Seri tiga bagian ini menunjukkan cara menggunakan jaringan saraf graf (GNN) dan Amazon Neptunus untuk menghasilkan rekomendasi film menggunakan Film IMDb dan Box Office Mojo/TV/OTT paket data yang dapat dilisensikan, yang menyediakan beragam metadata hiburan, termasuk lebih dari 1 miliar peringkat pengguna; kredit untuk lebih dari 11 juta pemain dan kru; 9 juta judul film, TV, dan hiburan; dan data pelaporan box office global dari lebih dari 60 negara. Banyak pelanggan media dan hiburan AWS melisensikan data IMDb melalui Pertukaran Data AWS untuk meningkatkan penemuan konten dan meningkatkan keterlibatan dan retensi pelanggan.
In bagian 1, kami membahas aplikasi GNN, dan cara mengubah dan menyiapkan data IMDb kami untuk kueri. Dalam postingan ini, kami membahas proses penggunaan Neptunus untuk menghasilkan penyematan yang digunakan untuk melakukan pencarian di luar katalog di Bagian 3 . Kami juga pergi Amazon Neptunus ML, fitur pembelajaran mesin (ML) dari Neptune, dan kode yang kami gunakan dalam proses pengembangan kami. Di Bagian 3 , kita membahas cara menerapkan penyematan grafik pengetahuan kita ke kasus penggunaan penelusuran di luar katalog.
Ikhtisar solusi
Kumpulan data besar yang terhubung sering kali berisi informasi berharga yang sulit diekstrak menggunakan kueri berdasarkan intuisi manusia saja. Teknik ML dapat membantu menemukan korelasi tersembunyi dalam grafik dengan miliaran hubungan. Korelasi ini dapat berguna untuk merekomendasikan produk, memprediksi kelayakan kredit, mengidentifikasi penipuan, dan banyak kasus penggunaan lainnya.
Neptune ML memungkinkan untuk membuat dan melatih model ML yang berguna pada grafik besar dalam hitungan jam, bukan minggu. Untuk mencapai hal ini, Neptune ML menggunakan teknologi GNN yang didukung oleh Amazon SageMaker dan Perpustakaan Grafik Dalam (DGL) (yang mana open-source). GNN adalah bidang baru dalam kecerdasan buatan (sebagai contoh, lihat Survei Komprehensif tentang Jaringan Syaraf Graf). Untuk tutorial langsung tentang penggunaan GNN dengan DGL, lihat Mempelajari jaringan saraf grafik dengan Deep Graph Library.
Dalam postingan ini, kami menunjukkan cara menggunakan Neptunus di pipeline kami untuk membuat penyematan.
Diagram berikut menggambarkan keseluruhan aliran data IMDb dari unduhan hingga pembuatan penyematan.
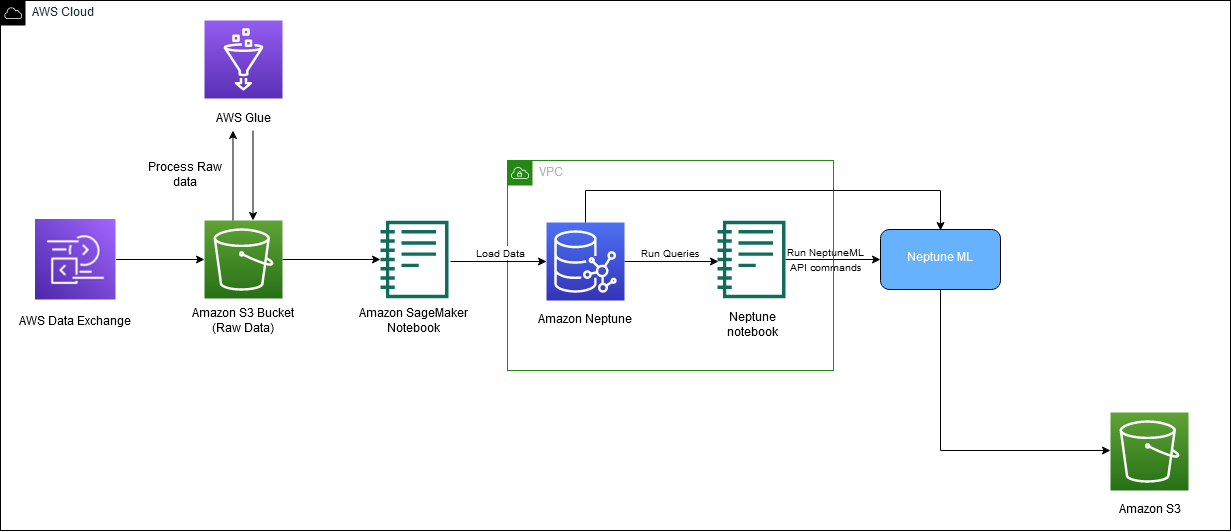
Kami menggunakan layanan AWS berikut untuk mengimplementasikan solusi:
Dalam postingan ini, kami memandu Anda melalui langkah-langkah tingkat tinggi berikut:
- Siapkan variabel lingkungan
- Buat tugas ekspor.
