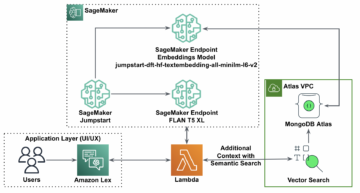
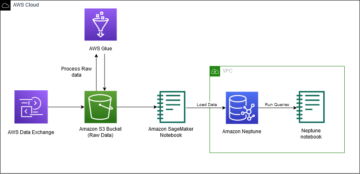
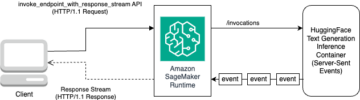
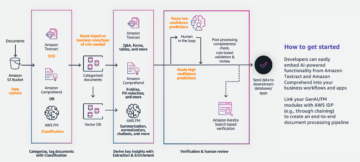
Amazon SageMaker adalah layanan pembelajaran mesin (ML) yang dikelola sepenuhnya. Dengan SageMaker, ilmuwan data dan pengembang dapat dengan cepat dan mudah membuat dan melatih model ML, lalu menerapkannya langsung ke lingkungan yang siap untuk produksi dan dihosting. Ini memberikan instans notebook pembuat Jupyter terintegrasi untuk akses mudah ke sumber data Anda untuk eksplorasi dan analisis, sehingga Anda tidak perlu mengelola server. Ini juga menyediakan umum Algoritme ML yang dioptimalkan untuk berjalan secara efisien terhadap data yang sangat besar dalam lingkungan terdistribusi.
Inferensi real-time SageMaker ideal untuk beban kerja yang memiliki persyaratan real-time, interaktif, dan latensi rendah. Dengan inferensi real-time SageMaker, Anda dapat menerapkan titik akhir REST yang didukung oleh jenis instans tertentu dengan jumlah komputasi dan memori tertentu. Menerapkan titik akhir real-time SageMaker hanyalah langkah pertama menuju produksi untuk banyak pelanggan. Kami ingin dapat memaksimalkan kinerja titik akhir untuk mencapai target transaksi per detik (TPS) dengan tetap mematuhi persyaratan latensi. Sebagian besar pengoptimalan kinerja untuk inferensi adalah memastikan Anda memilih jenis instans yang tepat dan menghitung untuk mendukung titik akhir.
Posting ini menjelaskan praktik terbaik untuk memuat pengujian titik akhir SageMaker guna menemukan konfigurasi yang tepat untuk jumlah instans dan ukuran. Hal ini dapat membantu kami memahami persyaratan instans minimum yang disediakan untuk memenuhi persyaratan latensi dan TPS kami. Dari sana, kami menyelami bagaimana Anda dapat melacak dan memahami metrik dan kinerja titik akhir SageMaker dengan memanfaatkan amazoncloudwatch metrik.
Kami pertama-tama mengukur kinerja model kami pada satu instans untuk mengidentifikasi TPS yang dapat ditanganinya sesuai dengan persyaratan latensi yang dapat diterima. Kemudian kami mengekstrapolasi temuan untuk memutuskan jumlah instans yang kami perlukan untuk menangani lalu lintas produksi kami. Terakhir, kami mensimulasikan lalu lintas tingkat produksi dan menyiapkan pengujian beban untuk titik akhir SageMaker real-time guna mengonfirmasi bahwa titik akhir kami dapat menangani beban tingkat produksi. Seluruh rangkaian kode untuk contoh tersedia di bawah ini Repositori GitHub.
Ikhtisar solusi
Untuk posting ini, kami menggunakan pra-terlatih Model DistilBERT Wajah Memeluk dari Memeluk Wajah Hub. Model ini dapat melakukan sejumlah tugas, tetapi kami mengirimkan payload khusus untuk analisis sentimen dan klasifikasi teks. Dengan contoh payload ini, kami berupaya untuk mencapai 1000 TPS.
