Posting ini ditulis bersama Babu Srinivasan dan Robert Walters dari MongoDB.
Amazon Managed Streaming untuk Apache Kafka (Amazon MSK) adalah layanan Apache Kafka yang dikelola sepenuhnya dan sangat tersedia. Amazon MSK mempermudah penyerapan dan pemrosesan data streaming secara waktu nyata dan menggunakan data tersebut dengan mudah dalam ekosistem AWS. Dengan Amazon MSK Tanpa Server, Anda dapat secara otomatis menyediakan dan mengelola sumber daya yang diperlukan untuk menyediakan kapasitas dan penyimpanan streaming sesuai permintaan untuk aplikasi Anda.
Amazon MSK juga mendukung integrasi sumber data seperti MongoDB Atlas via Amazon MSK Terhubung. MSK Connect memungkinkan integrasi data MongoDB tanpa server dengan Amazon MSK menggunakan Konektor MongoDB untuk Apache Kafka.
MongoDB Atlas Tanpa Server menyediakan layanan database yang secara dinamis menaikkan dan menurunkan skala dengan ukuran dan throughput data—dan skala biaya yang sesuai. Paling cocok untuk aplikasi dengan permintaan variabel untuk dikelola dengan konfigurasi minimal. Ini memberikan kinerja dan keandalan tinggi dengan pemutakhiran otomatis, enkripsi, keamanan, metrik, dan fitur cadangan yang dibangun dengan infrastruktur MongoDB Atlas.
MSK Tanpa Server adalah jenis klaster untuk Amazon MSK. Sama seperti MongoDB Atlas Tanpa Server, MSK Tanpa Server secara otomatis menyediakan dan menskalakan komputasi dan sumber daya penyimpanan. Anda sekarang dapat membuat alur kerja tanpa server end-to-end. Anda dapat membuat pipeline streaming tanpa server dengan penyerapan tanpa server menggunakan MSK Serverless dan penyimpanan tanpa server menggunakan MongoDB Atlas. Selain itu, MSK Connect sekarang mendukung nama host DNS pribadi. Ini memungkinkan instance MSK Tanpa Server untuk terhubung ke klaster MongoDB Tanpa Server melalui Tautan Pribadi AWS, memberi Anda konektivitas aman antar platform.
Jika Anda tertarik untuk menggunakan klaster non-server, lihat Mengintegrasikan MongoDB dengan Amazon Managed Streaming untuk Apache Kafka (MSK).
Posting ini menunjukkan cara mengimplementasikan pipeline streaming tanpa server dengan MSK Serverless, MSK Connect, dan MongoDB Atlas.
Ikhtisar solusi
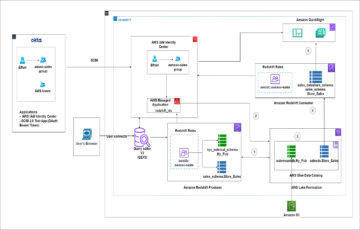
Diagram berikut menggambarkan arsitektur solusi kami.
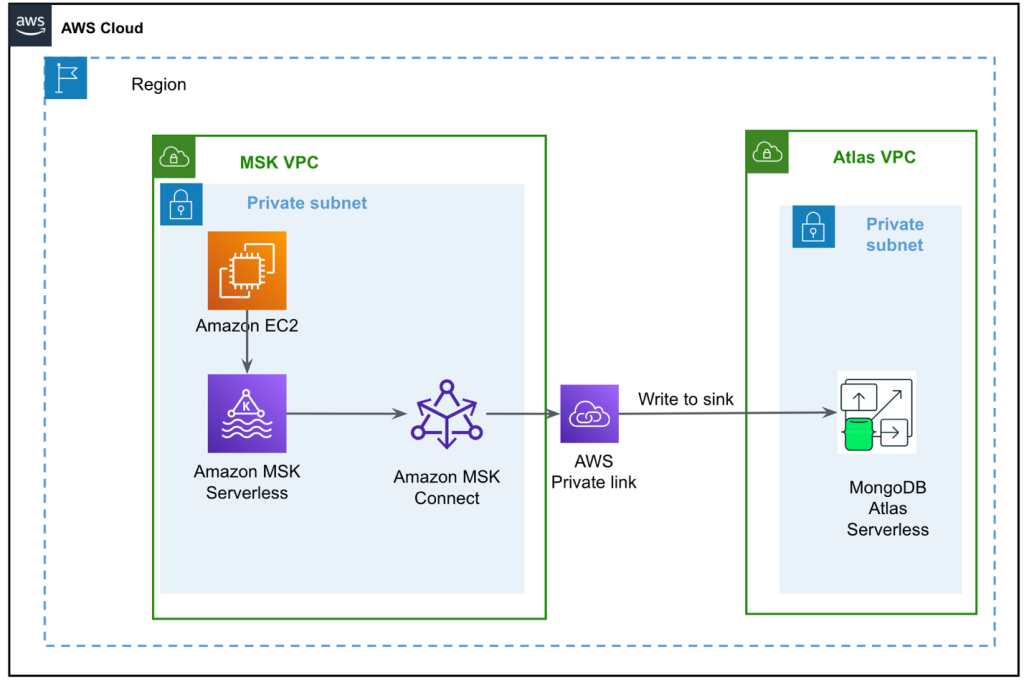
Aliran data dimulai dengan Cloud komputasi elastis Amazon Instance klien (Amazon EC2) yang menulis rekaman ke topik MSK. Saat data tiba, sebuah instance MongoDB Connector untuk Apache Kafka menulis data ke koleksi di klaster MongoDB Atlas Serverless. Untuk konektivitas yang aman antara kedua platform, koneksi AWS PrivateLink dibuat antara klaster MongoDB Atlas dan VPC yang berisi instance MSK.
