Pengantar
Dalam dunia bisnis saat ini, layanan layanan pelanggan memainkan peran penting dalam memastikan loyalitas dan kepuasan pelanggan. Memahami dan menganalisis sentimen yang diungkapkan selama interaksi dapat membantu meningkatkan kualitas layanan pelanggan. Analisis sentimen pada data audio layanan pelanggan bertindak sebagai alat yang ampuh untuk mencapai tujuan ini. Dalam panduan komprehensif ini, kami akan mengeksplorasi kompleksitas dalam melakukan analisis sentimen pada rekaman audio layanan pelanggan, memberikan peta jalan penerapan yang terperinci.

Tujuan Pembelajaran
- Pelajari cara membangun aplikasi web Flask yang menggunakan AWS.
- Pelajari prosedur melakukan analisis sentimen.
- Pelajari perhitungan yang terlibat dalam analisis sentimen.
- Pahami cara mengekstrak data yang diperlukan dan dapatkan wawasan dari analisis ini.
Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Daftar Isi
Prosedur Melakukan Analisis Sentimen
Tahap 1: Mempersiapkan Data
Memahami Tugas: Untuk melakukan analisis sentimen pada audio layanan pelanggan yang tersedia dan memberikan wawasan dari hasilnya.
Membuat Aplikasi Flask: Membangun aplikasi web Flask yang menggunakan pemahaman Amazon Web Services (AWS) untuk melakukan analisis. Aplikasi ini adalah dasar untuk proyek kami.
Mengunggah Rekaman Audio: Rekaman panggilan harus disimpan dalam database seperti bucket AWS S3 untuk memulai analisis.
Mengembangkan Antarmuka Pengguna: Membuat antarmuka yang ramah pengguna sangatlah penting. Ini dicapai dengan menggunakan CSS, HTML, dan JavaScript. Antarmuka ini membantu pengguna untuk memilih nama, tanggal, dan waktu.
Mendapatkan Masukan: Input pengguna seperti Nama, Tanggal dan Waktu Awal, serta Tanggal dan Waktu Akhir diambil untuk menyesuaikan proses analisis.
Mengambil Rekaman: Panduan untuk mengambil rekaman dari bucket S3 dalam interval waktu yang dipilih diberikan.
Transkripsi Audio: Inti dari analisis sentimen terletak pada teks yang ditranskrip. Bagian ini mengeksplorasi bagaimana AWS Transcribe mengubah kata-kata yang diucapkan dari rekaman yang tersedia menjadi teks
analisis.
Tahap 2: Menganalisis Data
Melakukan Analisis Sentimen: Menganalisis teks yang ditranskrip penting untuk panduan ini. Langkah pertama dari fase ini adalah membagi sejumlah besar teks menjadi beberapa bagian yang dapat dikelola. Langkah selanjutnya adalah melakukan analisis sentimen pada setiap bagian.
Menghitung Metrik Sentimen: Berikutnya adalah memperoleh wawasan yang bermakna. Kami akan menghitung rata-rata seluruh skor sentimen dan menghitung Net Promoter Score (NPS). NPS adalah metrik penting yang mengukur loyalitas pelanggan atau karyawan. Rumus NPSnya adalah sebagai berikut:
NPS = ((Total Positif / Total
Catatan) – (Total Negatif / Total Catatan)) * 100
Membuat Grafik Tren: Ini membantu untuk Memahami tren dari waktu ke waktu. Kami akan memandu Anda membuat grafik tren visual yang menggambarkan kemajuan skor sentimen. Grafik ini akan mencakup positif, negatif,
nilai campuran, dan netral dan NPS.
Halaman Hasil: Pada langkah terakhir analisis, kami akan membuat halaman hasil yang menampilkan hasil analisis kami. Halaman ini akan menyajikan laporan tentang metrik sentimen, grafik tren, dan wawasan yang dapat ditindaklanjuti
diambil dari interaksi layanan pelanggan.
Sekarang mari kita mulai analisis sentimen kita, mengikuti prosedur di atas.
