Questo post è stato scritto insieme a Babu Srinivasan e Robert Walters di MongoDB.
Streaming gestito da Amazon per Apache Kafka (Amazon MSK) è un servizio Apache Kafka completamente gestito e altamente disponibile. Amazon MSK semplifica l'acquisizione e l'elaborazione di flussi di dati in tempo reale e l'utilizzo semplice di tali dati all'interno dell'ecosistema AWS. Insieme a Amazon MSK senza server, puoi eseguire automaticamente il provisioning e gestire le risorse necessarie per fornire capacità di streaming on demand e storage per le tue applicazioni.
Amazon MSK supporta anche l'integrazione di origini dati come MongoDB Atlas tramite Amazon MSK Connect. MSK Connect consente l'integrazione serverless dei dati MongoDB con Amazon MSK utilizzando il Connettore MongoDB per Apache Kafka.
MongoDB Atlas senza server fornisce servizi di database che aumentano e diminuiscono dinamicamente in base alle dimensioni e alla velocità effettiva dei dati e il costo aumenta di conseguenza. È più adatto per applicazioni con esigenze variabili da gestire con una configurazione minima. Fornisce prestazioni e affidabilità elevate con funzionalità di aggiornamento automatico, crittografia, sicurezza, metriche e backup integrate nell'infrastruttura MongoDB Atlas.
MSK Serverless è un tipo di cluster per Amazon MSK. Proprio come MongoDB Atlas Serverless, MSK Serverless esegue automaticamente il provisioning e il ridimensionamento delle risorse di elaborazione e storage. Ora puoi creare flussi di lavoro serverless end-to-end. Puoi creare una pipeline di streaming serverless con acquisizione serverless utilizzando MSK Serverless e archiviazione serverless utilizzando MongoDB Atlas. Inoltre, MSK Connect ora supporta nomi host DNS privati. Ciò consente alle istanze Serverless MSK di connettersi ai cluster Serverless MongoDB tramite Collegamento privato AWS, fornendoti una connettività sicura tra le piattaforme.
Se sei interessato a utilizzare un cluster non serverless, fai riferimento a Integrazione di MongoDB con Amazon Managed Streaming per Apache Kafka (MSK).
Questo post mostra come implementare una pipeline di streaming serverless con MSK Serverless, MSK Connect e MongoDB Atlas.
Panoramica della soluzione
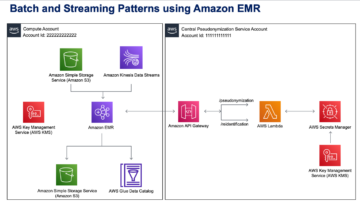
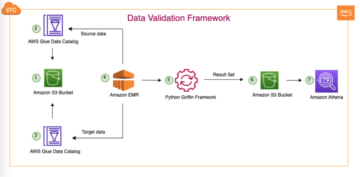
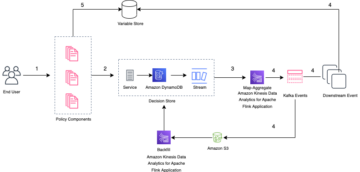
Il diagramma seguente illustra l'architettura della nostra soluzione.
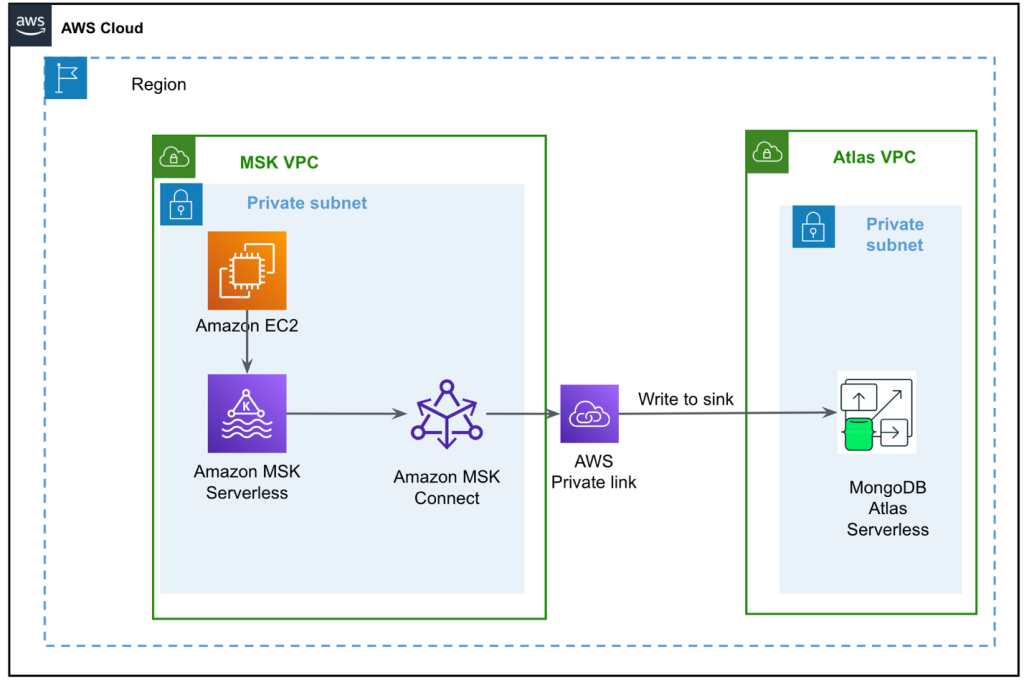
Il flusso di dati inizia con un Cloud di calcolo elastico di Amazon (Amazon EC2) istanza client che scrive record in un argomento MSK. Quando i dati arrivano, un'istanza del connettore MongoDB per Apache Kafka scrive i dati in una raccolta nel cluster MongoDB Atlas Serverless. Per una connettività sicura tra le due piattaforme, viene creata una connessione AWS PrivateLink tra il cluster MongoDB Atlas e il VPC contenente l'istanza MSK.
