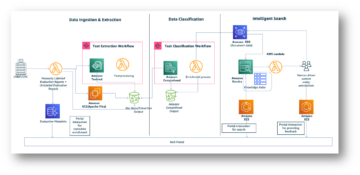
Saat ini, sebagian besar pelanggan kami tertarik dengan model bahasa besar (LLM) dan memikirkan bagaimana AI generatif dapat mengubah bisnis mereka. Namun, menghadirkan solusi dan model seperti itu ke dalam operasional bisnis seperti biasa bukanlah tugas yang mudah. Dalam postingan kali ini, kami membahas cara mengoperasionalkan aplikasi AI generatif menggunakan prinsip MLOps yang mengarah ke operasi model dasar (FMOps). Selain itu, kami mendalami kasus penggunaan AI generatif yang paling umum pada aplikasi teks-ke-teks dan operasi LLM (LLMOps), yang merupakan bagian dari FMOps. Gambar berikut menggambarkan topik yang kami diskusikan.
Secara khusus, kami memperkenalkan secara singkat prinsip-prinsip MLOps dan fokus pada pembeda utama dibandingkan dengan FMOps dan LLMOps terkait proses, orang, pemilihan dan evaluasi model, privasi data, dan penerapan model. Hal ini berlaku bagi pelanggan yang langsung menggunakannya, membuat model fondasi dari awal, atau menyempurnakannya. Pendekatan kami berlaku untuk model sumber terbuka dan kepemilikan secara setara.
Ringkasan operasionalisasi ML
Seperti yang didefinisikan dalam posting Peta jalan dasar MLOps untuk perusahaan dengan Amazon SageMaker, ML dan operasi (MLOps) adalah kombinasi manusia, proses, dan teknologi untuk memproduksi solusi pembelajaran mesin (ML) secara efisien. Untuk mencapai hal ini, kombinasi tim dan persona perlu berkolaborasi, seperti yang diilustrasikan pada gambar berikut.

Tim-tim tersebut adalah sebagai berikut:
- Tim analitik tingkat lanjut (data lake dan data mesh) – Insinyur data bertanggung jawab untuk menyiapkan dan menyerap data dari berbagai sumber, membangun pipeline ETL (ekstrak, transformasi, dan memuat) untuk mengkurasi dan membuat katalog data, serta menyiapkan data historis yang diperlukan untuk kasus penggunaan ML. Pemilik data ini berfokus pada penyediaan akses ke data mereka ke beberapa unit bisnis atau tim.
- Tim ilmu data – Ilmuwan data perlu fokus dalam menciptakan model terbaik berdasarkan indikator kinerja utama (KPI) yang telah ditentukan sebelumnya yang bekerja di notebook. Setelah fase penelitian selesai, data scientist perlu berkolaborasi dengan teknisi ML untuk membuat otomatisasi untuk pembangunan (pipeline ML) dan penerapan model ke dalam produksi menggunakan pipeline CI/CD.
- tim bisnis – Pemilik produk bertanggung jawab untuk menentukan kasus bisnis, persyaratan, dan KPI yang akan digunakan untuk mengevaluasi kinerja model. Konsumen ML adalah pemangku kepentingan bisnis lainnya yang menggunakan hasil inferensi (prediksi) untuk mendorong keputusan.
- Tim platform – Arsitek bertanggung jawab atas keseluruhan arsitektur cloud bisnis dan bagaimana semua layanan berbeda terhubung bersama. UKM Keamanan meninjau arsitektur berdasarkan kebijakan dan kebutuhan keamanan bisnis. Insinyur MLOps bertanggung jawab untuk menyediakan lingkungan yang aman bagi ilmuwan data dan insinyur ML untuk memproduksi kasus penggunaan ML. Secara khusus, mereka bertanggung jawab untuk menstandardisasi pipeline CI/CD, peran pengguna dan layanan serta pembuatan container, konsumsi model, pengujian, dan metodologi penerapan berdasarkan kebutuhan bisnis dan keamanan.
- Tim risiko dan kepatuhan – Untuk lingkungan yang lebih ketat, auditor bertanggung jawab untuk menilai data, kode, dan artefak model serta memastikan bahwa bisnis mematuhi peraturan, seperti privasi data.
Perhatikan bahwa beberapa persona dapat dicakup oleh orang yang sama bergantung pada skala dan kematangan MLOps bisnis.
Persona ini memerlukan lingkungan khusus untuk melakukan proses yang berbeda, seperti yang diilustrasikan dalam gambar berikut.

Lingkungannya adalah sebagai berikut:
- Administrasi platform – Lingkungan administrasi platform adalah tempat di mana tim platform memiliki akses untuk membuat akun AWS dan menghubungkan pengguna dan data yang tepat
- Data – Lapisan data, sering dikenal sebagai data lake atau data mesh, adalah lingkungan yang digunakan oleh para insinyur data atau pemilik dan pemangku kepentingan bisnis untuk mempersiapkan, berinteraksi, dan memvisualisasikan data
- Percobaan – Para ilmuwan data menggunakan sandbox atau lingkungan eksperimen untuk menguji perpustakaan baru dan teknik ML untuk membuktikan bahwa bukti konsep mereka dapat memecahkan masalah bisnis
- Pembuatan model, pengujian model, penerapan model – Lingkungan pembuatan, pengujian, dan penerapan model adalah lapisan MLOps, tempat ilmuwan data dan insinyur ML berkolaborasi untuk mengotomatisasi dan memindahkan penelitian ke produksi
- tata kelola ML – Bagian terakhir dari teka-teki adalah lingkungan tata kelola ML, tempat semua model dan artefak kode disimpan, ditinjau, dan diaudit oleh persona terkait
Diagram berikut mengilustrasikan arsitektur referensi, yang telah dibahas di Peta jalan dasar MLOps untuk perusahaan dengan Amazon SageMaker.

Setiap unit bisnis memiliki rangkaian akun pengembangan (pelatihan dan pembuatan model otomatis), praproduksi (pengujian otomatis), dan produksi (penerapan dan penyajian model) masing-masing untuk memproduksi kasus penggunaan ML, yang mengambil data dari data lake atau data terpusat atau terdesentralisasi. jaring, masing-masing. Semua model yang dihasilkan dan otomatisasi kode disimpan dalam akun perkakas terpusat menggunakan kemampuan registri model. Kode infrastruktur untuk semua akun ini dibuat versinya dalam akun layanan bersama (akun tata kelola analitik lanjutan) yang dapat diabstraksi, dibuat template, dipelihara, dan digunakan kembali oleh tim platform untuk orientasi ke platform MLOps setiap tim baru.
Definisi AI generatif dan perbedaannya dengan MLOps
Dalam ML klasik, kombinasi orang, proses, dan teknologi sebelumnya dapat membantu Anda memproduksi kasus penggunaan ML Anda. Namun, dalam AI generatif, sifat kasus penggunaan memerlukan perluasan kemampuan tersebut atau kemampuan baru. Salah satu gagasan baru tersebut adalah model dasar (FM). Disebut demikian karena dapat digunakan untuk membuat berbagai model AI lainnya, seperti yang diilustrasikan pada gambar berikut.

FM telah dilatih berdasarkan data berukuran terabyte dan memiliki ratusan miliar parameter untuk dapat memprediksi jawaban terbaik berikutnya berdasarkan tiga kategori utama kasus penggunaan AI generatif:
- Teks-ke-teks – FM (LLM) telah dilatih berdasarkan data tidak berlabel (seperti teks bebas) dan mampu memprediksi kata atau rangkaian kata terbaik berikutnya (paragraf atau esai panjang). Kasus penggunaan utama adalah seputar chatbot mirip manusia, ringkasan, atau pembuatan konten lainnya seperti kode pemrograman.
- Teks-ke-gambar – Data berlabel, seperti pasangan , telah digunakan untuk melatih FM, yang mampu memprediksi kombinasi piksel terbaik. Contoh kasus penggunaan adalah pembuatan desain pakaian atau gambar imajiner yang dipersonalisasi.
- Teks-ke-audio atau video – Data berlabel dan tidak berlabel dapat digunakan untuk pelatihan FM. Salah satu contoh utama penggunaan AI generatif adalah komposisi musik.
Untuk memproduksi kasus penggunaan AI generatif tersebut, kita perlu meminjam dan memperluas domain MLOps untuk mencakup hal-hal berikut:
- Operasi FM (FMOps) – Hal ini dapat menghasilkan solusi AI generatif, termasuk jenis kasus penggunaan apa pun
- Operasi LLM (LLMOps) – Ini adalah bagian dari FMOps yang berfokus pada produksi solusi berbasis LLM, seperti teks-ke-teks
Gambar berikut mengilustrasikan kasus penggunaan yang tumpang tindih.