Terapkan titik akhir waktu nyata
Posting ini menganggap Anda sudah familiar dengan cara menerapkan model. Mengacu pada Buat titik akhir Anda dan terapkan model Anda untuk memahami internal di balik hosting titik akhir. Untuk saat ini, kami dapat dengan cepat menunjuk ke model ini di Hugging Face Hub dan menerapkan titik akhir waktu nyata dengan cuplikan kode berikut:
Mari kita uji titik akhir kita dengan cepat dengan contoh payload yang ingin kita gunakan untuk pengujian beban:

Perhatikan bahwa kami mendukung titik akhir menggunakan satu Cloud komputasi elastis Amazon (Amazon EC2) dengan tipe ml.m5.12xlarge, yang berisi 48 vCPU dan 192 GiB memori. Jumlah vCPU merupakan indikasi yang baik dari konkurensi yang dapat ditangani instance. Secara umum, disarankan untuk menguji berbagai jenis instans untuk memastikan bahwa kami memiliki instans yang memiliki sumber daya yang digunakan dengan benar. Untuk melihat daftar lengkap instans SageMaker dan daya komputasi yang sesuai untuk Inferensi real-time, lihat Harga Amazon SageMaker.
Metrik untuk dilacak
Sebelum kita masuk ke pengujian beban, penting untuk memahami metrik apa yang harus dilacak untuk memahami perincian kinerja titik akhir SageMaker Anda. CloudWatch adalah alat logging utama yang digunakan SageMaker untuk membantu Anda memahami berbagai metrik yang menjelaskan kinerja titik akhir Anda. Anda dapat menggunakan log CloudWatch untuk men-debug pemanggilan titik akhir Anda; semua pernyataan logging dan cetak yang Anda miliki dalam kode inferensi Anda ditangkap di sini. Untuk informasi lebih lanjut, lihat Cara kerja Amazon CloudWatch.
Ada dua jenis metrik berbeda yang dicakup CloudWatch untuk SageMaker: metrik tingkat instans dan pemanggilan.
Metrik tingkat instans
Kumpulan parameter pertama yang perlu dipertimbangkan adalah metrik tingkat instans: CPUUtilization dan MemoryUtilization (untuk instans berbasis GPU, GPUUtilization). Untuk CPUUtilization, Anda mungkin melihat persentase di atas 100% pada awalnya di CloudWatch. Ini penting untuk disadari CPUUtilization, jumlah semua inti CPU sedang ditampilkan. Misalnya, jika instans di belakang titik akhir Anda berisi 4 vCPU, ini berarti rentang penggunaan hingga 400%. MemoryUtilization, di sisi lain, berada dalam kisaran 0–100%.
Secara khusus, Anda dapat menggunakan CPUUtilization untuk mendapatkan pemahaman yang lebih dalam tentang apakah Anda memiliki jumlah perangkat keras yang cukup atau bahkan berlebih. Jika Anda memiliki instans yang kurang dimanfaatkan (kurang dari 30%), Anda berpotensi menurunkan jenis instans Anda. Sebaliknya, jika penggunaan Anda sekitar 80–90%, sebaiknya pilih instans dengan komputasi/memori yang lebih besar. Dari pengujian kami, kami menyarankan sekitar 60–70% pemanfaatan perangkat keras Anda.
Metrik pemanggilan
Seperti namanya, metrik pemanggilan adalah tempat kami dapat melacak latensi end-to-end dari setiap pemanggilan ke titik akhir Anda. Anda dapat menggunakan metrik pemanggilan untuk mencatat jumlah kesalahan dan jenis kesalahan apa (5xx, 4xx, dan seterusnya) yang mungkin dialami titik akhir Anda. Lebih penting lagi, Anda dapat memahami perincian latensi panggilan titik akhir Anda. Banyak dari ini dapat ditangkap dengan ModelLatency dan OverheadLatency metrik, seperti yang diilustrasikan dalam diagram berikut.

Grafik ModelLatency metrik mencatat waktu yang dibutuhkan inferensi dalam wadah model di belakang titik akhir SageMaker. Perhatikan bahwa wadah model juga menyertakan kode atau skrip inferensi khusus yang telah Anda berikan untuk inferensi. Unit ini direkam dalam mikrodetik sebagai metrik pemanggilan, dan umumnya Anda dapat membuat grafik persentil di seluruh CloudWatch (p99, p90, dan seterusnya) untuk melihat apakah Anda memenuhi latensi target. Perhatikan bahwa beberapa faktor dapat memengaruhi model dan latensi penampung, seperti berikut ini:
- Skrip inferensi khusus – Apakah Anda telah mengimplementasikan wadah Anda sendiri atau menggunakan wadah berbasis SageMaker dengan penangan inferensi khusus, praktik terbaiknya adalah membuat profil skrip Anda untuk menangkap operasi apa pun yang secara khusus menambah banyak waktu ke latensi Anda.
