Questo post è stato co-scritto da Mahesh Pasupuleti e Gaurav Shah di Poshmark.
Poshmark è un mercato sociale leader per stili nuovi e di seconda mano per donne, uomini, bambini, animali domestici, casa e altro ancora. Combinando la connessione umana dello shopping fisico con i vantaggi di scala, facilità e selezione dell'e-commerce, Poshmark rende l'acquisto e la vendita semplici, sociali e sostenibili. La sua comunità di oltre 80 milioni di utenti registrati negli Stati Uniti, Canada, Australia e India sta guidando un futuro più sostenibile per l'industria della moda.
Un obiettivo importante da raggiungere per qualsiasi organizzazione è quello di aumentare le entrate della linea superiore. I ricavi principali si riferiscono al valore totale delle vendite di servizi o prodotti di un'organizzazione. I due approcci principali che le organizzazioni impiegano per aumentare le entrate sono l'espansione geografica per entrare in nuovi mercati e l'aumento della quota di mercato all'interno di un mercato migliorando l'esperienza del cliente (CX).
Migliorare la CX è una linea guida ben nota per attrarre e fidelizzare i clienti e quindi aumentare la quota di mercato. In questo post, condividiamo come Poshmark miglioramento della CX e accelerazione della crescita dei ricavi utilizzando una soluzione di analisi in tempo reale. Discutiamo su come creare una tale soluzione utilizzando Flussi di dati di Amazon Kinesis, Streaming gestito da Amazon per Kafka (Amazzonia MSK), Amazon Kinesis Data Analytics per Apache Flink; le decisioni progettuali che sono andate nell'architettura; e i vantaggi commerciali osservati da Poshmark.
Sfida di alto livello: la necessità di analisi in tempo reale
I precedenti sforzi di Poshmark per migliorare la CX attraverso l'analisi si basavano sull'elaborazione in batch dei dati di analisi e sull'utilizzo quotidiano per migliorare la CX. Sebbene questi sforzi basati sull'analisi batch abbiano avuto successo in una certa misura, hanno visto opportunità per migliorare l'esperienza del cliente con la personalizzazione in tempo reale e la guida alla sicurezza durante l'interazione del cliente con l'app Poshmark. Le informazioni sui clienti raccolte dall'analisi batch non potevano essere abbinate alle attività correnti dei clienti in tempo reale a causa delle latenze coinvolte nell'arricchimento delle attività correnti con le conoscenze acquisite attraverso i processi batch. Pertanto, mancava l'opportunità di fornire offerte su misura o mostrare prodotti in base alle preferenze e ai comportamenti dei clienti quasi in tempo reale, il che contribuisce a migliorare notevolmente l'esperienza del cliente. Allo stesso modo, mancava anche l'opportunità di individuare le frodi entro un secondo, prima del checkout.
Per migliorare l'esperienza del cliente, Poshmark ha deciso di investire nella creazione di una piattaforma di analisi in tempo reale per abilitare funzionalità in tempo reale, come spiegato più avanti in questo post. Gli ingegneri di Poshmark hanno lavorato a stretto contatto con gli architetti di AWS attraverso il Programma AWS Data Lab. L'AWS Data Lab offre impegni ingegneristici congiunti accelerati tra i clienti e le risorse tecniche AWS per creare risultati tangibili che accelerino le iniziative di modernizzazione dei dati e dell'analisi. Il Design Lab è un impegno da metà a due giorni con il team del cliente che offre una guida prescrittiva per arrivare alla progettazione dell'architettura della soluzione ottimale prima di iniziare a costruire la piattaforma.
Progettazione dell'architettura della soluzione attraverso il processo AWS Data Lab
Le parti interessate aziendali e tecniche di Poshmark e gli architetti di AWS Data Lab hanno discusso i requisiti aziendali a breve e lungo termine insieme alle capacità funzionali e non funzionali necessarie per decidere l'approccio dell'architettura. Hanno esaminato l'attuale architettura dello stato ei vincoli per comprendere il flusso di dati ei punti di integrazione tecnica. Il team congiunto ha discusso i pro ei contro dei vari servizi AWS che già esistono nell'attuale architettura di Poshmark, così come altri servizi AWS che possono soddisfare i requisiti.
Poshmark voleva affrontare i seguenti casi d'uso aziendali tramite la piattaforma di analisi in tempo reale:
- Sessionizzazione – Poshmark acquisisce sia gli eventi dell'applicazione lato server che gli eventi di tracciamento lato client. Volevano utilizzare questi eventi per identificare e analizzare le sessioni utente per tenere traccia del comportamento.
