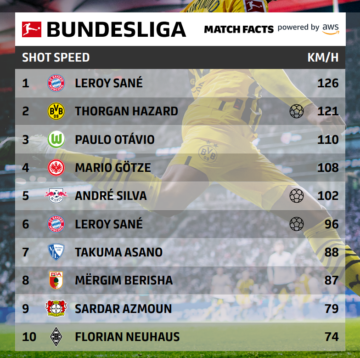
Dalam visi komputer, segmentasi semantik adalah tugas mengklasifikasikan setiap piksel dalam suatu gambar dengan kelas dari sekumpulan label yang diketahui sedemikian rupa sehingga piksel dengan label yang sama memiliki karakteristik tertentu. Ini menghasilkan topeng segmentasi dari gambar input. Misalnya, gambar berikut menunjukkan topeng segmentasi dari: cat label.
 |
 |
Di 2018 November, Amazon SageMaker mengumumkan peluncuran algoritma segmentasi semantik SageMaker. Dengan algoritme ini, Anda dapat melatih model Anda dengan kumpulan data publik atau kumpulan data Anda sendiri. Kumpulan data segmentasi gambar yang populer mencakup kumpulan data Common Objects in Context (COCO) dan PASCAL Visual Object Classes (PASCAL VOC), tetapi kelas labelnya terbatas dan Anda mungkin ingin melatih model pada objek target yang tidak disertakan dalam kumpulan data publik. Dalam hal ini, Anda dapat menggunakan Kebenaran Dasar Amazon SageMaker untuk memberi label dataset Anda sendiri.
Dalam posting ini, saya menunjukkan solusi berikut:
- Menggunakan Ground Truth untuk memberi label pada dataset segmentasi semantik
- Mengubah hasil dari Ground Truth ke format input yang diperlukan untuk algoritme segmentasi semantik bawaan SageMaker
- Menggunakan algoritma segmentasi semantik untuk melatih model dan melakukan inferensi
Pelabelan data segmentasi semantik
Untuk membangun model pembelajaran mesin untuk segmentasi semantik, kita perlu memberi label pada set data pada tingkat piksel. Ground Truth memberi Anda opsi untuk menggunakan annotator manusia melalui Amazon Mechanical Turk, vendor pihak ketiga, atau tenaga kerja pribadi Anda sendiri. Untuk mempelajari lebih lanjut tentang tenaga kerja, lihat Buat dan Kelola Tenaga Kerja. Jika Anda tidak ingin mengelola tenaga kerja pelabelan sendiri, Kebenaran Dasar Amazon SageMaker Plus adalah opsi hebat lainnya sebagai layanan pelabelan data turnkey baru yang memungkinkan Anda membuat set data pelatihan berkualitas tinggi dengan cepat dan mengurangi biaya hingga 40%. Untuk posting ini, saya menunjukkan kepada Anda cara memberi label dataset secara manual dengan fitur segmen otomatis Ground Truth dan pelabelan crowdsource dengan tenaga kerja Mechanical Turk.
Pelabelan manual dengan Ground Truth
Pada bulan Desember 2019, Ground Truth menambahkan fitur segmen otomatis ke antarmuka pengguna pelabelan segmentasi semantik untuk meningkatkan throughput pelabelan dan meningkatkan akurasi. Untuk informasi lebih lanjut, lihat Menyegmentasikan objek secara otomatis saat melakukan pelabelan segmentasi semantik dengan Amazon SageMaker Ground Truth. Dengan fitur baru ini, Anda dapat mempercepat proses pelabelan Anda pada tugas-tugas segmentasi. Alih-alih menggambar poligon yang pas atau menggunakan alat kuas untuk menangkap objek dalam gambar, Anda hanya menggambar empat titik: di titik paling atas, paling bawah, paling kiri, dan paling kanan dari objek. Ground Truth mengambil empat titik ini sebagai input dan menggunakan algoritma Deep Extreme Cut (DEXTR) untuk menghasilkan topeng yang pas di sekitar objek. Untuk tutorial menggunakan Ground Truth untuk pelabelan segmentasi semantik gambar, lihat Segmentasi Semantik Gambar. Berikut ini adalah contoh bagaimana alat segmentasi otomatis menghasilkan topeng segmentasi secara otomatis setelah Anda memilih empat titik ekstrim dari suatu objek.


