NLP multi-label mengacu pada tugas menetapkan beberapa label ke input teks yang diberikan, bukan hanya satu label. Dalam tugas NLP tradisional, seperti klasifikasi teks atau analisis sentimen, setiap input biasanya diberi satu label berdasarkan kontennya. Namun, dalam banyak skenario dunia nyata, sepotong teks dapat dimasukkan ke dalam beberapa kategori atau mengekspresikan banyak sentimen secara bersamaan.
NLP multi-label penting karena memungkinkan kami menangkap informasi yang lebih bernuansa dan kompleks dari data teks. Misalnya, dalam domain analisis umpan balik pelanggan, ulasan pelanggan dapat mengungkapkan sentimen positif dan negatif pada saat yang sama, atau mungkin menyentuh beberapa aspek produk atau layanan. Dengan menetapkan beberapa label pada masukan tersebut, kami dapat memperoleh pemahaman yang lebih komprehensif tentang umpan balik pelanggan dan mengambil tindakan yang lebih terarah untuk mengatasi masalah mereka.
Artikel ini menyelidiki kasus penting penggunaan NLP multi-label oleh Provectus.
konteks:
Seorang klien mendekati kami dengan permintaan untuk membantu mereka mengotomatisasi dokumen pelabelan jenis tertentu. Sekilas, tugas itu tampak mudah dan mudah diselesaikan. Namun, saat kami menangani kasus ini, kami menemukan kumpulan data dengan anotasi yang tidak konsisten. Meskipun pelanggan kami telah menghadapi tantangan dengan berbagai nomor kelas dan perubahan dalam tim peninjau mereka dari waktu ke waktu, mereka telah melakukan upaya yang signifikan untuk membuat kumpulan data yang beragam dengan berbagai anotasi. Meskipun terdapat beberapa ketidakseimbangan dan ketidakpastian dalam label, kumpulan data ini memberikan peluang berharga untuk analisis dan eksplorasi lebih lanjut.
Mari kita lihat lebih dekat kumpulan data, jelajahi metrik dan pendekatan kami, dan rekap bagaimana Provectus memecahkan masalah klasifikasi teks multi-label.
Dataset memiliki 14,354 pengamatan, dengan 124 kelas unik (label). Tugas kita adalah menetapkan satu atau beberapa kelas untuk setiap pengamatan.
Tabel 1 memberikan statistik deskriptif untuk kumpulan data.
Rata-rata, kami memiliki sekitar dua kelas per observasi, dengan rata-rata 261 teks berbeda yang mendeskripsikan satu kelas.

Tabel 1: Statistik Dataset
