkan, selesaikan langkah-langkah berikut:
- Di konsol Athena, pilih Editor Kueri di panel navigasi.
- Memeriksa
AwsDataCatalogdipilih sebagai sumber data. - Bawah Basis Data, pilih domain data yang ingin Anda jelajahi, berdasarkan konfigurasi yang Anda tetapkan di penyimpanan parameter. Jika menggunakan database sampel yang disediakan, gunakan
sports.
Bawah Tabel dan tampilan, kita bisa melihat daftar tabel yang dibuat oleh job AWS Glue.
- Pilih menu opsi (tiga titik) di sebelah nama tabel pertama, lalu pilih Pratinjau Data.
Anda dapat melihat data dimuat ke dalam tabel Iceberg. 
Lakukan pemuatan data tambahan
Sekarang kami mulai menangkap perubahan dari basis data relasional kami dan menerapkannya ke danau data transaksional. Langkah ini juga dibagi dalam tiga bagian: merekam perubahan, menerapkannya ke tabel Gunung Es, dan memverifikasi hasilnya.
Menangkap perubahan dari database relasional
Karena konfigurasi yang kami tentukan, tugas replikasi berhenti setelah menjalankan fase beban penuh. Sekarang kita memulai kembali tugas untuk menambahkan file inkremental dengan perubahan ke dalam lapisan mentah data lake.
- Di konsol AWS DMS, pilih tugas yang kami buat dan jalankan sebelumnya.
- pada tindakan menu, pilih Lanjut.
- Pilih Mulai tugas untuk mulai menangkap perubahan.
- Untuk memicu pembuatan file baru di data lake, lakukan penyisipan, pembaruan, atau penghapusan pada tabel database sumber Anda menggunakan alat administrasi database pilihan Anda. Jika menggunakan database sampel yang disediakan, Anda dapat menjalankan perintah SQL berikut:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Di halaman detail tugas AWS DMS, pilih Statistik tabel tab untuk melihat perubahan yang diambil.

- Buka lapisan mentah data lake untuk menemukan file baru yang menyimpan perubahan inkremental di dalam awalan setiap tabel, misalnya di bawah
sporting_eventawalan.
Rekor dengan perubahan untuk sporting_event tabel tampak seperti tangkapan layar berikut.

Perhatikan Op kolom di awal diidentifikasi dengan pembaruan (U). Selain itu, nilai tanggal/waktu kedua adalah kolom kontrol yang ditambahkan oleh AWS DMS dengan waktu perubahan direkam.

Terapkan perubahan pada tabel Gunung Es menggunakan AWS Glue
Sekarang kami menjalankan pekerjaan AWS Glue lagi, dan itu hanya akan memproses file inkremental baru secara otomatis sejak bookmark pekerjaan diaktifkan. Mari kita tinjau cara kerjanya.
Grafik dedupCDCRecords() function melakukan deduplikasi data karena beberapa perubahan pada satu ID rekaman dapat direkam dalam file data yang sama di Amazon S3. Deduplikasi dilakukan berdasarkan last_update_time kolom ditambahkan oleh AWS DMS yang menunjukkan stempel waktu saat perubahan direkam. Lihat kode Python berikut:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFPada saluran 99, the upsertRecordsSparkSQL() fungsi melakukan upsert dengan cara yang mirip dengan pemuatan awal, tetapi kali ini dengan perintah SQL MERGE.
Tinjau perubahan yang diterapkan
Buka konsol Athena dan jalankan kueri yang memilih rekaman yang diubah pada database sumber. Jika menggunakan database sampel yang disediakan, gunakan salah satu kueri SQL berikut:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Pantau konsumsi tabel
Skrip pekerjaan AWS Glue dikodekan dengan sederhana Penanganan pengecualian python untuk menangkap kesalahan selama memproses tabel tertentu. Bookmark pekerjaan disimpan setelah setiap tabel selesai diproses dengan sukses, untuk menghindari pemrosesan ulang tabel jika pekerjaan yang dijalankan dicoba ulang untuk tabel dengan kesalahan.
