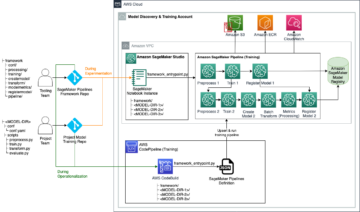
Amazon SageMaker menyediakan serangkaian algoritme bawaan, model pra-terlatih, dan templat solusi yang dibuat sebelumnya untuk membantu ilmuwan data dan praktisi pembelajaran mesin (ML) memulai pelatihan dan menerapkan model ML dengan cepat. Anda dapat menggunakan algoritme dan model ini untuk pembelajaran terawasi dan tidak terawasi. Mereka dapat memproses berbagai jenis data input, termasuk tabular, gambar, dan teks.
Mulai hari ini, SageMaker menyediakan empat algoritme pemodelan data tabular bawaan baru: LightGBM, CatBoost, AutoGluon-Tabular, dan TabTransformer. Anda dapat menggunakan algoritme tercanggih dan populer ini untuk tugas klasifikasi dan regresi tabular. Mereka tersedia melalui algoritme bawaan di konsol SageMaker serta melalui Mulai Lompatan Amazon SageMaker UI di dalam Studio Amazon SageMaker.
Berikut ini adalah daftar empat algoritme bawaan baru, dengan tautan ke dokumentasinya, contoh buku catatan, dan sumbernya.
Di bagian berikut, kami memberikan deskripsi teknis singkat tentang setiap algoritme, dan contoh cara melatih model melalui SageMaker SDK atau SageMaker Jumpstart.
CahayaGBM
CahayaGBM adalah implementasi open-source yang populer dan efisien dari algoritma Gradient Boosting Decision Tree (GBDT). GBDT adalah algoritma pembelajaran terawasi yang mencoba memprediksi variabel target secara akurat dengan menggabungkan ansambel perkiraan dari serangkaian model yang lebih sederhana dan lebih lemah. LightGBM menggunakan teknik tambahan untuk secara signifikan meningkatkan efisiensi dan skalabilitas GBDT konvensional.
KucingMeningkatkan
KucingMeningkatkan adalah implementasi open-source algoritma GBDT yang populer dan berkinerja tinggi. Dua kemajuan algoritme penting diperkenalkan di CatBoost: implementasi peningkatan berurutan, alternatif berbasis permutasi untuk algoritme klasik, dan algoritme inovatif untuk memproses fitur kategoris. Kedua teknik diciptakan untuk melawan pergeseran prediksi yang disebabkan oleh jenis kebocoran target khusus yang ada di semua implementasi algoritma peningkatan gradien yang ada saat ini.
AutoGluon-Tabel
AutoGluon-Tabel adalah proyek AutoML open-source yang dikembangkan dan dikelola oleh Amazon yang melakukan pemrosesan data tingkat lanjut, pembelajaran mendalam, dan penyusunan tumpukan multi-lapisan. Ini secara otomatis mengenali tipe data di setiap kolom untuk pra-pemrosesan data yang kuat, termasuk penanganan khusus bidang teks. AutoGluon cocok dengan berbagai model mulai dari pohon yang di-booster off-the-shelf hingga model jaringan saraf yang disesuaikan. Model-model ini digabungkan dengan cara baru: model ditumpuk dalam beberapa lapisan dan dilatih dengan cara berlapis yang menjamin data mentah dapat diterjemahkan ke dalam prediksi berkualitas tinggi dalam batasan waktu tertentu. Over-fitting dikurangi selama proses ini dengan membagi data dalam berbagai cara dengan pelacakan yang cermat dari contoh out-of-fold. AutoGluon dioptimalkan untuk kinerja, dan penggunaannya yang out-of-the-box telah mencapai beberapa posisi top-3 dan top-10 dalam kompetisi ilmu data.