Pelabelan crowdsourcing dengan tenaga kerja Mechanical Turk
Jika Anda memiliki kumpulan data yang besar dan Anda tidak ingin memberi label sendiri pada ratusan atau ribuan gambar secara manual, Anda dapat menggunakan Mechanical Turk, yang menyediakan tenaga kerja manusia sesuai permintaan, skalabel, untuk menyelesaikan pekerjaan yang dapat dilakukan manusia lebih baik daripada komputer. Perangkat lunak Mechanical Turk memformalkan tawaran pekerjaan kepada ribuan pekerja yang bersedia melakukan pekerjaan sedikit demi sedikit demi kenyamanan mereka. Perangkat lunak juga mengambil pekerjaan yang dilakukan dan mengkompilasinya untuk Anda, pemohon, yang membayar pekerja untuk pekerjaan yang memuaskan (hanya). Untuk memulai dengan Mechanical Turk, lihat Pengantar Amazon Mechanical Turk.
Buat tugas pelabelan
Berikut adalah contoh tugas pelabelan Mechanical Turk untuk set data penyu. Kumpulan data penyu berasal dari kompetisi Kaggle Deteksi Wajah Penyu Laut, dan saya memilih 300 gambar kumpulan data untuk tujuan demonstrasi. Penyu bukan kelas umum dalam kumpulan data publik sehingga dapat mewakili situasi yang memerlukan pelabelan kumpulan data besar.
- Di konsol SageMaker, pilih Pekerjaan pelabelan di panel navigasi.
- Pilih Buat pekerjaan pelabelan.
- Masukkan nama untuk pekerjaan Anda.
- Untuk Masukkan pengaturan data, pilih Pengaturan data otomatis.
Ini menghasilkan manifes data input. - Untuk Lokasi S3 untuk set data input, masukkan jalur untuk kumpulan data.

- Untuk Kategori tugas, pilih Gambar.
- Untuk Pemilihan tugas, pilih Segmentasi semantik.

- Untuk Jenis pekerja, pilih Amazon Mechanical Turk.
- Konfigurasikan pengaturan Anda untuk waktu tunggu tugas, waktu kedaluwarsa tugas, dan harga per tugas.

- Tambahkan label (untuk postingan ini,
sea turtle), dan berikan petunjuk pelabelan. - Pilih membuat.

Setelah Anda mengatur pekerjaan pelabelan, Anda dapat memeriksa kemajuan pelabelan di konsol SageMaker. Ketika ditandai sebagai selesai, Anda dapat memilih pekerjaan untuk memeriksa hasilnya dan menggunakannya untuk langkah selanjutnya.

Transformasi kumpulan data
Setelah Anda mendapatkan output dari Ground Truth, Anda dapat menggunakan algoritme bawaan SageMaker untuk melatih model pada kumpulan data ini. Pertama, Anda perlu menyiapkan kumpulan data berlabel sebagai antarmuka input yang diminta untuk algoritma segmentasi semantik SageMaker.
