Gunung Es Apache adalah format tabel terbuka untuk kumpulan data analitik yang sangat besar, yang menangkap informasi metadata tentang status kumpulan data saat berkembang dan berubah seiring waktu. Itu menambahkan tabel untuk menghitung mesin termasuk Spark, Trino, PrestoDB, Flink, dan Hive menggunakan format tabel kinerja tinggi yang berfungsi seperti tabel SQL. Iceberg telah menjadi sangat populer karena dukungannya untuk transaksi ACID di data lake dan fitur seperti evolusi skema dan partisi, perjalanan waktu, dan rollback.
Integrasi Apache Iceberg didukung oleh layanan analitik AWS termasuk Amazon ESDM, Amazon Athena, dan Lem AWS. Amazon EMR dapat menyediakan klaster dengan Spark, Hive, Trino, dan Flink yang dapat menjalankan Iceberg. Dimulai dengan Amazon EMR versi 6.5.0, Anda bisa gunakan Iceberg dengan cluster EMR Anda tanpa memerlukan tindakan bootstrap. Di awal tahun 2022, AWS mengumumkan ketersediaan umum transaksi ACID Athena, yang didukung oleh Apache Iceberg. Yang baru saja dirilis Mesin kueri Athena versi 3 memberikan integrasi yang lebih baik dengan format tabel Iceberg. AWS Glue 3.0 dan yang lebih baru mendukung kerangka kerja Apache Iceberg untuk data lake.
Dalam postingan ini, kami membahas apa yang diinginkan pelanggan di data lake modern dan bagaimana Apache Iceberg membantu memenuhi kebutuhan pelanggan. Kemudian kami menelusuri solusi untuk membangun data lake gunung es yang berkinerja tinggi dan terus berkembang Layanan Penyimpanan Sederhana Amazon (Amazon S3) dan memproses data inkremental dengan menjalankan pernyataan insert, update, dan delete SQL. Terakhir, kami menunjukkan kepada Anda cara menyetel kinerja proses untuk meningkatkan kinerja baca dan tulis.
Bagaimana Apache Iceberg menangani apa yang diinginkan pelanggan di data lake modern
Semakin banyak pelanggan membangun data lake, dengan data terstruktur dan tidak terstruktur, untuk mendukung banyak pengguna, aplikasi, dan alat analitik. Ada kebutuhan yang meningkat untuk danau data untuk mendukung basis data seperti fitur seperti transaksi ACID, pembaruan dan penghapusan tingkat catatan, perjalanan waktu, dan rollback. Apache Iceberg dirancang untuk mendukung fitur ini pada data lake berskala petabyte hemat biaya di Amazon S3.
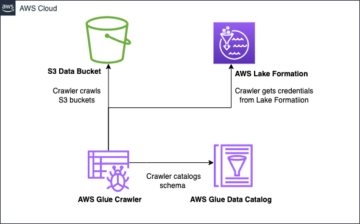
Apache Iceberg memenuhi kebutuhan pelanggan dengan menangkap informasi metadata yang kaya tentang kumpulan data pada saat file data individual dibuat. Ada tiga lapisan dalam arsitektur tabel gunung es: Katalog gunung es, lapisan metadata, dan lapisan data, seperti yang digambarkan pada gambar berikut (sumber).

Katalog Iceberg menyimpan penunjuk metadata ke file metadata tabel saat ini. Saat kueri pemilihan membaca tabel Gunung Es, mesin kueri terlebih dahulu masuk ke Katalog Gunung Es, lalu mengambil lokasi file metadata saat ini. Setiap kali ada pembaruan pada tabel Gunung Es, snapshot baru dari tabel dibuat, dan penunjuk metadata menunjuk ke file metadata tabel saat ini.
Berikut adalah contoh katalog Iceberg dengan implementasi AWS Glue. Anda dapat melihat nama database, lokasi (jalur S3) tabel Gunung Es, dan lokasi metadata.

Lapisan metadata memiliki tiga jenis file: file metadata, daftar manifes, dan file manifes dalam hierarki. Di bagian atas hierarki adalah file metadata, yang menyimpan informasi tentang skema tabel, informasi partisi, dan snapshot. Snapshot menunjuk ke daftar manifes. Daftar manifes memiliki informasi tentang setiap file manifes yang membentuk snapshot, seperti lokasi file manifes, partisi miliknya, dan batas bawah dan atas kolom partisi untuk file data yang dilacaknya. File manifes melacak file data serta detail tambahan tentang setiap file, seperti format file. Ketiga file tersebut bekerja dalam hierarki untuk melacak snapshot, skema, partisi, properti, dan file data dalam tabel Gunung Es.
