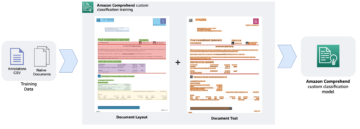
Ketika OpenAI merilis generasi ketiga model pembelajaran mesin (ML) mereka yang berspesialisasi dalam pembuatan teks pada Juli 2020, saya tahu ada sesuatu yang berbeda. Model ini mengejutkan seperti tidak ada yang datang sebelumnya. Tiba-tiba saya mendengar teman dan kolega, yang mungkin tertarik dengan teknologi tetapi biasanya tidak terlalu peduli dengan kemajuan terbaru di bidang AI/ML, membicarakannya. Bahkan Guardian menulis sebuah artikel tentang itu. Atau, lebih tepatnya, model menulis artikel dan Guardian mengedit dan menerbitkannya. Tidak dapat disangkal- GPT-3 adalah pengubah permainan.
Setelah model tersebut dirilis, orang-orang segera mulai membuat aplikasi potensial untuk itu. Dalam beberapa minggu, banyak demo yang mengesankan telah dibuat, yang dapat ditemukan di Situs web GPT-3. Satu aplikasi tertentu yang menarik perhatian saya adalah ringkasan teks – kemampuan komputer untuk membaca teks tertentu dan meringkas isinya. Ini adalah salah satu tugas tersulit untuk komputer karena menggabungkan dua bidang dalam bidang pemrosesan bahasa alami (NLP): pemahaman membaca dan pembuatan teks. Itulah sebabnya saya sangat terkesan dengan demo GPT-3 untuk peringkasan teks.
Anda dapat mencobanya di Situs web Hugging Face Spaces. Salah satu favorit saya saat ini adalah aplikasi yang menghasilkan ringkasan artikel berita hanya dengan URL artikel sebagai masukan.
Dalam seri dua bagian ini, saya mengusulkan panduan praktis untuk organisasi sehingga Anda dapat menilai kualitas model peringkasan teks untuk domain Anda.
Ikhtisar tutorial
Banyak organisasi tempat saya bekerja (amal, perusahaan, LSM) memiliki banyak sekali teks yang perlu mereka baca dan rangkum – laporan keuangan atau artikel berita, makalah penelitian ilmiah, aplikasi paten, kontrak hukum, dan banyak lagi. Secara alami, organisasi-organisasi ini tertarik untuk mengotomatisasi tugas-tugas ini dengan teknologi NLP. Untuk mendemonstrasikan seni kemungkinan, saya sering menggunakan demo peringkasan teks, yang hampir tidak pernah gagal untuk mengesankan.
Tapi sekarang bagaimana?
Tantangan bagi organisasi-organisasi ini adalah mereka ingin menilai model peringkasan teks berdasarkan ringkasan untuk banyak, banyak dokumen – bukan satu per satu. Mereka tidak ingin mempekerjakan pekerja magang yang tugasnya hanya membuka aplikasi, menempel di dokumen, tekan tombol Meringkaskan tombol, tunggu hasilnya, nilai apakah ringkasannya bagus, dan lakukan itu lagi untuk ribuan dokumen.