Mengimpor Perpustakaan yang Diperlukan
Di bagian ini, kami mengimpor pustaka Python penting yang penting untuk membangun aplikasi Flask, berinteraksi dengan layanan AWS, dan melakukan berbagai tugas lainnya.
from flask import Flask, render_template, request
import boto3
import json
import time
import urllib.request
import requests
import os
import pymysql
import re
import sys
import uuid
from datetime import datetime
import json
import csv
from io import StringIO
import urllibMengunggah Rekaman Audio
Sebelum memulai analisis rekaman panggilan kami, rekaman harus mudah diakses. Menyimpan rekaman di lokasi seperti bucket AWS S3 membantu pengambilan dengan mudah. Dalam penelitian ini, kami telah mengunggah
rekaman karyawan dan pelanggan sebagai rekaman terpisah dalam satu folder.
Membuat Antarmuka Pengguna
Menggunakan CSS, HTML, dan JavaScript, antarmuka pengguna yang menarik secara visual dibuat untuk aplikasi ini. Ini membantu pengguna untuk memilih masukan seperti Nama dan tanggal dari widget yang disediakan.
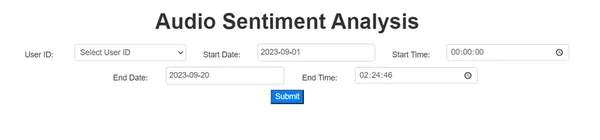
Mendapatkan Masukan
Kami menggunakan aplikasi Flask kami untuk mendapatkan informasi dari pengguna. Untuk melakukan ini, kami menggunakan metode POST untuk mengumpulkan detail seperti nama karyawan dan rentang tanggal. Kami kemudian dapat menganalisis sentimen karyawan dan pelanggan. Dalam demonstrasi kami, kami menggunakan rekaman panggilan karyawan untuk dianalisis. Kami juga dapat menggunakan rekaman panggilan pelanggan yang berinteraksi dengan karyawan tersebut, bukan panggilan karyawan tersebut.
Kita dapat menggunakan kode berikut untuk ini.
@app.route('/fetch_data', methods=['POST'])
def fetch_data(): name = request.form.get('name') begin_date = request.form.get('begin_date') begin_time = request.form.get('begin_time') begin_datetime_str = f"{begin_date}T{begin_time}.000Z" print('Begin time:',begin_datetime_str) end_date = request.form.get('end_date') end_time = request.form.get('end_time') end_datetime_str = f"{end_date}T{end_time}.000Z"Mengambil Rekaman
Untuk memulai analisis, kita perlu mendapatkan rekaman audio dari lokasi penyimpanannya. Baik rekaman tersebut ada di bucket AWS S3 atau database lainnya, kita harus mengikuti langkah-langkah tertentu untuk mendapatkan rekaman ini, terutama untuk jangka waktu tertentu. Kita harus memastikan bahwa kita menyediakan folder yang benar yang berisi rekaman karyawan atau pelanggan.
Contoh ini menunjukkan cara mendapatkan rekaman dari bucket S3.
# Initialize the S3 client
s3 = boto3.client('s3') # Specify the S3 bucket name and the prefix (directory) where your recordings are stored
bucket_name = 'your-s3-bucket-name'
prefix = 'recordings/' try: response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix) # Iterate through the objects and fetch them for obj in response.get('Contents', []): # Get the key (object path) key = obj['Key'] # Download the object to a local file local_filename = key.split('/')[-1] s3.download_file(bucket_name, key, local_filename) print(f"Downloaded {key} to {local_filename}")
except Exception as e: print(f"An error occurred: {e}")Transkripsi Audio
Mengubah kata-kata yang diucapkan dari audio menjadi teks merupakan suatu tantangan. Kami menggunakan alat praktis yang disebut Transkrip Amazon Web Services (AWS) untuk melakukan pekerjaan ini secara otomatis. Namun sebelum itu, kami membersihkan data audio dengan menghapus bagian yang tidak ada orang yang berbicara dan mengubah percakapan dalam bahasa lain ke bahasa Inggris. Selain itu, jika ada banyak orang yang berbicara dalam sebuah rekaman, kita perlu memisahkan suara mereka dan hanya fokus pada suara yang ingin kita analisis.
