Pengantar
Dalam proyek ini, kami akan fokus pada data dari India. Dan tujuan kami adalah membuat model prediktif sehingga ketika kami memberikan karakteristik seorang kandidat, model tersebut dapat memprediksi apakah mereka akan merekrut.
Grafik kumpulan data berkisar pada musim penempatan Sekolah Bisnis di India. Kumpulan data tersebut memiliki berbagai faktor tentang kandidat, seperti pengalaman kerja, persentase ujian, dll. Terakhir, berisi rincian status rekrutmen dan remunerasi.
Rekrutmen kampus adalah strategi untuk mencari, melibatkan, dan mempekerjakan talenta muda untuk magang dan posisi tingkat awal. Ini sering melibatkan bekerja dengan pusat layanan karir universitas dan menghadiri pameran karir untuk bertemu langsung dengan mahasiswa dan lulusan baru.

Pada artikel ini, kita akan mengimpor kumpulan data tersebut, membersihkannya, lalu menyiapkannya untuk membangun model Regresi Logistik.
Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Daftar Isi
Tujuan Membangun Model Regresi Logistik
Tujuan kami di sini adalah sebagai berikut:
Pertama, Kita akan menyiapkan kumpulan data untuk klasifikasi biner. Sekarang, apa maksudku? Saat kita mencoba memprediksi nilai berkelanjutan, seperti harga apartemen, nilainya bisa berkisar antara nol hingga jutaan dolar. Kami menyebutnya masalah regresi.
Namun dalam proyek ini, segalanya sedikit berbeda. Daripada memprediksi nilai yang berkelanjutan, kami memiliki kelompok atau kelas terpisah yang kami coba prediksi di antara mereka. Jadi ini disebut masalah Klasifikasi, dan karena dalam proyek kita, kita hanya akan memiliki dua kelompok yang kita coba pilih, sehingga menjadikannya klasifikasi biner.
Tujuan kedua adalah membuat model regresi logistik untuk memprediksi perekrutan. Dan tujuan ketiga kami adalah menjelaskan prediksi model kami menggunakan rasio odds.
Sekarang mengenai alur kerja pembelajaran mesin, langkah-langkah yang akan kita ikuti, dan beberapa hal baru, yang akan kita pelajari selama prosesnya. Jadi pada tahap impor, kami akan menyiapkan data kami untuk bekerja dengan target biner. Pada tahap eksplorasi, kita akan melihat keseimbangan kelas. Jadi pada dasarnya, berapa proporsi kandidat yang menduduki peringkat ketiga, dan berapa proporsi yang tidak? Dan pada tahap pengkodean fitur, kami akan melakukan pengkodean pada fitur kategorikal kami. Pada bagian split, kita akan melakukan split train test secara acak.
Untuk Modelnya:
Fase pembuatan, pertama, kita akan menetapkan garis dasar, dan karena kita akan menggunakan skor akurasi, kita akan membahas lebih lanjut tentang apa itu skor akurasi dan cara membuat garis dasar jika itu adalah metrik yang kita minati. Kedua, kita akan melakukan regresi logistik. Dan yang terakhir, kita akan melakukan tahap evaluasi. Kami akan kembali fokus pada skor akurasi. Terakhir, untuk mengkomunikasikan hasilnya, kita akan melihat rasio odds.
Terakhir, Sebelum mendalami pekerjaan ini, mari perkenalkan diri kita ke perpustakaan yang akan kita gunakan untuk proyek tersebut. Pertama, kita akan mengimpor data kita ke notebook Google Colab ke perpustakaan io. Kemudian, karena kita akan menggunakan model regresi logistik, kita akan mengimpornya dari scikit-learn. Setelah itu, juga dari scikit-learn, kami akan mengimpor metrik kinerja, skor akurasi, dan pemisahan uji-latihan.
Kami akan menggunakan Matplotlib dan Seaborn untuk visualisasi kami, dan JumlahPy akan hanya untuk sedikit matematika. Kita butuh Panda untuk memanipulasi data kami, LabelEncoder untuk mengkodekan variabel kategori kami, dan StandardScaler untuk menormalkan data. Itu akan menjadi perpustakaan yang kita butuhkan. Mari kita langsung menyiapkan datanya.
#import libraries
import io
import warnings import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler warnings.simplefilter(action="ignore", category=FutureWarning)Siapkan Data untuk Model Regresi Logistik
impor
Untuk mulai mempersiapkan datanya, mari kita lakukan pekerjaan penting kita. Pertama, kita memuat file data kita, lalu kita perlu memasukkannya ke dalam `df` DataFrame.
Kode Python:
Kita dapat melihat DataFrame kita yang indah, dan kita memiliki 215 catatan dan 15 kolom yang menyertakan atribut `status`, target kita. Ini adalah deskripsi untuk semua fitur.

Jelajahi
Sekarang kami memiliki semua fitur yang akan kami jelajahi. Jadi mari kita mulai analisis data eksplorasi kita. Pertama, mari kita lihat informasi untuk kerangka data ini dan lihat apakah ada yang perlu kita pertahankan atau perlu dibuang.
