Le reti neurali apprendono attraverso i numeri, quindi ogni parola verrà mappata su vettori per rappresentare una parola particolare. Il livello di incorporamento può essere pensato come una tabella di ricerca che memorizza gli incorporamenti di parole e li recupera utilizzando gli indici.
Le parole che hanno lo stesso significato saranno vicine in termini di distanza euclidea/somiglianza coseno. ad esempio, nella rappresentazione della parola sottostante, “sabato”, “domenica” e “lunedì” è associato allo stesso concetto, quindi possiamo vedere che le parole risultano simili.

La determinazione della posizione della parola, Perché abbiamo bisogno di determinare la posizione della parola? poiché il codificatore del trasformatore non ha ricorrenza come le reti neurali ricorrenti, dobbiamo aggiungere alcune informazioni sulle posizioni negli incorporamenti di input. Questo viene fatto usando la codifica posizionale. Gli autori dell'articolo hanno utilizzato le seguenti funzioni per modellare la posizione di una parola.
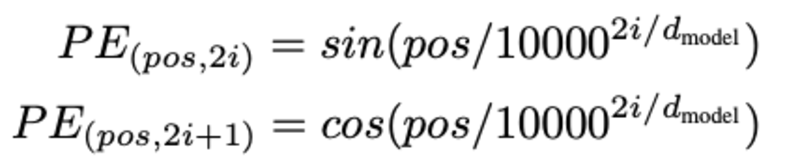
Cercheremo di spiegare la codifica posizionale.
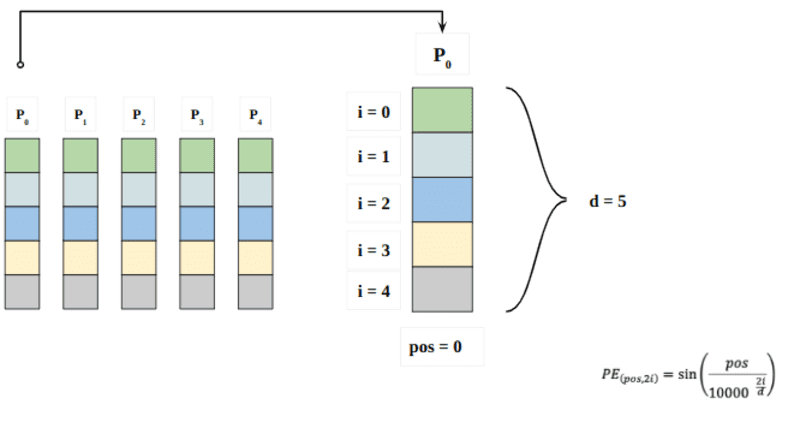
Qui "pos" si riferisce alla posizione della "parola" nella sequenza. P0 si riferisce all'incorporamento della posizione della prima parola; "d" indica la dimensione dell'incorporamento di parole/token. In questo esempio d=5. Infine, "i" si riferisce a ciascuna delle 5 singole dimensioni dell'incorporamento (ovvero 0, 1,2,3,4)
se "i" varia nell'equazione sopra, otterrai un mucchio di curve con frequenze variabili. Leggere i valori di incorporamento della posizione rispetto a frequenze diverse, fornendo valori diversi a diverse dimensioni di incorporamento per P0 e P4.
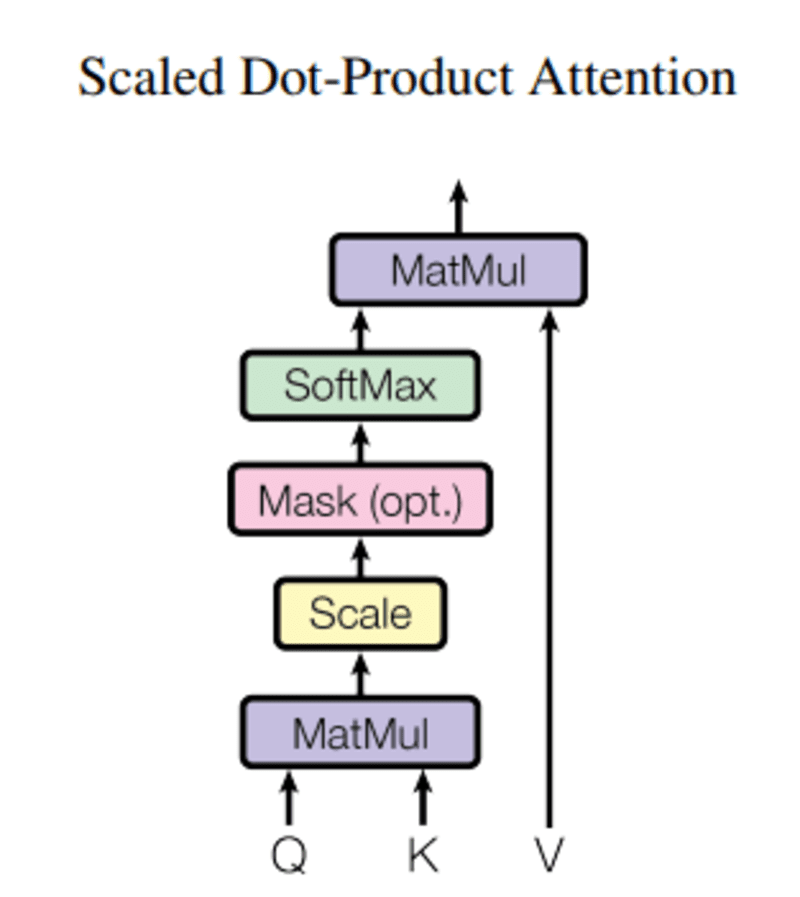
In questa interrogazione, q rappresenta una parola vettoriale, the chiavi k sono tutte le altre parole nella frase, e valore v rappresenta il vettore della parola.
