Pergeseran Merah Amazon adalah gudang data yang cepat, dapat diskalakan, aman, dan terkelola sepenuhnya yang memungkinkan Anda menganalisis semua data menggunakan SQL standar dengan mudah dan hemat biaya. Amazon Pergeseran Merah Berbagi Data memungkinkan pelanggan untuk berbagi data langsung yang konsisten secara transaksional dengan aman di satu klaster Amazon Redshift dengan klaster Amazon Redshift lainnya di seluruh akun dan wilayah tanpa perlu menyalin atau memindahkan data dari satu klaster ke klaster lainnya.
Berbagi Data Amazon Redshift pertama kali diluncurkan pada Maret 2021, dan menambahkan dukungan untuk berbagi data lintas akun telah ditambahkan Agustus 2021. Dukungan lintas wilayah menjadi tersedia secara umum di Februari 2022. Ini memberikan fleksibilitas dan kelincahan penuh untuk berbagi data di seluruh klaster Redshift di akun AWS yang sama, akun berbeda, atau wilayah berbeda.
Amazon Redshift Data Sharing digunakan untuk mendefinisikan ulang secara mendasar arsitektur penerapan Amazon Redshift menjadi model hub-spoke, data mesh untuk memenuhi SLA kinerja dengan lebih baik, menyediakan isolasi beban kerja, melakukan analitik lintas-grup, dengan mudah melakukan onboarding kasus penggunaan baru, dan yang paling penting melakukan semua ini tanpa kerumitan pemindahan data dan penyalinan data. Beberapa pertanyaan paling umum yang diajukan selama penerapan berbagi data adalah, "Seberapa besar klaster konsumen dan klaster produsen saya?", dan "Bagaimana cara mendapatkan performa harga terbaik untuk isolasi beban kerja?". Karena karakteristik beban kerja seperti ukuran data, tingkat penyerapan, pola kueri, dan aktivitas pemeliharaan dapat memengaruhi kinerja berbagi data, strategi berkelanjutan untuk mengukur klaster konsumen dan produsen untuk memaksimalkan kinerja dan meminimalkan biaya harus diterapkan. Dalam postingan ini, kami memberikan pendekatan langkah demi langkah untuk membantu Anda menentukan ukuran klaster produsen dan konsumen untuk performa harga terbaik berdasarkan beban kerja khusus Anda.
Panduan ukuran konsumen umum
