Setiap sistem pembelajaran mesin (ML) memiliki persyaratan perjanjian tingkat layanan (SLA) unik sehubungan dengan latensi, throughput, dan metrik biaya. Dengan kemajuan dalam desain perangkat keras, berbagai infrastruktur berbasis CPU dan GPU tersedia untuk membantu Anda mempercepat kinerja inferensi. Selain itu, Anda dapat membangun sistem ML ini dengan kombinasi model, tugas, kerangka kerja, pustaka, alat, dan mesin inferensi ML, sehingga penting untuk mengevaluasi kinerja sistem ML untuk kemungkinan konfigurasi penerapan yang terbaik. Anda memerlukan rekomendasi untuk menemukan infrastruktur layanan ML yang paling hemat biaya dan kombinasi yang tepat dari konfigurasi perangkat lunak untuk mencapai performa harga terbaik untuk menskalakan aplikasi ini.
Rekomendasi Inferensi Amazon SageMaker adalah kemampuan dari Amazon SageMaker yang mengurangi waktu yang diperlukan untuk mendapatkan model ML dalam produksi dengan mengotomatiskan pengujian beban dan penyetelan model di seluruh instans SageMaker ML. Dalam posting ini, kami menyoroti beberapa pembaruan terkini untuk Inference Recommender:
- Dukungan SageMaker Python SDK untuk menjalankan Inference Recommender
- Peningkatan kegunaan Inference Recommender
- API baru yang memberikan fleksibilitas dalam menjalankan Inference Recommender
- Integrasi yang lebih dalam dengan amazoncloudwatch untuk logging dan metrik
Kasus penggunaan deteksi penipuan kartu kredit
Setiap aktivitas penipuan yang tidak terdeteksi dan segera dimitigasi dapat menyebabkan kerugian finansial yang signifikan. Khususnya, transaksi penipuan pembayaran kartu kredit perlu segera diidentifikasi untuk melindungi kesehatan keuangan individu dan perusahaan. Dalam postingan ini, kami membahas kasus penggunaan deteksi penipuan kartu kredit, dan mempelajari cara menggunakan Inference Recommender untuk menemukan jenis instans inferensi optimal dan konfigurasi sistem ML yang dapat mendeteksi transaksi kartu kredit penipuan dalam milidetik.
Kami mendemonstrasikan cara menyiapkan pekerjaan Rekomendasi Inferensi untuk kasus penggunaan deteksi penipuan kartu kredit. Kami melatih model XGBoost untuk tugas klasifikasi pada kumpulan data penipuan kartu kredit. Kami menggunakan Inference Recommender dengan muatan khusus untuk memenuhi persyaratan SLA inferensi untuk memenuhi konkurensi puncak 30,000 transaksi per menit sambil menyajikan hasil prediksi dalam waktu kurang dari 100 milidetik. Berdasarkan rekomendasi jenis instans Inference Recommender, kami dapat menemukan instans ML penayangan real-time yang tepat yang menghasilkan performa harga yang tepat untuk kasus penggunaan ini. Terakhir, kami menerapkan model ke titik akhir real-time SageMaker untuk mendapatkan hasil prediksi.
Tabel berikut meringkas detail kasus penggunaan kami.
| Kerangka Model | XGBoost |
| Ukuran Model | 10 MB |
| Latensi ujung ke ujung | milidetik 100 |
| Panggilan per Detik | 500 (30,000 per menit) |
| Tugas ML | Klasifikasi Biner |
| Muatan Masukan | 10 KB |
Kami menggunakan kumpulan data penipuan kartu kredit yang dibuat secara sintetis. Dataset berisi 28 fitur numerik, waktu transaksi, jumlah transaksi, dan variabel target kelas. Itu class kolom sesuai dengan apakah atau tidak transaksi penipuan. Sebagian besar data adalah non-penipuan (284,315 sampel), dengan hanya 492 sampel yang sesuai dengan contoh penipuan. Dalam datanya, Class adalah variabel klasifikasi target (fraudulent vs. non-fraudulent) di kolom pertama, diikuti oleh variabel lainnya.