# Inspect DataFrame
df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 215 entries, 0 to 214
Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sl_no 215 non-null int64 1 gender 215 non-null object 2 ssc_p 215 non-null float64 3 ssc_b 215 non-null object 4 hsc_p 215 non-null float64 5 hsc_b 215 non-null object 6 hsc_s 215 non-null object 7 degree_p 215 non-null float64 8 degree_t 215 non-null object 9 workex 215 non-null object 10 etest_p 215 non-null float64 11 specialisation 215 non-null object 12 mba_p 215 non-null float64 13 status 215 non-null object 14 salary 148 non-null float64
dtypes: float64(6), int64(1), object(8)
memory usage: 25.3+ KBSekarang ketika kami melihat info `df`, ada beberapa hal yang kami cari, kami memiliki 215 baris dalam kerangka data kami, dan pertanyaan yang ingin kami tanyakan pada diri kami sendiri adalah, apakah ada data yang hilang? Dan kalau kita lihat di sini, sepertinya tidak ada data yang hilang kecuali kolom gaji, seperti yang diharapkan, karena kandidat yang belum dipekerjakan.
Kekhawatiran lain bagi kami di sini adalah, apakah ada fitur bocor yang akan memberikan informasi ke model kami yang tidak akan ada jika diterapkan di dunia nyata? Ingatlah bahwa kami ingin model kami memprediksi apakah kandidat akan ditempatkan atau tidak, dan kami ingin model kami membuat prediksi tersebut sebelum perekrutan terjadi. Jadi kami tidak ingin memberikan informasi apa pun tentang kandidat ini setelah perekrutan.
Jadi, jelas sekali bahwa fitur `gaji` ini memberikan informasi mengenai gaji yang ditawarkan perusahaan. Dan karena gaji ini untuk mereka yang diterima, fitur ini di sini merupakan kebocoran, dan kita harus menghilangkannya.
df.drop(columns="salary", inplace=True)Hal kedua yang ingin saya lihat adalah tipe data untuk fitur-fitur berbeda ini. Jadi, dengan melihat tipe data ini, kami memiliki delapan fitur kategorikal dengan target kami dan tujuh fitur numerik, dan semuanya benar. Jadi, setelah kita mempunyai ide-ide ini, mari luangkan waktu untuk mengeksplorasinya lebih dalam.
Kami tahu bahwa target kami memiliki dua kelas. Kami telah menempatkan kandidat dan tidak menempatkan kandidat. Pertanyaannya, berapakah proporsi relatif kedua kelas tersebut? Apakah keseimbangannya sama? Atau apakah yang satu lebih banyak dari yang lain? Itu adalah sesuatu yang perlu Anda perhatikan ketika Anda mengerjakan soal klasifikasi. Jadi ini adalah langkah penting bagi kami DAN DARI.
# Plot class balance
df["status"].value_counts(normalize=True).plot( kind="bar", xlabel="Class", ylabel="Relative Frequency", title="Class Balance"
);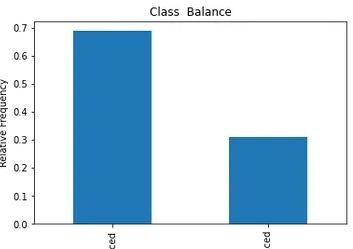
Kelas positif kami `ditempatkan` terhitung lebih dari 65% pengamatan kami, dan kelas negatif kami `Tidak Ditempatkan` berjumlah sekitar 30%. Sekarang, jika ini sangat tidak seimbang, misalnya, jika lebih dari 80 atau bahkan lebih dari itu, menurut saya ini adalah kelas yang tidak seimbang. Dan kami harus melakukan beberapa pekerjaan untuk memastikan model kami berfungsi dengan benar. Tapi ini adalah keseimbangan yang oke.
Ayo buat yang lain visualisasi untuk memperhatikan hubungan antara fitur kami dan target. Mari kita mulai dengan fitur numerik.
Pertama, kita akan melihat distribusi individual dari fitur menggunakan plot distribusi, dan kita juga akan melihat hubungan antara fitur numerik dan target kita dengan menggunakan plot kotak.
fig,ax=plt.subplots(5,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("number").drop(columns="sl_no")): plt.suptitle("Visualizing Distribution of Numerical Columns Indivualy and by Class",size=20) sns.histplot(data=df, x=i, kde=True, ax=ax[index,0]) sns.boxplot(data=df, x='status', y=i, ax=ax[index,1]);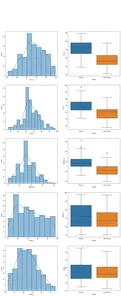
Di kolom pertama dari plot kami, kami dapat melihat bahwa semua distribusi mengikuti distribusi normal, dan sebagian besar kinerja pendidikan kandidat berkisar antara 60-80%.
Pada kolom kedua, kita mempunyai plot kotak ganda dengan kelas `Ditempatkan` di sebelah kanan dan kemudian kelas `Tidak Ditempatkan` di sebelah kiri. Untuk fitur `etest_p` dan `mba_p`, tidak banyak perbedaan pada kedua distribusi ini dari perspektif pembuatan model. Terdapat tumpang tindih yang signifikan dalam distribusi berdasarkan kelas, sehingga fitur-fitur ini tidak dapat menjadi prediktor yang baik untuk target kami. Adapun fitur-fitur lainnya, cukup berbeda untuk menjadikannya sebagai prediktor potensial yang baik untuk target kami. Mari beralih ke fitur kategorikal. Dan untuk menjelajahinya, kita akan menggunakan plot hitungan.
fig,ax=plt.subplots(7,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("object").drop(columns="status")): plt.suptitle("Visualizing Count of Categorical Columns",size=20) sns.countplot(data=df,x=i,ax=ax[index,0]) sns.countplot(data=df,x=i,ax=ax[index,1],hue="status")
Melihat alur ceritanya, kita melihat bahwa kita memiliki lebih banyak kandidat laki-laki dibandingkan perempuan. Dan sebagian besar kandidat kami tidak memiliki pengalaman kerja, namun kandidat ini mendapat pekerjaan lebih banyak daripada kandidat yang memiliki pengalaman kerja. Kami memiliki kandidat yang mengambil jurusan perdagangan sebagai mata kuliah `hsc` mereka, dan selain lulusan sarjana, kandidat dengan latar belakang sains adalah yang tertinggi kedua dalam kedua kasus tersebut.