Pada Gambar 1, kami melihat distribusi kelas di grafik teratas, dan kami memiliki sejumlah label HEAD dengan frekuensi kemunculan tertinggi dalam kumpulan data. Perhatikan juga bahwa mayoritas kelas memiliki frekuensi kejadian yang rendah.
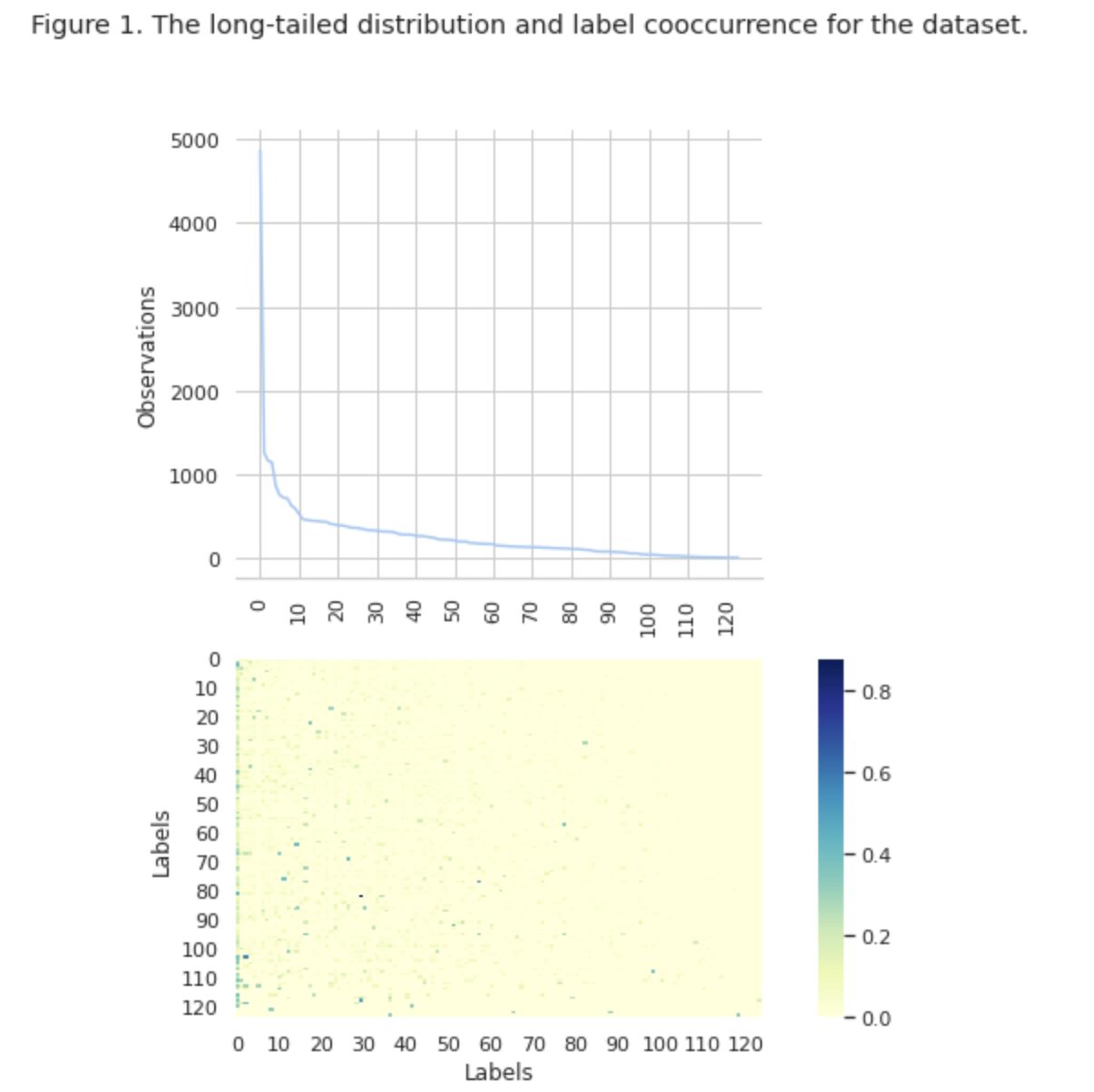
Pada grafik paling bawah kita melihat bahwa sering terjadi tumpang tindih antara kelas yang paling baik terwakili dalam kumpulan data, dan kelas yang memiliki signifikansi rendah.
Kami mengubah proses pemisahan dataset menjadi set train/val/test. Alih-alih menggunakan metode tradisional, kami menggunakan stratifikasi iteratif, untuk memberikan distribusi bukti hubungan label yang seimbang. Untuk itu, kami menggunakan Scikit Multi-belajar
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Kami memperoleh distribusi berikut:
- Dataset pelatihan berisi 60% data dan mencakup 124 label
- Dataset validasi berisi 20% dari data dan mencakup 124 label
- Kumpulan data uji berisi 20% dari data dan mencakup 124 label
Klasifikasi multi-label adalah jenis algoritme pembelajaran mesin yang diawasi yang memungkinkan kami menetapkan beberapa label ke satu sampel data. Ini berbeda dari klasifikasi biner di mana model hanya memprediksi dua kategori, dan klasifikasi multi-kelas di mana model hanya memprediksi satu dari beberapa kelas untuk sampel.
Metrik evaluasi untuk kinerja klasifikasi multi-label secara inheren berbeda dari yang digunakan dalam klasifikasi multi-kelas (atau biner) karena perbedaan yang melekat pada masalah klasifikasi. Informasi lebih rinci dapat ditemukan di Wikipedia.
Kami memilih metrik yang paling cocok untuk kami:
- Ketelitian mengukur proporsi prediksi positif sejati di antara total prediksi positif yang dibuat oleh model.
- Mengingat kembali mengukur proporsi prediksi positif sejati di antara semua sampel positif aktual.
- Skor F1 adalah rata-rata presisi dan daya ingat yang harmonis, yang membantu mengembalikan keseimbangan antara keduanya.
- Kerugian hamming adalah bagian dari label yang diprediksi salah
Kami juga melacak jumlah label yang diprediksi di set { didefinisikan sebagai hitungan untuk label, yang kami mencapai skor F1 > 0}.
Klasifikasi Multi-Label adalah jenis masalah pembelajaran yang diawasi di mana satu contoh atau contoh dapat dikaitkan dengan banyak label atau klasifikasi, berbeda dengan klasifikasi label tunggal tradisional, di mana setiap contoh hanya dikaitkan dengan satu label kelas.