Dibandingkan dengan ML dan MLOps klasik, FMOps dan LLMOps ditangguhkan berdasarkan empat kategori utama yang kami bahas di bagian berikut: orang dan proses, pemilihan dan adaptasi FM, evaluasi dan pemantauan FM, privasi data dan penerapan model, serta kebutuhan teknologi. Kami akan membahas pemantauan dalam posting terpisah.
Perjalanan operasionalisasi per jenis pengguna AI generatif
Untuk menyederhanakan deskripsi proses, kita perlu mengkategorikan tipe pengguna AI generatif utama, seperti yang ditunjukkan pada gambar berikut.

Jenis penggunanya adalah sebagai berikut:
- Penyedia – Pengguna yang membuat FM dari awal dan menyediakannya sebagai produk kepada pengguna lain (fine-tuner dan konsumen). Mereka memiliki keahlian ML dan pemrosesan bahasa alami (NLP) end-to-end yang mendalam serta keterampilan ilmu data, serta tim pelabel dan editor data yang sangat besar.
- Penyempurna – Pengguna yang melatih ulang (menyempurnakan) FM dari penyedia agar sesuai dengan kebutuhan khusus. Mereka mengatur penerapan model sebagai layanan untuk digunakan oleh konsumen. Para pengguna ini memerlukan keahlian ML dan ilmu data end-to-end yang kuat serta pengetahuan tentang penerapan dan inferensi model. Pengetahuan domain yang kuat untuk penyetelan, termasuk rekayasa cepat, juga diperlukan.
- Konsumen – Pengguna yang berinteraksi dengan layanan AI generatif dari penyedia atau penyempurna melalui perintah teks atau antarmuka visual untuk menyelesaikan tindakan yang diinginkan. Tidak diperlukan keahlian ML tetapi, sebagian besar, pengembang aplikasi atau pengguna akhir memiliki pemahaman tentang kemampuan layanan. Hanya rekayasa cepat yang diperlukan untuk hasil yang lebih baik.
Sesuai dengan definisi dan keahlian ML yang dibutuhkan, MLOps sebagian besar dibutuhkan oleh penyedia dan penyempurna, sementara konsumen dapat menggunakan prinsip produksi aplikasi, seperti DevOps dan AppDev untuk membuat aplikasi AI generatif. Selain itu, kami telah mengamati pergerakan di antara tipe pengguna, di mana penyedia layanan mungkin menjadi pihak yang melakukan penyesuaian untuk mendukung kasus penggunaan berdasarkan vertikal tertentu (seperti sektor keuangan) atau konsumen mungkin menjadi pihak yang melakukan penyesuaian untuk mencapai hasil yang lebih akurat. Tapi mari kita amati proses utama per tipe pengguna.
Perjalanan konsumen
Gambar berikut menggambarkan perjalanan konsumen.

Seperti disebutkan sebelumnya, konsumen diharuskan memilih, menguji, dan menggunakan FM, berinteraksi dengannya dengan memberikan masukan tertentu, atau dikenal sebagai meminta. Anjuran, dalam konteks pemrograman komputer dan AI, mengacu pada masukan yang diberikan kepada model atau sistem untuk menghasilkan respons. Ini bisa dalam bentuk teks, perintah, atau pertanyaan, yang digunakan sistem untuk memproses dan menghasilkan keluaran. Keluaran yang dihasilkan oleh FM kemudian dapat dimanfaatkan oleh pengguna akhir, yang juga harus dapat menilai keluaran tersebut untuk meningkatkan respons model di masa depan.
Di luar proses mendasar ini, kami melihat konsumen mengungkapkan keinginan untuk menyempurnakan model dengan memanfaatkan fungsionalitas yang ditawarkan oleh fine-tuner. Ambil contoh, situs web yang menghasilkan gambar. Di sini, pengguna akhir dapat membuat akun pribadi, mengunggah foto pribadi, dan kemudian membuat konten yang terkait dengan gambar tersebut (misalnya, membuat gambar yang menggambarkan pengguna akhir sedang mengendarai sepeda motor yang memegang pedang atau berada di lokasi yang eksotis). Dalam skenario ini, aplikasi AI generatif, yang dirancang oleh konsumen, harus berinteraksi dengan backend fine-tuner melalui API untuk memberikan fungsi ini kepada pengguna akhir.
Namun, sebelum kita mendalaminya, mari kita konsentrasi dulu pada perjalanan pemilihan model, pengujian, penggunaan, interaksi input dan output, serta rating, seperti yang ditunjukkan pada gambar berikut.

Langkah 1. Pahami kemampuan FM terbaik
Ada banyak dimensi yang perlu dipertimbangkan saat memilih model pondasi, bergantung pada kasus penggunaan, data yang tersedia, peraturan, dan sebagainya. Daftar periksa yang baik, meskipun tidak komprehensif, mungkin adalah sebagai berikut:
- FM berpemilik atau sumber terbuka – Model eksklusif sering kali memerlukan biaya finansial, namun biasanya menawarkan kinerja yang lebih baik (dalam hal kualitas teks atau gambar yang dihasilkan), sering kali dikembangkan dan dipelihara oleh tim penyedia model khusus yang memastikan kinerja dan keandalan optimal. Di sisi lain, kami juga melihat penerapan model sumber terbuka yang, selain gratis, juga menawarkan manfaat tambahan karena dapat diakses dan fleksibel (misalnya, setiap model sumber terbuka dapat disesuaikan). Contoh model berpemilik adalah model Claude Anthropic, dan contoh model sumber terbuka berperforma tinggi adalah Falcon-40B, mulai Juli 2023.
- Lisensi komersial – Pertimbangan perizinan sangat penting ketika memutuskan FM. Penting untuk diperhatikan bahwa beberapa model bersifat open-source tetapi tidak dapat digunakan untuk tujuan komersial, karena batasan atau ketentuan lisensi. Perbedaannya bisa jadi tidak kentara: Yang baru dirilis xgen-7b-8k-base model, misalnya, bersifat open source dan dapat digunakan secara komersial (lisensi Apache-2.0), sedangkan instruksi versi model telah disesuaikan xgen-7b-8k-inst hanya dirilis untuk keperluan penelitian saja. Saat memilih FM untuk aplikasi komersial, penting untuk memverifikasi perjanjian lisensi, memahami batasannya, dan memastikan kesesuaiannya dengan tujuan penggunaan proyek.
- parameter – Jumlah parameter, yang terdiri dari bobot dan bias dalam jaringan saraf, merupakan faktor kunci lainnya. Lebih banyak parameter umumnya berarti model yang lebih kompleks dan berpotensi kuat, karena model tersebut dapat menangkap pola dan korelasi yang lebih rumit dalam data. Namun, kelemahannya adalah hal ini membutuhkan lebih banyak sumber daya komputasi dan, oleh karena itu, biaya pengoperasiannya lebih besar. Selain itu, kami melihat tren ke arah model yang lebih kecil, terutama di ruang sumber terbuka (model berkisar antara 7–40 miliar) yang berkinerja baik, terutama ketika disempurnakan.
- Kecepatan – Kecepatan suatu model dipengaruhi oleh ukurannya. Model yang lebih besar cenderung memproses data lebih lambat (latensi lebih tinggi) karena meningkatnya kompleksitas komputasi. Oleh karena itu, sangat penting untuk menyeimbangkan kebutuhan akan model dengan daya prediksi yang tinggi (seringkali model yang lebih besar) dengan persyaratan praktis untuk kecepatan, terutama dalam aplikasi, seperti bot obrolan, yang memerlukan respons real-time atau mendekati real-time.
- Ukuran jendela konteks (jumlah token) – Jendela konteks, yang ditentukan oleh jumlah maksimum token yang dapat dimasukkan atau dikeluarkan per perintah, sangat penting dalam menentukan seberapa banyak konteks yang dapat dipertimbangkan model pada suatu waktu (token secara kasar diterjemahkan menjadi 0.75 kata dalam bahasa Inggris). Model dengan jendela konteks yang lebih besar dapat memahami dan menghasilkan rangkaian teks yang lebih panjang, yang dapat berguna untuk tugas yang melibatkan percakapan atau dokumen yang lebih panjang.
- Kumpulan data pelatihan – Penting juga untuk memahami jenis data apa yang dilatih oleh FM. Beberapa model mungkin dilatih pada beragam kumpulan data teks seperti data internet, skrip pengkodean, instruksi, atau masukan manusia. Orang lain mungkin juga dilatih tentang kumpulan data multimodal, seperti kombinasi data teks dan gambar. Hal ini dapat mempengaruhi kesesuaian model untuk tugas yang berbeda. Selain itu, suatu organisasi mungkin memiliki masalah hak cipta bergantung pada sumber persis tempat model tersebut dilatih—oleh karena itu, kumpulan data pelatihan harus diperiksa dengan cermat.
- Kualitas – Kualitas FM dapat bervariasi berdasarkan jenisnya (proprietary vs. open source), ukuran, dan apa yang dilatih. Kualitas bergantung pada konteks, artinya apa yang dianggap berkualitas tinggi untuk satu aplikasi mungkin tidak dianggap berkualitas tinggi untuk aplikasi lain. Misalnya, model yang dilatih menggunakan data internet mungkin dianggap berkualitas tinggi untuk menghasilkan teks percakapan, namun kurang berkualitas untuk tugas teknis atau khusus.
- Dapat disetel dengan baik – Kemampuan untuk menyempurnakan FM dengan menyesuaikan bobot atau lapisan modelnya dapat menjadi faktor penting. Penyempurnaan memungkinkan model beradaptasi lebih baik dengan konteks spesifik aplikasi, sehingga meningkatkan performa pada tugas spesifik yang ada. Namun, penyesuaian memerlukan sumber daya komputasi tambahan dan keahlian teknis, dan tidak semua model mendukung fitur ini. Model sumber terbuka (secara umum) selalu dapat disesuaikan karena artefak model tersedia untuk diunduh dan pengguna dapat memperluas dan menggunakannya sesuka hati. Model berpemilik terkadang menawarkan opsi penyesuaian.
- Keterampilan pelanggan yang ada – Pemilihan FM juga dapat dipengaruhi oleh keterampilan dan keakraban pelanggan atau tim pengembangan. Jika suatu organisasi tidak memiliki pakar AI/ML di timnya, layanan API mungkin lebih cocok untuk mereka. Selain itu, jika sebuah tim memiliki pengalaman luas dengan FM tertentu, akan lebih efisien jika terus menggunakannya daripada menginvestasikan waktu dan sumber daya untuk belajar dan beradaptasi dengan FM baru.
Berikut ini adalah contoh dua daftar terpilih, satu untuk model berpemilik dan satu lagi untuk model sumber terbuka. Anda dapat menyusun tabel serupa berdasarkan kebutuhan spesifik Anda untuk mendapatkan gambaran singkat tentang opsi yang tersedia. Perhatikan bahwa performa dan parameter model tersebut berubah dengan cepat dan mungkin sudah ketinggalan zaman saat dibaca, sementara kemampuan lainnya mungkin penting bagi pelanggan tertentu, seperti bahasa yang didukung.
Berikut ini adalah contoh FM berpemilik terkemuka yang tersedia di AWS (Juli 2023).