Sedikit catatan tentang model regresi logistik, walaupun untuk klasifikasi, namun satu kelompok dengan model linier lainnya seperti regresi linier, dan oleh karena itu, karena keduanya merupakan model linier. Kita juga perlu mengkhawatirkan masalah multikolinearitas. Jadi kita perlu membuat matriks korelasi, dan kemudian kita perlu memplotnya dalam peta panas.
Kami tidak ingin melihat semua fitur di sini, kami hanya ingin melihat fitur numerik, dan kami tidak ingin memasukkan target kami. Karena kalau target kita berkorelasi dengan beberapa fitur kita, itu bagus sekali.
corr = df.select_dtypes("number").corr()
# Plot heatmap of `correlation`
plt.title('Correlation Matrix')
sns.heatmap(corr, vmax=1, square=True, annot=True, cmap='GnBu');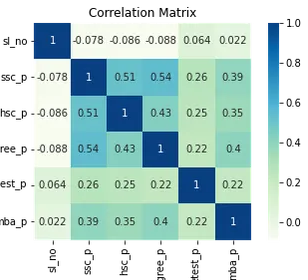
Berikut adalah warna biru muda, yang berarti sedikit atau tidak ada korelasi, dan biru tua, yang memiliki korelasi lebih tinggi. Jadi kami ingin mewaspadai warna biru tua itu. Kita bisa melihat garis biru tua, garis diagonal di tengah plot ini. Itulah ciri-ciri yang berkorelasi dengan dirinya sendiri. Dan kemudian, kita melihat beberapa kotak gelap. Itu berarti kami memiliki banyak korelasi antar fitur.
Pada langkah terakhir EDA kami, kami perlu memeriksa kardinalitas tinggi-rendah dalam fitur kategorikal. Kardinalitas mengacu pada jumlah nilai unik dalam variabel kategorikal. Kardinalitas tinggi berarti bahwa fitur kategorikal memiliki sejumlah besar nilai unik. Tidak ada jumlah pasti dari nilai unik yang membuat sebuah fitur berkardinalitas tinggi. Tetapi jika nilai fitur kategori unik untuk hampir semua pengamatan, biasanya dapat dihilangkan.
# Check for high- and low-cardinality categorical features
df.select_dtypes("object").nunique() gender 2
ssc_b 2
hsc_b 2
hsc_s 3
degree_t 3
workex 2
specialisation 2
status 2
dtype: int64Saya tidak melihat kolom apa pun yang jumlah nilai uniknya satu atau berapa pun sangat tinggi. Tapi menurut saya ada satu kolom tipe kategorikal yang kami lewatkan di sini. Dan alasannya adalah bahwa hal itu tidak dikodekan sebagai objek tetapi sebagai bilangan bulat.
Kolom `sl_no` bukanlah bilangan bulat seperti yang kita ketahui. Kandidat-kandidat ini diberi peringkat dalam urutan tertentu. Cuma name tag unik dan namanya seperti kategori kan? Jadi ini adalah variabel kategorikal. Dan tidak ada informasi apa pun di dalamnya, jadi kita harus membuangnya.
df.drop(columns="sl_no", inplace=True)Fitur Pengkodean
Kami menyelesaikan analisis kami, dan hal berikutnya yang perlu kami lakukan adalah mengkodekan fitur kategorikal kami, saya akan menggunakan `LabelEncoder`. Pengkodean Label adalah teknik pengkodean populer untuk menangani variabel kategori. Dengan menggunakan teknik ini, setiap label diberi bilangan bulat unik berdasarkan urutan abjad.
lb = LabelEncoder () cat_data = ['gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation', 'status']
for i in cat_data: df[i] = lb.fit_transform(df[i]) df.head()
Split
Kami mengimpor dan membersihkan data kami. Kami telah melakukan sedikit analisis data eksplorasi, dan sekarang kita perlu membagi data kita. Kami memiliki dua jenis pemisahan: pemisahan vertikal atau set target fitur dan pemisahan horizontal atau set pengujian kereta.
Mari kita mulai dengan yang vertikal. Kami akan Membuat matriks fitur kami `X` dan vektor target `y`. target kami adalah “status”. Fitur kita harus berupa semua kolom yang tersisa di `df`.
#vertical split
target = "status"
X = df.drop(columns = target)
y = df[target]Model umumnya berperforma lebih baik jika memiliki data yang dinormalisasi untuk dilatih, lalu apa yang dimaksud dengan normalisasi? Normalisasi adalah mengubah nilai beberapa variabel ke dalam rentang yang serupa. Target kami adalah menormalkan variabel kami. Jadi rentang nilainya adalah dari 0 hingga 1. Mari kita lakukan itu, dan saya akan menggunakan `StandardScaler.`
scaler = StandardScaler()
X = scaler.fit_transform(X)Sekarang mari kita lakukan set split horizontal atau train-test. Kita perlu membagi data kita (X dan y) menjadi set pelatihan dan pengujian menggunakan pemisahan uji-latihan secara acak. set pengujian kami harus 20% dari total data kami. Dan kami tidak lupa menyetel random_state agar dapat direproduksi.
