Le organizzazioni utilizzano i propri dati per risolvere problemi complessi avviando piccoli esperimenti iterativi e perfezionando la soluzione. Sebbene il potere degli esperimenti non possa essere ignorato, le organizzazioni devono essere caute sull'efficacia in termini di costi di tali esperimenti. Se il tempo viene speso per creare l'infrastruttura sottostante per abilitare gli esperimenti, aumenta ulteriormente il costo.
Gli sviluppatori hanno bisogno di un ambiente di sviluppo integrato (IDE) per l'esplorazione dei dati e il debug dei flussi di lavoro e di diversi profili di calcolo per l'esecuzione di questi flussi di lavoro. Se scegli Amazon EMR per tali casi d'uso, puoi utilizzare un IDE chiamato Amazon EMR Studio per l'esplorazione, la trasformazione, il controllo della versione e il debug dei dati ed eseguire processi Spark per elaborare grandi volumi di dati. Distribuzione Amazon EMR su Amazon EKS semplifica la gestione, riduce i costi e migliora le prestazioni. Tuttavia, un tecnico dei dati o un amministratore IT deve dedicare del tempo alla creazione dell'infrastruttura sottostante, alla configurazione della sicurezza e alla creazione di un endpoint gestito a cui gli utenti possono connettersi. Ciò significa che tali progetti devono attendere che questi esperti creino l'infrastruttura.
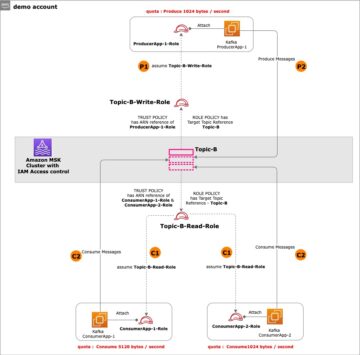
In questo post, mostriamo come un ingegnere di dati o un amministratore IT può utilizzare il Architettura di riferimento di AWS Analytics (ARA) per accelerare l'implementazione dell'infrastruttura, risparmiando alla tua organizzazione tempo e denaro spesi per questi esperimenti di analisi dei dati. Utilizziamo la libreria per distribuire un file Amazon Elastic Kubernetes (Amazon EKS), configuralo per utilizzare Amazon EMR su EKS e distribuisci a cluster virtuale ed endpoint gestiti e EMR Studio. È quindi possibile eseguire lavori sul cluster virtuale o eseguire l'analisi esplorativa dei dati con Notebook Jupyter su Amazon EMR Studio e Amazon EMR su EKS. L'architettura seguente rappresenta l'infrastruttura che distribuirai con AWS Analytics Reference Architecture.

Prerequisiti
Per seguire, devi disporre di un account AWS con bootstrap con il file Kit di sviluppo cloud AWS (AWSCDK). Per le istruzioni, fare riferimento a Bootstrapping. Il seguente tutorial utilizza TypeScript e richiede la versione 2 o successiva di AWS CDK. Se non hai installato il CDK di AWS, fai riferimento a Installa il CDK AWS.
Configura un progetto AWS CDK
Per distribuire le risorse utilizzando ARA, devi prima configurare un progetto AWS CDK e installare la libreria ARA. Completa i seguenti passaggi:
- Crea una cartella denominata emr-eks-app:
- Inizializza un progetto AWS CDK in una directory vuota ed esegui il seguente comando:
- Installa la libreria ARA:
- In lib/emr-eks-app.ts, importa la libreria ARA come segue. La prima riga chiama la libreria ARA, la seconda definisce le policy AWS Identity and Access Management (IAM):
Crea e definisci un cluster EKS e una capacità di calcolo
Per creare un EMR su EKS cluster virtuale, devi prima distribuire un cluster EKS. La libreria ARA definisce un costrutto chiamato EmrEksCluster. Il costrutto esegue il provisioning di un cluster EKS, abilita Ruoli IAM per gli account di servizioe distribuisce un set di controller di supporto come il controller di gestione dei certificati (necessario per l'endpoint gestito utilizzato da Amazon EMR Studio) e un auto scaler del cluster per avere un cluster elastico e risparmiare sui costi quando nessun lavoro viene inviato al cluster .