- Iscrizione illegittima e prevenzione dell'accesso – Poshmark voleva rilevare e vietare eventi di registrazione o accesso illegittimi da bot o traffico non umano in tempo reale sull'applicazione Poshmark.
- Traduzione dell'IP – Gli indirizzi IP presenti negli eventi saranno tradotti in città, stato e codice postale e arricchiti con altre informazioni per implementare servizi in grado di rilevare la posizione quasi in tempo reale che comprendono funzioni relative alla sicurezza e funzioni di personalizzazione.
- Anonimizzazione – Poshmark voleva rendere anonimi gli eventi e rendere disponibili i dati agli utenti interni per interrogarli quasi in tempo reale.
- Raccomandazioni personalizzate – Il comportamento degli utenti basato sugli eventi clickstream può essere catturato fino all'ultimo secondo prima di arricchirlo per la personalizzazione e inviarlo al modello per prevedere le raccomandazioni.
- Altri casi d'uso – Casi d'uso aggiuntivi relativi ad aggregazioni e casi d'uso di inferenza di machine learning (ML) come l'autorizzazione a operare, elencare il rilevamento dello spam ed evitare il furto di account (ATO), tra gli altri.
Un modello comune identificato per questi casi d'uso era la necessità di una pipeline centrale di arricchimento dei dati per arricchire gli eventi non elaborati in arrivo prima che i dati degli eventi possano essere utilizzati per l'effettiva elaborazione aziendale. Nel Design Lab, ci siamo concentrati sulla progettazione di pipeline di arricchimento dei dati volte ad arricchire gli eventi con dati da file statici, archivi di dati dinamici come database, API o all'interno dello stesso flusso di eventi per i suddetti casi d'uso di streaming. Più avanti in questo post, trattiamo i punti salienti discussi durante il laboratorio su design e architettura.
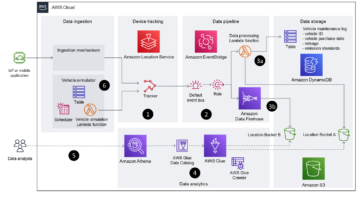
Architettura della soluzione di analisi in batch
Il diagramma seguente mostra l'architettura precedente di Poshmark. Per brevità, viene spiegato solo il flusso relativo alla piattaforma di analisi in tempo reale.

Le interazioni degli utenti sulle applicazioni web e mobili Poshmark generano eventi lato server. Questi eventi includono l'aggiunta al carrello, gli ordini, le transazioni e altro sui server delle applicazioni e la visualizzazione della pagina, i clic e altro sui server di tracciamento. Fluente con un Cinesi amazzonica plugin è impostato sia sull'applicazione che sui server di tracciamento a cui inviare questi eventi Flussi di dati di Amazon Kinesis. Il plug-in Fluentd Kinesis aggrega gli eventi prima di inviarli a Kinesis Data Streams. Un singolo flusso di dati Kinesis è attualmente configurato per acquisire questi eventi. Una chiave di partizione casuale è configurata in Fluentd per gli eventi per consentire una distribuzione uniforme degli eventi tra le partizioni. Il formato dei dati dell'evento è JSON annidato. Poshmark mantiene la stessa grammatica dello schema al primo livello di JSON sia per gli eventi del server lato server che per quelli lato client. Gli attributi a livello nidificato possono differire tra gli eventi lato server e quelli lato client.
Poshmark riceve circa 1 miliardo di eventi al giorno (100 milioni all'ora nelle ore di punta, 10 milioni all'ora nelle ore non di punta). La dimensione media del record dell'evento è di 1.2 KB.
I dati del flusso di dati Kinesis vengono utilizzati da due applicazioni:
- Un'applicazione di streaming Spark attiva Amazon EMR viene utilizzato per scrivere i dati dal flusso di dati Kinesis in un data lake ospitato su Servizio di archiviazione semplice Amazon (Amazon S3) in modo partizionato. I dati del data lake S3 vengono utilizzati per l'elaborazione in batch e l'analisi tramite Amazon EMR e Amazon RedShift.
- Druido ospitato su Cloud di calcolo elastico di Amazon (Amazon EC2) si integra con il flusso di dati Kinesis per l'importazione di streaming e consente agli utenti di eseguire query OLAP "slice-and-dice". I dashboard operativi sono ospitati su Grafana integrati con Druid.