Namun, agar bagian terjemahan dapat berfungsi, kami memerlukan rekaman audio dalam format yang dapat diakses melalui tautan web. Kode dan penjelasan di bawah ini akan ditampilkan
Anda bagaimana semua ini bekerja.
Kode Implementasi:
transcribe = boto3.client('transcribe', region_name=AWS_REGION_NAME)
def transcribe_audio(audio_uri): job_name_suffix = str(uuid.uuid4()) # Generate a unique job name using timestamp timestamp = str(int(time.time())) transcription_job_name = f'Transcription_{timestamp}_{job_name_suffix}' settings = { 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 } response = transcribe.start_transcription_job( TranscriptionJobName=transcription_job_name, LanguageCode='en-US', Media={'MediaFileUri': audio_uri}, Settings=settings ) transcription_job_name = response['TranscriptionJob']['TranscriptionJobName'] # Wait for the transcription job to complete while True: response = transcribe.get_transcription_job( TranscriptionJobName=transcription_job_name) status = response['TranscriptionJob']['TranscriptionJobStatus'] if status in ['COMPLETED', 'FAILED']: break print("Transcription in progress...") time.sleep(5) transcript_text = None if status == 'COMPLETED': transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] with urllib.request.urlopen(transcript_uri) as url: transcript_json = json.loads(url.read().decode()) transcript_text = transcript_json['results']['transcripts'][0]['transcript'] print("Transcription completed successfully!") print('Transribed Text is:', transcript_text) else: print("Transcription job failed.") # Check if there are any transcripts (if empty, skip sentiment analysis) if not transcript_text: print("Transcript is empty. Skipping sentiment analysis.") return None return transcript_text
Penjelasan:
Inisialisasi Pekerjaan: Tentukan nama unik dan kode bahasa (dalam hal ini, 'en-US' untuk bahasa Inggris) untuk memulai tugas AWS Transcribe.
Pengaturan Transkripsi: Kami menentukan pengaturan untuk pekerjaan transkripsi, termasuk opsi untuk menampilkan label speaker dan menentukan jumlah maksimum label speaker (berguna untuk audio multi-speaker).
Mulai Transkripsi: Pekerjaan akan dimulai menggunakan metode start_transcription_job. Ini menyalin audio yang disediakan secara asinkron.
Pantau Kemajuan Pekerjaan: Kami secara berkala memeriksa status pekerjaan transkripsi. Itu bisa sedang berlangsung, selesai, atau gagal. Kami berhenti sejenak dan menunggu selesai sebelum melanjutkan.
Akses Teks Transkripsi: Setelah pekerjaan berhasil diselesaikan, kami mengakses teks transkripsi dari URI transkrip yang disediakan. Teks ini kemudian tersedia untuk analisis sentimen.
Melakukan Analisis Sentimen
Analisis sentimen adalah hal penting dalam pekerjaan analisis kami. Ini semua tentang memahami perasaan dan konteks dalam teks tertulis yang muncul dari pengubahan audio menjadi kata-kata. Untuk menangani banyak teks, kami memecahnya menjadi bagian-bagian yang lebih kecil. Lalu, kami menggunakan alat yang disebut AWS Comprehend, yang sangat bagus dalam mencari tahu apakah teks terdengar positif, negatif, netral, atau campuran dari perasaan tersebut.