Saya menulis tutorial ini dengan mengingat diri saya di masa lalu dari empat minggu yang lalu – ini adalah tutorial yang saya harap saya miliki saat itu ketika saya memulai perjalanan ini. Dalam hal ini, audiens target dari tutorial ini adalah seseorang yang akrab dengan AI/ML dan telah menggunakan model Transformer sebelumnya, tetapi berada di awal perjalanan peringkasan teks mereka dan ingin mempelajarinya lebih dalam. Karena ini ditulis oleh "pemula" dan untuk pemula, saya ingin menekankan fakta bahwa tutorial ini adalah a panduan praktis – bukan itu panduan praktis. Tolong perlakukan itu seolah-olah George EP Box telah mengatakan:
![]()
Dalam hal seberapa banyak pengetahuan teknis yang diperlukan dalam tutorial ini: Ini memang melibatkan beberapa pengkodean dengan Python, tetapi sebagian besar waktu kami hanya menggunakan kode untuk memanggil API, jadi tidak diperlukan pengetahuan pengkodean yang mendalam juga. Sangat membantu untuk memahami konsep ML tertentu, seperti apa artinya kereta api dan menyebarkan model, konsep latihan, pengesahan, dan kumpulan data uji, dan seterusnya. Juga mencoba-coba dengan perpustakaan transformer sebelum mungkin berguna, karena kami menggunakan perpustakaan ini secara ekstensif sepanjang tutorial ini. Saya juga menyertakan tautan yang berguna untuk bacaan lebih lanjut untuk konsep-konsep ini.
Karena tutorial ini ditulis oleh seorang pemula, saya tidak berharap para ahli NLP dan praktisi deep learning tingkat lanjut mendapatkan banyak dari tutorial ini. Setidaknya tidak dari perspektif teknis – Anda mungkin masih menikmati membaca, jadi tolong jangan pergi dulu! Tetapi Anda harus bersabar sehubungan dengan penyederhanaan saya – saya mencoba untuk hidup dengan konsep membuat segala sesuatu dalam tutorial ini sesederhana mungkin, tetapi tidak sederhana.
Struktur tutorial ini
Seri ini membentang lebih dari empat bagian yang dibagi menjadi dua pos, di mana kita melalui berbagai tahap proyek peringkasan teks. Di pos pertama (bagian 1), kami mulai dengan memperkenalkan metrik untuk tugas peringkasan teks – ukuran kinerja yang memungkinkan kami menilai apakah ringkasan itu baik atau buruk. Kami juga memperkenalkan kumpulan data yang ingin kami rangkum dan membuat garis dasar menggunakan model no-ML – kami menggunakan heuristik sederhana untuk menghasilkan ringkasan dari teks tertentu. Membuat baseline ini adalah langkah yang sangat penting dalam setiap proyek ML karena memungkinkan kami untuk mengukur seberapa banyak kemajuan yang kami buat dengan menggunakan AI di masa mendatang. Ini memungkinkan kita untuk menjawab pertanyaan “Apakah benar-benar layak untuk berinvestasi dalam teknologi AI?”
Pada posting kedua, kami menggunakan model yang telah dilatih sebelumnya untuk menghasilkan ringkasan (bagian 2). Ini dimungkinkan dengan pendekatan modern dalam ML yang disebut belajar transfer. Ini adalah langkah lain yang berguna karena pada dasarnya kami mengambil model siap pakai dan mengujinya di kumpulan data kami. Ini memungkinkan kita untuk membuat garis dasar lain, yang membantu kita melihat apa yang terjadi ketika kita benar-benar melatih model pada kumpulan data kita. Pendekatannya disebut ringkasan nol-shot, karena model tidak memiliki eksposur ke set data kami.
Setelah itu, saatnya menggunakan model yang telah dilatih sebelumnya dan melatihnya pada dataset kita sendiri (bagian 3). Ini juga disebut mencari setelan. Ini memungkinkan model untuk belajar dari pola dan keanehan data kami dan perlahan beradaptasi dengannya. Setelah kita melatih modelnya, kita menggunakannya untuk membuat ringkasan (bagian 4).
Untuk meringkas:
- Bagian 1:
- Bagian 1: Gunakan model tanpa-ML untuk menetapkan garis dasar
- bagian 2:
- Bagian 2: Membuat ringkasan dengan model zero-shot
- Bagian 3: Melatih model peringkasan
- Bagian 4: Evaluasi model yang dilatih
Seluruh kode untuk tutorial ini tersedia di bawah ini GitHub repo.
Apa yang akan kita capai pada akhir tutorial ini?