Grafik Antarmuka Baris Perintah AWS (AWS CLI) menyediakan a get-job-bookmark perintah untuk AWS Glue yang memberikan wawasan tentang status bookmark untuk setiap tabel yang diproses.
- Di konsol AWS Glue Studio, pilih pekerjaan ETL.
- Pilih Pekerjaan Berjalan tab dan salin ID proses pekerjaan.
- Jalankan perintah berikut di terminal yang diautentikasi untuk AWS CLI, ganti
<GLUE_JOB_RUN_ID>pada baris 1 dengan nilai yang Anda salin. Jika tumpukan CloudFormation Anda tidak diberi namatransactionaldl-postgresql, berikan nama pekerjaan Anda pada baris 2 skrip:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunDalam solusi ini, saat pemrosesan tabel menyebabkan pengecualian, pekerjaan AWS Glue tidak akan gagal menurut logika ini. Sebagai gantinya, tabel akan ditambahkan ke dalam larik yang dicetak setelah pekerjaan selesai. Dalam skenario tersebut, pekerjaan akan ditandai sebagai gagal setelah mencoba memproses sisa tabel yang terdeteksi pada sumber data mentah. Dengan cara ini, tabel tanpa kesalahan tidak perlu menunggu hingga pengguna mengidentifikasi dan menyelesaikan masalah pada tabel yang berkonflik. Pengguna dapat dengan cepat mendeteksi pekerjaan yang berjalan yang memiliki masalah menggunakan status pekerjaan yang dijalankan AWS Glue, dan mengidentifikasi tabel spesifik mana yang menyebabkan masalah menggunakan log CloudWatch untuk pekerjaan yang dijalankan.
- Skrip pekerjaan mengimplementasikan fitur ini dengan kode Python berikut:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')Tangkapan layar berikut menampilkan cara log CloudWatch mencari tabel yang menyebabkan kesalahan pemrosesan.

Selaras dengan Lensa Analisis Data Kerangka AWS Well-Architected praktik, Anda dapat mengadaptasi mekanisme kontrol yang lebih canggih untuk mengidentifikasi dan memberi tahu pemangku kepentingan ketika kesalahan muncul di saluran data. Misalnya, Anda dapat menggunakan an Amazon DynamoDB tabel kontrol untuk menyimpan semua tabel dan pekerjaan berjalan dengan kesalahan, atau menggunakan Layanan Pemberitahuan Sederhana Amazon (Amazon SNS) ke mengirim peringatan ke operator ketika kriteria tertentu terpenuhi.
Jadwalkan pemuatan data batch tambahan
Tumpukan CloudFormation menyebarkan sebuah Jembatan Acara Amazon aturan (dinonaktifkan secara default) yang dapat memicu pekerjaan AWS Glue untuk berjalan sesuai jadwal. Untuk menyediakan jadwal Anda sendiri dan mengaktifkan aturan, selesaikan langkah-langkah berikut:
- Di konsol EventBridge, pilih Peraturan di panel navigasi.
- Cari aturan yang diawali dengan nama tumpukan CloudFormation Anda diikuti dengan
JobTrigger(sebagai contoh,transactionaldl-postgresql-JobTrigger-randomvalue). - Pilih aturannya.
- Bawah Jadwal Acara, pilih Edit.
Jadwal default dikonfigurasi untuk memicu setiap jam.
- Berikan jadwal yang Anda inginkan untuk menjalankan pekerjaan.
- Selain itu, Anda dapat menggunakan Ekspresi cron EventBridge dengan memilih Jadwal yang halus.

- Saat Anda selesai menyiapkan ekspresi cron, pilih Selanjutnya tiga kali, dan akhirnya memilih Perbarui Aturan untuk menyimpan perubahan.
