Decine di migliaia di clienti AWS utilizzano i servizi di machine learning (ML) di AWS per accelerare il loro sviluppo ML con strumenti e infrastrutture completamente gestiti. Per i clienti che hanno sviluppato modelli ML on-premise, come il loro desktop locale, vogliono migrare i loro modelli ML legacy nel cloud AWS per sfruttare appieno il set più completo di servizi ML, infrastruttura e risorse di implementazione disponibili su AWS .
Il termine codice legacy si riferisce al codice che è stato sviluppato per essere eseguito manualmente su un desktop locale e non è stato creato con SDK pronti per il cloud come il SDK AWS per Python (Boto3) or SDK Python di Amazon SageMaker. In altre parole, questi codici legacy non sono ottimizzati per la distribuzione nel cloud. La procedura consigliata per la migrazione consiste nel refactoring di questi codici legacy utilizzando il API Amazon SageMaker o SageMaker Python SDK. Tuttavia, in alcuni casi, le organizzazioni con un gran numero di modelli legacy potrebbero non avere il tempo o le risorse per riscrivere tutti quei modelli.
In questo post, condividiamo un approccio scalabile e facile da implementare per migrare il codice ML legacy nel cloud AWS per l'inferenza utilizzando Amazon Sage Maker ed Funzioni AWS Step, con una quantità minima di refactoring del codice richiesta. Puoi facilmente estendere questa soluzione per aggiungere più funzionalità. Dimostriamo come due persone diverse, un data scientist e un ingegnere MLOps, possono collaborare per sollevare e spostare centinaia di modelli legacy.
Panoramica della soluzione
In questo framework, eseguiamo il codice legacy in un contenitore come a Elaborazione di SageMaker lavoro. SageMaker esegue lo script legacy all'interno di un contenitore di elaborazione. L'immagine del contenitore di elaborazione può essere un'immagine integrata di SageMaker o un'immagine personalizzata. L'infrastruttura sottostante per un lavoro di elaborazione è completamente gestita da SageMaker. Non è richiesta alcuna modifica al codice legacy. La familiarità con la creazione di lavori di SageMaker Processing è tutto ciò che serve.
Assumiamo il coinvolgimento di due personaggi: un data scientist e un ingegnere MLOps. Il data scientist è responsabile dello spostamento del codice in SageMaker, manualmente o clonandolo da un repository di codice come AWS CodeCommit. Amazon Sage Maker Studio fornisce un ambiente di sviluppo integrato (IDE) per l'implementazione di vari passaggi nel ciclo di vita ML e il data scientist lo utilizza per creare manualmente un contenitore personalizzato che contenga gli artefatti di codice necessari per la distribuzione. Il contenitore verrà registrato in un registro contenitori come Registro dei contenitori Amazon Elastic (Amazon ECR) per scopi di distribuzione.
L'ingegnere MLOps si assume la responsabilità di creare un flusso di lavoro Step Functions che possiamo riutilizzare per distribuire il contenitore personalizzato sviluppato dal data scientist con i parametri appropriati. Il flusso di lavoro di Step Functions può essere modulare quanto necessario per adattarsi al caso d'uso oppure può consistere in un solo passaggio per avviare un singolo processo. Per ridurre al minimo lo sforzo richiesto per migrare il codice, abbiamo identificato tre componenti modulari per creare un processo di distribuzione completamente funzionale:
- Pre-elaborazione
- Inferenza
- Post produzione
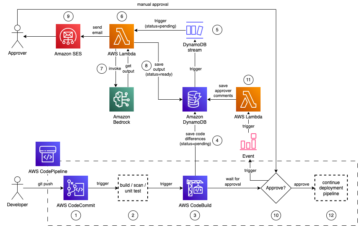
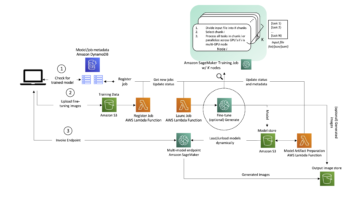
Il seguente diagramma illustra l'architettura e il flusso di lavoro della nostra soluzione.