Posting ini menuntun Anda melalui langkah-langkah berikut:
- Buat cluster MSK tanpa server.
- Buat klaster Tanpa Server MongoDB Atlas.
- Konfigurasi plugin MSK.
- Buat klien EC2.
- Konfigurasikan topik MSK.
- Konfigurasikan Konektor MongoDB untuk Apache Kafka sebagai wastafel.
Konfigurasikan cluster MSK tanpa server
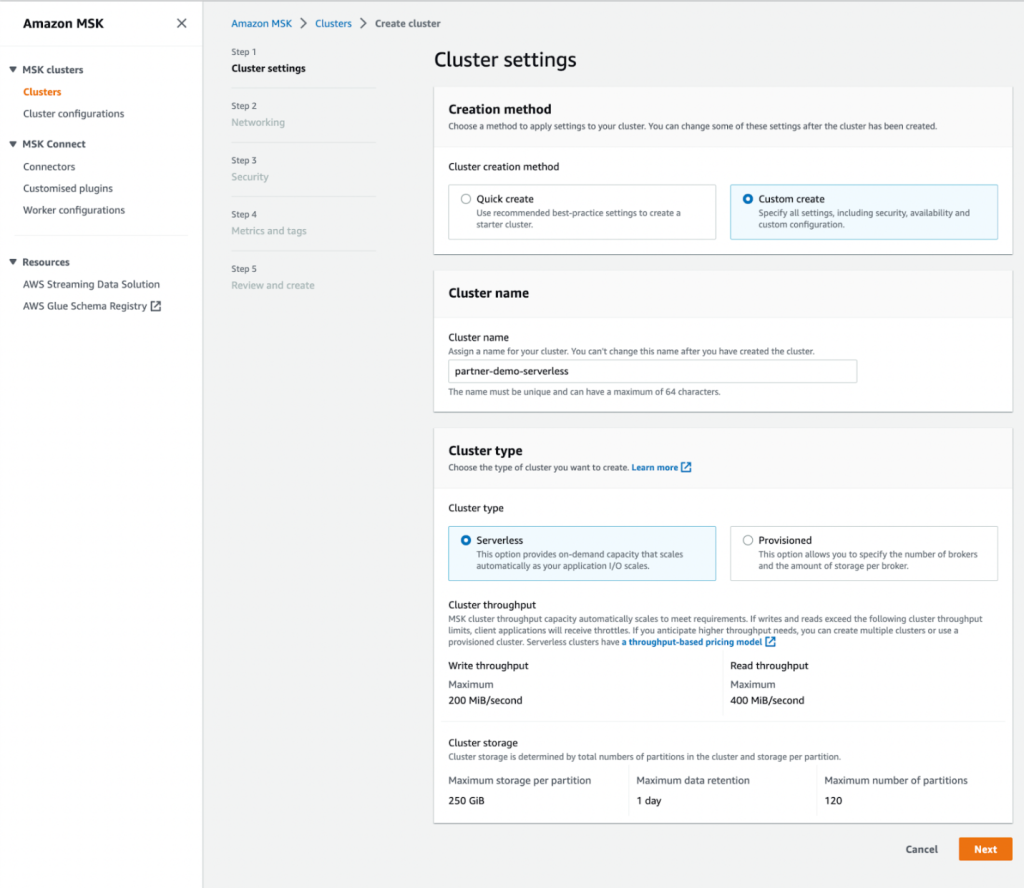
Untuk membuat cluster MSK tanpa server, selesaikan langkah-langkah berikut:
- Di konsol Amazon MSK, pilih Cluster di panel navigasi.
- Pilih Buat klaster.
- Untuk Metode pembuatan, pilih Buat kustom.
- Untuk Nama klaster, Masuk
MongoDBMSKCluster. - Untuk Tipe klusterPilih Tanpa Server.
- Pilih Selanjutnya.
- pada jaringan halaman, tentukan VPC Anda, Availability Zones, dan subnet yang sesuai.
- Catat Availability Zone dan subnet untuk digunakan nanti.
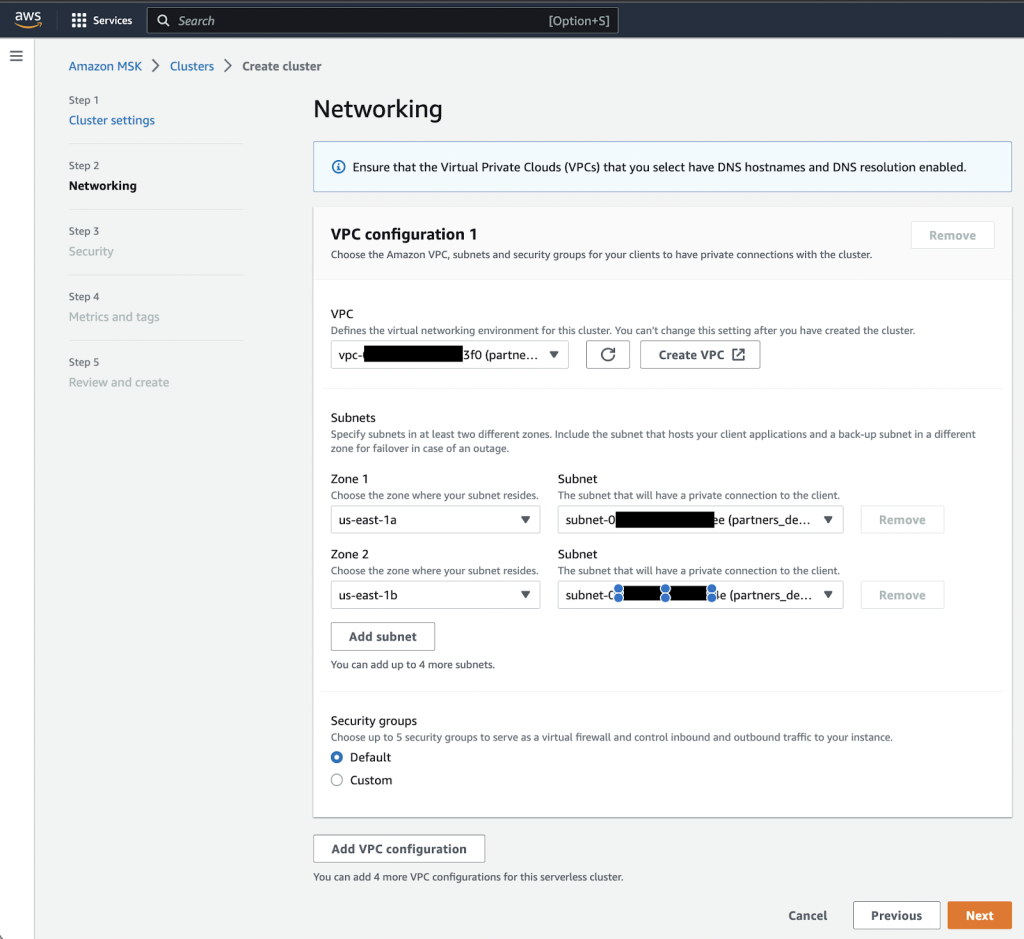
- Pilih Selanjutnya.
