Mencari solusi otomatisasi perusahaan? Tidak terlihat lagi!
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
var contentTitle = “Daftar Isi”; // Tetapkan judul Anda di sini, untuk menghindari membuat judul nanti var ToC = “
“+isiJudul+”
“; Daftar Isi += “
“; var tocDiv = document.getElementById('dynamictocnative'); tocDiv.outerHTML = ToC;
Apa itu Pencocokan Data?
Pencocokan data adalah proses menemukan entri identik dari satu atau lebih kumpulan data dan menyatukan catatan data. Ini dapat dilakukan di antara kumpulan data untuk memastikan bahwa data dari berbagai kumpulan data disinkronkan. Pencocokan memeriksa sejauh mana tumpang tindih di semua entri dalam satu kumpulan data dan mengembalikan probabilitas berbobot dari kecocokan untuk setiap pasangan catatan yang cocok. Setelah itu, Anda dapat memilih entri mana saja yang cocok dan mengambil tindakan pada data yang mendasarinya.
Ini dapat digunakan untuk menghilangkan konten duplikat atau untuk berbagai aplikasi penambangan data. Pencocokan data, umumnya, memungkinkan orang dengan volume data yang besar untuk melakukan penyelidikan yang lebih akurat yang menghasilkan hasil yang lebih akurat. Banyak upaya pencocokan data dilakukan untuk membangun hubungan penting antara dua kumpulan data besar untuk periklanan, keamanan, atau tujuan praktis lainnya.
Apa itu Klasifikasi Data?
Teknik mengklasifikasikan data ke dalam kelas-kelas yang sesuai sehingga dapat dimanfaatkan dan dijaga dengan lebih andal dikenal sebagai klasifikasi data. Teknik klasifikasi, pada tingkat yang paling dasar, membuat data lebih mudah ditemukan dan dipulihkan. Kapan pun menyangkut tata kelola strategi, regulasi, dan perlindungan data, klasifikasi data sangat penting.
Klasifikasi data memerlukan pengkategorian informasi agar lebih mudah diakses dan ditindaklanjuti. Ini juga menghapus banyak duplikasi data, yang dapat menghemat uang untuk penyimpanan dan pemulihan sekaligus mempercepat waktu pemrosesan. Namun proses kategorisasi mungkin tampak sangat kompleks, ini adalah masalah yang harus diketahui oleh setiap manajer yang efektif.
Apa saja jenis Klasifikasi Data?
Klasifikasi data seringkali memerlukan sejumlah besar kategori dan pengidentifikasi yang mencirikan jenis informasi, serta kerahasiaan dan keasliannya. Dalam proses klasifikasi data, ketidaktersediaan juga dapat diperhitungkan dalam persamaan. Kelezatan data sering diklasifikasikan berdasarkan beberapa tingkat kepentingan atau privasi, yang kemudian dikaitkan dengan langkah-langkah keamanan yang diterapkan untuk melindungi setiap tingkat klasifikasi.
Ada tiga bentuk klasifikasi data yang banyak digunakan:
Berbasis konten
Dokumen diperiksa dan ditafsirkan untuk data pribadi
Berbasis konteks
Program, lokal, atau pengembang, di antara banyak kriteria lainnya, digunakan sebagai penanda tidak langsung dari data pribadi
Berbasis pengguna
Identifikasi terminal pribadi dari setiap item diperlukan untuk ini. Kategorisasi ini berfokus pada keahlian dan penilaian pengguna selama pengembangan, perubahan, inspeksi, atau publikasi untuk menunjukkan file penting.
Berdasarkan kebutuhan industri dan jenis data, ketiga teknik dapat menjadi tepat dan tidak tepat.
Ingin mengikis data dari PDF dokumen, konversi PDF ke XML or mengotomatiskan ekstraksi tabel? Jelajahi Nanonet Pengikis PDF or Pengurai PDF untuk mengubah PDF ke database entri!
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
Contoh Klasifikasi Data
Berdasarkan tingkat risiko dari data tersebut,
Apa itu Matriks Klasifikasi Data?
Bisnis tertentu mungkin merasa mudah untuk membuat dan mengklasifikasikan data. Menilai kerentanan jaringan dan program biasanya jauh lebih mudah bila tidak ada terlalu banyak kategori data yang berbeda atau bahkan jika perusahaan memiliki interaksi yang terbatas. Namun, banyak bisnis dengan sejumlah besar data memaksa penilaian risiko penuh. Sebagian besar organisasi menggunakan "matriks klasifikasi data" untuk semua ini.
Menggunakan matriks untuk menilai data berdasarkan seberapa rentan ini harus rusak dan juga seberapa halus data tersebut akan memungkinkan Anda untuk dengan cepat memutuskan bagaimana dan di mana mengklasifikasikan dan melindungi semua informasi pribadi dengan benar.