Lapisan data memiliki file data individual dari tabel gunung es. Iceberg mendukung berbagai format file termasuk Parquet, ORC, dan Avro. Karena tabel Iceberg melacak file data individu bukan hanya menunjuk ke lokasi partisi dengan file data, itu mengisolasi operasi penulisan dari operasi membaca. Anda dapat menulis file data kapan saja, tetapi hanya melakukan perubahan secara eksplisit, yang membuat versi baru dari file snapshot dan metadata.
Ikhtisar solusi
Dalam postingan ini, kami memandu Anda melalui solusi untuk membangun data lake Apache Iceberg berperforma tinggi di Amazon S3; memproses data inkremental dengan menyisipkan, memperbarui, dan menghapus pernyataan SQL; dan sesuaikan tabel Gunung Es untuk meningkatkan kinerja baca dan tulis. Diagram berikut mengilustrasikan arsitektur solusi.

Untuk mendemonstrasikan solusi ini, kami menggunakan Ulasan Pelanggan Amazon kumpulan data dalam bucket S3 (s3://amazon-reviews-pds/parquet/). Dalam kasus penggunaan nyata, itu akan menjadi data mentah yang disimpan di ember S3 Anda. Kita dapat memeriksa ukuran data dengan kode berikut di Antarmuka Baris Perintah AWS (AWS CLI):
Jumlah total objek adalah 430, dan ukuran total adalah 47.4 GiB.
Untuk menyiapkan dan menguji solusi ini, kami menyelesaikan langkah tingkat tinggi berikut:
- Siapkan bucket S3 di zona pilihan untuk menyimpan data yang dikonversi dalam format tabel Gunung Es.
- Luncurkan kluster EMR dengan konfigurasi yang sesuai untuk Apache Iceberg.
- Buat buku catatan di EMR Studio.
- Konfigurasikan sesi Spark untuk Apache Iceberg.
- Mengonversi data ke format tabel Gunung Es dan memindahkan data ke zona kurasi.
- Jalankan masukkan, perbarui, dan hapus kueri di Athena untuk memproses data inkremental.
- Lakukan penyetelan kinerja.
Prasyarat
Untuk mengikuti panduan ini, Anda harus memiliki Akun AWS dengan Identitas AWS dan Manajemen Akses (IAM) yang memiliki akses yang memadai untuk menyediakan sumber daya yang dibutuhkan.
Siapkan bucket S3 untuk data Gunung Es di zona pilihan di data lake Anda
Pilih Wilayah tempat Anda ingin membuat bucket S3 dan berikan nama yang unik:
Luncurkan kluster EMR untuk menjalankan pekerjaan Iceberg menggunakan Spark
Anda dapat membuat kluster EMR dari Konsol Manajemen AWS, Amazon EMR CLI, atau Kit Pengembangan AWS Cloud (AWS-CDK). Untuk posting ini, kami memandu Anda tentang cara membuat kluster EMR dari konsol.
- Di konsol Amazon EMR, pilih Buat klaster.
- Pilih Advanced options.
- Untuk Konfigurasi Perangkat Lunak, pilih rilis Amazon EMR terbaru. Pada Januari 2023, rilis terbaru adalah 6.9.0. Iceberg membutuhkan rilis 6.5.0 dan yang lebih baru.
- Pilih JupyterEnterpriseGateway dan percikan sebagai perangkat lunak untuk menginstal.
- Untuk Edit pengaturan perangkat lunak, pilih Masukkan konfigurasi dan masuk
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Biarkan pengaturan lain di default dan pilih Selanjutnya.

- Untuk Perangkat keras, gunakan pengaturan default.
- Pilih Selanjutnya.
- Untuk Nama klaster, masukkan nama. Kita gunakan
iceberg-blog-cluster. - Biarkan pengaturan yang tersisa tidak berubah dan pilih Selanjutnya.
- Pilih Buat klaster.
Buat buku catatan di EMR Studio
Kami sekarang memandu Anda tentang cara membuat buku catatan di EMR Studio dari konsol.
- Di konsol IAM, buat peran layanan EMR Studio.