Miglioramenti desiderati alla soluzione iniziale
I casi d'uso discussi durante le sessioni sull'architettura rientrano in una o più combinazioni dei seguenti requisiti di elaborazione del flusso:
- Elaborazione di eventi senza stato – Ad esempio, anonimizzazione quasi in tempo reale.
- Ricerca esterna – Ricerca di un valore da archivi esterni. Ad esempio, indirizzo IP, città, codice postale, stato o ID.
- Elaborazione dei dati con stato – Accesso a eventi o aggregazioni passati o inferenze ML.
Per soddisfare questi requisiti, la piattaforma di streaming è suddivisa in due livelli:
- Arricchimento centrale dei dati – Questo livello esegue gli arricchimenti comunemente richiesti dalle applicazioni di streaming a valle. Ciò contribuirà a evitare la replica della stessa logica di arricchimento in ogni applicazione e consentirà una migliore manutenzione operativa. Nella maggior parte dei casi, l'arricchimento dovrebbe mirare all'elaborazione per record.
- Applicazioni di streaming specifiche – Questo livello ospiterà applicazioni di streaming specifiche rispetto ai casi d'uso e utilizzerà i dati arricchiti dalla pipeline di arricchimento dei dati centrale.
Per l'arricchimento centrale dei dati, abbiamo apportato i seguenti miglioramenti alla piattaforma:
- La latenza totale, inclusa l'acquisizione e l'arricchimento dei dati, era estremamente critica e dovrebbe essere nell'intervallo di latenza di millisecondi a due cifre in base al budget di latenza complessivo di Poshmark per ottenere risposte ML in tempo reale agli eventi. La latenza di acquisizione più bassa in assoluto è stata raggiunta da Kafka e il team ha deciso di utilizzare la versione gestita di Kafka, Amazon MSK.
- Allo stesso modo, è richiesto anche un trattamento dei dati a bassa latenza e di conseguenza dovrebbe essere preso in considerazione un quadro appropriato.
- Per evitare la duplicazione dei dati con conseguenti calcoli errati, sono state richieste garanzie di consegna una tantum.
- L'origine di arricchimento potrebbe essere qualsiasi origine come file statici, database e API e le latenze possono variare tra di loro. Quando un utente interagisce con un'applicazione Poshmark, vengono generati numerosi eventi lato server e lato client. Di conseguenza, per arricchire ogni evento sono necessarie le stesse informazioni dalla fonte di arricchimento. Queste informazioni ad accesso frequente memorizzate nella cache in una cache centralizzata ottimizzeranno il tempo di recupero.
Decisioni progettuali per la nuova soluzione
Poshmark ha preso le seguenti decisioni di progettazione per l'arricchimento centrale dei dati:
- Kafka può supportare una latenza di millisecondi a due cifre dal produttore al consumatore con un'adeguata messa a punto delle prestazioni. Kafka può fornire la semantica esattamente una volta sia per i produttori che per le applicazioni dei consumatori. AWS fornisce Kafka come parte della sua offerta Amazon MSK, eliminando il sovraccarico operativo della manutenzione e dell'esecuzione dell'infrastruttura del cluster Kafka su AWS, consentendoti così di concentrarti sullo sviluppo e l'esecuzione di applicazioni basate su Kafka. Poshmark ha deciso di utilizzare Amazon MSK per i propri requisiti di archiviazione e acquisizione di streaming.
- Abbiamo anche deciso di utilizzare Flink per le applicazioni di arricchimento dei dati in streaming per i seguenti motivi:
- Flink può fornire un'elaborazione a bassa latenza anche con un throughput più elevato garanzie esattamente una volta. Spark Structured Streaming, d'altra parte, può fornire una bassa latenza con un throughput ridotto grazie all'elaborazione basata su microbatch. L'elaborazione continua di Spark Structured Streaming è una funzionalità sperimentale e fornisce almeno una volta garantisce.
- La chiamata delle richieste di arricchimento a un archivio esterno se modellata in una funzione mappa (l'API della mappa di Spark o l'API MapFunction di Flink) effettuerà chiamate sincrone all'archivio esterno. La chiamata attenderà una risposta dall'archivio esterno prima di elaborare l'evento successivo, aggiungendo ritardi e riducendo il throughput complessivo. L'interazione asincrona consentirà l'invio di richieste e la ricezione di risposte contemporaneamente da archivi esterni. Ciò ridurrà i tempi di attesa e migliorerà il throughput complessivo. Flink sostiene I/O asincrono operatori in modo nativo, consentendo agli utenti di utilizzare client di richiesta asincrona con flussi di dati. L'API gestisce l'integrazione con i flussi di dati, oltre a gestire l'ordine, l'ora dell'evento, la tolleranza agli errori e altro ancora. Spark Structured Streaming non fornisce tale supporto in modo nativo e lo lascia agli utenti per l'implementazione personalizzata.