Kode Implementasi:
def split_text(text, max_length): # Split the text into chunks of maximum length chunks = [] start = 0 while start < len(text): end = start + max_length chunks.append(text[start:end]) start = end return chunks def perform_sentiment_analysis(transcript): transcript = str(transcript) # Define the maximum length for each chunk max_chunk_length = 5000 # Split the long text into smaller chunks text_chunks = split_text(transcript, max_chunk_length) # Perform sentiment analysis using AWS Comprehend comprehend = boto3.client('comprehend', region_name=AWS_REGION_NAME) sentiment_results = [] confidence_scores = [] # Perform sentiment analysis on each chunk for chunk in text_chunks: response = comprehend.detect_sentiment(Text=chunk, LanguageCode='en') sentiment_results.append(response['Sentiment']) confidence_scores.append(response['SentimentScore']) sentiment_counts = { 'POSITIVE': 0, 'NEGATIVE': 0, 'NEUTRAL': 0, 'MIXED': 0 } # Iterate over sentiment results for each chunk for sentiment in sentiment_results: sentiment_counts[sentiment] += 1 # Determine the majority sentiment aws_sentiment = max(sentiment_counts, key=sentiment_counts.get) # Calculate average confidence scores average_neutral_confidence = round( sum(score['Neutral'] for score in confidence_scores) / len(confidence_scores), 4) average_mixed_confidence = round( sum(score['Mixed'] for score in confidence_scores) / len(confidence_scores), 4) average_positive_confidence = round( sum(score['Positive'] for score in confidence_scores) / len(confidence_scores), 4) average_negative_confidence = round( sum(score['Negative'] for score in confidence_scores) / len(confidence_scores), 4) return { 'aws_sentiment': aws_sentiment, 'average_positive_confidence': average_positive_confidence, 'average_negative_confidence': average_negative_confidence, 'average_neutral_confidence': average_neutral_confidence, 'average_mixed_confidence': average_mixed_confidence }Penjelasan:
Menguraikan Teks: Untuk menangani banyak teks dengan lebih mudah, kami membagi transkrip menjadi bagian-bagian kecil agar kami dapat mengelola dengan lebih baik. Kami kemudian akan melihat bagian-bagian kecil ini satu per satu.
Memahami Emosi: Kami menggunakan AWS Comprehend untuk mengetahui emosi (seperti positif, negatif, netral, campuran) di setiap bagian kecil ini. Ini juga memberi tahu kita betapa yakinnya kita tentang emosi-emosi ini.
Menghitung Emosi: Kami mencatat berapa kali setiap emosi muncul di bagian-bagian kecil ini. Ini membantu kami mengetahui apa yang dirasakan kebanyakan orang secara keseluruhan.
Menemukan Keyakinan: Kami menghitung skor rata-rata untuk seberapa yakin AWS Comprehend terhadap emosi yang ditemukannya. Ini membantu kami melihat seberapa yakin sistem terhadap hasilnya.
Menghitung Metrik Sentimen
Setelah melakukan analisis sentimen pada setiap potongan teks, kami melanjutkan menghitung metrik sentimen yang bermakna. Metrik ini memberikan wawasan tentang keseluruhan sentimen dan persepsi pelanggan atau karyawan.
Kode Implementasi:
result = perform_sentiment_analysis(transcript)
def sentiment_metrics(result): # Initialize variables to store cumulative scores total_sentiment_value = '' total_positive_score = 0 total_negative_score = 0 total_neutral_score = 0 total_mixed_score = 0 # Counters for each sentiment category count_positive = 0 count_negative = 0 count_neutral = 0 count_mixed = 0 # Process the fetched data and calculate metrics for record in result: sentiment_value = aws_sentiment positive_score = average_positive_confidence negative_score = average_negative_confidence neutral_score = average_neutral_confidence mixed_score = average_mixed_confidence # Count occurrences of each sentiment category if sentiment_value == 'POSITIVE': count_positive += 1 elif sentiment_value == 'NEGATIVE': count_negative += 1 elif sentiment_value == 'NEUTRAL': count_neutral += 1 elif sentiment_value == 'MIXED': count_mixed += 1 # Calculate cumulative scores total_sentiment_value = max(sentiment_value) total_positive_score += positive_score total_negative_score += negative_score total_neutral_score += neutral_score total_mixed_score += mixed_score # Calculate averages total_records = len(result) overall_sentiment = total_sentiment_value average_positive = total_positive_score / total_records if total_records > 0 else 0 average_negative = total_negative_score / total_records if total_records > 0 else 0 average_neutral = total_neutral_score / total_records if total_records > 0 else 0 average_mixed = total_mixed_score / total_records if total_records > 0 else 0 # Calculate NPS only if there are records if total_records > 0: NPS = ((count_positive/total_records) - (count_negative/total_records)) * 100 NPS_formatted = "{:.2f}%".format(NPS) else: NPS_formatted = "N/A" # Create a dictionary to store the calculated metrics metrics = { "total_records": total_records, "overall_sentiment": overall_sentiment, "average_positive": average_positive, "average_negative": average_negative, "average_neutral": average_neutral, "average_mixed": average_mixed, "count_positive": count_positive, "count_negative": count_negative, "count_neutral": count_neutral, "count_mixed": count_mixed, "NPS": NPS_formatted } return metrics
Penjelasan:
Skor Kumulatif: Kita mulai dengan menetapkan beberapa variabel untuk melacak total skor perasaan positif, negatif, netral, dan campur aduk. Skor ini akan bertambah seiring kita mempelajari semua bagian yang dianalisis.