- Pilih Buat klaster.
Saat cluster tersedia, statusnya menjadi Active.

Buat klaster Tanpa Server MongoDB Atlas
Untuk membuat klaster MongoDB Atlas, ikuti Memulai dengan Atlas tutorial. Perhatikan bahwa untuk keperluan posting ini, Anda perlu membuat instance tanpa server.
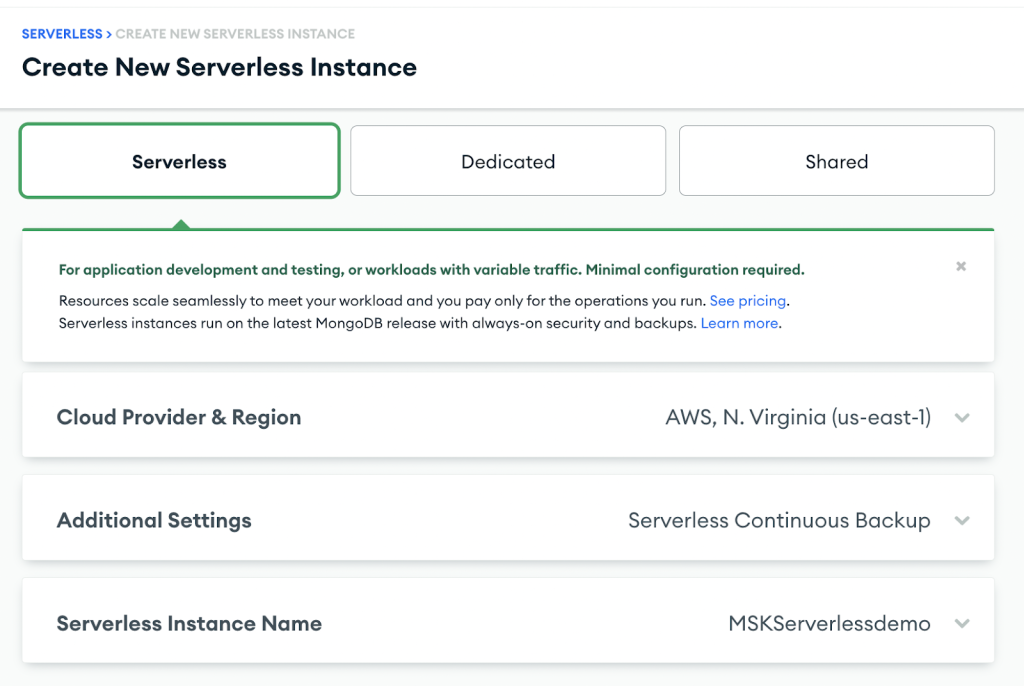
Setelah klaster dibuat, konfigurasikan titik akhir pribadi AWS dengan langkah-langkah berikut:
- pada Security menu, pilih Akses jaringan.

- pada Titik Akhir Pribadi tab, pilih Mesin Virtual Tanpa Server.

- Pilih Buat titik akhir baru.
- Untuk Mesin Virtual Tanpa Server, pilih instance yang baru saja Anda buat.
- Pilih Memastikan.
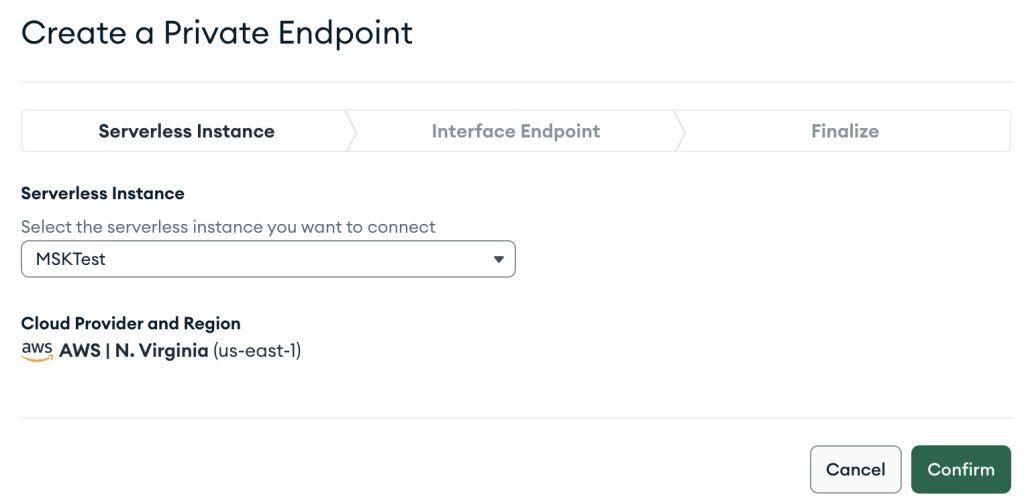
- Berikan konfigurasi titik akhir VPC Anda dan pilih Selanjutnya.