- Buat tugas pemrosesan data.
- Kirim tugas pelatihan.
- Unduh penyematan.
Kode untuk perintah Neptune ML
Kami menggunakan perintah berikut sebagai bagian dari penerapan solusi ini:
Kami menggunakan neptune_ml export untuk memeriksa status atau memulai proses ekspor Neptune ML, dan neptune_ml training untuk memulai dan memeriksa status tugas pelatihan model Neptune ML.
Untuk informasi lebih lanjut tentang ini dan perintah lainnya, lihat Menggunakan keajaiban meja kerja Neptunus di buku catatan Anda.
Prasyarat
Untuk mengikuti posting ini, Anda harus memiliki yang berikut:
- An Akun AWS
- Keakraban dengan SageMaker, Amazon S3, dan AWS CloudFormation
- Data grafik dimuat ke dalam kluster Neptunus (lihat bagian 1 untuk informasi lebih lanjut)
Siapkan variabel lingkungan
Sebelum kita mulai, Anda harus menyiapkan lingkungan Anda dengan menyetel variabel berikut: s3_bucket_uri dan processed_folder. s3_bucket_uri adalah nama ember yang digunakan di Bagian 1 dan processed_folder adalah lokasi Amazon S3 untuk keluaran dari tugas ekspor .
Buat tugas ekspor
Di Bagian 1, kami membuat notebook SageMaker dan layanan ekspor untuk mengekspor data kami dari klaster Neptune DB ke Amazon S3 dalam format yang diperlukan.
Sekarang setelah data kita dimuat dan layanan ekspor dibuat, kita perlu membuat pekerjaan ekspor untuk memulainya. Untuk melakukan ini, kami menggunakan NeptuneExportApiUri dan buat parameter untuk pekerjaan ekspor. Dalam kode berikut, kami menggunakan variabel expo dan export_params. Mengatur expo untuk Anda NeptuneExportApiUri nilai, yang dapat Anda temukan di Output tab tumpukan CloudFormation Anda. Untuk export_params, kami menggunakan titik akhir klaster Neptune Anda dan memberikan nilai untuk outputS3path, yang merupakan lokasi Amazon S3 untuk keluaran dari tugas ekspor.
Untuk mengirimkan pekerjaan ekspor gunakan perintah berikut:
Untuk memeriksa status pekerjaan ekspor gunakan perintah berikut:
Setelah pekerjaan Anda selesai, atur processed_folder variabel untuk menyediakan lokasi Amazon S3 dari hasil yang diproses:
Buat tugas pemrosesan data
Setelah ekspor selesai, kami membuat tugas pemrosesan data untuk menyiapkan data untuk proses pelatihan Neptune ML. Ini dapat dilakukan dengan beberapa cara berbeda. Untuk langkah ini, Anda dapat mengubah job_name dan modelType variabel, tetapi semua parameter lainnya harus tetap sama. Bagian utama dari kode ini adalah modelType parameter, yang dapat berupa model grafik heterogen (heterogeneous) atau grafik pengetahuan (kge).
