Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.

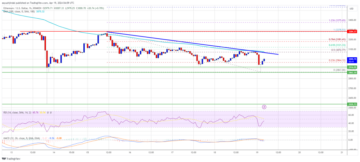
Ethereum Price Faces Crucial Test: Will $2,850 Withstand the Pressure?

KuCoin Postpones KARRAT/USDT Trade Launch; Announces Strong First-Quarter Performance – CryptoInfoNet

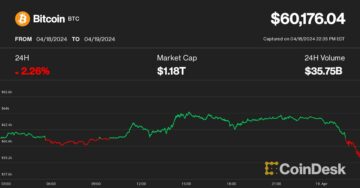
Bitcoin drops below $60,000 following Israel’s missile strike on Iran
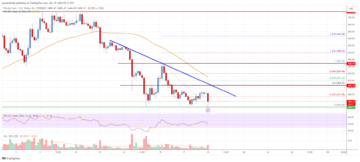
Bitcoin Cash Analysis: Bears Gain Strength Below $550 | Live Bitcoin News
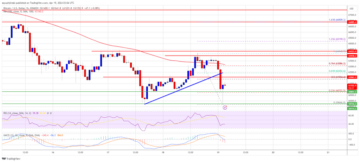
Bitcoin Price Still At Risk of Major Downside Break Below $60K

Bitcoin Price Dives Below $60,000 Less Than 24 Hours Before Halving – Decrypt
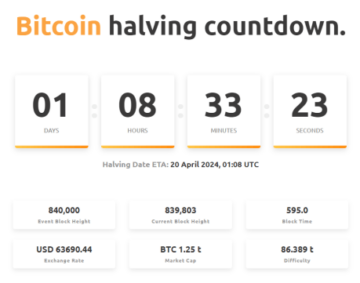
Bitcoin Miners Always Sell Into Halvings, Is This Time Any Different?
Bitcoin Dips Below $60K as Israel Launches Strike on Iran
Bitcoin: Expect The Unexpected – Analyst Sees Unconventional Bull Run Post-Halving

SEC claims Justin Sun’s alleged visits to US grant it personal jurisdiction to pursue legal action
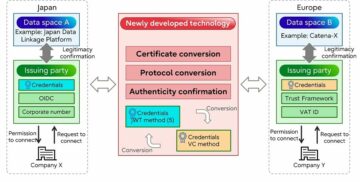
Fujitsu develops technology to convert corporate digital identity credentials, enabling participation of non-European companies in European data spaces

IMF says Bitcoin has become necessary financial tool for preserving wealth amid financial instability

Meta Pushes AI Chatbot Into Instagram, Facebook, WhatsApp – Decrypt

Meta announces Llama 3, launches dedicated AI web portal


The Price of BTC Won’t Rise After Bitcoin Halving, JP Morgan Says – Decrypt

Polygon Sees Whales Stacking Up as MATIC Price Eyes $1

Google Searches For ‘Bitcoin Halving’ Reach Highest Level Ever

“Governance Is Not Optional” Asserts Charles Hoskinson as Cardano Nears Voltaire Phase

Beyond Stablecoins: USDT-Issuer Tether Announces New Distinct Business Divisions – The Daily Hodl

Crypto Influencer Ansem Explains His Meme Coin Thesis and Why He’s Bullish on Bitcoin Runes – Decrypt

Tanssi launches incentivized campaign for its Dancebox testnet

Circle of Games secures $1 million of strategic funding from Nazara Technologies and The Hashgraph Association


‘Bitcoin has as many functionalities as other blockchains’: Trust Machines member weights in Bitcoin DeFi

Binance Converts $1B SAFU Fund to USDC, Now 3% of Circulating Supply

Whale Who Bought Ethereum at 2022 Bottom Sends 5,000 ETH to Kraken: Lookonchain – The Daily Hodl

JPMorgan’s CEO Jamie Dimon Renews Attack on Bitcoin, Calls it “Fraud”

Bitcoin has transformed cross-border transactions, IMF study notes

DeFi Has ‘Higher Level of Accountability’ Following Eisenberg Conviction, Experts Say – Unchained
Next Cryptocurrency To Explode Thursday, April 18 – Pyth Network, Dogecoin, Injective

Most Trending Cryptos on Ethereum Chain Today – Efinity Token, Open Custody Protocol, Not Financial Advice

Hester Peirce Calls Two of SEC’s Enforcement Actions ‘Arbitrary,’ Says Agency’s Ambiguity May Be Deliberate – The Daily Hodl
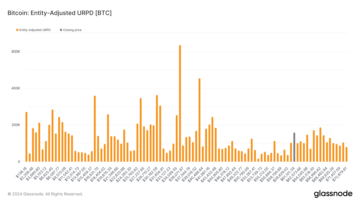
URPD metric indicates a lack of liquidity for Bitcoin below $60,000

Regulated Dollar Stablecoins Created by a Proposed New Senate Bill Would be Crypto’s Ultimate Trojan Horse – Unchained

Self-Proclaimed Bitcoin Creator Craig Wright Drops Lawsuit Against BTC Developers – The Daily Hodl

Sam Altman’s Worldcoin to Launch L2 Blockchain Prioritizing Human Transactions

BEFE Coin: Redefining the Possibilities of Crypto Investment | Live Bitcoin News

The Power Plant of Bitgert Coin: Assessing Its Function in the Crypto Landscape | Live Bitcoin News