Bagaimana cara kerja Pencocokan Data?
Menetapkan bahwa banyak "entitas", pada kenyataannya, "entitas" yang sama adalah tantangan yang coba diatasi oleh pencocokan data. Pencocokan data dapat dilakukan dengan berbagai cara. Metode ini sering didasarkan pada algoritma pencocokan data atau loop terprogram, di mana setiap item data diperiksa dan dibandingkan dengan setiap elemen dari kumpulan data lainnya. Beberapa algoritme digunakan untuk menjelajahi kumpulan data dan menemukan entri identik yang cocok.
Data dapat dikaitkan terutama dengan dua pendekatan. Rekam keterkaitan yang deterministik dan berdasarkan beberapa pengidentifikasi yang cocok. Penautan catatan probabilistik didasarkan pada kemungkinan beberapa pengidentifikasi yang cocok. Pencocokan data probabilistik adalah yang paling populer, karena penautan deterministik terlalu membatasi.
Pertama, data harus diatur, atau dibagi, menjadi blok-blok dengan ukuran dan atribut yang sama. Setelah ini, tempat beruang yang cocok. Nama, misalnya, dapat dicocokkan menurut abjad dan numerik.
Bobot relatif setiap properti kemudian ditentukan untuk mengevaluasi signifikansinya. Kemungkinan pencocokan kemudian harus dihitung. Terakhir, untuk menghitung Total Match Weight, algoritme menyesuaikan bobot relatif untuk setiap fitur. Hasilnya kemudian: kecocokan probabilitas untuk dua objek.
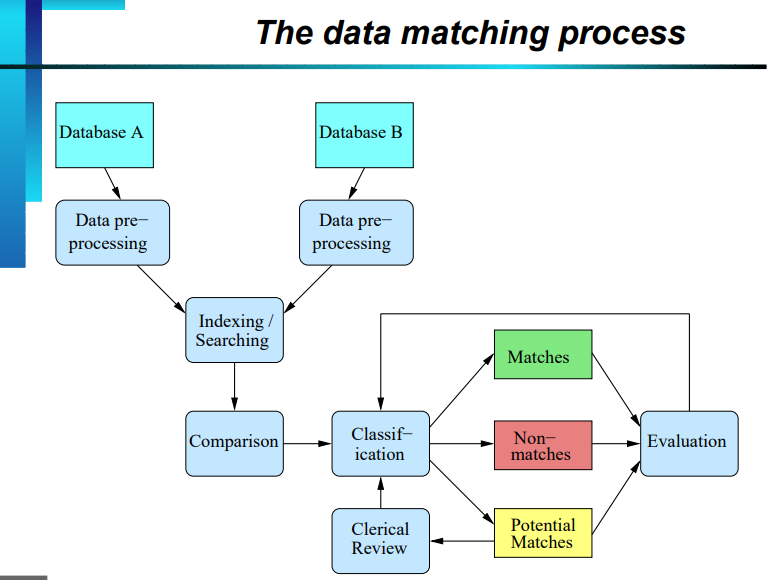
Sumber: Universitas Nasional Australia
Ingin mengotomatiskan tugas manual yang berulang? Periksa perangkat lunak pemrosesan dokumen berbasis alur kerja Nanonets kami. Ekstrak data dari faktur, kartu identitas, atau dokumen apa pun dengan autopilot!
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
Mengapa Pencocokan Data Penting?
Pencocokan data dapat membantu kami mengurangi detail yang identik. Ini diperlukan karena data yang berkualitas buruk, direplikasi, dan sumbang dapat menimbulkan berbagai komplikasi.
Biaya yang tidak perlu
Ini adalah urusan yang mahal bagi sebuah organisasi untuk mengirim beberapa katalog ke satu individu. Korporasi memproduksi lebih banyak file daripada yang diperlukan, dan ada biaya pengiriman yang harus dipertimbangkan, serta kemungkinan konsekuensi buruk apa pun; tidak ada tekanan seperti konsumen.
Berbagai sumber informasi pelanggan
Data harus tepat dan terperinci jika suatu organisasi ingin melakukan analisis data atau membuat prakiraan mengenai tren potensial. Tidak ada gambaran yang jelas tentang tindakan pelanggan jika data memiliki inkonsistensi.
Masalah Layanan Klien
Mempertahankan klien dan memberikan layanan yang sesuai menjadi lebih sulit ketika catatan pelanggan tersebar di banyak tempat. Mungkin tidak menyenangkan bagi pengguna untuk menerima gambaran menyeluruh tentang transaksi atau interaksi mereka jika ada beberapa transaksi untuk klien yang sama dalam berbagai format.
