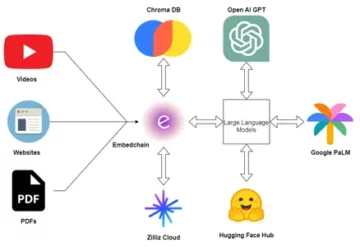
Saya telah memutuskan untuk menulis serangkaian artikel yang menjelaskan semua konsep dasar hingga lanjutan NLP menggunakan python. Jadi jika Anda ingin belajar NLP dengan membaca dan coding, ini akan menjadi rangkaian artikel yang sempurna untuk Anda.
Siapa pun yang baru atau nol di NLP dapat memulai dengan kami dan mengikuti rangkaian artikel ini.
Perpustakaan Digunakan: Keras, Tensorflow, Scikit learn, NLTK, Glove, dll.
Semua topik akan dijelaskan menggunakan kode python dan kerangka kerja pembelajaran mendalam dan pembelajaran mesin yang populer, seperti pembelajaran sci-kit, Keras, dan TensorFlow.
Apa itu NLP?
Pemrosesan Bahasa Alami adalah bagian dari ilmu komputer yang memungkinkan komputer memahami bahasa secara alami, seperti halnya seseorang. Ini berarti laptop akan memahami sentimen, ucapan, menjawab pertanyaan, ringkasan teks, dll. Kami tidak akan banyak berbicara tentang sejarah dan evolusinya. Jika Anda tertarik, pilih ini link.
Langkah1 Pembersihan Data
Data teks mentah datang langsung setelah berbagai sumber tidak dibersihkan. Kami menerapkan beberapa langkah untuk membuat data bersih. Data teks yang tidak dibersihkan berisi informasi tidak berguna yang menyimpang dari hasil, jadi itu selalu merupakan langkah pertama untuk membersihkan data. Beberapa teknik preprocessing standar harus diterapkan untuk membuat data lebih bersih. Data yang dibersihkan juga mencegah model dari overfitting.
Pada artikel ini, kita akan melihat topik berikut di bawah pemrosesan teks dan analisis data eksplorasi.
Saya mengubah data teks mentah menjadi bingkai data panda dan melakukan berbagai teknik pembersihan data.
import pandas as pd text = ['Ini adalah ARTIKEL TUGAS NLP yang ditulis oleh ABhishek Jaiswal** ','DI artikel ini saya akan menjelaskan berbagai teknik PEMBERSIHAN DATA', 'Jadi pantau terus untuk LEBIH LANJUT &&','Nah Saya tidak berpikir dia pergi ke usf, dia tinggal di sekitar'] df = pd.DataFrame({'text':text})
Keluaran:

Huruf kecil
Metode lower()mengubah semua karakter huruf besar menjadi huruf kecil dan kembali.
Menerapkan lower() metode menggunakan fungsi lambda
df['lower'] = df['text'].apply(lambda x: " ".join(x.lower() untuk x dalam x.split()))

Penghapusan Tanda Baca
Menghapus tanda baca (*,&,%#@#()) adalah langkah penting karena tanda baca tidak menambahkan informasi atau nilai tambahan apa pun ke data kami. Oleh karena itu, menghapus tanda baca akan mengurangi ukuran data; oleh karena itu, ini meningkatkan efisiensi komputasi.
Langkah ini bisa dilakukan dengan menggunakan metode Regex atau Replace.

string.punctuation mengembalikan string yang berisi semua tanda baca.

