
Artikel ini awalnya diterbitkan pada MajelisAI dan diterbitkan ulang ke TOPBOTS dengan izin dari penulis.
Model Difusi adalah model generatif yang telah mendapatkan popularitas yang signifikan dalam beberapa tahun terakhir, dan untuk alasan yang baik. Beberapa makalah mani dirilis pada tahun 2020-an sendirian telah menunjukkan kepada dunia kemampuan model Difusi, seperti mengalahkan GAN[6] pada sintesis gambar. Baru-baru ini, praktisi akan melihat Model Difusi yang digunakan di DALL-E2, model pembuatan gambar OpenAI yang dirilis bulan lalu.

Mengingat gelombang kesuksesan baru-baru ini oleh Model Difusi, banyak praktisi Pembelajaran Mesin pasti tertarik dengan cara kerja mereka. Pada artikel ini, kita akan memeriksa landasan teoretis untuk Model Difusi, dan kemudian mendemonstrasikan cara menghasilkan gambar dengan a Model Difusi di PyTorch. Mari selami!
Jika konten pendidikan yang mendalam ini bermanfaat bagi Anda, berlangganan milis AI kami untuk diperingatkan ketika kami merilis materi baru.
Model Difusi – Pendahuluan
Model Difusi adalah generatif model, artinya mereka digunakan untuk menghasilkan data yang serupa dengan data tempat mereka dilatih. Pada dasarnya, Model Difusi bekerja dengan: menghancurkan data pelatihan melalui penambahan berturut-turut kebisingan Gaussian, dan kemudian belajar sembuh data menurut membalikkan proses kebisingan ini. Setelah pelatihan, kita dapat menggunakan Model Difusi untuk menghasilkan data hanya dengan melewati kebisingan sampel secara acak melalui proses denoising dipelajari.

Lebih khusus, Model Difusi adalah model variabel laten yang memetakan ke ruang laten menggunakan rantai Markov tetap. Rantai ini secara bertahap menambahkan noise ke data untuk mendapatkan perkiraan posterior q(x1: T|x0), dimana x1,…, XT adalah variabel laten dengan dimensi yang sama dengan x0. Pada gambar di bawah, kita melihat rantai Markov seperti itu dimanifestasikan untuk data gambar.
Pada akhirnya, gambar ditransformasikan secara asimtotik menjadi noise Gaussian murni. Itu tujuan pelatihan model difusi adalah untuk mempelajari membalikkan proses – yaitu pelatihan pθ(xt−1|xt). Dengan melintasi mundur sepanjang rantai ini, kita dapat menghasilkan data baru.
Manfaat Model Difusi
Seperti disebutkan di atas, penelitian Model Difusi telah meledak dalam beberapa tahun terakhir. Terinspirasi oleh termodinamika non-kesetimbangan[1], Model Difusi saat ini memproduksi Kualitas gambar tercanggih, contohnya dapat dilihat di bawah ini:
Selain kualitas gambar mutakhir, Model Difusi hadir dengan sejumlah manfaat lain, termasuk tidak membutuhkan pelatihan permusuhan. Kesulitan pelatihan permusuhan didokumentasikan dengan baik; dan, dalam kasus di mana ada alternatif non-permusuhan dengan kinerja dan efisiensi pelatihan yang sebanding, biasanya yang terbaik adalah menggunakannya. Pada topik efisiensi pelatihan, Model Difusi juga memiliki manfaat tambahan dari skalabilitas dan paralelisasi.
Sementara Model Difusi hampir tampak menghasilkan hasil dari udara tipis, ada banyak pilihan dan detail matematika yang cermat dan menarik yang memberikan dasar untuk hasil ini, dan praktik terbaik masih berkembang dalam literatur. Mari kita lihat teori matematika yang mendukung Model Difusi lebih terinci sekarang.
Model Difusi – Penyelaman Mendalam
Seperti disebutkan di atas, Model Difusi terdiri dari proses maju (Atau proses difusi), di mana sebuah datum (umumnya sebuah gambar) secara progresif berderau, dan a proses terbalik (Atau proses difusi terbalik), di mana noise diubah kembali menjadi sampel dari distribusi target.
Transisi rantai pengambilan sampel dalam proses maju dapat diatur ke Gauss bersyarat ketika tingkat kebisingan cukup rendah. Menggabungkan fakta ini dengan asumsi Markov mengarah ke parameterisasi sederhana dari proses maju:

Catatan Matematika
Kami telah berbicara tentang merusak data dengan menambahkan Kebisingan Gaussian, tetapi mungkin pada awalnya tidak jelas di mana kami melakukan penambahan ini. Menurut persamaan di atas, pada setiap langkah dalam rantai, kita hanya mengambil sampel dari distribusi Gaussian yang rata-ratanya adalah nilai sebelumnya (yaitu gambar) dalam rantai.
Kedua pernyataan ini setara. Itu adalah

Untuk memahami alasannya, kami akan menggunakan sedikit penyalahgunaan notasi dengan menyatakan


Di mana implikasi terakhir berasal dari kesetaraan matematis antara jumlah variabel acak dan konvolusi distribusinya – lihat halaman Wikipedia ini for more information.
Dengan kata lain, kami telah menunjukkan bahwa menegaskan distribusi langkah waktu yang dikondisikan pada yang sebelumnya melalui rata-rata distribusi Gaussian sama dengan menyatakan bahwa distribusi langkah waktu yang diberikan adalah yang sebelumnya dengan penambahan derau Gaussian. Kami menghilangkan skalar yang diperkenalkan oleh jadwal varians dan menunjukkan ini untuk satu dimensi untuk kesederhanaan, tetapi bukti serupa berlaku untuk Gaussian multivariat.
Dimana1,…,T adalah jadwal varians (baik dipelajari atau tetap) yang, jika berperilaku baik, memastikan itu xT hampir merupakan Gaussian isotropik untuk T yang cukup besar.

Seperti disebutkan sebelumnya, "keajaiban" model difusi datang dalam proses terbalik. Selama pelatihan, model belajar untuk membalikkan proses difusi ini untuk menghasilkan data baru. Dimulai dengan derau Gaussian murni p(xT):=N(xT,0,I) model mempelajari distribusi bersama pθ(x0: T) sebagai

di mana parameter bergantung waktu dari transisi Gaussian dipelajari. Perhatikan khususnya bahwa formulasi Markov menegaskan bahwa distribusi transisi difusi balik yang diberikan hanya bergantung pada langkah waktu sebelumnya (atau langkah waktu berikutnya, tergantung pada bagaimana Anda melihatnya):

Pelatihan
Model Difusi dilatih oleh menemukan transisi Markov terbalik yang memaksimalkan kemungkinan data pelatihan. Dalam praktiknya, pelatihan secara ekuivalen terdiri dari meminimalkan batas atas variasi pada kemungkinan log negatif.

Detail Notasi
Perhatikan bahwa LVLB secara teknis adalah atas terikat (negatif dari ELBO) yang kami coba perkecil, tetapi kami menyebutnya sebagai LVLB untuk konsistensi dengan literatur.
Kami berusaha untuk menulis ulang LVLB istilah dari Divergensi Kullback-Leibler (KL). Divergensi KL adalah ukuran jarak statistik asimetris dari seberapa banyak satu distribusi probabilitas P berbeda dari distribusi referensi Q. Kami tertarik untuk merumuskan LVLB dalam hal divergensi KL karena distribusi transisi dalam rantai Markov kami adalah Gauss, dan divergensi KL antara Gauss memiliki bentuk tertutup.
Apa itu Divergensi KL?
Bentuk matematis dari divergensi KL untuk distribusi kontinu adalah

Di bawah ini Anda dapat melihat divergensi KL dari distribusi yang bervariasi P (biru) dari distribusi referensi Q (merah). Kurva hijau menunjukkan fungsi dalam integral dalam definisi divergensi KL di atas, dan luas total di bawah kurva mewakili nilai divergensi KL dari P dari Q pada saat tertentu, nilai yang juga ditampilkan secara numerik.
Pengecoran  dalam Hal Divergensi KL
dalam Hal Divergensi KL
Seperti disebutkan sebelumnya, adalah mungkin [1] untuk menulis ulang LVLB hampir sepenuhnya dalam hal divergensi KL:

dimana

Detail Derivasi
Batas variasi sama dengan

Mengganti distribusi dengan definisi mereka dengan asumsi Markov kami, kami mendapatkan