Di akhir tutorial ini, kita tidak akan memiliki model peringkasan teks yang dapat digunakan dalam produksi. Kami bahkan tidak akan memiliki baik model ringkasan (masukkan emoji teriakan di sini)!
Apa yang akan kita miliki adalah titik awal untuk fase proyek berikutnya, yaitu fase eksperimen. Di sinilah "sains" dalam ilmu data masuk, karena sekarang ini semua tentang bereksperimen dengan model yang berbeda dan pengaturan yang berbeda untuk memahami apakah model peringkasan yang cukup baik dapat dilatih dengan data pelatihan yang tersedia.
Dan, agar benar-benar transparan, kemungkinan besar kesimpulannya adalah bahwa teknologinya belum matang dan proyek tersebut tidak akan dilaksanakan. Dan Anda harus mempersiapkan pemangku kepentingan bisnis Anda untuk kemungkinan itu. Tapi itu topik untuk posting lain.
Bagian 1: Gunakan model tanpa-ML untuk menetapkan garis dasar
Ini adalah bagian pertama dari tutorial kami tentang menyiapkan proyek peringkasan teks. Di bagian ini, kami membuat baseline menggunakan model yang sangat sederhana, tanpa benar-benar menggunakan ML. Ini adalah langkah yang sangat penting dalam setiap proyek ML, karena memungkinkan kita untuk memahami seberapa besar nilai tambah ML dari waktu ke waktu proyek dan apakah layak untuk diinvestasikan di dalamnya.
Kode untuk tutorial dapat ditemukan di bawah ini GitHub repo.
Tanggal, tanggal, tanggal
Setiap proyek ML dimulai dengan data! Jika memungkinkan, kita harus selalu menggunakan data yang terkait dengan apa yang ingin kita capai dengan proyek peringkasan teks. Misalnya, jika tujuan kita adalah untuk meringkas aplikasi paten, kita juga harus menggunakan aplikasi paten untuk melatih model. Peringatan besar untuk proyek ML adalah bahwa data pelatihan biasanya perlu diberi label. Dalam konteks peringkasan teks, itu berarti kita perlu menyediakan teks yang akan diringkas serta ringkasan (label). Hanya dengan menyediakan keduanya, model dapat mempelajari seperti apa ringkasan yang baik.
Dalam tutorial ini, kami menggunakan kumpulan data yang tersedia untuk umum, tetapi langkah dan kode tetap sama persis jika kami menggunakan kumpulan data khusus atau pribadi. Dan lagi, jika Anda memiliki tujuan untuk model peringkasan teks Anda dan memiliki data yang sesuai, silakan gunakan data Anda sebagai gantinya untuk mendapatkan hasil maksimal dari ini.
Data yang kami gunakan adalah kumpulan data arXiv, yang berisi abstrak makalah arXiv beserta judulnya. Untuk tujuan kami, kami menggunakan abstrak sebagai teks yang ingin kami rangkum dan judul sebagai ringkasan referensi. Semua langkah mengunduh dan memproses data sebelumnya tersedia di bawah ini buku catatan. Kami membutuhkan Identitas AWS dan Manajemen Akses (IAM) peran yang memungkinkan memuat data ke dan dari Layanan Penyimpanan Sederhana Amazon (Amazon S3) untuk menjalankan notebook ini dengan sukses. Dataset dikembangkan sebagai bagian dari makalah Tentang Penggunaan ArXiv sebagai Dataset dan dilisensikan di bawah Creative Commons CC0 1.0 Dedikasi Domain Publik Universal.
Data dibagi menjadi tiga set data: pelatihan, validasi, dan data uji. Jika Anda ingin menggunakan data Anda sendiri, pastikan juga demikian. Diagram berikut mengilustrasikan bagaimana kami menggunakan kumpulan data yang berbeda.