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state = 42 ) print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape) X_train shape: (172, 12)
y_train shape: (172,)
X_test shape: (43, 12)
y_test shape: (43,)Bangun Model Regresi Logistik
Dasar
Jadi sekarang kita perlu mulai membangun model regresi logistik, dan kita harus mulai menyusun untuk menetapkan garis dasar kita. Ingatlah bahwa jenis masalah yang kita hadapi adalah masalah klasifikasi, dan terdapat metrik berbeda untuk mengevaluasi model klasifikasi. Yang ingin saya fokuskan adalah skor akurasi.
Sekarang, berapa skor akurasinya? Skor akurasi dalam pembelajaran mesin adalah metrik evaluasi yang mengukur jumlah prediksi benar yang dibuat oleh suatu model terhadap jumlah total prediksi yang dibuat. Kita menghitungnya dengan membagi jumlah prediksi yang benar dengan jumlah total prediksi. Artinya, skor akurasinya berkisar antara 0 dan 1. Nol itu tidak bagus. Di situlah Anda tidak ingin berada, dan yang satu itu sempurna.
Jadi, mari kita ingat dan ingat bahwa baseline adalah model yang memberikan satu prediksi berulang kali, terlepas dari apa observasinya, hanya satu tebakan untuk kita.
Dalam kasus kami, kami memiliki dua kelas, ditempatkan atau tidak. Jadi jika kita hanya bisa membuat satu prediksi, tebakan apa yang akan kita buat? Kalau dibilang kelas mayoritas. Menurutku itu masuk akal, bukan? Jika kita hanya dapat memiliki satu prediksi, kita mungkin harus memilih prediksi dengan observasi tertinggi dalam kumpulan data kita.
Jadi, baseline kami akan menggunakan persentase kelas mayoritas yang muncul di data pelatihan. Jika model tidak mengalahkan garis dasar ini, fitur-fitur tersebut tidak menambahkan informasi berharga untuk mengklasifikasikan observasi kami.
Kita dapat menggunakan metode `value_counts` dengan argumen `normalize = True` untuk menghitung akurasi dasar:
acc_baseline = y_train.value_counts(normalize=True).max()
print("Baseline Accuracy:", round(acc_baseline, 2)) Baseline Accuracy: 0.68Kita dapat melihat bahwa akurasi dasar kita adalah 68% atau 0.68 sebagai proporsinya. Jadi untuk menambah nilai agar bisa berguna, kami ingin melampaui angka itu dan mendekati angka tersebut. Itulah tujuan kami, dan sekarang mari mulai membangun model kami.
Pengulangan
Sekarang saatnya membangun model kita. Kita akan menggunakan regresi logistik, tapi sebelum kita melakukannya, mari kita bahas sedikit tentang apa itu regresi logistik dan cara kerjanya, lalu kita bisa melakukan hal-hal pengkodean. Dan untuk itu, di sini kita memiliki grid kecil.
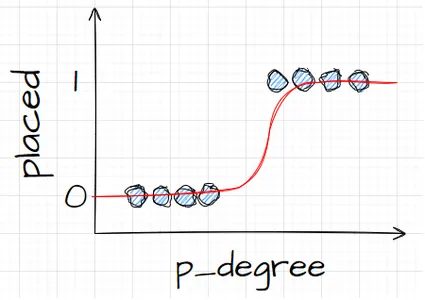
Sepanjang sumbu x, katakanlah saya memiliki p_degrees kandidat dalam kumpulan data kita. Dan saat saya bergerak dari kanan ke kiri, derajatnya semakin tinggi, dan kemudian sepanjang sumbu Y, saya memiliki kelas penempatan yang mungkin: nol dan satu.
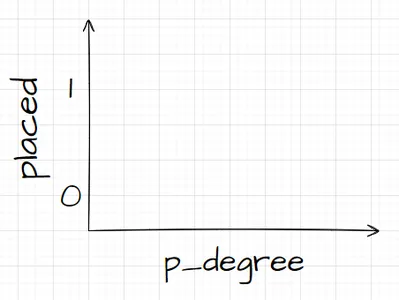
Jadi jika kita memplot titik data kita, akan terlihat seperti apa? Kami mengetahui dari analisis kami bahwa kandidat dengan `p_degree` tinggi kemungkinan besar akan diterima. Jadi, mungkin akan terlihat seperti ini, dimana kandidat dengan `p_degree` kecil akan turun ke nol. Dan kandidat dengan `p_degree` tinggi akan mendapat nilai satu.

Sekarang katakanlah kita ingin melakukan regresi linier dengan ini. Katakanlah kita ingin membuat garis. Sekarang, jika kita melakukan itu, apa yang akan terjadi adalah garis tersebut akan diplot sedemikian rupa sehingga berusaha sedekat mungkin dengan semua titik. Jadi kita mungkin akan mendapatkan garis yang terlihat seperti ini. Apakah ini model yang bagus?