Pekerjaan ekspor juga termasuk training-data-configuration.json. Gunakan file ini untuk menambah atau menghapus node atau edge yang tidak ingin Anda sediakan untuk pelatihan (misalnya, jika Anda ingin memprediksi link antara dua node, Anda dapat menghapus link tersebut di file konfigurasi ini). Untuk posting blog ini kami menggunakan file konfigurasi asli. Untuk informasi tambahan, lihat Mengedit file konfigurasi pelatihan.
Buat tugas pemrosesan data Anda dengan kode berikut:
Untuk memeriksa status pekerjaan ekspor gunakan perintah berikut:
Kirim tugas pelatihan
Setelah pekerjaan pemrosesan selesai, kita dapat memulai pekerjaan pelatihan kita, yaitu tempat kita membuat penyematan. Kami merekomendasikan jenis instans ml.m5.24xlarge, tetapi Anda dapat mengubahnya agar sesuai dengan kebutuhan komputasi Anda. Lihat kode berikut:
Kami mencetak variabel training_results untuk mendapatkan ID untuk tugas pelatihan. Gunakan perintah berikut untuk memeriksa status pekerjaan Anda:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Unduh penyematan
Setelah tugas pelatihan Anda selesai, langkah terakhir adalah mengunduh penyematan mentah Anda. Langkah-langkah berikut menunjukkan kepada Anda cara mengunduh penyematan yang dibuat dengan menggunakan KGE (Anda dapat menggunakan proses yang sama untuk RGCN).
Dalam kode berikut, kami menggunakan neptune_ml.get_mapping() dan get_embeddings() untuk mengunduh file pemetaan (mapping.info) dan file sematan mentah (entity.npy). Kemudian kita perlu memetakan penyematan yang sesuai ke ID yang sesuai.
Untuk mengunduh RGCN, ikuti proses yang sama dengan nama tugas pelatihan baru dengan memproses data dengan parameter modelType yang disetel ke heterogeneous, lalu latih model Anda dengan parameter modelName disetel ke rgcn melihat di sini untuk lebih jelasnya. Setelah selesai, panggil get_mapping dan get_embeddings berfungsi untuk mengunduh file baru Anda pemetaan.info dan entitas.npy file. Setelah Anda memiliki file entitas dan pemetaan, proses untuk membuat file CSV identik.
Terakhir, unggah penyematan Anda ke lokasi Amazon S3 yang Anda inginkan:
Pastikan Anda mengingat lokasi S3 ini, Anda perlu menggunakannya di Bagian 3.
Membersihkan
Setelah selesai menggunakan solusi, pastikan untuk membersihkan sumber daya apa pun untuk menghindari tagihan berkelanjutan.
Kesimpulan
Dalam posting ini, kami membahas cara menggunakan Neptune ML untuk melatih embedding GNN dari data IMDb.
Beberapa aplikasi terkait dari penyematan grafik pengetahuan adalah konsep seperti pencarian di luar katalog, rekomendasi konten, iklan bertarget, memprediksi tautan yang hilang, pencarian umum, dan analisis kohort. Pencarian di luar katalog adalah proses mencari konten yang bukan milik Anda, dan menemukan atau merekomendasikan konten yang ada di katalog Anda yang sedekat mungkin dengan apa yang dicari pengguna. Kami menyelami lebih dalam pencarian di luar katalog di Bagian 3.
Tentang Penulis
 Matius Rhodes adalah Ilmuwan Data yang bekerja di Lab Solusi Amazon ML. Dia berspesialisasi dalam membangun saluran Pembelajaran Mesin yang melibatkan konsep seperti Pemrosesan Bahasa Alami dan Visi Komputer.
Matius Rhodes adalah Ilmuwan Data yang bekerja di Lab Solusi Amazon ML. Dia berspesialisasi dalam membangun saluran Pembelajaran Mesin yang melibatkan konsep seperti Pemrosesan Bahasa Alami dan Visi Komputer.
 Divya Bhargavi adalah Ilmuwan Data dan Pimpinan Vertikal Media dan Hiburan di Amazon ML Solutions Lab, tempat dia memecahkan masalah bisnis bernilai tinggi bagi pelanggan AWS menggunakan Pembelajaran Mesin. Dia mengerjakan pemahaman gambar/video, sistem rekomendasi grafik pengetahuan, kasus penggunaan iklan prediktif.
