Posting ini ditulis bersama dengan Mahima Agarwal, Insinyur Pembelajaran Mesin, dan Deepak Mettem, Manajer Teknik Senior, di VMware Carbon Black
VMware Karbon Hitam adalah solusi keamanan ternama yang menawarkan perlindungan terhadap spektrum penuh serangan siber modern. Dengan terabyte data yang dihasilkan oleh produk, tim analitik keamanan berfokus pada membangun solusi pembelajaran mesin (ML) untuk memunculkan serangan kritis dan menyoroti ancaman yang muncul dari kebisingan.
Sangat penting bagi tim VMware Carbon Black untuk merancang dan membuat pipeline MLOps end-to-end khusus yang mengatur dan mengotomatiskan alur kerja dalam siklus hidup ML dan memungkinkan pelatihan model, evaluasi, dan penerapan.
Ada dua tujuan utama membangun pipeline ini: mendukung ilmuwan data untuk pengembangan model tahap akhir, dan prediksi model permukaan dalam produk dengan menyajikan model dalam volume tinggi dan dalam lalu lintas produksi waktu nyata. Oleh karena itu, VMware Carbon Black dan AWS memilih untuk membangun jalur pipa MLOps khusus menggunakan Amazon SageMaker untuk kemudahan penggunaan, keserbagunaan, dan infrastruktur yang dikelola sepenuhnya. Kami mengatur pelatihan ML dan pipeline penerapan menggunakan Alur Kerja Terkelola Amazon untuk Apache Airflow (Amazon MWAA), yang memungkinkan kami untuk lebih fokus pada pembuatan alur kerja dan pipeline secara terprogram tanpa harus mengkhawatirkan penskalaan otomatis atau pemeliharaan infrastruktur.
Dengan pipeline ini, apa yang sebelumnya merupakan riset ML berbasis notebook Jupyter kini menjadi proses otomatis yang menerapkan model ke produksi dengan sedikit intervensi manual dari data scientist. Sebelumnya, proses pelatihan, evaluasi, dan penerapan model dapat memakan waktu lebih dari satu hari; dengan penerapan ini, semuanya hanya berjarak satu pemicu dan telah mengurangi waktu keseluruhan menjadi beberapa menit.
Dalam postingan ini, arsitek VMware Carbon Black dan AWS membahas cara kami membuat dan mengelola alur kerja ML kustom menggunakan Gitlab, Amazon MWAA, dan SageMaker. Kami membahas apa yang telah kami capai sejauh ini, peningkatan lebih lanjut pada jalur pipa, dan pelajaran yang dipetik selama ini.
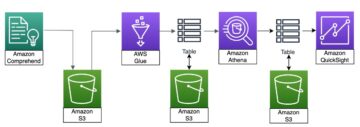
Ikhtisar solusi
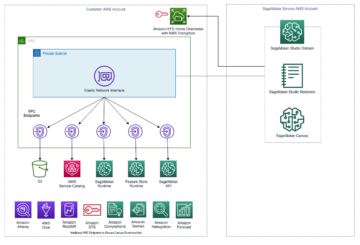
Diagram berikut mengilustrasikan arsitektur platform ML.

Desain Solusi tingkat tinggi
Platform ML ini dibayangkan dan dirancang untuk digunakan oleh model yang berbeda di berbagai repositori kode. Tim kami menggunakan GitLab sebagai alat manajemen kode sumber untuk memelihara semua repositori kode. Setiap perubahan dalam kode sumber repositori model terus diintegrasikan menggunakan Gitlab CI, yang memanggil alur kerja berikutnya dalam alur (pelatihan model, evaluasi, dan penerapan).
Diagram arsitektur berikut mengilustrasikan alur kerja end-to-end dan komponen yang terlibat dalam pipeline MLOps kami.

Alur Kerja Ujung-Ke-Ujung
Pipeline penerapan, evaluasi, dan pelatihan model ML diatur menggunakan Amazon MWAA, disebut sebagai a Grafik Asiklik yang Diarahkan (DAG). DAG adalah kumpulan tugas bersama, diatur dengan ketergantungan dan hubungan untuk mengatakan bagaimana mereka harus dijalankan.