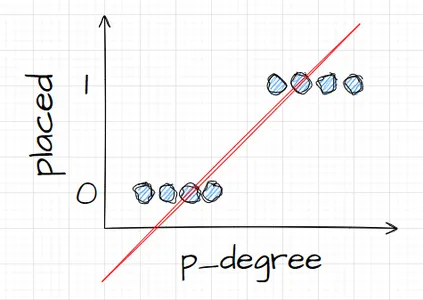
Tidak terlalu. Apa yang akan terjadi adalah terlepas dari p_degree kandidatnya, kita akan selalu mendapatkan semacam nilai. Dan itu tidak akan membantu kita karena angka-angka tersebut, dalam konteks ini, tidak berarti apa-apa. Masalah klasifikasi ini harus nol atau satu. Jadi, cara seperti itu tidak akan berhasil.
Di sisi lain, karena ini adalah sebuah garis, bagaimana jika kita memiliki kandidat dengan p_degree yang sangat rendah? Tiba-tiba perkiraan kami menjadi angka negatif. Dan sekali lagi, ini tidak masuk akal. Tidak ada bilangan negatif yang harus nol atau satu. Dan dengan cara yang sama, jika kita mempunyai kandidat dengan tingkat p yang sangat tinggi, saya mungkin akan mendapatkan hasil positif, sesuatu di atas satu. Dan sekali lagi, itu tidak masuk akal. Kita harus mempunyai angka nol atau satu.
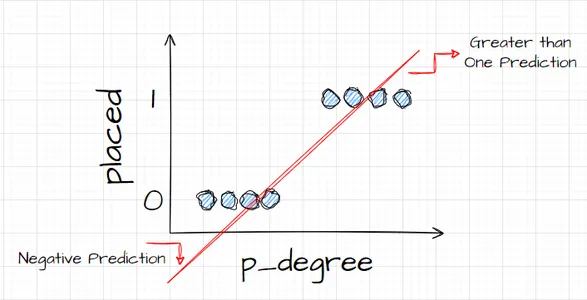
Jadi apa yang kita lihat di sini adalah beberapa keterbatasan serius dalam menggunakan regresi linier untuk klasifikasi. Jadi apa yang perlu kita lakukan? Kita perlu membuat model yang nomor satu: tidak berada di bawah nol atau di atas satu, sehingga perlu terikat antara nol dan satu. Dan yang kedua, apa pun hasil dari fungsi tersebut, persamaan yang kita buat, kita mungkin tidak boleh menganggapnya sebagai prediksi semata, melainkan sebagai langkah menuju pembuatan prediksi akhir.
Sekarang, izinkan saya menguraikan apa yang baru saja saya katakan, dan mari kita ingatkan diri kita sendiri bahwa ketika kita melakukan model regresi linier, kita akan mendapatkan persamaan linier ini, yang merupakan bentuk paling sederhana. Dan persamaan atau fungsi inilah yang memberi kita garis lurus itu.

Ada cara untuk mengikat garis antara 0 dan 1. Dan yang bisa kita lakukan adalah mengambil fungsi yang baru saja kita buat dan memasukkannya ke dalam fungsi lain, yang disebut a fungsi sigmoid.

Jadi, saya akan mengambil persamaan linier yang baru saja kita miliki, dan saya akan mengecilkannya ke dalam fungsi sigmoid dan meletakkannya sebagai eksponensial.
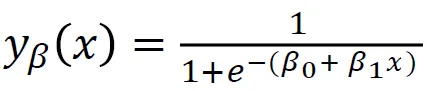
Yang terjadi bukannya mendapatkan garis lurus, kita malah mendapatkan garis yang terlihat seperti ini. Itu terjebak pada satu. Ia masuk dan mencoret-coret ke bawah. Kemudian terjebak di titik nol.
Baiklah, seperti itulah garisnya, dan kita dapat melihat bahwa kita telah memecahkan masalah pertama kita. Apapun yang kita keluarkan dari fungsi ini akan berada di antara 0 dan 1. Pada langkah kedua, kita tidak akan menganggap apapun yang keluar dari persamaan ini sebagai prediksi akhir. Sebaliknya, kami akan memperlakukannya sebagai suatu kemungkinan.
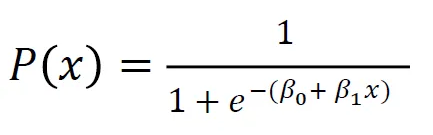
Apa yang saya maksud? Artinya ketika saya membuat prediksi, saya akan mendapatkan nilai floating point antara 0 dan 1. Dan yang akan saya lakukan adalah memperlakukannya sebagai probabilitas bahwa prediksi saya termasuk dalam kelas positif.
Jadi saya mendapat nilai naik 0.9999. Saya akan mengatakan kemungkinan bahwa kandidat ini termasuk dalam kelas kita yang positif dan ditempatkan adalah 99%. Jadi saya hampir yakin itu termasuk kelas positif. Sebaliknya kalau turun di titik 0.001 atau berapa pun, saya katakan angka ini rendah. Kemungkinan bahwa pengamatan khusus ini termasuk dalam kelas positif yang ditempatkan hampir nol. Jadi, menurutku itu termasuk kelas nol.
Jadi masuk akal untuk angka yang mendekati satu atau mendekati nol. Namun Anda mungkin bertanya pada diri sendiri, apa yang harus saya lakukan dengan nilai-nilai lain di antaranya? Cara kerjanya adalah kita letakkan garis potongnya tepat di angka 0.5, jadi nilai berapa pun yang saya dapat di bawah garis itu, saya taruh di angka nol, jadi prediksi saya tidak, dan jika di atas garis itu, jika di atas titik lima, ini saya masukkan ke kelas positif, prediksi saya satu.