Langkah-langkah berikut menunjukkan strategi umum untuk mengukur klaster produsen dan konsumen Anda. Anda dapat menggunakannya sebagai titik awal dan memodifikasinya untuk memenuhi skenario kasus penggunaan khusus Anda.
Ukur cluster produser Anda
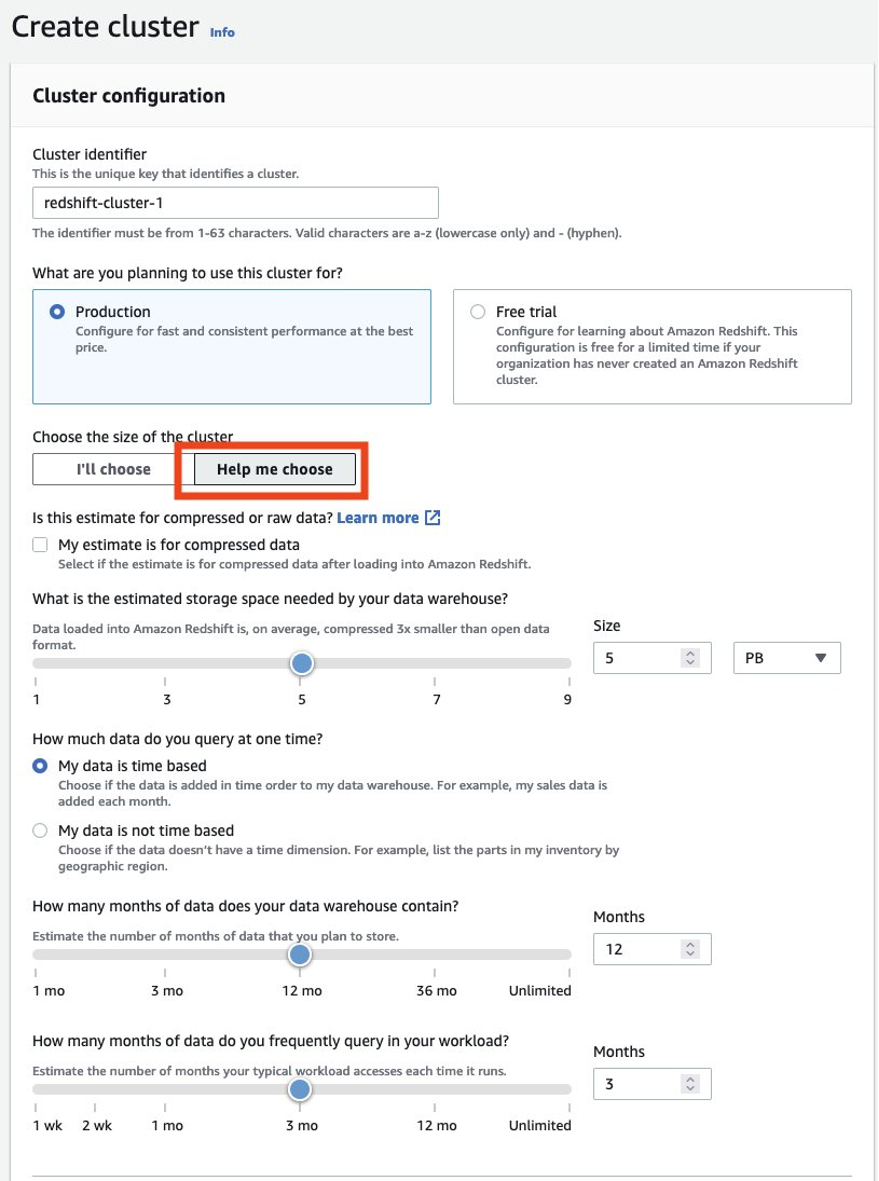
Anda harus selalu memastikan bahwa Anda mengukur klaster produser dengan benar untuk mendapatkan kinerja yang Anda perlukan untuk memenuhi SLA Anda. Anda dapat memanfaatkan kalkulator ukuran dari konsol Amazon Redshift untuk mendapatkan rekomendasi klaster produsen berdasarkan ukuran data dan karakteristik kueri Anda. Mencari Bantu saya memilih di konsol di Wilayah AWS yang mendukung tipe node RA3 untuk menggunakan kalkulator ukuran ini. Perhatikan bahwa ini hanyalah rekomendasi awal untuk memulai, dan Anda harus menguji menjalankan beban kerja penuh Anda pada klaster ukuran awal dan mengubah ukuran klaster secara elastis ke atas dan ke bawah sesuai untuk mendapatkan performa harga terbaik.
Ukuran dan penyiapan klaster konsumen awal
Anda harus selalu mengukur klaster konsumen berdasarkan kebutuhan komputasi Anda. Salah satu cara untuk memulai adalah dengan mengikuti panduan ukuran klaster umum yang mirip dengan klaster produsen di atas.
Atur pembagian data Amazon Redshift
Siapkan pembagian data dari produsen ke konsumen setelah Anda memiliki penyiapan klaster produsen dan konsumen. Lihat ini pos untuk panduan tentang cara menyiapkan berbagi data.
Uji beban kerja khusus konsumen pada kluster konsumen awal
Uji beban kerja khusus konsumen pada klaster konsumen awal yang baru. Hal ini dapat dilakukan dengan mengarahkan aplikasi konsumen, misalnya alat ETL, aplikasi BI, dan klien SQL, ke klaster konsumen baru dan menjalankan kembali beban kerja untuk mengevaluasi performa terhadap kebutuhan Anda.
Uji beban kerja konsumen saja pada konfigurasi cluster konsumen yang berbeda
Jika klaster konsumen ukuran awal memenuhi atau melebihi persyaratan kinerja beban kerja Anda, Anda dapat terus menggunakan konfigurasi klaster ini atau Anda dapat menguji pada konfigurasi yang lebih kecil untuk melihat apakah Anda dapat lebih mengurangi biaya dan tetap mendapatkan kinerja yang Anda butuhkan.