Divya Bhargavi adalah Ilmuwan Data dan Pimpinan Vertikal Media dan Hiburan di Amazon ML Solutions Lab, tempat dia memecahkan masalah bisnis bernilai tinggi bagi pelanggan AWS menggunakan Pembelajaran Mesin. Dia mengerjakan pemahaman gambar/video, sistem rekomendasi grafik pengetahuan, kasus penggunaan iklan prediktif.
 Rele Gaurav adalah Ilmuwan Data di Amazon ML Solution Lab, di mana dia bekerja dengan pelanggan AWS di berbagai vertikal berbeda untuk mempercepat penggunaan pembelajaran mesin dan layanan AWS Cloud mereka untuk memecahkan tantangan bisnis mereka.
Rele Gaurav adalah Ilmuwan Data di Amazon ML Solution Lab, di mana dia bekerja dengan pelanggan AWS di berbagai vertikal berbeda untuk mempercepat penggunaan pembelajaran mesin dan layanan AWS Cloud mereka untuk memecahkan tantangan bisnis mereka.
 Karan Sindwani adalah Ilmuwan Data di Amazon ML Solutions Lab, tempat dia membangun dan menerapkan model pembelajaran mendalam. Dia berspesialisasi dalam bidang visi komputer. Di waktu luangnya, dia menikmati hiking.
Karan Sindwani adalah Ilmuwan Data di Amazon ML Solutions Lab, tempat dia membangun dan menerapkan model pembelajaran mendalam. Dia berspesialisasi dalam bidang visi komputer. Di waktu luangnya, dia menikmati hiking.
 Soji Adeshina adalah Ilmuwan Terapan di AWS tempat dia mengembangkan model berbasis jaringan saraf grafik untuk pembelajaran mesin pada tugas grafik dengan aplikasi untuk penipuan & penyalahgunaan, grafik pengetahuan, sistem pemberi rekomendasi, dan ilmu kehidupan. Di waktu luangnya, ia senang membaca dan memasak.
Soji Adeshina adalah Ilmuwan Terapan di AWS tempat dia mengembangkan model berbasis jaringan saraf grafik untuk pembelajaran mesin pada tugas grafik dengan aplikasi untuk penipuan & penyalahgunaan, grafik pengetahuan, sistem pemberi rekomendasi, dan ilmu kehidupan. Di waktu luangnya, ia senang membaca dan memasak.
 Vidya Sagar Ravipati adalah seorang Manajer di Amazon ML Solutions Lab, tempat dia memanfaatkan pengalamannya yang luas dalam sistem terdistribusi berskala besar dan hasratnya terhadap pembelajaran mesin untuk membantu pelanggan AWS di berbagai vertikal industri mempercepat adopsi AI dan cloud mereka.