Berikut ini adalah contoh FM sumber terbuka terkenal yang tersedia di AWS (Juli 2023).

Setelah Anda mengumpulkan ikhtisar 10-20 model kandidat potensial, daftar pilihan ini perlu disempurnakan lebih lanjut. Pada bagian ini, kami mengusulkan mekanisme cepat yang akan menghasilkan dua atau tiga model akhir yang layak sebagai kandidat untuk putaran berikutnya.
Diagram berikut mengilustrasikan proses awal pemilihan.

Biasanya, insinyur cepat, yang ahli dalam membuat perintah berkualitas tinggi yang memungkinkan model AI memahami dan memproses masukan pengguna, bereksperimen dengan berbagai metode untuk melakukan tugas yang sama (seperti ringkasan) pada suatu model. Kami menyarankan agar petunjuk ini tidak dibuat dengan cepat, namun diambil secara sistematis dari katalog cepat. Katalog prompt ini adalah lokasi pusat untuk menyimpan perintah untuk menghindari replikasi, mengaktifkan kontrol versi, dan berbagi perintah dalam tim untuk memastikan konsistensi antara penguji prompt yang berbeda dalam tahap pengembangan yang berbeda, yang kami perkenalkan di bagian berikutnya. Katalog prompt ini analog dengan repositori Git dari toko fitur. Pengembang AI generatif, yang berpotensi menjadi orang yang sama dengan insinyur yang cepat, kemudian perlu mengevaluasi keluarannya untuk menentukan apakah keluaran tersebut cocok untuk aplikasi AI generatif yang ingin mereka kembangkan.
Langkah 2. Uji dan evaluasi FM teratas
Setelah daftar terpilih dikurangi menjadi sekitar tiga FM, kami merekomendasikan langkah evaluasi untuk menguji lebih lanjut kemampuan dan kesesuaian FM untuk kasus penggunaan. Tergantung pada ketersediaan dan sifat data evaluasi, kami menyarankan metode yang berbeda, seperti yang diilustrasikan pada gambar berikut.
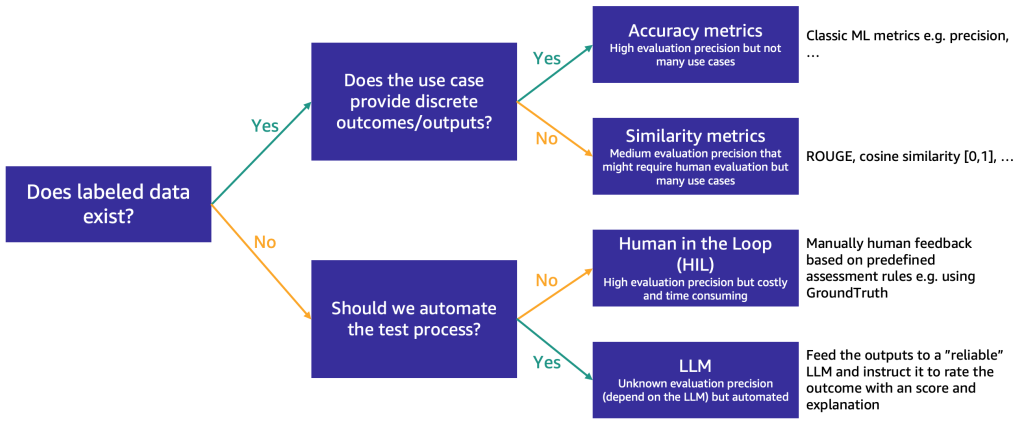
Metode yang digunakan pertama kali bergantung pada apakah Anda telah memberi label pada data pengujian atau belum.
Jika Anda memiliki data yang diberi label, Anda dapat menggunakannya untuk melakukan evaluasi model, seperti yang kita lakukan dengan model ML tradisional (memasukkan beberapa sampel dan membandingkan hasilnya dengan label). Bergantung pada apakah data pengujian memiliki label tersendiri (seperti analisis sentimen positif, negatif, atau netral) atau berupa teks tidak terstruktur (seperti ringkasan), kami mengusulkan metode evaluasi yang berbeda:
- Metrik akurasi – Dalam hal keluaran yang terpisah (seperti analisis sentimen), kita dapat menggunakan metrik akurasi standar seperti presisi, perolehan, dan skor F1
- Metrik kesamaan – Jika keluarannya tidak terstruktur (seperti ringkasan), kami menyarankan metrik kesamaan seperti ROUGE dan kesamaan kosinus
Beberapa kasus penggunaan tidak dapat memiliki satu jawaban yang benar (misalnya, “Buat cerita pendek anak-anak untuk putri saya yang berusia 5 tahun”). Dalam kasus seperti ini, mengevaluasi model menjadi lebih sulit karena Anda tidak memiliki data pengujian yang diberi label. Kami mengusulkan dua pendekatan, bergantung pada pentingnya peninjauan model oleh manusia versus evaluasi otomatis:
- Manusia-dalam-lingkaran (HIL) – Dalam hal ini, tim penguji cepat akan meninjau tanggapan dari suatu model. Bergantung pada seberapa kritis aplikasi tersebut, penguji cepat mungkin meninjau 100% keluaran model atau hanya sampel.
- Evaluasi yang didukung LLM – Dalam skenario ini, penguji cepat digantikan oleh LLM, idealnya yang lebih kuat (walaupun mungkin lebih lambat dan paling mahal) dibandingkan yang diuji. LLM akan meninjau semua respons yang dihasilkan model dan menilainya. Metode ini mungkin menghasilkan kualitas yang lebih rendah, namun merupakan opsi evaluasi yang lebih murah dan lebih cepat yang dapat memberikan ukuran awal yang baik mengenai kinerja model.
Misalnya, kita dapat menggunakan contoh prompt berikut untuk LLM, yang mencakup kueri input, respons LLM, dan instruksi: “Kami ingin meminta masukan Anda mengenai kinerja asisten AI dalam menanggapi pertanyaan pengguna yang ditampilkan di atas . Silakan menilai kegunaan, relevansi, keakuratan, tingkat detail tanggapan asisten. Asisten akan menerima skor keseluruhan pada skala 1 hingga 10, di mana skor yang lebih tinggi menunjukkan kinerja keseluruhan yang lebih baik.”
Prompt ini akan dikirim ke LLM lain (EvalLLM) untuk evaluasi. Berikut ini adalah contoh respon model Falcon-40B yang telah dievaluasi oleh EvalLLM (dalam hal ini Claude). Kami menggunakan pertanyaan “Bagaimana jika Terusan Suez tidak pernah dibangun?” Tanggapannya adalah sebagai berikut:
Pertanyaan: Bagaimana jika Terusan Suez tidak pernah dibangun?
falcon-40b-instruksikan
Jika Terusan Suez tidak pernah dibangun, kapal-kapal harus melakukan perjalanan keliling Afrika untuk bernavigasi antara Mediterania dan Laut Merah. Hal ini akan menambah waktu dan jarak perjalanan secara signifikan, sehingga kurang efisien dan lebih mahal. Selain itu, tanpa Terusan Suez, banyak negara di Timur Tengah dan Afrika Utara akan kehilangan koneksi ke seluruh dunia, sehingga menghambat pembangunan ekonomi dan budaya.
Ulasan (Skor: 9/10)
Tanggapan asisten sangat relevan, akurat, dan terperinci. Ini memberikan jawaban yang sangat baik untuk pertanyaan hipotetis pengguna tentang tidak adanya Terusan Suez. Asisten tersebut dengan tepat menunjukkan implikasinya terhadap perjalanan maritim serta dampak ekonomi dan budaya di Timur Tengah dan Afrika Utara. Namun, laporan ini dapat menguraikan lebih lanjut mengenai implikasi geopolitik atau dampaknya terhadap pola perdagangan global untuk mendapatkan respons yang lebih komprehensif.
Gambar berikut mengilustrasikan contoh proses evaluasi end-to-end.

