Amazon EMR di EKS adalah opsi penerapan di Amazon ESDM yang memungkinkan Anda menjalankan pekerjaan Spark Layanan Amazon Elastic Kubernetes (AmazonEKS). Cloud komputasi elastis Amazon (Amazon EC2) Instans Spot menghemat hingga 90% dibandingkan Instans Sesuai Permintaan, dan merupakan cara yang bagus untuk mengoptimalkan biaya beban kerja Spark yang berjalan di Amazon EMR di EKS. Karena Spot adalah layanan yang dapat diinterupsi, jika kami dapat memindahkan atau menggunakan kembali file pengacakan perantara, ini meningkatkan stabilitas keseluruhan dan SLA pekerjaan. Versi terbaru Amazon EMR di EKS telah mengintegrasikan fitur Spark untuk mengaktifkan kemampuan ini.
Dalam postingan ini, kami membahas fitur-fitur ini—Penonaktifan Node dan Persistent Volume Claim (PVC) yang digunakan kembali—dan dampaknya terhadap peningkatan toleransi kesalahan pekerjaan Spark di Amazon EMR pada EKS saat pengoptimalan biaya menggunakan Instans Spot EC2.
Amazon EMR di EKS dan Spot
Instans Spot EC2 adalah kapasitas EC2 cadangan yang disediakan dengan diskon besar hingga 90% dari harga Sesuai Permintaan. Instans Spot adalah pilihan tepat untuk beban kerja tanpa kewarganegaraan dan fleksibel. Peringatan dengan diskon dan kapasitas cadangan ini adalah bahwa Amazon EC2 dapat menginterupsi instans dengan peringatan proaktif atau reaktif (2 menit) saat kapasitas dibutuhkan kembali. Anda dapat menyediakan kapasitas komputasi di klaster EKS menggunakan Instans Spot menggunakan grup node terkelola atau terkelola sendiri dan menyediakan pengoptimalan biaya untuk beban kerja Anda.
Amazon EMR di EKS menggunakan Amazon EKS untuk menjalankan tugas dengan Waktu proses EMR untuk Apache Spark, yang dapat dioptimalkan biayanya dengan menjalankan Pelaksana percikan di Spot. Ini menyediakan hingga Biaya 61% lebih rendah dan peningkatan kinerja hingga 68%. untuk beban kerja Spark di Amazon EKS. Aplikasi Spark meluncurkan driver dan eksekutor untuk menjalankan komputasi. Spark adalah kerangka kerja toleran semi-kesalahan tahan terhadap kerugian pelaksana karena gangguan dan karena itu dapat berjalan di EC2 Spot. Di sisi lain, saat pengemudi terganggu, pekerjaan gagal. Oleh karena itu, kami merekomendasikan menjalankan driver pada instance on-demand. Beberapa dari Praktik Terbaik untuk menjalankan Spark di Amazon EKS berlaku dengan Amazon EMR di EKS.
Instans Spot EC2 juga membantu pengoptimalan biaya dengan meningkatkan throughput pekerjaan secara keseluruhan. Ini dapat dicapai dengan auto-scaling cluster menggunakan Cluster Autoscaler (untuk nodegroup yang dikelola) atau tukang kayu.
Meskipun eksekutor Spark tahan terhadap gangguan Spot, file acak dan data RDD hilang saat eksekutor terbunuh. File acak yang hilang perlu dihitung ulang, yang meningkatkan waktu kerja keseluruhan pekerjaan. Apache Spark telah merilis dua fitur (dalam versi 3.1 dan 3.2) yang mengatasi masalah ini. Amazon EMR di EKS merilis fitur seperti penonaktifan node (versi 6.3) dan penggunaan ulang PVC (versi 6.8) untuk menyederhanakan pemulihan dan penggunaan ulang file acak, yang meningkatkan ketahanan keseluruhan aplikasi Anda.
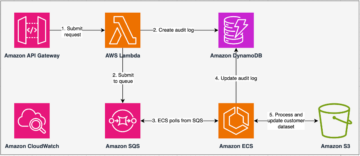
Penonaktifan node
Fitur dekomisioning node berfungsi dengan mencegah penjadwalan pekerjaan baru pada node yang akan dinonaktifkan. Itu juga memindahkan file acak atau cache yang ada di node tersebut ke pelaksana lain (peer). Jika tidak ada eksekutor lain yang tersedia, file acak dan cache dipindahkan ke penyimpanan fallback jarak jauh.