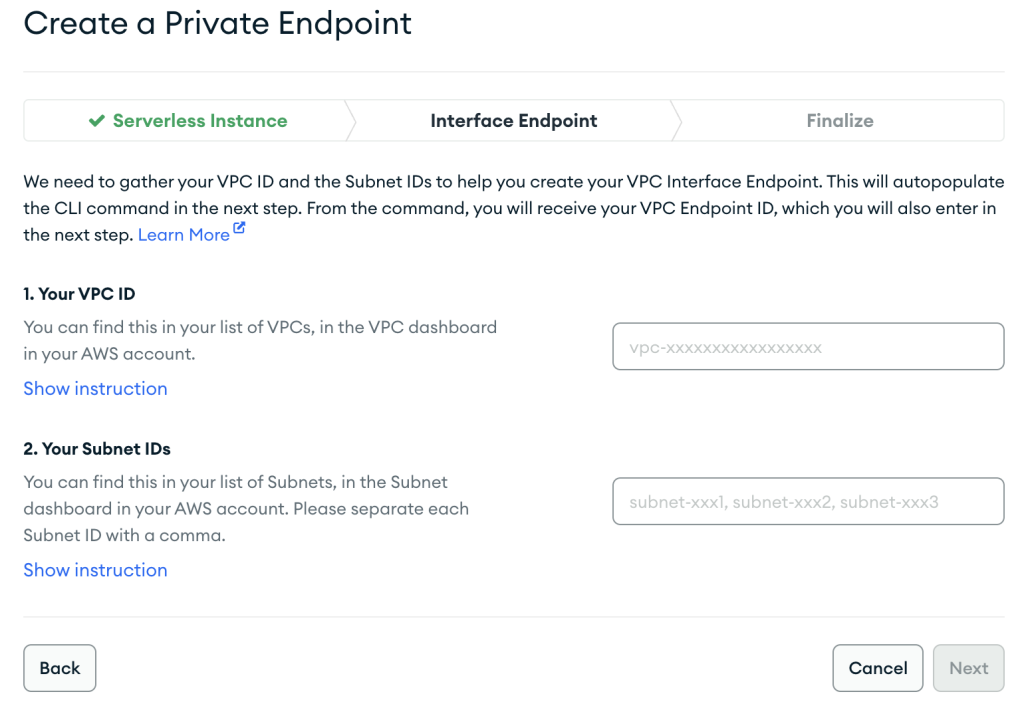
- Saat membuat sumber daya AWS PrivateLink, pastikan Anda menentukan VPC dan subnet yang sama persis dengan yang Anda gunakan sebelumnya saat membuat konfigurasi jaringan untuk instans MSK tanpa server.
- Pilih Selanjutnya.
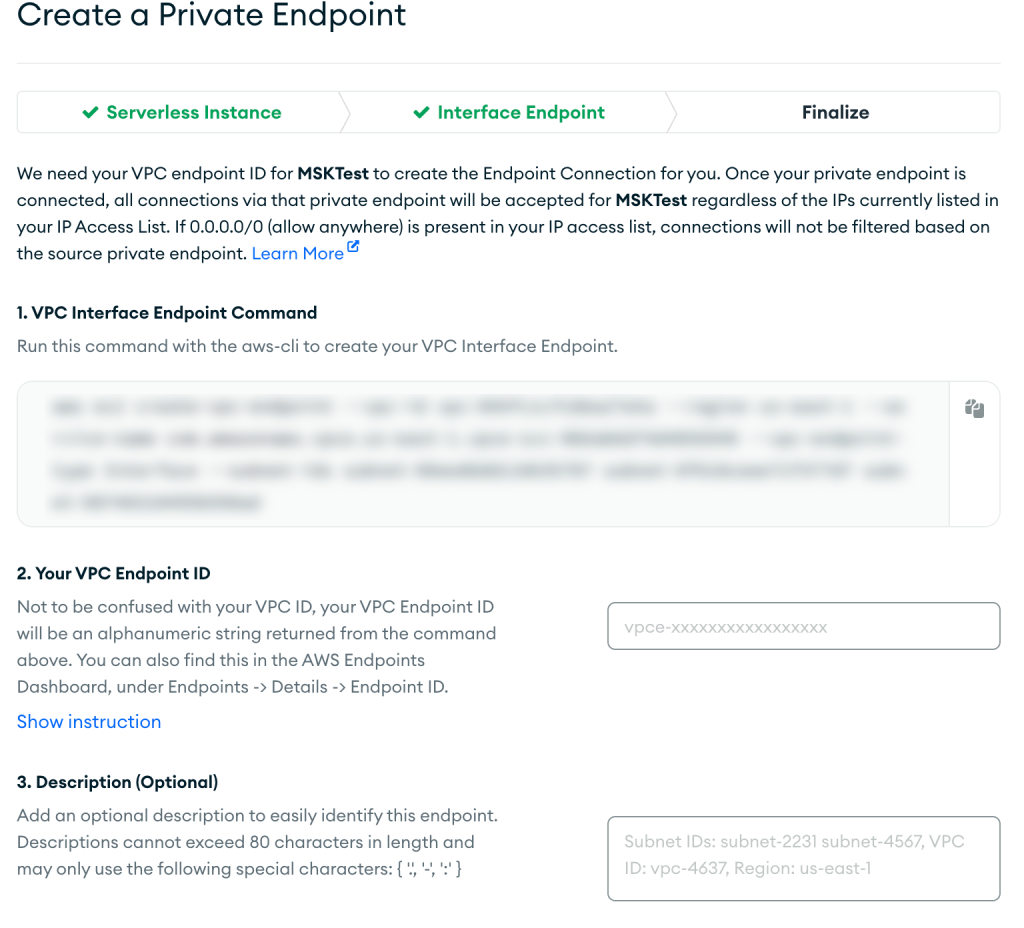
- Ikuti petunjuk di Menyelesaikan halaman, lalu pilih Memastikan setelah titik akhir VPC Anda dibuat.