Di sisi lain, jika klaster konsumen ukuran awal gagal memenuhi persyaratan kinerja beban kerja Anda, Anda dapat menguji lebih lanjut konfigurasi yang lebih besar untuk mendapatkan konfigurasi yang memenuhi SLA Anda.
Sebagai aturan umum, perbesar klaster konsumen sebanyak 2x konfigurasi klaster awal secara bertahap hingga memenuhi persyaratan beban kerja Anda.
Setelah Anda merencanakan konfigurasi apa yang ingin Anda uji, gunakan pengubahan ukuran elastis untuk mengubah ukuran klaster awal ke konfigurasi klaster target. Setelah pengubahan ukuran elastis selesai, lakukan pengujian beban kerja yang sama dan evaluasi performa terhadap SLA Anda. Pilih konfigurasi yang memenuhi target performa harga Anda.
Uji beban kerja hanya produsen pada konfigurasi klaster produsen yang berbeda
Setelah Anda memindahkan beban kerja konsumen ke klaster konsumen dengan performa harga optimal, mungkin ada peluang untuk mengurangi sumber daya komputasi di produsen untuk menghemat biaya.
Untuk mencapainya, Anda dapat menjalankan ulang beban kerja produser saja pada 1/2x ukuran produser asli dan mengevaluasi performa beban kerja. Mengubah ukuran klaster ke atas dan ke bawah sesuai hasil, lalu Anda memilih konfigurasi produsen minimum yang memenuhi persyaratan kinerja beban kerja Anda.
Evaluasi ulang setelah beban kerja penuh berjalan dari waktu ke waktu
Seiring Amazon Redshift terus berkembang, dan ada rilis peningkatan kinerja dan skalabilitas berkelanjutan, kinerja berbagi data akan terus meningkat. Selain itu, banyak variabel yang dapat memengaruhi performa kueri berbagi data. Berikut ini hanyalah beberapa contoh:
- Tingkat penyerapan dan jumlah perubahan data
- Pola kueri dan karakteristik
- Perubahan beban kerja
- Concurrency
- Kegiatan pemeliharaan, misalnya vakum, analisis, dan ATO
Inilah sebabnya mengapa Anda harus mengevaluasi ulang ukuran klaster produsen dan konsumen menggunakan strategi di atas sesekali, terutama setelah penerapan beban kerja penuh, untuk mendapatkan performa harga terbaik baru dari konfigurasi klaster Anda.
Solusi ukuran otomatis
Jika lingkungan Anda melibatkan arsitektur yang lebih kompleks, misalnya dengan beberapa alat atau aplikasi (BI, penyerapan atau streaming, ETL, ilmu data), maka mungkin tidak layak untuk menggunakan metode manual dari panduan umum di atas. Sebagai gantinya, Anda dapat memanfaatkan solusi di bagian ini untuk secara otomatis memutar ulang beban kerja dari klaster produksi Anda pada klaster konsumen dan produsen uji untuk mengevaluasi kinerjanya.
Utilitas Replay sederhana akan dimanfaatkan sebagai solusi otomatis untuk memandu Anda melalui proses mendapatkan ukuran klaster produsen dan konsumen yang tepat untuk kinerja harga terbaik.
Simple Replay adalah alat untuk melakukan analisis bagaimana-jika dan mengevaluasi kinerja beban kerja Anda dalam berbagai skenario. Misalnya, Anda dapat menggunakan alat ini untuk mengukur beban kerja Anda yang sebenarnya pada jenis instans baru seperti RA3, mengevaluasi fitur baru, atau menilai konfigurasi klaster yang berbeda. Ini juga mencakup dukungan yang ditingkatkan untuk memutar ulang penyerapan data dan mengekspor pipeline dengan pernyataan COPY dan UNLOAD. Untuk memulai dan memutar ulang beban kerja Anda, unduh alat dari Repositori GitHub Amazon Redshift.
Di sini kami membahas langkah-langkah untuk mengekstrak log beban kerja Anda dari kluster produksi sumber dan memutarnya kembali di lingkungan yang terisolasi. Ini memungkinkan Anda melakukan perbandingan langsung antara klaster Amazon Redshift ini dengan mulus dan memilih konfigurasi klaster yang paling sesuai dengan target kinerja harga Anda.