- Protokol komunikasi – Pertimbangkan koneksi REST vs. gRPC ke server model dalam wadah model.
- Optimalisasi kerangka kerja model – Ini adalah kerangka kerja khusus, misalnya dengan TensorFlow, ada sejumlah variabel lingkungan yang dapat Anda atur khusus untuk Penayangan TF. Pastikan untuk memeriksa penampung apa yang Anda gunakan dan jika ada pengoptimalan khusus kerangka kerja yang dapat Anda tambahkan di dalam skrip atau sebagai variabel lingkungan untuk dimasukkan ke dalam penampung.
OverheadLatency diukur sejak SageMaker menerima permintaan hingga mengembalikan respons ke klien, dikurangi latensi model. Bagian ini sebagian besar berada di luar kendali Anda dan berada di bawah waktu yang diambil oleh overhead SageMaker.
Latensi end-to-end secara keseluruhan bergantung pada berbagai faktor dan belum tentu jumlah dari ModelLatency plus OverheadLatency. Misalnya, jika klien Anda membuat InvokeEndpoint Panggilan API melalui internet, dari perspektif klien, latensi end-to-end adalah internet + ModelLatency + OverheadLatency. Karena itu, saat memuat pengujian titik akhir Anda untuk mengukur titik akhir itu sendiri secara akurat, sebaiknya fokus pada metrik titik akhir (ModelLatency, OverheadLatency, dan InvocationsPerInstance) untuk mengukur titik akhir SageMaker secara akurat. Masalah apa pun yang terkait dengan latensi end-to-end kemudian dapat diisolasi secara terpisah.
Beberapa pertanyaan yang perlu dipertimbangkan untuk latensi end-to-end:
- Di mana klien yang memanggil titik akhir Anda?
- Apakah ada lapisan perantara antara klien Anda dan runtime SageMaker?
Penskalaan otomatis
Kami tidak membahas penskalaan otomatis dalam postingan ini secara khusus, tetapi ini merupakan pertimbangan penting untuk menyediakan jumlah instans yang benar berdasarkan beban kerja. Bergantung pada pola lalu lintas Anda, Anda dapat melampirkan kebijakan penskalaan otomatis ke titik akhir SageMaker Anda. Ada berbagai opsi penskalaan, seperti TargetTrackingScaling, SimpleScaling, dan StepScaling. Ini memungkinkan titik akhir Anda untuk masuk dan keluar secara otomatis berdasarkan pola lalu lintas Anda.
Opsi umum adalah pelacakan target, di mana Anda dapat menentukan metrik CloudWatch atau metrik khusus yang telah Anda tentukan dan skalakan berdasarkan itu. Pemanfaatan penskalaan otomatis yang sering dilakukan adalah melacak InvocationsPerInstance metrik. Setelah Anda mengidentifikasi bottleneck di TPS tertentu, Anda sering dapat menggunakannya sebagai metrik untuk menskalakan ke lebih banyak instans agar dapat menangani beban lalu lintas puncak. Untuk mendapatkan perincian yang lebih dalam tentang titik akhir penskalaan otomatis SageMaker, lihat Mengonfigurasi titik akhir inferensi penskalaan otomatis di Amazon SageMaker.
Uji beban
Meskipun kami menggunakan Locust untuk menampilkan bagaimana kami dapat memuat pengujian dalam skala besar, jika Anda mencoba menyesuaikan ukuran instans di belakang titik akhir Anda, Rekomendasi Inferensi SageMaker adalah pilihan yang lebih efisien. Dengan alat pengujian beban pihak ketiga, Anda harus menerapkan titik akhir secara manual di berbagai instans. Dengan Inference Recommender, Anda cukup melewatkan larik jenis instans yang ingin diuji bebannya, dan SageMaker akan berputar pekerjaan untuk masing-masing contoh ini.