- Di konsol Amazon EMR, pilih Studio ESDM.
- Pilih Get started.
Grafik Get started halaman muncul di tab baru.
- Pilih Buat Studio di tab baru.
- Masukkan nama. Kami menggunakan gunung es-studio.
- Pilih VPC dan subnet yang sama seperti untuk klaster EMR, dan grup keamanan default.
- Pilih Identitas dan Manajemen Akses AWS (IAM) untuk autentikasi, dan pilih peran layanan EMR Studio yang baru saja Anda buat.
- Pilih jalur S3 untuk Pencadangan ruang kerja.
- Pilih Buat Studio.
- Setelah Studio dibuat, pilih URL akses Studio.
- Di dasbor EMR Studio, pilih Buat ruang kerja.
- Masukkan nama untuk Ruang Kerja Anda. Kita gunakan
iceberg-workspace. - Lihat lebih lanjut Konfigurasi lanjutan Dan pilihlah Lampirkan Ruang Kerja ke kluster EMR.
- Pilih cluster EMR yang Anda buat sebelumnya.
- Pilih Buat Ruang Kerja.
- Pilih nama Workspace untuk membuka tab baru.
Di panel navigasi, ada buku catatan yang memiliki nama yang sama dengan Workspace. Dalam kasus kami, ini adalah ruang kerja gunung es.
- Buka buku catatan.
- Saat diminta untuk memilih kernel, pilih percikan.
Konfigurasikan sesi Spark untuk Apache Iceberg
Gunakan kode berikut, berikan nama bucket S3 Anda sendiri:
Ini menetapkan konfigurasi sesi Spark berikut:
- spark.sql.katalog.demo – Mendaftarkan katalog Spark bernama demo, yang menggunakan plugin katalog Iceberg Spark.
- spark.sql.catalog.demo.catalog-impl – Katalog demo Spark menggunakan AWS Glue sebagai katalog fisik untuk menyimpan database Iceberg dan informasi tabel.
- spark.sql.catalog.demo.warehouse – Katalog demo Spark menyimpan semua metadata Iceberg dan file data di bawah jalur root yang ditentukan oleh properti ini:
s3://iceberg-curated-blog-data. - spark.sql.ekstensi – Menambahkan dukungan untuk ekstensi Iceberg Spark SQL, yang memungkinkan Anda untuk menjalankan prosedur Iceberg Spark dan beberapa perintah SQL khusus Iceberg (Anda menggunakan ini di langkah selanjutnya).
- spark.sql.catalog.demo.io-impl – Iceberg memungkinkan pengguna untuk menulis data ke Amazon S3 melalui S3FileIO. Katalog Data AWS Glue secara default menggunakan FileIO ini, dan katalog lain dapat memuat FileIO ini menggunakan properti katalog io-impl.
Mengonversi data ke format tabel Gunung Es
Anda dapat menggunakan Spark di Amazon EMR atau Athena untuk memuat tabel Gunung Es. Di sesi Spark notebook EMR Studio Workspace, jalankan perintah berikut untuk memuat data:
Setelah Anda menjalankan kode, Anda akan menemukan dua awalan yang dibuat di jalur S3 gudang data Anda (s3://iceberg-curated-blog-data/reviews.db/all_reviews): data dan metadata.
Memproses data inkremental menggunakan pernyataan insert, update, dan delete SQL di Athena
Athena adalah mesin kueri tanpa server yang dapat Anda gunakan untuk melakukan tugas baca, tulis, perbarui, dan pengoptimalan terhadap tabel Gunung Es. Untuk mendemonstrasikan bagaimana format data lake Apache Iceberg mendukung penyerapan data inkremental, kami menjalankan pernyataan insert, update, dan delete SQL pada data lake.
Arahkan ke konsol Athena dan pilih Editor-kueri. Jika ini pertama kalinya Anda menggunakan editor kueri Athena, Anda harus melakukannya konfigurasikan lokasi hasil kueri menjadi bucket S3 yang Anda buat sebelumnya. Anda seharusnya dapat melihat bahwa tabel reviews.all_reviews tersedia untuk kueri. Jalankan kueri berikut untuk memverifikasi bahwa Anda telah berhasil memuat tabel gunung es:
Memproses data inkremental dengan menjalankan pernyataan insert, update, dan delete SQL:
Penyesuaian kinerja
Di bagian ini, kami membahas berbagai cara untuk meningkatkan kinerja baca dan tulis Apache Iceberg.