Menghitung Sentimen: Kami terus menghitung berapa kali setiap jenis emosi muncul, seperti yang kami lakukan saat kami mencari tahu perasaan sebelumnya.
Menemukan Rata-rata: Kami menghitung skor rata-rata untuk emosi dan suasana hati secara keseluruhan berdasarkan apa yang tampaknya dirasakan kebanyakan orang. Kami juga menghitung sesuatu yang disebut Net Promoter Score (NPS) menggunakan rumus khusus yang kami sebutkan sebelumnya.
Membuat Grafik Tren
Untuk melihat bagaimana emosi berubah seiring waktu, kami membuat grafik tren. Ini seperti gambar yang secara visual menunjukkan apakah emosi meningkat atau menurun. Mereka membantu perusahaan mengidentifikasi pola apa pun dan menggunakan informasi ini untuk membuat keputusan cerdas berdasarkan data.
Prosedur:
Agregasi Data: Kami menghitung skor sentimen rata-rata dan nilai NPS untuk setiap minggunya. Nilai-nilai ini disimpan dalam format kamus dan akan digunakan untuk membuat grafik tren.
Menghitung Nomor Minggu: Untuk setiap rekaman audio, kami menentukan minggu terjadinya. Hal ini penting untuk mengatur data ke dalam tren mingguan.
Menghitung Rata-Rata: Kami menghitung skor sentimen rata-rata dan nilai NPS untuk setiap minggunya. Nilai-nilai ini akan digunakan untuk membuat grafik tren.
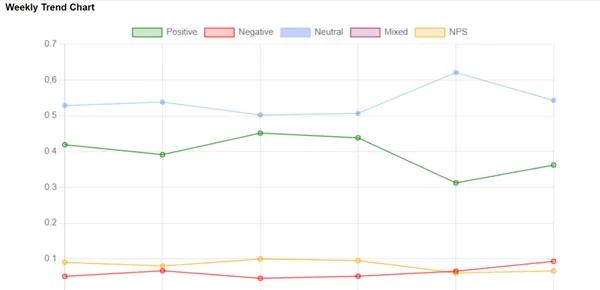
Hasil Analisis Sentimen
Setelah analisis, kita dapat membuat halaman hasil seperti gambar di bawah ini. Halaman ini memberikan laporan keseluruhan, seperti jumlah total rekaman, total durasi panggilan, dll. Selain itu, halaman ini menampilkan grafik yang mewakili skor rata-rata dan tren. Kami juga dapat mencatat skor negatif dan detailnya secara terpisah.