I seguenti passaggi sono coinvolti in questa soluzione:
- Il personaggio di data scientist utilizza Studio per importare il codice legacy tramite la clonazione da un repository di codice e quindi modulare il codice in componenti separati che seguono le fasi del ciclo di vita ML (pre-elaborazione, inferenza e post-elaborazione).
- Il data scientist utilizza Studio, e in particolare il CLI di Studio per la creazione di immagini strumento fornito da SageMaker, per creare un'immagine Docker. Questo strumento CLI consente al data scientist di creare l'immagine direttamente all'interno di Studio e di registrare automaticamente l'immagine in Amazon ECR.
- L'ingegnere MLOps utilizza l'immagine del contenitore registrata e crea una distribuzione per un caso d'uso specifico utilizzando Step Functions. Step Functions è un servizio di flusso di lavoro serverless in grado di controllare le API di SageMaker direttamente tramite l'uso di Amazon States Language.
Lavoro di elaborazione di SageMaker
Capiamo come a Lavoro di elaborazione di SageMaker corre. Il seguente diagramma mostra come SageMaker avvia un processo di elaborazione.

SageMaker prende il tuo script, copia i tuoi dati da Servizio di archiviazione semplice Amazon (Amazon S3), quindi estrae un contenitore di elaborazione. L'immagine del contenitore di elaborazione può essere un'immagine integrata di SageMaker o un'immagine personalizzata da te fornita. L'infrastruttura sottostante per un lavoro di elaborazione è completamente gestita da SageMaker. Le risorse del cluster vengono fornite per la durata del processo e ripulite al termine del processo. L'output del processo di elaborazione viene archiviato nel bucket S3 specificato. Per ulteriori informazioni sulla creazione del proprio contenitore, fare riferimento a Crea il tuo contenitore di elaborazione (scenario avanzato).
Il processo SageMaker Processing configura l'immagine di elaborazione utilizzando uno script del punto di ingresso del contenitore Docker. Puoi anche fornire il tuo punto di ingresso personalizzato utilizzando i parametri ContainerEntrypoint e ContainerArguments di Specifiche dell'app API. Se utilizzi il tuo punto di ingresso personalizzato, hai la flessibilità aggiuntiva di eseguirlo come script autonomo senza ricostruire le tue immagini.
Per questo esempio, costruiamo un contenitore personalizzato e utilizziamo un processo di elaborazione SageMaker per l'inferenza. I lavori di pre-elaborazione e post-elaborazione utilizzano la modalità script con un contenitore scikit-learn predefinito.
Prerequisiti
Per seguire questo post, completare i seguenti passaggi preliminari:
- Crea un dominio Studio. Per le istruzioni, fare riferimento a Integrazione nel dominio Amazon SageMaker utilizzando la configurazione rapida.
- Crea un bucket S3.
- Clonare il fornito Repository GitHub in Studio.
Il repository GitHub è organizzato in diverse cartelle che corrispondono a varie fasi del ciclo di vita ML, facilitando la facile navigazione e gestione:

Migrare il codice legacy
In questa fase, agiamo come data scientist responsabile della migrazione del codice legacy.
Iniziamo aprendo il build_and_push.ipynb taccuino.
La cella iniziale nel notebook ti guida nell'installazione del file CLI di Studio per la creazione di immagini. Questa CLI semplifica il processo di installazione creando automaticamente un ambiente di compilazione riutilizzabile con cui puoi interagire tramite comandi di alto livello. Con l'interfaccia a riga di comando, creare un'immagine è facile come dirle di crearla e il risultato sarà un collegamento alla posizione dell'immagine in Amazon ECR. Questo approccio elimina la necessità di gestire il complesso flusso di lavoro sottostante orchestrato dalla CLI, semplificando il processo di creazione dell'immagine.
Prima di eseguire il comando build, è importante assicurarsi che il ruolo che esegue il comando disponga delle autorizzazioni necessarie, come specificato nella CLI GitHub leggimi o post correlato. La mancata concessione delle autorizzazioni necessarie può causare errori durante il processo di compilazione.