Kami menggunakan aturan log untuk mengubah ekspresi menjadi jumlah log, dan kemudian kami mengeluarkan istilah pertama

Menggunakan Teorema Bayes dan asumsi Markov kami, ekspresi ini menjadi

Kami kemudian membagi istilah tengah menggunakan aturan log
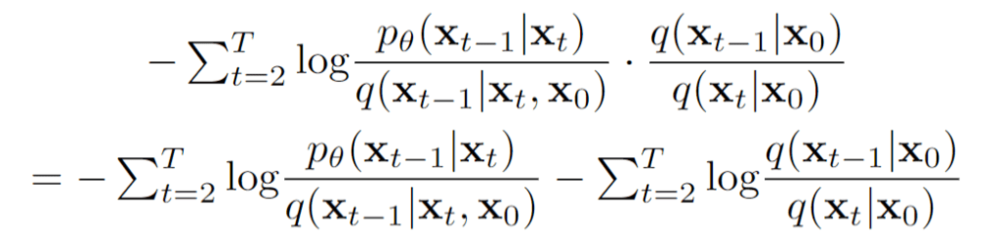
Mengisolasi suku kedua, kita lihat

Memasukkan ini kembali ke persamaan kami untuk LVLB, kita punya

Menggunakan aturan log, kami mengatur ulang

Selanjutnya, kami mencatat kesetaraan berikut untuk divergensi KL untuk dua distribusi apa pun:

Akhirnya, dengan menerapkan kesetaraan ini pada ekspresi sebelumnya, kita sampai pada

Mengkondisikan proses maju ke belakang pada x0 di Lt−1 menghasilkan bentuk penurut yang mengarah ke semua divergensi KL menjadi perbandingan antara Gaussians. Ini berarti bahwa divergensi dapat dihitung secara tepat dengan ekspresi bentuk tertutup daripada dengan perkiraan Monte Carlo[3].
Pilihan Model
Dengan dasar matematis untuk fungsi tujuan kita, kita sekarang perlu membuat beberapa pilihan mengenai bagaimana Model Difusi kita akan diimplementasikan. Untuk proses forward, satu-satunya pilihan yang diperlukan adalah mendefinisikan jadwal varians, yang nilainya umumnya meningkat selama proses forward.
Untuk proses sebaliknya, kami lebih memilih parameterisasi distribusi/arsitektur model Gaussian. Perhatikan tingkat fleksibilitas yang tinggi bahwa Model Difusi mampu – the hanya persyaratan pada arsitektur kami adalah bahwa input dan output memiliki dimensi yang sama.
Kami akan mengeksplorasi rincian pilihan ini secara lebih rinci di bawah ini.
Proses Maju dan LT
Seperti disebutkan di atas, mengenai proses maju, kita harus menentukan jadwal varians. Secara khusus, kami mengaturnya menjadi konstanta bergantung waktu, mengabaikan fakta bahwa mereka dapat dipelajari. Sebagai contoh[3], jadwal linier dari1= 10-4 untukT=0.2 dapat digunakan, atau mungkin deret geometri.
Terlepas dari nilai-nilai tertentu yang dipilih, fakta bahwa jadwal varians adalah hasil tetap dalam LT menjadi konstan sehubungan dengan set parameter yang dapat dipelajari, memungkinkan kita untuk mengabaikannya sejauh menyangkut pelatihan.

Proses Terbalik dan L1:T−1
Sekarang kita membahas pilihan yang diperlukan dalam mendefinisikan proses sebaliknya. Ingat dari atas kita mendefinisikan transisi Markov terbalik sebagai Gaussian:

Kita sekarang harus mendefinisikan bentuk-bentuk fungsional dariθ atauθ. Meskipun ada cara yang lebih rumit untuk membuat parameterθ[5], kita cukup mengatur