Di bagian berikut, kami menunjukkan cara menggunakan Inference Recommender untuk mendapatkan rekomendasi jenis instans hosting ML dan menemukan konfigurasi model yang optimal untuk mencapai performa harga yang lebih baik untuk aplikasi inferensi Anda.
Jenis dan konfigurasi instans ML mana yang harus Anda pilih?
Dengan Inference Recommender, Anda dapat menjalankan dua jenis pekerjaan: default dan lanjutan.
Tugas Instance Recommender default menjalankan serangkaian pengujian beban untuk merekomendasikan jenis instans ML yang tepat untuk setiap kasus penggunaan ML. Penerapan real-time SageMaker mendukung berbagai instans ML untuk menghosting dan melayani model XGBoost deteksi penipuan kartu kredit. Pekerjaan default dapat menjalankan uji beban pada pilihan instans yang Anda berikan dalam konfigurasi pekerjaan. Jika Anda sudah memiliki titik akhir untuk kasus penggunaan ini, Anda dapat menjalankan tugas ini untuk menemukan jenis instans berperforma hemat biaya. Inference Recommender akan mengompilasi dan mengoptimalkan model untuk perangkat keras tertentu yang menggunakan jenis instans titik akhir inferensi Amazon SageMaker Neo. Penting untuk dicatat bahwa tidak semua kompilasi menghasilkan peningkatan kinerja. Rekomendasi Inferensi akan melaporkan detail kompilasi ketika kondisi berikut terpenuhi:
- Kompilasi model yang berhasil menggunakan Neo. Mungkin ada masalah dalam proses kompilasi seperti payload yang tidak valid, tipe data, atau lainnya. Dalam hal ini, informasi kompilasi tidak tersedia.
- Inferensi berhasil menggunakan model yang disusun yang menunjukkan peningkatan kinerja, yang muncul dalam respon pekerjaan inferensi.
Tugas tingkat lanjut adalah tugas uji beban kustom yang memungkinkan Anda melakukan tolok ukur ekstensif berdasarkan persyaratan SLA aplikasi ML, seperti latensi, konkurensi, dan pola lalu lintas. Anda dapat mengonfigurasi pola lalu lintas ubahsuaian untuk mensimulasikan transaksi kartu kredit. Selain itu, Anda dapat menentukan latensi model end-to-end untuk memprediksi apakah suatu transaksi curang dan menentukan transaksi bersamaan maksimum ke model untuk prediksi. Inference Recommender menggunakan informasi ini untuk menjalankan uji beban tolok ukur kinerja. Latensi, konkurensi, dan metrik biaya dari tugas tingkat lanjut membantu Anda membuat keputusan yang tepat tentang infrastruktur layanan ML untuk aplikasi penting.
Ikhtisar solusi
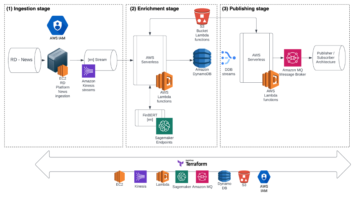
Diagram berikut menunjukkan arsitektur solusi untuk melatih model XGBoost pada kumpulan data penipuan kartu kredit, menjalankan tugas default untuk rekomendasi jenis instans, dan melakukan pengujian beban untuk menentukan konfigurasi inferensi optimal untuk kinerja harga terbaik.