In lib/emr-eks-app.ts, aggiungi la seguente riga:
Per saperne di più sulle proprietà che puoi personalizzare, fai riferimento a EmrEksClusterProps. Ci sono due parametri obbligatori in EmrEksCluster costrutto: il primo è eksAdminRoleArn role è obbligatorio ed è il ruolo che utilizzi per interagire con il piano di controllo Kubernetes. Questo ruolo deve disporre delle autorizzazioni amministrative per creare o aggiornare il cluster. Il secondo parametro è autoscaling, questo parametro consente di selezionare anche il meccanismo di ridimensionamento automatico Karpenter or Kubernetes Cluster Autoscaler nativo. In questo blog utilizzeremo Karpenter e ne consigliamo l'uso grazie alla scalabilità automatica più rapida, alla gestione semplificata dei nodi e al provisioning. Ora sei pronto per definire la capacità di calcolo.
Un modo per definire i nodi di lavoro in Amazon EKS è utilizzare i gruppi di nodi gestiti. Usiamo un gruppo di nodi chiamato tooling, che ospita il coredn, controller di ingresso, gestore certificati, Karpenter e qualsiasi altro pod necessario per l'esecuzione dell'EMR sui lavori EKS o ManagedEndpoint. Definiamo anche default Karpenter Fornitori che definiscono la capacità da utilizzare per i lavori inviati da EMR su EKS. Questi provisioner sono ottimizzati per diversi casi d'uso di Spark (lavori critici, lavori non critici, sperimentazione e sessioni interattive). Il costrutto consente inoltre di inviare il proprio provisioner definito da un manifest Kubernetes tramite un metodo chiamato addKarpenterProvisioner. Parliamo dei Provisioner predefiniti.
Configurazioni predefinite dei fornitori
I provisioner predefiniti sono impostati per una rapida sperimentazione e lo sono sempre creato per impostazione predefinita. Tuttavia, se non si desidera utilizzarli, è possibile impostare il file defaultNodeGroups parametro false nel EmrEksCluster proprietà al momento della creazione. I fornitori sono definiti come segue e vengono creati in ciascuna delle sottoreti utilizzate da Amazon EKS:
- Approvvigionatore critico – È dedicato a supportare i lavori con SLA aggressivi e sono sensibili al fattore tempo. Il provisioner utilizza le istanze on demand, che non vengono arrestate, a differenza delle istanze Spot, e il loro ciclo di vita segue uno dei processi. I nodi usano gli instance store, che sono dischi NVMe fisicamente collegati all'host, che offrono un elevato throughput di I/O che consente migliori prestazioni di Spark, perché viene usato come storage temporaneo per lo spill e lo shuffle del disco. I tipi di istanza utilizzati nel nodo sono della famiglia m6gd. Le istanze utilizzano il Gravitone AWS processore, che offre miglior rapporto prezzo/prestazioni rispetto ai processori x86. Per utilizzare questo provisioner nei tuoi lavori, puoi utilizzare quanto segue configurazione di esempio, a cui fa riferimento il sostituzione della configurazione dell'EMR sull'invio di lavoro EKS.
- Provisioner non critico – Questo fornitore sfrutta le istanze Spot per risparmiare sui costi per i lavori che non sono sensibili al fattore tempo o per i lavori utilizzati per gli esperimenti. Questo nodo utilizza istanze Spot perché i processi non sono critici e possono essere interrotti. Queste istanze possono essere arrestate se l'istanza viene recuperata. I tipi di istanza utilizzati nel nodo sono della famiglia m6gd, il driver è On-Demand e gli esecutori sono istanze spot.