Questo post ti guida attraverso i seguenti passaggi:
- Crea il cluster MSK senza server.
- Crea il cluster MongoDB Atlas Serverless.
- Configura il plug-in MSK.
- Crea il client EC2.
- Configura un argomento MSK.
- Configura il connettore MongoDB per Apache Kafka come sink.
Configura il cluster MSK senza server
Per creare un cluster MSK serverless, completare i seguenti passaggi:
- Sulla console Amazon MSK, scegli Cluster nel pannello di navigazione.
- Scegli Crea cluster.
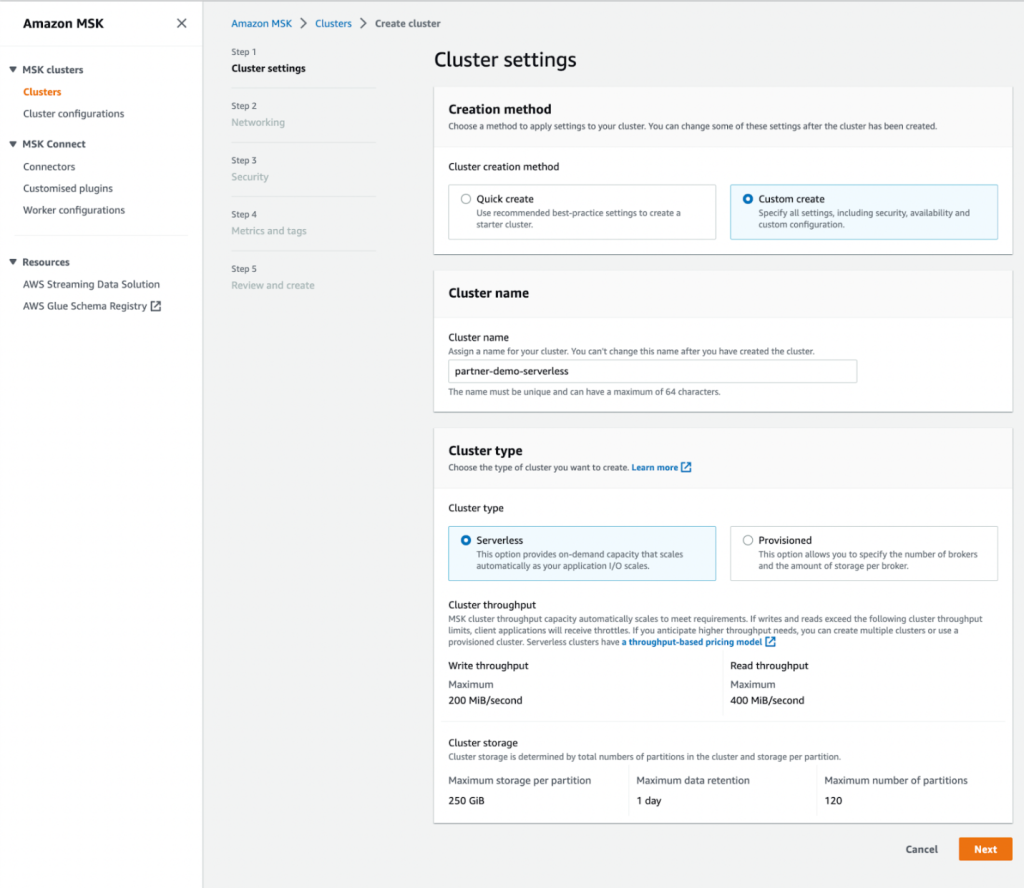
- Nel Metodo di creazione, selezionare Creazione personalizzata.
- Nel Nome del cluster, accedere
MongoDBMSKCluster. - Nel Tipo di grappoloSelezionare serverless.
- Scegli Avanti.
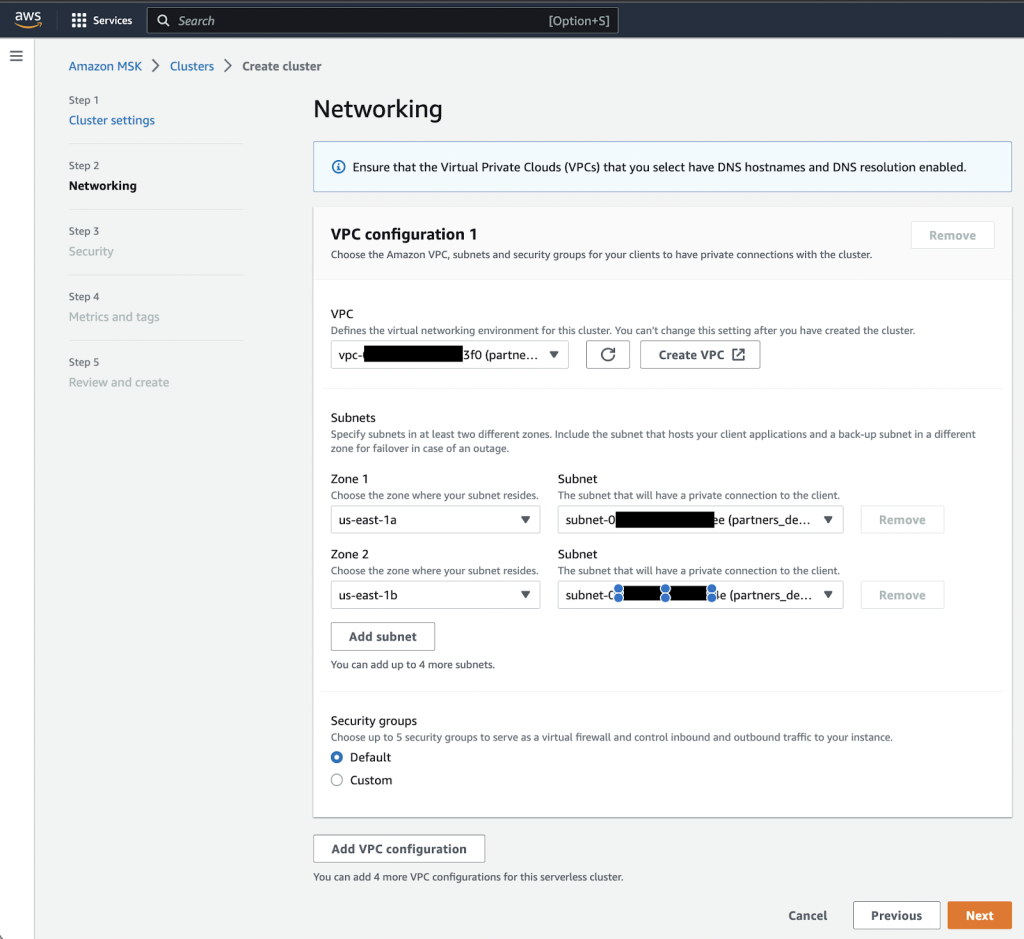
- Sulla Networking pagina, specifica il VPC, le zone di disponibilità e le sottoreti corrispondenti.