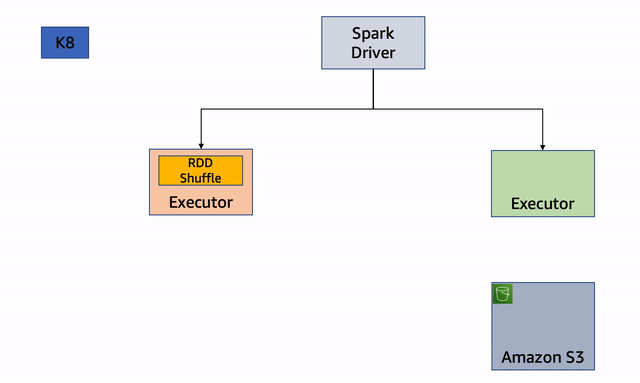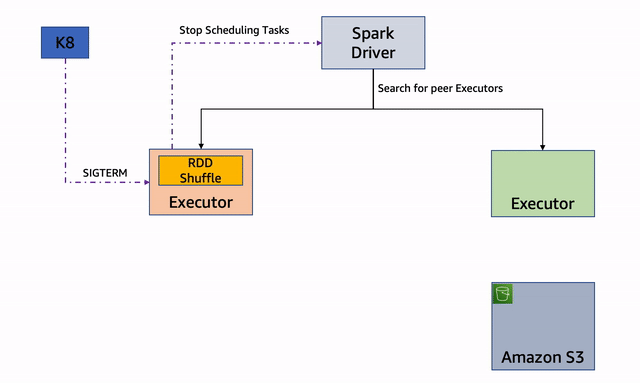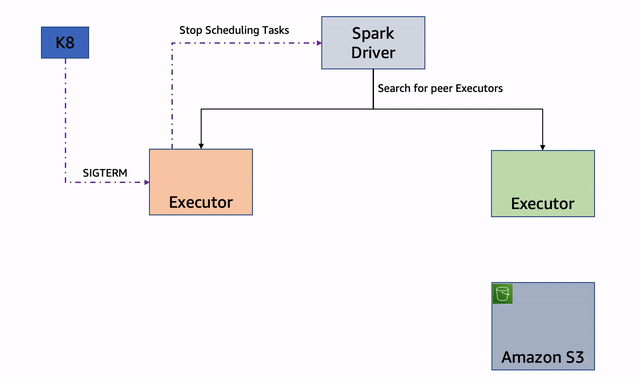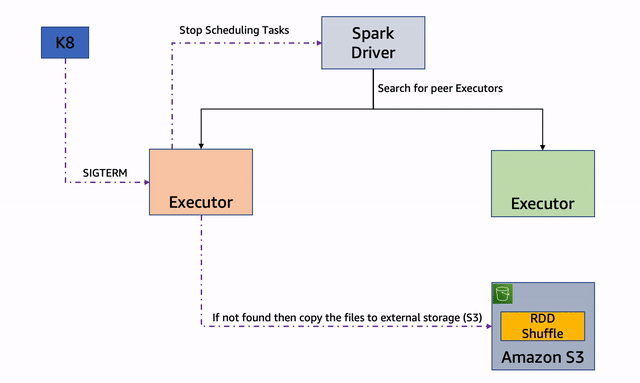
Gambar 1 : Penonaktifan Node
Mari kita lihat langkah-langkah penonaktifan lebih detail.
Jika salah satu node yang menjalankan eksekutor terganggu, eksekutor memulai proses penonaktifan dan mengirimkan pesan ke driver:
Eksekutor mencari file RDD atau shuffle dan mencoba mereplikasi atau memigrasikan file tersebut. Ini pertama kali mencoba untuk menemukan pelaksana rekan. Jika berhasil, itu akan memindahkan file ke pelaksana peer:
Namun, jika tidak dapat menemukan pelaksana rekan, ia akan mencoba memindahkan file ke penyimpanan cadangan jika tersedia.
Gambar 2: Penyimpanan Fallback
Pelaksana kemudian dinonaktifkan. Saat eksekutor baru muncul, file acak digunakan kembali:
Keuntungan utama dari proses ini adalah memungkinkan migrasi blok dan pengacakan data, sehingga mengurangi penghitungan ulang, yang menambah ketahanan keseluruhan sistem dan mengurangi runtime. Proses ini dapat dipicu oleh sinyal interupsi Spot (Sigterm) dan node draining. Pengurasan node dapat terjadi karena penjadwalan tugas prioritas tinggi atau secara mandiri.