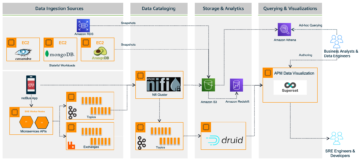
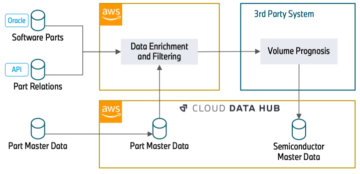
Diagram berikut menunjukkan arsitektur solusi.
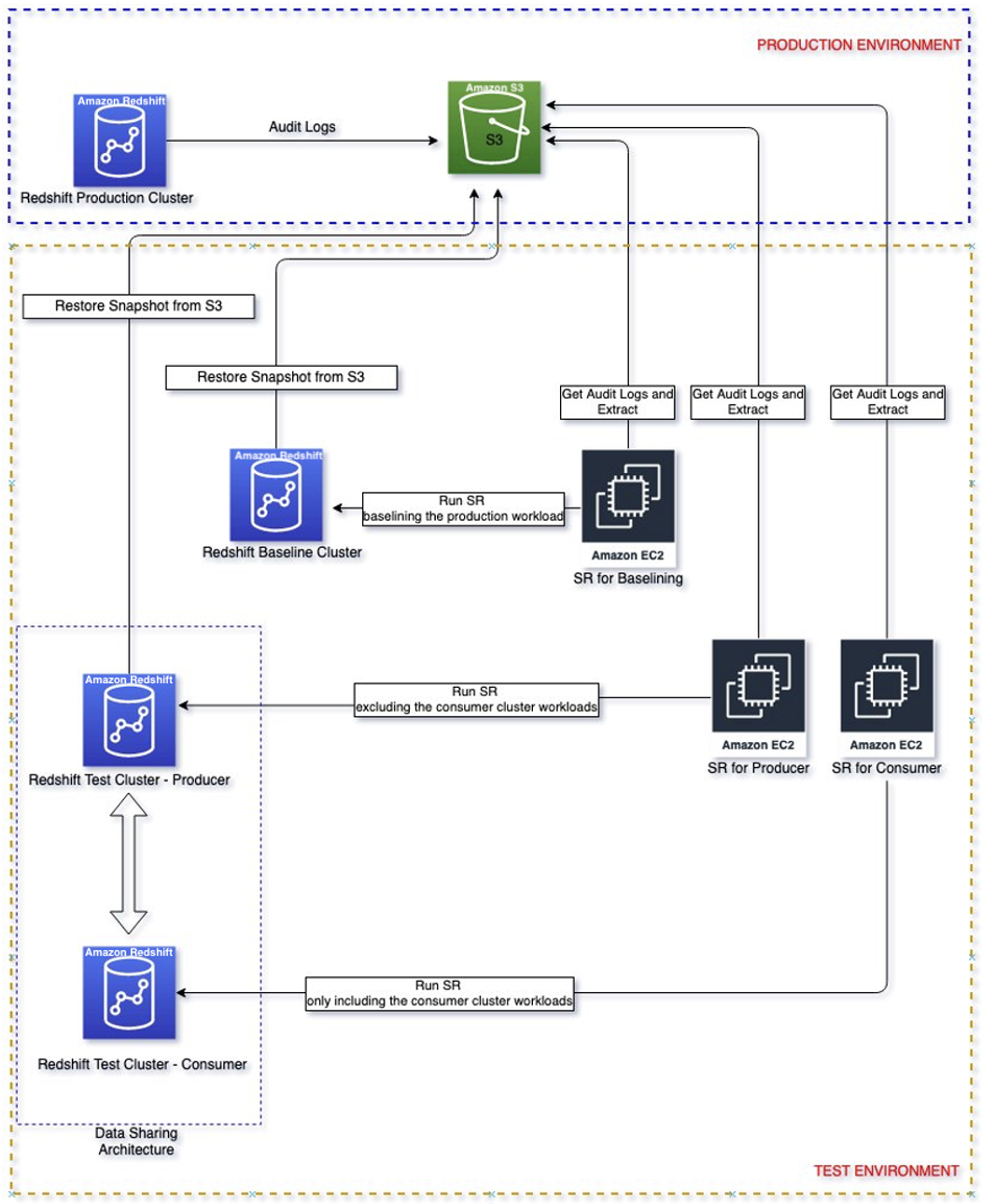
Panduan solusi
Ikuti langkah-langkah berikut untuk mendapatkan solusi untuk mengukur klaster konsumen dan produsen Anda.