Vedi il seguente codice:
Per semplificare il tuo codice legacy, dividilo in tre distinti script Python denominati preprocessing.py, predict.py e postprocessing.py. Aderisci alle migliori pratiche di programmazione convertendo il codice in funzioni chiamate da una funzione principale. Assicurarsi che tutte le librerie necessarie siano importate e che il file requirements.txt sia aggiornato per includere eventuali librerie personalizzate.
Dopo aver organizzato il codice, impacchettalo insieme al file dei requisiti in un contenitore Docker. Puoi creare facilmente il contenitore dall'interno di Studio utilizzando il seguente comando:
Per impostazione predefinita, l'immagine verrà inviata a un repository ECR chiamato sagemakerstudio con il tag latest. Inoltre, verrà utilizzato il ruolo di esecuzione dell'app Studio, insieme al bucket SageMaker Python SDK S3 predefinito. Tuttavia, queste impostazioni possono essere facilmente modificate utilizzando le opzioni CLI appropriate. Vedere il seguente codice:
Ora che il contenitore è stato creato e registrato in un repository ECR, è il momento di approfondire il modo in cui possiamo usarlo per eseguire predict.py. Ti mostriamo anche il processo di utilizzo di un file predefinito scikit-impara container per eseguire preprocessing.py e postprocessing.py.
Produci il contenitore
In questa fase, agiamo come ingegnere MLOps che produce il contenitore creato nella fase precedente.
Utilizziamo Step Functions per orchestrare il flusso di lavoro. Step Functions consente un'eccezionale flessibilità nell'integrare una vasta gamma di servizi nel flusso di lavoro, adattandosi a eventuali dipendenze esistenti che possono esistere nel sistema legacy. Questo approccio garantisce che tutti i componenti necessari siano perfettamente integrati ed eseguiti nella sequenza desiderata, risultando in una soluzione di flusso di lavoro efficiente ed efficace.
Step Functions può controllare determinati servizi AWS direttamente da Amazon States Language. Per ulteriori informazioni sull'utilizzo di Step Functions e sulla sua integrazione con SageMaker, fare riferimento a Gestisci SageMaker con Step Functions. Utilizzando la funzionalità di integrazione di Step Functions con SageMaker, eseguiamo gli script di pre-elaborazione e post-elaborazione utilizzando un processo di elaborazione SageMaker in modalità script ed eseguiamo l'inferenza come processo di elaborazione SageMaker utilizzando un contenitore personalizzato. Lo facciamo utilizzando SDK AWS per Python (Boto3) CreaProcessingJob Chiamate API.
Pre-elaborazione
SageMaker offre diverse opzioni per l'esecuzione di codice personalizzato. Se hai solo uno script senza dipendenze personalizzate, puoi eseguire lo script come Bring Your Own Script (BYOS). Per fare ciò, passa semplicemente il tuo script al contenitore del framework scikit-learn predefinito ed esegui un processo di elaborazione SageMaker in modalità script utilizzando i parametri ContainerArguments e ContainerEntrypoint nel Specifiche dell'app API. Questo è un metodo diretto e conveniente per eseguire semplici script.
Controlla la configurazione dello stato "Preprocessing Script Mode" nel file esempio di flusso di lavoro Step Functions per capire come configurare la chiamata API CreateProcessingJob per eseguire uno script personalizzato.
Inferenza
Puoi eseguire un contenitore personalizzato utilizzando il file Costruisci il tuo contenitore di elaborazione approccio. Il lavoro SageMaker Processing funziona con il file /opt/ml local path e puoi specificare i tuoi ProcessingInputs e il loro percorso locale nella configurazione. Il processo di elaborazione copia quindi gli artefatti nel contenitore locale e avvia il processo. Al termine del processo, copia gli artefatti specificati nel percorso locale di ProcessingOutputs nella posizione esterna specificata.