Saat Anda menggunakan Amazon EMR di EKS dengan node terkelola groups/Karpenter, penanganan interupsi Spot otomatis, di mana Amazon EKS dengan anggun menguras dan menyeimbangkan kembali node Spot untuk meminimalkan gangguan aplikasi saat node Spot berada pada risiko interupsi yang tinggi. Jika Anda menggunakan node terkelola groups/Karpenter, penonaktifan dipicu saat node terkuras dan karena proaktif, ini memberi Anda lebih banyak waktu (setidaknya 2 menit) untuk memindahkan file. Dalam kasus grup node yang dikelola sendiri, kami merekomendasikan penginstalan AWS Node Termination Handler untuk menangani interupsi, dan penonaktifan dipicu saat pemberitahuan reaktif (2 menit) diterima. Kami merekomendasikan untuk menggunakan Karpenter dengan Instans Spot karena memiliki penjadwalan node yang lebih cepat dengan pengikatan pod awal dan binpacking untuk mengoptimalkan penggunaan sumber daya.
Kode berikut mengaktifkan konfigurasi ini; rincian lebih lanjut tersedia di GitHub:
penggunaan ulang PVC
Apache Spark mengaktifkan PVC dinamis di versi 3.1, yang berguna dengan alokasi dinamis karena kita tidak perlu membuat klaim atau volume sebelumnya untuk pelaksana dan menghapusnya setelah selesai. PVC memungkinkan pemisahan data dan pemrosesan yang sesungguhnya saat kita menjalankan tugas Spark di Kubernetes, karena kita juga bisa menggunakannya sebagai penyimpanan lokal untuk menumpahkan file yang sedang dalam proses. Versi terbaru Amazon EMR 6.8 telah mengintegrasikan fitur penggunaan kembali PVC dari Spark, di mana jika eksekutor dihentikan karena gangguan EC2 Spot atau alasan lainnya (JVM), maka PVC tidak akan dihapus tetapi dipertahankan dan disambungkan kembali ke eksekutor lain. Jika ada file acak dalam volume itu, maka file tersebut akan digunakan kembali.
Seperti halnya decommission node, ini mengurangi runtime keseluruhan karena kita tidak perlu menghitung ulang file acak. Kami juga menghemat waktu yang diperlukan untuk meminta volume baru untuk pelaksana, dan file acak dapat digunakan kembali tanpa memindahkan file.
Diagram berikut menggambarkan alur kerja ini.
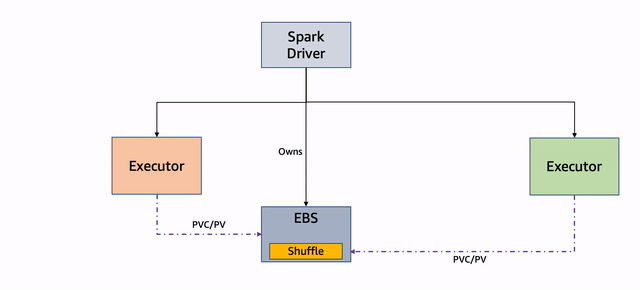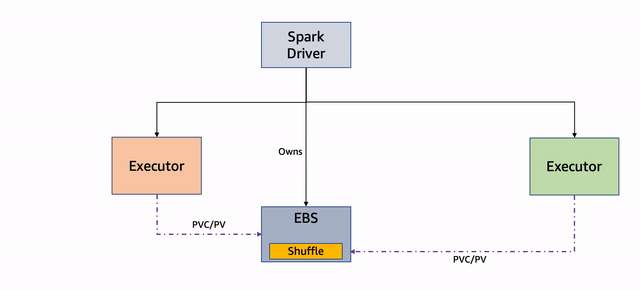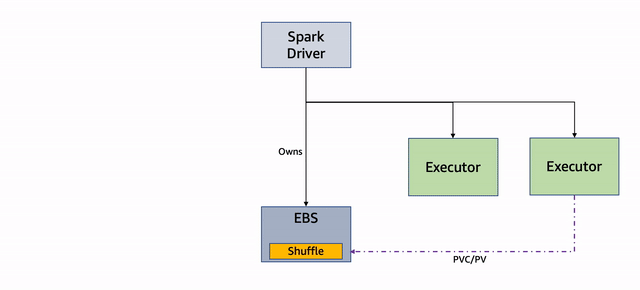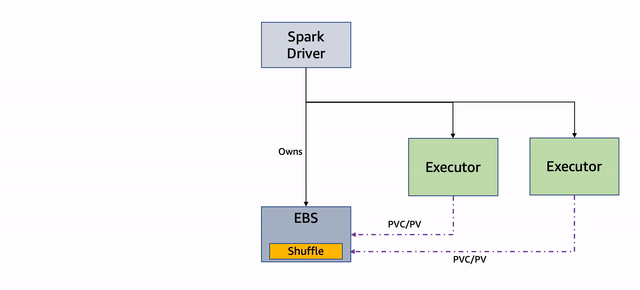
Gambar 3: Penggunaan Ulang PVC
Mari kita lihat langkah-langkahnya lebih detail.