Aturan dibuat dinonaktifkan secara default untuk memungkinkan Anda menjalankan pemuatan data awal terlebih dahulu.
- Aktifkan aturan dengan memilih Aktifkan.
Anda dapat menggunakan Pemantauan tab untuk melihat pemanggilan aturan, atau langsung di AWS Glue Jalankan Pekerjaan rincian.
Kesimpulan
Setelah menerapkan solusi ini, Anda telah mengotomatiskan penyerapan tabel Anda pada satu sumber data relasional. Organisasi yang menggunakan data lake sebagai platform data pusatnya biasanya perlu menangani banyak, terkadang bahkan puluhan sumber data. Selain itu, semakin banyak kasus penggunaan yang mengharuskan organisasi menerapkan kemampuan transaksional ke data lake. Anda dapat menggunakan solusi ini untuk mempercepat penerapan kemampuan tersebut di semua sumber data relasional Anda untuk mengaktifkan kasus penggunaan bisnis baru, mengotomatiskan proses penerapan untuk memperoleh lebih banyak nilai dari data Anda.
Tentang Penulis
 Luis Gerardo Baeza adalah Arsitek Data Besar di Lab Data Amazon Web Services (AWS). Dia memiliki 12 tahun pengalaman membantu organisasi di sektor kesehatan, keuangan dan pendidikan untuk mengadopsi program arsitektur perusahaan, komputasi awan, dan kemampuan analitik data. Luis saat ini membantu organisasi di seluruh Amerika Latin untuk mempercepat inisiatif data strategis.
Luis Gerardo Baeza adalah Arsitek Data Besar di Lab Data Amazon Web Services (AWS). Dia memiliki 12 tahun pengalaman membantu organisasi di sektor kesehatan, keuangan dan pendidikan untuk mengadopsi program arsitektur perusahaan, komputasi awan, dan kemampuan analitik data. Luis saat ini membantu organisasi di seluruh Amerika Latin untuk mempercepat inisiatif data strategis.
 SaiKiran Reddy Aenugu adalah Arsitek Data di Lab Data Amazon Web Services (AWS). Dia memiliki 10 tahun pengalaman menerapkan proses pemuatan data, transformasi, dan visualisasi. SaiKiran saat ini membantu organisasi di Amerika Utara untuk mengadopsi arsitektur data modern seperti data lake dan data mesh. Ia memiliki pengalaman di sektor ritel, maskapai penerbangan, dan keuangan.
SaiKiran Reddy Aenugu adalah Arsitek Data di Lab Data Amazon Web Services (AWS). Dia memiliki 10 tahun pengalaman menerapkan proses pemuatan data, transformasi, dan visualisasi. SaiKiran saat ini membantu organisasi di Amerika Utara untuk mengadopsi arsitektur data modern seperti data lake dan data mesh. Ia memiliki pengalaman di sektor ritel, maskapai penerbangan, dan keuangan.
 Narendra Merla adalah Arsitek Data di Lab Data Amazon Web Services (AWS). Dia memiliki 12 tahun pengalaman dalam merancang dan memproduksi data pipeline real-time dan berorientasi batch serta membangun data lake di lingkungan cloud dan on-premise. Narendra saat ini membantu organisasi di Amerika Utara untuk membangun dan merancang arsitektur data yang kuat, dan memiliki pengalaman di sektor telekomunikasi dan keuangan.