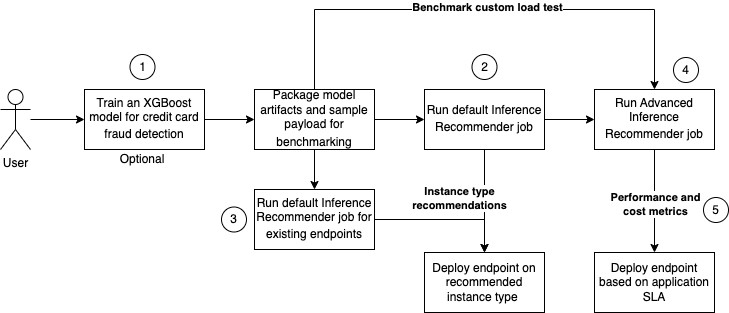
Diagram menunjukkan langkah-langkah berikut:
- Latih model XGBoost untuk mengklasifikasikan transaksi kartu kredit sebagai penipuan atau sah. Terapkan model terlatih ke titik akhir waktu-nyata SageMaker. Kemas artefak model dan contoh muatan (format .tar.gz), dan unggah ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) sehingga Inference Recommender dapat menggunakan ini saat pekerjaan dijalankan. Perhatikan bahwa langkah pelatihan dalam posting ini adalah opsional.
- Konfigurasikan dan jalankan tugas Inference Recommender default pada daftar jenis instans yang didukung untuk menemukan jenis instans ML yang tepat yang memberikan performa harga terbaik untuk kasus penggunaan ini.
- Secara opsional, jalankan tugas Inference Recommender default pada endpoint yang sudah ada.
- Mengonfigurasi dan menjalankan tugas Inference Recommender lanjutan untuk melakukan uji beban kustom guna mensimulasikan interaksi pengguna dengan aplikasi deteksi penipuan kartu kredit. Ini membantu Anda menemukan konfigurasi yang tepat untuk memenuhi latensi, konkurensi, dan biaya untuk kasus penggunaan ini.
- Menganalisis hasil tugas Inference Recommender default dan lanjutan, yang mencakup latensi rekomendasi jenis instans ML, performa, dan metrik biaya.
Contoh lengkap tersedia di GitHub kami buku catatan.
Prasyarat
Untuk menggunakan Inference Recommender, pastikan untuk memenuhi prasyarat.
Dukungan Python SDK untuk Inference Recommender
Kami baru-baru ini merilis dukungan Python SDK untuk Inference Recommender. Anda sekarang dapat menjalankan pekerjaan default dan lanjutan menggunakan satu fungsi: ukuran yang tepat. Berdasarkan parameter pemanggilan fungsi, Inference Recommender menyimpulkan apakah harus menjalankan pekerjaan default atau lanjutan. Ini sangat menyederhanakan penggunaan Inference Recommender menggunakan Python SDK. Untuk menjalankan tugas Inference Recommender, selesaikan langkah-langkah berikut:
- Buat model SageMaker dengan menentukan kerangka kerja, versi, dan cakupan gambar:
- Secara opsional, daftarkan model di Registri model SageMaker. Perhatikan bahwa parameter seperti domain dan tugas selama pembuatan paket model juga merupakan parameter opsional dalam rilis terbaru.
- Jalankan
right_sizeberfungsi pada jenis instans inferensi ML yang didukung menggunakan konfigurasi berikut. Karena XGBoost adalah algoritme intensif memori, kami menyediakan instans tipe ml.m5 untuk mendapatkan rekomendasi tipe instans. Anda dapat menghubungiright_sizeberfungsi pada objek registri model juga. - Tentukan parameter tambahan untuk
right_sizeberfungsi untuk menjalankan pekerjaan tingkat lanjut dan uji beban khusus pada model:- Konfigurasikan pola lalu lintas menggunakan
phasesparameter. Pada fase pertama, kami memulai uji beban dengan dua pengguna awal dan membuat dua pengguna baru untuk setiap menit selama 2 menit. Pada fase berikutnya, kami memulai uji beban dengan enam pengguna awal dan membuat dua pengguna baru untuk setiap menit selama 2 menit. Kondisi penghentian untuk uji beban adalah p95 latensi ujung ke ujung 100 milidetik dan konkurensi untuk mendukung 30,000 transaksi per menit atau 500 transaksi per detik. - Kami menyesuaikan titik akhir dengan variabel lingkungan
OMP_NUM_THREADSdengan nilai-nilai[3,4,5]dan kami bertujuan untuk membatasi persyaratan latensi hingga 100 milidetik dan mencapai konkurensi maksimal 30,000 pemanggilan per menit. Tujuannya adalah untuk menemukan nilai untuk apaOMP_NUM_THREADSmemberikan kinerja terbaik.