Menghapus tanda baca menggunakan ekspresi reguler:

Hentikan Penghapusan Kata
Kata-kata yang sering muncul dalam kalimat dan tidak memiliki arti yang signifikan dalam kalimat. Ini tidak penting untuk prediksi, jadi kami menghapus stopwords untuk mengurangi ukuran data dan mencegah overfitting. Catatan: Sebelum memfilter stopword, pastikan Anda menggunakan huruf kecil pada data karena stopword kami adalah huruf kecil.
Menggunakan perpustakaan NLTK, kita dapat memfilter Stopwords kita dari dataset.
# !pip install nltk import nltk nltk.download('stopwords') from nltk.corpus import stopwords allstopwords = stopwords.words('english') df.lower.apply(lambda x: " ".join(i for i in x .split() jika saya tidak ada di allstopwords))

Koreksi Ejaan
Sebagian besar data teks yang diekstraksi dalam ulasan pelanggan, blog, atau tweet memiliki beberapa kemungkinan kesalahan ejaan.
Memperbaiki kesalahan ejaan meningkatkan akurasi model.
Ada berbagai perpustakaan untuk memperbaiki kesalahan ejaan, tetapi metode yang paling nyaman adalah menggunakan gumpalan teks.
Metode correct() bekerja pada objek gumpalan teks dan mengoreksi kesalahan ejaan.
#Install textblob library !pip install textblob dari textblob import TextBlob

Tokenisasi
Tokenisasi berarti memecah teks menjadi kata-kata unit yang bermakna. Ada tokenizer kalimat dan juga tokenizer kata.
Tokenizer kalimat membagi paragraf menjadi kalimat yang bermakna, sedangkan tokenizer kata membagi kalimat menjadi unit kata yang bermakna. Banyak perpustakaan dapat melakukan tokenisasi seperti SpaCy, NLTK, dan TextBlob.
Memisahkan kalimat pada spasi untuk mendapatkan unit kata individu dapat dipahami sebagai tokenization.
import nltk mystring = "Binatang favorit saya adalah kucing" nltk.word_tokenize(mystring)
mystring.split("")
keluaran:
['Saya', 'favorit', 'binatang', 'adalah', 'kucing']
Suasana hati
Stemming adalah mengubah kata-kata menjadi kata dasar mereka menggunakan beberapa set aturan terlepas dari artinya. Yaitu,
- “ikan”, “ikan”, dan “memancing” berasal dari kata “ikan”.
- “bermain”, “bermain”, “bermain” berasal dari “bermain”.
- Stemming membantu mengurangi kosakata sehingga meningkatkan akurasi.
Cara paling sederhana untuk melakukan stemming adalah dengan menggunakan NLTK atau library TextBlob.
NLTK menyediakan berbagai teknik stemming, yaitu Snowball, PorterStemmer; teknik yang berbeda mengikuti seperangkat aturan yang berbeda untuk mengubah kata menjadi kata dasar mereka.
import nltk dari nltk.stem import PorterStemmer st = PorterStemmer() df['text'].apply(lambda x:" ".join([st.stem(word) untuk kata di x.split()]))

"artikel" berasal dari "articl","lives“-->“live".
Lemmatisasi
Lemmatisasi adalah mengubah kata menjadi kata dasar menggunakan pemetaan kosakata. Lemmatisasi dilakukan dengan bantuan part of speech dan artinya; karenanya tidak menghasilkan kata dasar yang tidak berarti. Tapi lemmatization lebih lambat dari stemming.
- "baik, ""lebih baik," atau "terbaik” dilemmatisasi menjadi “baik".
- Lemmatization akan mengubah semua sinonim menjadi satu akar kata. yaitu “mobil","mobil"," truk"," kendaraan” dilemmatisasi menjadi “mobil”.
- Lemmatization biasanya mendapatkan hasil yang lebih baik.
Yaitu. leafs Berasal dari. daun bertangkai leav sementara leafs , leaves dilemmatisasi menjadi leaf
Lemmatization dapat dilakukan dengan menggunakan NLTK, perpustakaan TextBlob.

Lemmatize seluruh dataset.