Konfigurasikan properti tabel Apache Iceberg
Apache Iceberg adalah format tabel, dan mendukung properti tabel untuk mengonfigurasi perilaku tabel seperti membaca, menulis, dan katalog. Anda dapat meningkatkan kinerja baca dan tulis pada tabel Gunung Es dengan menyesuaikan properti tabel.
Misalnya, jika Anda menyadari bahwa Anda menulis terlalu banyak file kecil untuk tabel Gunung Es, Anda dapat mengonfigurasi ukuran file tulis untuk menulis lebih sedikit tetapi file berukuran lebih besar, untuk membantu meningkatkan kinerja kueri.
| Milik | Default | Deskripsi Produk |
| tulis.target-berkas-ukuran-byte | 536870912 (512 MB) | Mengontrol ukuran file yang dibuat untuk menargetkan sekitar byte sebanyak ini |
Gunakan kode berikut untuk mengubah format tabel:
Mempartisi dan menyortir
Agar kueri berjalan cepat, semakin sedikit data yang dibaca, semakin baik. Iceberg memanfaatkan kekayaan metadata yang ditangkapnya pada waktu penulisan dan memfasilitasi teknik seperti perencanaan pemindaian, partisi, pemangkasan, dan statistik tingkat kolom seperti nilai min/maks untuk melewati file data yang tidak memiliki catatan kecocokan. Kami memandu Anda melalui cara kerja perencanaan pemindaian kueri dan partisi di Iceberg dan bagaimana kami menggunakannya untuk meningkatkan kinerja kueri.
Perencanaan pemindaian kueri
Untuk kueri tertentu, langkah pertama dalam mesin kueri adalah perencanaan pemindaian, yaitu proses menemukan file dalam tabel yang diperlukan untuk kueri. Merencanakan dalam tabel Gunung Es sangat efisien, karena metadata kaya Gunung Es dapat digunakan untuk memangkas file metadata yang tidak diperlukan, selain memfilter file data yang tidak berisi data yang cocok. Dalam pengujian kami, kami mengamati Athena memindai 50% atau kurang data untuk kueri tertentu pada tabel Gunung Es dibandingkan dengan data asli sebelum dikonversi ke format Gunung Es.
Ada dua jenis penyaringan:
- Pemfilteran metadata – Iceberg menggunakan dua tingkat metadata untuk melacak file dalam snapshot: daftar manifes dan file manifes. Ini pertama kali menggunakan daftar manifes, yang bertindak sebagai indeks file manifes. Selama perencanaan, Iceberg memfilter manifes menggunakan rentang nilai partisi dalam daftar manifes tanpa membaca semua file manifes. Kemudian menggunakan file manifes yang dipilih untuk mendapatkan file data.
- Penyaringan data – Setelah memilih daftar file manifes, Iceberg menggunakan data partisi dan statistik tingkat kolom untuk setiap file data yang disimpan dalam file manifes untuk memfilter file data. Selama perencanaan, predikat kueri diubah menjadi predikat pada data partisi dan diterapkan terlebih dahulu untuk memfilter file data. Kemudian, statistik kolom seperti jumlah nilai tingkat kolom, jumlah nol, batas bawah, dan batas atas digunakan untuk memfilter file data yang tidak cocok dengan predikat kueri. Dengan menggunakan batas atas dan bawah untuk memfilter file data pada waktu perencanaan, Iceberg sangat meningkatkan kinerja kueri.
Mempartisi dan menyortir
Mempartisi adalah cara untuk mengelompokkan rekaman dengan nilai kolom kunci yang sama secara tertulis. Manfaat partisi adalah kueri yang lebih cepat yang hanya mengakses sebagian data, seperti yang dijelaskan sebelumnya dalam perencanaan pemindaian kueri: pemfilteran data. Iceberg membuat partisi menjadi sederhana dengan mendukung partisi tersembunyi, dengan cara Iceberg menghasilkan nilai partisi dengan mengambil nilai kolom dan mengubahnya secara opsional.
