Pembelajaran tanpa pengawasan adalah cabang pembelajaran mesin di mana model mempelajari pola dari data yang tersedia daripada diberikan dengan label yang sebenarnya. Kami membiarkan algoritme muncul dengan jawabannya.
Dalam pembelajaran tanpa pengawasan, ada dua teknik utama; pengelompokan dan pengurangan dimensi. Teknik clustering menggunakan algoritma untuk mempelajari pola untuk mensegmentasi data. Sebaliknya, teknik reduksi dimensi mencoba mengurangi jumlah fitur dengan mempertahankan informasi aktual sebanyak mungkin.
Contoh algoritma untuk pengelompokan adalah K-Means, dan untuk reduksi dimensi adalah PCA. Ini adalah algoritma yang paling banyak digunakan untuk pembelajaran tanpa pengawasan. Namun, kami jarang berbicara tentang metrik untuk mengevaluasi pembelajaran tanpa pengawasan. Meskipun bermanfaat, kami masih perlu mengevaluasi hasilnya untuk mengetahui apakah keluarannya tepat.
Artikel ini akan membahas metrik yang digunakan untuk mengevaluasi algoritme pembelajaran mesin tanpa pengawasan dan akan dibagi menjadi dua bagian; Metrik algoritme pengelompokan dan metrik reduksi dimensi. Mari kita masuk ke dalamnya.
Kami tidak akan membahas secara rinci tentang algoritma pengelompokan karena itu bukan poin utama dari artikel ini. Sebagai gantinya, kami akan fokus pada contoh metrik yang digunakan untuk evaluasi dan cara menilai hasilnya.
Artikel ini akan menggunakan Kumpulan Data Anggur dari Kaggle sebagai contoh dataset kami. Mari kita baca datanya terlebih dahulu dan gunakan algoritma K-Means untuk mengelompokkan data.
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('wine-clustering.csv') kmeans = KMeans(n_clusters=4, random_state=0)
kmeans.fit(df)Saya memulai cluster sebagai 4, yang berarti kami membagi data menjadi 4 cluster. Apakah jumlah cluster yang tepat? Atau ada nomor cluster yang lebih cocok? Umumnya, kita dapat menggunakan teknik yang disebut metode siku untuk menemukan cluster yang sesuai. Biarkan saya menunjukkan kode di bawah ini.
wcss = []
for k in range(1, 11): kmeans = KMeans(n_clusters=k, random_state=0) kmeans.fit(df) wcss.append(kmeans.inertia_) # Plot the elbow method
plt.plot(range(1, 11), wcss, marker='o')
plt.xlabel('Number of Clusters (k)')
plt.ylabel('WCSS')
plt.title('Elbow Method')
plt.show() 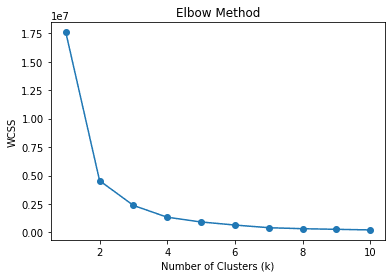
Dalam metode siku, kami menggunakan WCSS atau Within-Cluster Sum of Squares untuk menghitung jumlah jarak kuadrat antara titik data dan masing-masing centroid cluster untuk berbagai k (cluster). Nilai k terbaik diharapkan adalah yang paling banyak menurunkan WCSS atau siku pada gambar di atas, yaitu 2.
Namun, kita dapat memperluas metode siku untuk menggunakan metrik lain untuk menemukan k terbaik. Bagaimana dengan algoritma secara otomatis menemukan nomor cluster tanpa bergantung pada centroid? Ya, kami juga dapat mengevaluasinya menggunakan metrik serupa.
Sebagai catatan, kita dapat mengasumsikan centroid sebagai rata-rata data untuk setiap cluster meskipun kita tidak menggunakan algoritma K-Means. Jadi, algoritme apa pun yang tidak bergantung pada centroid saat mensegmentasi data masih dapat menggunakan evaluasi metrik apa pun yang bergantung pada centroid.
