I semi di un cambio di paradigma di machine learning (ML) esistono da decenni, ma con la pronta disponibilità di una capacità di elaborazione virtualmente infinita, un'enorme proliferazione di dati e il rapido progresso delle tecnologie ML, i clienti di tutti i settori stanno rapidamente adottando e utilizzando ML tecnologie per trasformare le loro attività.
Proprio di recente, le applicazioni di intelligenza artificiale generativa hanno catturato l'attenzione e l'immaginazione di tutti. Siamo davvero a un punto di svolta entusiasmante nell'adozione diffusa del ML e crediamo che ogni esperienza e applicazione del cliente verrà reinventata con l'IA generativa.
L'IA generativa è un tipo di intelligenza artificiale in grado di creare nuovi contenuti e idee, tra cui conversazioni, storie, immagini, video e musica. Come tutte le IA, l'IA generativa è alimentata da modelli ML, modelli molto grandi che vengono preaddestrati su vasti corpora di dati e comunemente indicati come modelli di base (FM).
Le dimensioni e la natura generica dei FM li rendono diversi dai modelli ML tradizionali, che in genere eseguono attività specifiche, come analizzare il testo per il sentiment, classificare le immagini e prevedere le tendenze.
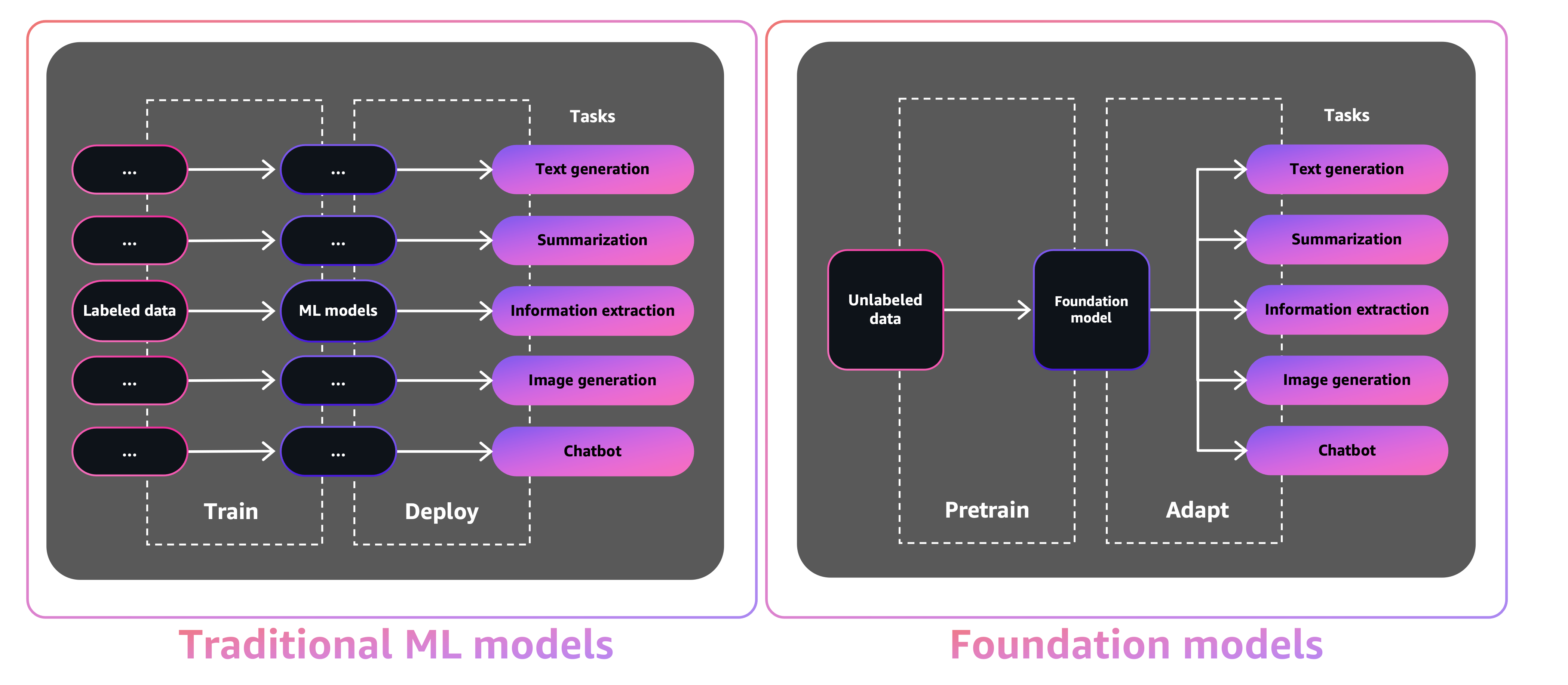
Con i modelli ML tradizionali, per raggiungere ogni attività specifica, è necessario raccogliere dati etichettati, addestrare un modello e distribuirlo. Con i modelli di base, invece di raccogliere dati etichettati per ogni modello e addestrare più modelli, puoi utilizzare lo stesso FM pre-addestrato per adattare varie attività. Puoi anche personalizzare FM per eseguire funzioni specifiche del dominio che si differenziano per le tue attività, utilizzando solo una piccola parte dei dati e del calcolo necessari per addestrare un modello da zero.