Untuk memecahkan masalah klasifikasi multi-label, ada dua kategori teknik utama:
- Metode transformasi masalah
- Metode adaptasi algoritma
Metode transformasi masalah memungkinkan kita mengubah tugas klasifikasi multi-label menjadi beberapa tugas klasifikasi satu label. Misalnya, pendekatan baseline Relevansi Biner (BR) memperlakukan setiap label sebagai masalah klasifikasi biner yang terpisah. Dalam hal ini, masalah multi-label ditransformasikan menjadi masalah multi-label tunggal.
Metode adaptasi algoritme memodifikasi algoritme itu sendiri untuk menangani data multi-label secara asli, tanpa mengubah tugas menjadi beberapa tugas klasifikasi satu label. Contoh dari pendekatan ini adalah model BERT, yang merupakan model bahasa berbasis transformer terlatih yang dapat disesuaikan untuk berbagai tugas NLP, termasuk klasifikasi teks multi-label. BERT dirancang untuk menangani data multi-label secara langsung, tanpa perlu transformasi masalah.
Dalam konteks penggunaan BERT untuk klasifikasi teks multi-label, pendekatan standar adalah menggunakan kerugian Binary Cross-Entropy (BCE) sebagai fungsi kerugian. Kerugian BCE adalah fungsi kerugian yang umum digunakan untuk masalah klasifikasi biner dan dapat dengan mudah diperluas untuk menangani masalah klasifikasi multi-label dengan menghitung kerugian untuk setiap label secara terpisah, lalu menjumlahkan kerugian tersebut. Dalam hal ini, fungsi kerugian BCE mengukur kesalahan antara probabilitas yang diprediksi dan label yang sebenarnya, di mana probabilitas yang diprediksi diperoleh dari lapisan aktivasi sigmoid akhir dalam model BERT.
Sekarang, mari kita lihat lebih dekat Gambar 2 di bawah ini.
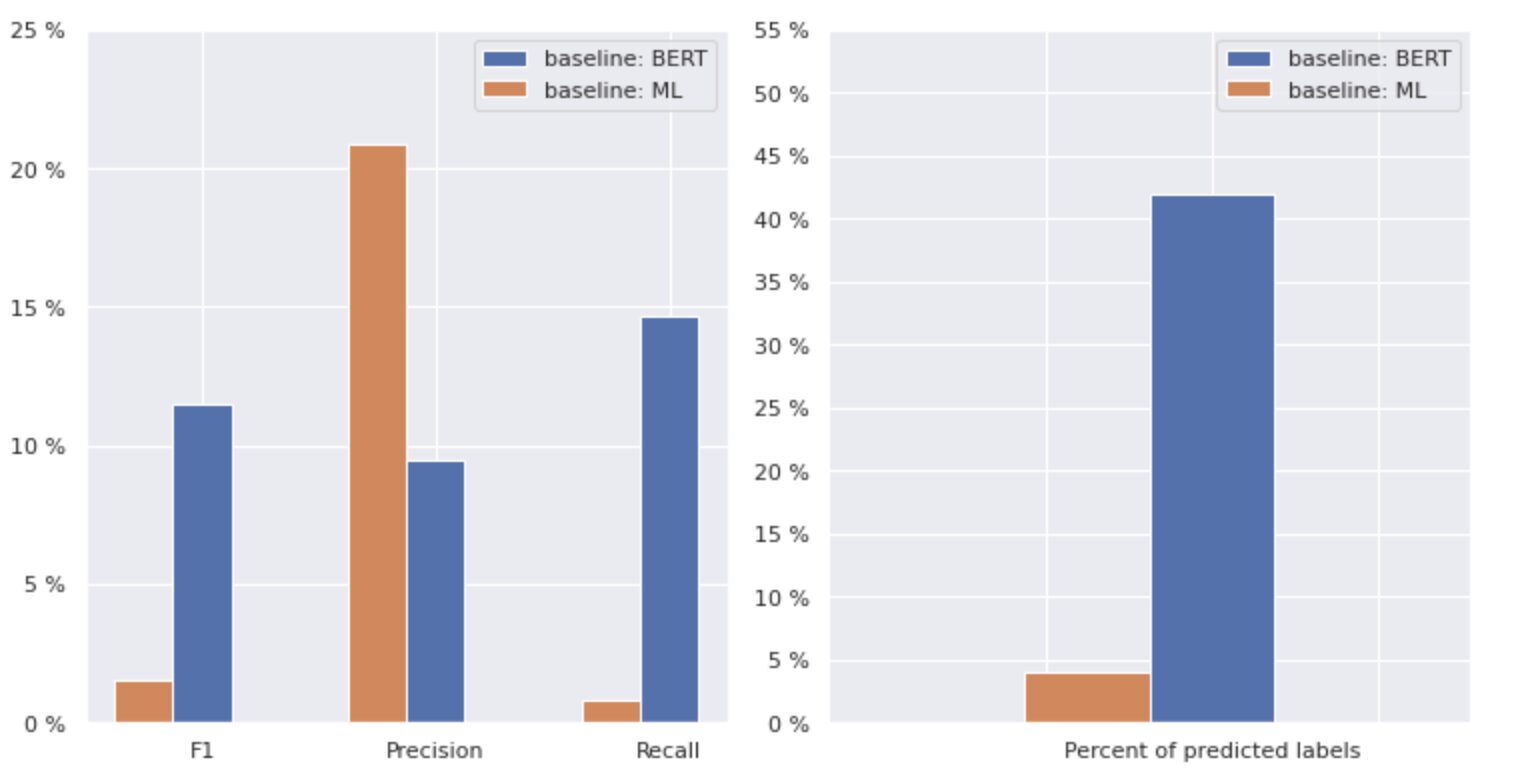
Gambar 2. Metrik untuk model baseline
Grafik di sebelah kiri menunjukkan perbandingan metrik untuk "baseline: BERT" dan "baseline: ML". Dengan demikian, dapat dilihat bahwa untuk “baseline: BERT”, skor F1 dan Recall kira-kira 1.5 kali lebih tinggi, sedangkan Presisi untuk “baseline: ML” 2 kali lebih tinggi daripada model 1. Dengan menganalisis persentase keseluruhan kelas yang diprediksi ditampilkan di sebelah kanan, kita melihat bahwa "baseline: BERT" memprediksi kelas lebih dari 10 kali lipat dari "baseline: ML".
Karena hasil maksimal untuk “baseline: BERT” kurang dari 50% dari semua kelas, hasilnya cukup mengecewakan. Mari kita cari tahu cara meningkatkan hasil ini.
Berdasarkan artikel yang luar biasa “Metode Penyeimbangan untuk Klasifikasi Teks Multi Label dengan Distribusi Kelas Ekor Panjang”, kami belajar bahwa kerugian berimbang distribusi mungkin merupakan pendekatan yang paling cocok untuk kami.