- Approvvigionatore di notebook – Il provisioner serve per l'esecuzione di endpoint gestiti utilizzati da Amazon EMR Studio per l'esplorazione dei dati tramite Amazon EMR su EKS. Le istanze sono della famiglia t3 e sono on demand per driver e istanze Spot per gli esecutori per mantenere bassi i costi. Se le istanze dell'esecutore vengono arrestate, ne vengono avviate di nuove da Karpenter. Se le istanze dell'esecutore vengono arrestate troppo spesso, puoi definirne di tue che utilizzino le istanze on demand.
Le seguenti link fornisce ulteriori dettagli su come viene definito ciascun provisioner. Una proprietà di importazione definita nei Provisioner predefiniti è che ce n'è una per ogni zona di disponibilità. Questo è importante perché ti consente di ridurre i costi di trasferimento di rete tra zone di disponibilità quando Spark esegue uno shuffle.
Per questo post, utilizziamo i Provisioner predefiniti, quindi non è necessario aggiungere alcuna riga di codice per questa sezione. Se vuoi aggiungere i tuoi fornitori, puoi sfruttare il metodo addKarpenterProvisioner per applicare i propri manifest. Puoi usare i metodi di supporto in Utils classe come readYamlDocument per leggere documenti YAML e loadYaml carica i file YAML e passali come argomenti a addKarpenterProvisioner metodo.
Distribuisci il cluster virtuale e un ruolo di esecuzione
Un cluster virtuale è uno spazio dei nomi Kubernetes con cui è registrato Amazon EMR; quando invii un lavoro, i pod del driver e dell'executor sono in esecuzione nello spazio dei nomi associato. Il EmrEksCluster costrutto offre un metodo chiamato addEmrVirtualCluster, che crea automaticamente il cluster virtuale. Il metodo prende EmrVirtualClusterOptions come parametro, che ha i seguenti attributi:
- Nome – Il nome del tuo cluster virtuale.
- creareSpazio dei nomi – Un campo facoltativo che crea lo spazio dei nomi EKS. Questo è di tipo booleano e per impostazione predefinita non crea uno spazio dei nomi EKS separato, quindi il tuo cluster virtuale viene creato nello spazio dei nomi predefinito.
- eksNamespace – Il nome dello spazio dei nomi EKS da collegare al cluster EMR virtuale. Se non viene fornito alcuno spazio dei nomi, il costrutto utilizza lo spazio dei nomi predefinito.
- In
lib/emr-eks-app.ts, aggiungi la seguente riga per creare il tuo cluster virtuale:Ora creiamo il ruolo di esecuzione, che è un ruolo IAM utilizzato dal driver e dall'esecutore per interagire con i servizi AWS. Prima di poter creare il ruolo di esecuzione per Amazon EMR, dobbiamo prima creare il file
ManagedPolicy. Tieni presente che nel codice seguente creiamo una policy per consentire l'accesso al bucket Amazon Simple Storage Service (Amazon S3) e ai log di Amazon CloudWatch. - In
lib/emr-eks-app.ts, aggiungi la riga seguente per creare il criterio:Se desideri utilizzare il catalogo dati di AWS Glue, aggiungi la relativa autorizzazione nella policy precedente.
Ora creiamo il ruolo di esecuzione per Amazon EMR su EKS utilizzando la policy definita nella fase precedente utilizzando il
createExecutionRolemetodo di istanza. I pod driver ed esecutore possono quindi assumere questo ruolo per accedere ed elaborare i dati. L'ambito del ruolo è tale che solo i pod nello spazio dei nomi del cluster virtuale possono assumerlo. Per ulteriori informazioni sulla condizione implementata da questo metodo per limitare l'accesso al ruolo solo ai pod creati da Amazon EMR su EKS nello spazio dei nomi del cluster virtuale, consulta Utilizzo dei ruoli di esecuzione dei processi con Amazon EMR su EKS. - In
lib/emr-eks-app.ts, aggiungi la riga seguente per creare il ruolo di esecuzione:Il codice precedente produce un ruolo IAM chiamato
execRoleJobcon la policy IAM definita inemrekspolicye limitato allo spazio dei nomidataanalysis. - Infine, emettiamo i parametri che sono importanti per l'esecuzione del lavoro:
Distribuisci Amazon EMR Studio ed esegui il provisioning degli utenti
Per distribuire un EMR Studio per l'esplorazione dei dati e la creazione di lavori, la libreria ARA ha un costrutto chiamato NotebookPlatform. Questo costrutto ti consente di distribuire tutti gli EMR Studios di cui hai bisogno (entro il limite dell'account) e configurarli con la modalità di autenticazione adatta a te e assegnare loro gli utenti. Per ulteriori informazioni sulle modalità di autenticazione disponibili in Amazon EMR Studio, consulta Scegli una modalità di autenticazione per Amazon EMR Studio.