Berdasarkan contoh ini, untuk melakukan evaluasi, kita perlu menyediakan contoh perintah, yang kita simpan di katalog perintah, dan kumpulan data evaluasi berlabel atau tidak berlabel berdasarkan aplikasi spesifik kita. Misalnya, dengan kumpulan data evaluasi berlabel, kami dapat memberikan perintah (masukan dan kueri) seperti “Beri saya nama lengkap PM Inggris pada tahun 2023” dan keluaran serta jawaban, seperti “Rishi Sunak”. Dengan kumpulan data yang tidak berlabel, kami hanya memberikan pertanyaan atau instruksi, seperti “Buat kode sumber untuk situs web ritel.” Kami menyebut kombinasi katalog cepat dan kumpulan data evaluasi sebagai katalog cepat evaluasi. Alasan kami membedakan katalog cepat dan katalog cepat evaluasi adalah karena katalog cepat didedikasikan untuk kasus penggunaan tertentu, bukan petunjuk dan instruksi umum (seperti menjawab pertanyaan) yang terdapat dalam katalog cepat.
Dengan katalog prompt evaluasi ini, langkah berikutnya adalah memberikan prompt evaluasi kepada FM teratas. Hasilnya adalah kumpulan data hasil evaluasi yang berisi petunjuk, keluaran setiap FM, dan keluaran berlabel beserta skornya (jika ada). Dalam kasus katalog cepat evaluasi yang tidak berlabel, terdapat langkah tambahan bagi HIL atau LLM untuk meninjau hasil dan memberikan skor serta umpan balik (seperti yang kami jelaskan sebelumnya). Hasil akhir akan merupakan hasil agregat yang menggabungkan skor semua keluaran (menghitung presisi rata-rata atau penilaian manusia) dan memungkinkan pengguna untuk mengukur kualitas model.
Setelah hasil evaluasi terkumpul, kami mengusulkan pemilihan model berdasarkan beberapa dimensi. Hal ini biasanya disebabkan oleh faktor-faktor seperti presisi, kecepatan, dan biaya. Gambar berikut menunjukkan sebuah contoh.

Setiap model akan memiliki kekuatan dan trade-off tertentu sepanjang dimensi ini. Bergantung pada kasus penggunaannya, kita harus menetapkan berbagai prioritas pada dimensi ini. Pada contoh sebelumnya, kami memilih untuk memprioritaskan biaya sebagai faktor terpenting, diikuti oleh presisi, dan kemudian kecepatan. Meskipun lebih lambat dan tidak seefisien FM1, namun tetap cukup efektif dan jauh lebih murah untuk dihosting. Akibatnya, kita mungkin memilih FM2 sebagai pilihan utama.
Langkah 3. Kembangkan backend dan frontend aplikasi AI generatif
Pada titik ini, pengembang AI generatif telah memilih FM yang tepat untuk aplikasi spesifik bersama dengan bantuan teknisi dan penguji yang cepat. Langkah selanjutnya adalah mulai mengembangkan aplikasi AI generatif. Kami telah memisahkan pengembangan aplikasi AI generatif menjadi dua lapisan, backend dan front end, seperti yang ditunjukkan pada gambar berikut.

Di bagian belakang, pengembang AI generatif menggabungkan FM yang dipilih ke dalam solusi dan bekerja sama dengan teknisi cepat untuk menciptakan otomatisasi guna mengubah masukan pengguna akhir menjadi perintah FM yang sesuai. Penguji prompt membuat entri yang diperlukan ke katalog prompt untuk pengujian otomatis atau manual (HIL atau LLM). Kemudian, pengembang AI generatif membuat rangkaian cepat dan mekanisme aplikasi untuk memberikan hasil akhir. Rangkaian cepat, dalam konteks ini, adalah teknik untuk menciptakan aplikasi LLM yang lebih dinamis dan sadar konteks. Ia bekerja dengan memecah tugas yang kompleks menjadi serangkaian subtugas yang lebih kecil dan lebih mudah dikelola. Misalnya, jika kita mengajukan pertanyaan kepada LLM, “Di mana perdana menteri Inggris lahir dan seberapa jauh tempat itu dari London,” tugas tersebut dapat dipecah menjadi pertanyaan-pertanyaan individual, yang pertanyaannya dapat dibuat berdasarkan jawabannya. dari evaluasi cepat sebelumnya, seperti “Siapa perdana menteri Inggris”, “Di mana tempat lahir mereka”, dan “Seberapa jauh tempat itu dari London?” Untuk memastikan kualitas masukan dan keluaran tertentu, pengembang AI generatif juga perlu membuat mekanisme untuk memantau dan memfilter masukan pengguna akhir dan keluaran aplikasi. Jika, misalnya, aplikasi LLM diharapkan menghindari permintaan dan tanggapan yang beracun, mereka dapat menerapkan detektor toksisitas untuk input dan output dan memfilternya. Terakhir, mereka perlu menyediakan mekanisme pemeringkatan, yang akan mendukung perluasan katalog evaluasi dengan contoh-contoh yang baik dan buruk. Penjelasan lebih rinci mengenai mekanisme tersebut akan disajikan pada postingan mendatang.
Untuk menyediakan fungsionalitas kepada pengguna akhir AI generatif, diperlukan pengembangan situs web frontend yang berinteraksi dengan backend. Oleh karena itu, persona DevOps dan AppDevs (pengembang aplikasi di cloud) harus mengikuti praktik pengembangan terbaik untuk mengimplementasikan fungsionalitas input/output dan pemeringkatan.
Selain fungsi dasar ini, frontend dan backend perlu menggabungkan fitur pembuatan akun pengguna pribadi, mengunggah data, memulai penyesuaian sebagai kotak hitam, dan menggunakan model yang dipersonalisasi, bukan FM dasar. Produksi aplikasi AI generatif serupa dengan aplikasi normal. Gambar berikut menggambarkan contoh arsitektur.