Opini Publik Buruk
Klien tidak suka dibombardir dengan konten, baik itu dalam bentuk email mingguan atau surat pos, terutama jika itu adalah kampanye yang sama dari waktu ke waktu. Melakukan panggilan dingin yang identik dengan orang yang sama tidak akan memberikan dampak positif pada klien.
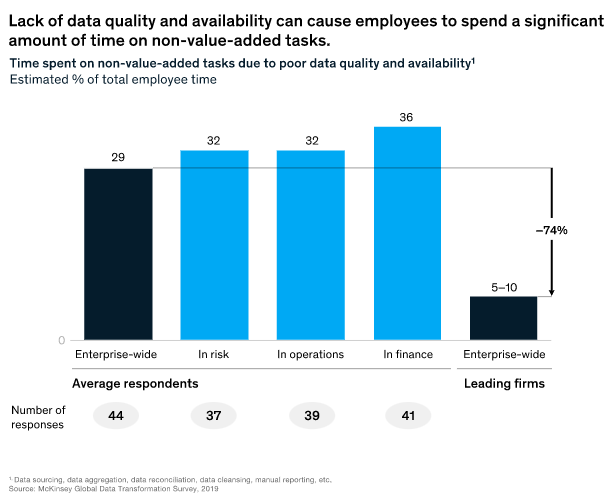
Sumber: McKinsey
Bagaimana Pencocokan Data dapat digunakan?
Perusahaan dapat lebih mudah menemukan entri duplikat menggunakan pencocokan data – juga dikenal sebagai hubungan catatan – dengan mengidentifikasi koneksi yang lebih andal. Pilih catatan master dan hapus yang serupa. Juga, lihat kecocokan potensial yang bukan entitas yang sama.
Akibatnya, setelah menganalisis dan membersihkan, pencocokan data dianggap sebagai fungsi yang paling penting.
Ingin menggunakan otomatisasi proses robotik? Lihat perangkat lunak pemrosesan dokumen berbasis alur kerja Nanonets. Tidak ada kode. Tidak ada platform yang merepotkan.
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
Apa manfaat menggunakan Pencocokan Data?
Pencocokan data adalah salah satu fase pertama dalam seluruh rencana pengelolaan data perusahaan, terutama jika didasarkan pada pengelolaan data induk.
Tingkatkan Presisi
Pencocokan data memudahkan untuk membandingkan data, melihat tren, dan menunjukkan tanda bahaya dalam data kompleks yang perlu diselidiki lebih lanjut. Ini adalah instrumen yang dapat diandalkan yang memungkinkan persyaratan prediksi yang lebih baik sambil membatasi data yang tidak relevan ke tingkat minimal.
Tingkatkan Keandalan Data
Organisasi menggunakan jaringan luas dari aplikasi dan sistem data yang saling berhubungan untuk menciptakan infrastruktur data internal. Namun, ketika data dikumpulkan dari berbagai sumber, ada kemungkinan besar inkonsistensi dalam informasi tersebut. Pembersihan data dan pengurangan duplikat sangat penting dalam situasi ini untuk memastikan kepercayaan data.
Data Struktur
Pembelajaran mesin memerlukan penggabungan data dari berbagai sumber. Skimming melalui beberapa set data mentah, pembersihan, karakterisasi, meminimalkan pengulangan, dan menggabungkan untuk hasil analisis yang akurat menjadi lebih mudah menggunakan teknologi pencocokan data. Untuk menstandarisasi data, perusahaan harus dapat mengatur dan memfilter entri dalam jumlah besar dari berbagai sumber data.
Ini juga memerlukan konversi informasi numerik, seperti informasi kontak, menjadi struktur yang sesuai dan seragam. Data diformat dan disiapkan untuk diproses dan dianalisis oleh sistem informasi manajemen sekunder.
Tingkatkan Akurasi
Setiap pilihan yang diambil berdasarkan informasi yang tidak akurat adalah buang-buang waktu dan sumber daya. Organisasi akan mendapat manfaat dari pencocokan data untuk meningkatkan kinerja lintas disiplin. Prestasi kerja dan kinerja keseluruhan akan meningkat secara signifikan.
Perbaiki Data
Dengan menggabungkan data dari sumber pihak ketiga yang andal dengan kumpulan data yang ada, organisasi dapat memperoleh keuntungan dari penguatan basis data. Perusahaan dapat meningkatkan pendapatan, branding, manufaktur, dan aktivitas lainnya dengan meningkatkan akurasi dan keandalan data pelanggan. Data yang ditingkatkan mengisi setiap celah dalam informasi pelanggan, memberikan perusahaan gambaran yang komprehensif tentang basis pelanggannya.