Distribusi-kerugian seimbang
Distribution-balanced loss adalah teknik yang digunakan dalam masalah klasifikasi teks multi-label untuk mengatasi ketidakseimbangan dalam distribusi kelas. Dalam masalah ini, beberapa kelas memiliki frekuensi kejadian yang jauh lebih tinggi dibandingkan dengan yang lain, yang mengakibatkan bias model terhadap kelas yang lebih sering ini.
Untuk mengatasi masalah ini, kerugian berimbang distribusi bertujuan untuk menyeimbangkan kontribusi masing-masing sampel dalam fungsi kerugian. Ini dicapai dengan menimbang ulang kehilangan setiap sampel berdasarkan kebalikan dari frekuensi kejadiannya dalam kumpulan data. Dengan demikian, kontribusi kelas yang lebih jarang meningkat, dan kontribusi kelas yang lebih sering berkurang, sehingga menyeimbangkan distribusi kelas secara keseluruhan.
Teknik ini terbukti efektif dalam meningkatkan kinerja model pada masalah distribusi kelas long-tailed. Dengan mengurangi dampak dari kelas yang sering dan meningkatkan dampak dari kelas yang jarang, model ini mampu menangkap pola dalam data dengan lebih baik dan menghasilkan prediksi yang lebih seimbang.

Implementasi Kelas Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Dengan menyelidiki dataset secara cermat, kami telah menyimpulkan bahwa parameternya
= 0.405.
Penyetelan ambang batas
Langkah lain dalam meningkatkan model kami adalah proses penyetelan ambang batas, baik pada tahap pelatihan, maupun pada tahap validasi dan pengujian. Kami menghitung dependensi metrik seperti skor-f1, presisi, dan daya ingat pada tingkat ambang batas, dan kami memilih ambang batas berdasarkan skor metrik tertinggi. Di bawah ini Anda dapat melihat implementasi fungsi dari proses ini.
Optimalisasi skor F1 dengan menyetel ambang batas:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Evaluasi dan perbandingan dengan baseline
Pendekatan ini memungkinkan kami untuk melatih model baru dan mendapatkan hasil berikut, yang dibandingkan dengan baseline: BERT pada Gambar 3 di bawah.

Gambar 3. Perbandingan metrik berdasarkan baseline dan pendekatan yang lebih baru.
Dengan membandingkan metrik yang relevan untuk klasifikasi, kami melihat peningkatan yang signifikan dalam ukuran kinerja hampir 5-6 kali lipat:
Skor F1 meningkat dari 12% → 55%, sementara Presisi meningkat dari 9% → 59% dan Recall meningkat dari 15% → 51%.
Dengan perubahan yang ditunjukkan pada grafik kanan pada Gambar 3, sekarang kita dapat memprediksi 80% kelas.