- Prendi nota delle zone di disponibilità e delle sottoreti da utilizzare in seguito.
- Scegli Avanti.
- Scegli Crea cluster.
Quando il cluster è disponibile, il suo stato diventa Active.

Crea il cluster MongoDB Atlas Serverless
Per creare un cluster MongoDB Atlas, segui il file Iniziare con Atlas tutorial. Si noti che per gli scopi di questo post, è necessario creare un'istanza senza server.
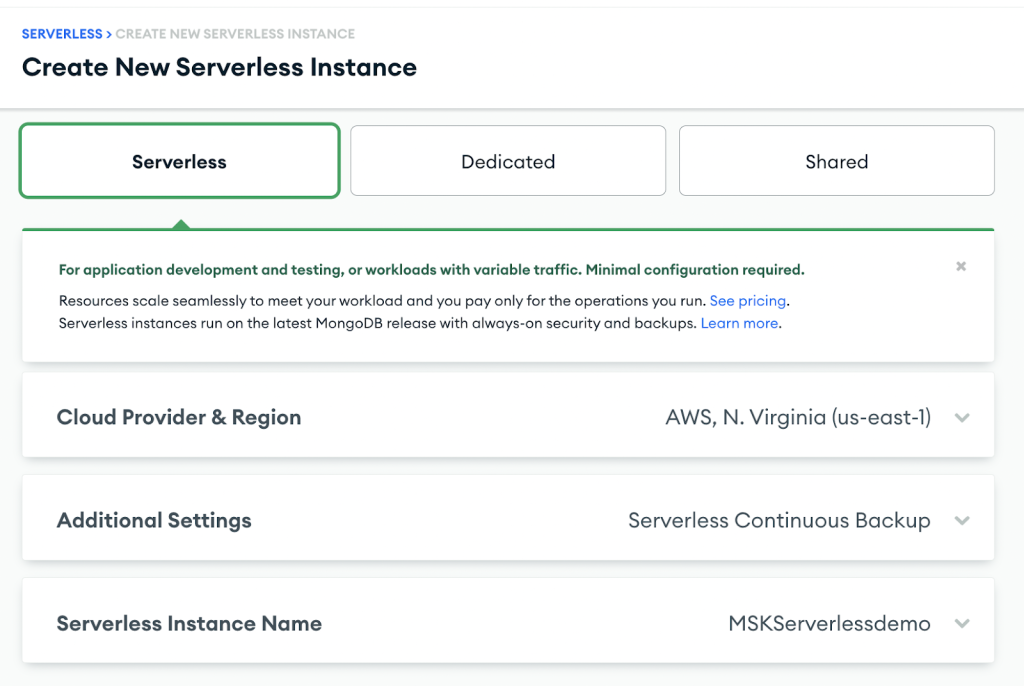
Dopo aver creato il cluster, configura un endpoint privato AWS con i seguenti passaggi:
- Sulla Sicurezza menù, scegliere Accesso alla rete.

- Sulla Endpoint privato scheda, scegliere Istanza senza server.

- Scegli Crea un nuovo endpoint.
- Nel Istanza senza server, scegli l'istanza appena creata.
- Scegli Confermare.
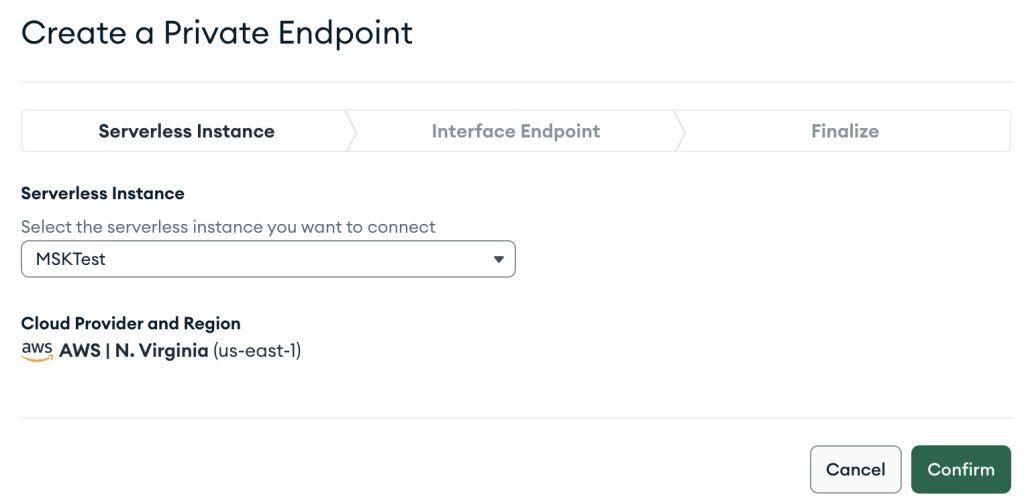
- Fornisci la configurazione dell'endpoint VPC e scegli Avanti.