Koefisien Siluet
Silhouette adalah suatu teknik dalam clustering untuk mengukur kesamaan data di dalam cluster dibandingkan dengan cluster lainnya. Koefisien Silhouette adalah representasi numerik yang berkisar dari -1 hingga 1. Nilai 1 berarti setiap klaster benar-benar berbeda dari yang lain, dan nilai -1 berarti semua data ditempatkan pada klaster yang salah. 0 berarti tidak ada cluster yang berarti dari data.
Kita dapat menggunakan kode berikut untuk menghitung koefisien Silhouette.
# Calculate Silhouette Coefficient
from sklearn.metrics import silhouette_score sil_coeff = silhouette_score(df.drop("labels", axis=1), df["labels"])
print("Silhouette Coefficient:", round(sil_coeff, 3))Koefisien Siluet: 0.562
Kita dapat melihat bahwa segmentasi kita di atas memiliki Koefisien Silhouette positif, yang berarti ada tingkat pemisahan antar cluster, meskipun beberapa tumpang tindih masih terjadi.
Indeks Calinski-Harabasz
Calinski-Harabasz Index atau Variance Ratio Criterion adalah indeks yang digunakan untuk mengevaluasi kualitas klaster dengan mengukur rasio dispersi antar klaster terhadap dispersi dalam klaster. Pada dasarnya, kami mengukur perbedaan antara jumlah kuadrat jarak data antara cluster dan data di dalam cluster internal.
Semakin tinggi skor Indeks Calinski-Harabasz, semakin baik, yang berarti cluster terpisah dengan baik. Namun, tidak ada batas atas skor yang berarti bahwa metrik ini lebih baik untuk mengevaluasi angka k yang berbeda daripada menginterpretasikan hasil sebagaimana adanya.
Mari gunakan kode Python untuk menghitung skor Indeks Calinski-Harabasz.
# Calculate Calinski-Harabasz Index
from sklearn.metrics import calinski_harabasz_score ch_index = calinski_harabasz_score(df.drop('labels', axis=1), df['labels'])
print("Calinski-Harabasz Index:", round(ch_index, 3))Indeks Calinski-Harabasz: 708.087
Satu pertimbangan lain untuk skor Indeks Calinski-Harabasz adalah bahwa skor tersebut sensitif terhadap jumlah cluster. Jumlah klaster yang lebih tinggi juga dapat menghasilkan skor yang lebih tinggi. Jadi sebaiknya gunakan metrik lain bersama Indeks Calinski-Harabasz untuk memvalidasi hasilnya.
Indeks Davies-Bouldin
Indeks Davies-Bouldin adalah metrik evaluasi pengelompokan yang diukur dengan menghitung kesamaan rata-rata antara setiap klaster dan yang paling mirip. Rasio jarak dalam-cluster dengan jarak antar-cluster menghitung kesamaan. Ini berarti semakin jauh cluster dan semakin sedikit tersebar akan menghasilkan skor yang lebih baik.
Berbeda dengan metrik kami sebelumnya, Indeks Davies-Bouldin bertujuan untuk mendapatkan skor yang lebih rendah sebanyak mungkin. Semakin rendah skornya, semakin terpisah setiap cluster. Mari gunakan contoh Python untuk menghitung skor.
# Calculate Davies-Bouldin Index
from sklearn.metrics import davies_bouldin_score dbi = davies_bouldin_score(df.drop('labels', axis=1), df['labels'])
print("Davies-Bouldin Index:", round(dbi, 3))Indeks Davies-Bouldin: 0.544
Kita tidak bisa mengatakan skor di atas baik atau buruk karena sama dengan metrik sebelumnya, kita masih perlu mengevaluasi hasilnya dengan menggunakan berbagai metrik sebagai pendukung.
Tidak seperti pengelompokan, pengurangan dimensi bertujuan untuk mengurangi jumlah fitur sambil mempertahankan informasi asli sebanyak mungkin. Karena itu, banyak metrik evaluasi dalam reduksi dimensi semuanya tentang pelestarian informasi. Mari kurangi dimensi dengan PCA dan lihat cara kerja metrik.