Belalang
Untuk contoh ini, kami menggunakan Belalang, alat pengujian beban sumber terbuka yang dapat Anda implementasikan menggunakan Python. Locust mirip dengan banyak alat pengujian beban sumber terbuka lainnya, tetapi memiliki beberapa manfaat khusus:
- Mudah untuk mengatur – Seperti yang kami tunjukkan dalam posting ini, kami akan memberikan skrip Python sederhana yang dapat dengan mudah direfaktorisasi untuk titik akhir dan muatan spesifik Anda.
- Terdistribusi dan terukur – Locust berbasis peristiwa dan memanfaatkan acara Dibawah tenda. Ini sangat berguna untuk menguji beban kerja yang sangat bersamaan dan mensimulasikan ribuan pengguna secara bersamaan. Anda dapat mencapai TPS tinggi dengan satu proses yang menjalankan Locust, tetapi juga memiliki a pembangkitan beban terdistribusi fitur yang memungkinkan Anda untuk menskalakan ke beberapa proses dan mesin klien, seperti yang akan kita jelajahi di pos ini.
- Metrik belalang dan UI – Locust juga menangkap latensi end-to-end sebagai metrik. Ini dapat membantu melengkapi metrik CloudWatch Anda untuk memberikan gambaran lengkap tentang pengujian Anda. Ini semua ditangkap di Locust UI, tempat Anda dapat melacak pengguna, pekerja, dan lainnya secara bersamaan.
Untuk lebih memahami Locust, lihat mereka dokumentasi.
Penyiapan Amazon EC2
Anda dapat mengatur Locust di lingkungan apa pun yang kompatibel untuk Anda. Untuk posting ini, kami menyiapkan instans EC2 dan menginstal Locust di sana untuk melakukan pengujian. Kami menggunakan instans EC5.18 c2xlarge. Kekuatan komputasi sisi klien juga perlu dipertimbangkan. Saat Anda kehabisan daya komputasi di sisi klien, hal ini sering kali tidak ditangkap, dan disalahartikan sebagai kesalahan titik akhir SageMaker. Penting untuk menempatkan klien Anda di lokasi dengan daya komputasi yang memadai yang dapat menangani beban yang sedang Anda uji. Untuk instans EC2 kami, kami menggunakan Ubuntu Deep Learning AMI, tetapi Anda dapat menggunakan AMI apa pun selama Anda dapat menyiapkan Locust dengan benar di mesin. Untuk memahami cara meluncurkan dan menghubungkan ke instans EC2 Anda, lihat tutorialnya Memulai instans Amazon EC2 Linux.
UI Locust dapat diakses melalui port 8089. Kita dapat membukanya dengan menyesuaikan aturan grup keamanan masuk untuk Instans EC2. Kami juga membuka port 22 sehingga kami dapat SSH ke instans EC2. Pertimbangkan untuk membatasi sumber ke alamat IP spesifik tempat Anda mengakses instans EC2.

Setelah Anda terhubung ke instans EC2, kami menyiapkan lingkungan virtual Python dan menginstal Locust API sumber terbuka melalui CLI:
Kami sekarang siap bekerja dengan Locust untuk memuat pengujian titik akhir kami.
Pengujian belalang
Semua uji beban Locust dilakukan berdasarkan a File belalang yang Anda sediakan. File Locust ini menentukan tugas untuk uji beban; disinilah kita mendefinisikan Boto3 kita panggilan API invoke_endpoint. Lihat kode berikut:
Dalam kode sebelumnya, sesuaikan parameter pemanggilan endpoint agar sesuai dengan pemanggilan model spesifik Anda. Kami menggunakan InvokeEndpoint API menggunakan potongan kode berikut di file Locust; ini adalah titik uji coba beban kami. File Locust yang kami gunakan adalah belalang_script.py.
Sekarang setelah skrip Locust kami siap, kami ingin menjalankan pengujian Locust terdistribusi untuk menguji stres instans tunggal kami untuk mengetahui berapa banyak lalu lintas yang dapat ditangani instans kami.