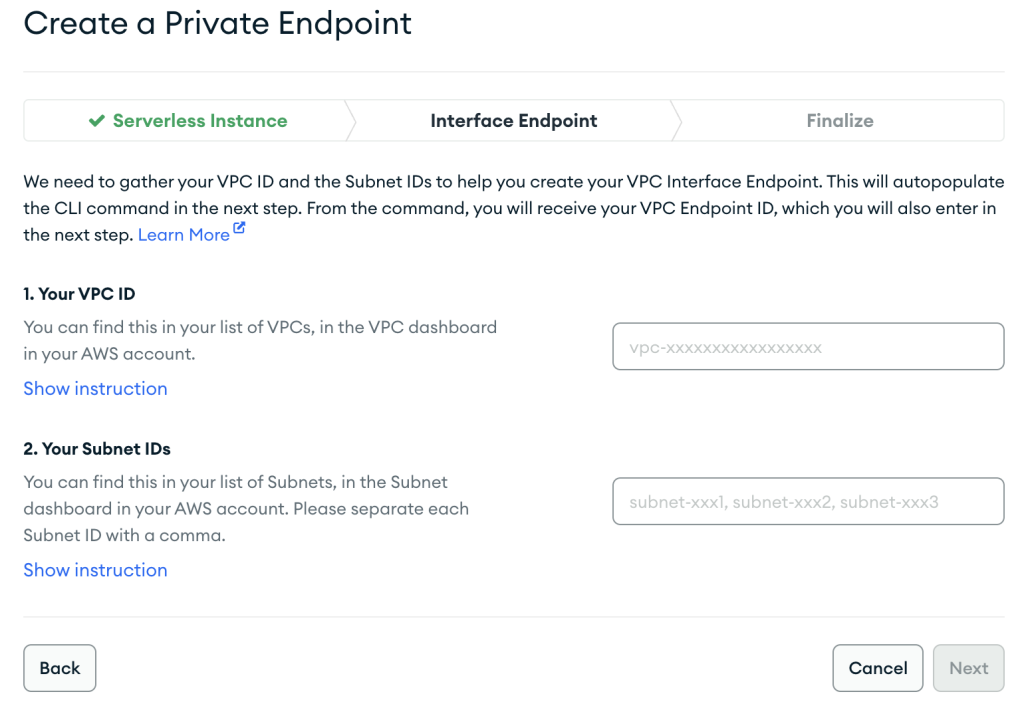
- Quando crei la risorsa AWS PrivateLink, assicurati di specificare esattamente lo stesso VPC e le stesse sottoreti che hai utilizzato in precedenza durante la creazione della configurazione di rete per l'istanza MSK serverless.
- Scegli Avanti.
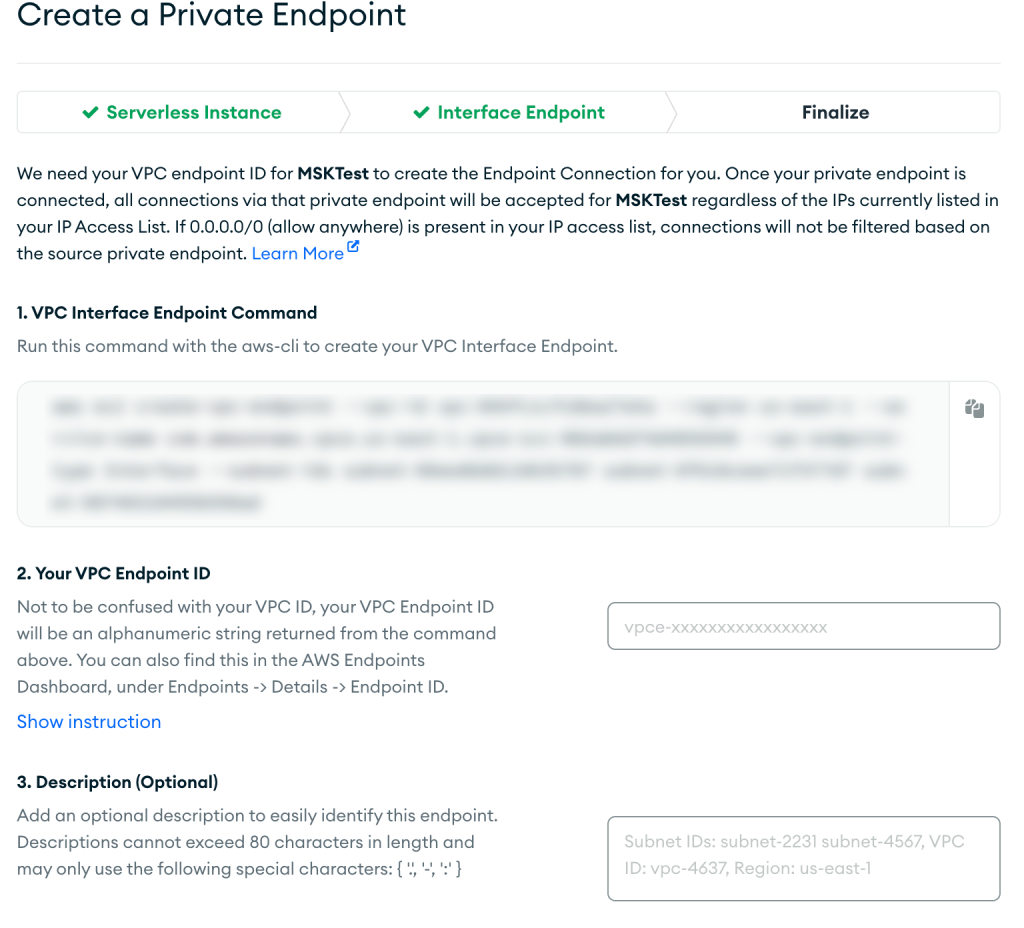
- Segui le istruzioni sul ultimare pagina, quindi scegli Confermare dopo la creazione dell'endpoint VPC.