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler #Scaled the data
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df) pca = PCA()
pca.fit(df_scaled)Dalam contoh di atas, kami menyesuaikan PCA dengan data, tetapi kami belum mengurangi jumlah fiturnya. Sebagai gantinya, kami ingin mengevaluasi pengurangan dimensi dan trade-off varians dengan Kumulatif Dijelaskan Varians. Ini adalah metrik umum untuk pengurangan dimensi untuk melihat bagaimana informasi tetap ada dengan setiap pengurangan fitur.
#Calculate Cumulative Explained Variance
cev = np.cumsum(pca.explained_variance_ratio_) plt.plot(range(1, len(cev) + 1), cev, marker='o')
plt.xlabel('Number of PC')
plt.ylabel('CEV')
plt.title('CEV vs. Number of PC')
plt.grid() 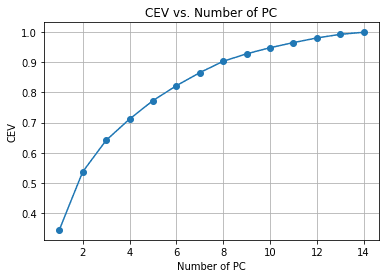
Kita dapat melihat dari grafik di atas jumlah PC yang dipertahankan dibandingkan dengan varians yang dijelaskan. Sebagai patokan, kami sering memilih sekitar 90-95% dipertahankan saat kami mencoba melakukan pengurangan dimensi, jadi sekitar 14 fitur dikurangi menjadi 8 jika kami mengikuti bagan di atas.
Mari kita lihat metrik lain untuk memvalidasi pengurangan dimensi kita.
Kepercayaan
Kepercayaan adalah pengukuran kualitas teknik reduksi dimensi. Metrik ini mengukur seberapa baik dimensi yang diperkecil mempertahankan data asli tetangga terdekat.
Pada dasarnya metrik mencoba melihat seberapa baik teknik reduksi dimensi mempertahankan data dalam mempertahankan struktur lokal data aslinya.
Metrik Keandalan berkisar antara 0 hingga 1, di mana nilai yang mendekati 1 berarti tetangga yang dekat dengan titik data dimensi yang dikurangi sebagian besar juga dekat dengan dimensi aslinya.
Mari gunakan kode Python untuk menghitung metrik Keandalan.
from sklearn.manifold import trustworthiness # Calculate Trustworthiness. Tweak the number of neighbors depends on the dataset size.
tw = trustworthiness(df_scaled, df_pca, n_neighbors=5)
print("Trustworthiness:", round(tw, 3))Dapat dipercaya: 0.87
Pemetaan Sammon
Pemetaan Sammon adalah teknik reduksi dimensi non-linier untuk mempertahankan jarak berpasangan dimensi tinggi saat direduksi. Tujuannya adalah menggunakan fungsi Stres Sammon untuk menghitung jarak berpasangan antara data asli dan ruang reduksi.
Semakin rendah skor fungsi stres Sammon, semakin baik karena menunjukkan preservasi berpasangan yang lebih baik. Mari kita coba gunakan contoh kode Python.
Pertama, kami akan menginstal paket tambahan untuk Pemetaan Sammon.
pip install sammon-mappingKemudian kita akan menggunakan kode berikut untuk menghitung tegangan Sammon.
# Calculate Sammon's Stress
from sammon import sammon pca_res, sammon_st = sammon.sammon(np.array(df)) print("Sammon's Stress:", round(sammon_st, 5))Stres Sammon: 1e-05
Hasilnya menunjukkan Sammon's Score yang rendah yang berarti ada penyimpanan data.