Dalam kasus penggunaan kami, pertama-tama kami menjalankan kueri berikut pada tabel Gunung Es yang tidak dipartisi. Kemudian kami mempartisi tabel Gunung Es berdasarkan kategori ulasan, yang akan digunakan dalam kondisi kueri WHERE untuk memfilter rekaman. Dengan mempartisi, kueri dapat memindai lebih sedikit data. Lihat kode berikut:
Jalankan pernyataan pilih berikut pada tabel all_reviews yang tidak dipartisi vs. tabel yang dipartisi untuk melihat perbedaan kinerja:
Tabel berikut menunjukkan peningkatan kinerja partisi data, dengan peningkatan kinerja sekitar 50% dan data yang dipindai 70% lebih sedikit.
| Nama Set Data | Kumpulan Data Tidak Berpartisi | Kumpulan Data yang Dipartisi |
| Waktu proses (detik) | 8.20 | 4.25 |
| Data Dipindai (MB) | 131.55 | 33.79 |
Perhatikan bahwa waktu proses adalah waktu proses rata-rata dengan beberapa proses dalam pengujian kami.
Kami melihat peningkatan kinerja yang baik setelah mempartisi. Namun, ini dapat ditingkatkan lebih lanjut dengan menggunakan statistik tingkat kolom dari file manifes Iceberg. Untuk menggunakan statistik tingkat kolom secara efektif, Anda ingin lebih lanjut mengurutkan rekaman Anda berdasarkan pola kueri. Menyortir seluruh kumpulan data menggunakan kolom yang sering digunakan dalam kueri akan menyusun ulang data sedemikian rupa sehingga setiap file data berakhir dengan rentang nilai unik untuk kolom tertentu. Jika kolom ini digunakan dalam kondisi kueri, ini memungkinkan mesin kueri untuk melewati file data lebih lanjut, sehingga memungkinkan kueri yang lebih cepat.
Salin-saat-tulis vs. baca-saat-gabung
Saat mengimplementasikan update dan delete pada tabel Iceberg di data lake, ada dua pendekatan yang ditentukan oleh properti tabel Iceberg:
- Salin-saat-tulis – Dengan pendekatan ini, ketika ada perubahan pada tabel Gunung Es, baik pembaruan atau penghapusan, file data yang terkait dengan rekaman yang terpengaruh akan digandakan dan diperbarui. Catatan akan diperbarui atau dihapus dari file data duplikat. Snapshot baru dari tabel Gunung Es akan dibuat dan mengarah ke versi file data yang lebih baru. Hal ini membuat keseluruhan menulis lebih lambat. Mungkin ada situasi di mana penulisan bersamaan diperlukan dengan konflik sehingga percobaan ulang harus terjadi, yang semakin menambah waktu penulisan. Di sisi lain, saat membaca data, tidak diperlukan proses tambahan. Kueri akan mengambil data dari file data versi terbaru.
- Gabung-saat-baca – Dengan pendekatan ini, ketika ada pembaruan atau penghapusan pada tabel Gunung Es, file data yang ada tidak akan ditulis ulang; sebagai gantinya file hapus baru akan dibuat untuk melacak perubahan. Untuk penghapusan, file hapus baru akan dibuat dengan rekaman yang dihapus. Saat membaca tabel Gunung Es, file hapus akan diterapkan ke data yang diambil untuk memfilter catatan hapus. Untuk pembaruan, file hapus baru akan dibuat untuk menandai catatan yang diperbarui sebagai dihapus. Kemudian file baru akan dibuat untuk rekaman tersebut tetapi dengan nilai yang diperbarui. Saat membaca tabel Gunung Es, file hapus dan file baru akan diterapkan ke data yang diambil untuk mencerminkan perubahan terbaru dan memberikan hasil yang benar. Jadi, untuk kueri berikutnya, langkah ekstra untuk menggabungkan file data dengan penghapusan dan file baru akan terjadi, yang biasanya akan menambah waktu kueri. Di sisi lain, penulisan mungkin lebih cepat karena tidak perlu menulis ulang file data yang ada.
Untuk menguji dampak dari kedua pendekatan tersebut, Anda dapat menjalankan kode berikut untuk menyetel properti tabel Gunung Es:
Jalankan pembaruan, hapus, dan pilih pernyataan SQL di Athena untuk menunjukkan perbedaan runtime untuk copy-on-write vs. merge-on-read:
Tabel berikut meringkas runtime kueri.
| Pertanyaan | Salin-on-Tulis | Gabung-saat-Baca | ||||
| UPDATE | DELETE | MEMILIH | UPDATE | DELETE | MEMILIH | |
| Waktu proses (detik) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Data dipindai (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Perhatikan bahwa waktu proses adalah waktu proses rata-rata dengan beberapa proses dalam pengujian kami.