In caso di successo, il nuovo endpoint privato verrà visualizzato nell'elenco, come mostrato nello screenshot seguente.
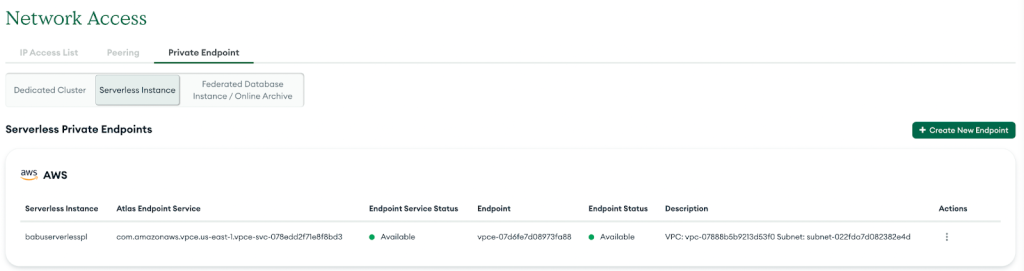
Configura il plug-in MSK
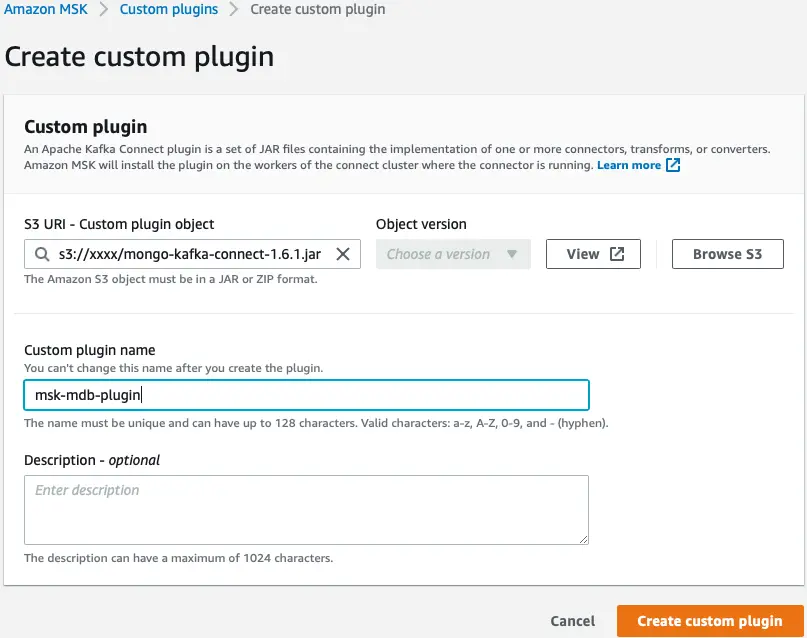
Successivamente, creiamo un plug-in personalizzato in Amazon MSK utilizzando il connettore MongoDB per Apache Kafka. Il connettore deve essere caricato su un file Servizio di archiviazione semplice Amazon (Amazon S3) prima di poter creare il plug-in. Per scaricare il connettore MongoDB per Apache Kafka, fare riferimento a Scarica un file JAR del connettore.
- Sulla console Amazon MSK, scegli Plugin personalizzati nel pannello di navigazione.
- Scegli Crea plug-in personalizzato.
- Nel URI S3, immettere la posizione S3 del connettore scaricato.
- Scegli Crea plug-in personalizzato.
Configura un client EC2
Successivamente, configuriamo un'istanza EC2. Utilizziamo questa istanza per creare l'argomento e inserire i dati nell'argomento. Per le istruzioni, fare riferimento alla sezione Configura un client EC2 nella posta Integrazione di MongoDB con Amazon Managed Streaming per Apache Kafka (MSK).
Crea un argomento nel cluster MSK
Per creare un argomento Kafka, dobbiamo prima installare l'interfaccia a riga di comando di Kafka.
- Sull'istanza EC2 del client, installa prima Java:
sudo yum install java-1.8.0
- Quindi, esegui il seguente comando per scaricare Apache Kafka:
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Scompattare il file tar utilizzando il seguente comando:
tar -xzf kafka_2.12-2.6.2.tgz
La distribuzione di Kafka include una cartella bin con strumenti che possono essere utilizzati per gestire gli argomenti.
- Vai
kafka_2.12-2.6.2directory ed emettere il seguente comando per creare un argomento Kafka sul cluster MSK senza server:
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
È possibile copiare l'endpoint del server di bootstrap nel file Visualizza le informazioni sul cliente page per il tuo cluster MSK serverless.