Pembelajaran tanpa pengawasan adalah cabang pembelajaran mesin yang mencoba mempelajari pola dari data. Dibandingkan dengan pembelajaran yang diawasi, evaluasi keluaran mungkin tidak banyak membahas. Pada artikel ini, kami mencoba mempelajari beberapa metrik pembelajaran tanpa pengawasan, termasuk:
- Kuadrat Jumlah Dalam-Kluster
- Koefisien Siluet
- Indeks Calinski-Harabasz
- Indeks Davies-Bouldin
- Kumulatif Dijelaskan Varians
- Kepercayaan
- Pemetaan Sammon
Cornellius Yudha Wijaya adalah asisten manajer ilmu data dan penulis data. Selama bekerja full-time di Allianz Indonesia, ia suka berbagi tips Python dan Data melalui media sosial dan media tulis.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/04/exploring-unsupervised-learning-metrics.html?utm_source=rss&utm_medium=rss&utm_campaign=exploring-unsupervised-learning-metrics
- :adalah
- $NAIK
- 1
- 11
- 7
- 8
- 9
- a
- Tentang Kami
- atas
- Tambahan
- bertujuan
- algoritma
- algoritma
- Semua
- Allianz
- di samping
- Meskipun
- jumlah
- dan
- jawaban
- selain
- sesuai
- ADALAH
- sekitar
- artikel
- AS
- ditugaskan
- Asisten
- At
- secara otomatis
- tersedia
- rata-rata
- Buruk
- Pada dasarnya
- BE
- karena
- makhluk
- di bawah
- TERBAIK
- Lebih baik
- antara
- Cabang
- by
- menghitung
- menghitung
- menghitung
- bernama
- CAN
- Grafik
- Pilih
- Penyelesaian
- lebih dekat
- Kelompok
- kekelompokan
- kode
- bagaimana
- Umum
- umum
- dibandingkan
- sama sekali
- pertimbangan
- kontras
- bisa
- data
- titik data
- ilmu data
- mengurangi
- Derajat
- tergantung
- rinci
- MELAKUKAN
- perbedaan
- berbeda
- Dimensi
- membahas
- tersebar
- Penyebaran
- jarak
- Terbagi
- Dont
- setiap
- Eter (ETH)
- mengevaluasi
- mengevaluasi
- evaluasi
- Bahkan
- contoh
- contoh
- Lihat lebih lanjut
- diharapkan
- menjelaskan
- Menjelajahi
- Fitur
- Fitur
- beberapa
- Menemukan
- temuan
- Pertama
- cocok
- Fokus
- mengikuti
- berikut
- Untuk
- dari
- fungsi
- lebih lanjut
- mendapatkan
- baik
- Terjadi
- Memiliki
- lebih tinggi
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- ide
- mengimpor
- in
- Termasuk
- indeks
- menunjukkan
- Indonesia
- informasi
- memulai
- install
- sebagai gantinya
- intern
- IT
- NYA
- jpg
- KDnugget
- pemeliharaan
- Tahu
- label
- Label
- memimpin
- BELAJAR
- pengetahuan
- batas
- lokal
- melihat
- Rendah
- mesin
- Mesin belajar
- Utama
- membuat
- manajer
- banyak
- pemetaan
- berarti
- cara
- mengukur
- ukur
- Media
- metode
- metrik
- Metrik
- mungkin
- model
- lebih
- paling
- Perlu
- tetangga
- jumlah
- nomor
- tujuan
- of
- on
- ONE
- asli
- Lainnya
- Lainnya
- keluaran
- paket
- panda
- pola
- pola
- PC
- gambar
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- poin
- positif
- mungkin
- perlu
- sebelumnya
- disediakan
- Ular sanca
- kualitas
- mulai
- agak
- perbandingan
- Baca
- menurunkan
- mengurangi
- mengandalkan
- sisa
- perwakilan
- itu
- mengakibatkan
- Aturan
- s
- Ilmu
- skor
- bagian
- ruas
- segmentasi
- peka
- Share
- Menunjukkan
- ditunjukkan
- mirip
- Ukuran
- So
- Sosial
- media sosial
- beberapa
- Space
- Kuadrat
- kotak
- Masih
- tekanan
- struktur
- cocok
- pembelajaran yang diawasi
- mendukung
- Berbicara
- teknik
- bahwa
- Grafik
- Mereka
- Ini
- Tips
- untuk
- kepercayaan
- belajar tanpa pengawasan
- menggunakan
- MENGESAHKAN
- nilai
- Nilai - Nilai
- berbagai
- melalui
- vs
- BAIK
- yang
- sementara
- akan
- dengan
- dalam
- tanpa
- kerja
- bekerja
- akan
- penulis
- penulisan
- Salah
- zephyrnet.dll