Saluran data masukan yang diminta
Segmentasi semantik SageMaker mengharapkan set data pelatihan Anda disimpan di Layanan Penyimpanan Sederhana Amazon (Amazon S3). Dataset di Amazon S3 diharapkan disajikan dalam dua saluran, satu untuk train dan satu untuk validation, menggunakan empat direktori, dua untuk gambar dan dua untuk anotasi. Anotasi diharapkan berupa gambar PNG yang tidak dikompresi. Kumpulan data mungkin juga memiliki peta label yang menjelaskan bagaimana pemetaan anotasi dibuat. Jika tidak, algoritma menggunakan default. Untuk inferensi, titik akhir menerima gambar dengan image/jpeg Jenis konten. Berikut ini adalah struktur saluran data yang diperlukan:
Setiap gambar JPG di direktori kereta dan validasi memiliki gambar label PNG yang sesuai dengan nama yang sama di train_annotation dan validation_annotation direktori. Konvensi penamaan ini membantu algoritme mengaitkan label dengan gambar yang sesuai selama pelatihan. Kereta, train_annotation, validasi, dan validation_annotation saluran adalah wajib. Anotasi adalah gambar PNG saluran tunggal. Format ini berfungsi selama metadata (mode) dalam gambar membantu algoritme membaca gambar anotasi menjadi integer unsigned 8-bit saluran tunggal.
Keluaran dari pekerjaan pelabelan Ground Truth
Output yang dihasilkan dari pekerjaan pelabelan Ground Truth memiliki struktur folder berikut:
Masker segmentasi disimpan di s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Setiap gambar anotasi adalah file .png yang dinamai berdasarkan indeks gambar sumber dan waktu pelabelan gambar ini selesai. Misalnya, berikut adalah gambar sumber (Image_1.jpg) dan topeng segmentasi yang dihasilkan oleh tenaga kerja Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Perhatikan bahwa indeks topeng berbeda dari nomor dalam nama gambar sumber.
 |
 |
Manifes keluaran dari pekerjaan pelabelan ada di /manifests/output/output.manifest mengajukan. Ini adalah file JSON, dan setiap baris merekam pemetaan antara gambar sumber dan labelnya serta metadata lainnya. Baris JSON berikut merekam pemetaan antara gambar sumber yang ditampilkan dan anotasinya:
Gambar sumber disebut Image_1.jpg, dan nama anotasinya adalah 0_2022-02-10T17:41: 04.724225.png. Untuk menyiapkan data sebagai format saluran data yang diperlukan dari algoritma segmentasi semantik SageMaker, kita perlu mengubah nama anotasi agar memiliki nama yang sama dengan gambar JPG sumber. Dan kita juga perlu membagi dataset menjadi train dan validation direktori untuk gambar sumber dan anotasi.
Ubah output dari pekerjaan pelabelan Ground Truth ke format input yang diminta
Untuk mengubah output, selesaikan langkah-langkah berikut:
- Unduh semua file dari pekerjaan pelabelan dari Amazon S3 ke direktori lokal:
- Baca file manifes dan ubah nama anotasi menjadi nama yang sama dengan gambar sumber:
- Pisahkan set data kereta dan validasi:
- Buat direktori dalam format yang diperlukan untuk saluran data algoritma segmentasi semantik:
- Pindahkan gambar kereta dan validasi serta anotasinya ke direktori yang dibuat.
- Untuk gambar, gunakan kode berikut:
- Untuk anotasi, gunakan kode berikut:
- Unggah set data pelatihan dan validasi serta set data anotasinya ke Amazon S3:
Pelatihan model segmentasi semantik SageMaker
Di bagian ini, kami menelusuri langkah-langkah untuk melatih model segmentasi semantik Anda.