- Konfigurasikan pola lalu lintas menggunakan
Jalankan pekerjaan Inference Recommender menggunakan Boto3 API
Anda dapat menggunakan Boto3 API untuk meluncurkan Inference Recommender default dan pekerjaan tingkat lanjut. Anda perlu menggunakan Boto3 API (buat_inferensi_rekomendasi_pekerjaan) untuk menjalankan tugas Inference Recommender pada endpoint yang sudah ada. Inference Recommender menyimpulkan kerangka kerja dan versi dari titik akhir real-time SageMaker yang ada. Python SDK tidak mendukung menjalankan pekerjaan Inference Recommender pada titik akhir yang ada.
Cuplikan kode berikut menunjukkan cara membuat tugas default:
Nanti di postingan ini, kami membahas parameter yang diperlukan untuk mengonfigurasi pekerjaan tingkat lanjut.
Konfigurasikan pola lalu lintas menggunakan TrafficPattern parameter. Pada fase pertama, kami memulai uji beban dengan dua pengguna awal (InitialNumberOfUsers) dan buat dua pengguna baru (SpawnRate) untuk setiap menit selama 2 menit (DurationInSeconds). Pada fase berikutnya, kami memulai uji beban dengan enam pengguna awal dan membuat dua pengguna baru untuk setiap menit selama 2 menit. kondisi berhenti (StoppingConditions) untuk uji beban adalah latensi end-to-end p95 (ModelLatencyThresholds) dari 100 milidetik (ValueInMilliseconds) dan konkurensi untuk mendukung 30,000 transaksi per menit atau 500 transaksi per detik (MaxInvocations). Lihat kode berikut:
Hasil dan metrik pekerjaan Inference Recommender
Hasil pekerjaan Inference Recommender default berisi daftar rekomendasi konfigurasi titik akhir, termasuk jenis instans, jumlah instans, dan variabel lingkungan. Hasilnya berisi konfigurasi untuk SAGEMAKER_MODEL_SERVER_WORKERS dan OMP_NUM_THREADS terkait dengan metrik latensi, konkurensi, dan throughput. OMP_NUM_THREADS adalah parameter lingkungan merdu server model. Seperti yang ditunjukkan pada detail di tabel berikut, dengan instance ml.m5.4xlarge dengan SAGEMAKER_MODEL_SERVER_WORKERS=3 dan OMP_NUM_THREADS=3, kami mendapatkan throughput 32,628 pemanggilan per menit dan latensi model di bawah 10 milidetik. ml.m5.4xlarge memiliki peningkatan latensi 100%, peningkatan konkurensi sekitar 115% dibandingkan dengan konfigurasi instans ml.m5.xlarge. Selain itu, 66% lebih hemat biaya dibandingkan dengan konfigurasi instans ml.m5.12xlarge sekaligus mencapai latensi dan throughput yang sebanding.