Jika satu atau lebih node yang menjalankan eksekutor terganggu, pod yang mendasarinya dihentikan dan driver mendapatkan pembaruan. Perhatikan bahwa driver adalah pemilik PVC dari pelaksana, dan mereka tidak dihentikan. Lihat kode berikut:
ExecutorPodsAllocator mencoba mengalokasikan pod eksekutor baru untuk menggantikan yang dihentikan karena gangguan. Selama alokasi, diketahui berapa banyak PVC yang ada yang memiliki file dan dapat digunakan kembali:
ExecutorPodsAllocator meminta sebuah pod dan ketika meluncurkannya, PVC digunakan kembali. Dalam contoh berikut, PVC dari pelaksana 6 digunakan kembali untuk pod pelaksana baru 11:
File acak, jika ada di PVC digunakan kembali.
Keuntungan utama dari teknik ini adalah memungkinkan kita untuk menggunakan kembali file pengacakan yang telah dihitung sebelumnya di lokasi aslinya, sehingga mengurangi waktu keseluruhan pekerjaan dijalankan.
Ini berfungsi untuk PVC statis dan dinamis. Amazon EKS penawaran tiga penawaran penyimpanan berbeda, yang juga dapat dienkripsi: Toko Blok Elastis Amazon (AmazonEBS), Sistem File Amazon Elastis (Amazon EFS), dan Amazon FSx untuk Lustre. Kami merekomendasikan penggunaan PVC dinamis dengan Amazon EBS karena dengan PVC statis, Anda perlu membuat beberapa PVC.
Kode berikut mengaktifkan konfigurasi ini; rincian lebih lanjut tersedia di GitHub:
Agar ini berfungsi, kita perlu mengaktifkan PVC dengan Amazon EKS dan menyebutkan detailnya di konfigurasi waktu proses Spark. Untuk instruksi, lihat Bagaimana cara menggunakan penyimpanan persisten di Amazon EKS? Kode berikut berisi detail konfigurasi Spark untuk menggunakan PVC sebagai penyimpanan lokal; rincian lainnya tersedia di GitHub:
Kesimpulan
Dengan Amazon EMR di EKS (6.9) dan fitur-fitur yang dibahas dalam postingan ini, Anda dapat lebih mengurangi waktu proses keseluruhan untuk pekerjaan Spark saat dijalankan dengan Instans Spot. Ini juga meningkatkan ketahanan dan fleksibilitas pekerjaan secara keseluruhan sambil mengoptimalkan biaya beban kerja di EC2 Spot.
Cobalah ESDM pada lokakarya EKS untuk peningkatan kinerja saat menjalankan beban kerja Spark di Kubernetes dan mengoptimalkan biaya menggunakan Instans Spot EC2.
tentang Penulis
 Kinnar Kumar Sen adalah Sr. Solutions Architect di Amazon Web Services (AWS) yang berfokus pada Flexible Compute. Sebagai bagian dari tim EC2 Flexible Compute, dia bekerja dengan pelanggan untuk memandu mereka ke opsi komputasi paling elastis dan efisien yang sesuai untuk beban kerja mereka yang berjalan di AWS. Kinnar memiliki lebih dari 15 tahun pengalaman industri bekerja dalam penelitian, konsultasi, teknik, dan arsitektur.