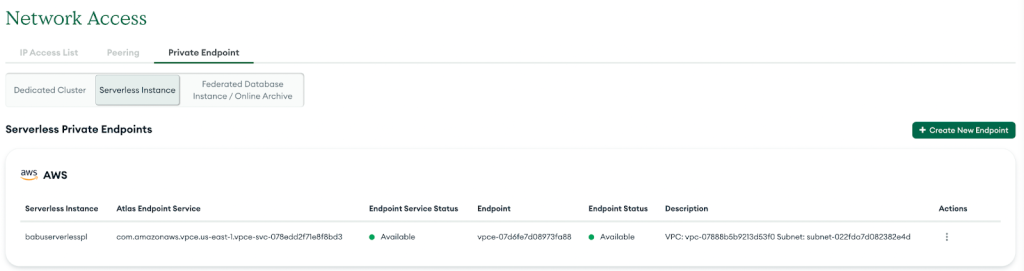
Setelah berhasil, endpoint pribadi baru akan muncul dalam daftar, seperti yang ditunjukkan pada tangkapan layar berikut.
Konfigurasikan Plugin MSK
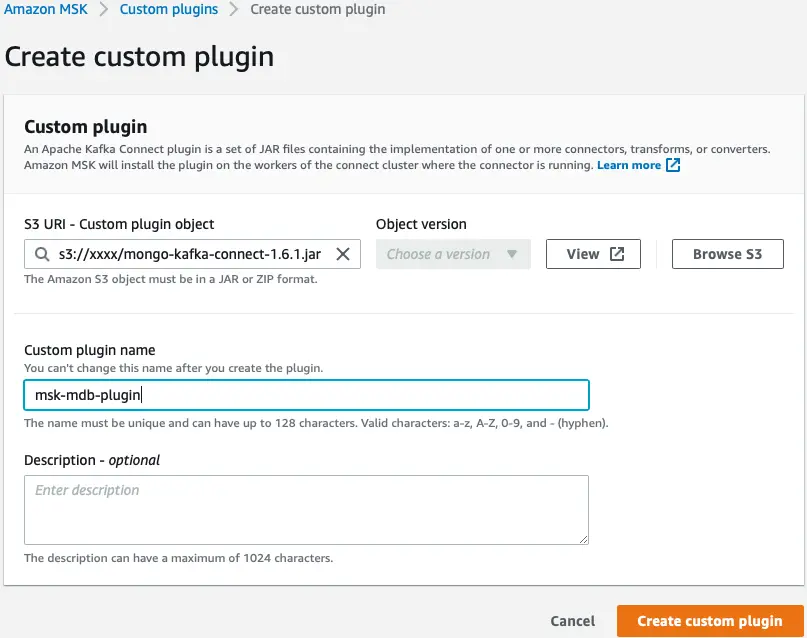
Selanjutnya, kami membuat plugin khusus di Amazon MSK menggunakan MongoDB Connector untuk Apache Kafka. Konektor perlu diunggah ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) sebelum Anda dapat membuat plugin. Untuk mengunduh Konektor MongoDB untuk Apache Kafka, lihat Unduh File JAR Konektor.
- Di konsol Amazon MSK, pilih Plugin yang disesuaikan di panel navigasi.
- Pilih Buat plugin khusus.
- Untuk URI S3, masukkan lokasi S3 dari konektor yang diunduh.
- Pilih Buat plugin khusus.
Konfigurasi klien EC2
Selanjutnya, mari konfigurasikan instans EC2. Kami menggunakan instance ini untuk membuat topik dan memasukkan data ke dalam topik. Untuk instruksi, lihat bagian Konfigurasi klien EC2 di pos Mengintegrasikan MongoDB dengan Amazon Managed Streaming untuk Apache Kafka (MSK).
Buat topik di cluster MSK
Untuk membuat topik Kafka, kita perlu menginstal Kafka CLI terlebih dahulu.
- Pada instans EC2 klien, instal Java terlebih dahulu:
sudo yum install java-1.8.0
- Selanjutnya, jalankan perintah berikut untuk mengunduh Apache Kafka:
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Buka paket file tar menggunakan perintah berikut:
tar -xzf kafka_2.12-2.6.2.tgz
Distribusi Kafka menyertakan folder bin dengan alat yang dapat digunakan untuk mengelola topik.
- Pergi ke
kafka_2.12-2.6.2direktori dan keluarkan perintah berikut untuk membuat topik Kafka di cluster MSK tanpa server:
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
Anda dapat menyalin titik akhir server bootstrap di Lihat Informasi Klien halaman untuk cluster MSK tanpa server Anda.