Pada tingkat tinggi, arsitektur solusi mencakup tiga komponen utama:
- Repositori kode pipeline ML
- Pipeline evaluasi dan pelatihan model ML
- Pipeline penerapan model ML
Mari kita bahas bagaimana komponen yang berbeda ini dikelola dan bagaimana mereka berinteraksi satu sama lain.
Repositori kode pipeline ML
Setelah repo model mengintegrasikan repo MLOps sebagai pipeline hilirnya, dan ilmuwan data melakukan kode dalam repo modelnya, pelari GitLab melakukan validasi dan pengujian kode standar yang ditentukan dalam repo tersebut dan memicu pipeline MLOps berdasarkan perubahan kode. Kami menggunakan pipeline multi-proyek Gitlab untuk mengaktifkan pemicu ini di berbagai repo.
Pipeline MLOps GitLab menjalankan serangkaian tahapan tertentu. Itu melakukan validasi kode dasar menggunakan pylint, mengemas pelatihan model dan kode inferensi dalam image Docker, dan menerbitkan image container ke Registry Kontainer Elastis Amazon (ECR Amazon). Amazon ECR adalah registri kontainer terkelola penuh yang menawarkan hosting berkinerja tinggi, sehingga Anda dapat menerapkan gambar dan artefak aplikasi dengan andal di mana saja.
Pipeline evaluasi dan pelatihan model ML
Setelah gambar dipublikasikan, itu memicu pelatihan dan evaluasi Aliran Udara Apache pipa melalui AWS Lambda fungsi. Lambda adalah layanan komputasi berbasis peristiwa tanpa server yang memungkinkan Anda menjalankan kode untuk hampir semua jenis aplikasi atau layanan backend tanpa menyediakan atau mengelola server.
Setelah pipa berhasil dipicu, DAG Pelatihan dan Evaluasi akan dijalankan, yang selanjutnya akan memulai pelatihan model di SageMaker. Di akhir alur pelatihan ini, grup pengguna yang teridentifikasi mendapat pemberitahuan dengan pelatihan dan hasil evaluasi model melalui email Layanan Pemberitahuan Sederhana Amazon (Amazon SNS) dan Slack. Amazon SNS adalah layanan pub/sub yang dikelola sepenuhnya untuk perpesanan A2A dan A2P.
Setelah analisis hasil evaluasi yang cermat, ilmuwan data atau insinyur ML dapat menerapkan model baru jika kinerja model yang baru dilatih lebih baik dibandingkan versi sebelumnya. Performa model dievaluasi berdasarkan metrik khusus model (seperti skor F1, MSE, atau matriks konfusi).
Pipeline penerapan model ML
Untuk memulai penerapan, pengguna memulai tugas GitLab yang memicu DAG Penerapan melalui fungsi Lambda yang sama. Setelah pipeline berjalan dengan sukses, pipeline membuat atau memperbarui titik akhir SageMaker dengan model baru. Ini juga mengirimkan pemberitahuan dengan detail titik akhir melalui email menggunakan Amazon SNS dan Slack.
Jika terjadi kegagalan di salah satu jalur pipa, pengguna akan diberi tahu melalui saluran komunikasi yang sama.
SageMaker menawarkan inferensi real-time yang ideal untuk beban kerja inferensi dengan latensi rendah dan persyaratan throughput tinggi. Titik akhir ini dikelola sepenuhnya, penyeimbangan muatan, dan penskalaan otomatis, serta dapat diterapkan di beberapa Availability Zone untuk ketersediaan tinggi. Pipeline kami membuat titik akhir untuk model setelah berjalan dengan sukses.
Di bagian berikut, kami memperluas berbagai komponen dan mendalami detailnya.
GitLab: Paket model dan trigger pipeline
Kami menggunakan GitLab sebagai repositori kode kami dan untuk pipeline untuk mengemas kode model dan memicu DAG Aliran Udara hilir.
Pipa multi-proyek
Fitur pipa multi-proyek GitLab digunakan di mana pipa induk (hulu) adalah repo model dan pipa anak (hilir) adalah repo MLOps. Setiap repo mempertahankan .gitlab-ci.yml, dan blok kode berikut yang diaktifkan di pipeline upstream akan memicu pipeline MLOps downstream.