Ukuran kluster produksi Anda
Anda harus selalu memastikan untuk mengukur klaster produksi yang ada dengan benar untuk mendapatkan performa yang Anda perlukan untuk memenuhi persyaratan beban kerja. Anda dapat memanfaatkan kalkulator ukuran dari konsol Amazon Redshift untuk mendapatkan rekomendasi pada klaster produksi berdasarkan ukuran data dan karakteristik kueri Anda. Mencari Bantu saya memilih di konsol di Wilayah AWS yang mendukung tipe node RA3 untuk menggunakan kalkulator ukuran ini. Perhatikan bahwa ini hanyalah rekomendasi awal untuk memulai. Anda harus menguji menjalankan beban kerja penuh Anda pada klaster ukuran awal dan mengubah ukuran klaster secara elastis ke atas dan ke bawah untuk mendapatkan performa harga terbaik.
Identifikasi beban kerja yang akan diisolasi
Anda mungkin memiliki beban kerja berbeda yang berjalan di klaster asli Anda, tetapi langkah pertama adalah mengidentifikasi beban kerja paling penting untuk bisnis yang ingin diisolasi. Ini karena kami ingin memastikan bahwa arsitektur baru dapat memenuhi persyaratan beban kerja Anda. Ini pos adalah referensi bagus untuk kasus penggunaan isolasi beban kerja berbagi data yang dapat membantu Anda memutuskan beban kerja mana yang dapat diisolasi.
Siapkan Putar Ulang Sederhana
Setelah Anda mengetahui beban kerja kritis Anda, Anda harus melakukannya aktifkan logging audit di kluster produksi tempat beban kerja penting yang diidentifikasi di atas sedang berjalan untuk merekam aktivitas kueri dan menyimpannya Layanan Penyimpanan Sederhana Amazon (Amazon S3). Perhatikan bahwa mungkin perlu waktu hingga tiga jam untuk mengirimkan log audit ke Amazon S3. Setelah log audit tersedia, lanjutkan ke pengaturan Putar Ulang Sederhana lalu ekstrak beban kerja kritis dari log audit. Perhatikan bahwa waktu_mulai dan waktu_akhir dapat digunakan sebagai parameter untuk memfilter beban kerja kritis jika beban kerja tersebut berjalan dalam jangka waktu tertentu, misalnya pukul 9 hingga 11. Kalau tidak, itu akan mengekstrak semua aktivitas yang dicatat.
Beban kerja dasar
Buat klaster baseline dengan konfigurasi yang sama seperti klaster produser dengan memulihkan dari snapshot produksi. Tujuan memulai dengan konfigurasi yang sama adalah untuk mendasarkan kinerja dengan lingkungan yang terisolasi.
Setelah cluster dasar tersedia, memutar ulang beban kerja yang diekstraksi di cluster dasar. Keluaran dari tayangan ulang ini akan menjadi dasar yang digunakan untuk membandingkan dengan tayangan ulang berikutnya pada konfigurasi konsumen yang berbeda.
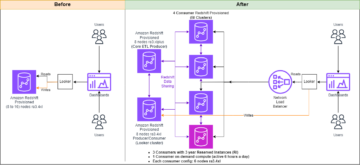
Menyiapkan kluster uji produsen dan konsumen awal
Buat klaster produser dengan konfigurasi klaster produksi yang sama dengan memulihkan dari snapshot produksi. Buat cluster konsumen dengan ukuran konsumen awal yang direkomendasikan dari panduan sebelumnya. Selanjutnya, atur pembagian data antara produsen dan konsumen.