Ikuti contoh buku catatan dan atur saluran data
Anda dapat mengikuti petunjuk di Algoritme Semantik Segmentasi sekarang tersedia di Amazon SageMaker untuk mengimplementasikan algoritme segmentasi semantik ke kumpulan data berlabel Anda. sampel ini buku catatan menunjukkan contoh ujung ke ujung yang memperkenalkan algoritma. Di buku catatan, Anda mempelajari cara melatih dan menghosting model segmentasi semantik menggunakan jaringan konvolusi penuh (FCN) algoritma menggunakan Dataset Pascal VOC untuk latihan. Karena saya tidak berencana untuk melatih model dari dataset Pascal VOC, saya melewatkan Langkah 3 (persiapan data) di buku catatan ini. Sebagai gantinya, saya langsung membuat train_channel, train_annotation_channe, validation_channel, dan validation_annotation_channel menggunakan lokasi S3 tempat saya menyimpan gambar dan anotasi saya:
Sesuaikan hyperparameters untuk dataset Anda sendiri di estimator SageMaker
Saya mengikuti buku catatan dan membuat objek penaksir SageMaker (ss_estimator) untuk melatih algoritma segmentasi saya. Satu hal yang perlu kita sesuaikan untuk dataset baru adalah di ss_estimator.set_hyperparameters: kita perlu berubah num_classes=21 untuk num_classes=2 (turtle dan background), dan saya juga berubah epochs=10 untuk epochs=30 karena 10 hanya untuk tujuan demo. Kemudian saya menggunakan instance p3.2xlarge untuk pelatihan model dengan menyetel instance_type="ml.p3.2xlarge". Pelatihan selesai dalam 8 menit. Terbaik MIOU (Mean Intersection over Union) sebesar 0.846 dicapai pada epoch 11 dengan a pix_acc (persentase piksel dalam gambar Anda yang diklasifikasikan dengan benar) sebesar 0.925, yang merupakan hasil yang cukup bagus untuk kumpulan data kecil ini.
Hasil inferensi model
Saya menghosting model pada instance ml.c5.xlarge berbiaya rendah:
Terakhir, saya menyiapkan test set 10 gambar kura-kura untuk melihat hasil inferensi dari model segmentasi yang dilatih:
Gambar berikut menunjukkan hasilnya.

Masker segmentasi penyu terlihat akurat dan saya senang dengan hasil ini yang dilatih pada dataset 300 gambar yang diberi label oleh pekerja Mechanical Turk. Anda juga dapat menjelajahi jaringan lain yang tersedia seperti jaringan penguraian adegan piramida (PSP) or DeepLab-V3 di buku catatan sampel dengan set data Anda.
Membersihkan
Hapus titik akhir setelah Anda selesai menggunakannya untuk menghindari timbulnya biaya lanjutan:
Kesimpulan
Dalam posting ini, saya menunjukkan cara menyesuaikan pelabelan data segmentasi semantik dan pelatihan model menggunakan SageMaker. Pertama, Anda dapat menyiapkan pekerjaan pelabelan dengan alat segmentasi otomatis atau menggunakan tenaga kerja Mechanical Turk (serta opsi lainnya). Jika Anda memiliki lebih dari 5,000 objek, Anda juga dapat menggunakan pelabelan data otomatis. Kemudian Anda mengubah output dari pekerjaan pelabelan Ground Truth Anda ke format input yang diperlukan untuk pelatihan segmentasi semantik bawaan SageMaker. Setelah itu, Anda dapat menggunakan instance komputasi yang dipercepat (seperti p2 atau p3) untuk melatih model segmentasi semantik dengan yang berikut ini buku catatan dan menerapkan model ke instans yang lebih hemat biaya (seperti ml.c5.xlarge). Terakhir, Anda dapat meninjau hasil inferensi pada dataset pengujian Anda dengan beberapa baris kode.
Mulailah dengan segmentasi semantik SageMaker pelabelan data dan pelatihan model dengan kumpulan data favorit Anda!
tentang Penulis
 Kara Yang adalah Ilmuwan Data di AWS Professional Services. Dia bersemangat membantu pelanggan mencapai tujuan bisnis mereka dengan layanan cloud AWS. Dia telah membantu organisasi membangun solusi ML di berbagai industri seperti manufaktur, otomotif, kelestarian lingkungan, dan kedirgantaraan.
Kara Yang adalah Ilmuwan Data di AWS Professional Services. Dia bersemangat membantu pelanggan mencapai tujuan bisnis mereka dengan layanan cloud AWS. Dia telah membantu organisasi membangun solusi ML di berbagai industri seperti manufaktur, otomotif, kelestarian lingkungan, dan kedirgantaraan.
