Bruce Warrington melalui Unsplash
Alasan mengapa model pembelajaran mesin secara umum menjadi lebih pintar adalah karena ketergantungan mereka pada penggunaan data berlabel untuk membantu mereka membedakan antara dua objek serupa.
Namun, tanpa kumpulan data berlabel ini, Anda akan menemui kendala besar saat membuat model pembelajaran mesin yang paling efektif dan tepercaya. Kumpulan data berlabel selama fase pelatihan model adalah penting.
Pembelajaran mendalam telah banyak digunakan untuk menyelesaikan tugas-tugas seperti Computer vision menggunakan pembelajaran yang diawasi. Namun, seperti banyak hal dalam hidup, ia datang dengan batasan. Klasifikasi yang diawasi membutuhkan kuantitas dan kualitas data pelatihan berlabel yang tinggi untuk menghasilkan model yang kuat. Ini berarti model klasifikasi tidak dapat menangani kelas yang tidak terlihat.
Dan kita semua tahu berapa banyak daya komputasi, pelatihan ulang, waktu, dan uang yang diperlukan untuk melatih model pembelajaran mendalam.
Tapi bisakah model masih bisa membedakan antara dua objek tanpa menggunakan data pelatihan? Ya, itu disebut pembelajaran zero-shot. Pembelajaran zero-shot adalah kemampuan model untuk dapat menyelesaikan tugas tanpa menerima atau menggunakan contoh pelatihan apa pun.
Manusia secara alami mampu belajar tanpa harus berusaha keras. Otak kita sudah menyimpan kamus dan memungkinkan kita untuk membedakan objek dengan melihat sifat fisiknya karena basis pengetahuan kita saat ini. Kita dapat menggunakan basis pengetahuan ini untuk melihat persamaan dan perbedaan antara objek dan menemukan hubungan di antara mereka.
Sebagai contoh, katakanlah kita mencoba membuat model klasifikasi pada spesies hewan. Berdasarkan DuniaKitaInData, ada 2.13 juta spesies yang dihitung pada tahun 2021. Oleh karena itu, jika kita ingin membuat model klasifikasi yang paling efektif untuk spesies hewan, kita membutuhkan 2.13 juta kelas yang berbeda. Juga dibutuhkan akan banyak data. Kuantitas dan kualitas data yang tinggi sulit ditemukan.
Jadi bagaimana pembelajaran zero-shot memecahkan masalah ini?
Karena pembelajaran zero-shot tidak mengharuskan model untuk mempelajari data pelatihan dan cara mengklasifikasikan kelas, ini memungkinkan kita untuk tidak terlalu mengandalkan kebutuhan model akan data berlabel.
Berikut ini adalah apa saja yang perlu diisi oleh data Anda untuk melanjutkan dengan pembelajaran zero-shot.
Terlihat Kelas
Ini terdiri dari kelas data yang sebelumnya telah digunakan untuk melatih model.
Kelas Tak Terlihat
Ini terdiri dari kelas data yang BELUM digunakan untuk melatih model dan model pembelajaran zero-shot baru akan digeneralisasi.
Informasi Tambahan
Karena data dalam kelas tak terlihat tidak diberi label, pembelajaran zero-shot akan memerlukan informasi tambahan untuk mempelajari, dan menemukan korelasi, tautan, dan properti. Ini dapat berupa penyisipan kata, deskripsi, dan informasi semantik.
Metode Pembelajaran Zero-shot
Pembelajaran zero-shot biasanya digunakan di:
- Metode berbasis pengklasifikasi
- Metode berbasis instance
magang
Pembelajaran zero-shot digunakan untuk membangun model untuk kelas yang tidak berlatih menggunakan data berlabel, oleh karena itu diperlukan dua tahap berikut:
1. Latihan
Tahap pelatihan merupakan proses metode pembelajaran yang berusaha menangkap sebanyak mungkin pengetahuan tentang kualitas data. Kita bisa melihat ini sebagai fase pembelajaran.
2. Inferensi
Selama tahap inferensi, semua pengetahuan yang dipelajari dari tahap pelatihan diterapkan dan digunakan untuk mengklasifikasikan contoh ke dalam satu set kelas baru. Kita dapat melihat ini sebagai fase membuat prediksi.
Bagaimana cara kerjanya?
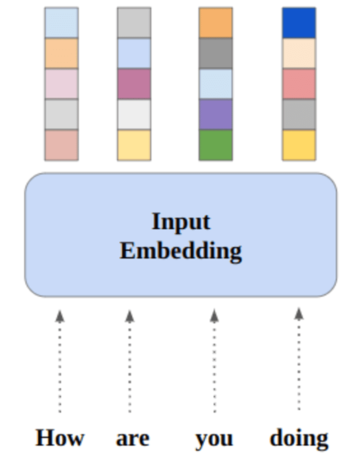
Pengetahuan dari kelas yang terlihat akan ditransfer ke kelas yang tidak terlihat dalam ruang vektor berdimensi tinggi; ini disebut ruang semantik. Misalnya, dalam klasifikasi citra, ruang semantik beserta citra akan mengalami dua langkah:
1. Ruang penyisipan bersama
Di sinilah vektor semantik dan vektor fitur visual diproyeksikan.