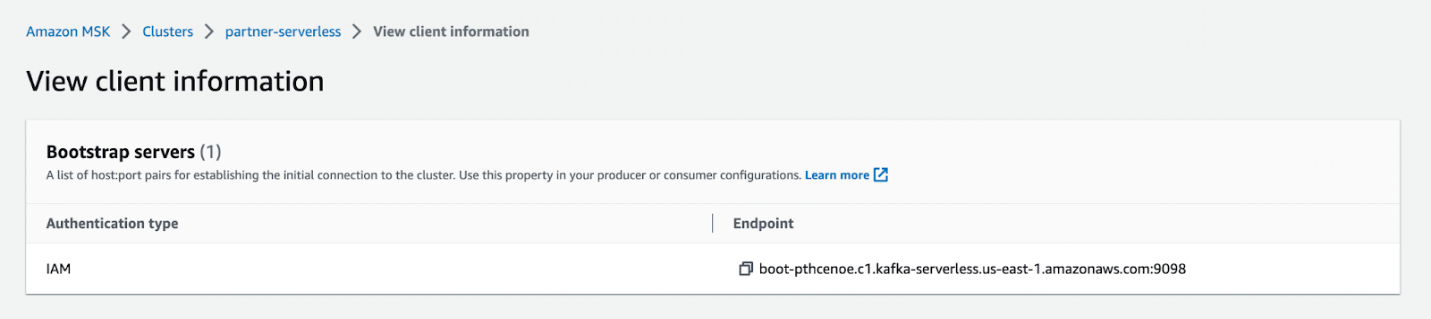
Puoi configurare l'autenticazione IAM seguendo queste istruzioni istruzioni.
Configurare il connettore sink
Ora, configuriamo un connettore sink per inviare i dati all'istanza MongoDB Atlas Serverless.
- Sulla console Amazon MSK, scegli Connettori RF nel pannello di navigazione.
- Scegli Crea connettore.
- Seleziona il plug-in che hai creato in precedenza.
- Scegli Avanti.
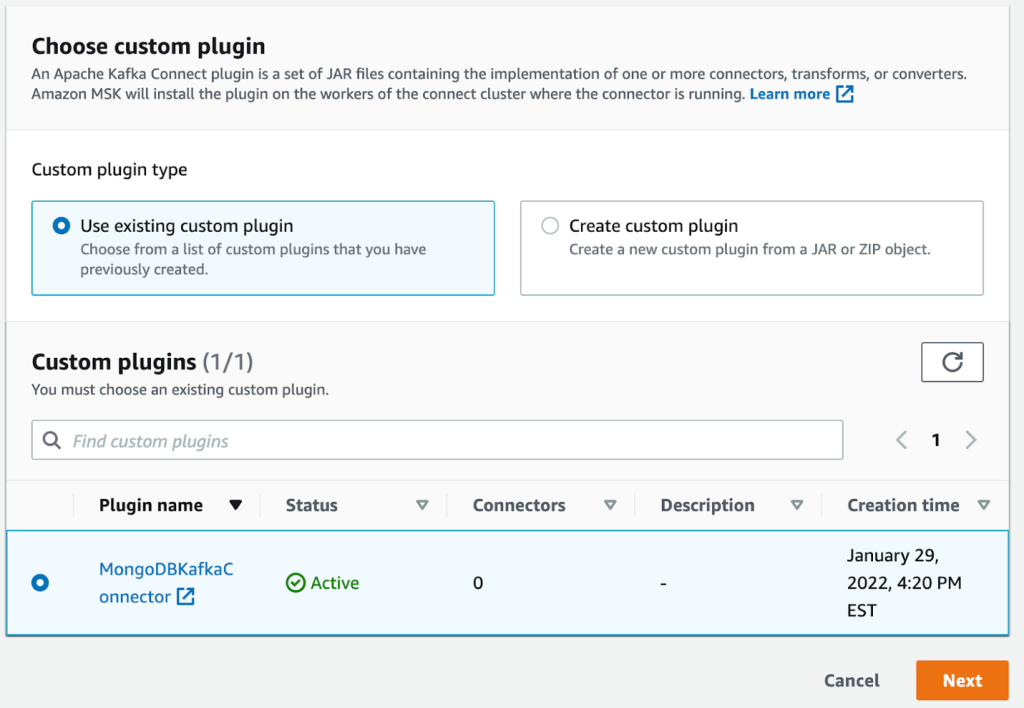
- Seleziona l'istanza MSK serverless che hai creato in precedenza.
- Inserisci la tua configurazione di connessione come il seguente codice:
Assicurati che la connessione all'istanza MongoDB Atlas Serverless avvenga tramite AWS PrivateLink. Per ulteriori informazioni, fare riferimento a Connessione sicura delle applicazioni a un piano dati MongoDB Atlas con AWS PrivateLink.
- Nel Autorizzazioni di accesso sezione, creare un file Gestione dell'identità e dell'accesso di AWS (IAM) ruolo con il politica di fiducia richiesta.
- Scegli Avanti.
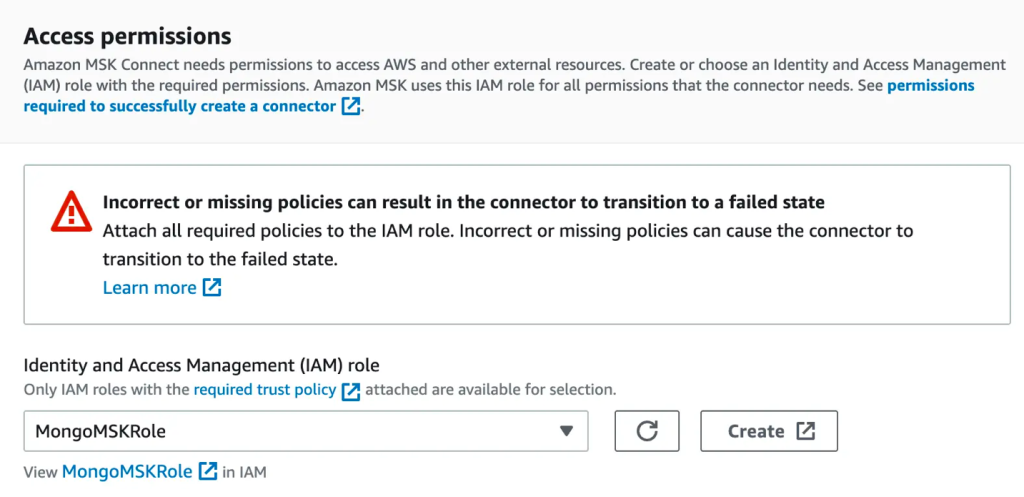
- Specificare Log di Amazon CloudWatch come opzione di consegna dei log.