TabTransformator
TabTransformator adalah arsitektur pemodelan data tabular dalam yang baru untuk pembelajaran yang diawasi. TabTransformer dibangun di atas Transformers berbasis perhatian-diri. Lapisan Transformer mengubah penyematan fitur kategoris menjadi penyematan kontekstual yang kuat untuk mencapai akurasi prediksi yang lebih tinggi. Selanjutnya, embeddings kontekstual yang dipelajari dari TabTransformer sangat kuat terhadap fitur data yang hilang dan berisik, dan memberikan interpretasi yang lebih baik. Model ini adalah produk terbaru Ilmu Amazon penelitian (kertas dan resmi posting blog di sini) dan telah diadopsi secara luas oleh komunitas ML, dengan berbagai implementasi pihak ketiga (Keras, Perekat Otomatis,) dan fitur media sosial seperti tweet, menuju ilmu data, sedang, dan Kaggle.
Manfaat algoritme bawaan SageMaker
Saat memilih algoritme untuk jenis masalah dan data khusus Anda, menggunakan algoritme bawaan SageMaker adalah opsi termudah, karena hal itu memberikan manfaat utama berikut:
- Algoritme bawaan tidak memerlukan pengkodean untuk mulai menjalankan eksperimen. Satu-satunya input yang perlu Anda berikan adalah data, hyperparameter, dan sumber daya komputasi. Ini memungkinkan Anda menjalankan eksperimen lebih cepat, dengan lebih sedikit overhead untuk melacak hasil dan perubahan kode.
- Algoritme bawaan hadir dengan paralelisasi di beberapa instans komputasi dan dukungan GPU langsung dari kotak untuk semua algoritme yang berlaku (beberapa algoritme mungkin tidak disertakan karena keterbatasan bawaan). Jika Anda memiliki banyak data untuk melatih model Anda, sebagian besar algoritme bawaan dapat dengan mudah menskalakan untuk memenuhi permintaan. Bahkan jika Anda sudah memiliki model yang telah dilatih sebelumnya, mungkin masih lebih mudah untuk menggunakan konsekuensi wajarnya di SageMaker dan memasukkan hyperparameter yang sudah Anda ketahui daripada memindahkannya dan menulis skrip pelatihan sendiri.
- Anda adalah pemilik artefak model yang dihasilkan. Anda dapat mengambil model itu dan menerapkannya di SageMaker untuk beberapa pola inferensi yang berbeda (lihat semua jenis penyebaran yang tersedia) dan penskalaan dan pengelolaan titik akhir yang mudah, atau Anda dapat menerapkannya di mana pun Anda membutuhkannya.
Sekarang mari kita lihat cara melatih salah satu algoritme bawaan ini.
Latih algoritme bawaan menggunakan SageMaker SDK
Untuk melatih model yang dipilih, kita perlu mendapatkan URI model itu, serta skrip pelatihan dan gambar wadah yang digunakan untuk pelatihan. Untungnya, ketiga input ini hanya bergantung pada nama model, versi (untuk daftar model yang tersedia, lihat Tabel Model yang Tersedia JumpStart), dan jenis instans yang ingin Anda latih. Ini ditunjukkan dalam cuplikan kode berikut:
Grafik train_model_id berubah menjadi lightgbm-regression-model jika kita berurusan dengan masalah regresi. ID untuk semua model lain yang diperkenalkan dalam posting ini tercantum dalam tabel berikut.
| Model | Jenis Masalah | ID Model |
| CahayaGBM | Klasifikasi | lightgbm-classification-model |
| . | Regresi | lightgbm-regression-model |
| KucingMeningkatkan | Klasifikasi | catboost-classification-model |
| . | Regresi | catboost-regression-model |
| AutoGluon-Tabel | Klasifikasi | autogluon-classification-ensemble |
| . | Regresi | autogluon-regression-ensemble |
| TabTransformator | Klasifikasi | pytorch-tabtransformerclassification-model |
| . | Regresi | pytorch-tabtransformerregression-model |
Kami kemudian menentukan di mana input kami berada Layanan Penyimpanan Sederhana Amazon (Amazon S3). Kami menggunakan kumpulan data sampel publik untuk contoh ini. Kami juga menentukan di mana kami ingin output kami pergi, dan mengambil daftar default hyperparameter yang diperlukan untuk melatih model yang dipilih. Anda dapat mengubah nilainya sesuai keinginan Anda.