- Poshmark ha scelto Kinesis Data Analytics per Apache Flink per eseguire l'applicazione di arricchimento dei dati. Kinesis Data Analytics per Apache Flink fornisce l'infrastruttura sottostante per le tue applicazioni Apache Flink. Gestisce funzionalità di base come il provisioning delle risorse di calcolo, il calcolo parallelo, ridimensionamento automaticoe backup delle applicazioni (implementati come checkpoint e snapshot).
- Un microservizio di arricchimento che accompagna Amazon ElastiCache per Redis è stato creato per astrarre l'accesso dalle applicazioni di arricchimento dei dati. AsyncFunction nell'operatore di I/O asincrono Flink non è multithread e non funzionerà in modo veramente asincrono se la chiamata è bloccata o in attesa di una risposta. Il microservizio di arricchimento gestisce le richieste e le risposte in modo asincrono provenienti dagli operatori di I/O asincroni di Flink. I dati vengono inoltre memorizzati nella cache in ElastiCache per Redis per migliorare la latenza del microservizio.
- Le applicazioni Poshmark ML sono i consumatori di questi dati arricchiti. Il team ha creato e implementato diversi modelli ML nel tempo. Questi modelli includono un algoritmo di apprendimento per classificare, rilevamento delle frodi, personalizzazione e consigli e filtraggio dello spam online. In precedenza, per implementare ciascun modello in produzione, il team di Poshmark doveva eseguire una serie di passaggi di configurazione dell'infrastruttura che prevedevano l'estrazione dei dati da fonti in tempo reale, la creazione di funzionalità di aggregazione in tempo reale dai dati in streaming, l'archiviazione di queste funzionalità in un ambiente a bassa latenza database (Redis) per inferenze inferiori al millisecondo e infine eseguire inferenze tramite Amazon Sage Maker endpoint ospitati.
- Abbiamo inoltre progettato una pipeline di archiviazione delle funzionalità ML che utilizza i dati dalle fonti di streaming arricchite (Kinesis o Kafka), genera funzionalità a livello singolo e a livello aggregato e inserisce queste funzionalità generate in un repository dell'archivio delle funzionalità con una latenza molto bassa inferiore a 80 millisecondi.
- I modelli ML sono ora in grado di estrarre le funzionalità necessarie con una latenza inferiore a 10 millisecondi dal repository delle funzionalità ed eseguire l'inferenza del modello in tempo reale.
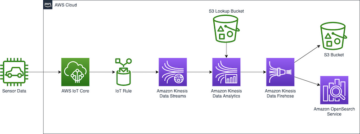
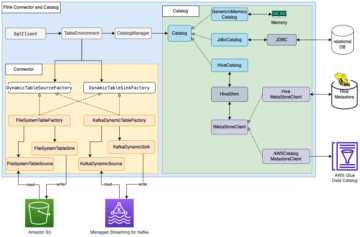
Architettura della soluzione di analisi in tempo reale
Il diagramma seguente illustra l'architettura della soluzione per l'analisi in tempo reale con Amazon MSK e Kinesis Data Analytics per Apache Flink.

Il flusso di lavoro è il seguente:
- Gli utenti interagiscono sull'applicazione web o mobile di Poshmark.
- Gli eventi lato server vengono acquisiti sui server applicazioni e gli eventi lato client vengono acquisiti sui server di tracciamento. Questi eventi vengono scritti nel cluster MSK downstream.
- Gli eventi non elaborati verranno inseriti nel cluster MSK utilizzando il plug-in Fluentd per produrre dati per Kafka.
- Il microservizio di arricchimento è costituito da API di ricerca dell'arricchimento reattive (asincrone) che recuperano i dati dagli archivi dati persistenti. ElastiCache per Redis memorizza nella cache i dati a cui si accede di frequente, riducendo i tempi di recupero per le API di ricerca di arricchimento.
- L'applicazione Flink in esecuzione su Kinesis Data Analytics per Apache Flink consuma eventi non elaborati da Amazon MSK ed esegue l'arricchimento dei dati in base al record. L'applicazione di arricchimento dei dati di Flink utilizza l'I/O asincrono di Flink per leggere i dati esterni dall'archivio di ricerca di arricchimento per arricchire gli eventi del flusso.