Tingkatkan Kepatuhan
Pencocokan data membantu memastikan bahwa hukum dipatuhi. Sebelum menghubungi klien, organisasi harus terlebih dahulu mendapatkan persetujuan untuk menggunakan informasi pengguna, seperti nomor telepon, dalam inisiatif pemasaran. Memperoleh otorisasi dari klien menjadi lebih kompleks karena model multimodal keterlibatan konsumen. Selain itu, risiko penalti meningkat ketika data salah dan bervariasi antar situs web. Bisnis dapat menunjukkan dengan tepat pelanggan yang mereka hadapi, memungkinkan mereka untuk meminta izin khusus.
Kurangi ruang yang dibutuhkan untuk penyimpanan
Mengurangi duplikat adalah metode untuk mengurangi jumlah entri dalam koleksi. Ini membutuhkan lebih sedikit ruang untuk penyimpanan, mengurangi tekanan pada jaringan setiap kali suatu program meminta informasi, dan meningkatkan kualitas informasi.
Pencegahan penipuan
Banyak penyedia asuransi kehilangan uang karena klaim palsu dan penggantian karena interkoneksi tersembunyi antara perusahaan. Program yang berbeda menerima berbagai laporan data, namun tidak ada pencocokan data yang menyiratkan tidak ada lampu merah yang disiagakan. Penipu menghasilkan inkonsistensi dengan menyimpan data yang identik di beberapa lokasi dalam suatu organisasi, sehingga sulit untuk dilacak kembali ke dokumentasi awal.
Personil juga dapat menggunakan penipuan untuk membuat catatan, seperti tanda terima pembelian atau bahkan dokumen lainnya, untuk menguntungkan diri mereka sendiri. Menggunakan algoritma untuk menemukan hubungan konvensional antara bentuk yang berbeda, program pencocokan data dapat menemukan hubungan antara kumpulan data yang berbeda.
Apa manfaat dari Klasifikasi Data?
Meningkatkan Keamanan
Ketika kami mengklasifikasikan data klien (korporat atau konsumen) berdasarkan berbagai kriteria apakah itu tingkat risiko atau formatnya, ada baiknya kami menemukan jawaban atas berbagai pertanyaan yang berkaitan dengan tingkat sensitivitas data, lokasi data, tingkat keamanan atau dampak pelanggaran keamanan dan siapa yang dapat mengakses atau mengubah data. Oleh karena itu, perubahan dapat dilakukan pada struktur kerangka kerja saat ini untuk mengurangi risiko pelanggaran, perusakan, atau modifikasi data sensitif. Ini juga dapat membantu kami mengoptimalkan biaya dengan mengalokasikan lebih sedikit sumber daya ke data yang kurang penting.
Kepatuhan Peraturan
Klasifikasi data membantu dalam menemukan data peraturan dalam organisasi, serta memastikan bahwa sistem keamanan yang memadai tersedia dan juga bahwa konten dapat diakses dan dinavigasi, sebagaimana diamanatkan oleh persyaratan peraturan. Hal ini meningkatkan peluang kami untuk lulus audit rutin, memastikan bahwa data dikelola dengan aman untuk persyaratan peraturan, dan menjaga kami dengan semua kebijakan yang berlaku, dan undang-undang perlindungan data setiap hari.
Meningkatkan Efisiensi
Klasifikasi data akan membantu organisasi dalam berhasil mengamankan, melestarikan, dan mengendalikan data mereka dari saat dihasilkan hingga dibuang. Hal ini memungkinkan kami untuk mengembangkan pemahaman yang lebih baik tentang dan mengatur arsip yang disimpan dan didistribusikan oleh organisasi, serta memungkinkan koneksi langsung yang cepat ke dan penggunaan data aman di seluruh organisasi. Hal ini juga membantu dalam penilaian risiko dengan membantu organisasi dalam menentukan kekuatan data dan konsekuensi dari ini dihancurkan, dicuri, salah penanganan, atau dikompromikan.
Jika Anda bekerja dengan faktur, dan tanda terima atau khawatir tentang verifikasi ID, periksa Nanonets OCR online or ekstraktor teks PDF untuk mengekstrak teks dari dokumen PDF gratis. Klik di bawah untuk mempelajari lebih lanjut Solusi Otomatisasi Perusahaan Nanonets.
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
Bagaimana cara mengoptimalkan Klasifikasi Data?
Membentuk sistem Klasifikasi Data
Organisasi selanjutnya harus menetapkan garis besar struktur klasifikasi dengan parameter bisnis yang ditingkatkan dan kesadaran akan jenis informasi sensitif khusus mereka ketika satu struktur klasifikasi data telah dibangun. Namun, ini bukan tugas yang sederhana. Semua bisnis itu unik, tetapi tidak ada yang namanya paket perlindungan data universal.