L'IA generativa ha il potenziale per sconvolgere molti settori rivoluzionando il modo in cui i contenuti vengono creati e consumati. La produzione di contenuti originali, la generazione di codice, il miglioramento del servizio clienti e il riepilogo dei documenti sono casi d'uso tipici dell'IA generativa.
JumpStart di Amazon SageMaker fornisce modelli open source preaddestrati per un'ampia gamma di tipi di problemi per aiutarti a iniziare con ML. Puoi addestrare e ottimizzare questi modelli in modo incrementale prima della distribuzione. JumpStart fornisce anche modelli di soluzioni che configurano l'infrastruttura per casi d'uso comuni e notebook di esempio eseguibili per ML con Amazon Sage Maker.
Con oltre 600 modelli pre-addestrati disponibili e in crescita ogni giorno, JumpStart consente agli sviluppatori di incorporare rapidamente e facilmente tecniche di ML all'avanguardia nei loro flussi di lavoro di produzione. Puoi accedere ai modelli pre-addestrati, ai modelli di soluzione e agli esempi tramite la pagina di destinazione JumpStart in Amazon Sage Maker Studio. Puoi anche accedere ai modelli JumpStart utilizzando SageMaker Python SDK. Per informazioni su come utilizzare i modelli JumpStart a livello di programmazione, vedere Utilizza gli algoritmi SageMaker JumpStart con modelli preaddestrati.
Nell'aprile 2023, AWS ha presentato Roccia Amazzonica, che fornisce un modo per creare app generative basate sull'intelligenza artificiale tramite modelli preaddestrati da startup tra cui Laboratori AI21, Antropicoe Stabilità AI. Amazon Bedrock offre anche l'accesso ai modelli di base Titan, una famiglia di modelli addestrati internamente da AWS. Con l'esperienza serverless di Amazon Bedrock, puoi trovare facilmente il modello giusto per le tue esigenze, iniziare rapidamente, personalizzare privatamente FM con i tuoi dati e integrarli e distribuirli facilmente nelle tue applicazioni utilizzando gli strumenti e le funzionalità AWS che conosci con (comprese le integrazioni con funzionalità di SageMaker ML come Esperimenti Amazon SageMaker per testare diversi modelli e Pipeline di Amazon SageMaker per gestire i tuoi FM su larga scala) senza dover gestire alcuna infrastruttura.
In questo post, mostriamo come distribuire modelli AI generativi di immagini e testo da JumpStart utilizzando il Kit di sviluppo cloud AWS (AWSCDK). AWS CDK è un framework di sviluppo software open source per definire le risorse delle tue applicazioni cloud utilizzando linguaggi di programmazione familiari come Python.
Utilizziamo il modello Stable Diffusion per la generazione di immagini e il modello FLAN-T5-XL per comprensione del linguaggio naturale (NLU) e generazione di testo da Abbracciare il viso nel JumpStart.
Panoramica della soluzione
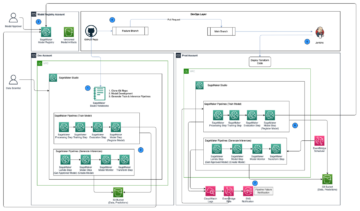
L'applicazione web è costruita su Snello, una libreria Python open source che semplifica la creazione e la condivisione di bellissime app Web personalizzate per ML e data science. Ospitiamo l'applicazione web utilizzando Servizio di container elastici Amazon (Amazon ECS) con AWS Fargate ed è accessibile tramite un Application Load Balancer. Fargate è una tecnologia che puoi utilizzare con Amazon ECS per l'esecuzione contenitori senza dover gestire server o cluster o macchine virtuali. Gli endpoint del modello AI generativo vengono lanciati dalle immagini JumpStart in Registro dei contenitori Amazon Elastic (Amazon ECR). I dati del modello sono memorizzati su Servizio di archiviazione semplice Amazon (Amazon S3) nell'account JumpStart. L'applicazione web interagisce con i modelli tramite Gateway API Amazon ed AWS Lambda funziona come mostrato nel diagramma seguente.