Pipeline upstream mengirimkan kode model ke pipeline downstream tempat pekerjaan pengemasan dan penerbitan CI dipicu. Kode untuk menampung kode model dan menerbitkannya ke Amazon ECR dikelola dan dikelola oleh jalur pipa MLOps. Ini mengirimkan variabel seperti ACCESS_TOKEN (dapat dibuat di bawah Settings, Mengakses), variabel JOB_ID (untuk mengakses artefak upstream), dan $CI_PROJECT_ID (ID proyek repo model), sehingga pipeline MLOps dapat mengakses file kode model. Dengan artefak pekerjaan fitur dari Gitlab, repo downstream mengakses artefak jarak jauh menggunakan perintah berikut:
Repo model dapat menggunakan pipeline hilir untuk beberapa model dari repo yang sama dengan memperluas tahapan yang memicunya menggunakan Meluas kata kunci dari GitLab, yang memungkinkan Anda menggunakan kembali konfigurasi yang sama di berbagai tahapan.
Setelah memublikasikan gambar model ke Amazon ECR, pipeline MLOps memicu pipeline pelatihan Amazon MWAA menggunakan Lambda. Setelah persetujuan pengguna, ini memicu penyebaran model pipa Amazon MWAA juga menggunakan fungsi Lambda yang sama.
Pembuatan versi semantik dan meneruskan versi ke hilir
Kami mengembangkan kode khusus untuk versi gambar ECR dan model SageMaker. Pipeline MLOps mengelola logika pembuatan versi semantik untuk gambar dan model sebagai bagian dari tahap di mana kode model dimasukkan ke dalam wadah, dan meneruskan versi ke tahap selanjutnya sebagai artefak.
Pelatihan ulang
Karena pelatihan ulang adalah aspek penting dari siklus hidup ML, kami telah mengimplementasikan kemampuan pelatihan ulang sebagai bagian dari saluran kami. Kami menggunakan API model daftar SageMaker untuk mengidentifikasi apakah itu pelatihan ulang berdasarkan nomor versi dan stempel waktu pelatihan ulang model.
Kami mengelola jadwal harian pipa pelatihan ulang menggunakan Pipeline jadwal GitLab.
Terraform: Penyiapan infrastruktur
Selain klaster Amazon MWAA, repositori ECR, fungsi Lambda, dan topik SNS, solusi ini juga menggunakan Identitas AWS dan Manajemen Akses (IAM) peran, pengguna, dan kebijakan; Layanan Penyimpanan Sederhana Amazon (Amazon S3) bucket, dan an amazoncloudwatch penerus log.
Untuk merampingkan penyiapan dan pemeliharaan infrastruktur untuk layanan yang terlibat di seluruh jalur pipa kami, kami menggunakan Terraform untuk mengimplementasikan infrastruktur sebagai kode. Setiap kali pembaruan infra diperlukan, perubahan kode memicu pipa GitLab CI yang kami siapkan, yang memvalidasi dan menerapkan perubahan ke berbagai lingkungan (misalnya, menambahkan izin ke kebijakan IAM di akun dev, stage, dan prod).
Amazon ECR, Amazon S3, dan Lambda: Fasilitasi saluran pipa
Kami menggunakan layanan utama berikut untuk memfasilitasi jalur pipa kami:
- ECR Amazon – Untuk mempertahankan dan memungkinkan pengambilan gambar wadah model dengan mudah, kami menandainya dengan versi semantik dan mengunggahnya ke repositori ECR yang disiapkan per
${project_name}/${model_name}melalui Terraform. Ini memungkinkan lapisan isolasi yang baik antara model yang berbeda, dan memungkinkan kita untuk menggunakan algoritme khusus dan untuk memformat permintaan dan tanggapan inferensi untuk menyertakan informasi manifes model yang diinginkan (nama model, versi, jalur data pelatihan, dan sebagainya). - Amazon S3 – Kami menggunakan bucket S3 untuk mempertahankan data pelatihan model, artefak model terlatih per model, DAG Airflow, dan informasi tambahan lainnya yang diperlukan oleh pipeline.
- Lambda – Karena kluster Aliran Udara kami diterapkan di VPC terpisah untuk pertimbangan keamanan, DAG tidak dapat diakses secara langsung. Oleh karena itu, kami menggunakan fungsi Lambda, yang juga dikelola dengan Terraform, untuk memicu DAG apa pun yang ditentukan oleh nama DAG. Dengan penyiapan IAM yang tepat, tugas GitLab CI memicu fungsi Lambda, yang melewati konfigurasi hingga DAG pelatihan atau penerapan yang diminta.