![]()
Tentu, pertanyaan umum pada saat ini adalah: Berapa banyak data yang kita butuhkan? Seperti yang mungkin sudah Anda tebak, jawabannya adalah: tergantung. Itu tergantung pada seberapa terspesialisasi domainnya (meringkas aplikasi paten sangat berbeda dari meringkas artikel berita), seberapa akurat model yang dibutuhkan agar berguna, berapa biaya pelatihan model, dan seterusnya. Kami kembali ke pertanyaan ini di lain waktu ketika kami benar-benar melatih model, tetapi singkatnya adalah kami harus mencoba ukuran kumpulan data yang berbeda ketika kami berada dalam fase eksperimen proyek.
Apa yang membuat model yang baik?
Di banyak proyek ML, mengukur kinerja model agak mudah. Itu karena biasanya ada sedikit ambiguitas seputar apakah hasil model itu benar. Label dalam dataset seringkali biner (Benar/Salah, Ya/Tidak) atau kategorikal. Bagaimanapun, mudah dalam skenario ini untuk membandingkan keluaran model dengan label dan menandainya sebagai benar atau salah.
Saat menghasilkan teks, ini menjadi lebih menantang. Ringkasan (label) yang kami berikan dalam kumpulan data kami hanyalah satu cara untuk meringkas teks. Tetapi ada banyak kemungkinan untuk meringkas teks yang diberikan. Jadi, bahkan jika modelnya tidak cocok dengan label 1:1 kami, hasilnya mungkin masih berupa ringkasan yang valid dan berguna. Jadi bagaimana kita membandingkan ringkasan model dengan yang kami berikan? Metrik yang paling sering digunakan dalam peringkasan teks untuk mengukur kualitas model adalah Skor ROUGE. Untuk memahami mekanisme metrik ini, lihat Metrik Performa Terbaik di NLP. Singkatnya, skor ROUGE mengukur tumpang tindih dari n-gram (urutan bersebelahan dari n item) antara ringkasan model (ringkasan kandidat) dan ringkasan referensi (label yang kami berikan dalam kumpulan data kami). Tapi, tentu saja, ini bukan ukuran yang sempurna. Untuk memahami batasannya, lihat Untuk ROUGE atau tidak ROUGE?
Jadi, bagaimana cara menghitung skor ROUGE? Ada beberapa paket Python di luar sana untuk menghitung metrik ini. Untuk memastikan konsistensi, kita harus menggunakan metode yang sama di seluruh proyek kita. Karena kita akan, pada poin selanjutnya dalam tutorial ini, menggunakan skrip pelatihan dari perpustakaan Transformers alih-alih menulis milik kita sendiri, kita bisa mengintip ke kode sumber skrip dan salin kode yang menghitung skor ROUGE:
Dengan menggunakan metode ini untuk menghitung skor, kami memastikan bahwa kami selalu membandingkan apel dengan apel di seluruh proyek.
Fungsi ini menghitung beberapa skor ROUGE: rouge1, rouge2, rougeL, dan rougeLsum. "Jumlah" dalam rougeLsum mengacu pada fakta bahwa metrik ini dihitung di seluruh ringkasan, sedangkan rougeL dihitung sebagai rata-rata atas kalimat individu. Jadi, skor ROUGE mana yang harus kita gunakan untuk proyek kita? Sekali lagi, kita harus mencoba pendekatan yang berbeda dalam fase eksperimen. Untuk apa nilainya, kertas ROUGE asli menyatakan bahwa “ROUGE-2 dan ROUGE-L bekerja dengan baik dalam tugas ringkasan dokumen tunggal” sementara “ROUGE-1 dan ROUGE-L bekerja dengan baik dalam mengevaluasi ringkasan singkat.”