Controlla la configurazione dello stato "Contenitore personalizzato di inferenza" nel file esempio di flusso di lavoro Step Functions per capire come configurare la chiamata API CreateProcessingJob per eseguire un contenitore personalizzato.
Post produzione
Puoi eseguire uno script di post-elaborazione proprio come uno script di pre-elaborazione utilizzando il passaggio CreateProcessingJob di Step Functions. L'esecuzione di uno script di post-elaborazione consente di eseguire attività di elaborazione personalizzate dopo il completamento del processo di inferenza.
Crea il flusso di lavoro Step Functions
Per la prototipazione rapida, utilizziamo le Step Functions Lingua degli Stati dell'Amazzonia. È possibile modificare direttamente la definizione di Step Functions utilizzando la lingua degli stati. Fare riferimento al esempio di flusso di lavoro Step Functions.
È possibile creare una nuova macchina a stati Step Functions nella console Step Functions selezionando Scrivi il tuo flusso di lavoro nel codice.

Step Functions può esaminare le risorse che utilizzi e creare un ruolo. Tuttavia, potresti visualizzare il seguente messaggio:
“Step Functions non può generare una policy IAM se RoleArn per SageMaker proviene da un percorso. Hardcode SageMaker RoleArn nella definizione della tua macchina a stati o scegli un ruolo esistente con le autorizzazioni appropriate per Step Functions per chiamare SageMaker.
Per risolvere questo problema, è necessario creare un file Gestione dell'identità e dell'accesso di AWS (IAM) per Step Functions. Per le istruzioni, fare riferimento a Creazione di un ruolo IAM per la tua macchina a stati. Quindi collega la seguente policy IAM per fornire le autorizzazioni necessarie per l'esecuzione del flusso di lavoro:
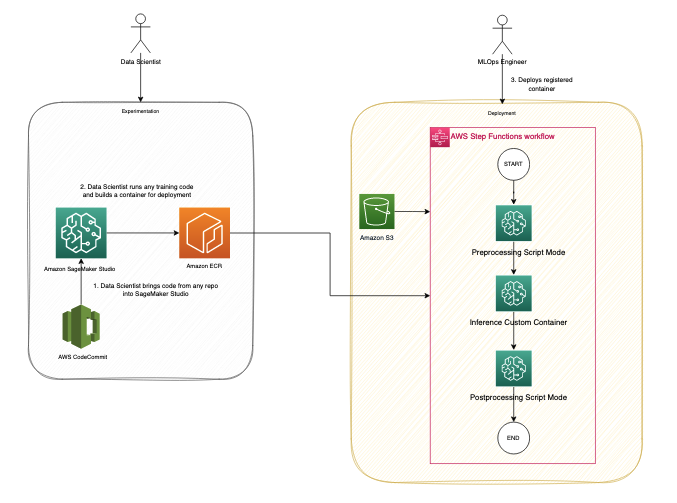
La figura seguente illustra il flusso di dati e immagini del contenitore in ogni fase del flusso di lavoro di Step Functions.

Di seguito è riportato un elenco dei parametri minimi richiesti per l'inizializzazione in Step Functions; puoi anche fare riferimento al parametri di input di esempio JSON:
- input_uri – L'URI S3 per i file di input
- output_uri – L'URI S3 per i file di output
- codice_uri – L'URI S3 per i file di script
- custom_immagine_uri – L'URI del contenitore per il contenitore personalizzato creato
- scikit_image_uri – L'URI del contenitore per il framework scikit-learn predefinito
- ruolo – Il ruolo di esecuzione per eseguire il processo
- tipo_istanza – Il tipo di istanza che devi utilizzare per eseguire il contenitore
- dimensione_volume – La dimensione del volume di archiviazione richiesta per il contenitore
- max_runtime – Il tempo di esecuzione massimo per il contenitore, con un valore predefinito di 1 ora
Esegui il flusso di lavoro
Abbiamo suddiviso il codice legacy in parti gestibili: pre-elaborazione, inferenza e post-elaborazione. Per supportare le nostre esigenze di inferenza, abbiamo creato un contenitore personalizzato dotato delle dipendenze di libreria necessarie. Il nostro piano è utilizzare Step Functions, sfruttando la sua capacità di chiamare l'API SageMaker. Abbiamo mostrato due metodi per l'esecuzione di codice personalizzato utilizzando l'API SageMaker: un processo di elaborazione SageMaker che utilizza un'immagine predefinita e prende uno script personalizzato in fase di esecuzione e un processo di elaborazione SageMaker che utilizza un contenitore personalizzato, che viene fornito con il necessario artefatti per eseguire l'inferenza personalizzata.