Amazon MWAA: Jalur pelatihan dan penerapan
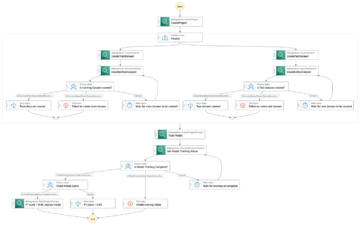
Seperti disebutkan sebelumnya, kami menggunakan Amazon MWAA untuk mengatur alur pelatihan dan penerapan. Kami menggunakan operator SageMaker yang tersedia di Paket penyedia Amazon untuk Airflow untuk berintegrasi dengan SageMaker (untuk menghindari template jinja).
Kami menggunakan operator berikut dalam alur pelatihan ini (ditunjukkan dalam diagram alur kerja berikut):

Pipa Pelatihan MWAA
Kami menggunakan operator berikut dalam alur penyebaran (ditunjukkan dalam diagram alur kerja berikut):

Pipa Penerapan Model
Kami menggunakan Slack dan Amazon SNS untuk menerbitkan pesan kesalahan/keberhasilan dan hasil evaluasi di kedua pipeline. Slack menyediakan berbagai opsi untuk menyesuaikan pesan, termasuk yang berikut ini:
- SnsPublishOperator - Kita gunakan SnsPublishOperator untuk mengirim pemberitahuan keberhasilan/kegagalan ke email pengguna
- API kendur – Kami menciptakan URL webhook yang masuk untuk mendapatkan notifikasi pipa ke saluran yang diinginkan
CloudWatch dan VMware Wavefront: Pemantauan dan pencatatan log
Kami menggunakan dasbor CloudWatch untuk mengonfigurasi pemantauan dan pencatatan titik akhir. Ini membantu memvisualisasikan dan melacak berbagai metrik kinerja operasional dan model yang spesifik untuk setiap proyek. Selain kebijakan penskalaan otomatis yang disiapkan untuk melacak beberapa di antaranya, kami terus memantau perubahan dalam penggunaan CPU dan memori, permintaan per detik, latensi respons, dan metrik model.
CloudWatch bahkan terintegrasi dengan dasbor VMware Tanzu Wavefront sehingga dapat memvisualisasikan metrik untuk titik akhir model serta layanan lain di tingkat proyek.
Manfaat bisnis dan apa selanjutnya
Pipeline ML sangat penting untuk layanan dan fitur ML. Dalam postingan ini, kami membahas kasus penggunaan ML end-to-end yang menggunakan kemampuan dari AWS. Kami membuat pipeline khusus menggunakan SageMaker dan Amazon MWAA, yang dapat digunakan kembali di seluruh proyek dan model, serta mengotomatiskan siklus hidup ML, yang mengurangi waktu dari pelatihan model hingga penerapan produksi menjadi sesedikit 10 menit.
Dengan pengalihan beban siklus hidup ML ke SageMaker, SageMaker menyediakan infrastruktur yang dioptimalkan dan dapat diskalakan untuk pelatihan dan penerapan model. Penyajian model dengan SageMaker membantu kami membuat prediksi waktu nyata dengan latensi milidetik dan kemampuan pemantauan. Kami menggunakan Terraform untuk kemudahan penyiapan dan mengelola infrastruktur.
Langkah selanjutnya untuk pipeline ini adalah menyempurnakan pipeline pelatihan model dengan kemampuan pelatihan ulang baik itu dijadwalkan atau berdasarkan deteksi penyimpangan model, mendukung penerapan bayangan atau pengujian A/B untuk penerapan model yang lebih cepat dan berkualitas, serta pelacakan garis keturunan ML. Kami juga berencana untuk mengevaluasi Pipa Amazon SageMaker karena integrasi GitLab sekarang didukung.
Pelajaran yang dipetik
Sebagai bagian dari membangun solusi ini, kami belajar bahwa Anda harus menggeneralisasi lebih awal, tetapi jangan menggeneralisasi secara berlebihan. Ketika kami pertama kali menyelesaikan desain arsitektur, kami mencoba membuat dan memberlakukan templat kode untuk kode model sebagai praktik terbaik. Namun, masih sangat awal dalam proses pengembangan sehingga template terlalu umum atau terlalu detail untuk dapat digunakan kembali untuk model mendatang.