- Gli eventi arricchiti vengono scritti nel cluster MSK in diversi argomenti di eventi arricchiti.
- L'applicazione di streaming Spark esistente utilizza l'argomento degli eventi arricchiti (o l'argomento degli eventi non elaborati) in Amazon MSK e scrive i dati in un data lake S3.
- L'importazione di streaming Druid ora legge dall'argomento degli eventi arricchiti o dall'argomento degli eventi non elaborati in Amazon MSK a seconda dei requisiti.
Arricchimento dei dati dell'evento acquisito
In questa sezione vengono illustrati i diversi passaggi per arricchire i dati dell'evento acquisiti.
Elaborazione di arricchimento
Kinesis Data Analytics per Apache Flink fornisce l'infrastruttura sottostante per le applicazioni Apache Flink. Gestisce funzionalità di base come il provisioning delle risorse di calcolo, il calcolo parallelo, il ridimensionamento automatico e i backup delle applicazioni (implementati come checkpoint e snapshot). Puoi usare le funzionalità di programmazione di alto livello di Flink (come operatori, funzioni, sorgenti e sink) nello stesso modo in cui le usi quando ospiti tu stesso l'infrastruttura di Flink.
Flink su Amazon EMR offre la flessibilità di scegliere la versione, l'installazione, la configurazione, le istanze e lo storage di Flink. Tuttavia, devi anche occuparti della gestione del cluster e dei requisiti operativi come la scalabilità, il backup delle applicazioni e il provisioning.
Negozio di ricerca di arricchimento
AsyncFunction nell'operatore di I/O asincrono Flink non è multithread e non funzionerà in modo veramente asincrono se la chiamata è bloccata o in attesa di una risposta. L'API di ricerca dell'arricchimento dovrebbe gestire le richieste e le risposte in modo asincrono provenienti dagli operatori di I/O asincroni di Flink. L'API di ricerca dell'arricchimento può essere ospitata su Amazon EC2 o contenitori come Servizio di container elastici Amazon (Amazon ECS) o Servizio Amazon Elastic Kubernetes (Amazon EKS).
Quando un utente interagisce con un'applicazione Poshmark, vengono generati numerosi eventi lato server e lato client. Di conseguenza, le stesse informazioni sono necessarie per arricchire ogni evento. Queste informazioni ad accesso frequente memorizzate nella cache in una cache centralizzata possono ottimizzare i tempi di recupero. La latenza della cache centralizzata può essere ulteriormente ridotta ospitando il client (API di ricerca dell'arricchimento) e il server della cache nella stessa zona di disponibilità.
Riconciliazione in caso di errori della pipeline
L'arricchimento degli eventi può non riuscire nelle applicazioni di arricchimento dei dati per vari motivi, ad esempio il timeout dell'archivio esterno o le informazioni mancanti nell'archivio. I campi arricchiti possono o meno essere critici per le applicazioni di streaming a valle. Dovresti creare le tue applicazioni di streaming downstream considerando che questi errori possono verificarsi e implementare un meccanismo di fallback, ad esempio ritentando l'arricchimento su richiesta dall'applicazione. La gestione degli errori sarà regolata anche dalla tolleranza di latenza dell'applicazione.
Il trattamento dei dati è basato sul tempo dell'evento. In alcune situazioni, i dati possono arrivare in ritardo nella piattaforma. Sia Flink che Spark consentono agli utenti di ritardare e filigrane di gestire i dati in arrivo definendo soglie. I dati che arrivano in ritardo oltre la soglia vengono eliminati dall'elaborazione. È possibile ottenere questi dati scartati troppo tardi in Flink utilizzando un output laterale. Non esiste tale disposizione in Spark Structured Streaming.
Alcune applicazioni di streaming richiedono alla loro controparte batch di riconciliare i dati su base oraria o giornaliera per gestire la mancata corrispondenza dei dati o la discrepanza dei dati a causa di dati in arrivo in ritardo o dati mancanti.
customer experience migliorata
La nuova architettura in tempo reale ha offerto i seguenti vantaggi per una migliore esperienza del cliente:
- Anonimizzazione – Poshmark è ora in grado di fornire e utilizzare dati anonimi in tempo reale per molteplici funzioni sia interne che esterne perché l'anonimizzazione avviene in tempo reale.