Dalam arsitektur ini, pengembang AI generatif, insinyur cepat, dan DevOps atau AppDevs membuat dan menguji aplikasi secara manual dengan menerapkannya melalui CI/CD ke lingkungan pengembangan (AI App Dev generatif pada gambar sebelumnya) menggunakan repositori kode khusus dan menggabungkannya dengan cabang pengembang. Pada tahap ini, pengembang AI generatif akan menggunakan FM yang sesuai dengan memanggil API seperti yang telah disediakan oleh penyedia fine-tuner FM. Kemudian, untuk menguji aplikasi secara ekstensif, mereka perlu mempromosikan kode tersebut ke cabang pengujian, yang akan memicu penerapan melalui CI/CD ke lingkungan praproduksi (Pra-produksi Aplikasi AI generatif). Pada lingkungan ini, penguji cepat perlu mencoba sejumlah besar kombinasi cepat dan meninjau hasilnya. Kombinasi petunjuk, keluaran, dan tinjauan perlu dipindahkan ke katalog cepat evaluasi untuk mengotomatiskan proses pengujian di masa mendatang. Setelah pengujian ekstensif ini, langkah terakhir adalah mempromosikan aplikasi AI generatif ke produksi melalui CI/CD dengan menggabungkan dengan cabang utama (generative AI App Prod). Perhatikan bahwa semua data, termasuk katalog cepat, data dan hasil evaluasi, data dan metadata pengguna akhir, serta metadata model yang disempurnakan, perlu disimpan di lapisan data lake atau data mesh. Pipeline dan repositori CI/CD perlu disimpan dalam akun perkakas terpisah (mirip dengan yang dijelaskan untuk MLOps).
Perjalanan penyedia
Penyedia FM perlu melatih FM, seperti model pembelajaran mendalam. Bagi mereka, siklus hidup dan infrastruktur MLOps end-to-end diperlukan. Penambahan diperlukan dalam persiapan data historis, evaluasi model, dan pemantauan. Gambar berikut menggambarkan perjalanan mereka.

Dalam ML klasik, data historis paling sering dibuat dengan memasukkan kebenaran dasar melalui saluran ETL. Misalnya, dalam kasus penggunaan prediksi churn, otomatisasi memperbarui tabel database berdasarkan status baru pelanggan untuk churn/tidak churn secara otomatis. Dalam kasus FM, mereka memerlukan miliaran titik data berlabel atau tidak berlabel. Dalam kasus penggunaan teks-ke-gambar, tim pelabel data perlu memberi label berpasangan secara manual. Ini adalah upaya yang mahal dan membutuhkan sumber daya manusia dalam jumlah besar. Kebenaran Dasar Amazon SageMaker Plus dapat menyediakan tim pemberi label untuk melakukan aktivitas ini untuk Anda. Untuk beberapa kasus penggunaan, proses ini juga dapat diotomatisasi sebagian, misalnya dengan menggunakan model mirip CLIP. Dalam kasus LLM, seperti teks-ke-teks, datanya tidak diberi label. Namun, mereka perlu bersiap dan mengikuti format data historis tak berlabel yang ada. Oleh karena itu, editor data diperlukan untuk melakukan persiapan data yang diperlukan dan memastikan konsistensi.
Setelah data historis disiapkan, langkah selanjutnya adalah pelatihan dan produksi model. Perhatikan bahwa teknik evaluasi yang sama seperti yang kami jelaskan untuk konsumen dapat digunakan.
Perjalanan para fine-tuner
Fine-tuner bertujuan untuk mengadaptasi FM yang ada ke dalam konteks spesifiknya. Misalnya, model FM dapat meringkas teks tujuan umum tetapi tidak dapat membuat laporan keuangan secara akurat atau tidak dapat menghasilkan kode sumber untuk bahasa pemrograman yang tidak umum. Dalam kasus tersebut, penyempurna perlu memberi label pada data, menyempurnakan model dengan menjalankan tugas pelatihan, menerapkan model, mengujinya berdasarkan proses konsumen, dan memantau model. Diagram berikut menggambarkan proses ini.

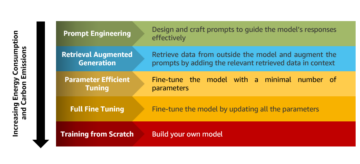
Untuk saat ini, ada dua mekanisme penyesuaian:
- Mencari setelan – Dengan menggunakan FM dan data berlabel, tugas pelatihan menghitung ulang bobot dan bias lapisan model pembelajaran mendalam. Proses ini memerlukan komputasi yang intensif dan memerlukan jumlah data yang representatif, namun dapat menghasilkan hasil yang akurat.
- Penyempurnaan hemat parameter (PEFT) – Daripada menghitung ulang semua bobot dan bias, para peneliti telah menunjukkan bahwa dengan menambahkan lapisan kecil tambahan ke model pembelajaran mendalam, mereka dapat mencapai hasil yang memuaskan (misalnya, LoRA). PEFT memerlukan daya komputasi yang lebih rendah dibandingkan penyempurnaan mendalam dan tugas pelatihan dengan data masukan yang lebih sedikit. Kelemahannya adalah potensi akurasi yang lebih rendah.
Diagram berikut menggambarkan mekanisme ini.

Sekarang kita telah mendefinisikan dua metode penyesuaian utama, langkah selanjutnya adalah menentukan bagaimana kita dapat menerapkan dan menggunakan FM sumber terbuka dan berpemilik.
Dengan FM sumber terbuka, penyetel dapat mengunduh artefak model dan kode sumber dari web, misalnya dengan menggunakan Memeluk Wajah Model Hub. Hal ini memberi Anda fleksibilitas untuk menyempurnakan model secara mendalam, menyimpannya ke registri model lokal, dan menerapkannya ke Amazon SageMaker titik akhir. Proses ini memerlukan koneksi internet. Untuk mendukung lingkungan yang lebih aman (seperti untuk pelanggan di sektor keuangan), Anda dapat mengunduh model di lokasi, menjalankan semua pemeriksaan keamanan yang diperlukan, dan mengunggahnya ke bucket lokal di akun AWS. Kemudian, fine-tuner menggunakan FM dari bucket lokal tanpa koneksi internet. Hal ini memastikan privasi data, dan data tidak menyebar melalui internet. Diagram berikut menggambarkan metode ini.

Dengan FM berpemilik, proses penerapannya berbeda karena fine-tuner tidak memiliki akses ke artefak model atau kode sumber. Model disimpan di akun AWS dan registrasi model milik penyedia FM. Untuk menerapkan model seperti itu ke titik akhir SageMaker, penyetel hanya dapat meminta paket model yang akan diterapkan langsung ke titik akhir. Proses ini memerlukan data pelanggan untuk digunakan di akun milik penyedia FM, sehingga menimbulkan pertanyaan mengenai data sensitif pelanggan yang digunakan di akun jarak jauh untuk melakukan penyesuaian, dan model di-host di registri model yang dibagikan di antara banyak pelanggan. . Hal ini menyebabkan masalah multi-tenancy yang menjadi lebih menantang jika penyedia layanan FM harus melayani model ini. Jika fine-tuner digunakan Batuan Dasar Amazon, tantangan-tantangan ini teratasi—data tidak dikirim melalui internet dan penyedia FM tidak memiliki akses ke data fine-tuner. Tantangan yang sama juga terjadi pada model sumber terbuka jika penyetel ingin menyajikan model dari beberapa pelanggan, seperti contoh yang kami berikan sebelumnya pada situs web tempat ribuan pelanggan akan mengunggah gambar hasil personalisasi. Namun, skenario ini dapat dianggap terkendali karena hanya fine-tuner yang terlibat. Diagram berikut menggambarkan metode ini.

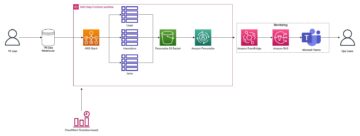
Dari perspektif teknologi, arsitektur yang perlu didukung oleh fine-tuner adalah seperti MLOps (lihat gambar berikut). Penyempurnaan perlu dilakukan di dev dengan membuat pipeline ML, seperti menggunakan Pipa Amazon SageMaker; melakukan prapemrosesan, penyempurnaan (pekerjaan pelatihan), dan pascapemrosesan; dan mengirimkan model yang telah disempurnakan ke registri model lokal jika ada FM sumber terbuka (jika tidak, model baru akan disimpan ke lingkungan penyedia FM berpemilik). Kemudian, dalam praproduksi, kita perlu menguji model seperti yang kami jelaskan untuk skenario konsumen. Terakhir, model akan disajikan dan dipantau di produksi. Perhatikan bahwa FM saat ini (yang telah disesuaikan) memerlukan titik akhir instans GPU. Jika kita perlu menerapkan setiap model yang telah disesuaikan ke titik akhir yang terpisah, hal ini mungkin meningkatkan biaya jika terdapat ratusan model. Oleh karena itu, kita perlu menggunakan titik akhir multi-model dan menyelesaikan tantangan multi-penyewa.