- Coinsmart. Pertukaran Bitcoin dan Crypto Terbaik Eropa.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. AKSES GRATIS.
- CryptoHawk. Radar Altcoin. Uji Coba Gratis.
- Sumber: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Tentang Kami
- mempercepat
- dipercepat
- tepat
- Mencapai
- dicapai
- di seluruh
- menambahkan
- Aerospace
- algoritma
- algoritma
- Semua
- Amazon
- mengumumkan
- Lain
- sekitar
- Menghubungkan
- Otomatis
- secara otomatis
- otomotif
- tersedia
- AWS
- latar belakang
- karena
- TERBAIK
- Lebih baik
- antara
- membangun
- built-in
- bisnis
- menangkap
- kasus
- tertentu
- perubahan
- saluran
- Pilih
- kelas
- kelas-kelas
- tergolong
- awan
- layanan cloud
- kode
- Umum
- kompetisi
- lengkap
- komputer
- komputer
- komputasi
- kepercayaan
- konsul
- Konten
- kenyamanan
- Sesuai
- hemat biaya
- Biaya
- membuat
- dibuat
- pelanggan
- menyesuaikan
- data
- ilmuwan data
- mendalam
- mendemonstrasikan
- menyebarkan
- berbeda
- langsung
- gambar
- selama
- setiap
- memungkinkan
- ujung ke ujung
- Titik akhir
- Enter
- lingkungan
- mapan
- contoh
- Kecuali
- diharapkan
- mengharapkan
- menyelidiki
- ekstrim
- Menghadapi
- Fitur
- Pertama
- mengikuti
- berikut
- format
- dari
- dihasilkan
- Anda
- baik
- abu-abu
- besar
- senang
- membantu
- membantu
- membantu
- berkualitas tinggi
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTTPS
- manusia
- Manusia
- Ratusan
- gambar
- gambar
- melaksanakan
- memperbaiki
- memasukkan
- termasuk
- Meningkatkan
- indeks
- industri
- informasi
- memasukkan
- contoh
- Antarmuka
- persimpangan
- memperkenalkan
- IT
- Pekerjaan
- Jobs
- dikenal
- label
- pelabelan
- Label
- besar
- jalankan
- BELAJAR
- pengetahuan
- Tingkat
- Terbatas
- baris
- baris
- Daftar
- lokal
- tempat
- lokasi
- Panjang
- melihat
- mesin
- Mesin belajar
- mengelola
- wajib
- manual
- pabrik
- peta
- pemetaan
- masker
- masker
- besar-besaran
- mekanis
- mungkin
- ML
- model
- model
- lebih
- beberapa
- nama
- penamaan
- Navigasi
- jaringan
- jaringan
- berikutnya
- buku catatan
- jumlah
- Penawaran
- pilihan
- Opsi
- organisasi
- Lainnya
- sendiri
- bergairah
- persen
- melakukan
- poin
- Poligon
- Populer
- Mempersiapkan
- cukup
- harga pompa cor beton mini
- swasta
- proses
- menghasilkan
- profesional
- memberikan
- menyediakan
- publik
- tujuan
- segera
- RE
- arsip
- mewakili
- wajib
- membutuhkan
- Hasil
- ulasan
- sama
- terukur
- ilmuwan
- SEA
- segmentasi
- terpilih
- layanan
- Layanan
- set
- pengaturan
- Share
- Menunjukkan
- ditunjukkan
- Sederhana
- situasi
- kecil
- So
- Perangkat lunak
- Solusi
- membagi
- mulai
- penyimpanan
- Keberlanjutan
- target
- tugas
- tim
- uji
- Grafik
- Sumber
- hal
- pihak ketiga
- ribuan
- Melalui
- keluaran
- waktu
- alat
- Pelatihan VE
- Pelatihan
- Mengubah
- serikat
- menggunakan
- pengesahan
- vendor
- penglihatan
- SIAPA
- Kerja
- pekerja
- Tenaga kerja
- bekerja
- Anda