Setiap subkategori dalam garis besar kategorisasi data harus menentukan kategori yang akan dimasukkan, bahaya pelanggaran data, dan standar manajemen data.
Membentuk berbagai kategori Klasifikasi Data
Meskipun ada banyak cara berbeda untuk mengkategorikan data, sebagian besar bisnis menggunakan garis besar kategorisasi empat input: umum, pribadi, rahasia, dan terbatas.
- Materi promosi, detail kontak, perjanjian layanan klien, dan data harga adalah contoh informasi publik yang dapat diakses secara terbuka dan tersedia untuk masyarakat umum tanpa batasan atau dampak negatif.
- Interaksi pelanggan, buku pegangan pemasaran, dan diagram proses adalah contoh data orang dalam dengan tingkat kebutuhan keamanan yang rendah namun tidak dimaksudkan untuk publikasi publik. Pengungkapan materi semacam itu yang tidak diinginkan dapat mengakibatkan aib publik dan kerugian kompetitif dalam waktu dekat.
- Materi sensitif yang, jika bocor, masih dapat berdampak buruk pada bisnis perusahaan, termasuk merugikan pengguna, afiliasi, atau staf. Perjanjian dengan vendor, evaluasi dan pembayaran personel, dan data pelanggan hanyalah beberapa contoh.
- Informasi komersial yang sangat sensitif yang, jika bocor, dapat mempertaruhkan kepentingan keuangan, administratif, hukum, dan sosial perusahaan. Detail kartu debit pelanggan adalah contohnya.
Praktik kebijakan terbaik
Dengan menggunakan praktik terbaik, organisasi dapat menjamin bahwa prosedur kategorisasi mereka berhasil dan mereka mendapatkan nilai lebih darinya. Perusahaan juga lebih memilih untuk mencegah risiko kategorisasi data yang salah, yang juga dapat menyebabkan kesan buruk jangka panjang dari alat perlindungan data penting ini.
Empat fase termasuk dalam beberapa praktik terbaik untuk membangun rencana kategorisasi yang komprehensif dan efektif.
Menggabungkan kategorisasi data yang terkomputerisasi, bersamaan, dan tahan lama
Penilaian perangkat lunak dan perangkat keras yang tepat merampingkan prosedur kategorisasi data dengan menilai dan mengkategorikan data secara mandiri sesuai dengan spesifikasi yang telah ditentukan sebelumnya.
Putuskan untuk mengklasifikasikan data Anda
Kerjasama dari atas ke bawah dan melalui bantuan tim eksekutif untuk mempromosikan usaha. Ini menetapkan harapan bahwa kategorisasi adalah perhatian utama dan semua orang diharapkan untuk mengambil bagian. Ini juga menunjukkan bahwa organisasi menghargai privasinya dan bahwa keamanan dan manajemen data yang tepat adalah bagian dari kebiasaan organisasi.
Tentukan budaya kepatuhan keamanan baru
Mengurangi kehadiran Anda memerlukan pelatihan penyedia data, pengguna, dan pemilik tentang peran dan fungsi masing-masing dalam melindungi data dan memungkinkan semua orang membantu membatasi kerentanan Anda. Banyak bisnis secara teratur mengatur sesi terkait privasi. Namun, lebih baik mengembangkan cara untuk menanamkan perasaan pemahaman perlindungan privasi yang gigih dalam praktik sehari-hari personel.
Berkolaborasi dengan TI dan organisasi
Perusahaan dapat terus memberikan saran, bantuan, dan izin di setiap tahap prosedur dengan mengadopsi prosedur yang andal dengan TI.
Kasus penggunaan teratas untuk Pencocokan Data
Meskipun tujuan keseluruhan pencocokan data adalah untuk menemukan data yang lebih tepat dan berbeda dari kumpulan catatan yang identik, metode yang digunakan bervariasi menurut industri.
Jasa Keuangan
Pencocokan data digunakan oleh perusahaan fintech, perbankan, dan jasa keuangan untuk mengelola proyek seperti menemukan penjahat pencucian uang dan menyelesaikan skor kredit klien. Untuk memperoleh gambaran lengkap klien di beberapa kegiatan komersial, bank menggunakan teknik pencocokan data.
Sektor publik
Untuk mengungkap penipuan, mematuhi standar, dan melaksanakan penilaian sosiopolitik, entitas pemerintah dan sektor publik mengandalkan pemusatan catatan dengan meninjau data identifikasi pribadi, seperti SSN, dan nomor registrasi. Pencocokan data dapat membantu dalam mendeteksi kemungkinan penipuan, aktivitas, dan orang yang terlibat. Juga, untuk survei nasional, pemerintah menerima beragam data demografis, yang biasanya dikumpulkan oleh berbagai organisasi di bawah pedoman yang berbeda dan dipelihara dalam sistem yang berbeda. Pihak berwenang dapat mengembangkan studi statistik dan memperoleh pemahaman yang lebih baik tentang berbagai bagian negara dengan menggabungkan kumpulan data ini.