Mode terdistribusi belalang sedikit lebih bernuansa daripada tes Locust proses tunggal. Dalam mode terdistribusi, kami memiliki satu pekerja utama dan banyak pekerja. Pekerja utama menginstruksikan pekerja tentang cara menelurkan dan mengontrol pengguna bersamaan yang mengirimkan permintaan. Di kami terdistribusi.sh skrip, kami melihat secara default bahwa 240 pengguna akan didistribusikan ke 60 pekerja. Perhatikan bahwa --headless flag di Locust CLI menghapus fitur UI dari Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Kami pertama kali menjalankan pengujian terdistribusi pada satu contoh yang mendukung titik akhir. Idenya di sini adalah kami ingin memaksimalkan satu instans sepenuhnya untuk memahami jumlah instans yang kami perlukan untuk mencapai target TPS kami sambil tetap berada dalam persyaratan latensi kami. Perhatikan bahwa jika Anda ingin mengakses UI, ubah Locust_UI variabel lingkungan ke True dan ambil IP publik instans EC2 Anda dan petakan port 8089 ke URL.
Tangkapan layar berikut menunjukkan metrik CloudWatch kami.

Akhirnya, kami melihat bahwa meskipun kami awalnya mencapai TPS 200, kami mulai melihat kesalahan 5xx di log sisi klien EC2 kami, seperti yang ditunjukkan pada tangkapan layar berikut.
Kami juga dapat memverifikasi ini dengan melihat metrik tingkat instans kami, khususnya CPUUtilization.
 Di sini kami perhatikan
Di sini kami perhatikan CPUUtilization hampir 4,800%. Contoh ml.m5.12x.large kami memiliki 48 vCPU (48 * 100 = 4800~). Ini memenuhi seluruh instance, yang juga membantu menjelaskan kesalahan 5xx kami. Kami juga melihat peningkatan ModelLatency.
Tampaknya instans tunggal kami terguling dan tidak memiliki komputasi untuk menopang beban melebihi 200 TPS yang kami amati. TPS target kita adalah 1000, jadi mari kita coba tingkatkan jumlah instans kita menjadi 5. Ini mungkin harus lebih banyak lagi dalam pengaturan produksi, karena kita mengamati kesalahan pada 200 TPS setelah titik tertentu.

Kami melihat di log Locust UI dan CloudWatch bahwa kami memiliki TPS hampir 1000 dengan lima instans mendukung titik akhir.

 Jika Anda mulai mengalami kesalahan bahkan dengan pengaturan perangkat keras ini, pastikan untuk memantau
Jika Anda mulai mengalami kesalahan bahkan dengan pengaturan perangkat keras ini, pastikan untuk memantau CPUUtilization untuk memahami gambaran lengkap di balik hosting titik akhir Anda. Sangat penting untuk memahami penggunaan perangkat keras Anda untuk melihat apakah Anda perlu meningkatkan atau bahkan menurunkan. Terkadang masalah tingkat penampung menyebabkan kesalahan 5xx, tetapi jika CPUUtilization rendah, ini menunjukkan bahwa itu bukan perangkat keras Anda tetapi sesuatu pada tingkat penampung atau model yang mungkin menyebabkan masalah ini (variabel lingkungan yang tepat untuk jumlah pekerja yang tidak disetel, misalnya). Di sisi lain, jika Anda melihat instans Anda semakin tersaturasi, itu adalah tanda bahwa Anda perlu menambah armada instans saat ini atau mencoba instans yang lebih besar dengan armada yang lebih kecil.
Meskipun kami meningkatkan jumlah instans menjadi 5 untuk menangani 100 TPS, kami dapat melihat bahwa ModelLatency metrik masih tinggi. Hal ini disebabkan kasus menjadi jenuh. Secara umum, kami menyarankan untuk memanfaatkan sumber daya instance antara 60–70%.
Membersihkan
Setelah pengujian beban, pastikan untuk membersihkan semua sumber daya yang tidak akan Anda gunakan melalui konsol SageMaker atau melalui hapus_titik akhir Panggilan API Boto3. Selain itu, pastikan untuk menghentikan instans EC2 Anda atau penyiapan klien apa pun yang Anda miliki agar tidak dikenai biaya lebih lanjut di sana.