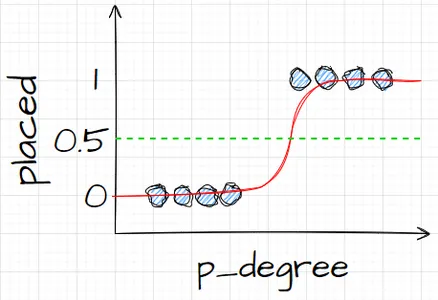
Jadi, sekarang saya memiliki fungsi yang memberi saya prediksi antara nol dan satu, dan saya memperlakukannya sebagai probabilitas. Dan kalau probabilitasnya di atas 0.5 atau 50%, saya bilang oke positif kelas satu. Dan kalau di bawah 50%, saya katakan, itu kelas negatif, nol. Jadi begitulah cara kerja regresi logistik. Dan sekarang kita memahaminya, mari kita kodekan dan sesuaikan. Saya akan mengatur hyperparameter 'max_iter' ke 1000. Parameter ini mengacu pada jumlah maksimum iterasi agar pemecah dapat berkumpul.
# Build model
model = LogisticRegression(max_iter=1000) # Fit model to training data
model.fit(X_train, y_train) LogisticRegression(max_iter=1000)Mengevaluasi
Sekarang saatnya melihat bagaimana kinerja model kita. Saatnya untuk mengevaluasi. Jadi, ingatlah bahwa kali ini, metrik kinerja yang kita minati adalah skor akurasi, dan kita menginginkan skor yang akurat. Dan kami ingin mengalahkan baseline 0.68. Akurasi model dapat dihitung menggunakan fungsi akurasi_score. Fungsi ini memerlukan dua argumen, label sebenarnya, dan label prediksi.
acc_train = accuracy_score(y_train, model.predict(X_train))
acc_test = model.score(X_test, y_test) print("Training Accuracy:", round(acc_train, 2))
print("Test Accuracy:", round(acc_test, 2)) Training Accuracy: 0.9
Test Accuracy: 0.88Kami bisa melihat akurasi latihan kami di angka 90%. Ini mengalahkan baseline. Akurasi pengujian kami sedikit lebih rendah yaitu 88%. Itu juga mengalahkan baseline dan sangat mendekati akurasi latihan kami. Jadi itu kabar baik karena itu berarti model kita tidak overfitting atau apa pun. Dan itu mungkin bisa digeneralisasikan dengan baik. Jadi itu kabar baik.
Hasil
Ingatlah bahwa dengan regresi logistik, kita mendapatkan prediksi akhir nol atau satu. Namun di bawah prediksi tersebut, terdapat kemungkinan angka floating point antara nol atau satu, dan terkadang akan berguna untuk melihat perkiraan probabilitas tersebut. Mari kita lihat prediksi latihan kita, dan mari kita lihat lima prediksi pertama. Metode `prediksi` memprediksi target observasi yang tidak berlabel.
model.predict(X_train)[:5] array([0, 1, 1, 1, 1])Jadi itulah prediksi terakhirnya, tapi apa kemungkinan di baliknya? Untuk mendapatkannya, kita perlu melakukan kode yang sedikit berbeda. Daripada menggunakan metode `predict` dengan model kita, saya akan menggunakan `predict_proba` dengan data pelatihan kita.
y_train_pred_proba = model.predict_proba(X_train)
print(y_train_pred_proba[:5]) [[0.92003219 0.07996781] [0.03202019 0.96797981] [0.00678421 0.99321579] [0.03889446 0.96110554] [0.00245525 0.99754475]]Kita bisa melihat semacam daftar bersarang dengan dua kolom berbeda di dalamnya. Kolom di sebelah kiri mewakili probabilitas bahwa seorang kandidat tidak ditempatkan atau kelas negatif kita `Tidak Ditempatkan.` Kolom lainnya mewakili kelas positif `Ditempatkan` atau probabilitas bahwa seorang kandidat ditempatkan.
Saya akan fokus pada kolom kedua. Jika kita melihat estimasi probabilitas pertama dengan benar, kita dapat melihat bahwa nilainya adalah 0.07. Jadi karena angkanya di bawah 50%, menurut model kami, prediksi saya adalah nol. Dan untuk prediksi berikut, kita dapat melihat bahwa semuanya berada di atas 0.5, dan itulah mengapa model kita pada akhirnya memperkirakan satu.
Sekarang kami ingin mengekstrak nama fitur dan pentingnya dan menempatkannya dalam satu seri. Dan karena kita perlu menampilkan kepentingan fitur sebagai rasio odds, kita perlu melakukan sedikit transformasi matematis dengan mengambil eksponensial kepentingan kita.
# Features names
features = ['gender', 'ssc_p', 'ssc_b', 'hsc_p', 'hsc_b', 'hsc_s', 'degree_p' ,'degree_t', 'workex', 'etest_p', 'specialisation', 'mba_p']
# Get importances
importances = model.coef_[0]
# Put importances into a Series
odds_ratios = pd.Series(np.exp(importances), index= features).sort_values()
# Review odds_ratios.head() mba_p 0.406590
degree_t 0.706021
specialisation 0.850301
hsc_b 0.876864
etest_p 0.877831
dtype: float64Sebelum membahas rasio peluang dan apa itu, mari kita buat grafik batang horizontal. Mari gunakan panda untuk membuat plot, dan ingat bahwa kita akan mencari lima koefisien terbesar. Dan kami tidak ingin menggunakan semua rasio peluang. Jadi kami ingin menggunakan ekornya.