Setelah mengirimkan model pertama melalui pipeline, template keluar secara alami berdasarkan wawasan dari pekerjaan kami sebelumnya. Saluran pipa tidak dapat melakukan semuanya sejak hari pertama.
Eksperimen dan produksi model seringkali memiliki persyaratan yang sangat berbeda (atau terkadang bahkan bertentangan). Sangat penting untuk menyeimbangkan persyaratan ini sejak awal sebagai sebuah tim dan memprioritaskannya.
Selain itu, Anda mungkin tidak memerlukan setiap fitur layanan. Menggunakan fitur penting dari layanan dan memiliki desain termodulasi adalah kunci untuk pengembangan yang lebih efisien dan saluran pipa yang fleksibel.
Kesimpulan
Dalam postingan ini, kami menunjukkan cara membangun solusi MLOps menggunakan SageMaker dan Amazon MWAA yang mengotomatiskan proses penerapan model ke produksi, dengan sedikit intervensi manual dari data scientist. Kami mendorong Anda untuk mengevaluasi berbagai layanan AWS seperti SageMaker, Amazon MWAA, Amazon S3, dan Amazon ECR untuk membangun solusi MLOps yang lengkap.
*Apache, Apache Airflow, dan Airflow adalah merek dagang terdaftar atau merek dagang dari Yayasan Perangkat Lunak Apache di Amerika Serikat dan/atau negara lain.
Tentang Penulis
 Deepak Mettem adalah Senior Engineering Manager di VMware, Carbon Black Unit. Dia dan timnya bekerja untuk membangun aplikasi dan layanan berbasis streaming yang sangat tersedia, dapat diskalakan, dan tangguh untuk menghadirkan solusi berbasis pembelajaran mesin kepada pelanggan secara real-time. Dia dan timnya juga bertanggung jawab untuk membuat alat yang diperlukan bagi ilmuwan data untuk membuat, melatih, menerapkan, dan memvalidasi model ML mereka dalam produksi.
Deepak Mettem adalah Senior Engineering Manager di VMware, Carbon Black Unit. Dia dan timnya bekerja untuk membangun aplikasi dan layanan berbasis streaming yang sangat tersedia, dapat diskalakan, dan tangguh untuk menghadirkan solusi berbasis pembelajaran mesin kepada pelanggan secara real-time. Dia dan timnya juga bertanggung jawab untuk membuat alat yang diperlukan bagi ilmuwan data untuk membuat, melatih, menerapkan, dan memvalidasi model ML mereka dalam produksi.
 Mahima Agarwal adalah Insinyur Pembelajaran Mesin di VMware, Carbon Black Unit.
Mahima Agarwal adalah Insinyur Pembelajaran Mesin di VMware, Carbon Black Unit.
Dia bekerja merancang, membangun, dan mengembangkan komponen inti dan arsitektur platform pembelajaran mesin untuk VMware CB SBU.
 Vamshi Krishna Enabothala adalah Arsitek Spesialis AI Terapan Senior di AWS. Dia bekerja dengan pelanggan dari berbagai sektor untuk mempercepat inisiatif data, analitik, dan pembelajaran mesin berdampak tinggi. Dia sangat tertarik dengan sistem rekomendasi, NLP, dan area visi komputer di AI dan ML. Di luar pekerjaan, Vamshi adalah penggemar RC, membuat peralatan RC (pesawat, mobil, dan drone), dan juga suka berkebun.
Vamshi Krishna Enabothala adalah Arsitek Spesialis AI Terapan Senior di AWS. Dia bekerja dengan pelanggan dari berbagai sektor untuk mempercepat inisiatif data, analitik, dan pembelajaran mesin berdampak tinggi. Dia sangat tertarik dengan sistem rekomendasi, NLP, dan area visi komputer di AI dan ML. Di luar pekerjaan, Vamshi adalah penggemar RC, membuat peralatan RC (pesawat, mobil, dan drone), dan juga suka berkebun.
 Sahil Thapar adalah Arsitek Solusi Perusahaan. Dia bekerja dengan pelanggan untuk membantu mereka membangun aplikasi yang sangat tersedia, dapat diskalakan, dan tangguh di AWS Cloud. Dia saat ini berfokus pada wadah dan solusi pembelajaran mesin.