Putar ulang beban kerja pada produsen dan konsumen awal
Replay beban kerja produsen hanya pada cluster produsen ukuran awal. Hal ini dapat dilakukan dengan menggunakan parameter filter "Kecualikan" untuk mengecualikan kueri konsumen, misalnya pengguna yang menjalankan kueri konsumen.
Replay beban kerja konsumen hanya pada cluster konsumen ukuran awal. Hal ini dapat dilakukan dengan menggunakan parameter filter "Sertakan" untuk mengecualikan kueri konsumen, misalnya pengguna yang menjalankan kueri konsumen.
Evaluasi kinerja pemutaran ulang ini terhadap persyaratan kinerja dasar dan beban kerja.
Putar ulang beban kerja konsumen pada konfigurasi yang berbeda
Jika klaster konsumen ukuran awal memenuhi atau melebihi persyaratan performa beban kerja Anda, Anda dapat menggunakan konfigurasi klaster ini atau mengikuti langkah-langkah berikut untuk menguji konfigurasi yang lebih kecil guna melihat apakah Anda dapat mengurangi biaya lebih lanjut dan tetap mendapatkan performa yang Anda perlukan.
Bandingkan hasil kinerja konsumen awal dengan persyaratan beban kerja Anda:
- Jika hasilnya melebihi persyaratan kinerja beban kerja Anda, maka Anda dapat mengurangi ukuran klaster konsumen secara bertahap, dimulai dengan 1/2x, ulangi pemutaran ulang dan evaluasi kinerja, lalu ubah ukuran ke atas atau ke bawah berdasarkan hasil hingga memenuhi beban kerja Anda Persyaratan. Tujuannya adalah untuk mendapatkan sweet spot di mana Anda merasa nyaman dengan persyaratan performa dan mendapatkan harga serendah mungkin.
- Jika hasilnya gagal memenuhi persyaratan kinerja beban kerja Anda, maka Anda dapat meningkatkan ukuran cluster secara bertahap, dimulai dengan 2x ukuran aslinya, coba putar ulang dan evaluasi kinerja hingga memenuhi persyaratan kinerja beban kerja Anda.
Putar ulang beban kerja produsen pada konfigurasi yang berbeda
Setelah Anda membagi beban kerja Anda ke klaster konsumen, beban pada klaster produsen harus dikurangi dan Anda harus mengevaluasi performa beban kerja klaster produsen untuk mencari peluang berhemat guna menghemat biaya.
Langkah-langkahnya mirip dengan replay konsumen. Secara elastis mengubah ukuran klaster produsen secara bertahap dimulai dengan 1/2x ukuran aslinya, memutar ulang beban kerja produsen saja dan mengevaluasi kinerja, lalu mengubah ukuran lebih lanjut ke atas atau ke bawah hingga memenuhi persyaratan kinerja beban kerja Anda. Tujuannya adalah untuk mendapatkan sweet spot di mana Anda merasa nyaman dengan persyaratan performa beban kerja dan mendapatkan harga serendah mungkin. Setelah Anda memiliki konfigurasi klaster produsen yang diinginkan, coba putar ulang beban kerja konsumen pada klaster konsumen untuk memastikan performa tidak terpengaruh oleh perubahan konfigurasi klaster produsen. Terakhir, Anda harus memutar ulang beban kerja produsen dan konsumen secara bersamaan untuk memastikan kinerja dicapai dalam skenario beban kerja penuh.
Evaluasi ulang setelah beban kerja penuh berjalan dari waktu ke waktu
Mirip dengan panduan umum, Anda harus mengevaluasi ulang ukuran klaster produsen dan konsumen menggunakan strategi sebelumnya, terutama setelah penerapan beban kerja penuh untuk mendapatkan kinerja harga terbaik baru dari konfigurasi klaster Anda.
Membersihkan
Menjalankan uji ukuran ini di akun AWS Anda mungkin memiliki beberapa implikasi biaya karena ini menyediakan klaster Amazon Redshift baru, yang mungkin dikenai biaya sebagai instans sesuai permintaan jika Anda tidak memiliki Instans Cadangan. Saat Anda menyelesaikan evaluasi, kami menyarankan untuk menghapus klaster Amazon Redshift untuk menghemat biaya. Kami juga menyarankan untuk menjeda kluster Anda saat tidak digunakan.