La figura seguente mostra l'esecuzione del flusso di lavoro Step Functions.

Sommario
In questo post, abbiamo discusso il processo di migrazione del codice Python ML legacy dagli ambienti di sviluppo locali e l'implementazione di una procedura MLOps standardizzata. Con questo approccio, puoi trasferire facilmente centinaia di modelli e incorporare le pratiche di distribuzione aziendale desiderate. Abbiamo presentato due diversi metodi per eseguire codice personalizzato su SageMaker e puoi selezionare quello più adatto alle tue esigenze.
Se hai bisogno di una soluzione altamente personalizzabile, ti consigliamo di utilizzare l'approccio del contenitore personalizzato. Potresti trovare più adatto l'uso di immagini predefinite per eseguire il tuo script personalizzato se disponi di script di base e non hai bisogno di creare il tuo contenitore personalizzato, come descritto nella fase di pre-elaborazione menzionata in precedenza. Inoltre, se necessario, puoi applicare questa soluzione per containerizzare i passaggi di addestramento e valutazione del modello legacy, proprio come il passaggio di inferenza è containerizzato in questo post.
Informazioni sugli autori
 Bhavana Chirumamilla è un Senior Resident Architect presso AWS con una forte passione per i dati e le operazioni di machine learning. Porta una vasta esperienza ed entusiasmo per aiutare le aziende a costruire dati efficaci e strategie di ML. Nel suo tempo libero, Bhavana ama passare il tempo con la sua famiglia e dedicarsi a varie attività come viaggiare, fare escursioni, fare giardinaggio e guardare documentari.
Bhavana Chirumamilla è un Senior Resident Architect presso AWS con una forte passione per i dati e le operazioni di machine learning. Porta una vasta esperienza ed entusiasmo per aiutare le aziende a costruire dati efficaci e strategie di ML. Nel suo tempo libero, Bhavana ama passare il tempo con la sua famiglia e dedicarsi a varie attività come viaggiare, fare escursioni, fare giardinaggio e guardare documentari.
 Shyam Namavaram è un architetto senior di soluzioni specializzate in intelligenza artificiale (AI) e machine learning (ML) presso Amazon Web Services (AWS). Lavora con passione con i clienti per accelerare la loro adozione di IA e ML fornendo indicazioni tecniche e aiutandoli a innovare e creare soluzioni cloud sicure su AWS. È specializzato in AI e ML, container e tecnologie di analisi. Al di fuori del lavoro ama fare sport e vivere la natura con il trekking.
Shyam Namavaram è un architetto senior di soluzioni specializzate in intelligenza artificiale (AI) e machine learning (ML) presso Amazon Web Services (AWS). Lavora con passione con i clienti per accelerare la loro adozione di IA e ML fornendo indicazioni tecniche e aiutandoli a innovare e creare soluzioni cloud sicure su AWS. È specializzato in AI e ML, container e tecnologie di analisi. Al di fuori del lavoro ama fare sport e vivere la natura con il trekking.
 QingweiLi è uno specialista in machine learning presso Amazon Web Services. Ha conseguito il dottorato in ricerca operativa dopo aver rotto il conto dell'assegno di ricerca del suo consulente e non è riuscito a consegnare il premio Nobel che aveva promesso. Attualmente, aiuta i clienti nel settore dei servizi finanziari e assicurativi a creare soluzioni di machine learning su AWS. Nel tempo libero gli piace leggere e insegnare.