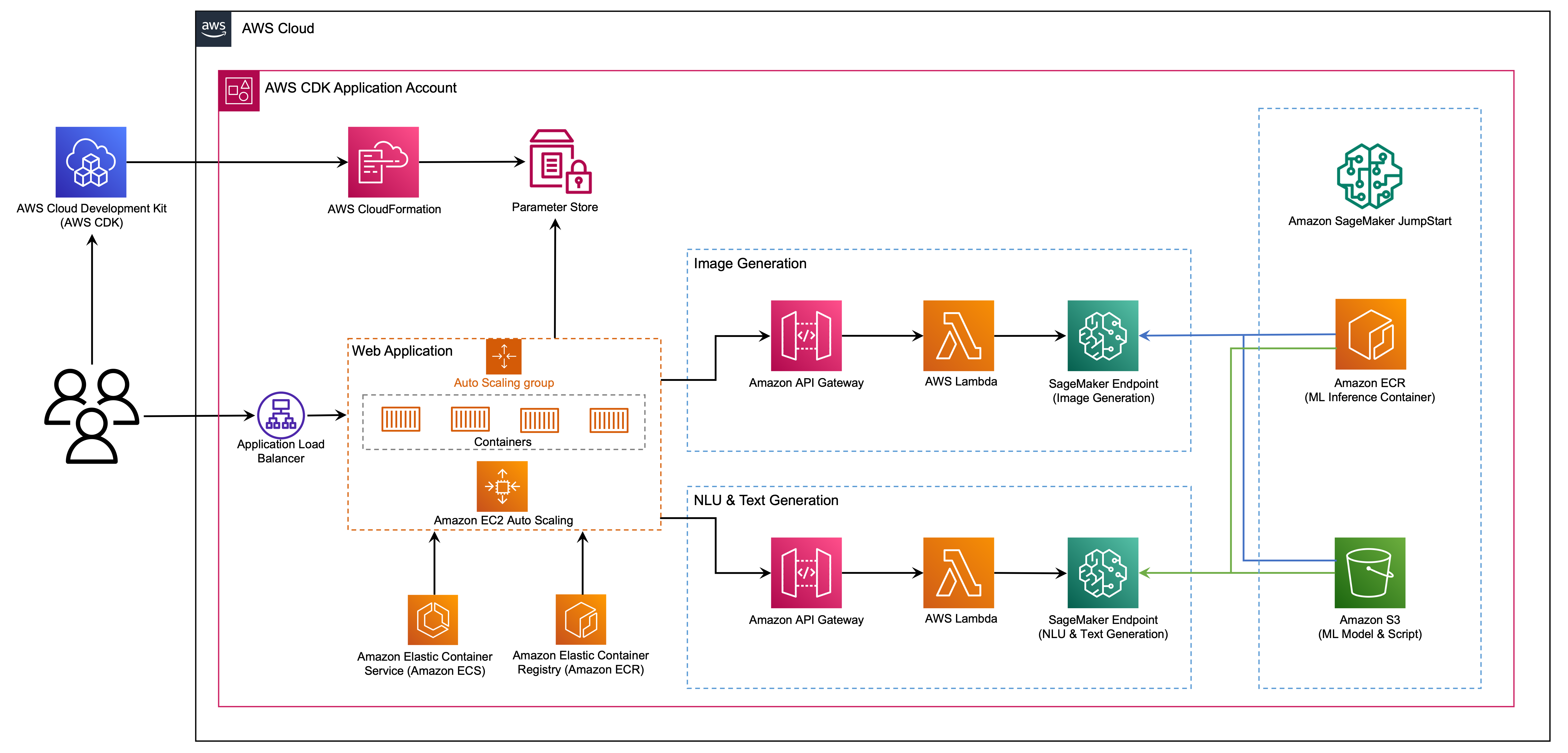
API Gateway fornisce all'applicazione Web e ad altri client un'interfaccia RESTful standard, proteggendo al contempo le funzioni Lambda che si interfacciano con il modello. Ciò semplifica il codice dell'applicazione client che utilizza i modelli. Gli endpoint API Gateway sono pubblicamente accessibili in questo esempio, consentendo la possibilità di estendere questa architettura per implementare diversi Controlli di accesso API e integrarsi con altre applicazioni.
In questo post, ti guidiamo attraverso i seguenti passaggi:
- installare il Interfaccia della riga di comando di AWS (AWS CLI) e AWS CDK v2 sul tuo computer locale.
- Clonare e configurare l'applicazione AWS CDK.
- Distribuisci l'applicazione AWS CDK.
- Usa il modello AI per la generazione di immagini.
- Usa il modello AI per la generazione di testo.
- Visualizza le risorse distribuite su Console di gestione AWS.
Forniamo una panoramica del codice in questo progetto nell'appendice alla fine di questo post.
Prerequisiti
Devi avere i seguenti prerequisiti:
È possibile distribuire l'infrastruttura in questa esercitazione dal computer locale oppure è possibile utilizzare AWS Cloud9 come workstation di distribuzione. AWS Cloud9 viene fornito precaricato con AWS CLI, AWS CDK e Docker. Se opti per AWS Cloud9, creare l'ambiente dal Console AWS.