- Attenuazione delle frodi – Poshmark era in precedenza in grado di rilevare e prevenire il 45% delle ATO con la soluzione basata su batch. Con il sistema in tempo reale, Poshmark è in grado di prevenire l'80% delle ATO.
- Personalizzazione – Fornendo risultati di ricerca personalizzati, Poshmark ha ottenuto un miglioramento dell'8% delle percentuali di clic per la ricerca. Questo è un aumento significativo nella parte superiore della canalizzazione, aumentando le conversioni di ricerca complessive.
Il miglioramento di questi tre fattori ha aiutato i clienti finali ad acquisire fiducia nell'app e nel sito Web Poshmark, che a loro volta hanno consentito ai clienti di aumentare la loro interazione con l'app e hanno contribuito ad accelerare il coinvolgimento e la crescita dei clienti.
Conclusione
In questo post, abbiamo discusso l'importazione di clickstream in tempo reale e i dati degli eventi di log in Amazon MSK. Abbiamo mostrato come l'arricchimento dei dati acquisiti può essere eseguito tramite Kinesis Data Analytics per Apache Flink. Abbiamo suddiviso l'elaborazione dell'arricchimento in più componenti, come Kinesis Data Analytics per Apache Flink, i microservizi di arricchimento e l'archivio di ricerca degli arricchimenti e una cache di arricchimento. Abbiamo discusso delle applicazioni a valle che hanno utilizzato queste informazioni sui clienti arricchite per eseguire controlli di sicurezza in tempo reale e offrire consigli personalizzati agli utenti finali. Abbiamo anche discusso alcune delle aree che potrebbero richiedere attenzione in caso di guasti nella pipeline. Infine, abbiamo mostrato come Poshmark ha migliorato la propria esperienza del cliente e guadagnato quote di mercato implementando questa pipeline di analisi in tempo reale.
Circa gli autori
 Mahesh Pasupuleti è vicepresidente di Data & Machine Learning Engineering presso Poshmark. Ha aiutato diverse startup ad avere successo in diversi domini, tra cui lo streaming multimediale, l'assistenza sanitaria, il settore finanziario e i mercati. Ama l'ingegneria del software, la creazione di squadre ad alte prestazioni e la strategia, e ama il giardinaggio e giocare a badminton nel tempo libero.
Mahesh Pasupuleti è vicepresidente di Data & Machine Learning Engineering presso Poshmark. Ha aiutato diverse startup ad avere successo in diversi domini, tra cui lo streaming multimediale, l'assistenza sanitaria, il settore finanziario e i mercati. Ama l'ingegneria del software, la creazione di squadre ad alte prestazioni e la strategia, e ama il giardinaggio e giocare a badminton nel tempo libero.
 Gaurav Shah è direttore dell'ingegneria dei dati e del machine learning presso Poshmark. Lui e il suo team aiutano a creare soluzioni basate sui dati per favorire la crescita di Poshmark.
Gaurav Shah è direttore dell'ingegneria dei dati e del machine learning presso Poshmark. Lui e il suo team aiutano a creare soluzioni basate sui dati per favorire la crescita di Poshmark.
 Raghu Mannam è Sr. Solutions Architect presso AWS a San Francisco. Lavora a stretto contatto con startup in fase avanzata, molte delle quali hanno avuto recenti IPO. Il suo focus è la soluzione end-to-end che include sicurezza, automazione DevOps, resilienza, analisi, apprendimento automatico e ottimizzazione del carico di lavoro nel cloud.
Raghu Mannam è Sr. Solutions Architect presso AWS a San Francisco. Lavora a stretto contatto con startup in fase avanzata, molte delle quali hanno avuto recenti IPO. Il suo focus è la soluzione end-to-end che include sicurezza, automazione DevOps, resilienza, analisi, apprendimento automatico e ottimizzazione del carico di lavoro nel cloud.
 Deepesh Malviya è Solutions Architect Manager nel team AWS Data Lab. Lui e il suo team aiutano i clienti a progettare e creare soluzioni di dati, analisi e machine learning per accelerare le loro iniziative chiave come parte di AWS Data Lab.