Seperti yang ditunjukkan oleh hasil pengujian kami, selalu ada kompromi dalam kedua pendekatan tersebut. Pendekatan mana yang digunakan bergantung pada kasus penggunaan Anda. Singkatnya, pertimbangan datang ke latensi pada baca vs. tulis. Anda dapat merujuk tabel berikut dan membuat pilihan yang tepat.
| . | Salin-on-Tulis | Gabung-saat-Baca |
| Pro | Bacaan lebih cepat | Menulis lebih cepat |
| Kekurangan | Tulisan mahal | Latensi yang lebih tinggi saat membaca |
| Kapan harus digunakan | Baik untuk sering membaca, pembaruan dan penghapusan yang jarang, atau pembaruan batch besar | Baik untuk tabel dengan pembaruan dan penghapusan yang sering |
Pemadatan data
Jika ukuran file data Anda kecil, Anda mungkin akan mendapatkan ribuan atau jutaan file dalam tabel Gunung Es. Ini secara dramatis meningkatkan operasi I/O dan memperlambat kueri. Selanjutnya, Iceberg melacak setiap file data dalam kumpulan data. Lebih banyak file data menghasilkan lebih banyak metadata. Hal ini pada gilirannya meningkatkan operasi overhead dan I/O dalam membaca file metadata. Untuk meningkatkan kinerja kueri, disarankan untuk memadatkan file data kecil menjadi file data yang lebih besar.
Saat memperbarui dan menghapus rekaman di tabel Gunung Es, jika pendekatan baca-gabung digunakan, Anda mungkin berakhir dengan banyak penghapusan kecil atau file data baru. Menjalankan pemadatan akan menggabungkan semua file ini dan membuat versi file data yang lebih baru. Ini menghilangkan kebutuhan untuk merekonsiliasi mereka selama membaca. Direkomendasikan untuk memiliki pekerjaan pemadatan reguler untuk memengaruhi pembacaan sesedikit mungkin sambil tetap mempertahankan kecepatan tulis yang lebih cepat.
Jalankan perintah pemadatan data berikut, lalu jalankan kueri pemilihan dari Athena:
Tabel berikut membandingkan runtime sebelum vs setelah pemadatan data. Anda dapat melihat sekitar 40% peningkatan kinerja.
| Pertanyaan | Sebelum Pemadatan Data | Setelah Pemadatan Data |
| Waktu proses (detik) | 97.75 | 32.676 detik |
| Data dipindai (MB) | 137.16 M | 189.19 M |
Perhatikan bahwa kueri pemilihan dijalankan pada all_reviews tabel setelah memperbarui dan menghapus operasi, sebelum dan sesudah pemadatan data. Waktu proses adalah waktu proses rata-rata dengan beberapa proses dalam pengujian kami.
Membersihkan
Setelah Anda mengikuti langkah-langkah solusi untuk melakukan kasus penggunaan, selesaikan langkah-langkah berikut untuk membersihkan sumber daya Anda dan menghindari biaya lebih lanjut:
- Jatuhkan tabel dan database AWS Glue dari Athena atau jalankan kode berikut di notebook Anda:
- Di konsol EMR Studio, pilih ruang kerja di panel navigasi.
- Pilih Ruang Kerja yang Anda buat dan pilih Delete.
- Di konsol EMR, navigasikan ke Studios .
- Pilih Studio yang Anda buat dan pilih Delete.
- Di konsol EMR, pilih Cluster di panel navigasi.
- Pilih cluster dan pilih Mengakhiri.
- Hapus bucket S3 dan sumber daya lainnya yang Anda buat sebagai bagian dari prasyarat untuk postingan ini.
Kesimpulan
Dalam postingan ini, kami memperkenalkan framework Apache Iceberg dan bagaimana framework ini membantu menyelesaikan beberapa tantangan yang kami hadapi di data lake modern. Kemudian kami memandu Anda menemukan solusi untuk memproses data inkremental di data lake menggunakan Apache Iceberg. Terakhir, kami mendalami penyetelan kinerja untuk meningkatkan kinerja baca dan tulis untuk kasus penggunaan kami.