Artinya, kita berasumsi bahwa Gaussian multivariat adalah produk dari Gaussian independen dengan varians identik, nilai varians yang dapat berubah dengan waktu. Kita atur varians ini agar setara dengan jadwal varians proses maju kami.
Mengingat formulasi baru dariθ, kita punya

yang memungkinkan kita untuk berubah

untuk

di mana suku pertama dalam perbedaan adalah kombinasi linier dari xt dan x0 itu tergantung pada jadwal varianst. Bentuk pasti dari fungsi ini tidak relevan untuk tujuan kita, tetapi dapat ditemukan di [3].
Arti penting dari proporsi di atas adalah bahwa parameterisasi paling sederhana dariθ hanya memprediksi rata-rata posterior difusi. Yang penting, penulis [3] benar-benar menemukan bahwa pelatihanθ untuk memprediksi kebisingan komponen pada setiap langkah waktu tertentu menghasilkan hasil yang lebih baik. Secara khusus, mari

dimana

Ini mengarah ke fungsi kerugian alternatif berikut:, yang penulis [3] ditemukan mengarah pada pelatihan yang lebih stabil dan hasil yang lebih baik:

Para penulis [3] juga perhatikan hubungan formulasi Model Difusi ini dengan model generatif pencocokan skor berdasarkan dinamika Langevin. Memang, tampaknya Model Difusi dan model Berbasis Skor mungkin merupakan dua sisi dari mata uang yang sama, mirip dengan pengembangan mekanika kuantum berbasis gelombang yang independen dan bersamaan dan mekanika kuantum berbasis matriks yang mengungkapkan dua formulasi setara dari fenomena yang sama.[2].
Arsitektur jaringan
Sementara fungsi kerugian kami yang disederhanakan berusaha untuk melatih modelθ, kita masih belum mendefinisikan arsitektur model ini. Perhatikan bahwa hanya persyaratan untuk model adalah bahwa dimensi input dan outputnya identik.
Mengingat batasan ini, mungkin tidak mengejutkan bahwa Model Difusi gambar umumnya diimplementasikan dengan arsitektur mirip U-Net.

Dekoder Proses Terbalik dan L0
Jalur sepanjang proses sebaliknya terdiri dari banyak transformasi di bawah distribusi Gaussian bersyarat terus menerus. Pada akhir proses sebaliknya, ingatlah bahwa kita mencoba untuk menghasilkan gambar, yang terdiri dari nilai piksel bilangan bulat. Oleh karena itu, kita harus memikirkan cara untuk mendapatkan diskrit (log) kemungkinan untuk setiap kemungkinan nilai piksel di semua piksel.
Cara yang dilakukan adalah dengan mengatur transisi terakhir dalam rantai difusi terbalik ke dekoder diskrit independen. Menentukan peluang munculnya bayangan x0 diberikan x1, pertama-tama kita memaksakan independensi antara dimensi data:

di mana D adalah dimensi data dan superskrip i menunjukkan ekstraksi satu koordinat. Tujuannya sekarang adalah untuk menentukan seberapa besar kemungkinan setiap nilai integer untuk piksel tertentu diberikan distribusi di seluruh nilai yang mungkin untuk piksel yang sesuai dalam gambar yang sedikit terganggu pada waktu t=1:

di mana distribusi piksel untuk t=1 diturunkan dari Gaussian multivariat di bawah ini yang matriks kovarians diagonalnya memungkinkan kita untuk membagi distribusi menjadi produk Gaussian univariat, satu untuk setiap dimensi data:

Kami berasumsi bahwa gambar terdiri dari bilangan bulat dalam 0,1,…,255 (seperti gambar RGB standar) yang telah diskalakan secara linier ke [−1,1]. Kami kemudian memecah garis nyata menjadi "ember" kecil, di mana, untuk nilai piksel skala tertentu x, bucket untuk rentang tersebut adalah [x−1/255, x+1/255]. Probabilitas nilai piksel x, diberikan distribusi Gaussian univariat dari piksel yang sesuai dalam x1, adalah area di bawah distribusi Gaussian univariat dalam bucket yang berpusat di x.
Di bawah ini Anda dapat melihat area untuk masing-masing ember ini dengan probabilitasnya untuk mean-0 Gaussian yang, dalam konteks ini, sesuai dengan distribusi dengan nilai piksel rata-rata 255/2 (setengah kecerahan). Kurva merah mewakili distribusi piksel tertentu di t = 1 gambar, dan area memberikan probabilitas nilai piksel yang sesuai di t = 0 gambar.
Catatan Teknis
Bucket pertama dan terakhir meluas ke -inf dan +inf untuk mempertahankan probabilitas total.
Diberikan a t = 0 nilai piksel untuk setiap piksel, nilai pθ(x0|x1) hanyalah produk mereka. Proses ini secara ringkas diringkas oleh persamaan berikut:

dimana

dan

Mengingat persamaan ini untuk pθ(x0|x1), kita dapat menghitung suku akhir dari LVLB yang tidak dirumuskan sebagai KL Divergence:

Tujuan Akhir
Seperti disebutkan di bagian terakhir, penulis [3] menemukan bahwa memprediksi komponen noise dari suatu gambar pada langkah waktu tertentu menghasilkan hasil terbaik. Pada akhirnya, mereka menggunakan tujuan berikut:

Oleh karena itu, algoritma pelatihan dan pengambilan sampel untuk Model Difusi kami dapat secara ringkas ditangkap pada gambar di bawah ini:
Ringkasan Teori Model Difusi
Pada bagian ini kita menyelami teori Model Difusi secara mendetail. Sangat mudah untuk terjebak dalam detail matematika, jadi kami mencatat poin terpenting dalam bagian di bawah ini untuk menjaga diri kami tetap berorientasi dari perspektif mata burung:
- Model Difusi kami diparameterisasi sebagai Rantai Markov, artinya variabel laten kita x1,…, XT hanya bergantung pada langkah waktu sebelumnya (atau mengikuti).
- Grafik distribusi transisi dalam rantai Markov adalah Gaussian, di mana proses maju membutuhkan jadwal varians, dan parameter proses sebaliknya dipelajari.
- Proses difusi memastikan bahwa xT is terdistribusi asimtotik sebagai Gaussian isotropik untuk T yang cukup besar.
- Dalam kasus kami, jadwal varians telah diperbaiki, tapi juga bisa dipelajari. Untuk jadwal tetap, mengikuti deret geometri mungkin memberikan hasil yang lebih baik daripada deret linier. Dalam kedua kasus, varians umumnya meningkat dengan waktu dalam seri (yaitui<βj untuk saya
- Model Difusi adalah sangat fleksibel dan izinkan Apa pun arsitektur yang dimensi input dan outputnya sama untuk digunakan. Banyak implementasi menggunakan Seperti U-Net ilmu bangunan.
- Grafik tujuan pelatihan adalah untuk memaksimalkan kemungkinan data pelatihan. Ini dimanifestasikan sebagai penyetelan parameter model ke meminimalkan batas atas variasi dari kemungkinan log negatif data.
- Hampir semua suku dalam fungsi tujuan dapat dijadikan sebagai Divergensi KL sebagai hasil dari asumsi Markov kami. Nilai-nilai ini menjadi dapat dipertahankan untuk dihitung mengingat bahwa kami menggunakan Gaussians, oleh karena itu menghilangkan kebutuhan untuk melakukan pendekatan Monte Carlo.
- Pada akhirnya, menggunakan tujuan pelatihan yang disederhanakan untuk melatih fungsi yang memprediksi komponen kebisingan dari variabel laten yang diberikan menghasilkan hasil terbaik dan paling stabil.
- A dekoder diskrit digunakan untuk mendapatkan kemungkinan log di seluruh nilai piksel sebagai langkah terakhir dalam proses difusi terbalik.
Dengan gambaran umum Model Difusi tingkat tinggi ini di benak kita, mari kita lanjutkan untuk melihat cara menggunakan Model Difusi di PyTorch.
Model Difusi di PyTorch
Sementara Model Difusi belum didemokratisasi ke tingkat yang sama seperti arsitektur/pendekatan lama lainnya dalam Pembelajaran Mesin, masih ada implementasi yang tersedia untuk digunakan. Cara termudah untuk menggunakan Model Difusi di PyTorch adalah dengan menggunakan denoising-diffusion-pytorch package, yang mengimplementasikan model difusi gambar seperti yang dibahas dalam artikel ini. Untuk menginstal paket, cukup ketik perintah berikut di terminal:
pip install denoising_diffusion_pytorch
Contoh Minimal
Untuk melatih model dan menghasilkan gambar, pertama-tama kita mengimpor paket yang diperlukan:
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
Selanjutnya, kami mendefinisikan arsitektur jaringan kami, dalam hal ini U-Net. Itu dim parameter menentukan jumlah peta fitur sebelum down-sampling pertama, dan dim_mults parameter memberikan penggandaan untuk nilai ini dan pengambilan sampel yang berurutan:
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
Sekarang setelah arsitektur jaringan kita didefinisikan, kita perlu mendefinisikan Model Difusi itu sendiri. Kami memberikan model U-Net yang baru saja kami definisikan bersama dengan beberapa parameter – ukuran gambar yang akan dihasilkan, jumlah langkah waktu dalam proses difusi, dan pilihan antara norma L1 dan L2.
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
Sekarang Model Difusi didefinisikan, saatnya untuk melatih. Kami menghasilkan data acak untuk dilatih, dan kemudian melatih Model Difusi dengan cara biasa:
training_images = torch.randn(8, 3, 128, 128)
loss = diffusion(training_images)
loss.backward()
Setelah model dilatih, kami akhirnya dapat menghasilkan gambar dengan menggunakan sample() metode dari diffusion obyek. Di sini kami menghasilkan 4 gambar, yang hanya noise karena data pelatihan kami acak:
sampled_images = diffusion.sample(batch_size = 4)