Buat garis dasar
Selanjutnya kita ingin membuat baseline dengan menggunakan model sederhana tanpa ML. Apa artinya? Di bidang peringkasan teks, banyak penelitian menggunakan pendekatan yang sangat sederhana: mereka mengambil yang pertama n kalimat teks dan menyatakannya sebagai ringkasan kandidat. Mereka kemudian membandingkan ringkasan kandidat dengan ringkasan referensi dan menghitung skor ROUGE. Ini adalah pendekatan sederhana namun kuat yang dapat kita terapkan dalam beberapa baris kode (seluruh kode untuk bagian ini ada di bawah ini buku catatan):
Kami menggunakan dataset uji untuk evaluasi ini. Ini masuk akal karena setelah kami melatih model, kami juga menggunakan kumpulan data uji yang sama untuk evaluasi akhir. Kami juga mencoba nomor yang berbeda untuk n: kita mulai dengan hanya kalimat pertama sebagai ringkasan kandidat, lalu dua kalimat pertama, dan terakhir tiga kalimat pertama.
Tangkapan layar berikut menunjukkan hasil untuk model pertama kami.
![]()
Skor ROUGE adalah yang tertinggi, dengan hanya kalimat pertama sebagai ringkasan kandidat. Ini berarti bahwa mengambil lebih dari satu kalimat membuat ringkasan terlalu bertele-tele dan mengarah ke skor yang lebih rendah. Jadi itu berarti kami akan menggunakan skor untuk ringkasan satu kalimat sebagai dasar kami.
Penting untuk dicatat bahwa, untuk pendekatan yang begitu sederhana, angka-angka ini sebenarnya cukup bagus, terutama untuk rouge1 skor. Untuk menempatkan angka-angka ini dalam konteks, kita dapat merujuk ke Model Pegasus, yang menunjukkan skor model mutakhir untuk kumpulan data yang berbeda.
Kesimpulan dan apa selanjutnya
Di Bagian 1 dari seri kami, kami memperkenalkan kumpulan data yang kami gunakan di seluruh proyek ringkasan serta metrik untuk mengevaluasi ringkasan. Kami kemudian membuat baseline berikut dengan model sederhana tanpa ML.
![]()
Dalam majalah posting berikutnya, kami menggunakan model zero-shot – khususnya, model yang telah dilatih secara khusus untuk peringkasan teks pada artikel berita publik. Namun, model ini tidak akan dilatih sama sekali pada dataset kami (karenanya dinamakan "zero-shot").
Saya serahkan kepada Anda sebagai pekerjaan rumah untuk menebak bagaimana kinerja model zero-shot ini dibandingkan dengan baseline kami yang sangat sederhana. Di satu sisi, ini akan menjadi model yang jauh lebih canggih (sebenarnya ini adalah jaringan saraf). Di sisi lain, ini hanya digunakan untuk meringkas artikel berita, sehingga mungkin kesulitan dengan pola yang melekat pada dataset arXiv.
tentang Penulis
![]() Heiko Hotzo adalah Senior Solutions Architect untuk AI & Machine Learning dan memimpin komunitas Natural Language Processing (NLP) dalam AWS. Sebelum peran ini, dia adalah Kepala Ilmu Data untuk Layanan Pelanggan UE Amazon. Heiko membantu pelanggan kami sukses dalam perjalanan AI/ML mereka di AWS dan telah bekerja dengan organisasi di banyak industri, termasuk Asuransi, Layanan Keuangan, Media dan Hiburan, Perawatan Kesehatan, Utilitas, dan Manufaktur. Di waktu luangnya, Heiko sering bepergian.
Heiko Hotzo adalah Senior Solutions Architect untuk AI & Machine Learning dan memimpin komunitas Natural Language Processing (NLP) dalam AWS. Sebelum peran ini, dia adalah Kepala Ilmu Data untuk Layanan Pelanggan UE Amazon. Heiko membantu pelanggan kami sukses dalam perjalanan AI/ML mereka di AWS dan telah bekerja dengan organisasi di banyak industri, termasuk Asuransi, Layanan Keuangan, Media dan Hiburan, Perawatan Kesehatan, Utilitas, dan Manufaktur. Di waktu luangnya, Heiko sering bepergian.