Potongan kelas
Kami membagi label kami menjadi empat grup: HEAD, MEDIUM, TAIL, dan ZERO. Setiap kelompok berisi label dengan jumlah pengamatan data pendukung yang sama.
Seperti yang terlihat pada Gambar 4, distribusi kelompok berbeda. Kotak mawar (HEAD) memiliki distribusi miring negatif, kotak tengah (MEDIUM) memiliki distribusi miring positif, dan kotak hijau (TAIL) tampaknya memiliki distribusi normal.
Semua kelompok juga memiliki outlier, yaitu titik-titik di luar kumis dalam plot kotak. Grup HEAD memiliki dampak besar pada kelas MAJOR.
Selain itu, kami telah mengidentifikasi grup terpisah bernama "ZERO" yang berisi label yang tidak dapat dipelajari dan dikenali oleh model karena jumlah kemunculan minimal dalam kumpulan data (kurang dari 3% dari semua pengamatan).
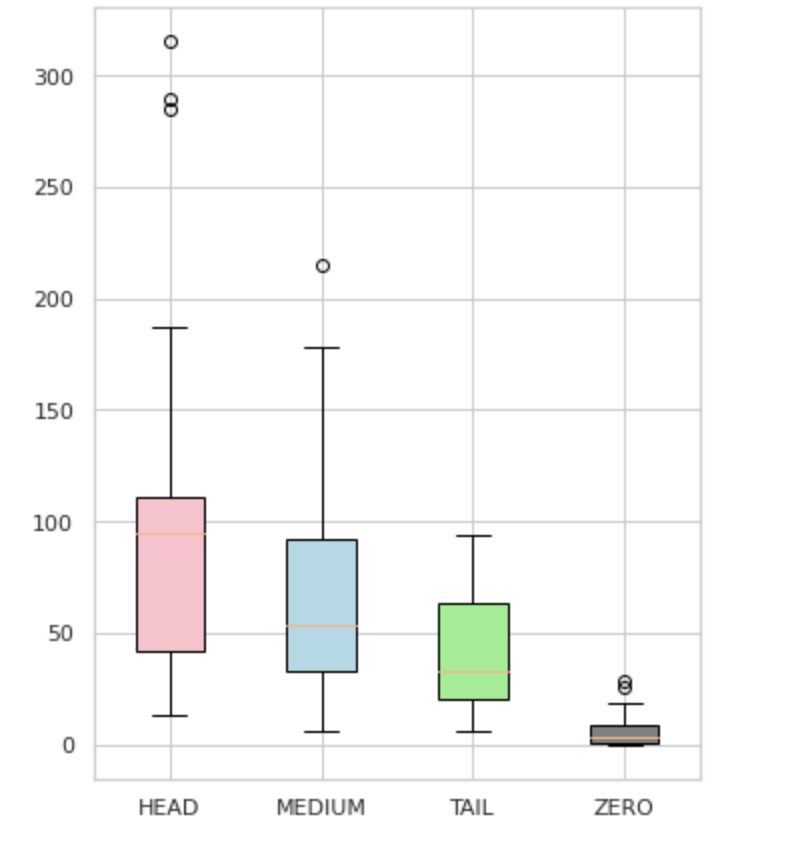
Gambar 4. Jumlah label vs. grup
Tabel 2 memberikan informasi tentang metrik per setiap grup label untuk subkumpulan data pengujian.
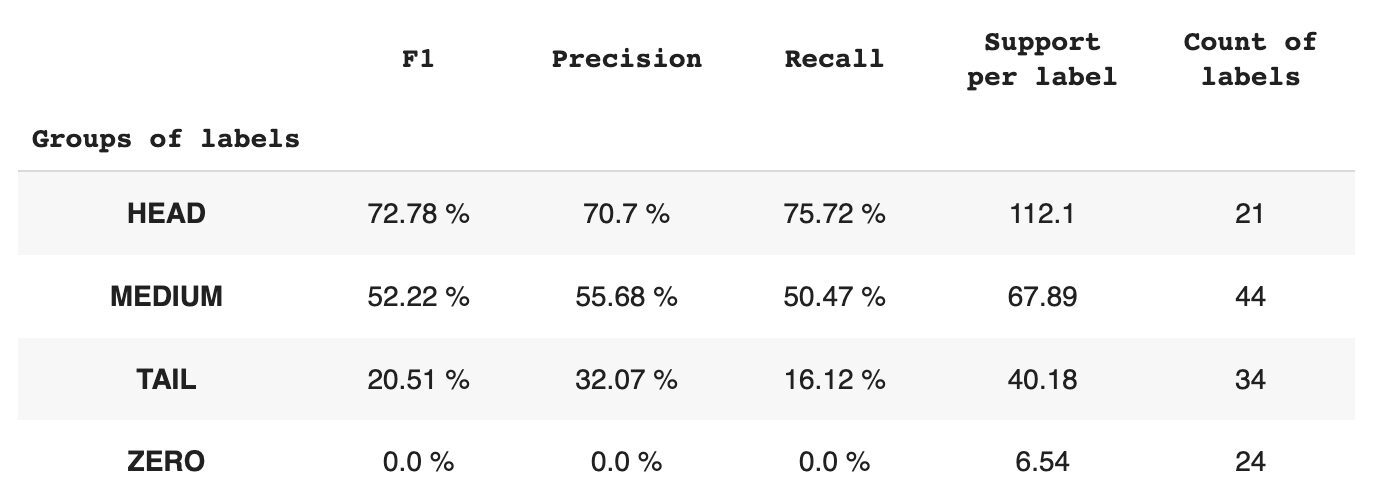
Tabel 2. Metrik per grup.