Lo scopo dell'attenzione è calcolare l'importanza del termine chiave rispetto al termine di ricerca relativo alla stessa persona/cosa o concetto.
Nel nostro caso, V è uguale a Q.
Il meccanismo dell'attenzione ci dà l'importanza della parola in una frase.
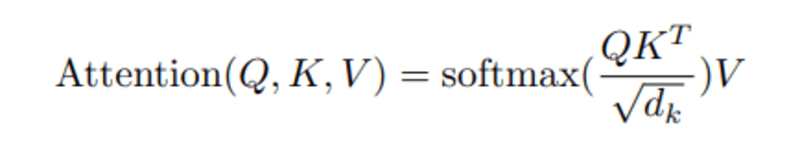
Quando calcoliamo il prodotto scalare normalizzato tra la query e le chiavi, otteniamo un tensore che rappresenta l'importanza relativa di ogni altra parola per la query.
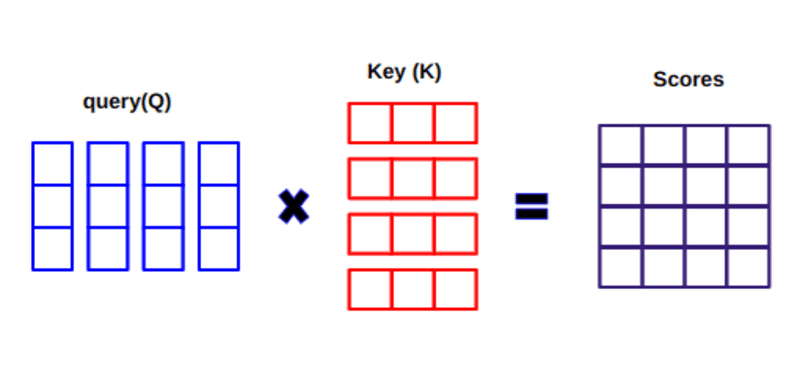
Quando calcoliamo il prodotto scalare tra Q e KT, proviamo a stimare come i vettori (cioè le parole tra query e chiavi) sono allineati e restituiamo un peso per ogni parola nella frase.
Quindi, normalizziamo il risultato al quadrato di d_k e la funzione softmax regolarizza i termini e li ridimensiona tra 0 e 1.
Infine, moltiplichiamo il risultato (cioè i pesi) per il valore (cioè tutte le parole) per ridurre l'importanza delle parole non rilevanti e concentrarci solo sulle parole più importanti.
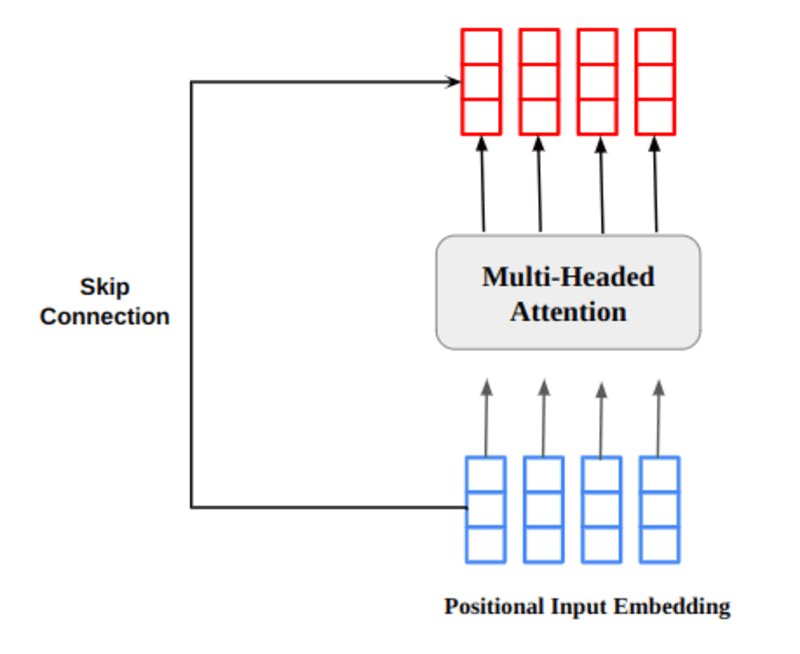
Il vettore di output dell'attenzione a più teste viene aggiunto all'incorporamento dell'input posizionale originale. Questa è chiamata connessione residua/salta connessione. L'output della connessione residua passa attraverso la normalizzazione del livello. L'uscita residua normalizzata viene fatta passare attraverso una rete di feed-forward puntuale per un'ulteriore elaborazione.