Narendra Merla adalah Arsitek Data di Lab Data Amazon Web Services (AWS). Dia memiliki 12 tahun pengalaman dalam merancang dan memproduksi data pipeline real-time dan berorientasi batch serta membangun data lake di lingkungan cloud dan on-premise. Narendra saat ini membantu organisasi di Amerika Utara untuk membangun dan merancang arsitektur data yang kuat, dan memiliki pengalaman di sektor telekomunikasi dan keuangan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Tentang Kami
- mempercepat
- mengakses
- Menurut
- mengakui
- di seluruh
- menyesuaikan
- menambahkan
- Tambahan
- Selain itu
- Menambahkan
- admin
- administrasi
- mengambil
- Adopsi
- Setelah
- perusahaan penerbangan
- Semua
- sudah
- Amazon
- Amazon Athena
- Amazon RDS
- Amazon Web Services
- Layanan Web Amazon (AWS)
- Amerika
- analisis
- analisis
- dan
- Angeles
- Apache
- muncul
- Aplikasi
- terapan
- Menerapkan
- pendekatan
- sekitar
- arsitektur
- susunan
- terkait
- dikonfirmasi
- mengotomatisasikan
- Otomatis
- secara otomatis
- mengotomatisasi
- rata-rata
- menghindari
- AWS
- Formasi AWS Cloud
- Lem AWS
- berdasarkan
- kelelawar
- karena
- menjadi
- sebelum
- Awal
- Besar
- Big data
- membangun
- pembangun
- Bangunan
- bisnis
- Bisa Dapatkan
- kemampuan
- topi
- menangkap
- Menangkap
- kasus
- kasus
- katalog
- gulat
- Menyebabkan
- penyebab
- menyebabkan
- CDC
- pusat
- tertentu
- perubahan
- Perubahan
- pilihan
- Pilih
- memilih
- terpilih
- awan
- komputasi awan
- kode
- Kolom
- Kolom
- perusahaan
- lengkap
- komputasi
- konfigurasi
- konfigurasi
- Memastikan
- Berbenturan
- Terhubung
- koneksi
- pertimbangan
- konsul
- Konsumen
- konsumsi
- mengandung
- terus
- kontinu
- kontrol
- bisa
- membuat
- dibuat
- menciptakan
- membuat
- penciptaan
- kriteria
- Sekarang
- adat
- pelanggan
- menyesuaikan
- data
- Data Analytics
- Danau Data
- Platform Data
- Basis Data
- database
- Tanggal
- Default
- didefinisikan
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- menyebarkan
- Mendesain
- dirancang
- merancang
- rincian
- terdeteksi
- Pengembangan
- berbeda
- langsung
- cacat
- Terbagi
- Tidak
- domain
- domain
- Dont
- selama
- setiap
- Terdahulu
- mudah
- Pendidikan
- usaha
- antara
- aktif
- diaktifkan
- terenkripsi
- enkripsi
- Titik akhir
- Mesin
- Enter
- Enterprise
- lingkungan
- kesalahan
- Eter (ETH)
- Bahkan
- Setiap
- contoh
- melebihi
- Kecuali
- pengecualian
- ada
- ada
- diharapkan
- mengharapkan
- pengalaman
- menyelidiki
- ekstensi
- ekstrak
- Gagal
- akrab
- Fashion
- Fitur
- beberapa
- File
- File
- Akhirnya
- keuangan
- keuangan
- Menemukan
- menyelesaikan
- Pertama
- diikuti
- berikut
- Untuk Konsumen
- bentuk
- pembentukan
- Kerangka
- dari
- penuh
- fungsi
- dihasilkan
- generasi
- mendapatkan
- memberikan
- beasiswa
- Pertumbuhan
- menangani
- kesehatan
- membantu
- membantu
- hirarki
- sejarah
- memegang
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- besar
- IAM
- diidentifikasi
- identifier
- mengidentifikasi
- mengenali
- melaksanakan
- implementasi
- diimplementasikan
- mengimplementasikan
- mengimplementasikan