| Jenis Mesin Virtual | Hitungan Instance Awal | OMP_NUM_THREADS | Biaya Per Jam | Doa Maks | Latensi Model | Pemanfaatan CPU | Pemanfaatan Memori | Pekerja Server Model SageMaker |
| ml.m5.xbesar | 1 | 2 | 0.23 | 15189 | 18 | 108.864 | 1.62012 | 1 |
| ml.m5.4lebih besar | 1 | 3 | 0.922 | 32628 | 9 | 220.57001 | 0.69791 | 3 |
| ml.m5.besar | 1 | 2 | 0.115 | 13793 | 19 | 106.34 | 3.24398 | 1 |
| ml.m5.12lebih besar | 1 | 4 | 2.765 | 32016 | 4 | 215.32401 | 0.44658 | 7 |
| ml.m5.2lebih besar | 1 | 2 | 0.461 | 32427 | 13 | 248.673 | 1.43109 | 3 |
Kami telah menyertakan fungsi pembantu CloudWatch di notebook. Anda dapat menggunakan fungsi untuk mendapatkan bagan terperinci dari titik akhir Anda selama uji beban. Bagan memiliki detail tentang metrik pemanggilan seperti pemanggilan, latensi model, latensi overhead, dan lainnya, serta metrik instans seperti CPUUtilization dan MemoryUtilization. Contoh berikut menampilkan metrik CloudWatch untuk konfigurasi model ml.m5.4xlarge kami.

Anda dapat memvisualisasikan hasil pekerjaan Inference Recommender Studio Amazon SageMaker dengan memilih Rekomendasi Inferensi bawah penyebaran di panel navigasi. Dengan sasaran penerapan untuk kasus penggunaan ini (latensi tinggi, throughput tinggi, biaya default), tugas Inference Recommender default merekomendasikan instans ml.m5.4xlarge karena memberikan kinerja latensi dan throughput terbaik untuk mendukung maksimal 34,600 pemanggilan per menit ( 576TPS). Anda dapat menggunakan metrik ini untuk menganalisis dan menemukan konfigurasi terbaik yang memenuhi persyaratan latensi, konkurensi, dan biaya aplikasi ML Anda.

Kami baru saja memperkenalkan ListInferenceRecommendationsJobSteps, yang memungkinkan Anda menganalisis subtugas dalam tugas Inference Recommender. Cuplikan kode berikut menunjukkan cara menggunakan list_inference_recommendations_job_steps API Boto3 untuk mendapatkan daftar subtugas. Ini dapat membantu dengan debugging kegagalan pekerjaan Inference Recommender pada tingkat langkah. Fungsionalitas ini belum didukung di Python SDK.
Kode berikut menunjukkan respons:
Jalankan tugas Inference Recommender tingkat lanjut
Selanjutnya, kami menjalankan tugas Inference Recommender lanjutan untuk menemukan konfigurasi yang optimal seperti SAGEMAKER_MODEL_SERVER_WORKERS dan OMP_NUM_THREADS pada tipe instans ml.m5.4xlarge. Kami menyetel hyperparameter tugas lanjutan untuk menjalankan uji beban pada kombinasi yang berbeda:
Anda dapat melihat hasil pekerjaan Inference Recommender lanjutan di konsol Studio, seperti yang ditunjukkan pada tangkapan layar berikut.

Dengan menggunakan perintah Boto3 API atau CLI, Anda dapat mengakses semua metrik dari hasil pekerjaan Inference Recommender tingkat lanjut. InitialInstanceCount adalah jumlah instance yang harus Anda sediakan di endpoint untuk dipenuhi ModelLatencyThresholds dan MaxInvocations disebutkan dalam StoppingConditions. Tabel berikut merangkum hasil kami.
| Jenis Mesin Virtual | Hitungan Instance Awal | OMP_NUM_THREADS | Biaya Per Jam | Doa Maks | Latensi Model | Pemanfaatan CPU | Pemanfaatan Memori |
| ml.m5.2lebih besar | 2 | 3 | 0.922 | 39688 | 6 | 86.732803 | 3.04769 |
| ml.m5.2lebih besar | 2 | 4 | 0.922 | 42604 | 6 | 177.164993 | 3.05089 |
| ml.m5.2lebih besar | 2 | 5 | 0.922 | 39268 | 6 | 125.402 | 3.08665 |
| ml.m5.4lebih besar | 2 | 3 | 1.844 | 38174 | 4 | 102.546997 | 2.68003 |
| ml.m5.4lebih besar | 2 | 4 | 1.844 | 39452 | 4 | 141.826004 | 2.68136 |
| ml.m5.4lebih besar | 2 | 5 | 1.844 | 40472 | 4 | 107.825996 | 2.70936 |
Membersihkan
Ikuti petunjuk di notebook untuk menghapus semua sumber daya yang dibuat sebagai bagian dari postingan ini untuk menghindari biaya tambahan.