# Horizontal bar chart, five largest coefficients
odds_ratios.tail().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("High Importance Features");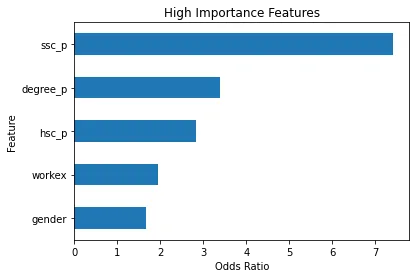
Sekarang saya ingin Anda membayangkan sebuah garis vertikal tepat di angka 5, dan saya ingin memulai dengan melihatnya. Mari kita bahas masing-masing secara individu atau hanya pada pasangan pertama. Jadi mari kita mulai di sini dengan `ssc_p`, yang mengacu pada `persentase Pendidikan Menengah – Kelas 10`. Dan kita dapat melihat bahwa odds rasionya berada di angka 30. Sekarang, apa maksudnya? Artinya, jika seorang kandidat memiliki `ssc_p` yang tinggi, peluangnya untuk ditempatkan enam kali lebih besar dibandingkan kandidat lainnya, dan semua hal dianggap sama. Jadi cara lain untuk memikirkannya adalah ketika kandidat memiliki `ssc_p` peluang rekrutmen kandidat meningkat enam kali lipat.
Jadi setiap rasio odds lebih dari lima meningkatkan peluang kandidat ditempatkan. Dan itulah mengapa kita memiliki garis vertikal di angka lima. Dan kelima macam fitur ini merupakan karakteristik yang paling terkait dengan peningkatan rekrutmen. Jadi, itulah rasio peluang kami. Sekarang, kita telah melihat fitur yang paling terkait dengan peningkatan perekrutan. Mari kita lihat fitur-fitur yang terkait dengannya, penurunan perekrutan. Jadi sekarang saatnya untuk melihat yang terkecil. Jadi daripada melihat ekornya, kita akan melihatnya.
odds_ratios.head().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("Low Importance Features");
Hal pertama yang perlu kita lihat di sini adalah pemberitahuan pada sumbu x semuanya satu atau lebih rendah. Sekarang, apa artinya itu? Jadi mari kita lihat rasio peluang terkecil kita di sini. Ini mba_p yang mengacu pada persentase MBA. Kita dapat melihat bahwa itu siap sekitar 0.45. Sekarang, apa artinya itu? Nah, selisih antara 0.45 dan 1 adalah 0.55. Baiklah? Dan apa arti angka itu? Kandidat dengan MBA cenderung tidak direkrut sebesar 55%, Semua hal lain dianggap sama. Baiklah? Jadi itu menurunkan peluang rekrutmen dengan faktor 0.55 atau 55%. Dan itu benar untuk semuanya di sini.
Kesimpulan
Jadi apa yang kita pelajari? Pertama, pada fase persiapan data, kita mempelajari bahwa kita sedang mengerjakan klasifikasi, khususnya klasifikasi biner. Dalam hal mengeksplorasi data, kami melakukan banyak hal, tetapi dalam hal sorotan, kami melihat keseimbangan kelas, bukan? Proporsi kelas positif dan negatif kita. Kemudian kami membagi data kami untuk model regresi logistik.
Karena ini adalah model klasifikasi, kami mempelajari metrik kinerja baru, yaitu skor akurasi. Sekarang, skor akurasinya berkisar antara 0 dan 1. Nol berarti buruk, dan satu berarti baik. Saat kami melakukan iterasi, kami belajar tentang regresi logistik. Itu cara yang ajaib, di mana Anda dapat mengambil persamaan linier, garis lurus, dan memasukkannya ke dalam fungsi lain, fungsi sigmoid, dan fungsi aktivasi, lalu mendapatkan estimasi probabilitas dari persamaan tersebut dan mengubah estimasi probabilitas tersebut menjadi prediksi.
Kemudian dengan evaluasi, kami melihat bahwa akurasi kami melebihi baseline. Jadi itu adalah kabar baik. Terakhir, ketika kita mempelajari tentang rasio peluang dan cara kita menafsirkan koefisien dalam model regresi logistik untuk melihat apakah fitur tertentu akan meningkatkan peluang kita merekrut kandidat atau menurunkan peluang tersebut.
Kode sumber proyek: https://github.com/SawsanYusuf/Campus-Recruitment.git
Media yang ditampilkan dalam artikel ini bukan milik Analytics Vidhya dan digunakan atas kebijaksanaan Penulis.