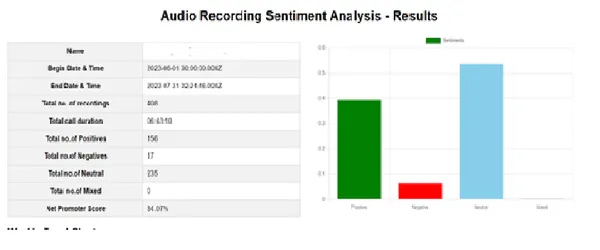
Kesimpulan
Dalam dunia bisnis yang serba cepat saat ini, memahami perasaan pelanggan sangatlah penting. Ini seperti memiliki alat rahasia untuk membuat pelanggan lebih bahagia. Analisis sentimen pada rekaman panggilan audio membantu mendapatkan wawasan tentang interaksi pelanggan. Artikel ini menjelaskan langkah-langkah melakukan analisis sentimen, mulai dari mengubah audio menjadi teks hingga membuat grafik tren.
Pertama, kami menggunakan alat seperti AWS Transcribe untuk membantu kami mengubah kata-kata yang diucapkan dari transkripsi audio ini menjadi teks yang dapat dibaca. Analisis sentimen kemudian menilai emosi dan konteksnya dan mengkategorikannya menjadi sentimen positif, negatif, netral, atau campuran.
Metrik sentimen melibatkan pengumpulan skor dan penghitungan Net Promoter Score (NPS), yang kemudian dapat diplot pada bagan dan grafik untuk mengidentifikasi masalah, memantau kemajuan, dan meningkatkan loyalitas.
Pengambilan Kunci
- Analisis sentimen adalah alat yang ampuh bagi bisnis untuk memahami masukan, melakukan perbaikan, dan memberikan pengalaman pelanggan.
- Perubahan sentimen dari waktu ke waktu dapat divisualisasikan melalui grafik tren, sehingga membantu organisasi mengambil keputusan berdasarkan data.
Tanya Jawab Umum (FAQ)
Jawab. Analisis sentimen menentukan nada emosional dan konteks data teks menggunakan teknik NLP. Dalam layanan pelanggan, jenis analisis ini membantu organisasi memahami bagaimana perasaan pelanggan tentang produk atau layanan mereka. Hal ini penting karena memberikan wawasan yang dapat ditindaklanjuti mengenai kepuasan pelanggan dan memungkinkan bisnis meningkatkan layanan mereka berdasarkan umpan balik pelanggan. Ini membantu untuk melihat bagaimana karyawan berinteraksi dengan pelanggan.
Jawab. Transkripsi audio adalah proses mengubah kata-kata yang diucapkan dalam audio menjadi teks tertulis. Dalam analisis sentimen, ini adalah hal pertama yang kami lakukan. Kami menggunakan alat seperti AWS Transcribe untuk mengubah perkataan orang dalam panggilan menjadi kata-kata yang dapat dipahami komputer. Setelah itu, kita bisa melihat kata-katanya untuk mengetahui bagaimana perasaan orang.
Jawab. Sentimen biasanya dikategorikan ke dalam empat kategori utama: Positif, Negatif, Netral, dan Campuran. “Positif” menunjukkan sentimen atau kepuasan positif. “Negatif” mencerminkan ketidakpuasan atau sentimen negatif. “Netral” berarti kurangnya sentimen positif dan negatif, dan “Campuran” berarti mencampurkan emosi positif dan negatif dalam teks.
Jawab. NPS adalah angka yang memberi tahu kita seberapa besar orang menyukai suatu perusahaan atau layanan. Kita mencarinya dengan mengambil persentase orang yang menyukainya (positif) dan mengurangkan persentase orang yang tidak menyukainya (negatif). Rumusnya seperti ini: NPS = ((Orang Positif / Total Orang) – (Orang Negatif / Total Orang)) * 100. NPS yang lebih tinggi berarti pelanggan yang lebih bahagia.
Jawab. Grafik tren seperti gambar yang menunjukkan bagaimana perasaan orang berubah seiring waktu. Mereka membantu perusahaan melihat apakah pelanggan menjadi lebih bahagia atau sedih. Perusahaan dapat menggunakan grafik tren untuk menemukan pola dan melihat apakah perbaikannya berhasil. Grafik tren membantu perusahaan membuat pilihan cerdas dan dapat memeriksa perubahannya untuk membuat pelanggan senang.