Menerapkan praktik terbaik Amazon Redshift dan berbagi data
Pengukuran yang tepat untuk klaster produsen dan konsumen Anda akan memberi Anda awal yang baik untuk mendapatkan performa harga terbaik dari penerapan Amazon Redshift Anda. Namun, ukuran bukanlah satu-satunya faktor yang dapat memaksimalkan kinerja Anda. Dalam hal ini, memahami dan mengikuti praktik terbaik sama pentingnya.
Praktik terbaik penyetelan kinerja Amazon Redshift umum berlaku untuk penerapan berbagi data. Pastikan penerapan Anda mengikuti ini Praktik Terbaik.
Ada banyak praktik terbaik khusus berbagi data yang harus Anda ikuti untuk memastikan bahwa Anda memaksimalkan kinerja. Lihat ini pos lebih lanjut.
Kesimpulan
Tidak ada rekomendasi satu ukuran untuk semua tentang ukuran kelompok produsen dan konsumen. Ini bervariasi menurut beban kerja dan SLA kinerja Anda. Tujuan postingan ini adalah untuk memberi Anda panduan tentang cara mengevaluasi performa beban kerja berbagi data spesifik untuk menentukan ukuran klaster konsumen dan produsen untuk mendapatkan performa harga terbaik. Pertimbangkan untuk menguji beban kerja Anda pada produsen dan konsumen menggunakan replay sederhana sebelum menerapkannya dalam produksi untuk mendapatkan performa harga terbaik.
Tentang Penulis
 BP Yau adalah Manajer Produk Senior di AWS. Dia bersemangat membantu pelanggan merancang solusi big data untuk memproses data dalam skala besar. Sebelum AWS, dia membantu Amazon.com Supply Chain Optimization Technologies memigrasikan gudang data Oracle ke Amazon Redshift dan membangun platform analitik data besar generasi berikutnya menggunakan teknologi AWS.
BP Yau adalah Manajer Produk Senior di AWS. Dia bersemangat membantu pelanggan merancang solusi big data untuk memproses data dalam skala besar. Sebelum AWS, dia membantu Amazon.com Supply Chain Optimization Technologies memigrasikan gudang data Oracle ke Amazon Redshift dan membangun platform analitik data besar generasi berikutnya menggunakan teknologi AWS.
 Sidhanth Muralidhar adalah Manajer Akun Teknis Utama di AWS. Dia bekerja dengan pelanggan perusahaan besar yang menjalankan beban kerja mereka di AWS. Dia bersemangat bekerja dengan pelanggan dan membantu mereka merancang beban kerja untuk biaya, keandalan, kinerja, dan keunggulan operasional dalam skala besar dalam perjalanan cloud mereka. Dia juga sangat tertarik dengan Analisis Data.
Sidhanth Muralidhar adalah Manajer Akun Teknis Utama di AWS. Dia bekerja dengan pelanggan perusahaan besar yang menjalankan beban kerja mereka di AWS. Dia bersemangat bekerja dengan pelanggan dan membantu mereka merancang beban kerja untuk biaya, keandalan, kinerja, dan keunggulan operasional dalam skala besar dalam perjalanan cloud mereka. Dia juga sangat tertarik dengan Analisis Data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Tentang Kami
- atas
- demikian
- Akun
- Akun
- Mencapai
- dicapai
- di seluruh
- kegiatan
- menambahkan
- Mengadopsi
- Setelah
- terhadap
- Semua
- memungkinkan
- selalu
- Amazon
- Amazon.com
- jumlah
- analisis
- analisis
- menganalisa
- dan
- Lain
- berlaku
- aplikasi
- pendekatan
- arsitektur
- Audit
- Otomatis
- secara otomatis
- tersedia
- AWS
- berdasarkan
- Dasar
- karena
- sebelum
- patokan
- TERBAIK
- Praktik Terbaik
- Lebih baik
- antara
- Besar