La maschera è una matrice delle stesse dimensioni dei punteggi di attenzione riempiti con valori di 0 e infiniti negativi.
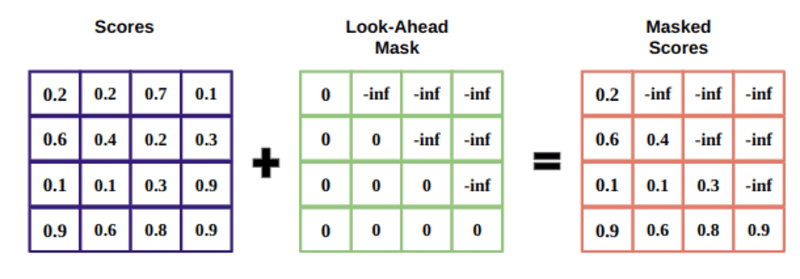
Il motivo della maschera è che una volta preso il softmax dei punteggi mascherati, gli infiniti negativi ottengono zero, lasciando zero punteggi di attenzione per i token futuri.
Questo dice al modello di non concentrarsi su quelle parole.
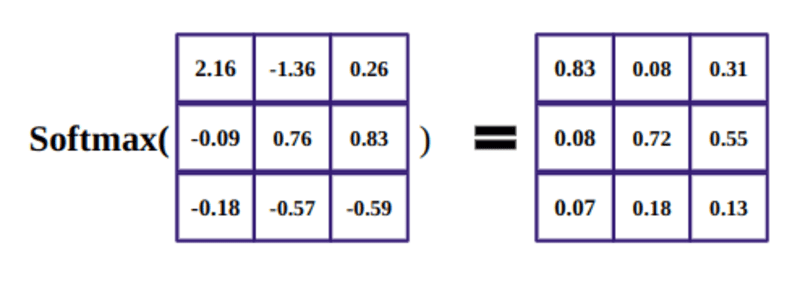
Lo scopo della funzione softmax è quello di prendere numeri reali (positivi e negativi) e trasformarli in numeri positivi che sommano a 1.
Ravikumar Naduvin è impegnato nella costruzione e nella comprensione delle attività di PNL utilizzando PyTorch.
Originale. Ripubblicato con il permesso.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Chi siamo
- sopra
- aggiunto
- contro
- Allineati
- Tutti
- ed
- associato
- attenzione
- gli autori
- perché
- prima
- sotto
- fra
- Costruzione
- Mazzo
- detto
- Custodie
- Chiudi
- rispetto
- Calcolare
- informatica
- concetto
- concetti
- veloce
- Determinare
- determinazione
- diverso
- dimensioni
- DOT
- ogni
- stima
- esempio
- Spiegare
- pieno
- Infine
- Nome
- Focus
- i seguenti
- function
- funzioni
- ulteriormente
- futuro
- ottenere
- ottenere
- GitHub
- dà
- Dare
- va
- afferrare
- Come
- HTTPS
- importanza
- importante
- in
- Indici
- individuale
- informazioni
- ingresso
- KDnuggets
- Le
- Tasti
- Sapere
- strato
- IMPARARE
- partenza
- ricerca
- mask
- Matrice
- significato
- si intende
- meccanismo
- modello
- maggior parte
- Bisogno
- negativo.
- Rete
- reti
- Neurale
- reti neurali
- nlp
- numeri
- i
- Altro
- Carta
- particolare
- Passato
- autorizzazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- posizione
- posizioni
- positivo
- lavorazione
- Prodotto
- scopo
- metti
- pytorch
- Lettura
- di rose
- ragione
- ricorrenza
- ridurre
- si riferisce
- relazionato
- rappresentare
- rappresentazione
- rappresenta
- colpevole
- risultante
- ritorno
- stesso
- condanna
- Sequenza
- dovrebbero
- simile
- Taglia
- So
- alcuni
- Squared
- negozi
- tavolo
- Fai
- task
- dice
- condizioni
- I
- pensiero
- Attraverso
- a
- Tokens
- trasformatori
- TURNO
- e una comprensione reciproca
- us
- APPREZZIAMO
- Valori
- peso
- quale
- volere
- Word
- parole
- zefiro
- zero