terkait
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2023/03/campus-recruitment-classification-with-logistic-regression/
- 1
- 10
- 11
- 214
- 7
- 9
- a
- Tentang Kami
- diterima
- ketepatan
- Activation
- Setelah
- Semua
- Meskipun
- analisis
- analisis
- Analisis Vidhya
- dan
- Lain
- Apartemen
- argumen
- argumen
- sekitar
- artikel
- terkait
- menghadiri
- Sumbu
- latar belakang
- Buruk
- Saldo
- bar
- Dasar
- Pada dasarnya
- indah
- karena
- sebelum
- di belakang
- makhluk
- di bawah
- Lebih baik
- antara
- Bit
- Biru
- Kotak
- membangun
- Bangunan
- menghitung
- dihitung
- Kampus
- calon
- calon
- Lowongan Kerja
- kasus
- kasus
- Kategori
- Pusat
- kesempatan
- karakteristik
- Grafik
- memeriksa
- Pilih
- kelas
- kelas-kelas
- klasifikasi
- Klasifikasi
- kode
- Pengkodean
- Perguruan tinggi
- Kolom
- Kolom
- Perdagangan
- menyampaikan
- Perhatian
- kesimpulan
- koneksi
- konteks
- bertemu
- Core
- Timeline
- Korelasi
- bisa
- sepasang
- Tentu saja
- membuat
- data
- analisis data
- titik data
- kumpulan data
- berurusan
- mengurangi
- dikerahkan
- deskripsi
- rincian
- MELAKUKAN
- perbedaan
- berbeda
- kebijaksanaan
- mendiskusikan
- Display
- berbeda
- distribusi
- distribusi
- melakukan
- dolar
- Dont
- dua kali lipat
- turun
- Menjatuhkan
- menjatuhkan
- setiap
- Pendidikan
- edukasi
- menarik
- cukup
- entry-level
- memperkirakan
- dll
- Eter (ETH)
- mengevaluasi
- evaluasi
- Bahkan
- segala sesuatu
- Kecuali
- diharapkan
- pengalaman
- Analisis Data Eksplorasi
- menyelidiki
- Menjelajahi
- eksponensial
- ekstrak
- Fitur
- Fitur
- perempuan
- File
- terakhir
- Akhirnya
- Pertama
- cocok
- Fokus
- mengikuti
- berikut
- bentuk
- rumus
- FRAME
- Frekuensi
- dari
- fungsi
- Gender
- umumnya
- mendapatkan
- pergi
- Memberikan
- tujuan
- Pergi
- akan
- baik
- lebih besar
- kisi
- Kelompok
- tangan
- Terjadi
- di sini
- High
- lebih tinggi
- paling tinggi
- highlight
- Mempekerjakan
- Horisontal
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTTPS
- ide-ide
- mengimpor
- pentingnya
- penting
- in
- memasukkan
- Meningkatkan
- Pada meningkat
- Meningkatkan
- indeks
- India
- sendiri-sendiri
- Secara individual
- Info
- informasi
- sebagai gantinya
- tertarik
- memperkenalkan
- Pengantar
- melibatkan
- isu
- IT
- Menjaga
- Jenis
- Tahu
- Label
- besar
- terbesar
- Terakhir
- BELAJAR
- belajar
- pengetahuan
- perpustakaan
- Perpustakaan
- Mungkin
- baris
- Daftar
- sedikit
- memuat
- melihat
- terlihat seperti
- tampak
- mencari
- Lot
- Rendah
- mesin
- Mesin belajar
- terbuat
- Mayoritas
- membuat
- MEMBUAT
- matematika
- matematis
- matplotlib.dll
- Matriks
- MBA
- cara
- ukuran
- Media
- Pelajari
- Memori
- metode
- metrik
- Metrik
- hilang
- model
- model
- lebih
- paling
- pindah
- nama
- nav
- Perlu
- negatif
- New
- berita
- normal
- buku catatan
- jumlah
- nomor
- mati rasa
- obyek
- tujuan
- Kesempatan
- Oke
- ONE
- urutan
- Lainnya
- dimiliki
- panda
- bagian
- persentase
- sempurna
- melakukan
- prestasi
- pertunjukan
- orang
- perspektif
- tahap
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- poin
- posisi
- positif
- mungkin
- potensi
- meramalkan
- diprediksi
- ramalan
- Prediksi
- Predictor
- Prediksi
- siap
- mempersiapkan
- probabilitas
- mungkin
- Masalah
- masalah
- proyek
- diterbitkan
- menempatkan
- pertanyaan
- Acak
- jarak
- perbandingan
- siap
- nyata
- dunia nyata
- alasan
- baru
- arsip
- perekrutan
- mengacu
- regresi
- hubungan
- tinggal
- ingat
- merupakan
- membutuhkan
- ISTIRAHAT
- Hasil
- ulasan
- Tersebut
- gaji
- sama
- mengatakan
- Ilmu
- scikit-belajar
- yg keturunan dr laut
- Kedua
- tampaknya
- rasa
- Seri
- Layanan
- set
- set
- tujuh
- beberapa
- Bentuknya
- harus
- ditunjukkan
- Pertunjukkan
- penting
- mirip
- sejak
- ENAM
- sedikit berbeda
- kecil
- terkecil
- So
- beberapa
- sesuatu
- sumber
- kode sumber
- Sourcing
- Secara khusus
- membagi
- kotak
- awal
- Status
- Langkah
- lurus
- Penyelarasan
- Siswa
- tiba-tiba
- besar
- tabel
- Mengambil
- pengambilan
- Bakat
- Berbicara
- target
- istilah
- uji
- Grafik
- mereka
- diri
- hal
- hal
- Berpikir
- waktu
- kali
- untuk
- ton
- Total
- Pelatihan VE
- Pelatihan
- Transformasi
- mengubah
- benar
- MENGHIDUPKAN
- jenis
- unik
- universitas
- us
- penggunaan
- menggunakan
- biasanya
- Berharga
- Informasi Berharga
- nilai
- Nilai - Nilai
- variabel
- visualisasi
- Apa
- Apa itu
- apakah
- yang
- SIAPA
- akan
- Kerja
- alur kerja
- kerja
- bekerja
- dunia
- akan
- akan memberi
- X
- muda
- diri
- zephyrnet.dll
- nol