Kami harap postingan ini memberikan beberapa informasi berguna bagi Anda untuk memutuskan apakah Anda ingin mengadopsi Apache Iceberg dalam solusi data lake Anda.
Tentang Penulis
 Flora Wu adalah Sr. Resident Architect di AWS Data Lab. Dia membantu pelanggan perusahaan membuat strategi analitik data dan membangun solusi untuk mempercepat hasil bisnis mereka. Di waktu luangnya, dia menikmati bermain tenis, menari salsa, dan bepergian.
Flora Wu adalah Sr. Resident Architect di AWS Data Lab. Dia membantu pelanggan perusahaan membuat strategi analitik data dan membangun solusi untuk mempercepat hasil bisnis mereka. Di waktu luangnya, dia menikmati bermain tenis, menari salsa, dan bepergian.
 Daniel Li adalah Arsitek Solusi Senior di Amazon Web Services. Dia berfokus untuk membantu pelanggan mengembangkan, mengadopsi, dan mengimplementasikan layanan dan strategi cloud. Saat tidak bekerja, dia suka menghabiskan waktu di luar rumah bersama keluarganya.
Daniel Li adalah Arsitek Solusi Senior di Amazon Web Services. Dia berfokus untuk membantu pelanggan mengembangkan, mengadopsi, dan mengimplementasikan layanan dan strategi cloud. Saat tidak bekerja, dia suka menghabiskan waktu di luar rumah bersama keluarganya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Sanggup
- Tentang Kami
- atas
- mempercepat
- mengakses
- manajemen akses
- Tindakan
- tindakan
- tambahan
- Tambahan
- alamat
- alamat
- Menambahkan
- mengambil
- Keuntungan
- Setelah
- terhadap
- Semua
- memungkinkan
- selalu
- Amazon
- Amazon ESDM
- Amazon Web Services
- Analitik
- analisis
- dan
- mengumumkan
- Apache
- aplikasi
- terapan
- pendekatan
- pendekatan
- sesuai
- arsitektur
- terkait
- Otentikasi
- tersedianya
- tersedia
- rata-rata
- menghindari
- AWS
- Lem AWS
- berdasarkan
- karena
- menjadi
- sebelum
- manfaat
- Lebih baik
- antara
- lebih besar
- Bootstrap
- membangun
- Bangunan
- bisnis
- menangkap
- Menangkap
- kasus
- kasus
- katalog
- katalog
- Kategori
- tantangan
- perubahan
- Perubahan
- memeriksa
- pilihan
- Pilih
- klasifikasi
- awan
- layanan cloud
- Kelompok
- kode
- Kolom
- Kolom
- menggabungkan
- bagaimana
- melakukan
- dibandingkan
- lengkap
- menghitung
- bersamaan
- kondisi
- konfigurasi
- pertimbangan
- konsul
- Konversi
- dikonversi
- hemat biaya
- Biaya
- bisa
- membuat
- dibuat
- menciptakan
- dikuratori
- terbaru
- pelanggan
- pelanggan
- Tarian
- dasbor
- data
- Data Analytics
- Danau Data
- pengolahan data
- data warehouse
- Basis Data
- kumpulan data
- mendalam
- menyelam dalam
- Default
- didefinisikan
- Demo
- mendemonstrasikan
- tergantung
- dirancang
- rincian
- mengembangkan
- Pengembangan
- perbedaan
- berbeda
- membahas
- Dont
- turun
- secara dramatis
- Menjatuhkan
- selama
- setiap
- Terdahulu
- Awal
- editor
- efektif
- efisien
- antara
- menghilangkan
- diaktifkan
- memungkinkan
- berakhir
- Mesin
- Mesin
- Enter
- Enterprise
- pelanggan perusahaan
- Eter (ETH)
- Bahkan
- evolusi
- berkembang
- berkembang
- contoh
- ada
- ada
- menjelaskan
- ekstensi
- tambahan
- memfasilitasi
- keluarga
- FAST
- lebih cepat
- Fitur
- Angka
- File
- File
- menyaring
- penyaringan
- filter
- Akhirnya
- Menemukan
- Pertama
- pertama kali
- berfokus
- mengikuti
- berikut
- format
- Kerangka
- sering
- dari
- lebih lanjut