Il costrutto crea tutti i ruoli e le policy IAM necessari a Amazon EMR Studio. Crea inoltre un bucket S3 in cui tutti i notebook vengono archiviati da Amazon EMR Studio. Il bucket è crittografato con a chiave gestita dal cliente (CMK) generato dallo stack AWS CDK. I passaggi seguenti mostrano come creare il proprio EMR Studio con il costrutto.
La costruzione della piattaforma per notebook richiede NotebookPlatformProps come proprietà, che consente di definire EMR Studio, uno spazio dei nomi, il nome di EMR Studio e la sua modalità di autenticazione.
- In
lib/emr-eks-app.ts, aggiungi la seguente riga:Per questo post, utilizziamo gli utenti IAM in modo che tu possa riprodurlo facilmente nel tuo account. Tuttavia, se disponi già della federazione IAM o del Single Sign-On (SSO), puoi utilizzarli al posto degli utenti IAM. Per ulteriori informazioni sui parametri di
NotebookPlatformProps, fare riferimento a NotebookPlatformProps.Successivamente, dobbiamo creare e assegnare gli utenti ad Amazon EMR Studio. Per questo, il costrutto ha un metodo chiamato
addUserche prende un elenco di utenti e li assegna ad Amazon EMR Studio in caso di SSO o aggiorna la policy IAM per consentire l'accesso ad Amazon EMR Studio per gli utenti IAM forniti. L'utente può anche disporre di più endpoint gestiti e per ogni utente può essere definita la propria versione di Amazon EMR. Possono utilizzare un set diverso di istanze Amazon Elastic Compute Cloud (Amazon EC2) e autorizzazioni diverse utilizzando i ruoli di esecuzione del lavoro. - In
lib/emr-eks-app.ts, aggiungi la seguente riga:Nel codice precedente, per brevità, riutilizziamo la stessa policy IAM che abbiamo creato nel ruolo di esecuzione.
Si noti che il costrutto ottimizza il numero di endpoint gestiti creati. Se due endpoint hanno lo stesso nome, ne viene creato solo uno.
- Ora che abbiamo definito la nostra distribuzione, possiamo distribuirla:
È possibile trovare un progetto di esempio che contiene tutti i passaggi della procedura dettagliata nel seguente GitHub deposito.