Para fine-tuner mengadaptasi model FM berdasarkan konteks spesifik untuk menggunakannya demi tujuan bisnis mereka. Artinya, seringkali, para penyempurna juga merupakan konsumen yang diperlukan untuk mendukung semua lapisan, seperti yang kami jelaskan di bagian sebelumnya, termasuk pengembangan aplikasi AI generatif, data lake dan data mesh, serta MLOps.
Gambar berikut mengilustrasikan siklus hidup penyempurnaan FM lengkap yang dibutuhkan oleh penyetel halus untuk menyediakan pengguna akhir AI generatif.

Gambar berikut mengilustrasikan langkah-langkah utama.

Langkah-langkah utamanya adalah sebagai berikut:
- Pengguna akhir membuat akun pribadi dan mengunggah data pribadi.
- Data disimpan di data lake dan diproses terlebih dahulu untuk mengikuti format yang diharapkan FM.
- Hal ini memicu penyempurnaan pipeline ML yang menambahkan model ke registri model,
- Dari sana, model diterapkan ke produksi dengan pengujian minimum atau model mendorong pengujian ekstensif dengan HIL dan gerbang persetujuan manual.
- Model yang disempurnakan tersedia untuk pengguna akhir.
Karena infrastruktur ini rumit untuk pelanggan non-perusahaan, AWS merilis Amazon Bedrock untuk meringankan upaya menciptakan arsitektur tersebut dan mendekatkan FM yang telah disesuaikan ke produksi.
Persona FMOps dan LLMOps serta pembeda proses
Berdasarkan perjalanan tipe pengguna sebelumnya (konsumen, produsen, dan fine-tuner), diperlukan persona baru dengan keterampilan khusus, seperti yang diilustrasikan pada gambar berikut.

Persona barunya adalah sebagai berikut:
- Pelabelan dan editor data – Pengguna ini memberi label pada data, seperti memasangkan, atau menyiapkan data tak berlabel, seperti teks bebas, dan memperluas tim analitik tingkat lanjut dan lingkungan data lake.
- Penyempurna – Para pengguna ini memiliki pengetahuan mendalam tentang FM dan tahu cara menyesuaikannya, sehingga memperluas tim ilmu data yang akan fokus pada ML klasik.
- Pengembang AI generatif – Mereka memiliki pengetahuan mendalam dalam memilih FM, merangkai perintah dan aplikasi, serta memfilter input dan output. Mereka termasuk dalam tim baru—tim aplikasi AI generatif.
- Insinyur yang cepat – Pengguna ini merancang perintah masukan dan keluaran untuk menyesuaikan solusi dengan konteks dan menguji serta membuat versi awal katalog cepat. Tim mereka adalah tim aplikasi AI generatif.
- Penguji yang cepat – Mereka menguji solusi AI generatif (backend dan frontend) dalam skala besar dan memberikan hasilnya untuk menambah katalog cepat dan kumpulan data evaluasi. Tim mereka adalah tim aplikasi AI generatif.
- AppDev dan DevOps – Mereka mengembangkan bagian depan (seperti situs web) dari aplikasi AI generatif. Tim mereka adalah tim aplikasi AI generatif.
- Pengguna akhir AI generatif – Pengguna ini menggunakan aplikasi AI generatif sebagai kotak hitam, berbagi data, dan menilai kualitas keluaran.
Versi peta proses MLOps yang diperluas untuk menggabungkan AI generatif dapat diilustrasikan dengan gambar berikut.