Kesimpulan
Menemukan infrastruktur layanan ML yang tepat, termasuk jenis instans, konfigurasi model, dan kebijakan penskalaan otomatis, bisa jadi membosankan. Posting ini menunjukkan bagaimana Anda dapat menggunakan Inference Recommender Python SDK dan Boto3 API untuk meluncurkan pekerjaan default dan lanjutan untuk menemukan infrastruktur dan konfigurasi inferensi yang optimal. Kami juga membahas peningkatan baru pada Inference Recommender, termasuk dukungan Python SDK dan peningkatan kegunaan. Lihat kami Repositori GitHub untuk memulai.
Tentang Penulis
 Shiva Raaj Kotini bekerja sebagai Manajer Produk Utama dalam portofolio produk inferensi AWS SageMaker. Dia berfokus pada penerapan model, penyetelan kinerja, dan pengoptimalan di SageMaker untuk inferensi.
Shiva Raaj Kotini bekerja sebagai Manajer Produk Utama dalam portofolio produk inferensi AWS SageMaker. Dia berfokus pada penerapan model, penyetelan kinerja, dan pengoptimalan di SageMaker untuk inferensi.
 John Barboza adalah Insinyur Perangkat Lunak di AWS. Dia memiliki pengalaman luas bekerja pada sistem terdistribusi. Fokusnya saat ini adalah meningkatkan pengalaman inferensi SageMaker. Di waktu luangnya, ia menikmati memasak dan bersepeda.
John Barboza adalah Insinyur Perangkat Lunak di AWS. Dia memiliki pengalaman luas bekerja pada sistem terdistribusi. Fokusnya saat ini adalah meningkatkan pengalaman inferensi SageMaker. Di waktu luangnya, ia menikmati memasak dan bersepeda.
 Mohan Gandhi adalah Insinyur Perangkat Lunak Senior di AWS. Dia telah bersama AWS selama 10 tahun terakhir dan telah bekerja di berbagai layanan AWS seperti Amazon EMR, Amazon EFA, dan Amazon RDS. Saat ini, dia berfokus pada peningkatan pengalaman inferensi SageMaker. Di waktu luangnya, ia menikmati hiking dan maraton.
Mohan Gandhi adalah Insinyur Perangkat Lunak Senior di AWS. Dia telah bersama AWS selama 10 tahun terakhir dan telah bekerja di berbagai layanan AWS seperti Amazon EMR, Amazon EFA, dan Amazon RDS. Saat ini, dia berfokus pada peningkatan pengalaman inferensi SageMaker. Di waktu luangnya, ia menikmati hiking dan maraton.
 Ram Vegaraju adalah Arsitek ML dengan tim layanan SageMaker. Dia berfokus untuk membantu pelanggan membangun dan mengoptimalkan solusi AI/ML mereka di Amazon SageMaker. Di waktu luangnya, ia suka bepergian dan menulis.
Ram Vegaraju adalah Arsitek ML dengan tim layanan SageMaker. Dia berfokus untuk membantu pelanggan membangun dan mengoptimalkan solusi AI/ML mereka di Amazon SageMaker. Di waktu luangnya, ia suka bepergian dan menulis.
 Vikram Elango adalah Sr. AIML Specialist Solutions Architect di AWS, berbasis di Virginia USA. Dia saat ini berfokus pada AI Generatif, LLM, rekayasa cepat, pengoptimalan inferensi model besar, dan penskalaan ML di seluruh perusahaan. Vikram membantu pelanggan industri keuangan dan asuransi dengan desain, pemikiran kepemimpinan untuk membangun dan menerapkan aplikasi pembelajaran mesin dalam skala besar. Di waktu senggangnya, ia senang bepergian, hiking, memasak, dan berkemah bersama keluarganya.