- Grup HEAD berisi 21 label dengan rata-rata 112 pengamatan dukungan per label. Grup ini dipengaruhi oleh outlier dan, karena keterwakilannya yang tinggi dalam kumpulan data, metriknya tinggi: F1 – 73%, Presisi – 71%, Ingat – 75%.
- Grup MEDIUM terdiri dari 44 label dengan dukungan rata-rata 67 pengamatan, yang kira-kira dua kali lebih rendah dari grup HEAD. Metrik untuk grup ini diperkirakan akan menurun sebesar 50%: F1 – 52%, Presisi – 56%, Recall – 51%.
- Grup TAIL memiliki jumlah kelas terbesar, tetapi semuanya kurang terwakili dalam kumpulan data, dengan rata-rata 40 pengamatan dukungan per label. Akibatnya, metrik turun secara signifikan: F1 – 21%, Presisi – 32%, Recall – 16%.
- Grup ZERO menyertakan kelas yang sama sekali tidak dapat dikenali oleh model, kemungkinan karena kemunculannya yang rendah dalam kumpulan data. Masing-masing dari 24 label dalam grup ini memiliki rata-rata 7 observasi pendukung.
Gambar 5 memvisualisasikan informasi yang disajikan pada Tabel 2, memberikan representasi visual metrik per grup label.
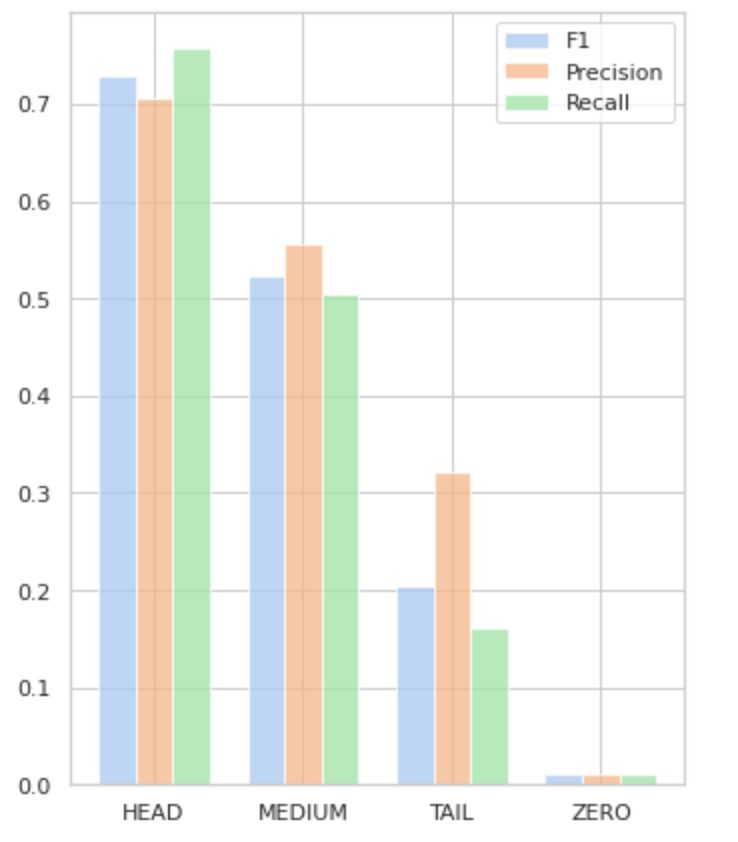
Gambar 5. Metrik vs. grup label. Semua nilai NOL = 0.
Dalam artikel komprehensif ini, kami telah menunjukkan bahwa tugas klasifikasi teks multi-label yang tampaknya sederhana dapat menjadi tantangan ketika metode tradisional diterapkan. Kami telah mengusulkan penggunaan fungsi kerugian distribusi-balancing untuk mengatasi masalah ketidakseimbangan kelas.