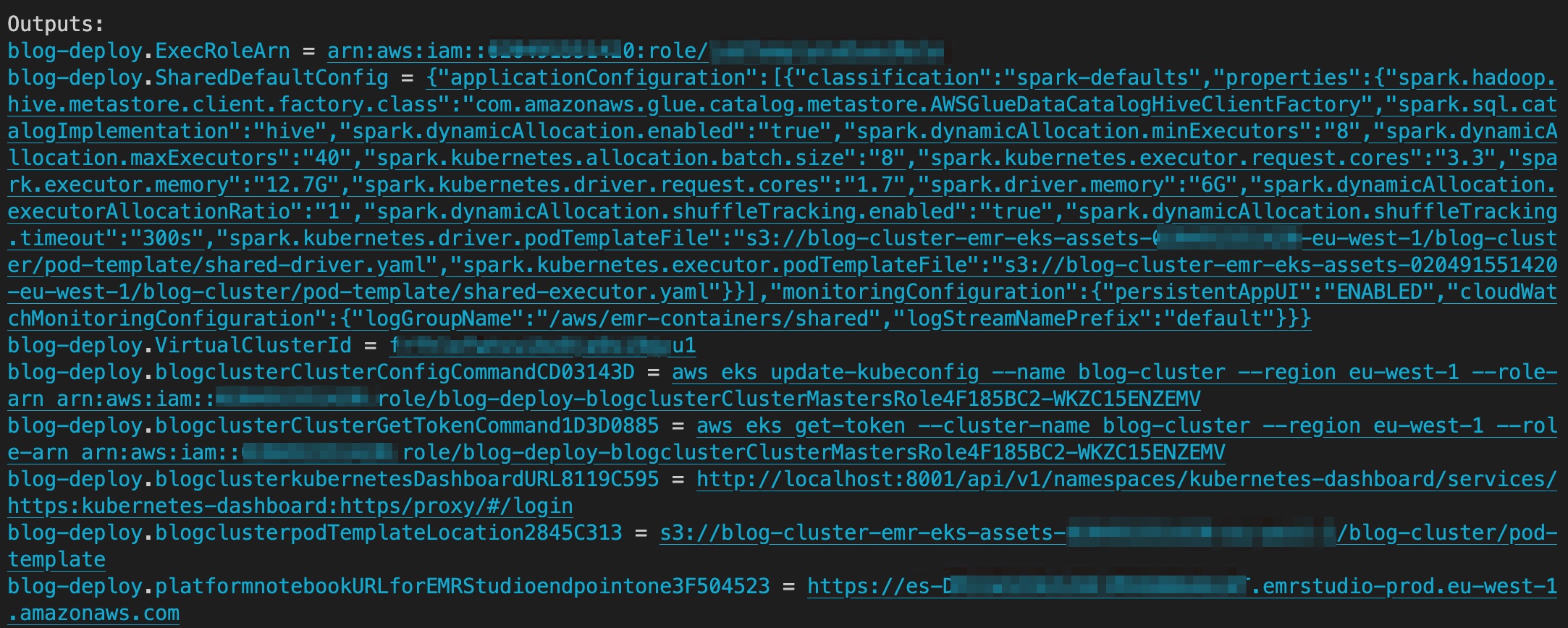
Quando la distribuzione è completa, l'output contiene il bucket S3 contenente gli asset per podTemplate, il collegamento per EMR Studio e l'ID cluster virtuale EMR Studio. Lo screenshot seguente mostra l'output di AWS CDK dopo il completamento della distribuzione.
Invia lavori

Poiché stiamo utilizzando i Provisioner predefiniti, utilizzeremo il file podTemplate che è definito dal costrutto disponibile su Repository ARA su GitHub. Questi vengono caricati per te dal costrutto in un bucket S3 chiamato <clustername>-emr-eks-assets; devi solo fare riferimento a loro nel tuo lavoro Spark. In questo lavoro, utilizzi anche i parametri del lavoro nell'output alla fine della distribuzione di AWS CDK. Questi parametri ti consentono di utilizzare il catalogo dati di AWS Glue e di implementare best practice di Spark su Kubernetes come dynamicAllocation e collocazione pod. Alla fine di cdk deploy ARA produrrà configurazioni di esempio di lavoro con le migliori pratiche elencate prima che puoi utilizzare per inviare un lavoro. Puoi inviare un lavoro come segue.
L'esecuzione di un processo è un'unità di lavoro, ad esempio un file JAR Spark che viene inviato all'EMR sul cluster EKS. Iniziamo un lavoro usando il start-job-run comando. Nota che puoi usare SparkSubmitParameters per specificare il percorso Amazon S3 al modello di pod, come mostrato nel seguente comando:
Il codice assume i seguenti valori:
- – L'ID del cluster virtuale EMR
- – Il nome del lavoro Spark
- – Il ruolo di esecuzione che hai creato
- – L'URI Amazon S3 del lavoro Spark
- – L'URI Amazon S3 del modello di pod del driver, che ottieni dall'output di AWS CDK
- – L'URI Amazon S3 del modello di pod executor
- – Il nome del gruppo di log di CloudWatch
- – Il prefisso del flusso di log di CloudWatch
Puoi accedere alla console di Amazon EMR per verificare lo stato del processo e visualizzare i log. Puoi anche controllare lo stato eseguendo il file describe-job-run comando:
Esplora i dati utilizzando Amazon EMR Studio
In questa sezione, mostriamo come creare uno spazio di lavoro in Amazon EMR Studio e connettersi all'endpoint gestito Amazon EKS dallo spazio di lavoro. Dall'output, utilizza il collegamento ad Amazon EMR Studio per passare alla distribuzione di EMR Studio. Devi accedere con l'IAM nome utente hai fornito nel addUser metodo.