- Completa il tuo connettore.
Quando lo stato del connettore passa ad Attivo, la pipeline è pronta.

Inserisci i dati nell'argomento MSK
Sul tuo client EC2, inserisci i dati nell'argomento MSK utilizzando il file kafka-console-producer come segue:
Per verificare che i dati fluiscano correttamente dall'argomento Kafka al cluster MongoDB senza server, utilizziamo l'interfaccia utente di MongoDB Atlas.

In caso di problemi, assicurati di controllare i file di registro. In questo esempio, abbiamo utilizzato CloudWatch per leggere gli eventi generati da Amazon MSK e dal connettore MongoDB per Apache Kafka.

ripulire
Per evitare di incorrere in addebiti futuri, ripulisci le risorse che hai creato. Innanzitutto, elimina il cluster MSK, il connettore e l'istanza EC2:
- Sulla console Amazon MSK, scegli Cluster nel pannello di navigazione.
- Seleziona il tuo cluster e sul Azioni menù, scegliere Elimina.
- Scegli Connettori RF nel pannello di navigazione.
- Seleziona il tuo connettore e scegli Elimina.
- Scegli Plugin personalizzati nel pannello di navigazione.
- Seleziona il tuo plug-in e scegli Elimina.
- Sulla console Amazon EC2, scegli Istanze nel pannello di navigazione.
- Scegli l'istanza che hai creato.
- Scegli Stato dell'istanza, Quindi scegliere Termina istanza.
- Sulla VPC Amazon console, scegli endpoint nel pannello di navigazione.
- Seleziona l'endpoint che hai creato e sul file Azioni menù, scegliere Elimina gli endpoint VPC.
Ora puoi eliminare il cluster Atlas e AWS PrivateLink:
- Accedi alla console del cluster Atlas.
- Passare al cluster serverless da eliminare.
- Nel menu a discesa delle opzioni, scegli Terminare.
- Passare alla Accesso alla rete .
- Scegli l'endpoint privato.
- Seleziona l'istanza senza server.
- Nel menu a discesa delle opzioni, scegli Terminare.

Sommario
In questo post, ti abbiamo mostrato come creare una pipeline di ingestione di streaming serverless utilizzando MSK Serverless e MongoDB Atlas Serverless. Con MSK Serverless, puoi eseguire automaticamente il provisioning e gestire le risorse richieste in base alle necessità. Abbiamo utilizzato un connettore MongoDB distribuito su MSK Connect per integrare perfettamente i due servizi e abbiamo utilizzato un client EC2 per inviare dati di esempio all'argomento MSK. MSK Connect ora supporta Nomi host DNS privati, consentendoti di utilizzare nomi di dominio privati tra i servizi. In questo post, il connettore ha utilizzato i server DNS predefiniti del VPC per risolvere il nome DNS privato specifico della zona di disponibilità. Questa configurazione AWS PrivateLink ha consentito una connettività sicura e privata tra l'istanza MSK Serverless e l'istanza MongoDB Atlas Serverless.
Per continuare il tuo apprendimento, controlla le seguenti risorse:
Informazioni sugli autori

Igor Alekseev è Senior Partner Solution Architect presso AWS nel dominio Dati e analisi. Nel suo ruolo Igor sta lavorando con partner strategici aiutandoli a costruire complesse architetture ottimizzate per AWS. Prima di entrare in AWS, come Data/Solution Architect ha implementato molti progetti nel dominio dei Big Data, inclusi diversi data lake nell'ecosistema Hadoop. In qualità di Data Engineer, è stato coinvolto nell'applicazione di AI/ML al rilevamento delle frodi e all'automazione dell'ufficio.
 Kiran Matty è un Principal Product Manager con Amazon Web Services (AWS) e lavora con il team Amazon Managed Streaming per Apache Kafka (Amazon MSK) con sede a Palo Alto, in California. È appassionato di creare streaming performanti e servizi analitici che aiutino le aziende a realizzare i loro casi d'uso critici.
Kiran Matty è un Principal Product Manager con Amazon Web Services (AWS) e lavora con il team Amazon Managed Streaming per Apache Kafka (Amazon MSK) con sede a Palo Alto, in California. È appassionato di creare streaming performanti e servizi analitici che aiutino le aziende a realizzare i loro casi d'uso critici.
 Babu Srivasan è Senior Partner Solutions Architect presso MongoDB. Nel suo ruolo attuale, sta lavorando con AWS per creare le integrazioni tecniche e le architetture di riferimento per le soluzioni AWS e MongoDB. Ha più di due decenni di esperienza nelle tecnologie Database e Cloud. È appassionato di fornire soluzioni tecniche ai clienti che lavorano con più Global System Integrator (GSI) in più aree geografiche.
Babu Srivasan è Senior Partner Solutions Architect presso MongoDB. Nel suo ruolo attuale, sta lavorando con AWS per creare le integrazioni tecniche e le architetture di riferimento per le soluzioni AWS e MongoDB. Ha più di due decenni di esperienza nelle tecnologie Database e Cloud. È appassionato di fornire soluzioni tecniche ai clienti che lavorano con più Global System Integrator (GSI) in più aree geografiche.