- perbaikan
- in
- memasukkan
- termasuk
- Termasuk
- masuk
- menunjukkan
- sendiri-sendiri
- informasi
- mulanya
- inisiatif
- Sisipan
- wawasan
- contoh
- sebagai gantinya
- instruksi
- Menengah
- isu
- masalah
- IT
- perulangan
- Pekerjaan
- Jobs
- json
- Menjaga
- kunci
- kunci-kunci
- Tahu
- laboratorium
- danau
- Latin
- Amerika Latin
- lapisan
- lapisan
- memimpin
- BELAJAR
- perpustakaan
- MEMBATASI
- baris
- Daftar
- memuat
- pemuatan
- beban
- tempat
- melihat
- TERLIHAT
- itu
- Los Angeles
- Lot
- Utama
- mempertahankan
- membuat
- berhasil
- pengelolaan
- manajer
- pelaksana
- manual
- banyak
- pemetaan
- ditandai
- menu
- Bergabung
- pesan
- mungkin
- migrasi
- minimum
- menit
- menit
- modern
- memodifikasi
- Memantau
- pemantauan
- lebih
- paling
- Paling Populer
- beberapa
- nama
- Bernama
- nama
- Arahkan
- Navigasi
- Perlu
- dibutuhkan
- kebutuhan
- New
- berikutnya
- utara
- Amerika Utara
- pemberitahuan
- jumlah
- obyek
- objek
- ONE
- terus-menerus
- OP
- operasi
- dioptimalkan
- Opsi
- organisatoris
- organisasi
- terorganisir
- asli
- jika tidak
- di luar
- sendiri
- pemilik
- pane
- parameter
- parameter
- bagian
- bagian
- path
- pola
- melakukan
- melakukan
- melakukan
- periode
- Izin
- tahap
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Populer
- Pos
- Postgresql
- praktek
- disukai
- prasyarat
- menyajikan
- primer
- Masalah
- proses
- proses
- pengolahan
- Diproduksi
- program
- memberikan
- disediakan
- menyediakan
- Ular sanca
- segera
- menaikkan
- Penilaian
- Mentah
- data mentah
- Baca
- real-time
- catatan
- arsip
- menggantikan
- direplikasi
- replikasi
- membutuhkan
- wajib
- sumber
- Sumber
- ISTIRAHAT
- Hasil
- eceran
- kembali
- Pengembalian
- ulasan
- kuat
- Peran
- Aturan
- aturan
- Run
- berjalan
- sama
- Save
- skenario
- menjadwalkan
- cakupan
- script
- Pencarian
- Kedua
- Sektor
- melihat
- terpilih
- memilih
- seleksi
- terpisah
- Layanan
- set
- pengaturan
- pengaturan
- harus
- Menunjukkan
- Pertunjukkan
- mirip
- Sederhana
- sejak
- tunggal
- So
- larutan
- Memecahkan
- beberapa
- mutakhir
- sumber
- sumber
- spasi
- percikan
- tertentu
- spesifikasi
- ditentukan
- Olahraga
- SQL
- tumpukan
- Tumpukan
- Tahap
- stakeholder
- awal
- mulai
- Mulai
- dimulai
- Negara
- statistika
- Status
- Langkah
- Tangga
- terhenti
- penyimpanan
- menyimpan
- tersimpan
- toko
- Strategis
- struktur
- tersusun
- studio
- berhasil
- seperti itu
- besar
- mendukung
- sistem
- tabel
- target
- tugas
- tugas
- tim
- tim
- telekomunikasi
- Template
- terminal
- Grafik
- Sumber
- mereka
- ribuan
- tiga
- Melalui
- waktu
- waktu
- kali
- timestamp
- untuk
- alat
- puncak
- Total
- Pelacakan
- tradisional
- transaksional
- Mengubah
- Transformasi
- memicu
- tutorial
- jenis
- bawah
- memahami
- unik
- Memperbarui
- Pembaruan
- menggunakan
- gunakan case
- Pengguna
- Pengguna
- biasanya
- nilai
- memverifikasi
- View
- visualisasi
- volume
- menunggu
- Gudang
- jaringan
- layanan web
- yang
- akan
- dalam
- tanpa
- bekerja
- menulis
- tertulis
- yaml
- tahun
- tahun
- Anda
- zephyrnet.dll