Media yang ditampilkan dalam artikel ini bukan milik Analytics Vidhya dan digunakan atas kebijaksanaan Penulis.
terkait
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2023/09/decoding-customer-care-sentiments-comprehensive-audio-analysis-guide/
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 11
- 12
- 14
- 5000
- a
- Tentang Kami
- atas
- mengakses
- diakses
- dapat diakses
- dicapai
- mencapai
- tindakan
- menambahkan
- Setelah
- pengumpulan
- Semua
- juga
- Amazon
- Amazon Web Services
- Layanan Web Amazon (AWS)
- an
- analisis
- analisis
- Analisis Vidhya
- menganalisa
- dianalisis
- menganalisis
- dan
- Apa pun
- menarik
- Aplikasi
- ADALAH
- artikel
- AS
- bertanya
- dinilai
- At
- audio
- secara otomatis
- tersedia
- rata-rata
- AWS
- berdasarkan
- BE
- karena
- sebelum
- mulai
- Awal
- di bawah
- Manfaat
- Lebih baik
- Besar
- blogathon
- kedua
- Istirahat
- membangun
- Bangunan
- bisnis
- bisnis
- tapi
- by
- menghitung
- dihitung
- menghitung
- perhitungan
- panggilan
- bernama
- Panggilan
- CAN
- menangkap
- ditangkap
- yang
- kasus
- kategori
- Kategori
- tertentu
- menantang
- perubahan
- Perubahan
- mengubah
- Charts
- memeriksa
- pilihan
- klien
- kode
- datang
- Perusahaan
- perusahaan
- lengkap
- Lengkap
- penyelesaian
- kompleksitas
- memahami
- luas
- komputer
- melakukan
- kepercayaan
- yakin
- isi
- konteks
- percakapan
- mengubah
- mengkonversi
- bisa
- counter
- perhitungan
- menutupi
- membuat
- dibuat
- membuat
- kritis
- sangat penting
- CSS
- pelanggan
- Kepuasan pelanggan
- pelanggan
- menyesuaikan
- data
- ilmu data
- Data-driven
- Basis Data
- Tanggal
- Tanggal
- tanggal Waktu
- transaksi
- keputusan
- decoding
- menetapkan
- menyampaikan
- terperinci
- rincian
- Menentukan
- ditentukan
- MELAKUKAN
- kebijaksanaan
- menampilkan
- membagi
- do
- tidak
- Dont
- turun
- Download
- lamanya
- selama
- e
- setiap
- Terdahulu
- mudah
- Mudah
- lain
- emosi
- emosional
- emosi
- Karyawan
- karyawan
- kosong
- memungkinkan
- akhir
- Inggris
- mempertinggi
- memastikan
- kesalahan
- terutama
- penting
- dll
- Eter (ETH)
- contoh
- Kecuali
- pengecualian
- Pengalaman
- menjelaskan
- penjelasan
- menyelidiki
- mengeksplorasi
- menyatakan
- ekstrak
- Gagal
- serba cepat
- umpan balik
- merasa
- perasaan
- Sudah diambil
- Angka
- File
- terakhir
- Menemukan
- menemukan
- Pertama
- Fokus
- mengikuti
- berikut
- berikut
- Untuk
- bentuk
- format
- rumus
- Prinsip Dasar
- empat
- dari
- mendasar
- Mendapatkan
- mengumpulkan
- menghasilkan
- mendapatkan
- mendapatkan
- diberikan
- memberikan
- Go
- tujuan
- grafik
- besar
- bimbingan
- membimbing
- menangani
- berguna
- lebih bahagia
- senang
- Memiliki
- memiliki
- Hati
- membantu
- membantu
- membantu
- lebih tinggi
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- mengenali
- if
- implementasi
- mengimpor
- penting
- memperbaiki
- perbaikan
- in
- Di lain
- Termasuk
- meningkatkan
- menunjukkan
- sendiri-sendiri