Crea un'area di lavoro
Per creare un'area di lavoro, completare i seguenti passaggi:
- Accedi a EMR Studio creato da AWS CDK.
- Scegli Crea spazio di lavoro.
- Immettere un nome per l'area di lavoro e una descrizione facoltativa.
- Seleziona Consentire Collaborazione nell'area di lavoro se vuoi lavorare con altri utenti di Studio in questo spazio di lavoro in tempo reale.
- Scegli Crea spazio di lavoro.

Dopo aver creato l'area di lavoro, selezionala dall'elenco delle aree di lavoro per aprire l'ambiente JupyterLab.
Lo screenshot seguente mostra l'aspetto del terminale. Per ulteriori informazioni sull'interfaccia utente, fare riferimento a Comprendere l'interfaccia utente di Workspace.
Connettiti a un EMR sull'endpoint gestito EKS
Puoi connetterti facilmente all'EMR sull'endpoint gestito EKS dall'area di lavoro.
- Nel riquadro di navigazione, in Cluster menu, selezionare Cluster EMR su EKS per Tipo di grappolo.
I cluster virtuali vengono visualizzati nel menu a discesa Cluster EMR su EKS e l'endpoint viene visualizzato nel menu a discesa Endpoint. Se sono presenti più endpoint, vengono visualizzati qui e puoi passare facilmente da un endpoint all'altro dall'area di lavoro. - Selezionare l'endpoint appropriato e scegliere Allega.

Lavora con un taccuino
Ora puoi aprire un notebook e connetterti a un kernel preferito per svolgere le tue attività. Ad esempio, puoi selezionare un kernel PySpark, come mostrato nello screenshot seguente.
Esplora i tuoi dati
Il primo passaggio del nostro esercizio di esplorazione dei dati consiste nel creare una sessione Spark e quindi caricare il set di dati del taxi di New York dal bucket S3 in un Frame dati. Utilizzare il seguente blocco di codice per caricare i dati in un frame di dati. Copia l'URI di Amazon S3 per la posizione in cui risiede il set di dati in Amazon S3.
Dopo aver caricato i dati in un frame di dati, sostituiamo i dati del file current_date colonna con la data corrente effettiva, contare il numero di righe e salvare i dati in un file Parquet:
Lo screenshot seguente mostra il risultato del nostro notebook in esecuzione su Amazon EMR Studio e con PySpark in esecuzione su Amazon EMR su EKS.
ripulire
Per ripulire dopo questo post, corri cdk destroy.
Conclusione
In questo post, abbiamo mostrato come utilizzare l'ARA per implementare rapidamente un'infrastruttura di analisi dei dati e iniziare a sperimentare con i dati. È possibile trovare l'esempio completo a cui si fa riferimento in questo post nel file Repository GitHub. L'architettura di riferimento di AWS Analytics implementa un modello di analisi comune e le best practice AWS per offrirti costrutti pronti all'uso per i tuoi esperimenti. Uno dei modelli è la mesh di dati, che puoi consultare come utilizzare in questo post sul blog.
Puoi anche esplorare altro costrutti offerti in questa libreria per sperimentare i servizi AWS Analytics prima di trasferire il carico di lavoro alla produzione.
Informazioni sugli autori
 Lofi Mouhib è un Senior Solutions Architect che lavora per il team del settore pubblico con Amazon Web Services. Aiuta i clienti del settore pubblico in tutta l'area EMEA a realizzare le loro idee, creare nuovi servizi e innovare per i cittadini. Nel tempo libero, Lotfi ama andare in bicicletta e correre.