Vikram Elango adalah Sr. AIML Specialist Solutions Architect di AWS, berbasis di Virginia USA. Dia saat ini berfokus pada AI Generatif, LLM, rekayasa cepat, pengoptimalan inferensi model besar, dan penskalaan ML di seluruh perusahaan. Vikram membantu pelanggan industri keuangan dan asuransi dengan desain, pemikiran kepemimpinan untuk membangun dan menerapkan aplikasi pembelajaran mesin dalam skala besar. Di waktu senggangnya, ia senang bepergian, hiking, memasak, dan berkemah bersama keluarganya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/improved-ml-model-deployment-using-amazon-sagemaker-inference-recommender/
- :memiliki
- :adalah
- :bukan
- $NAIK
- 000
- 1
- 10
- 100
- 116
- 20
- 200
- 2023
- 28
- 9
- a
- Tentang Kami
- mengakses
- Mencapai
- mencapai
- di seluruh
- kegiatan
- Tambahan
- Selain itu
- memajukan
- maju
- kemajuan
- terhadap
- Persetujuan
- AI
- AI / ML
- AIML
- algoritma
- Semua
- memungkinkan
- juga
- Amazon
- Amazon ESDM
- Amazon RDS
- Amazon SageMaker
- jumlah
- an
- menganalisa
- dan
- Apa pun
- api
- Lebah
- Aplikasi
- aplikasi
- disetujui
- arsitektur
- ADALAH
- AS
- terkait
- At
- mobil
- mengotomatisasi
- tersedia
- menghindari
- AWS
- berdasarkan
- BE
- karena
- menjadi
- patokan
- Benchmark
- TERBAIK
- Lebih baik
- membangun
- by
- panggilan
- berkemah
- CAN
- kartu
- kasus
- Menyebabkan
- beban
- Charts
- memeriksa
- memilih
- kelas
- klasifikasi
- Klasifikasi
- kode
- Kolom
- kombinasi
- kombinasi
- Perusahaan
- sebanding
- dibandingkan
- lengkap
- Lengkap
- bersamaan
- Kondisi
- konfigurasi
- konfigurasi
- konsul
- mengandung
- memasak
- Sesuai
- berkorespondensi
- Biaya
- hemat biaya
- bisa
- membuat
- dibuat
- penciptaan
- kredit
- kartu kredit
- terbaru
- Sekarang
- adat
- pelanggan
- data
- Tanggal
- memutuskan
- keputusan
- Default
- mendemonstrasikan
- menyebarkan
- penyebaran
- Mendesain
- terperinci
- rincian
- terdeteksi
- Deteksi
- berbeda
- membahas
- dibahas
- didistribusikan
- sistem terdistribusi
- Tidak
- domain
- selama
- ujung ke ujung
- Titik akhir
- insinyur
- Teknik
- Mesin
- perusahaan
- Lingkungan Hidup
- Eter (ETH)
- mengevaluasi
- Setiap
- contoh
- contoh
- ada
- pengalaman
- luas
- Pengalaman yang luas
- keluarga
- Fitur
- Februari
- Akhirnya
- keuangan
- kesehatan keuangan
- Menemukan
- temuan
- Pertama
- keluwesan
- Fokus
- terfokus
- berfokus
- diikuti
- berikut
- Untuk
- format
- Kerangka
- kerangka
- penipuan
- deteksi penipuan
- curang
- aktivitas penipuan
- dari
- fungsi
- fungsi
- fungsi
- generatif
- AI generatif
- mendapatkan
- GitHub
- memberikan
- GMT
- tujuan
- sangat
- Perangkat keras
- desain perangkat keras
- Memiliki
- he
- Kesehatan
- membantu
- membantu
- membantu
- High
- Menyoroti
- mendaki
- tuan rumah