Il costo stimato per completare questo post è di $ 50, supponendo che lasci le risorse in esecuzione per 8 ore. Assicurati di eliminare le risorse che crei in questo post per evitare addebiti continui.
Installa AWS CLI e AWS CDK sulla tua macchina locale
Se non disponi già dell'AWS CLI sul tuo computer locale, fai riferimento a Installazione o aggiornamento dell'ultima versione di AWS CLI ed Configurazione dell'AWS CLI.
Installa AWS CDK Toolkit a livello globale utilizzando il seguente comando del gestore pacchetti del nodo:
Esegui il seguente comando per verificare la corretta installazione e stampa il numero di versione di AWS CDK:
Assicurati di avere Docker installato sul tuo computer locale. Immetti il seguente comando per verificare la versione:
Clonare e configurare l'applicazione AWS CDK
Sul tuo computer locale, clona l'applicazione AWS CDK con il seguente comando:
Vai alla cartella del progetto:
Prima di distribuire l'applicazione, esaminiamo la struttura della directory:
I stack contiene il codice per ogni stack nell'applicazione AWS CDK. IL code La cartella contiene il codice per le funzioni Lambda. Il repository contiene anche l'applicazione web che si trova sotto la cartella web-app.
I cdk.json file indica a AWS CDK Toolkit come eseguire l'applicazione.
Questa applicazione è stata testata in us-east-1 Region, ma dovrebbe funzionare in qualsiasi regione che disponga dei servizi richiesti e del tipo di istanza di inferenza ml.g4dn.4xlarge Specificato in app.py.
Crea un ambiente virtuale
Questo progetto è impostato come un progetto Python standard. Crea un ambiente virtuale Python usando il seguente codice:
Utilizzare il comando seguente per attivare l'ambiente virtuale:
Se sei su una piattaforma Windows, attiva l'ambiente virtuale come segue:
Dopo l'attivazione dell'ambiente virtuale, aggiorna pip alla versione più recente:
Installa le dipendenze richieste:
Prima di distribuire qualsiasi applicazione AWS CDK, devi eseguire il bootstrap di uno spazio nel tuo account e nella regione in cui esegui la distribuzione. Per eseguire il bootstrap nella regione predefinita, immetti il seguente comando:
Se desideri eseguire la distribuzione in un account e una regione specifici, immetti il seguente comando:
Per ulteriori informazioni su questa configurazione, visitare Nozioni di base su AWS CDK.
Struttura dello stack dell'applicazione AWS CDK
L'applicazione AWS CDK contiene più stack, come mostrato nel diagramma seguente.

Puoi elencare gli stack nella tua applicazione AWS CDK con il seguente comando:
Di seguito sono riportati altri utili comandi AWS CDK:
- CDK ls - Elenca tutti gli stack nell'app
- sintetizzatore cdk – Emette il sintetizzato AWS CloudFormazione modello
- distribuzione cdk – Distribuisce questo stack nell'account e nella regione AWS predefiniti
- cd diff – Confronta lo stack distribuito con lo stato corrente
- cdk documenti – Apre la documentazione di AWS CDK
La sezione successiva mostra come distribuire l'applicazione AWS CDK.
Distribuisci l'applicazione AWS CDK
L'applicazione AWS CDK verrà distribuita nella regione predefinita in base alla configurazione della workstation. Se vuoi forzare la distribuzione in una regione specifica, imposta il tuo AWS_DEFAULT_REGION ambiente variabile di conseguenza.
A questo punto, puoi distribuire l'applicazione AWS CDK. Per prima cosa avvii lo stack di rete VPC:
Se ti viene richiesto, entra y per procedere con la distribuzione. Dovresti vedere un elenco di risorse AWS di cui viene eseguito il provisioning nello stack. Questo passaggio richiede circa 3 minuti per essere completato.
Quindi avvii lo stack dell'applicazione Web:
Dopo aver analizzato lo stack, AWS CDK visualizzerà l'elenco delle risorse nello stack. Immettere y per procedere con la distribuzione. Questo passaggio richiede circa 5 minuti.

Annota il WebApplicationServiceURL dall'output da utilizzare in seguito. Puoi anche recuperarlo sulla console AWS CloudFormation, sotto il file GenerativeAiDemoWebStack impilare le uscite.
Ora, avvia lo stack di endpoint del modello AI per la generazione di immagini:
Questo passaggio richiede circa 8 minuti. L'endpoint del modello di generazione dell'immagine è distribuito, ora possiamo usarlo.
Usa il modello AI per la generazione di immagini
Il primo esempio dimostra come utilizzare Stable Diffusion, una potente tecnica di modellazione generativa che consente la creazione di immagini di alta qualità dai prompt di testo.