Kinnar Kumar Sen adalah Sr. Solutions Architect di Amazon Web Services (AWS) yang berfokus pada Flexible Compute. Sebagai bagian dari tim EC2 Flexible Compute, dia bekerja dengan pelanggan untuk memandu mereka ke opsi komputasi paling elastis dan efisien yang sesuai untuk beban kerja mereka yang berjalan di AWS. Kinnar memiliki lebih dari 15 tahun pengalaman industri bekerja dalam penelitian, konsultasi, teknik, dan arsitektur.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/run-fault-tolerant-and-cost-optimized-spark-clusters-using-amazon-emr-on-eks-and-amazon-ec2-spot-instances/
- 1
- 10
- 100
- 11
- 15 tahun
- 7
- 9
- a
- Sanggup
- dicapai
- Tindakan
- menambahkan
- alamat
- Menambahkan
- Keuntungan
- Setelah
- alokasi
- memungkinkan
- Amazon
- Amazon EC2
- Amazon ESDM
- Amazon Web Services
- Layanan Web Amazon (AWS)
- dan
- Lain
- Apache
- berlaku
- Aplikasi
- arsitektur
- Otomatis
- tersedia
- AWS
- kembali
- karena
- makhluk
- Memblokir
- Blok
- Cache
- Kapasitas
- kasus
- pilihan
- klaim
- klaim
- Kelompok
- kode
- penyelesaian
- komputasi
- menghitung
- konfigurasi
- konsultasi
- mengandung
- Biaya
- Biaya
- membuat
- pelanggan
- data
- penyebaran
- rinci
- rincian
- berbeda
- Diskon
- membahas
- dibahas
- Gangguan
- Dont
- terkuras
- pengemudi
- driver
- selama
- dinamis
- Awal
- efisien
- tinggi
- aktif
- memungkinkan
- terenkripsi
- Teknik
- Eter (ETH)
- contoh
- ada
- Exit
- pengalaman
- gagal
- lebih cepat
- Fitur
- Fitur
- angka-angka
- File
- File
- Menemukan
- Pertama
- keluwesan
- fleksibel
- berfokus
- berikut
- ditemukan
- Kerangka
- dari
- FS
- lebih lanjut
- mendapatkan
- mendapatkan
- gif
- GitHub
- memberikan
- besar
- Kelompok
- Grup
- membimbing
- menangani
- Penanganan
- terjadi
- membantu
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTML
- HTTPS
- Dampak
- ditingkatkan
- meningkatkan
- in
- Meningkatkan
- meningkatkan
- secara mandiri
- indeks
- industri
- Info
- Instalasi
- contoh
- instruksi
- terpadu
- terganggu
- isu
- IT
- Pekerjaan
- Jobs
- kunci
- Terbaru
- meluncurkan
- adalah ide yang bagus
- lokal
- tempat
- log4j
- melihat
- mencari
- TERLIHAT
- berhasil
- manajer
- banyak
- peta
- tanda
- pesan
- Metrik
- bermigrasi
- menit
- dimodifikasi
- lebih
- paling
- MOUNT
- pindah
- bergerak
- bergerak
- beberapa
- nama
- Bernama
- Perlu
- kebutuhan
- New
- simpul
- node
- pemberitahuan
- Penawaran
- ONE
- optimasi
- Optimize
- dioptimalkan
- mengoptimalkan
- pilihan
- Opsi
- asli
- Lainnya
- secara keseluruhan
- pemilik
- bagian
- path
- buah pir
- prestasi
- plato
- Kecerdasan Data Plato
- Data Plato
- Pos
- menyajikan
- mencegah
- harga
- Proaktif
- proses
- pengolahan
- properties
- memberikan
- disediakan
- menyediakan
- ketentuan
- alasan
- diterima
- sarankan
- Memulihkan
- pemulihan
- menurunkan
- mengurangi
- mengurangi
- dirilis
- terpencil
- menggantikan
- permintaan
- permintaan
- wajib
- penelitian
- tabah
- sumber
- dapat digunakan kembali
- Risiko
- bulat
- Run
- berjalan
- Save
- layanan
- Layanan
- kocokan
- penutupan
- Sinyal
- menyederhanakan
- Solusi
- beberapa
- percikan
- Spot
- Stabilitas
- Mulai
- dimulai
- Tangga
- penyimpanan
- sukses
- seperti itu
- cocok
- pendukung
- sistem
- tugas
- tim
- Grafik
- mereka
- dengan demikian
- karena itu
- tiga
- keluaran
- waktu
- untuk
- toleransi
- terlalu
- dipicu
- benar
- pokok
- Memperbarui
- memperbarui
- us
- menggunakan
- versi
- volume
- volume
- peringatan
- jaringan
- layanan web
- yang
- sementara
- akan
- tanpa
- Kerja
- kerja
- bekerja
- akan
- XML
- tahun
- Anda
- zephyrnet.dll