Lofi Mouhib è un Senior Solutions Architect che lavora per il team del settore pubblico con Amazon Web Services. Aiuta i clienti del settore pubblico in tutta l'area EMEA a realizzare le loro idee, creare nuovi servizi e innovare per i cittadini. Nel tempo libero, Lotfi ama andare in bicicletta e correre.
 Sandipan Bhaumik è un Senior Analytics Specialist Solutions Architect con sede a Londra. Ha lavorato con clienti in diversi settori come servizi bancari e finanziari, sanità, energia e servizi pubblici, produzione e vendita al dettaglio, aiutandoli a risolvere sfide complesse con piattaforme di dati su larga scala. In AWS si concentra su account strategici nel Regno Unito e in Irlanda e aiuta i clienti ad accelerare il loro viaggio verso il cloud e a innovare utilizzando i servizi di analisi e machine learning di AWS. Ama giocare a badminton e leggere libri.
Sandipan Bhaumik è un Senior Analytics Specialist Solutions Architect con sede a Londra. Ha lavorato con clienti in diversi settori come servizi bancari e finanziari, sanità, energia e servizi pubblici, produzione e vendita al dettaglio, aiutandoli a risolvere sfide complesse con piattaforme di dati su larga scala. In AWS si concentra su account strategici nel Regno Unito e in Irlanda e aiuta i clienti ad accelerare il loro viaggio verso il cloud e a innovare utilizzando i servizi di analisi e machine learning di AWS. Ama giocare a badminton e leggere libri.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- Chi siamo
- accelerare
- accesso
- gestione degli accessi
- Il mio account
- conti
- operanti in
- azioni
- Aggiunge
- amministrativo
- Dopo shavasana, sedersi in silenzio; saluti;
- aggressivo
- Tutti
- assegnazione
- consente
- già
- Sebbene il
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- .
- analitica
- ed
- Apache
- App
- apparire
- APPLICA
- opportuno
- architettura
- argomenti
- Attività
- associato
- allegare
- gli attributi
- Autenticazione
- autore
- auto
- disponibile
- AWS
- Colla AWS
- AWS Identity and Access Management (IAM)
- Settore bancario
- basato
- perché
- prima
- sotto
- MIGLIORE
- best practice
- Meglio
- fra
- Bloccare
- Blog
- Libri
- costruire
- costruttore
- detto
- Bandi
- Ultra-Grande
- Custodie
- casi
- catalogo
- cauto
- CD
- a livello internazionale
- sfide
- dai un'occhiata
- Scegli
- cittadini
- classe
- classificazione
- cliente
- Cloud
- Cluster
- codice
- Colonna
- COM
- Uncommon
- completamento di una
- complesso
- Calcolare
- condizione
- Connettiti
- consolle
- costruire
- contiene
- di controllo
- controllore
- Costo
- Costi
- creare
- creato
- crea
- Creazione
- creazione
- critico
- Corrente
- Clienti
- personalizzare
- dati
- analisi dei dati
- Dati Analytics
- ingegnere dei dati
- Data
- datetime
- dedicato
- Predefinito
- definisce
- schierare
- distribuzione
- deployment
- Distribuisce
- descrizione
- dettagli
- Mercato
- diverso
- discutere
- documento
- non
- Dont
- autista
- ogni
- facilmente
- effetto
- o
- abilitato
- Abilita
- consentendo
- crittografato
- endpoint
- ingegnere
- Ambiente
- Etere (ETH)
- esempio
- esecuzione
- Esercitare
- esperimento
- esperti
- esplorazione
- Analisi dei dati esplorativi
- esplora
- fabbrica
- famiglia
- più veloce
- Federazione
- campo
- Compila il
- File
- finanziario
- servizi finanziari
- Trovare
- Nome
- si concentra
- seguire
- i seguenti
- segue
- TELAIO