QingweiLi è uno specialista in machine learning presso Amazon Web Services. Ha conseguito il dottorato in ricerca operativa dopo aver rotto il conto dell'assegno di ricerca del suo consulente e non è riuscito a consegnare il premio Nobel che aveva promesso. Attualmente, aiuta i clienti nel settore dei servizi finanziari e assicurativi a creare soluzioni di machine learning su AWS. Nel tempo libero gli piace leggere e insegnare.
 Srivasa Shaik è un Solutions Architect presso AWS con sede a Boston. Aiuta i clienti aziendali ad accelerare il loro viaggio verso il cloud. È appassionato di container e tecnologie di machine learning. Nel tempo libero ama passare il tempo con la sua famiglia, cucinare e viaggiare.
Srivasa Shaik è un Solutions Architect presso AWS con sede a Boston. Aiuta i clienti aziendali ad accelerare il loro viaggio verso il cloud. È appassionato di container e tecnologie di machine learning. Nel tempo libero ama passare il tempo con la sua famiglia, cucinare e viaggiare.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/bring-legacy-machine-learning-code-into-amazon-sagemaker-using-aws-step-functions/
- :È
- $ SU
- 1
- 10
- 100
- 214
- 8
- a
- capacità
- Chi siamo
- accelerare
- accesso
- Il mio account
- Legge
- Action
- attività
- aggiunto
- Inoltre
- indirizzo
- aderire
- Adozione
- Avanzate
- Vantaggio
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- Tutti
- consente
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- Amazon Web Services (AWS)
- quantità
- analitica
- ed
- api
- API
- App
- APPLICA
- approccio
- opportuno
- architettura
- SONO
- artificiale
- intelligenza artificiale
- Intelligenza artificiale (AI)
- AS
- At
- allegare
- automaticamente
- disponibile
- AWS
- Apprendimento automatico di AWS
- Funzioni AWS Step
- basato
- basic
- BE
- iniziare
- MIGLIORE
- Boston
- portare
- Porta
- Rotto
- Rotto
- costruire
- Costruzione
- costruito
- incassato
- by
- chiamata
- detto
- Bandi
- Materiale
- non può
- Custodie
- casi
- certo
- il cambiamento
- Scegli
- cliente
- Cloud
- Cluster
- codice
- Codici
- collaboreranno
- COM
- completamento di una
- complesso
- componenti
- globale
- condizione
- Configurazione
- consolle
- costruire
- Contenitore
- Tecnologie Container
- contiene
- di controllo
- Comodo
- cucina
- creare
- crea
- Creazione
- Attualmente
- costume
- Clienti
- personalizzabile
- dati
- scienziato di dati
- più profondo
- Predefinito
- consegnare
- dimostrare
- schierare
- deployment
- descritta
- tavolo
- sviluppato
- in via di sviluppo
- Mercato
- diverso
- direttamente
- discusso
- distinto
- paesaggio differenziato
- docker
- Contenitore Docker
- documentari
- dominio
- Dont
- giù
- durante
- ogni
- In precedenza
- facilmente
- facile
- effetto
- Efficace
- efficiente
- sforzo
- o
- elimina
- impegnandosi
- ingegnere
- garantire
- assicura
- Impresa
- clienti aziendali
- aziende
- entusiasmo
- Ambiente
- ambienti
- attrezzato
- errori
- Etere (ETH)
- valutazione
- esempio
- eccezionale
- esecuzione
- esistente
- esperienza
- sperimentare
- estendere
- esterno
- facilitando
- fallito
- Familiarità
- famiglia
- figura
- Compila il
- finanziario
- servizio finanziario
- Trovare
- in forma
- Flessibilità
- flusso
- seguire
- i seguenti
- Nel
- Contesto
- da
- completamente
- function
- funzionale
- funzionalità
- funzioni
- Inoltre
- generare
- GitHub
- concedere
- guida
- Guide
- Avere
- Aiuto
- aiutare