 Robert Walters è attualmente Senior Product Manager presso MongoDB. Prima di MongoDB, Rob ha trascorso 17 anni in Microsoft ricoprendo vari ruoli, tra cui la gestione dei programmi nel team di SQL Server, la consulenza e la prevendita tecnica. Rob è coautore di tre brevetti per le tecnologie utilizzate all'interno di SQL Server ed è stato l'autore principale di diversi libri tecnici su SQL Server. Rob è attualmente un blogger attivo sui blog MongoDB.
Robert Walters è attualmente Senior Product Manager presso MongoDB. Prima di MongoDB, Rob ha trascorso 17 anni in Microsoft ricoprendo vari ruoli, tra cui la gestione dei programmi nel team di SQL Server, la consulenza e la prevendita tecnica. Rob è coautore di tre brevetti per le tecnologie utilizzate all'interno di SQL Server ed è stato l'autore principale di diversi libri tecnici su SQL Server. Rob è attualmente un blogger attivo sui blog MongoDB.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/
- 10
- 100
- 7
- a
- Chi siamo
- accesso
- di conseguenza
- operanti in
- attivo
- aggiunta
- Dopo shavasana, sedersi in silenzio; saluti;
- AI / ML
- consente
- Amazon
- Amazon EC2
- Amazon Web Services
- Amazon Web Services (AWS)
- Analitico
- analitica
- ed
- Apache
- Apache Kafka
- applicazioni
- AMMISSIONE
- architettura
- Arriva
- atlante
- Autenticazione
- autore
- Automatizzata
- automaticamente
- Automazione
- disponibilità
- disponibile
- AWS
- di riserva
- basato
- base
- diventa
- prima
- MIGLIORE
- fra
- Big
- Big Data
- blog
- Libri
- bootstrap
- costruire
- Costruzione
- costruito
- California
- Ultra-Grande
- casi
- Modifiche
- oneri
- dai un'occhiata
- Scegli
- cliente
- Cloud
- Cluster
- codice
- collezione
- collezioni
- completamento di una
- complesso
- Calcolare
- Configurazione
- Connettiti
- veloce
- Connettività
- consolle
- consulting
- continua
- Corrispondente
- Costo
- creare
- creato
- Creazione
- creazione
- critico
- Corrente
- Attualmente
- costume
- Clienti
- dati
- ingegnere dei dati
- Banca Dati
- decenni
- Predefinito
- consegna
- richieste
- schierato
- dettagli
- rivelazione
- dialogo
- distribuzione
- dns
- dominio
- NOMI DI DOMINIO
- giù
- scaricare
- In precedenza
- facilmente
- ecosistema
- consentendo
- crittografia
- da un capo all'altro
- endpoint
- ingegnere
- entrare
- aziende
- Etere (ETH)
- eventi
- esempio
- esperienza
- Caratteristiche
- Compila il
- File
- Nome
- flusso
- flussi
- seguire
- i seguenti
- segue
- frode
- rilevazione di frodi
- da
- completamente
- futuro
- generato
- geografie
- globali
- Hadoop
- Aiuto
- aiutare
- qui
- Alta
- vivamente
- Come
- Tutorial
- HTML
- HTTPS
- IAM
- Identità
- realizzare
- implementato
- in
- inclusi
- Compreso
- informazioni
- Infrastruttura
- install
- esempio
- istruzioni
- integrare
- integrazione
- integrazioni
- interessato
- coinvolto
- problema
- sicurezza
- IT
- Java
- accoppiamento
- kafka
- Le
- portare
- apprendimento
- Lista
- località
- make
- FA
- gestire
- gestito
- gestione
- direttore
- molti
- Menu
- Metrica
- Microsoft
- minimo
- MongoDB
- Scopri di più
- multiplo
- Nome
- nomi
- Navigazione
- Bisogno
- esigenze
- Rete
- Accesso alla rete
- internazionale
- New
- Office
- Opzione
- Opzioni
- palo Alto
- vetro
- partner
- partner
- appassionato
- Brevetti
- performance
- conduttura
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- plug-in
- Post
- precedente
- Direttore
- Precedente
- un bagno
- processi
- Prodotto
- product manager
- Programma
- progetti
- proprietà
- fornire
- fornisce
- fornitura
- fornitura
- fini
- Leggi
- pronto
- di rose
- tempo reale
- rendersi conto
- record
- problemi di
- necessario
- risorsa
- Risorse
- ROBERT
- Ruolo
- ruoli
- Correre
- stesso
- Scala
- bilancia
- senza soluzione di continuità
- Sezione
- sicuro
- in modo sicuro
- problemi di
- anziano
- serverless
- servizio
- Servizi
- impostazioni
- alcuni
- mostrare attraverso le sue creazioni
- mostrato
- Un'espansione
- Taglia
- soluzione
- Soluzioni
- Fonte
- fonti
- esaurito
- SQL
- iniziato
- inizio
- Stato dei servizi
- Passi
- conservazione
- Strategico
- partner strategici
- Streaming
- sottorete
- sottoreti
- il successo
- Con successo
- tale
- supporti
- sistema
- task
- team
- Consulenza
- Tecnologie
- I
- loro
- tre
- Attraverso
- tempo
- a
- strumenti
- argomento
- Argomenti
- Affidati ad
- lezione
- ui
- upgrade
- caricato
- uso
- APPREZZIAMO
- vario
- verificare
- via
- sito web
- servizi web
- volere
- entro
- flussi di lavoro
- lavoro
- lavori
- anni
- Trasferimento da aeroporto a Sharm
- zefiro
- zone