Lapisan aplikasi baru adalah lingkungan tempat pengembang AI generatif, insinyur cepat, dan penguji, serta AppDevs menciptakan backend dan front end aplikasi AI generatif. Pengguna akhir AI generatif berinteraksi dengan front end aplikasi AI generatif melalui internet (seperti UI web). Di sisi lain, pelabel dan editor data perlu memproses data terlebih dahulu tanpa mengakses bagian belakang data lake atau data mesh. Oleh karena itu, UI web (situs web) dengan editor diperlukan untuk berinteraksi secara aman dengan data. SageMaker Ground Truth menyediakan fungsi ini secara langsung.
Kesimpulan
MLOps dapat membantu kami memproduksi model ML secara efisien. Namun, untuk mengoperasionalkan aplikasi AI generatif, Anda memerlukan keterampilan, proses, dan teknologi tambahan, yang mengarah pada FMOps dan LLMOps. Dalam postingan ini, kami mendefinisikan konsep utama FMOps dan LLMOps serta menjelaskan pembeda utama dibandingkan dengan kemampuan MLOps dalam hal orang, proses, teknologi, pemilihan model FM, dan evaluasi. Selanjutnya, kami mengilustrasikan proses pemikiran pengembang AI generatif dan siklus hidup pengembangan aplikasi AI generatif.
Di masa depan, kami akan fokus pada penyediaan solusi per domain yang kami diskusikan, dan akan memberikan rincian lebih lanjut tentang cara mengintegrasikan pemantauan FM (seperti toksisitas, bias, dan halusinasi) dan pola arsitektur sumber data pihak ketiga atau swasta, seperti Retrieval Augmented Generation (RAG), menjadi FMOps/LLMOps.
Untuk mempelajari lebih lanjut, lihat Peta jalan dasar MLOps untuk perusahaan dengan Amazon SageMaker dan mencoba solusi end-to-end di Menerapkan praktik MLOps dengan model pra-terlatih Amazon SageMaker JumpStart.
Jika Anda memiliki komentar atau pertanyaan, silakan tinggalkan di bagian komentar.
Tentang Penulis
 Sokratis Kartakis adalah Arsitek Solusi Spesialis Pembelajaran Mesin dan Operasi Senior untuk Amazon Web Services. Sokratis berfokus untuk memungkinkan pelanggan perusahaan melakukan industrialisasi solusi Machine Learning (ML) mereka dengan memanfaatkan layanan AWS dan membentuk model operasi mereka, yaitu fondasi MLOps, dan peta jalan transformasi yang memanfaatkan praktik pengembangan terbaik. Dia telah menghabiskan lebih dari 15 tahun dalam menciptakan, merancang, memimpin, dan menerapkan solusi ML dan Internet of Things (IoT) tingkat produksi end-to-end yang inovatif dalam domain energi, ritel, kesehatan, keuangan/perbankan, olahraga motor, dll. Sokratis suka menghabiskan waktu luangnya bersama keluarga dan teman, atau mengendarai sepeda motor.
Sokratis Kartakis adalah Arsitek Solusi Spesialis Pembelajaran Mesin dan Operasi Senior untuk Amazon Web Services. Sokratis berfokus untuk memungkinkan pelanggan perusahaan melakukan industrialisasi solusi Machine Learning (ML) mereka dengan memanfaatkan layanan AWS dan membentuk model operasi mereka, yaitu fondasi MLOps, dan peta jalan transformasi yang memanfaatkan praktik pengembangan terbaik. Dia telah menghabiskan lebih dari 15 tahun dalam menciptakan, merancang, memimpin, dan menerapkan solusi ML dan Internet of Things (IoT) tingkat produksi end-to-end yang inovatif dalam domain energi, ritel, kesehatan, keuangan/perbankan, olahraga motor, dll. Sokratis suka menghabiskan waktu luangnya bersama keluarga dan teman, atau mengendarai sepeda motor.
 Heiko Hotzo adalah Arsitek Solusi Senior untuk AI & Pembelajaran Mesin dengan fokus khusus pada pemrosesan bahasa alami, model bahasa besar, dan AI generatif. Sebelumnya, beliau menjabat sebagai Kepala Ilmu Data untuk Layanan Pelanggan UE Amazon. Heiko membantu pelanggan kami meraih kesuksesan dalam perjalanan AI/ML mereka di AWS dan telah bekerja dengan organisasi di banyak industri, termasuk asuransi, layanan keuangan, media dan hiburan, layanan kesehatan, utilitas, dan manufaktur. Di waktu luangnya, Heiko sering bepergian.
Heiko Hotzo adalah Arsitek Solusi Senior untuk AI & Pembelajaran Mesin dengan fokus khusus pada pemrosesan bahasa alami, model bahasa besar, dan AI generatif. Sebelumnya, beliau menjabat sebagai Kepala Ilmu Data untuk Layanan Pelanggan UE Amazon. Heiko membantu pelanggan kami meraih kesuksesan dalam perjalanan AI/ML mereka di AWS dan telah bekerja dengan organisasi di banyak industri, termasuk asuransi, layanan keuangan, media dan hiburan, layanan kesehatan, utilitas, dan manufaktur. Di waktu luangnya, Heiko sering bepergian.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Otomotif / EV, Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- ChartPrime. Tingkatkan Game Trading Anda dengan ChartPrime. Akses Di Sini.
- BlockOffset. Modernisasi Kepemilikan Offset Lingkungan. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/fmops-llmops-operationalize-generative-ai-and-differences-with-mlops/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 2023
- 23
- 75
- a
- kemampuan
- Sanggup
- Tentang Kami
- atas
- ABSTRAK
- mengakses
- dapat diakses
- mengakses
- Akun
- Akun
- ketepatan
- tepat
- akurat
- Mencapai
- tindakan
- kegiatan
- menyesuaikan
- adaptasi
- menambahkan
- menambahkan
- tambahan
- Tambahan
- keuntungan tambahan
- Selain itu
- tambahan
- Menambahkan
- administrasi
- Adopsi
- maju
- Afrika
- Setelah
- Persetujuan
- AI
- AI & Pembelajaran Mesin
- Asisten AI
- Model AI
- Layanan AI
- saya menggunakan kasus
- AI / ML
- tujuan
- Rata
- Semua
- mengizinkan
- memungkinkan
- sepanjang
- sudah
- juga
- Meskipun
- selalu
- Amazon
- Amazon SageMaker
- Mulai Lompatan Amazon SageMaker
- Amazon Web Services
- antara
- jumlah
- an
- analisis
- analisis
- dan
- dan infrastruktur
- Lain
- menjawab
- jawaban
- Apa pun
- api
- Lebah
- aplikasi
- Aplikasi
- Pengembangan Aplikasi
- aplikasi
- Mendaftar
- pendekatan
- pendekatan
- sesuai
- persetujuan
- sekitar
- arsitek
- arsitektur
- arsitektur
- ADALAH
- sekitar
- AS
- Menilai
- Asisten
- At
- diaudit
- auditor
- ditambah
- mengotomatisasikan
- Otomatis
- secara otomatis
- secara otomatis
- Otomatisasi
- tersedianya
- tersedia
- rata-rata
- menghindari
- AWS
- Backend
- Buruk
- Saldo
- berdasarkan
- dasar
- BE
- karena
- menjadi
- menjadi
- menjadi
- sebelum
- makhluk
- patokan
- Manfaat
- TERBAIK
- Lebih baik
- antara
- prasangka
- bias
- Milyar
- miliaran
- Black
- lahir
- meminjam
- kedua
- bot
- Kotak
- kotak
- Cabang
- Melanggar
- secara singkat
- Membawa
- Rusak
- membangun
- Bangunan
- dibangun di
- bisnis
- tapi
- by
- menghitung
- panggilan
- bernama
- panggilan
- CAN
- calon
- calon
- kemampuan
- kemampuan
- menangkap
- kasus
- kasus
- katalog
- kategori
- pusat
- terpusat
- tertentu
- menantang
- tantangan
- menantang
- perubahan
- chatbots
- murah
- Cek
- pilihan
- memilih
- klasik
- rapat
- lebih dekat
- Pakaian
- awan
- kode
- Pengkodean
- Berkolaborasi
- kombinasi
- kombinasi
- menggabungkan
- bagaimana
- komentar
- komersial
- secara komersial
- Umum
- membandingkan
- dibandingkan
- lengkap
- penyelesaian
- kompleks
- kompleksitas
- pemenuhan
- compliant
- komposisi
- luas
- kekuatan komputasi
- komputer
- memusatkan
- konsep
- konsep
- Kekhawatiran
- Kondisi
- Mengadakan
- dilakukan
- terhubung
- koneksi
- Karena itu
- Mempertimbangkan
- pertimbangan
- dianggap
- memakan
- konsumen
- Konsumen
- konsumsi
- Wadah
- mengandung
- Konten
- pembuatan konten
- konteks
- terus
- kontrol
- percakapan
- percakapan
- hak cipta
- benar
- korelasi
- Sesuai
- Biaya
- mahal
- Biaya
- bisa
- negara
- menutupi
- tercakup
- membuat
- dibuat
- menciptakan
- membuat
- penciptaan
- kritis
- sangat penting
- kultural
- terbaru
- adat
- pelanggan
- data pelanggan
- Layanan Pelanggan
- pelanggan
- data
- Danau Data
- titik data
- Persiapan data
- privasi data
- ilmu data
- Basis Data
- kumpulan data
- Terdesentralisasi
- Memutuskan
- keputusan
- dedicated
- mendalam
- menyelam dalam
- belajar mendalam
- didefinisikan
- mendefinisikan
- definisi
- definisi
- menyampaikan
- menggali
- Permintaan
- Tergantung
- tergantung
- menggambarkan
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- menggambarkan
- dijelaskan
- deskripsi
- Mendesain
- dirancang
- merancang
- keinginan
- diinginkan
- terperinci
- rincian
- Menentukan
- menentukan
- dev
- mengembangkan
- dikembangkan
- Pengembang
- pengembang
- berkembang
- Pengembangan
- tim pengembangan
- DevOps
- perbedaan
- berbeda
- membedakan
- ukuran
- langsung
- membahas
- dibahas
- ditampilkan
- jarak
- menyelam
- beberapa
- do
- dokumen
- Tidak
- domain