Deepesh Malviya è Solutions Architect Manager nel team AWS Data Lab. Lui e il suo team aiutano i clienti a progettare e creare soluzioni di dati, analisi e machine learning per accelerare le loro iniziative chiave come parte di AWS Data Lab.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/accelerating-revenue-growth-with-real-time-analytics-poshmarks-journey/
- :È
- $10 milioni
- $ SU
- 1
- 10
- 100
- a
- capace
- Assoluta
- ABSTRACT
- accelerare
- accelerata
- accelerando
- accesso
- accessibile
- Accedendo
- di conseguenza
- Il mio account
- Raggiungere
- raggiunto
- operanti in
- attività
- aggiuntivo
- indirizzo
- indirizzi
- algoritmo
- Consentire
- consente
- già
- Sebbene il
- Amazon
- Amazon EC2
- Amazon EMR
- tra
- analitica
- analizzare
- ed
- Apache
- api
- API
- App
- Applicazioni
- applicazioni
- approccio
- approcci
- opportuno
- architettura
- SONO
- aree
- in giro
- AS
- At
- attenzione
- gli attributi
- Australia
- autorizzazione
- Automatico
- Automazione
- disponibilità
- disponibile
- media
- taglia media
- evitare
- evitando
- AWS
- di riserva
- backup
- Bandire
- basato
- base
- BE
- perché
- prima
- vantaggi
- Meglio
- fra
- Al di là di
- Miliardo
- bloccato
- bots
- Rotto
- budget limitato.
- costruire
- Costruzione
- costruito
- affari
- Vantaggi per le aziende
- Acquisto
- by
- nascondiglio
- chiamata
- Bandi
- Materiale
- Canada
- funzionalità
- catturare
- cattura
- che
- Custodie
- casi
- lotta
- centrale
- centralizzata
- Challenge
- Procedi all'acquisto
- Controlli
- Scegli
- Città
- cliente
- clienti
- strettamente
- Cloud
- Cluster
- combinazioni
- combinando
- arrivo
- Uncommon
- comunemente
- comunità
- componenti
- calcolo
- Calcolare
- fiducia
- Configurazione
- veloce
- Svantaggi
- considerato
- considerando
- vincoli
- consumato
- Consumer
- Consumatori
- Contenitore
- Tecnologie Container
- continuo
- conversioni
- Nucleo
- potuto
- Controparte
- coprire
- creare
- critico
- Corrente
- Stato attuale
- Attualmente
- costume
- cliente
- Il coinvolgimento del cliente
- esperienza del cliente
- Clienti
- CX
- alle lezioni
- dati
- Dati Analytics
- arricchimento dei dati
- Lago di dati
- data-driven
- Banca Dati
- banche dati
- giorno
- decide
- deciso
- decisioni
- definizione
- ritardi
- consegna
- Dipendente
- schierato
- distribuzione
- Design
- progettato
- rivelazione
- in via di sviluppo
- DevOps
- differire
- diverso
- Direttore
- discrepanza
- discutere
- discusso
- distribuzione
- Diviso
- non
- domini
- guidare
- guida
- druido
- durante
- dinamico
- ogni
- ecommerce
- sforzi
- eliminando
- imbarcarsi
- enable
- abilitato
- che comprende
- da un capo all'altro
- Fidanzamento
- Ingegneria
- Ingegneri
- arricchire
- arricchito
- arricchendo
- entrare
- Etere (ETH)
- Anche
- Evento
- eventi
- esempio
- esistente
- Espandere
- esperienza
- ha spiegato
- estensione
- esterno
- esternamente
- estratto
- estrazione
- Fattori
- FAIL
- Fallimento
- Autunno
- Moda
- caratteristica
- Caratteristiche
- pochi
- campi
- File
- filtraggio
- Infine
- finanziario
- Settore finanziario
- Nome
- Flessibilità
- flusso
- Focus
- concentrato
- i seguenti
- segue
- Nel
- formato
- Contesto
- Francisco
- frode
- rilevazione di frodi
- Gratis
- frequentemente
- da
- function
- funzionale
- funzioni
- ulteriormente
- futuro
- Guadagno
- generare
- generato
- ottenere
- dà
- Go
- scopo
- Grammatica
- Crescere
- Crescita
- garanzie
- guida
- Metà
- cura
- maniglia
- Maniglie
- Manovrabilità
- accade
- Avere
- assistenza sanitaria
- Aiuto
- aiutato
- Alta
- alto livello
- superiore
- Casa
- ospitato
- di hosting
- ORE
- Casa
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- umano
- ID
- identificato
- identificare
- realizzare
- implementazione
- implementato
- Implementazione
- importante
- competenze
- migliorata
- miglioramento
- miglioramento
- in
- includere