- da
- pieno
- funzioni
- ulteriormente
- generato
- ottenere
- GitHub
- Go
- Gruppo
- Gruppo
- Hadoop
- assistenza sanitaria
- aiutare
- aiuta
- qui
- Alta
- Alveare
- host
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- IAM
- idee
- Identità
- identità e gestione degli accessi
- Gestione dell'identità e degli accessi (IAM)
- realizzare
- implementato
- attrezzi
- importare
- importante
- migliora
- in
- industrie
- informazioni
- Infrastruttura
- innovare
- install
- esempio
- invece
- istruzioni
- integrato
- interagire
- interattivo
- Interfaccia
- sospeso
- Irlanda
- IT
- Lavoro
- Offerte di lavoro
- viaggio
- json
- mantenere
- kubernetes
- grandi
- larga scala
- IMPARARE
- apprendimento
- Leva
- Biblioteca
- LIMITE
- linea
- Linee
- LINK
- connesso
- Lista
- elencati
- caricare
- località
- Londra
- SEMBRA
- Basso
- macchina
- machine learning
- gestito
- gestione
- direttore
- obbligatorio
- consigliato per la
- molti
- si intende
- meccanismo
- Memorie
- Menu
- metodo
- metodi
- Moda
- soldi
- Scopri di più
- multiplo
- Nome
- Detto
- Navigare
- Navigazione
- necessaria
- Bisogno
- di applicazione
- esigenze
- Rete
- New
- New York
- nodo
- nodi
- taccuino
- computer portatili
- numero
- offrire
- offerto
- Offerte
- ONE
- aprire
- ottimizzati
- Ottimizza
- organizzazione
- organizzazioni
- Altro
- proprio
- vetro
- parametro
- parametri
- sentiero
- Cartamodello
- modelli
- performance
- autorizzazione
- permessi
- Fisicamente
- posto
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- baccelli
- Termini e Condizioni
- politica
- Post
- energia
- pratiche
- preferito
- precedente
- problemi
- processi
- Processore
- Produzione
- Profili
- progetto
- progetti
- proprietà
- proprietà
- purché
- fornisce
- fornitura
- la percezione
- rapidamente
- veloce
- Leggi
- Lettura
- pronto
- di rose
- tempo reale
- rendersi conto
- raccomandare
- record
- ridurre
- riduce
- registrato
- sostituire
- rappresentare
- richiesta
- richiede
- Risorse
- limitare
- colpevole
- nello specifico retail
- Ruolo
- ruoli
- Correre
- running
- sake
- stesso
- Risparmi
- risparmio
- Secondo
- Sezione
- settore
- problemi di
- anziano
- delicata
- servizio
- Servizi
- Sessione
- set
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- mescolare
- segno
- Un'espansione
- semplificata
- singolo
- Taglia
- piccole
- So
- soluzione
- Soluzioni
- RISOLVERE
- Scintilla
- specialista
- spendere
- esaurito
- Spot
- SQL
- pila
- inizia a
- iniziato
- Di partenza
- dichiarazioni
- Stato dei servizi
- step
- Passi
- fermato
- conservazione
- memorizzati
- negozi
- Strategico
- ruscello
- studio
- studios
- sottomissione
- inviare
- presentata
- sottoreti
- tale
- adatto
- in dotazione
- Supporto
- Interruttore
- prende
- task
- team
- modello
- temporaneo
- terminal
- I
- Regno Unito
- loro
- Attraverso
- portata
- tempo
- a
- pure
- Totale
- trasferimento
- Trasformazione
- transizione
- vero
- lezione
- Tipi di
- Dattiloscritto
- Uk
- sottostante
- unità
- Aggiornanento
- Aggiornamenti
- caricato
- URI
- uso
- Utente
- Interfaccia utente
- utenti
- utilità
- APPREZZIAMO
- Valori
- versione
- controllo della versione
- Visualizza
- virtuale
- volume
- aspettare
- sito web
- servizi web
- Che
- quale
- volere
- entro
- Lavora
- lavorato
- lavoratore
- flussi di lavoro
- lavoro
- scrivere
- YAML
- Trasferimento da aeroporto a Sharm
- zefiro