2. Kemiripan tertinggi
Di sinilah fitur dicocokkan dengan kelas yang tidak terlihat.
Untuk membantu memahami proses dengan dua tahap (pelatihan dan inferensi), mari kita terapkan dalam penggunaan klasifikasi citra.
Pelatihan

Jari Hytonen melalui Unsplash
Sebagai manusia, jika Anda membaca teks di sebelah kanan pada gambar di atas, Anda akan langsung berasumsi bahwa ada 4 anak kucing dalam keranjang coklat. Tapi katakanlah Anda tidak tahu apa itu 'anak kucing'. Anda akan menganggap ada keranjang coklat dengan 4 benda di dalamnya, yang disebut 'anak kucing'. Setelah Anda menemukan lebih banyak gambar yang berisi sesuatu yang terlihat seperti 'anak kucing', Anda akan dapat membedakan 'anak kucing' dari hewan lain.
Inilah yang terjadi saat Anda menggunakan Prapelatihan Gambar-Bahasa Kontrastif (CLIP) oleh OpenAI untuk pembelajaran zero-shot dalam klasifikasi gambar. Ini dikenal sebagai informasi tambahan.
Anda mungkin berpikir, 'itu hanya data berlabel'. Saya mengerti mengapa Anda berpikir seperti itu, tetapi sebenarnya tidak. Informasi tambahan bukanlah label data, mereka adalah bentuk pengawasan untuk membantu model belajar selama tahap pelatihan.
Ketika model pembelajaran zero-shot melihat pasangan gambar-teks dalam jumlah yang cukup, itu akan dapat membedakan dan memahami frasa dan bagaimana mereka berkorelasi dengan pola tertentu dalam gambar. Dengan menggunakan teknik CLIP 'contrastive learning', model pembelajaran zero-shot telah mampu mengakumulasi basis pengetahuan yang baik untuk dapat membuat prediksi pada tugas-tugas klasifikasi.
Ini adalah ringkasan dari pendekatan CLIP di mana mereka melatih pembuat enkode gambar dan pembuat enkode teks secara bersamaan untuk memprediksi pasangan yang benar dari sekumpulan contoh pelatihan (gambar, teks). Silakan lihat gambar di bawah ini:

Mempelajari Model Visual yang Dapat Dipindahtangankan Dari Pengawasan Bahasa Alami
Kesimpulan
Setelah model melewati tahap pelatihan, ia memiliki basis pengetahuan yang baik tentang pemasangan gambar-teks dan sekarang dapat digunakan untuk membuat prediksi. Namun sebelum kita dapat langsung membuat prediksi, kita perlu menyiapkan tugas klasifikasi dengan membuat daftar semua kemungkinan label yang dapat dihasilkan oleh model.
Misalnya, tetap dengan tugas klasifikasi gambar pada spesies hewan, kita memerlukan daftar semua spesies hewan. Masing-masing label ini akan disandikan, T? ke T? menggunakan encoder teks terlatih yang terjadi pada tahap pelatihan.
Setelah label dikodekan, kami dapat memasukkan gambar melalui pembuat enkode gambar yang telah dilatih sebelumnya. Kami akan menggunakan kesamaan kosinus metrik jarak untuk menghitung kesamaan antara pengkodean gambar dan setiap pengkodean label teks.
Klasifikasi citra dilakukan berdasarkan label yang paling mirip dengan citra. Dan begitulah cara pembelajaran zero-shot dicapai, khususnya dalam klasifikasi gambar.
Kelangkaan Data
Seperti yang disebutkan sebelumnya, data dengan kuantitas dan kualitas tinggi sulit didapatkan. Tidak seperti manusia yang sudah memiliki kemampuan belajar zero-shot, mesin memerlukan input data berlabel untuk dipelajari dan kemudian dapat beradaptasi dengan variasi yang mungkin terjadi secara alami.
Jika kita melihat contoh spesies hewan, jumlahnya sangat banyak. Dan karena jumlah kategori terus bertambah di domain yang berbeda, akan membutuhkan banyak usaha untuk terus mengumpulkan data yang dianotasi.
Karena itu, pembelajaran zero-shot menjadi lebih berharga bagi kami. Semakin banyak peneliti tertarik pada pengenalan atribut otomatis untuk mengkompensasi kurangnya data yang tersedia.
Pelabelan Data
Manfaat lain dari pembelajaran zero-shot adalah properti pelabelan datanya. Pelabelan data dapat menjadi padat karya dan sangat membosankan, dan karenanya, dapat menyebabkan kesalahan selama proses. Pelabelan data membutuhkan ahli, seperti profesional medis yang mengerjakan kumpulan data biomedis, yang sangat mahal dan memakan waktu.