- aiuta
- alto livello
- vivamente
- escursionismo
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- centinaia
- IAM
- identificato
- Identità
- Immagine
- immagini
- implementazione
- Implementazione
- importare
- importante
- in
- In altre
- includere
- incorporare
- industria
- Infrastruttura
- inizialmente
- avviare
- innovare
- ingresso
- install
- installazione
- esempio
- istruzioni
- assicurazione
- settore assicurativo
- integrato
- Integrazione
- integrazione
- Intelligence
- interagire
- coinvolto
- coinvolgimento
- IT
- SUO
- Lavoro
- Offerte di lavoro
- viaggio
- jpg
- json
- solo uno
- Lingua
- grandi
- con i più recenti
- IMPARARE
- apprendimento
- Eredità
- biblioteche
- Biblioteca
- ciclo di vita
- piace
- LINK
- Lista
- locale
- località
- Guarda
- macchina
- machine learning
- Principale
- gestire
- gestito
- gestione
- manualmente
- massimo
- menzionato
- messaggio
- metodo
- metodi
- migrare
- migrazione
- ridurre al minimo
- ordine
- ML
- MLOp
- Moda
- modello
- modelli
- componibile
- Scopri di più
- maggior parte
- in movimento
- Detto
- Natura
- Navigazione
- necessaria
- Bisogno
- di applicazione
- esigenze
- New
- premio Nobel
- taccuino
- numero
- of
- Offerte
- on
- ONE
- apertura
- opera
- Operazioni
- ottimizzati
- Opzioni
- orchestrato
- organizzazioni
- Organizzato
- Altro
- produzione
- al di fuori
- proprio
- proprietà
- pacchetto
- parametri
- Ricambi
- passione
- appassionato
- sentiero
- eseguire
- permessi
- piano
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- politica
- Post
- pratica
- pratiche
- predire
- presentata
- precedente
- premio
- processi
- lavorazione
- Programmazione
- promesso
- corretto
- prototipazione
- fornire
- purché
- fornisce
- fornitura
- Maglioni
- fini
- spinto
- Python
- Presto
- rapidamente
- gamma
- Lettura
- ricevuto
- raccomandato
- Refactoring
- si riferisce
- registrato
- registri
- registro
- deposito
- richiedere
- necessario
- Requisiti
- riparazioni
- risorsa
- Risorse
- responsabile
- colpevole
- risultante
- riutilizzabile
- Ruolo
- Correre
- running
- sagemaker
- scalabile
- scenario
- Scienziato
- scikit-impara
- script
- sdk
- senza soluzione di continuità
- sicuro
- Selezione
- anziano
- separato
- Sequenza
- serverless
- servizio
- Servizi
- set
- Set
- impostazioni
- flessibile.
- alcuni
- Condividi
- spostamento
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- Un'espansione
- semplicemente
- singolo
- Taglia
- So
- soluzione
- Soluzioni
- alcuni
- specialista
- specializzata
- specifico
- in particolare
- specificato
- Spendere
- giri
- Sports
- tappe
- standalone
- inizio
- Regione / Stato
- dichiarazione
- stati
- step
- Passi
- conservazione
- memorizzati
- lineare
- strategie
- snellire
- razionalizzazione
- forte
- studio
- tale
- adatto
- abiti
- supporto
- sistema
- TAG
- Fai
- prende
- presa
- task
- Insegnamento
- Consulenza
- Tecnologie
- che
- I
- loro
- Li
- Strumenti Bowman per analizzare le seguenti finiture:
- migliaia
- tre
- Attraverso
- tempo
- a
- strumenti
- Training
- trasferimento
- Di viaggio
- sottostante
- capire
- aggiornato
- URI
- uso
- caso d'uso
- utilità
- utilizzare
- utilizzati
- utilizza
- APPREZZIAMO
- vario
- versione
- volume
- guardare
- Ricchezza
- sito web
- servizi web
- quale
- OMS
- volere
- con
- entro
- senza
- parole
- Lavora
- flusso di lavoro
- lavoro
- lavori
- Trasferimento da aeroporto a Sharm
- zefiro