Akhirnya, kami membuat instance SageMaker Estimator dengan semua input yang diambil dan luncurkan pekerjaan pelatihan dengan .fit, meneruskannya URI dataset pelatihan kami. Itu entry_point skrip yang disediakan bernama transfer_learning.py (sama untuk tugas dan algoritme lain), dan saluran data input diteruskan ke .fit harus diberi nama training.
Perhatikan bahwa Anda dapat melatih algoritme bawaan dengan Tuning model otomatis SageMaker untuk memilih hyperparameter yang optimal dan lebih meningkatkan kinerja model.
Latih algoritme bawaan menggunakan SageMaker JumpStart
Anda juga dapat melatih algoritme bawaan ini dengan beberapa klik melalui SageMaker JumpStart UI. JumpStart adalah fitur SageMaker yang memungkinkan Anda melatih dan menerapkan algoritme bawaan dan model terlatih dari berbagai kerangka kerja ML dan hub model melalui antarmuka grafis. Ini juga memungkinkan Anda untuk menerapkan solusi ML lengkap yang menyatukan model ML dan berbagai layanan AWS lainnya untuk menyelesaikan kasus penggunaan yang ditargetkan.
Untuk informasi lebih lanjut, lihat Jalankan klasifikasi teks dengan Amazon SageMaker JumpStart menggunakan TensorFlow Hub dan model Hugging Face.
Kesimpulan
Dalam postingan ini, kami mengumumkan peluncuran empat algoritme bawaan baru yang andal untuk ML pada kumpulan data tabular yang sekarang tersedia di SageMaker. Kami memberikan deskripsi teknis tentang algoritme ini, serta contoh tugas pelatihan untuk LightGBM menggunakan SageMaker SDK.
Bawa set data Anda sendiri dan coba algoritme baru ini di SageMaker, dan lihat contoh buku catatan untuk menggunakan algoritme bawaan yang tersedia di GitHub.
Tentang Penulis
![]() Dr Xin Huang adalah Ilmuwan Terapan untuk Amazon SageMaker JumpStart dan algoritma bawaan Amazon SageMaker. Dia berfokus pada pengembangan algoritme pembelajaran mesin yang dapat diskalakan. Minat penelitiannya adalah di bidang pemrosesan bahasa alami, pembelajaran mendalam yang dapat dijelaskan pada data tabular, dan analisis yang kuat dari pengelompokan ruang-waktu non-parametrik. Dia telah menerbitkan banyak makalah di ACL, ICDM, konferensi KDD, dan jurnal Royal Statistical Society: Series A.
Dr Xin Huang adalah Ilmuwan Terapan untuk Amazon SageMaker JumpStart dan algoritma bawaan Amazon SageMaker. Dia berfokus pada pengembangan algoritme pembelajaran mesin yang dapat diskalakan. Minat penelitiannya adalah di bidang pemrosesan bahasa alami, pembelajaran mendalam yang dapat dijelaskan pada data tabular, dan analisis yang kuat dari pengelompokan ruang-waktu non-parametrik. Dia telah menerbitkan banyak makalah di ACL, ICDM, konferensi KDD, dan jurnal Royal Statistical Society: Series A.
![]() Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan algoritma bawaan Amazon SageMaker JumpStart dan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan algoritma bawaan Amazon SageMaker JumpStart dan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
 João Moura adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia sebagian besar berfokus pada kasus penggunaan NLP dan membantu pelanggan mengoptimalkan pelatihan dan penerapan model Deep Learning. Dia juga merupakan pendukung aktif solusi ML kode rendah dan perangkat keras khusus ML.
João Moura adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia sebagian besar berfokus pada kasus penggunaan NLP dan membantu pelanggan mengoptimalkan pelatihan dan penerapan model Deep Learning. Dia juga merupakan pendukung aktif solusi ML kode rendah dan perangkat keras khusus ML.