Kesimpulan
Dalam postingan ini, kami menjelaskan bagaimana Anda dapat memuat pengujian titik akhir waktu-nyata SageMaker Anda. Kami juga membahas metrik apa yang harus Anda evaluasi saat memuat pengujian titik akhir Anda untuk memahami perincian kinerja Anda. Pastikan untuk memeriksa Rekomendasi Inferensi SageMaker untuk lebih memahami contoh ukuran yang tepat dan lebih banyak teknik pengoptimalan kinerja.
Tentang Penulis
 Marc Karpa adalah Arsitek ML dengan tim Layanan SageMaker. Dia berfokus untuk membantu pelanggan merancang, menerapkan, dan mengelola beban kerja ML dalam skala besar. Di waktu luangnya, ia senang bepergian dan menjelajahi tempat-tempat baru.
Marc Karpa adalah Arsitek ML dengan tim Layanan SageMaker. Dia berfokus untuk membantu pelanggan merancang, menerapkan, dan mengelola beban kerja ML dalam skala besar. Di waktu luangnya, ia senang bepergian dan menjelajahi tempat-tempat baru.
 Ram Vegaraju adalah Arsitek ML dengan tim Layanan SageMaker. Dia berfokus untuk membantu pelanggan membangun dan mengoptimalkan solusi AI/ML mereka di Amazon SageMaker. Di waktu luangnya, dia suka bepergian dan menulis.
Ram Vegaraju adalah Arsitek ML dengan tim Layanan SageMaker. Dia berfokus untuk membantu pelanggan membangun dan mengoptimalkan solusi AI/ML mereka di Amazon SageMaker. Di waktu luangnya, dia suka bepergian dan menulis.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Sanggup
- atas
- diterima
- mengakses
- dapat diakses
- mengakses
- akurat
- Mencapai
- di seluruh
- tambahan
- alamat
- Setelah
- terhadap
- AI / ML
- Bertujuan
- Semua
- memungkinkan
- Meskipun
- Amazon
- Amazon EC2
- Amazon SageMaker
- jumlah
- analisis
- dan
- api
- sekitar
- susunan
- melampirkan
- menulis
- mobil
- secara otomatis
- tersedia
- AWS
- kembali
- bersandaran
- beking
- berdasarkan
- karena
- di belakang
- makhluk
- patokan
- manfaat
- Manfaat
- TERBAIK
- Praktik Terbaik
- antara
- tubuh
- Kerusakan
- membangun
- C + +
- panggilan
- Panggilan
- Bisa Dapatkan
- menangkap
- menangkap
- gulat
- tertentu
- perubahan
- beban
- memeriksa
- kelas
- klasifikasi
- klien
- kode
- Umum
- cocok
- menghitung
- bersamaan
- Mengadakan
- konfigurasi
- Memastikan
- Terhubung
- terhubung
- Koneksi
- Mempertimbangkan
- pertimbangan
- konsul
- Wadah
- mengandung
- konteks
- kontrol
- Sesuai
- bisa
- menutupi
- meliputi
- CPU
- membuat
- sangat penting
- terbaru
- adat
- pelanggan
- data
- mendalam
- belajar mendalam
- lebih dalam
- Default
- Mendefinisikan
- mendemonstrasikan
- Tergantung
- tergantung
- menyebarkan
- penggelaran
- menggambarkan
- dijelaskan
- Mendesain
- pengembang
- berbeda
- langsung
- dibahas
- Display
- didistribusikan
- Tidak
- Dont
- turun
- setiap
- mudah
- efisien
- efisien
- antara
- memungkinkan
- ujung ke ujung
- Titik akhir
- Seluruh
- Lingkungan Hidup
- kesalahan
- kesalahan
- penting
- Eter (ETH)
- Bahkan
- contoh
- pengecualian
- menjalankan
- mengalami
- Menjelaskan
- eksplorasi
- menyelidiki
- Menjelajahi
- ekspor
- sangat
- Menghadapi
- faktor
- Air terjun
- akrab
- Fitur
- beberapa
- File
- Akhirnya
- Menemukan
- Pertama
- ARMADA KAPAL
- Fokus
- berfokus
- berikut
- format
- Kerangka
- sering