Celebrate Teacher Appreciation Month with Thoughtful Crypto-Powered Gift Cards | BitPay
Latest Meme Coins To Invest in Now Thursday, April 18 – Shina Inu, Dorgeverse, Slerf, Chimpzee

$TON Token Goes Live On Leading Web3 Telegram Casino Lucky Block

April 2024 Newsletter for All Things BitPay & Crypto | BitPay

Cardano Unveils New Governance Model with Interim Constitution, Explains Frederik Gregaard

Tastytrade Partners with Unusual Whales for Options Trading

Scaramucci on Bitcoin: Not Yet a Safe Haven, But Could Surpass Gold’s Market Cap

In markets, this time is almost never different. This Bitcoin halving is different.

ceτi AI Acquires Big Energy Investments Inc. in Latest Move

Bitwise Reveals Short and Long-Term Bitcoin Price Impacts of Halving Events


Coinbase’s Former Executive Nana Murugesan Named President of Ethereum Scaling Firm

Bittensor And TON Holders Count On Current Momentum For Higher Gains; Borroe Finance Could Catapult Investors To Massive Profit

ceτi AI Acquires Big Energy Investments Inc. to Boost Its High-Performance Computing Capabilities in North America

Binance converts US$1 bln fund; eyes India comeback after obtaining Dubai license

US Senators Introduce Bipartisan Stablecoin Bill to Establish Regulatory Framework
US, Japan express concern over Japanese yen – MarketPulse


Kraken Introduces Simple, Secure, and Powerful Kraken Wallet

e& life joins Dubai FinTech Summit as a Powered By sponsor

DC Healthcare Rides the Wave of Success with New Openings at Publika and Bukit Indah

Australian dollar shrugs off soft job numbers – MarketPulse


Mitsubishi Heavy Industries and NGK to Jointly Develop Hydrogen Purification System from Ammonia Cracking Gas

Ethereum’s Major Event, Devcon, to Preview in the Philippines This April | BitPinas
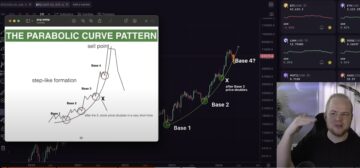
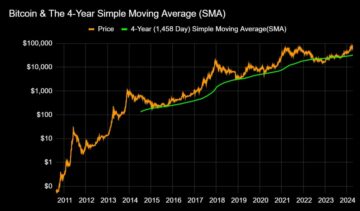
Bitcoin Still on an Exponential Upward Trajectory, According to Analyst Kevin Svenson – But There’s a Catch – The Daily Hodl

After 12 Years at Bank of New Zealand, Financial Expert Joins FMA

Blockchain Applications in the Pharmaceutical Industry

Scalability Performance Analysis of Blockchain Using Hierarchical Model in Healthcare


Binance Could Come Back to India by Paying $2M Fine: Report

Interactive Brokers Expands in Japan, Offers Global CFDs

Unicorn Airdrops to Over 30 Competing NFT and Memecoin Communities

Binance Converts Secure Asset Fund (SAFU) for Users to USDC – Unchained
Bitcoin Dominance Increases as Halving Nears and BTC Price Lingers Near $61K

Bitcoin Withdrawal Volume Surges On Exchanges Contradicting Bear Market Outlook – ZyCrypto Analysis – CryptoInfoNet

Medical Virtual Reality Platform ‘Veyond Metaverse’ Launches On Apple Vision Pro – CryptoInfoNet

Bitcoin Poised to Enter Lenghty Re-Accumulation Phase as Pullback Hits 18%

Worldcoin Announces Layer 2 Network ‘World Chain’ – Unchained

How Top Esports Teams Thrived Despite the Challenging Market

EOS Price Analysis: Uptrend At Risk Below $0.85 | Live Bitcoin News

Bitgert Coin: Riding the Wave of Cryptocurrency Innovation | Live Bitcoin News
LINK Price Eyes Recovery If It’s Able to Hold One Crucial Level

Toyota Launches All-New Land Cruiser “250” Series in Japan

Bitcoin halving optimism faces challenges from economic realities: Goldman Sachs
Litecoin (LTC) Price Analysis: Bears Take Control Below $90 | Live Bitcoin News

To acquire stake in Hangzhou Bizike, Phoenitron Holdings has eye on trillion-dollar e-commerce market
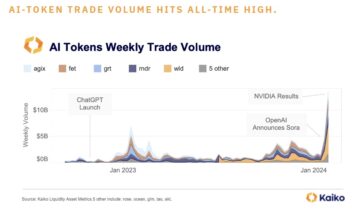
AI Tokens Beat Bitcoin – Crypto Market’s New Favorite – The Daily Hodl

Crypto Whale Loses $4.5 Million in Risky Ethereum ($ETH) Leverage Play

Fujitsu and Oracle collaborate to deliver sovereign cloud and AI capabilities in Japan

Ragnarok Enters Web3 Through Ronin And Gravity Partnership

The Executive Centre Announces Record Revenue in FY2023 Annual Results

Research on Treatments for Alzheimer’s Disease Based on Its Pathological Mechanisms Recieves Award for Science and Technology (Research Category)

JUST IN! Coinbase Announces It Will List A New Altcoin – Omni Network (OMNI)
NEAR Protocol Price Jumped As Kangamoon Approaches Presale Close

Thai SEC To Protect Token Holders With Tightened ICO Rules
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.