- Coinsmart. Pertukaran Bitcoin dan Crypto Terbaik Eropa.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. AKSES GRATIS.
- CryptoHawk. Radar Altcoin. Uji Coba Gratis.
- Sumber: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- Mencapai
- dicapai
- di seluruh
- aktif
- Tambahan
- maju
- uang muka
- terhadap
- algoritma
- algoritmik
- algoritma
- Semua
- memungkinkan
- sudah
- alternatif
- Amazon
- Amazon Web Services
- analisis
- mengumumkan
- berlaku
- terapan
- arsitektur
- DAERAH
- secara otomatis
- secara otomatis
- tersedia
- AWS
- karena
- Manfaat
- Lebih baik
- Didorong
- meningkatkan
- Kotak
- built-in
- hati-hati
- kasus
- disebabkan
- perubahan
- klasik
- klasifikasi
- kode
- Pengkodean
- Kolom
- bagaimana
- masyarakat
- Kompetisi
- menghitung
- konferensi
- konsul
- Wadah
- membuat
- dibuat
- kritis
- Sekarang
- adat
- pelanggan
- data
- pengolahan data
- ilmu data
- berurusan
- keputusan
- mendalam
- Permintaan
- menunjukkan
- menyebarkan
- penggelaran
- penyebaran
- deskripsi
- mengembangkan
- dikembangkan
- berkembang
- berbeda
- Buruh pelabuhan
- setiap
- mudah
- efisiensi
- efisien
- Titik akhir
- perkiraan
- contoh
- contoh
- ada
- Menghadapi
- Fitur
- Fitur
- Fields
- terfokus
- berfokus
- berikut
- kerangka
- dari
- lebih lanjut
- Selanjutnya
- GPU
- Penanganan
- Perangkat keras
- tinggi
- membantu
- membantu
- membantu
- di sini
- berkualitas tinggi
- lebih tinggi
- sangat
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTTPS
- Pusat
- gambar
- implementasi
- memperbaiki
- termasuk
- Termasuk
- informasi
- inheren
- inovatif
- memasukkan
- contoh
- kepentingan
- Antarmuka
- IT
- Pekerjaan
- majalah
- Tahu
- bahasa
- jalankan
- belajar
- pengetahuan
- link
- Daftar
- Daftar
- mesin
- Mesin belajar
- utama
- pengelolaan
- cara
- Media
- medium
- ML
- model
- model
- lebih
- paling
- beberapa
- Alam
- jaringan
- Optimize
- dioptimalkan
- pilihan
- Lainnya
- sendiri
- pemilik
- tertentu
- Lewat
- prestasi
- Populer
- kuat
- meramalkan
- ramalan
- Prediksi
- menyajikan
- Masalah
- proses
- pengolahan
- Produk
- proyek
- memberikan
- disediakan
- menyediakan
- publik
- diterbitkan
- segera
- mulai
- Mentah
- mengakui
- wilayah
- membutuhkan
- penelitian
- Sumber
- dihasilkan
- Hasil
- Run
- berjalan
- sama
- Skalabilitas
- terukur
- Skala
- skala
- Ilmu
- ilmuwan
- ilmuwan
- SDK
- terpilih
- Seri
- Seri A
- Layanan
- set
- beberapa
- bergeser
- Sederhana
- So
- Sosial
- media sosial
- Masyarakat
- larutan
- Solusi
- MEMECAHKAN
- beberapa
- khusus
- spesialis
- tumpukan
- awal
- mulai
- state-of-the-art
- statistik
- Masih
- penyimpanan
- mendukung
- target
- ditargetkan
- tugas
- Teknis
- teknik
- Grafik
- pihak ketiga
- tiga
- Melalui
- di seluruh
- waktu
- hari ini
- bersama
- Pelacakan
- Pelatihan VE
- Pelatihan
- Mengubah
- jenis
- ui
- unik
- menggunakan
- kasus penggunaan
- nilai
- berbagai
- versi
- cara
- jaringan
- layanan web
- Apa
- dalam
- Anda