Industri Pendidikan
Pencocokan data digunakan di bidang pendidikan untuk mendeteksi duplikasi dalam kumpulan data pembelajaran dan pengajaran di seluruh geografi, serta untuk menilai kinerja siswa, membedakan pendekatan pengajaran yang bervariasi, menilai fluktuasi nilai, atau membedakan antara teknik pengajaran yang efektif dan tidak efektif.
Sektor kesehatan
Data pasien dicocokkan di fasilitas kesehatan untuk menentukan diagnosis yang tepat dan resep yang tepat. Untuk menjaga integritas catatan pasien mereka, mereka menerapkan pencocokan data dan proses pembersihan melalui aplikasi bisnis. Tanpa prosedur deduplikasi otomatis, pasien mungkin ditawari obat yang tidak cocok atau mendapatkan beberapa perawatan untuk penyakit yang sama. Rekam medis dicocokkan dengan beberapa kumpulan data lain untuk menilai dampak dari berbagai faktor seperti obat-obatan, pengobatan, dan kondisi.
Pemasaran dan Penjualan
Dengan mengintegrasikan penyempurnaan data dan keterampilan validasi, teknologi pencocokan data memungkinkan perusahaan untuk menemukan dan mengkategorikan kelompok sasaran tergantung pada banyak karakteristik sosiodemografis. Dengan personalisasi yang tepat, bisnis dapat meningkatkan dampak operasi pemasaran dan periklanan dengan menghasilkan iklan atau promosi yang sangat cocok dan sesuai untuk pelanggan potensial.
Ingin mengotomatiskan tugas manual yang berulang? Hemat Waktu, Tenaga & Uang sambil meningkatkan efisiensi!
.cta-first-blue{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: #546ffff; warna putih; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-first-blue:hover{ color:#546fff; latar belakang:putih; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; perbatasan: padat #546fff !penting; } .cta-second-black{ transisi: semua 0.1s cubic-bezier(0.4, 0, 0.2, 1) 0s; batas-radius: 0px; font-berat: tebal; ukuran font: 16px; tinggi garis: 24px; bantalan: 12px 24px; latar belakang: putih; warna: #333; tinggi: 56px; perataan teks: kiri; tampilan: inline-flex; arah fleksibel: baris; -moz-box-align: tengah; align-item: tengah; spasi huruf: 0px; ukuran kotak: kotak perbatasan; border-width:2px !penting; batas: solid #333 !penting; } .cta-second-black:hover{ color:white; latar belakang:#333; transisi: semua 0.1s kubik-bezier(0.4, 0, 0.2, 1) 0s; border-width:2px !penting; batas: solid #333 !penting; } .column1{ lebar minimum: 240 piksel; max-width: fit-konten; padding-kanan: 4%; } .column2{ lebar minimum: 200 piksel; max-width: fit-konten; } .cta-main{ tampilan: fleksibel; }
Tantangan dalam Pencocokan Data
Algoritma Pencocokan Data Bisa Rumit
Pencocokan data terkadang merupakan proses yang sederhana jika protokol untuk pengumpulan informasi dan standar masuk sudah ada. Teknik pencocokan mungkin memerlukan alasan yang rumit untuk mengambil semua variabel yang mungkin cocok jika ada sedikit teknik standarisasi pra-dataset yang ketat.
Standarisasi data sangat penting
Data dalam jumlah besar, khususnya, berpotensi menimbulkan masalah. Misalnya, format yang tidak tepat, penggunaan karakter, dan sebagainya. Karena nama yang diketik ini dapat muncul pada beberapa entri, program harus mengakomodasi bagaimana input ini harus diproses.
Kesalahan Klien
Klien dapat menyebabkan masalah, terutama jika mereka dapat melaporkan catatan dan dokumen. Jika pengguna salah menandai perusahaan besar sebagai "tersangka" dalam catatan pekerjaan, banyak kandidat sah yang menggunakan perusahaan yang sama dapat ditandai sebagai "tersangka" sebagai bagian dari penilaian awal. Keputusan ini hampir pasti akan berdampak merugikan pada operasi perekrutan perusahaan serta organisasi lain yang memperdagangkan dan membandingkan data.