Sahil Thapar adalah Arsitek Solusi Perusahaan. Dia bekerja dengan pelanggan untuk membantu mereka membangun aplikasi yang sangat tersedia, dapat diskalakan, dan tangguh di AWS Cloud. Dia saat ini berfokus pada wadah dan solusi pembelajaran mesin.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :adalah
- $NAIK
- 1
- 10
- 100
- 7
- 8
- a
- Tentang Kami
- mempercepat
- mengakses
- diakses
- demikian
- Akun
- dicapai
- di seluruh
- asiklik
- tambahan
- Tambahan
- Informasi Tambahan
- Setelah
- terhadap
- AI
- algoritma
- Semua
- memungkinkan
- Amazon
- Amazon SageMaker
- analisis
- analisis
- dan
- di manapun
- Apache
- api
- Aplikasi
- aplikasi
- terapan
- AI terapan
- persetujuan
- arsitektur
- ADALAH
- daerah
- AS
- penampilan
- At
- Serangan
- menulis
- mobil
- Otomatis
- mengotomatiskan
- tersedianya
- tersedia
- menghindari
- AWS
- Backend
- Saldo
- berdasarkan
- dasar
- BE
- karena
- Awal
- Manfaat
- TERBAIK
- Lebih baik
- antara
- Black
- Memblokir
- Cabang
- membawa
- membangun
- Bangunan
- dibangun di
- beban
- by
- CAN
- tidak bisa
- kemampuan
- karbon
- mobil
- kasus
- CB
- tertentu
- Perubahan
- saluran
- anak
- memilih
- awan
- Kelompok
- kode
- koleksi
- Komunikasi
- dibandingkan
- lengkap
- komponen
- menghitung
- komputer
- Visi Komputer
- melakukan
- konfigurasi
- konfigurasi
- Berbenturan
- kebingungan
- pertimbangan
- memakan
- dikonsumsi
- Wadah
- Wadah
- terus menerus
- Mudah
- Core
- bisa
- negara
- CPU
- membuat
- dibuat
- menciptakan
- membuat
- kritis
- sangat penting
- Sekarang
- adat
- pelanggan
- menyesuaikan
- cyberattacks
- DAG
- harian
- dasbor
- data
- ilmuwan data
- hari
- didefinisikan
- mengantarkan
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- penyebaran
- menyebarkan
- Mendesain
- dirancang
- merancang
- terperinci
- rincian
- Deteksi
- dev
- dikembangkan
- berkembang
- Pengembangan
- berbeda
- langsung
- membahas
- dibahas
- Buruh pelabuhan
- Dont
- turun
- Drone
- setiap
- Terdahulu
- Awal
- kemudahan penggunaan
- efisien
- antara
- muncul
- aktif
- diaktifkan
- memungkinkan
- mendorong
- ujung ke ujung
- Titik akhir
- insinyur
- Teknik
- Enterprise
- Solusi perusahaan
- penggemar
- lingkungan
- peralatan
- penting
- Eter (ETH)
- mengevaluasi
- dievaluasi
- mengevaluasi
- evaluasi
- evaluasi
- Bahkan
- Acara
- Setiap
- segala sesuatu
- contoh
- Lihat lebih lanjut
- memperpanjang
- f1
- memudahkan
- Kegagalan
- jauh
- lebih cepat
- Fitur
- Fitur
- beberapa
- File
- Pertama
- fleksibel
- Fokus
- terfokus
- berfokus
- berikut
- Untuk
- format
- dari
- penuh
- spektrum penuh
- sepenuhnya
- fungsi
- fungsi
- lebih lanjut
- masa depan
- dihasilkan
- mendapatkan
- baik
- Kelompok
- Memiliki
- memiliki
- membantu
- membantu
- membantu
- High
- kinerja tinggi
- sangat
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- diidentifikasi
- mengenali
- identitas
- gambar
- gambar
- melaksanakan
- implementasi
- diimplementasikan
- in
- memasukkan
- termasuk
- Termasuk
- informasi
- Infrastruktur
- inisiatif
- wawasan
- mengintegrasikan
- terpadu
- Terintegrasi