Kami telah membandingkan kinerja pendekatan yang kami usulkan dengan metode klasik, dan mengevaluasinya menggunakan metrik bisnis dunia nyata. Hasilnya menunjukkan bahwa memanfaatkan fungsi kerugian untuk mengatasi ketidakseimbangan kelas dan kejadian bersama label menawarkan solusi yang layak untuk klasifikasi teks multi-label.
Kasus penggunaan yang diusulkan menyoroti pentingnya mempertimbangkan pendekatan dan teknik yang berbeda ketika berhadapan dengan klasifikasi teks multi-label, dan manfaat potensial dari fungsi kerugian keseimbangan distribusi dalam mengatasi ketidakseimbangan kelas.
Jika Anda menghadapi masalah serupa dan ingin melakukannya merampingkan operasi pemrosesan dokumen dalam organisasi Anda, silakan hubungi saya atau tim Provectus. Kami akan dengan senang hati membantu Anda menemukan metode yang lebih efisien untuk mengotomatiskan proses Anda.
Oleksii Babych adalah Insinyur Pembelajaran Mesin di Provectus. Dengan latar belakang fisika, dia memiliki keterampilan analitis dan matematika yang sangat baik, dan telah memperoleh pengalaman berharga melalui penelitian ilmiah dan presentasi konferensi internasional, termasuk SPIE Photonics West. Oleksii berspesialisasi dalam menciptakan solusi AI/ML skala besar end-to-end untuk industri kesehatan dan tekfin. Dia terlibat dalam setiap tahap siklus hidup pengembangan ML, mulai dari mengidentifikasi masalah bisnis hingga menerapkan dan menjalankan model ML produksi.
Rinat Akhmetov adalah Arsitek Solusi ML di Provectus. Dengan latar belakang praktis yang kuat dalam Pembelajaran Mesin (terutama dalam Computer Vision), Rinat adalah seorang kutu buku, penggemar data, insinyur perangkat lunak, dan pecandu kerja yang hasrat terbesar keduanya adalah pemrograman. Di Provectus, Rinat bertanggung jawab atas fase penemuan dan pembuktian konsep, dan memimpin pelaksanaan proyek AI yang kompleks.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :adalah
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Sanggup
- Tentang Kami
- Mencapai
- dicapai
- tindakan
- Activation
- adaptasi
- alamat
- menangani
- AI
- AI / ML
- bertujuan
- algoritma
- algoritma
- Semua
- memungkinkan
- alfa
- antara
- jumlah
- analisis
- Analytical
- menganalisis
- dan
- Muncul
- terapan
- Mendaftar
- pendekatan
- pendekatan
- sekitar
- ADALAH
- artikel
- AS
- aspek
- ditugaskan
- membantu
- terkait
- At
- mengotomatisasi
- rata-rata
- latar belakang
- Saldo
- berdasarkan
- Dasar
- BE
- karena
- di bawah
- Manfaat
- TERBAIK
- beta
- Lebih baik
- antara
- prasangka
- Terbesar
- Bawah
- Kotak
- built-in
- bisnis
- by
- dihitung
- CAN
- tidak bisa
- menangkap
- kasus
- kategori
- CB
- tertentu
- tantangan
- menantang
- Perubahan
- biaya
- kelas
- kelas-kelas
- klasik
- klasifikasi
- klien
- rapat
- lebih dekat
- umum
- dibandingkan
- pembandingan
- perbandingan
- kompleks
- luas
- komputer
- Visi Komputer
- komputasi
- konsep
- Kekhawatiran
- Disimpulkan
- Konferensi
- mengingat
- kontak
- mengandung
- Konten
- konteks
- kontribusi
- meliputi
- membuat
- pelanggan
- siklus
- data
- berurusan
- mengurangi
- didefinisikan
- mendemonstrasikan
- menunjukkan
- penggelaran
- dirancang
- terperinci
- Pengembangan
- perbedaan
- berbeda
- langsung
- penemuan
- berbeda
- distribusi
- distribusi
- beberapa
- Terbagi
- dokumen
- dokumen
- melakukan
- domain
- Menjatuhkan
- setiap
- mudah
- Efektif
- efisien
- upaya
- aktif
- ujung ke ujung
- insinyur
- penggemar
- sama
- kesalahan
- terutama
- Eter (ETH)
- dievaluasi
- Setiap
- bukti
- contoh
- unggul
- eksekusi
- diharapkan
- pengalaman
- eksplorasi