Pembelajaran zero-shot menjadi lebih populer karena keterbatasan data di atas. Ada beberapa makalah yang saya sarankan untuk Anda baca jika Anda tertarik dengan kemampuannya:
Nisa Arya adalah Ilmuwan Data dan Penulis Teknis Freelance. Dia sangat tertarik untuk memberikan saran atau tutorial karir Ilmu Data dan pengetahuan berbasis teori seputar Ilmu Data. Dia juga ingin mengeksplorasi berbagai cara Kecerdasan Buatan dapat bermanfaat bagi umur panjang kehidupan manusia. Seorang pembelajar yang tajam, berusaha untuk memperluas pengetahuan teknologi dan keterampilan menulisnya, sambil membantu membimbing orang lain.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- kemampuan
- kemampuan
- Sanggup
- Tentang Kami
- atas
- Menurut
- Mengumpulkan
- dicapai
- di seluruh
- menyesuaikan
- nasihat
- terhadap
- Semua
- memungkinkan
- sudah
- jumlah
- dan
- hewan
- hewan
- terapan
- Mendaftar
- pendekatan
- sekitar
- buatan
- kecerdasan buatan
- secara otomatis
- tersedia
- mendasarkan
- berdasarkan
- keranjang
- menjadi
- menjadi
- sebelum
- makhluk
- di bawah
- manfaat
- antara
- biomedis
- memperluas
- membangun
- dihitung
- bernama
- Bisa Dapatkan
- tidak bisa
- mampu
- menangkap
- Lowongan Kerja
- kategori
- tertentu
- kelas
- kelas-kelas
- klasifikasi
- Klasifikasi
- Mengumpulkan
- bagaimana
- lengkap
- kekuatan komputasi
- menghitung
- komputer
- Visi Komputer
- terus
- bisa
- membuat
- membuat
- terbaru
- data
- ilmu data
- ilmuwan data
- kumpulan data
- mendalam
- belajar mendalam
- Ketergantungan
- perbedaan
- berbeda
- membedakan
- jarak
- domain
- selama
- setiap
- Efektif
- usaha
- kesalahan
- contoh
- contoh
- mahal
- ahli
- menjelaskan
- menyelidiki
- Fitur
- Fitur
- beberapa
- Menemukan
- berikut
- bentuk
- lepas
- dari
- Umum
- mendapatkan
- baik
- terbesar
- Tumbuh
- membimbing
- menangani
- tangan
- Terjadi
- Sulit
- memiliki
- membantu
- membantu
- High
- paling tinggi
- sangat
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- manusia
- Manusia
- ide
- gambar
- Klasifikasi gambar
- gambar
- penting
- in
- informasi
- memasukkan
- Intelijen
- tertarik
- IT
- Tajam
- Menjaga
- Tahu
- pengetahuan
- dikenal
- label
- pelabelan
- Label
- Kekurangan
- bahasa
- memimpin
- BELAJAR
- belajar
- pengetahuan
- Hidup
- keterbatasan
- LINK
- link
- Daftar
- umur panjang
- melihat
- mencari
- TERLIHAT
- Lot
- mesin
- Mesin belajar
- Mesin
- utama
- membuat
- Membuat
- banyak
- cara
- medis
- tersebut
- metode
- metode
- metrik
- mungkin
- juta
- model
- model
- uang
- lebih
- paling
- Alam
- Perlu
- New
- jumlah
- objek
- hambatan
- terjadi
- ONE
- OpenAI
- urutan
- Lainnya
- Lainnya
- pasangan
- pasangan
- dokumen
- khususnya
- pola
- tahap
- frase
- fisik
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- Populer
- mungkin
- kekuasaan
- meramalkan
- Prediksi
- sebelumnya
- Masalah
- proses
- menghasilkan
- profesional
- diproyeksikan
- properties
- menyediakan
- menempatkan
- kualitas
- kualitas
- kuantitas
- Baca
- alasan
- diterima
- pengakuan
- sarankan
- membutuhkan
- membutuhkan
- peneliti
- pembatasan
- kuat
- Ilmu
- ilmuwan
- pencarian
- melihat
- set
- mirip
- kesamaan
- keterampilan
- cerdas
- So
- MEMECAHKAN
- sesuatu
- Space
- Secara khusus
- Tahap
- magang
- Tangga
- pelekatan
- Masih
- menyimpan
- seperti itu
- cukup
- RINGKASAN
- pengawasan
- Mengambil
- Dibutuhkan
- tugas
- tugas
- tech
- Teknis
- Grafik
- mereka
- karena itu
- hal
- Pikir
- Melalui
- waktu
- membuang-buang waktu
- untuk
- bersama
- Pelatihan VE
- Pelatihan
- ditransfer
- terpercaya
- tutorial
- khas
- memahami
- us
- menggunakan
- dimanfaatkan
- Berharga
- melalui
- View
- penglihatan
- cara
- Apa
- yang
- Sementara
- SIAPA
- sangat
- akan
- tanpa
- Word
- Kerja
- kerja
- akan
- penulis
- penulisan
- Anda
- zephyrnet.dll
- Pembelajaran Zero-Shot