- integrasi
- berinteraksi
- intervensi
- memanggil
- terlibat
- isolasi
- IT
- NYA
- Pekerjaan
- Jobs
- jpg
- Menjaga
- kunci
- kunci-kunci
- Latensi
- lapisan
- belajar
- pengetahuan
- Pelajaran
- Pelajaran
- Lets
- Tingkat
- siklus hidup
- 'like'
- sedikit
- memuat
- Rendah
- mesin
- Mesin belajar
- Utama
- memelihara
- mempertahankan
- pemeliharaan
- membuat
- mengelola
- berhasil
- pengelolaan
- manajer
- mengelola
- pelaksana
- panduan
- Matriks
- Memori
- tersebut
- pesan
- pesan
- Metrik
- mungkin
- mili detik
- menit
- ML
- MLOps
- model
- model
- modern
- Memantau
- pemantauan
- lebih
- lebih efisien
- beberapa
- nama
- tentu saja
- perlu
- Perlu
- New
- berikutnya
- nLP
- Kebisingan
- pemberitahuan
- pemberitahuan
- jumlah
- of
- menawarkan
- Penawaran
- on
- ONE
- operasional
- operator
- dioptimalkan
- Opsi
- diatur
- terorganisir
- Lainnya
- di luar
- secara keseluruhan
- paket
- paket
- pengemasan
- bagian
- melewati
- Lewat
- bergairah
- path
- prestasi
- izin
- pipa saluran
- rencana
- Pesawat
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Kebijakan
- kebijaksanaan
- Pos
- praktek
- Prediksi
- sebelumnya
- Prioritaskan
- proses
- Produk
- Produksi
- proyek
- memprojeksikan
- tepat
- perlindungan
- disediakan
- pemberi
- menyediakan
- menerbitkan
- diterbitkan
- Terbit
- Penerbitan
- tujuan
- berkualitas
- jarak
- real-time
- Rekomendasi
- mengurangi
- disebut
- terdaftar
- pendaftaran
- Hubungan
- terpencil
- Terkenal
- gudang
- diminta
- permintaan
- wajib
- Persyaratan
- penelitian
- tabah
- tanggapan
- tanggung jawab
- Hasil
- pelatihan ulang
- dapat digunakan kembali
- peran
- Run
- pelari
- pembuat bijak
- sama
- terukur
- skala
- menjadwalkan
- dijadwalkan
- ilmuwan
- ilmuwan
- Kedua
- bagian
- Sektor
- keamanan
- senior
- terpisah
- Tanpa Server
- Server
- layanan
- Layanan
- porsi
- set
- penyiapan
- bayangan
- PERGESERAN
- harus
- ditunjukkan
- Sederhana
- kendur
- So
- sejauh ini
- Perangkat lunak
- larutan
- Solusi
- beberapa
- sumber
- kode sumber
- spesialis
- tertentu
- ditentukan
- Spektrum
- lampu sorot
- Tahap
- magang
- standar
- awal
- dimulai
- Negara
- Tangga
- penyimpanan
- Penyelarasan
- Streaming
- mempersingkat
- selanjutnya
- berhasil
- seperti itu
- mendukung
- Didukung
- Permukaan
- sistem
- MENANDAI
- Mengambil
- tugas
- tim
- template
- Terraform
- pengujian
- bahwa
- Grafik
- mereka
- Mereka
- karena itu
- Ini
- ancaman
- tiga
- Melalui
- di seluruh
- keluaran
- waktu
- timestamp
- untuk
- bersama
- terlalu
- alat
- alat
- puncak
- tema
- jalur
- Pelacakan
- merek dagang
- lalu lintas
- Pelatihan VE
- terlatih
- Pelatihan
- memicu
- dipicu
- MENGHIDUPKAN
- bawah
- satuan
- Serikat
- Amerika Serikat
- Pembaruan
- us
- penggunaan
- menggunakan
- gunakan case
- Pengguna
- Pengguna
- MENGESAHKAN
- pengesahan
- variabel
- berbagai
- versi
- sebenarnya
- penglihatan
- membayangkan
- vmware
- volume
- Cara..
- BAIK
- Apa
- apakah
- yang
- lebar
- Rentang luas
- dengan
- dalam
- tanpa
- Kerja
- alur kerja
- Alur kerja
- bekerja
- akan
- zephyrnet.dll
- Zip
- zona