- Coinsmart. Pertukaran Bitcoin dan Crypto Terbaik Eropa.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. AKSES GRATIS.
- CryptoHawk. Radar Altcoin. Uji Coba Gratis.
- Sumber: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- Tentang Kami
- ABSTRAK
- mengakses
- tepat
- dicapai
- maju
- kemajuan
- AI
- Semua
- sudah
- Amazon
- Kemenduaan
- jumlah
- Lain
- Lebah
- Aplikasi
- aplikasi
- pendekatan
- sekitar
- Seni
- artikel
- artikel
- para penonton
- tersedia
- rata-rata
- AWS
- Dasar
- Pada dasarnya
- Awal
- makhluk
- bisnis
- panggilan
- yang
- tertangkap
- menantang
- kode
- Pengkodean
- Umum
- masyarakat
- Perusahaan
- dibandingkan
- sama sekali
- menghitung
- konsep
- mengandung
- Konten
- kontrak
- membuat
- adat
- Layanan Pelanggan
- pelanggan
- data
- ilmu data
- lebih dalam
- dikembangkan
- berbeda
- dokumen
- Tidak
- domain
- Menghibur
- terutama
- menetapkan
- EU
- segala sesuatu
- contoh
- mengharapkan
- ahli
- mata
- Menghadapi
- Fields
- Akhirnya
- keuangan
- jasa keuangan
- Pertama
- berikut
- Depan
- ditemukan
- fungsi
- lebih lanjut
- permainan
- menghasilkan
- generasi
- tujuan
- akan
- baik
- besar
- wali
- membimbing
- memiliki
- kepala
- kesehatan
- bermanfaat
- membantu
- di sini
- menyewa
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTTPS
- besar
- identitas
- melaksanakan
- diimplementasikan
- penting
- memasukkan
- Termasuk
- sendiri-sendiri
- industri
- asuransi
- memperkenalkan
- investasi
- IT
- Pekerjaan
- Juli
- kunci
- pengetahuan
- Label
- bahasa
- Terbaru
- Memimpin
- BELAJAR
- pengetahuan
- Meninggalkan
- Informasi
- Perpustakaan
- Izin
- link
- sedikit
- mesin
- Mesin belajar
- MEMBUAT
- Membuat
- pabrik
- tanda
- Cocok
- mengukur
- Media
- keberatan
- ML
- model
- model
- lebih
- paling
- Alam
- jaringan
- berita
- buku catatan
- nomor
- Buka
- urutan
- organisasi
- Lainnya
- kertas
- paten
- Konsultan Ahli
- prestasi
- perspektif
- tahap
- Titik
- kemungkinan
- kemungkinan
- mungkin
- Posts
- potensi
- kuat
- swasta
- Produksi
- proyek
- memprojeksikan
- mengusulkan
- memberikan
- menyediakan
- publik
- tujuan
- kualitas
- pertanyaan
- jarak
- RE
- Bacaan
- laporan
- membutuhkan
- wajib
- penelitian
- Hasil
- Run
- Tersebut
- Ilmu
- rasa
- Seri
- layanan
- Layanan
- set
- pengaturan
- Pendek
- Sederhana
- So
- Solusi
- Seseorang
- sesuatu
- mutakhir
- Space
- spasi
- khusus
- spesialisasi
- Secara khusus
- membagi
- awal
- mulai
- dimulai
- state-of-the-art
- Negara
- penyimpanan
- tekanan
- studi
- sukses
- berhasil
- Berbicara
- target
- tugas
- Teknis
- Teknologi
- uji
- ribuan
- Melalui
- di seluruh
- waktu
- Judul
- Pelatihan
- jelas
- mengobati
- terakhir
- memahami
- Universal
- us
- menggunakan
- biasanya
- nilai
- menunggu
- Apa
- apakah
- SIAPA
- Wikipedia
- dalam
- tanpa
- Kerja
- bekerja
- bernilai
- penulisan
- X
- nol