Vidya Sagar Ravipati adalah seorang Manajer di Amazon ML Solutions Lab, tempat dia memanfaatkan pengalamannya yang luas dalam sistem terdistribusi berskala besar dan hasratnya terhadap pembelajaran mesin untuk membantu pelanggan AWS di berbagai vertikal industri mempercepat adopsi AI dan cloud mereka.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Tentang Kami
- penyalahgunaan
- mempercepat
- di seluruh
- Tambahan
- Informasi Tambahan
- Adopsi
- pengiklanan
- Setelah
- AI
- Semua
- sendirian
- Amazon
- Lab Solusi Amazon ML
- analisis
- dan
- aplikasi
- terapan
- Mendaftar
- sesuai
- DAERAH
- buatan
- kecerdasan buatan
- AWS
- berdasarkan
- antara
- Milyar
- miliaran
- Blog
- Kotak
- Film laris
- membangun
- Bangunan
- membangun
- bisnis
- panggilan
- kasus
- kasus
- katalog
- tantangan
- perubahan
- beban
- memeriksa
- Penyelesaian
- awan
- adopsi cloud
- layanan cloud
- Kelompok
- kode
- Kelompok
- lengkap
- luas
- komputer
- Visi Komputer
- komputasi
- konsep
- Mengadakan
- konfigurasi
- terhubung
- Konten
- Sesuai
- negara
- membuat
- dibuat
- kredit
- Kredit
- pelanggan
- Keterlibatan pelanggan
- pelanggan
- data
- pengolahan data
- ilmuwan data
- kumpulan data
- mendalam
- belajar mendalam
- lebih dalam
- menyebarkan
- rincian
- Pengembangan
- mengembangkan
- dgl
- berbeda
- penemuan
- membahas
- dibahas
- didistribusikan
- sistem terdistribusi
- Dont
- Download
- antara
- muncul
- Titik akhir
- interaksi
- Menghibur
- entitas
- Lingkungan Hidup
- Eter (ETH)
- contoh
- pengalaman
- ekspor
- ekstrak
- Fitur
- beberapa
- bidang
- File
- File
- Menemukan
- temuan
- aliran
- mengikuti
- berikut
- format
- penipuan
- dari
- penuh
- fungsi
- Umum
- menghasilkan
- generasi
- mendapatkan
- Aksi
- Go
- grafik
- grafik
- hands-on
- Sulit
- membantu
- bermanfaat
- Tersembunyi
- tingkat tinggi
- JAM
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- manusia
- identik
- mengidentifikasi
- melaksanakan
- mengimplementasikan
- memperbaiki
- in
- termasuk
- Termasuk
- Meningkatkan
- indeks
- industri
- Info
- informasi
- contoh
- sebagai gantinya
- Intelijen
- melibatkan
- IT
- Pekerjaan
- json
- kunci
- pengetahuan
- laboratorium
- bahasa
- besar
- besar-besaran
- Terakhir
- memimpin
- pengetahuan
- memanfaatkan
- Perpustakaan
- Lisensi
- Hidup
- Biologi
- LINK
- link
- tempat
- mesin
- Mesin belajar
- Utama
- MEMBUAT
- manajer
- banyak
- peta
- pemetaan
- Media
- medium
- Anggota
- Metadata
- juta
- hilang
- ML
- model
- model
- lebih
- film
- nama
- Alam
- Pengolahan Bahasa alami
- Perlu
- kebutuhan
- Neptunus
- berbasis jaringan
- jaringan
- jaringan saraf
- New
- node
- buku catatan
- Office
- terus-menerus
- asli
- Lainnya
- secara keseluruhan
- sendiri
- paket
- parameter
- parameter
- bagian
- gairah
- pipa saluran
- plato
- Kecerdasan Data Plato
- Data Plato
- mungkin
- Pos
- kekuasaan
- didukung
- meramalkan
- memprediksi
- Mempersiapkan
- Mencetak
- masalah
- proses
- pengolahan
- Produk
- Profil
- memberikan
- menyediakan
- jarak
- peringkat
- Mentah
- Bacaan
- sarankan
- Rekomendasi
- rekomendasi
- merekomendasikan
- terkait
- Hubungan
- tinggal
- ingat
- menghapus
- Pelaporan
- wajib
- Sumber
- Hasil
- penyimpanan
- pembuat bijak
- sama
- ILMU PENGETAHUAN
- ilmuwan
- Pencarian
- mencari
- Seri
- layanan
- Layanan
- set
- pengaturan
- harus
- Menunjukkan
- larutan
- Solusi
- MEMECAHKAN
- Memecahkan
- spesialisasi
- tumpukan
- awal
- Status
- Langkah
- Tangga
- menyimpan
- menyerahkan
- seperti itu
- setelan
- Survei
- sistem
- ditargetkan
- tugas
- teknik
- Teknologi
- Grafik
- Daerah
- mereka
- Melalui
- waktu
- judul
- untuk
- Pelatihan VE
- Pelatihan
- Mengubah
- benar
- tutorial
- tv
- pemahaman
- menggunakan
- gunakan case
- Pengguna
- Berharga
- nilai
- Luas
- versi
- vertikal
- penglihatan
- cara
- minggu
- Apa
- yang
- lebar
- Rentang luas
- akan
- kerja
- bekerja
- Anda
- zephyrnet.dll