- Accedere all'applicazione Web utilizzando il file
WebApplicationServiceURLdall'uscita diGenerativeAiDemoWebStacknel tuo browser.
- Nel pannello di navigazione, scegli Generazione di immagini.
- I Nome endpoint SageMaker ed URL GW dell'API i campi saranno precompilati, ma puoi modificare la richiesta per la descrizione dell'immagine, se lo desideri.
- Scegli Genera immagine.

- L'applicazione effettuerà una chiamata all'endpoint SageMaker. Ci vogliono pochi secondi. Verrà visualizzata un'immagine con le caratteristiche nella descrizione dell'immagine.

Usa il modello AI per la generazione del testo
Il secondo esempio è incentrato sull'utilizzo del modello FLAN-T5-XL, che è una base o modello linguistico di grandi dimensioni (LLM), per ottenere l'apprendimento nel contesto per la generazione di testo, affrontando anche un'ampia gamma di comprensione del linguaggio naturale (NLU) e naturale attività di generazione del linguaggio (NLG).
Alcuni ambienti potrebbero limitare il numero di endpoint che puoi avviare contemporaneamente. In tal caso, puoi avviare un endpoint SageMaker alla volta. Per arrestare un endpoint SageMaker nell'app AWS CDK, devi distruggere lo stack di endpoint distribuito e prima di avviare l'altro stack di endpoint. Per rifiutare l'endpoint del modello AI di generazione dell'immagine, immetti il seguente comando:
Quindi avvia lo stack di endpoint del modello AI di generazione del testo:
Inserisci y quando richiesto.
Dopo l'avvio dello stack dell'endpoint del modello di generazione del testo, completare i seguenti passaggi:
- Torna all'applicazione web e scegli Generazione di testo nel pannello di navigazione.
- I Contesto di input Il campo è precompilato con una conversazione tra un cliente e un agente riguardante un problema con il telefono del cliente, ma puoi inserire il tuo contesto se lo desideri.

- Sotto il contesto, troverai alcune query precompilate nel menu a discesa. Scegli una query e scegli Genera risposta.
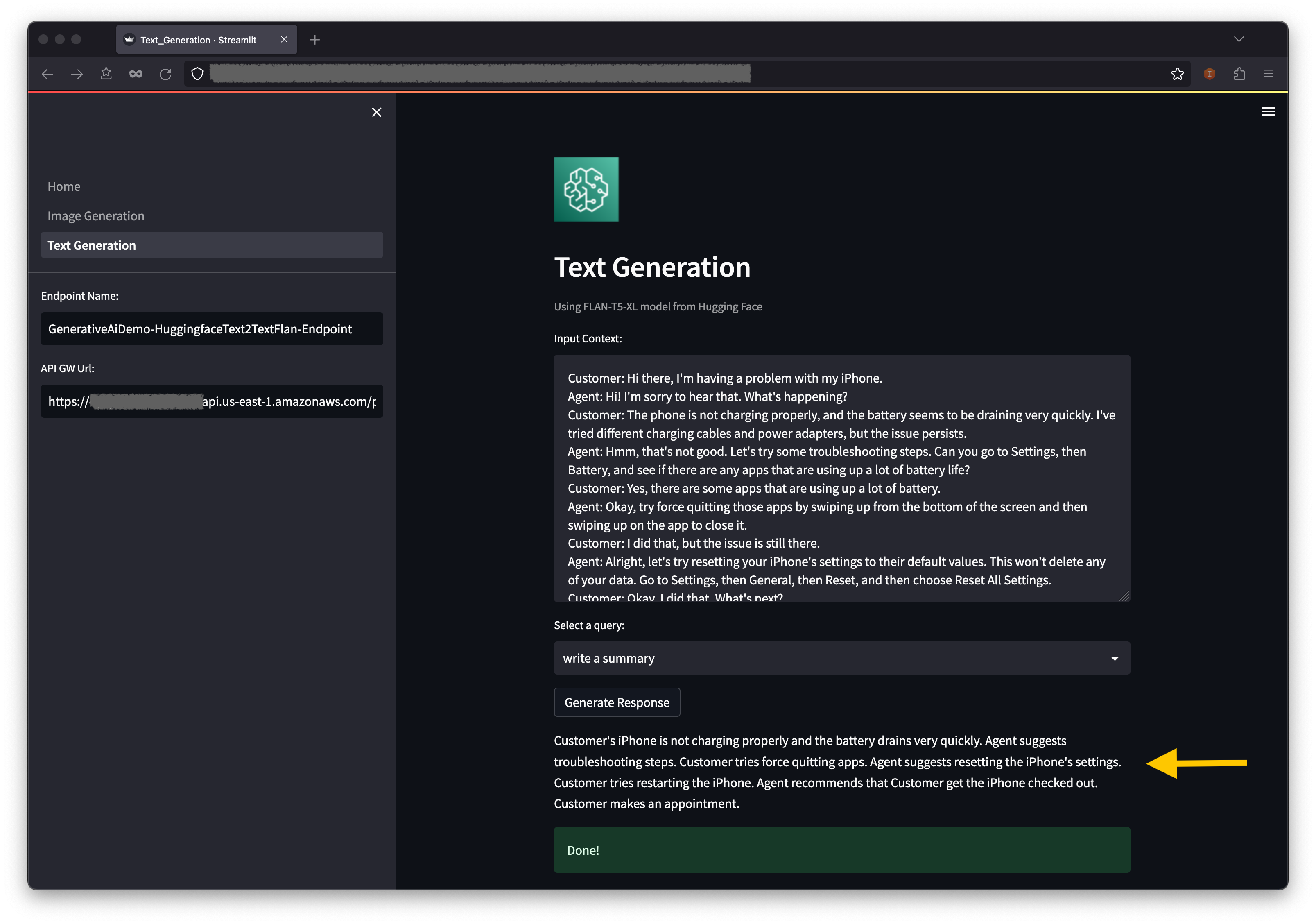
- Puoi anche inserire la tua query nel file Query di input campo e quindi scegliere Genera risposta.