Kesalahan Pencocokan Data
Jika dua entri berkaitan dengan entitas yang berbeda, tetapi pencocokan menganggap keduanya tampaknya sama, hasil positif palsu. Negatif palsu terjadi ketika dua entri tampaknya terkait dengan subjek yang sama, tetapi pencocokan mengklaim tidak. Ini harus dipahami oleh organisasi, serta frekuensi dan akibatnya.
Kesimpulan
Pencocokan data sangat penting untuk setiap organisasi yang berupaya memperbaiki penyimpanan datanya dan menerapkan strategi bisnis berbasis data, terlepas dari rintangan dan batasannya. Hal ini memungkinkan bisnis untuk mengembangkan bisnis yang dapat diskalakan dan pengurangan duplikasi informasi pelanggan, hubungan catatan, pengurangan, pengayaan, pengambilan, dan pengaturan standarisasi. Ini juga menciptakan sumber informasi titik untuk mengoptimalkan kegunaan data di seluruh perusahaan.
var contentTitle = “Daftar Isi”; // Tetapkan judul Anda di sini, untuk menghindari membuat judul nanti var ToC = “
“+isiJudul+”
“; Daftar Isi += “
“; var tocDiv = document.getElementById('dynamictocnative'); tocDiv.outerHTML = ToC;
Nanonet OCR & OCR API online punya banyak yang menarik gunakan kasing tHal ini dapat mengoptimalkan kinerja bisnis Anda, menghemat biaya, dan meningkatkan pertumbuhan. Temukan bagaimana kasus penggunaan Nanonet dapat diterapkan pada produk Anda.
- "
- &
- a
- Tentang Kami
- mempercepat
- mengakses
- dapat diakses
- menampung
- Menurut
- tepat
- memperoleh
- di seluruh
- tindakan
- kegiatan
- pengiklanan
- nasihat
- Afiliasi
- perjanjian
- bantu
- algoritma
- algoritma
- Semua
- Membiarkan
- memungkinkan
- sudah
- antara
- jumlah
- analisis
- Analytical
- berlaku
- aplikasi
- Mendaftar
- pendekatan
- sesuai
- aplikasi
- penilaian
- keaslian
- otorisasi
- mengotomatisasikan
- secara otomatis
- Otomatisasi
- tersedia
- kesadaran
- latar belakang
- Perbankan
- Bank
- Dasar
- Bears
- karena
- sebelum
- makhluk
- di bawah
- manfaat
- Manfaat
- TERBAIK
- Praktik Terbaik
- antara
- pin
- batas
- merek
- pelanggaran
- pelanggaran
- Bangunan
- bisnis
- bisnis
- dihitung
- Kampanye
- calon
- Kartu-kartu
- kasus
- katalog
- Menyebabkan
- menantang
- kesempatan
- karakter
- pilihan
- Pilih
- klaim
- kelas-kelas
- klasifikasi
- Pembersihan
- klien
- kode
- koleksi
- komersial
- Perusahaan
- perusahaan
- dibandingkan
- kompetitif
- lengkap
- menyelesaikan
- kompleks
- luas
- Kondisi
- Mengadakan
- koneksi
- Koneksi
- persetujuan
- Mempertimbangkan
- konsumen
- kontak
- Konten
- isi
- terus
- kontrak
- Konversi
- Timeline
- PERUSAHAAN
- Sesuai
- Biaya
- bisa
- membuat
- menciptakan
- kredit
- Penjahat
- kriteria
- kritis
- terbaru
- pelanggan
- pelanggan
- bea cukai
- harian
- data
- Pelanggaran Data
- manajemen data
- data mining
- perlindungan data
- keamanan data
- kumpulan data
- Basis Data
- berurusan
- Kartu debit
- keputusan
- demografis
- Tergantung
- menyebarkan
- musnah
- terperinci
- rincian
- Deteksi
- Menentukan
- menentukan
- mengembangkan
- Pengembang
- Pengembangan
- berbeda
- membedakan
- sulit
- langsung
- menemukan
- Display
- dokumen
- duplikat
- selama
- setiap
- Pendidikan
- efek
- Efektif
- usaha
- upaya
- menghapuskan
- pekerjaan
- aktif
- memungkinkan
- memungkinkan
- memastikan
- Enterprise
- perusahaan
- entitas
- entitas
- terutama
- menetapkan
- menetapkan
- mengevaluasi
- sehari-hari
- semua orang
- contoh
- contoh
- eksekutif
- ada
- diharapkan
- biaya
- keahlian
- menyelidiki
- faktor
- akrab
- Fitur
- Akhirnya
- keuangan
- temuan
- fintech
- Perusahaan
- Pertama
- cocok