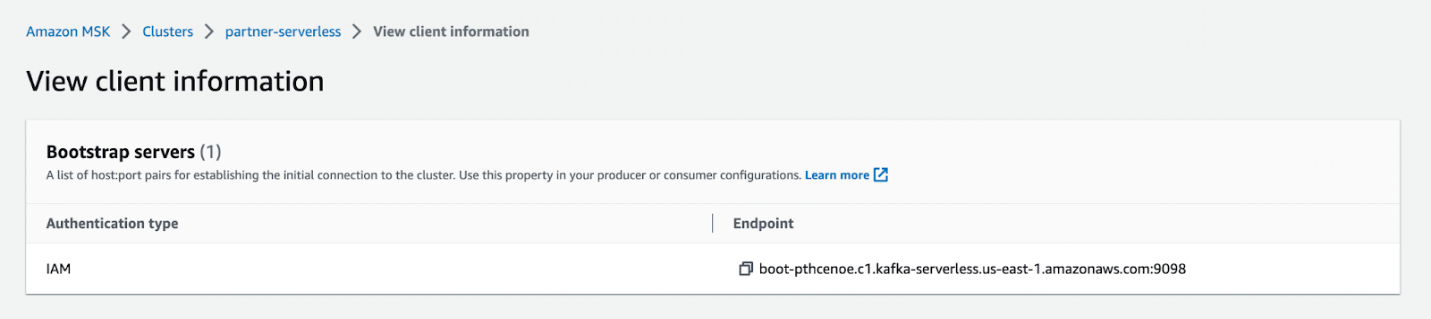
Anda dapat mengonfigurasi autentikasi IAM dengan mengikuti ini instruksi.
Konfigurasikan konektor wastafel
Sekarang, mari konfigurasikan sink connector untuk mengirim data ke instance MongoDB Atlas Serverless.
- Di konsol Amazon MSK, pilih konektor di panel navigasi.
- Pilih Buat konektor.
- Pilih plugin yang Anda buat tadi.
- Pilih Selanjutnya.
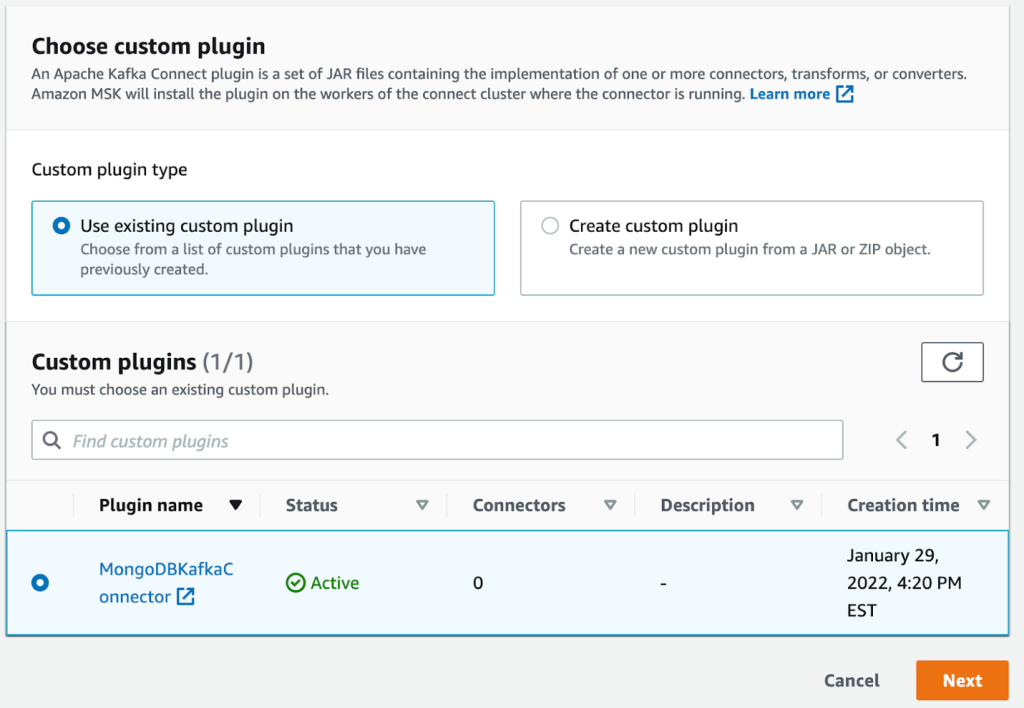
- Pilih instance MSK tanpa server yang Anda buat sebelumnya.
- Masukkan konfigurasi koneksi Anda sebagai kode berikut:
Pastikan koneksi ke instans MongoDB Atlas Tanpa Server melalui AWS PrivateLink. Untuk informasi lebih lanjut, lihat Menghubungkan Aplikasi dengan Aman ke Pesawat Data MongoDB Atlas dengan AWS PrivateLink.
- Dalam majalah Izin Akses bagian, membuat Identitas AWS dan Manajemen Akses (IAM) peran dengan diperlukan kebijakan kepercayaan.
- Pilih Selanjutnya.
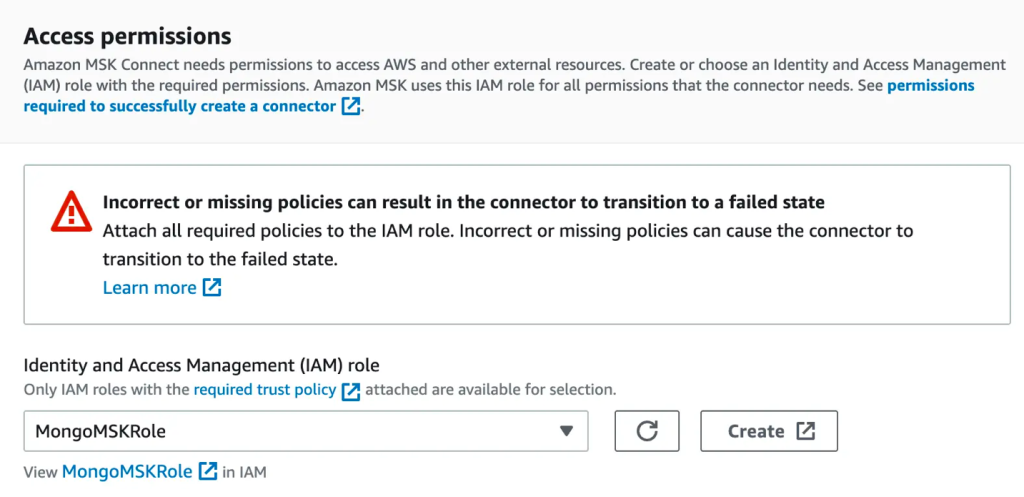
- Menentukan Log Amazon CloudWatch sebagai opsi pengiriman log Anda.