Pelatihan Data Kustom
Grafik denoising-diffusion-pytorch package juga memungkinkan Anda melatih model difusi pada kumpulan data tertentu. Cukup ganti 'path/to/your/images' string dengan jalur direktori dataset di Trainer() objek di bawah ini, dan ubah image_size ke nilai yang sesuai. Setelah itu, cukup jalankan kode untuk melatih model, lalu ambil sampel seperti sebelumnya. Perhatikan bahwa PyTorch harus dikompilasi dengan CUDA diaktifkan untuk menggunakan Trainer kelas:
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
).cuda()
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
).cuda()
trainer = Trainer(
diffusion,
'path/to/your/images',
train_batch_size = 32,
train_lr = 2e-5,
train_num_steps = 700000, # total training steps
gradient_accumulate_every = 2, # gradient accumulation steps
ema_decay = 0.995, # exponential moving average decay
amp = True # turn on mixed precision
)
trainer.train()
Di bawah ini Anda dapat melihat denoising progresif dari noise Gaussian multivariat ke digit MNIST yang mirip dengan difusi terbalik:

Penutup
Model Difusi adalah pendekatan konseptual sederhana dan elegan untuk masalah menghasilkan data. Hasil State-of-the-Art mereka dikombinasikan dengan pelatihan non-permusuhan telah mendorong mereka ke tingkat yang sangat tinggi, dan perbaikan lebih lanjut dapat diharapkan di tahun-tahun mendatang mengingat status mereka yang baru lahir. Secara khusus, Model Difusi telah ditemukan penting untuk kinerja model mutakhir seperti DALL-E2.
Referensi
[1] Pembelajaran Tanpa Pengawasan Mendalam menggunakan Termodinamika Nonequilibrium
[2] Pemodelan Generatif dengan Memperkirakan Gradien Distribusi Data
[3] Model Probabilistik Difusi Denoising
[4] Peningkatan Teknik untuk Model Generatif Berbasis Skor Pelatihan
[5] Model Probabilistik Difusi Denoising yang Ditingkatkan
[6] Model Difusi Mengalahkan GAN pada Sintesis Gambar
[7] GLIDE: Menuju Pembuatan dan Pengeditan Gambar Fotorealistik dengan Model Difusi Berpanduan Teks
[8] Pembuatan Gambar Bersyarat Teks Hierarki dengan CLIP Latent
Selamat menikmati artikel ini? Mendaftar untuk lebih banyak pembaruan penelitian AI.
Kami akan memberi tahu Anda ketika kami merilis lebih banyak artikel ringkasan seperti ini.
terkait
- AI
- ai seni
- generator seni ai
- punya robot
- kecerdasan buatan
- sertifikasi kecerdasan buatan
- kecerdasan buatan dalam perbankan
- robot kecerdasan buatan
- robot kecerdasan buatan
- blockchain
- konferensi blockchain
- kecerdasan
- Visi Komputer
- kecerdasan buatan percakapan
- konferensi kripto
- dall's
- belajar mendalam
- google itu
- Tamu
- Mesin belajar
- Fitur utama
- plato
- plato ai
- Kecerdasan Data Plato
- Permainan Plato
- Data Plato
- permainan plato
- skala ai
- sintaksis
- Panduan Teknis
- TOPBOT
- zephyrnet.dll