Visualizza le risorse distribuite sulla console
Nella console AWS CloudFormation, scegli Stacks nel riquadro di navigazione per visualizzare gli stack distribuiti.
Nella console Amazon ECS, puoi vedere i cluster sul file Cluster .

Nella console AWS Lambda, puoi vedere le funzioni sul file funzioni .
Nella console API Gateway, puoi vedere gli endpoint API Gateway in API .

Nella console SageMaker, puoi vedere gli endpoint del modello distribuito su endpoint .
Quando gli stack vengono lanciati, vengono generati alcuni parametri. Questi sono memorizzati nel file Archivio parametri di AWS Systems Manager. Per visualizzarli, scegli Archivio parametri nel riquadro di navigazione in Gestore di sistemi AWS console.

ripulire
Per evitare costi inutili, ripulisci tutta l'infrastruttura creata con il seguente comando sulla tua workstation:
entrare y al sollecito. Questo passaggio richiede circa 10 minuti. Controlla se tutte le risorse vengono eliminate sulla console. Elimina anche i bucket S3 di asset creati da AWS CDK sulla console Amazon S3 e i repository di asset su Amazon ECR.
Conclusione
Come dimostrato in questo post, puoi utilizzare AWS CDK per distribuire modelli di intelligenza artificiale generativa in JumpStart. Abbiamo mostrato un esempio di generazione di immagini e un esempio di generazione di testo utilizzando un'interfaccia utente basata su Streamlit, Lambda e API Gateway.
Ora puoi creare i tuoi progetti di intelligenza artificiale generativa utilizzando modelli di intelligenza artificiale preaddestrati in JumpStart. Puoi anche estendere questo progetto per mettere a punto i modelli di base per il tuo caso d'uso e controllare l'accesso agli endpoint di API Gateway.
Ti invitiamo a testare la soluzione e a contribuire al progetto su GitHub. Condividi i tuoi pensieri su questo tutorial nei commenti!
Riepilogo licenza License
Questo codice di esempio è reso disponibile con una licenza MIT modificata. Vedi il LICENZA ILLIMITATA file per ulteriori informazioni. Inoltre, rivedere le rispettive licenze per il diffusione stabile ed flan-t5-xl modelli su Hugging Face.
Circa gli autori
 Hantzley Tauckoor è un APJ Partner Solutions Architecture Leader con sede a Singapore. Ha 20 anni di esperienza nel settore ICT in molteplici aree funzionali, tra cui l'architettura delle soluzioni, lo sviluppo aziendale, la strategia di vendita, la consulenza e la leadership. Dirige un team di Senior Solutions Architects che consente ai partner di sviluppare soluzioni congiunte, costruire capacità tecniche e guidarli attraverso la fase di implementazione man mano che i clienti migrano e modernizzano le loro applicazioni ad AWS.
Hantzley Tauckoor è un APJ Partner Solutions Architecture Leader con sede a Singapore. Ha 20 anni di esperienza nel settore ICT in molteplici aree funzionali, tra cui l'architettura delle soluzioni, lo sviluppo aziendale, la strategia di vendita, la consulenza e la leadership. Dirige un team di Senior Solutions Architects che consente ai partner di sviluppare soluzioni congiunte, costruire capacità tecniche e guidarli attraverso la fase di implementazione man mano che i clienti migrano e modernizzano le loro applicazioni ad AWS.
 Kwonyul Choi è un CTO di BABITALK, una startup coreana di piattaforme per la cura della bellezza, con sede a Seoul. Prima di ricoprire questo ruolo, Kownyul ha lavorato come Software Development Engineer presso AWS, concentrandosi su AWS CDK e Amazon SageMaker.