- Lengkapi konektor Anda.
Saat status konektor berubah menjadi Aktif, pipeline sudah siap.

Masukkan data ke dalam topik MSK
Pada klien EC2 Anda, masukkan data ke dalam topik MSK menggunakan kafka-console-producer sebagai berikut:
Untuk memverifikasi bahwa data berhasil mengalir dari topik Kafka ke klaster MongoDB tanpa server, kami menggunakan MongoDB Atlas UI.

Jika Anda mengalami masalah, pastikan untuk memeriksa file log. Dalam contoh ini, kami menggunakan CloudWatch untuk membaca kejadian yang dihasilkan dari Amazon MSK dan Konektor MongoDB untuk Apache Kafka.

Membersihkan
Untuk menghindari timbulnya biaya di masa mendatang, bersihkan sumber daya yang Anda buat. Pertama, hapus cluster MSK, konektor, dan instans EC2:
- Di konsol Amazon MSK, pilih Cluster di panel navigasi.
- Pilih klaster Anda dan pada tindakan menu, pilih Delete.
- Pilih konektor di panel navigasi.
- Pilih konektor Anda dan pilih Delete.
- Pilih Plugin yang disesuaikan di panel navigasi.
- Pilih plugin Anda dan pilih Delete.
- Di konsol Amazon EC2, pilih Contoh di panel navigasi.
- Pilih instance yang Anda buat.
- Pilih Keadaan contoh, Lalu pilih Hentikan instance.
- pada VPC Amazon konsol, pilih Titik akhir di panel navigasi.
- Pilih titik akhir yang Anda buat dan pada tindakan menu, pilih Hapus titik akhir VPC.
Sekarang Anda dapat menghapus klaster Atlas dan AWS PrivateLink:
- Masuk ke konsol cluster Atlas.
- Arahkan ke cluster tanpa server yang akan dihapus.
- Pada menu tarik-turun opsi, pilih Mengakhiri.
- Arahkan ke folder Akses jaringan bagian.
- Pilih titik akhir pribadi.
- Pilih instance tanpa server.
- Pada menu tarik-turun opsi, pilih Mengakhiri.

Kesimpulan
Dalam postingan ini, kami menunjukkan kepada Anda cara membuat pipeline penyerapan streaming tanpa server menggunakan MSK Tanpa Server dan MongoDB Atlas Tanpa Server. Dengan MSK Tanpa Server, Anda dapat secara otomatis menyediakan dan mengelola sumber daya yang diperlukan sesuai kebutuhan. Kami menggunakan konektor MongoDB yang diterapkan di MSK Connect untuk mengintegrasikan kedua layanan secara mulus, dan menggunakan klien EC2 untuk mengirim data sampel ke topik MSK. MSK Connect sekarang mendukung Nama host DNS pribadi, memungkinkan Anda menggunakan nama domain pribadi di antara layanan. Dalam posting ini, konektor menggunakan server DNS default VPC untuk menyelesaikan nama DNS pribadi khusus Availability Zone. Konfigurasi AWS PrivateLink ini memungkinkan konektivitas yang aman dan pribadi antara instans Tanpa Server MSK dan instans Tanpa Server MongoDB Atlas.
Untuk melanjutkan pembelajaran Anda, lihat referensi berikut:
Tentang Penulis

Igor Alekseev adalah Arsitek Solusi Mitra Senior di AWS dalam domain Data dan Analitik. Dalam perannya, Igor bekerja dengan mitra strategis membantu mereka membangun arsitektur yang kompleks dan dioptimalkan untuk AWS. Sebelum bergabung dengan AWS, sebagai Arsitek Data/Solusi, dia mengimplementasikan banyak proyek di domain Big Data, termasuk beberapa data lake di ekosistem Hadoop. Sebagai Insinyur Data, dia terlibat dalam penerapan AI/ML untuk deteksi penipuan dan otomatisasi kantor.
 Kirana Matty adalah Manajer Produk Utama dengan Amazon Web Services (AWS) dan bekerja dengan tim Amazon Managed Streaming for Apache Kafka (Amazon MSK) yang berbasis di Palo Alto, California. Dia bersemangat membangun layanan streaming dan analitik berkinerja tinggi yang membantu perusahaan mewujudkan kasus penggunaan kritis mereka.
Kirana Matty adalah Manajer Produk Utama dengan Amazon Web Services (AWS) dan bekerja dengan tim Amazon Managed Streaming for Apache Kafka (Amazon MSK) yang berbasis di Palo Alto, California. Dia bersemangat membangun layanan streaming dan analitik berkinerja tinggi yang membantu perusahaan mewujudkan kasus penggunaan kritis mereka.
 Babu Srinivasan adalah Arsitek Solusi Mitra Senior di MongoDB. Dalam perannya saat ini, dia bekerja dengan AWS untuk membangun integrasi teknis dan arsitektur referensi untuk solusi AWS dan MongoDB. Dia memiliki lebih dari dua dekade pengalaman dalam teknologi Database dan Cloud. Dia bersemangat memberikan solusi teknis kepada pelanggan yang bekerja dengan beberapa Global System Integrators (GSIs) di berbagai wilayah geografis.
Babu Srinivasan adalah Arsitek Solusi Mitra Senior di MongoDB. Dalam perannya saat ini, dia bekerja dengan AWS untuk membangun integrasi teknis dan arsitektur referensi untuk solusi AWS dan MongoDB. Dia memiliki lebih dari dua dekade pengalaman dalam teknologi Database dan Cloud. Dia bersemangat memberikan solusi teknis kepada pelanggan yang bekerja dengan beberapa Global System Integrators (GSIs) di berbagai wilayah geografis.