Langkah 2 Analisis Data Eksplorasi
Selama ini kita telah melihat berbagai teknik preprocessing teks yang harus dilakukan setelah mendapatkan data mentah. Setelah membersihkan data kami, kami sekarang dapat melakukan analisis data eksplorasi dan menjelajahi dan memahami data teks.
Frekuensi Kata dalam Data
Menghitung kata unik dalam data kami memberikan gambaran tentang istilah data kami yang paling sering, paling jarang. Seringkali kita menjatuhkan komentar yang paling jarang untuk membuat pelatihan model kita lebih digeneralisasikan.
nltk menyediakan Freq_dist kelas untuk menghitung frekuensi kata, dan dibutuhkan sekantong kata sebagai input.
all_words = [] untuk kalimat dalam df['diproses']: all_words.extend(kalimat.split())
all_words Berisi semua kata yang tersedia di dataset kami. Kita sering menyebutnya kosakata.
impor nltk nltk.Freq_dist(semua_kata)

Ini menunjukkan kata sebagai kunci dan jumlah kemunculan dalam data kami sebagai nilai.
kata Cloud
Wordcloud adalah representasi bergambar dari frekuensi kata dari kumpulan data. WordCloud lebih mudah dipahami dan memberikan gambaran yang lebih baik tentang data tekstual kita.
Grafik perpustakaan wordcloud Mari kita buat cloud kata dalam beberapa baris kode.
mengimpor perpustakaan:
dari wordcloud impor WordCloud dari wordcloud impor STOPWORDS impor matplotlib.pyplot sebagai plt
Kita dapat menggambar awan kata menggunakan teks yang berisi semua kata dari data kita.
kata = [] untuk pesan di df['diproses']: kata.extend([kata demi kata di message.split() jika kata tidak ada di STOPWORDS]) wordcloud = WordCloud(width = 1000, height = 500).generate( " ".join(words)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.show()

background_color = 'white'menggunakan parameter ini, kita dapat mengubah warna latar belakang kata cloud.collocations = FalseMenyimpannya sebagai False akan mengabaikan kata-kata kolokasi. Kolokasi adalah kata-kata yang dibentuk oleh kata-kata yang muncul bersama-sama. Yaitu memperhatikan, pekerjaan rumah, dll.- Kita dapat menyesuaikan tinggi dan lebar menggunakan parameter.
Note : Sebelum membuat kata cloud selalu hapus stopwords.
Catatan Akhir
Dalam artikel ini, kami melihat berbagai teknik yang diperlukan untuk pra-pemrosesan data tekstual. Setelah pembersihan data, kami melakukan analisis data eksplorasi menggunakan cloud kata dan membuat frekuensi kata.
Dalam artikel kedua dari seri ini, kita akan mempelajari topik-topik berikut:
Sumber: https://www.analyticsvidhya.com/blog/2022/01/nlp-tutorials-part-i-from-basics-to-advance/
- "
- &
- Tentang Kami
- Semua
- analisis
- sekitar
- artikel
- artikel
- tersedia
- Kantong Kata
- Dasar-dasar
- blog
- panggilan
- kesempatan
- perubahan
- Pembersihan
- awan
- kode
- Pengkodean
- komentar
- Komputer Ilmu
- komputer
- data
- analisis data
- belajar mendalam
- berbeda
- Tidak
- Menjatuhkan
- efisiensi
- Inggris
- dll
- evolusi
- Pertama
- Memperbaiki
- mengikuti
- menghasilkan
- mendapatkan
- membantu
- membantu
- sejarah
- Beranda
- HTTPS
- ide
- penting
- meningkatkan
- sendiri-sendiri
- informasi
- IT
- pemeliharaan
- keras
- kunci
- bahasa
- laptop
- BELAJAR
- pengetahuan
- lemmatisasi
- Perpustakaan
- Mesin belajar
- Membuat
- medium
- model
- lebih
- nLP
- Membayar
- Populer
- ramalan
- menyediakan
- Ular sanca
- Mentah
- data mentah
- Bacaan
- menurunkan
- menggantikan
- Hasil
- Pengembalian
- Review
- aturan
- Ilmu
- Seri
- set
- Ukuran
- So
- Space
- awal
- tinggal
- batang
- pembicaraan
- teknik
- tensorflow
- bersama
- Tokenisasi
- Topik
- Pelatihan
- tutorial
- us
- biasanya
- nilai
- kata
- bekerja
- X
- nol