- menyelidiki
- ekspres
- f1
- dihadapi
- menghadapi
- umpan balik
- Angka
- terakhir
- temuan
- fintech
- Pertama
- Mengapung
- berikut
- Untuk
- ditemukan
- pecahan
- Frekuensi
- sering
- dari
- fungsi
- fungsionil
- fungsi
- lebih lanjut
- Mendapatkan
- diberikan
- Sekilas
- grafik
- Hijau
- Kelompok
- Grup
- menangani
- senang
- Memiliki
- kepala
- kesehatan
- membantu
- membantu
- High
- lebih tinggi
- paling tinggi
- highlight
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- diidentifikasi
- mengidentifikasi
- ketidakseimbangan
- Dampak
- dampak
- implementasi
- mengimpor
- pentingnya
- penting
- memperbaiki
- meningkatkan
- in
- termasuk
- Termasuk
- salah
- Meningkatkan
- Pada meningkat
- meningkatkan
- secara mandiri
- industri
- informasi
- inheren
- memasukkan
- contoh
- sebagai gantinya
- Internasional
- diinvestasikan
- terlibat
- isu
- IT
- NYA
- jpg
- hanya satu
- KDnugget
- label
- pelabelan
- Label
- bahasa
- besar-besaran
- terbesar
- lapisan
- Memimpin
- BELAJAR
- belajar
- pengetahuan
- Tingkat
- Hidup
- Daftar
- melihat
- lepas
- kerugian
- Rendah
- mesin
- Mesin belajar
- terbuat
- Utama
- utama
- Mayoritas
- banyak
- pemetaan
- matematika
- maksimum
- ukuran
- medium
- metode
- metode
- metrik
- Metrik
- minimal
- ML
- MLB
- model
- model
- memodifikasi
- modul
- lebih
- lebih efisien
- paling
- beberapa
- Bernama
- Perlu
- negatif
- negatif
- New
- nLP
- normal
- penting
- jumlah
- nomor
- mati rasa
- memperoleh
- diperoleh
- of
- menawarkan
- on
- ONE
- Kesempatan
- menentang
- Opsi
- organisasi
- Lainnya
- jika tidak
- di luar
- terkemuka
- secara keseluruhan
- parameter
- gairah
- pola
- persentase
- prestasi
- Fisika
- bagian
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- poin
- PoS
- positif
- potensi
- berpotensi
- Praktis
- Ketelitian
- meramalkan
- diprediksi
- Prediksi
- Prediksi
- Presentasi
- disajikan
- Masalah
- masalah
- proses
- proses
- pengolahan
- menghasilkan
- Produk
- Produksi
- Pemrograman
- memprojeksikan
- bukti
- bukti konsep
- diusulkan
- memberikan
- disediakan
- menyediakan
- menyediakan
- pytorch
- menaikkan
- jarak
- agak
- dunia nyata
- menyeimbangkan
- rekap
- mengenali
- menurunkan
- mengurangi
- mengurangi
- mengacu
- hubungan
- relevansi
- relevan
- perwakilan
- diwakili
- permintaan
- penelitian
- mengakibatkan
- dihasilkan
- Hasil
- kembali
- Pengembalian
- ulasan
- ROSE
- berjalan
- s
- sama
- skenario
- Penelitian ilmiah
- Kedua
- pencarian
- terpilih
- DIRI
- sentimen
- terpisah
- layanan
- set
- set
- Bentuknya
- ditunjukkan
- Pertunjukkan
- makna
- penting
- signifikan
- mirip
- Sederhana
- serentak
- tunggal
- Ukuran
- keterampilan
- So
- Perangkat lunak
- Software Engineer
- padat
- larutan
- Solusi
- MEMECAHKAN
- beberapa
- spesialisasi
- ditentukan
- Tahap
- magang
- standar
- statistika
- Langkah
- mudah
- seperti itu
- cocok
- pembelajaran yang diawasi
- mendukung
- pendukung
- tabel
- MENANDAI
- Mengambil
- ditargetkan
- tugas
- tugas
- tim
- teknik
- uji
- pengujian
- Klasifikasi Teks
- bahwa
- Grafik
- informasi
- mereka
- Mereka
- diri
- Ini
- ambang
- Melalui
- waktu
- kali
- untuk
- puncak
- obor
- Total
- menyentuh
- terhadap
- jalur
- tradisional
- Pelatihan VE
- Pelatihan
- Mengubah
- Transformasi
- berubah
- mengubah
- memperlakukan
- benar
- khas
- ketidakpastian
- pemahaman
- unik
- us
- menggunakan
- gunakan case
- Memanfaatkan
- pengesahan
- Berharga
- Nilai - Nilai
- berbagai
- giat
- penglihatan
- vs
- berat
- Barat
- yang
- sementara
- Wikipedia
- akan
- dengan
- dalam
- tanpa
- bekerja
- Anda
- zephyrnet.dll
- nol