- Selanjutnya
- Umum
- dihasilkan
- mendapatkan
- diberikan
- Pergi
- baik
- sangat
- Kelompok
- tangan
- terjadi
- membantu
- membantu
- membantu
- Tersembunyi
- hirarki
- tingkat tinggi
- kinerja tinggi
- berkinerja tinggi
- Sarang lebah
- berharap
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- HTTPS
- IAM
- identitas
- identitas dan manajemen akses
- Dampak
- dampak
- melaksanakan
- implementasi
- mengimplementasikan
- memperbaiki
- ditingkatkan
- perbaikan
- meningkatkan
- in
- Termasuk
- Meningkatkan
- Pada meningkat
- Meningkatkan
- indeks
- sendiri-sendiri
- informasi
- install
- sebagai gantinya
- integrasi
- diperkenalkan
- Isolat
- IT
- Januari
- Jobs
- kunci
- laboratorium
- danau
- besar
- lebih besar
- Latensi
- Terbaru
- rilis terbaru
- lapisan
- lapisan
- memimpin
- adalah ide yang bagus
- MEMBATASI
- baris
- Daftar
- sedikit
- memuat
- tempat
- membuat
- MEMBUAT
- pengelolaan
- banyak
- tanda
- pasar
- Cocok
- sesuai
- Bergabung
- Metadata
- mungkin
- jutaan
- modern
- lebih
- pindah
- beberapa
- nama
- Bernama
- Arahkan
- Navigasi
- Perlu
- dibutuhkan
- kebutuhan
- New
- buku catatan
- obyek
- Buka
- operasi
- Operasi
- optimasi
- Optimize
- urutan
- asli
- Lainnya
- di luar rumah
- secara keseluruhan
- sendiri
- pane
- bagian
- path
- pola
- melakukan
- prestasi
- fisik
- perencanaan
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- Plugin
- poin
- Populer
- mungkin
- Pos
- didukung
- prasyarat
- Prosedur
- proses
- pengolahan
- menghasilkan
- properties
- milik
- memberikan
- menyediakan
- menyediakan
- ketentuan
- jarak
- Mentah
- data mentah
- Baca
- Bacaan
- nyata
- baru-baru ini
- direkomendasikan
- arsip
- mencerminkan
- wilayah
- register
- reguler
- melepaskan
- dirilis
- yang tersisa
- wajib
- membutuhkan
- Sumber
- mengakibatkan
- Hasil
- Review
- Kaya
- Peran
- akar
- Run
- berjalan
- sama
- pemindaian
- detik
- Bagian
- keamanan
- terpilih
- memilih
- Tanpa Server
- layanan
- Layanan
- Sidang
- set
- set
- pengaturan
- pengaturan
- harus
- Menunjukkan
- Pertunjukkan
- Sederhana
- situasi
- Ukuran
- melambat
- kecil
- Potret
- So
- Perangkat lunak
- larutan
- Solusi
- beberapa
- percikan
- tertentu
- kecepatan
- Pengeluaran
- SQL
- Mulai
- Negara
- Pernyataan
- Laporan
- statistik
- Langkah
- Tangga
- Masih
- penyimpanan
- menyimpan
- tersimpan
- toko
- strategi
- Penyelarasan
- tersusun
- data terstruktur dan tidak terstruktur
- studio
- subnet
- selanjutnya
- berhasil
- seperti itu
- cukup
- RINGKASAN
- mendukung
- Didukung
- pendukung
- Mendukung
- tabel
- Dibutuhkan
- pengambilan
- target
- tugas
- teknik
- tenis
- uji
- pengujian
- tes
- Grafik
- informasi
- Negara
- mereka
- dengan demikian
- ribuan
- tiga
- Melalui
- waktu
- perjalanan waktu
- untuk
- bersama
- terlalu
- alat
- puncak
- Total
- jalur
- Transaksi
- mengubah
- perjalanan
- Perjalanan
- MENGHIDUPKAN
- jenis
- bawah
- unik
- Memperbarui
- diperbarui
- Pembaruan
- memperbarui
- URL
- menggunakan
- gunakan case
- Pengguna
- biasanya
- VAL
- nilai
- Nilai - Nilai
- memeriksa
- versi
- berjalan
- walkthrough
- Gudang
- jam tangan
- cara
- jaringan
- layanan web
- Apa
- apakah
- yang
- sementara
- lebar
- Rentang luas
- akan
- tanpa
- Kerja
- kerja
- bekerja
- akan
- menulis
- penulisan
- Anda
- zephyrnet.dll