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- diidentifikasi
- gambar
- segera
- mengimpor
- penting
- ditingkatkan
- perbaikan
- perbaikan
- meningkatkan
- in
- memasukkan
- termasuk
- Termasuk
- Meningkatkan
- industri
- Info
- informasi
- informasi
- Infrastruktur
- infrastruktur
- mulanya
- contoh
- instruksi
- asuransi
- industri asuransi
- integrasi
- interaksi
- diperkenalkan
- masalah
- IT
- Pekerjaan
- Jobs
- jpg
- kunci
- besar
- Terakhir
- Latensi
- jalankan
- Kepemimpinan
- BELAJAR
- pengetahuan
- Legit
- Tingkat
- perpustakaan
- 'like'
- MEMBATASI
- Daftar
- memuat
- lepas
- mesin
- Mesin belajar
- Mayoritas
- membuat
- Membuat
- manajer
- max
- maksimum
- Pelajari
- tersebut
- Metrik
- menit
- menit
- ML
- model
- model
- lebih
- paling
- nama
- Navigasi
- Perlu
- dibutuhkan
- NEO
- New
- pengguna baru
- buku catatan
- sekarang
- jumlah
- obyek
- of
- on
- hanya
- optimal
- optimasi
- Optimize
- or
- Lainnya
- kami
- paket
- pane
- parameter
- parameter
- bagian
- khususnya
- pola
- pembayaran
- Puncak
- melakukan
- prestasi
- melakukan
- tahap
- plato
- Kecerdasan Data Plato
- Data Plato
- portofolio
- mungkin
- Pos
- meramalkan
- ramalan
- Prediksi
- Utama
- proses
- Produk
- manajer produk
- Produksi
- melindungi
- memberikan
- disediakan
- menyediakan
- ketentuan
- Ular sanca
- jarak
- real-time
- baru
- baru-baru ini
- Rekomendasi
- rekomendasi
- direkomendasikan
- mengurangi
- daftar
- pendaftaran
- melepaskan
- dirilis
- melaporkan
- wajib
- kebutuhan
- Persyaratan
- Sumber
- menghormati
- tanggapan
- Hasil
- Run
- berjalan
- pembuat bijak
- Inferensi SageMaker
- Skala
- skala
- cakupan
- SDK
- Kedua
- bagian
- seleksi
- senior
- melayani
- layanan
- Layanan
- porsi
- set
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- penting
- Sederhana
- tunggal
- ENAM
- So
- Perangkat lunak
- Software Engineer
- larutan
- Solusi
- beberapa
- spesialis
- tertentu
- ditentukan
- kecepatan
- awal
- mulai
- Status
- Langkah
- Tangga
- henti
- penyimpanan
- Tali
- studio
- seperti itu
- mendukung
- Didukung
- Mendukung
- secara sintetis
- sistem
- sistem
- tabel
- target
- tugas
- tugas
- tim
- uji
- pengujian
- tes
- dari
- bahwa
- Grafik
- mereka
- Mereka
- Ini
- ini
- pikir
- pemikiran kepemimpinan
- keluaran
- waktu
- untuk
- alat
- terima kasih
- lalu lintas
- Pelatihan VE
- terlatih
- Pelatihan
- .
- Transaksi
- Perjalanan
- jenis
- bawah
- unik
- Pembaruan
- Amerika Serikat
- kegunaan
- menggunakan
- gunakan case
- Pengguna
- Pengguna
- nilai
- Nilai - Nilai
- variabel
- berbagai
- versi
- View
- virginia
- membayangkan
- vs
- adalah
- we
- BAIK
- adalah
- apakah
- yang
- sementara
- lebar
- Rentang luas
- akan
- dengan
- bekerja
- kerja
- penulisan
- XGBoost
- tahun
- Menghasilkan
- kamu
- Anda
- zephyrnet.dll