 Robert Walters saat ini adalah Manajer Produk Senior di MongoDB. Sebelum MongoDB, Rob menghabiskan 17 tahun di Microsoft bekerja di berbagai peran, termasuk manajemen program di tim SQL Server, konsultasi, dan pra-penjualan teknis. Rob telah ikut menulis tiga paten untuk teknologi yang digunakan dalam SQL Server dan merupakan penulis utama beberapa buku teknis tentang SQL Server. Rob saat ini adalah blogger aktif di Blog MongoDB.
Robert Walters saat ini adalah Manajer Produk Senior di MongoDB. Sebelum MongoDB, Rob menghabiskan 17 tahun di Microsoft bekerja di berbagai peran, termasuk manajemen program di tim SQL Server, konsultasi, dan pra-penjualan teknis. Rob telah ikut menulis tiga paten untuk teknologi yang digunakan dalam SQL Server dan merupakan penulis utama beberapa buku teknis tentang SQL Server. Rob saat ini adalah blogger aktif di Blog MongoDB.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/
- 10
- 100
- 7
- a
- Tentang Kami
- mengakses
- demikian
- di seluruh
- aktif
- tambahan
- Setelah
- AI / ML
- memungkinkan
- Amazon
- Amazon EC2
- Amazon Web Services
- Layanan Web Amazon (AWS)
- Analytical
- analisis
- dan
- Apache
- Apache Kafka
- aplikasi
- Menerapkan
- arsitektur
- Tiba
- atlas
- Otentikasi
- penulis
- Otomatis
- secara otomatis
- Otomatisasi
- tersedianya
- tersedia
- AWS
- backup
- berdasarkan
- dasar
- menjadi
- sebelum
- TERBAIK
- antara
- Besar
- Big data
- blog
- Buku-buku
- Bootstrap
- membangun
- Bangunan
- dibangun di
- california
- Kapasitas
- kasus
- Perubahan
- beban
- memeriksa
- Pilih
- klien
- awan
- Kelompok
- kode
- koleksi
- koleksi
- lengkap
- kompleks
- menghitung
- konfigurasi
- Terhubung
- koneksi
- Konektivitas
- konsul
- konsultasi
- terus
- Sesuai
- Biaya
- membuat
- dibuat
- membuat
- penciptaan
- kritis
- terbaru
- Sekarang
- adat
- pelanggan
- data
- insinyur data
- Basis Data
- dekade
- Default
- pengiriman
- tuntutan
- dikerahkan
- rincian
- Deteksi
- dialog
- distribusi
- dns
- domain
- NAMA DOMAIN
- turun
- Download
- Terdahulu
- mudah
- ekosistem
- memungkinkan
- enkripsi
- ujung ke ujung
- Titik akhir
- insinyur
- Enter
- perusahaan
- Eter (ETH)
- peristiwa
- contoh
- pengalaman
- Fitur
- File
- File
- Pertama
- aliran
- Mengalir
- mengikuti
- berikut
- berikut
- penipuan
- deteksi penipuan
- dari
- sepenuhnya
- masa depan
- dihasilkan
- geografi
- Aksi
- Hadoop
- membantu
- membantu
- di sini
- High
- sangat
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- IAM
- identitas
- melaksanakan
- diimplementasikan
- in
- termasuk
- Termasuk
- informasi
- Infrastruktur
- install
- contoh
- instruksi
- mengintegrasikan
- integrasi
- integrasi
- tertarik
- terlibat
- isu
- masalah
- IT
- Jawa
- bergabung
- kafka
- kunci
- memimpin
- pengetahuan
- Daftar
- tempat
- membuat
- MEMBUAT
- mengelola
- berhasil
- pengelolaan
- manajer
- banyak
- menu
- Metrik
- Microsoft
- minimal
- MongoDB
- lebih
- beberapa
- nama
- nama
- Navigasi
- Perlu
- kebutuhan
- jaringan
- Akses jaringan
- jaringan
- New
- Office
- pilihan
- Opsi
- Palo Alto
- pane
- pasangan
- rekan
- bergairah
- Paten
- prestasi
- pipa saluran
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Plugin
- Pos
- sebelumnya
- Utama
- Sebelumnya
- swasta
- proses
- Produk
- manajer produk
- program
- memprojeksikan
- properties
- memberikan
- menyediakan
- menyediakan
- ketentuan
- tujuan
- Baca
- siap
- nyata
- real-time
- menyadari
- arsip
- keandalan
- wajib
- sumber
- Sumber
- ROBERT
- Peran
- peran
- Run
- sama
- Skala
- sisik
- mulus
- Bagian
- aman
- aman
- keamanan
- senior
- Tanpa Server
- layanan
- Layanan
- pengaturan
- beberapa
- Menunjukkan
- ditunjukkan
- Sederhana
- Ukuran
- larutan
- Solusi
- sumber
- sumber
- menghabiskan
- SQL
- mulai
- dimulai
- Status
- Tangga
- penyimpanan
- Strategis
- mitra strategis
- Streaming
- subnet
- subnet
- sukses
- berhasil
- seperti itu
- Mendukung
- sistem
- tugas
- tim
- Teknis
- Teknologi
- Grafik
- mereka
- tiga
- Melalui
- waktu
- untuk
- alat
- tema
- Topik
- Kepercayaan
- tutorial
- ui
- meningkatkan
- upload
- menggunakan
- nilai
- berbagai
- memeriksa
- melalui
- jaringan
- layanan web
- akan
- dalam
- Alur kerja
- kerja
- bekerja
- tahun
- Anda
- zephyrnet.dll
- zona