- Compreso
- In arrivo
- Aumento
- crescente
- India
- industria
- informazioni
- Infrastruttura
- inizialmente
- iniziative
- intuizioni
- integrato
- Integra
- integrazione
- interagire
- interazione
- interazioni
- interagisce
- interno
- internamente
- Investire
- coinvolto
- IP
- Indirizzo IP
- Gli indirizzi IP
- IPO
- IT
- SUO
- giunto
- viaggio
- json
- kafka
- Le
- bambini
- Flussi di dati Kinesis
- conoscenze
- kubernetes
- laboratorio
- lago
- Cognome
- In ritardo
- Latenza
- strato
- galline ovaiole
- principale
- apprendimento
- Livello
- piace
- linea
- annuncio
- cerca
- ricerca
- Basso
- macchina
- machine learning
- fatto
- Principale
- mantiene
- manutenzione
- make
- FA
- gestito
- gestione
- direttore
- molti
- carta geografica
- Rappresentanza
- mercato
- mercati
- Mercati
- meccanismo
- Media
- Soddisfare
- Uomo
- microservices
- milione
- millisecondo
- mancante
- attenuazione
- ML
- Mobile
- Applicazioni mobili
- modello
- modelli
- modernizzazione
- Scopri di più
- maggior parte
- multiplo
- Bisogno
- di applicazione
- New
- GENERAZIONE
- numero
- of
- offrire
- offerto
- offerta
- Offerte
- on
- On-Demand
- ONE
- online
- operare
- operativa
- operatore
- Operatori
- Opportunità
- Opportunità
- ottimale
- ottimizzazione
- OTTIMIZZA
- minimo
- ordini
- organizzazione
- organizzazioni
- Altro
- Altri
- produzione
- complessivo
- pagina
- accoppiato
- Parallel
- parte
- passato
- Cartamodello
- Corrente di
- eseguire
- performance
- esecuzione
- personalizzazione
- Personalizzata
- Animali
- Fisico
- conduttura
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- plug-in
- punti
- possibile
- Post
- predire
- presenti
- prevenire
- precedente
- in precedenza
- i processi
- lavorazione
- produrre
- produttore
- Produttori
- Produzione
- Prodotti
- Programmazione
- PROS
- fornire
- fornisce
- fornitura
- fornitura
- casuale
- gamma
- Crudo
- Leggi
- di rose
- tempo reale
- motivi
- riceve
- ricevente
- recente
- raccomandazioni
- record
- ridurre
- Ridotto
- riducendo
- si riferisce
- registrato
- replicazione
- deposito
- richiesta
- richieste
- richiedere
- necessario
- Requisiti
- elasticità
- Risorse
- risposta
- colpevole
- risultante
- Risultati
- conservare
- Le vendite
- la crescita dei ricavi
- rivisto
- Correre
- running
- vendite
- stesso
- San
- San Francisco
- Scala
- scala
- Cerca
- Secondo
- Sezione
- settore
- problemi di
- selezionato
- prodotti
- Vendita
- semantica
- invio
- Serie
- Server
- Servizi
- sessioni
- set
- flessibile.
- alcuni
- Condividi
- Shopping
- dovrebbero
- vetrina
- Spettacoli
- significativa
- Allo stesso modo
- Un'espansione
- singolo
- situazioni
- Taglia
- Social
- Software
- Ingegneria del software
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- carne in scatola
- Scintilla
- specifico
- stakeholder
- Startup
- Regione / Stato
- Passi
- conservazione
- Tornare al suo account
- negozi
- Strategia
- ruscello
- Streaming
- flussi
- lottare
- strutturato
- avere successo
- di successo
- tale
- Super
- supporto
- supporti
- sostenibile
- un futuro sostenibile
- sistema
- su misura
- Fai
- team
- le squadre
- Consulenza
- integrazione tecnica
- che
- I
- il giunto
- loro
- Li
- in tal modo
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- tre
- soglia
- Attraverso
- portata
- tempo
- sincronizzazione
- a
- tolleranza
- top
- argomento
- Argomenti
- Totale
- pista
- Tracking
- traffico
- Le transazioni
- TURNO
- per
- sottostante
- capire
- us
- uso
- Utente
- utenti
- utilizzare
- utilizzati
- APPREZZIAMO
- vario
- versione
- via
- Visualizza
- aspettare
- In attesa
- ricercato
- Modo..
- sito web
- Sito web
- WELL
- noto
- quale
- volere
- con
- entro
- Donna
- Lavora
- lavorato
- flusso di lavoro
- lavori
- scrivere
- scritto
- Wrong
- Trasferimento da aeroporto a Sharm
- te stesso
- zefiro
- Codice postale