- dari
- penuh
- sepenuhnya
- lebih lanjut
- Umum
- umumnya
- mendapatkan
- mendapatkan
- baik
- grafik
- lebih besar
- Kelompok
- Grup
- menangani
- senang
- Perangkat keras
- membantu
- membantu
- membantu
- di sini
- High
- sangat
- kap
- tuan rumah
- host
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- Pusat
- ide
- ideal
- diidentifikasi
- mengenali
- Dampak
- melaksanakan
- diimplementasikan
- mengimpor
- penting
- in
- termasuk
- Meningkatkan
- Pada meningkat
- menunjukkan
- indikasi
- informasi
- mulanya
- install
- contoh
- terpadu
- interaktif
- Internet
- memanggil
- IP
- Alamat IP
- terpencil
- masalah
- IT
- Diri
- json
- besar
- sebagian besar
- lebih besar
- Latensi
- jalankan
- lapisan
- memimpin
- terkemuka
- pengetahuan
- Tingkat
- linux
- Daftar
- sedikit
- memuat
- beban
- tempat
- Panjang
- mencari
- Lot
- Rendah
- mesin
- Mesin belajar
- Mesin
- membuat
- Membuat
- mengelola
- berhasil
- manual
- banyak
- peta
- Maksimalkan
- cara
- Pelajari
- pertemuan
- Memori
- metrik
- Metrik
- mungkin
- minimum
- ML
- mode
- model
- model
- Memantau
- lebih
- lebih efisien
- beberapa
- nama
- hampir
- perlu
- Perlu
- New
- buku catatan
- jumlah
- ONE
- Buka
- open source
- Operasi
- optimasi
- Optimize
- dioptimalkan
- pilihan
- Opsi
- urutan
- Lainnya
- di luar
- sendiri
- cat
- parameter
- bagian
- Lulus
- lalu
- path
- pola
- pola
- Puncak
- melakukan
- prestasi
- perspektif
- memilih
- gambar
- bagian
- Tempat
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- plus
- Titik
- Pos
- berpotensi
- kekuasaan
- praktek
- praktek
- Predictor
- primer
- Mencetak
- masalah
- proses
- proses
- Produksi
- Profil
- tepat
- tepat
- memberikan
- menyediakan
- ketentuan
- publik
- Ular sanca
- Pertanyaan
- segera
- jarak
- siap
- real-time
- menyadari
- menerima
- direkomendasikan
- wilayah
- terkait
- permintaan
- Persyaratan
- Sumber
- tanggapan
- ISTIRAHAT
- mengakibatkan
- Hasil
- Pengembalian
- aturan
- Run
- berjalan
- pembuat bijak
- Inferensi SageMaker
- Skala
- skala
- ilmuwan
- Pelingkupan
- script
- Kedua
- keamanan
- tampaknya
- DIRI
- mengirim
- sentimen
- layanan
- porsi
- set
- pengaturan
- pengaturan
- penyiapan
- beberapa
- harus
- ditunjukkan
- Pertunjukkan
- menandatangani
- mirip
- Sederhana
- hanya
- tunggal
- Ukuran
- lebih kecil
- So
- Solusi
- sesuatu
- sumber
- sumber
- Menelurkan
- tertentu
- Secara khusus
- Berputar
- standar
- awal
- mulai
- Laporan
- Langkah
- Masih
- berhenti
- tekanan
- berjuang
- seperti itu
- cukup
- setelan
- besar
- suplemen
- Mengambil
- Dibutuhkan
- target
- tugas
- tugas
- tim
- teknik
- uji
- Uji coba
- pengujian
- tes
- Klasifikasi Teks
- Grafik
- Sumber
- mereka
- pihak ketiga
- ribuan
- Melalui
- waktu
- kali
- untuk
- alat
- alat
- terima kasih
- jalur
- Pelacakan
- lalu lintas
- Pelatihan VE
- Transaksi
- Perjalanan
- benar
- tutorial
- jenis
- Ubuntu
- ui
- bawah
- memahami
- pemahaman
- satuan
- URL
- us
- menggunakan
- Pengguna
- Penggunaan
- dimanfaatkan
- memanfaatkan
- Memanfaatkan
- variasi
- memeriksa
- melalui
- maya
- Apa
- apakah
- yang
- sementara
- akan
- dalam
- Kerja
- pekerja
- pekerja
- akan
- penulisan
- Anda
- zephyrnet.dll