- tetap
- berfokus
- berikut
- bentuk
- format
- bentuk
- Kerangka
- dari
- penuh
- fungsi
- fungsi
- lebih lanjut
- Selanjutnya
- pertemuan
- Umum
- umumnya
- menghasilkan
- dihasilkan
- menghasilkan
- Pemberian
- tujuan
- Anda
- pemerintahan
- Pemerintah
- Kelompok
- Pertumbuhan
- menjamin
- pedoman
- terjadi
- Perangkat keras
- kesehatan
- tinggi
- membantu
- membantu
- di sini
- sangat
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTTPS
- Lari gawang
- Identifikasi
- mengidentifikasi
- identitas
- Dampak
- diimplementasikan
- penting
- memperbaiki
- termasuk
- Termasuk
- Tergabung
- indeks
- menunjukkan
- sendiri-sendiri
- industri
- informasi
- Infrastruktur
- inisiatif
- memasukkan
- contoh
- instrumen
- asuransi
- integritas
- kepentingan
- terlibat
- masalah
- IT
- pemeliharaan
- dikenal
- besar
- Hukum
- Hukum
- memimpin
- BELAJAR
- pengetahuan
- Informasi
- Tingkat
- MEMBATASI
- Terbatas
- batas
- LINK
- menghubungkan
- tempat
- lokasi
- jangka panjang
- melihat
- terbuat
- memelihara
- utama
- membuat
- MEMBUAT
- Membuat
- mengelola
- berhasil
- pengelolaan
- manajer
- panduan
- pabrik
- Marketing
- menguasai
- Cocok
- sesuai
- bahan
- bahan
- Matriks
- hal
- ukuran
- medis
- mungkin
- Pertambangan
- model
- uang
- Pencucian uang
- Bulan
- lebih
- paling
- Paling Populer
- beberapa
- nama
- bangsa
- nasional
- Navigasi
- Dekat
- perlu
- negatif
- jaringan
- jaringan
- berikutnya
- normal
- jumlah
- nomor
- ditawarkan
- Operasi
- Optimize
- organisasi
- organisatoris
- organisasi
- terorganisir
- Lainnya
- secara keseluruhan
- bagian
- tertentu
- khususnya
- Lewat
- Membayar
- Konsultan Ahli
- prestasi
- orang
- pribadi
- data pribadi
- Personalisasi
- Personil
- gambar
- penempatan
- Platform
- kebanyakan
- Titik
- Kebijakan
- kebijaksanaan
- kolam
- Populer
- positif
- kemungkinan
- mungkin
- potensi
- kekuasaan
- ramalan
- kehadiran
- pers
- di harga
- primer
- pribadi
- swasta
- masalah
- proses
- Otomatisasi proses
- proses
- pengolahan
- Produk
- Keuntungan
- program
- program
- memprojeksikan
- mendorong
- milik
- perlindungan
- protokol
- penyedia
- menyediakan
- publik
- sektor publik
- membeli
- kualitas
- Mentah
- menerima
- catatan
- arsip
- Memulihkan
- pemulihan
- menurunkan
- mengurangi
- mengenai
- Pendaftaran
- reguler
- Regulasi
- regulator
- Hubungan
- Pers
- dapat diandalkan
- melaporkan
- laporan
- permintaan
- permintaan
- membutuhkan
- wajib
- Persyaratan
- membutuhkan
- Sumber
- Hasil
- Pengembalian
- keras
- Risiko
- penilaian risiko
- risiko
- Otomatisasi Proses Robot
- Safety/keselamatan
- sama
- terukur
- penipuan
- sekunder
- sektor
- Dijamin
- aman
- keamanan
- layanan
- sesi
- set
- beberapa
- penting
- Sederhana
- tunggal
- Ukuran
- keterampilan
- So
- Sosial
- Perangkat lunak
- padat
- larutan
- Space
- khusus
- spesifikasi
- Spot
- Tahap
- taruhan
- standar
- statistika
- Masih
- penyimpanan
- Penyelarasan
- tekanan
- studi
- subyek
- sukses
- berhasil
- sistem
- target
- tugas
- Pengajaran
- tim
- teknik
- Teknologi
- terminal
- Grafik
- hukum
- hal
- pihak ketiga
- tiga
- Melalui
- di seluruh
- waktu
- Judul
- alat
- puncak
- perdagangan
- Pelatihan
- Transaksi
- transisi
- jelas
- Tren
- jenis
- khas
- menemukan
- bawah
- pemahaman
- dipahami
- unik
- Universal
- us
- menggunakan
- Pengguna
- biasanya
- Penggunaan
- pengesahan
- nilai
- variasi
- berbagai
- vendor
- Verifikasi
- volume
- kerentanan
- cara
- situs web
- mingguan
- apakah
- sementara
- SIAPA
- dalam
- tanpa
- Kerja
- Menghasilkan
- Anda