- domain
- Dont
- turun
- Download
- mendorong
- dua
- dinamis
- e
- setiap
- Terdahulu
- Timur
- Mudah
- Ekonomis
- editor
- Efektif
- efisien
- efisien
- usaha
- antara
- diuraikan
- terpilih
- aktif
- memungkinkan
- akhir
- ujung ke ujung
- Titik akhir
- endpoint
- energi
- insinyur
- Teknik
- Insinyur
- Inggris
- mempertinggi
- memastikan
- Memastikan
- Enterprise
- pelanggan perusahaan
- perusahaan
- Menghibur
- Lingkungan Hidup
- lingkungan
- sama
- terutama
- penting
- dll
- Eter (ETH)
- EU
- mengevaluasi
- dievaluasi
- evaluasi
- Bahkan
- Setiap
- contoh
- contoh
- unggul
- gembira
- Latihan
- ada
- ada
- Eksotik
- mengharapkan
- mahal
- pengalaman
- eksperimen
- keahlian
- ahli
- mengeksploitasi
- mengekspresikan
- memperpanjang
- memperpanjang
- perpanjangan
- luas
- Pengalaman yang luas
- secara ekstensif
- ekstrak
- f1
- Menghadapi
- faktor
- faktor
- Keakraban
- keluarga
- jauh
- lebih cepat
- Fitur
- umpan balik
- pemberian makanan
- Angka
- menyaring
- penyaringan
- terakhir
- Akhirnya
- keuangan
- laporan keuangan
- Sektor keuangan
- jasa keuangan
- Pertama
- cocok
- keluwesan
- fleksibel
- Fokus
- terfokus
- berfokus
- berfokus
- mengikuti
- diikuti
- berikut
- berikut
- Untuk
- Untuk Konsumen
- bentuk
- format
- Prinsip Dasar
- empat
- Gratis
- teman
- dari
- depan
- Ujung depan
- Frontend
- penuh
- fungsi
- mendasar
- lebih lanjut
- Selanjutnya
- masa depan
- Gates
- mengukur
- memberikan
- Umum
- tujuan umum
- umumnya
- menghasilkan
- dihasilkan
- menghasilkan
- menghasilkan
- generasi
- generatif
- AI generatif
- geopolitik
- mendapatkan
- pergi
- diberikan
- memberikan
- Aksi
- perdagangan global
- baik
- pemerintahan
- GPU
- Tanah
- memiliki
- tangan
- Memanfaatkan
- Memiliki
- memiliki
- he
- kepala
- Kesehatan
- kesehatan
- membantu
- membantu
- di sini
- High
- berkualitas tinggi
- lebih tinggi
- sangat
- -nya
- historis
- memegang
- tuan rumah
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- HTTPS
- manusia
- Ratusan
- i
- idealnya
- if
- menggambarkan
- gambar
- gambar
- imajiner
- Dampak
- melaksanakan
- mengimplementasikan
- implikasi
- pentingnya
- penting
- meningkatkan
- in
- memasukkan
- termasuk
- Termasuk
- menggabungkan
- Meningkatkan
- Pada meningkat
- menunjukkan
- indikator
- sendiri-sendiri
- industri
- mempengaruhi
- terpengaruh
- Infrastruktur
- mulanya
- memulai
- inovatif
- memasukkan
- input
- contoh
- sebagai gantinya
- instruksi
- asuransi
- mengintegrasikan
- dimaksudkan
- berinteraksi
- berinteraksi
- interaksi
- interaktif
- Antarmuka
- Internet
- koneksi internet
- internet hal-hal
- ke
- memperkenalkan
- investasi
- terlibat
- melibatkan
- idiot
- IT
- NYA
- Pekerjaan
- perjalanan
- Perjalanan
- Juli
- hanya
- kunci
- faktor utama
- Jenis
- Tahu
- pengetahuan
- dikenal
- label
- Label
- danau
- bahasa
- besar
- lebih besar
- Terakhir
- Latensi
- lapisan
- lapisan
- terkemuka
- Memimpin
- BELAJAR
- pengetahuan
- Meninggalkan
- LEND
- kurang
- Tingkat
- leveraging
- perpustakaan
- Lisensi
- Perizinan
- siklus hidup
- 'like'
- 'like
- keterbatasan
- LINK
- memuat
- lokal
- terletak
- tempat
- London
- Panjang
- lagi
- menurunkan
- mesin
- Mesin belajar
- terbuat
- Utama
- memelihara
- Mayoritas
- Membuat
- dikelola
- wajib
- panduan
- manual
- pabrik
- banyak
- peta
- Maritim
- besar-besaran
- kematangan
- maksimum
- Mungkin..
- me
- makna
- cara
- mekanisme
- mekanisme
- Media
- Laut Tengah
- tersebut
- penggabungan
- jala
- Metadata
- metode
- Metodologi
- metode
- Metrik
- Tengah
- Timur Tengah
- mungkin
- minimum
- menteri
- ML
- teknik ML
- MLOps
- model
- model
- Memantau
- dipantau
- pemantauan
- lebih
- lebih efisien
- paling
- kebanyakan
- Motorsports
- pindah
- terharu
- gerakan
- banyak
- beberapa
- musik
- harus
- my
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Alam
- Arahkan
- perlu
- Perlu
- dibutuhkan
- kebutuhan
- negatif
- jaringan
- saraf
- saraf jaringan
- Netral
- tak pernah
- New
- baru saja
- berikutnya
- nLP
- tidak
- normal
- utara
- penting
- mencatat
- laptop
- jumlah
- mengamati
- diamati
- of
- menawarkan
- ditawarkan
- sering
- on
- Onboarding
- ONE
- yang
- hanya
- Buka
- open source
- operasi
- Operasi
- optimal
- pilihan
- Opsi
- or
- organisasi
- organisasi
- Lainnya
- Lainnya
- jika tidak
- kami
- di luar
- Hasil
- keluaran
- lebih
- secara keseluruhan
- ikhtisar
- sendiri
- pemilik
- pemilik
- paket
- pasang
- parameter
- pola
- Konsultan Ahli
- untuk
- melakukan
- prestasi
- melakukan
- mungkin
- orang
- pribadi
- Personalized
- perspektif
- tahap
- Foto
- bagian
- pipa saluran
- Tempat
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- Titik
- poin
- Kebijakan
- positif
- memiliki
- mungkin
- Pos
- Posts
- potensi
- berpotensi
- kekuasaan
- kuat
- Praktis
- praktek
- Ketelitian
- meramalkan
- ramalan
- Prediksi
- prediktif
- persiapan
- Mempersiapkan
- siap
- mempersiapkan
- disajikan
- sebelumnya
- sebelumnya
- Perdana
- perdana menteri
- prinsip-prinsip
- Sebelumnya
- Prioritaskan
- pribadi
- swasta
- Masalah
- proses
- proses
- pengolahan
- Diproduksi
- produsen
- Produk
- Produksi
- Pemrograman
- proyek
- mendorong
- bukti
- bukti konsep
- mengusulkan
- hak milik
- Rasakan itu
- memberikan
- disediakan
- pemberi
- penyedia
- menyediakan
- menyediakan
- tujuan
- tujuan
- mendorong
- teka-teki
- kualitas
- pertanyaan
- Pertanyaan
- Cepat
- meningkatkan
- jarak
- mulai
- cepat
- Penilaian
- agak
- penilaian
- Bacaan
- real-time
- alasan
- menerima
- sarankan
- Merah
- mengurangi
- referensi
- memperhalus
- mengenai
- pendaftar
- pendaftaran
- peraturan
- terkait
- dirilis
- relevansi
- relevan
- keandalan
- sisa
- terpencil
- diganti
- melaporkan
- gudang
- perwakilan
- wakil
- permintaan
- permintaan
- wajib
- Persyaratan
- membutuhkan
- penelitian
- peneliti
- Sumber
- tanggapan
- tanggapan
- tanggung jawab
- ISTIRAHAT
- pembatasan
- Bersifat membatasi
- mengakibatkan
- Hasil
- eceran
- menggunakan kembali
- ulasan
- review jurnal
- naik
- benar
- peta jalan
- Peran
- peran
- kira-kira
- bulat
- Run
- berjalan
- pembuat bijak
- sama
- bak pasir
- Skala
- skala
- skenario
- skenario
- Ilmu
- ilmuwan
- skor
- skor
- menggaruk
- script
- SEA
- Bagian
- bagian
- sektor
- aman
- aman
- keamanan
- kebijakan keamanan
- melihat
- pencarian
- terpilih
- memilih
- seleksi
- mengirim
- senior
- mengirim
- sentimen
- terpisah
- Urutan
- Seri
- melayani
- layanan
- Layanan
- porsi
- set
- beberapa
- membentuk
- Share
- berbagi
- kapal
- Pendek
- harus
- ditunjukkan
- Pertunjukkan
- sisi
- penting
- signifikan
- mirip
- menyederhanakan
- Ukuran
- keterampilan
- kecil
- lebih kecil
- UKM
- So
- larutan
- Solusi
- MEMECAHKAN
- beberapa
- sumber
- kode sumber
- sumber
- Space
- khusus
- spesialis
- khusus
- tertentu
- Secara khusus
- kecepatan
- menghabiskan
- menghabiskan
- Tahap
- magang
- stakeholder
- standar
- standardisasi
- awal
- Status
- Langkah
- Tangga
- menyimpan
- tersimpan
- Cerita
- kekuatan
- kuat
- Kemudian
- sukses
- seperti itu
- menyarankan
- kesesuaian
- cocok
- meringkaskan
- RINGKASAN
- mendukung
- Didukung
- Seharusnya
- yakin
- SWIFT
- sistem
- tabel
- Mengambil
- tugas
- tugas
- tim
- tim
- Teknis
- teknik
- Teknologi
- Teknologi
- istilah
- uji
- diuji
- penguji
- pengujian
- dari
- bahwa
- Grafik
- Masa depan
- Sumber
- Inggris
- Dunia
- mereka
- Mereka
- diri
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- hal
- Pikir
- pihak ketiga
- ini
- itu
- meskipun?
- pikir
- ribuan
- tiga
- waktu
- untuk
- bersama
- token
- Token
- puncak
- Topik
- terhadap
- perdagangan
- tradisional
- Pelatihan VE
- terlatih
- Pelatihan
- Mengubah
- Transformasi
- perjalanan
- perjalanan
- kecenderungan
- memicu
- benar
- kebenaran
- mencoba
- dua
- mengetik
- jenis
- khas
- ui
- Uk
- memahami
- pemahaman
- satuan
- unit
- Pembaruan
- Mengunggah
- us
- dapat digunakan
- penggunaan
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- kegunaan
- menggunakan
- keperluan
- dimanfaatkan
- berbagai
- memeriksa
- versi
- kontrol versi
- Lawan
- vertikal
- melalui
- giat
- membayangkan
- Perjalanan
- vs
- ingin
- adalah
- we
- jaringan
- layanan web
- Situs Web
- BAIK
- Apa
- Apa itu
- ketika
- sedangkan
- apakah
- yang
- sementara
- SIAPA
- lebar
- Rentang luas
- akan
- jendela
- Windows
- dengan
- dalam
- tanpa
- Word
- kata
- Kerja
- bekerja sama
- bekerja
- kerja
- bekerja
- dunia
- akan
- tahun
- Menghasilkan
- kamu
- Anda
- zephyrnet.dll