- informasi
- memulai
- input
- wawasan
- sebagai gantinya
- berinteraksi
- berinteraksi
- interaksi
- Antarmuka
- ke
- terlibat
- masalah
- IT
- NYA
- JavaScript
- Pekerjaan
- json
- hanya
- Menjaga
- kunci
- Tahu
- Label
- Kekurangan
- bahasa
- Bahasa
- besar
- Panjang
- perpustakaan
- terletak
- 'like'
- LINK
- lokal
- tempat
- lokasi
- Panjang
- melihat
- TERLIHAT
- Lot
- banyak
- Loyalitas
- Utama
- Mayoritas
- membuat
- mengelola
- dikelola
- banyak
- maksimum
- berarti
- cara
- Media
- tersebut
- metode
- metrik
- Metrik
- mencampur
- campur aduk
- Percampuran
- Memantau
- suasana hati
- lebih
- paling
- banyak
- beberapa
- harus
- nama
- nama
- perlu
- Perlu
- negatif
- negatif
- bersih
- Netral
- berikutnya
- nLP
- tidak
- None
- mencatat
- jumlah
- obyek
- objek
- terjadi
- of
- menawarkan
- on
- sekali
- ONE
- hanya
- Opsi
- or
- organisasi
- pengorganisasian
- OS
- Lainnya
- kami
- di luar
- lebih
- secara keseluruhan
- dimiliki
- halaman
- bagian
- bagian
- path
- pola
- berhenti sebentar
- Konsultan Ahli
- orang
- persentase
- persepsi
- melakukan
- melakukan
- periode
- tahap
- Film
- plato
- Kecerdasan Data Plato
- Data Plato
- memainkan
- positif
- Pos
- kuat
- mempersiapkan
- menyajikan
- Prosedur
- memproses
- proses
- Produk
- Kemajuan
- proyek
- memberikan
- disediakan
- menyediakan
- menyediakan
- diterbitkan
- Ular sanca
- kualitas
- menghitung
- RE
- catatan
- rekaman
- arsip
- mencerminkan
- menghapus
- melaporkan
- mewakili
- mewakili
- permintaan
- permintaan
- wajib
- tanggapan
- mengakibatkan
- Hasil
- kembali
- benar
- peta jalan
- Peran
- kepuasan
- disimpan
- mengatakan
- mengatakan
- Ilmu
- skor
- skor
- Rahasia
- Bagian
- melihat
- terlihat
- terpilih
- sentimen
- perasaan
- terpisah
- terpisah
- layanan
- Layanan
- pengaturan
- pengaturan
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- tunggal
- lebih kecil
- pintar
- beberapa
- sesuatu
- Pembicara
- khusus
- tertentu
- membagi
- lisan
- awal
- mulai
- Mulai
- Status
- Langkah
- Tangga
- menyimpan
- tersimpan
- Belajar
- berhasil
- seperti itu
- yakin
- sistem
- pengambilan
- pembicaraan
- tugas
- tugas
- mengatakan
- teks
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- hal
- ini
- Melalui
- waktu
- kali
- timestamp
- untuk
- hari ini
- NADA
- alat
- alat
- Total
- jalur
- Salinan
- Terjemahan
- kecenderungan
- Tren
- benar
- mencoba
- Putar
- mengetik
- khas
- memahami
- pemahaman
- unik
- upload
- URI
- URL
- us
- menggunakan
- bekas
- berguna
- Pengguna
- User Interface
- user-friendly
- Pengguna
- kegunaan
- menggunakan
- biasanya
- Nilai - Nilai
- variabel
- berbagai
- sangat
- visual
- SUARA
- volume
- menunggu
- ingin
- adalah
- we
- jaringan
- aplikasi web
- layanan web
- webp
- minggu
- mingguan
- adalah
- Apa
- Apa itu
- ketika
- apakah
- yang
- sementara
- SIAPA
- mengapa
- akan
- dengan
- dalam
- kata
- Kerja
- bekerja
- dunia
- tertulis
- kamu
- Anda
- zephyrnet.dll