- Big data
- membangun
- bisnis
- menangkap
- kasus
- kasus
- tertentu
- rantai
- Perubahan
- ciri
- karakteristik
- dibebankan
- klien
- awan
- Kelompok
- COM
- nyaman
- Umum
- membandingkan
- perbandingan
- lengkap
- Lengkap
- kompleks
- kompleksitas
- menghitung
- melakukan
- konfigurasi
- Mempertimbangkan
- konsisten
- konsul
- konsumen
- terus
- terus
- kontinu
- Biaya
- Biaya
- bisa
- membuat
- kritis
- pelanggan
- data
- Data Analytics
- ilmu data
- berbagi data
- disampaikan
- tergantung
- penyebaran
- rincian
- Menentukan
- berbeda
- langsung
- Dont
- turun
- Download
- selama
- mudah
- antara
- memungkinkan
- ditingkatkan
- Enterprise
- Lingkungan Hidup
- sama
- terutama
- Eter (ETH)
- mengevaluasi
- evaluasi
- berkembang
- contoh
- contoh
- melebihi
- Keunggulan
- ada
- ekspor
- ekstrak
- gagal
- FAST
- layak
- Fitur
- menyaring
- Akhirnya
- Pertama
- keluwesan
- mengikuti
- berikut
- berikut
- dari
- penuh
- secara fundamental
- lebih lanjut
- Selanjutnya
- Mendapatkan
- umumnya
- generasi
- mendapatkan
- mendapatkan
- GitHub
- Memberikan
- Go
- baik
- membimbing
- membantu
- membantu
- membantu
- JAM
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- diidentifikasi
- mengenali
- Dampak
- dampak
- diimplementasikan
- implikasi
- penting
- perbaikan
- meningkatkan
- in
- termasuk
- Meningkatkan
- mulanya
- mulanya
- contoh
- sebagai gantinya
- bunga
- terlibat
- terpencil
- isolasi
- IT
- perjalanan
- Tajam
- Tahu
- besar
- lebih besar
- diluncurkan
- Lets
- Leverage
- hidup
- memuat
- melihat
- pemeliharaan
- membuat
- manajer
- panduan
- Maksimalkan
- Pelajari
- Memenuhi
- metode
- mungkin
- bermigrasi
- minimum
- model
- lebih
- paling
- pindah
- gerakan
- beberapa
- Perlu
- membutuhkan
- kebutuhan
- New
- berikutnya
- simpul
- banyak sekali
- kesempatan
- Di atas kapal
- ONE
- operasional
- Kesempatan
- optimasi
- optimal
- peramal
- asli
- Lainnya
- jika tidak
- parameter
- parameter
- bergairah
- pola
- melakukan
- prestasi
- melakukan
- periode
- rencana
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- mungkin
- Pos
- praktek
- sebelumnya
- harga pompa cor beton mini
- Utama
- proses
- produsen
- Produk
- manajer produk
- Produksi
- tepat
- memberikan
- menyediakan
- tujuan
- Pertanyaan
- Penilaian
- sarankan
- Rekomendasi
- direkomendasikan
- menurunkan
- mengurangi
- daerah
- Pers
- keandalan
- Persyaratan
- dilindungi
- sumber
- memulihkan
- mengakibatkan
- Hasil
- Aturan
- Run
- berjalan
- sama
- Save
- Skalabilitas
- terukur
- Skala
- skenario
- Ilmu
- mulus
- Bagian
- aman
- aman
- Mencari
- layanan
- penyiapan
- Share
- berbagi
- harus
- Menunjukkan
- Pertunjukkan
- mirip
- Sederhana
- Ukuran
- ukuran
- lebih kecil
- Potret
- larutan
- Solusi
- beberapa
- sumber
- tertentu
- membagi
- Spot
- standar
- awal
- mulai
- Mulai
- Laporan
- Langkah
- Tangga
- Masih
- penyimpanan
- menyimpan
- Penyelarasan
- Streaming
- selanjutnya
- menyediakan
- supply chain
- Optimalisasi Rantai Pasokan
- mendukung
- manis
- Mengambil
- target
- Teknis
- Teknologi
- uji
- pengujian
- tes
- Grafik
- Sumber
- mereka
- tiga
- Melalui
- waktu
- untuk
- alat
- alat
- jenis
- pemahaman
- menggunakan
- gunakan case
- Pengguna
- Kekosongan
- Apa
- yang
- SIAPA
- akan
- tanpa
- kerja
- bekerja
- Anda
- zephyrnet.dll