Kwonyul Choi è un CTO di BABITALK, una startup coreana di piattaforme per la cura della bellezza, con sede a Seoul. Prima di ricoprire questo ruolo, Kownyul ha lavorato come Software Development Engineer presso AWS, concentrandosi su AWS CDK e Amazon SageMaker.
 Arunprasath Shankar è un Senior AI/ML Specialist Solutions Architect di AWS, che aiuta i clienti globali a scalare le loro soluzioni di AI in modo efficace ed efficiente nel cloud. Nel tempo libero, ad Arun piace guardare film di fantascienza e ascoltare musica classica.
Arunprasath Shankar è un Senior AI/ML Specialist Solutions Architect di AWS, che aiuta i clienti globali a scalare le loro soluzioni di AI in modo efficace ed efficiente nel cloud. Nel tempo libero, ad Arun piace guardare film di fantascienza e ascoltare musica classica.
 Satish Upreti è Migration Lead PSA and Security SME nell'organizzazione partner di APJ. Satish ha 20 anni di esperienza nelle tecnologie di cloud privato e cloud pubblico on-premise. Da quando è entrato in AWS nell'agosto 2020 come specialista della migrazione, fornisce un'ampia consulenza tecnica e supporto ai partner AWS per pianificare e implementare migrazioni complesse.
Satish Upreti è Migration Lead PSA and Security SME nell'organizzazione partner di APJ. Satish ha 20 anni di esperienza nelle tecnologie di cloud privato e cloud pubblico on-premise. Da quando è entrato in AWS nell'agosto 2020 come specialista della migrazione, fornisce un'ampia consulenza tecnica e supporto ai partner AWS per pianificare e implementare migrazioni complesse.
Appendice: procedura dettagliata del codice
In questa sezione viene fornita una panoramica del codice in questo progetto.
Applicazione AWS CDK
L'applicazione principale di AWS CDK è contenuta nel file app.py file nella directory principale. Il progetto è composto da più stack, quindi dobbiamo importare gli stack:
Definiamo i nostri modelli di IA generativa e otteniamo i relativi URI da SageMaker:
La funzione get_sagemaker_uris recupera tutte le informazioni sul modello da JumpStart. Vedere script/sagemaker_uri.py.
Quindi, istanziamo gli stack:
Il primo stack da avviare è lo stack VPC, GenerativeAiVpcNetworkStack. Lo stack dell'applicazione Web, GenerativeAiDemoWebStack, dipende dallo stack VPC. La dipendenza viene eseguita tramite il parametro che passa vpc=network_stack.vpc.
See app.py per il codice completo
Stack di rete VPC
Nello stack GenerativeAiVpcNetworkStack, creiamo un VPC con una sottorete pubblica e una sottorete privata che si estende su due zone di disponibilità:
See /stack/generative_ai_vpc_network_stack.py per il codice completo
Stack di applicazioni web dimostrative
Nello stack GenerativeAiDemoWebStack, lanciamo le funzioni Lambda e i rispettivi endpoint API Gateway attraverso i quali l'applicazione Web interagisce con gli endpoint del modello SageMaker. Vedere il seguente frammento di codice:
L'applicazione Web è containerizzata e ospitata su Amazon ECS con Fargate. Vedere il seguente frammento di codice:
See /stack/generative_ai_demo_web_stack.py per il codice completo
Stack di endpoint del modello SageMaker per la generazione di immagini
Lo stack GenerativeAiTxt2imgSagemakerStack crea l'endpoint del modello di generazione dell'immagine da JumpStart e archivia il nome dell'endpoint in Systems Manager Parameter Store. Questo parametro verrà utilizzato dall'applicazione web. Vedere il seguente codice:
See /stack/generative_ai_txt2img_sagemaker_stack.py per il codice completo
Stack di endpoint del modello SageMaker per la generazione di NLU e testo
Lo stack GenerativeAiTxt2nluSagemakerStack crea l'NLU e l'endpoint del modello di generazione del testo da JumpStart e archivia il nome dell'endpoint in Systems Manager Parameter Store. Questo parametro verrà utilizzato anche dall'applicazione web. Vedere il seguente codice:
See /stack/generative_ai_txt2nlu_sagemaker_stack.py per il codice completo
applicazione web
L'applicazione web si trova in /web-app directory. È un'applicazione Streamlit che è containerizzata secondo il Dockerfile:
Per ulteriori informazioni su Streamlit, vedere Documentazione semplificata.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/deploy-generative-ai-models-from-amazon-sagemaker-jumpstart-using-the-aws-cdk/
- :ha
- :È
- $ SU
- 1
- 10
- 100
- 20
- 20 anni
- 2020
- 2023
- 7
- 8
- 9
- a
- Chi siamo
- accesso
- accessibile
- accessibile
- di conseguenza
- Il mio account
- Raggiungere
- operanti in
- adattare
- indirizzamento
- Adottando
- Adozione
- avanzamento
- consigli
- Agente
- AI
- AI-alimentato
- AI / ML
- Algoritmi
- Tutti
- Consentire
- già
- anche
- Amazon
- Gateway API Amazon
- Amazon Sage Maker
- JumpStart di Amazon SageMaker
- Amazon Web Services
- an
- l'analisi
- ed
- in qualsiasi
- api
- App
- Applicazioni
- applicazioni
- applicazioni
- Aprile
- architettura
- SONO
- aree
- in giro
- AS
- Attività
- At
- attenzione
- AGOSTO
- disponibilità
- disponibile
- evitare
- AWS
- AWS Cloud9
- AWS CloudFormazione
- AWS Lambda
- precedente
- equilibratore
- basato
- BAT
- BE
- bellissimo
- Bellezza ed estetica
- prima
- essendo
- CREDIAMO
- fra
- bootstrap
- ampio
- del browser
- costruire
- costruito
- affari
- sviluppo commerciale
- aziende
- ma
- by
- chiamata
- Materiale
- funzionalità
- Ultra-Grande
- catturato
- che
- Custodie
- casi
- CD
- centri
- il cambiamento
- caratteristiche
- oneri
- dai un'occhiata
- Scegli
- cliente
- clienti
- Cloud
- Cloud9
- codice
- viene
- Uncommon
- comunemente
- completamento di una
- complesso
- Calcolare
- computer
- Configurazione
- consolle
- costruire
- consulting
- consumato
- contenute
- Contenitore
- contiene
- contenuto
- contesto
- contribuire
- di controllo
- Conversazione
- Conversazioni
- correggere
- Costo
- creare
- creato
- crea
- creazione
- CTO
- Corrente
- costume
- cliente
- esperienza del cliente
- Servizio clienti
- Clienti
- personalizzare
- bordo tagliente
- dati
- scienza dei dati
- giorno
- decenni
- Predefinito
- definisce
- dimostrato
- dimostra
- Dipendenza
- dipendente
- schierare
- schierato
- distribuzione
- deployment
- Distribuisce
- descrizione
- distruggere
- sviluppare
- sviluppatori
- Mercato
- diverso
- Emittente
- Dsiplay
- disturbare
- docker
- documento
- fatto
- Dont
- giù
- ogni
- facilmente
- facile
- in maniera efficace
- in modo efficiente
- enable
- Abilita
- fine
- endpoint
- ingegnere
- entrare
- Ambiente
- ambienti
- stimato
- Etere (ETH)
- Ogni
- ogni giorno
- di tutti
- esempio
- Esempi
- coinvolgenti
- esistito
- esperienza
- estendere
- estensivo
- Faccia
- falso
- familiare
- famiglia
- Caratteristiche
- pochi
- campo
- campi
- Compila il
- Trovare
- Nome
- Focus
- i seguenti
- segue
- Nel
- forza
- Fondazione
- frazione
- Contesto
- da
- pieno
- function
- funzionale
- funzioni
- porta
- raccogliere
- raccolta
- scopo generale
- generato
- ELETTRICA
- generativo
- AI generativa
- ottenere
- Idiota
- globali
- Globalmente
- Crescita
- Avere
- avendo
- he
- Aiuto
- aiutare
- alta qualità
- il suo
- Casa
- host
- ospitato
- ORE
- Come
- Tutorial
- HTML
- http
- HTTPS
- ICT
- idee
- if
- Immagine
- generazione di immagini
- immagini
- immaginazione
- realizzare
- implementazione
- importare
- in
- Compreso
- incorporare
- industrie
- industria
- Punto di flessione
- informazioni
- Infrastruttura
- install
- installazione
- installato
- esempio
- invece
- integrare
- integrazioni
- interagisce
- Interfaccia
- ai miglioramenti
- invitare
- problema
- IT
- accoppiamento
- giunto
- jpg
- json
- Coreano
- atterraggio
- pagina di destinazione
- Lingua
- Le Lingue
- grandi
- dopo
- con i più recenti
- lanciare
- lanciato
- lancio
- portare
- leader
- Leadership
- Leads
- IMPARARE
- apprendimento
- Lasciare
- Biblioteca
- Licenza
- licenze
- piace
- LIMITE
- linea
- Lista
- Ascolto
- elenchi
- caricare
- locale
- collocato
- macchina
- machine learning
- macchine
- fatto
- Principale
- make
- FA
- gestire
- gestione
- direttore
- molti
- massiccio
- Menu
- forza
- migrare
- migrazione
- verbale
- CON
- ML
- Tecniche di machine learning
- modello
- modellismo
- modelli
- modernizzare
- modificato
- Scopri di più
- Film
- multiplo
- Musica
- devono obbligatoriamente:
- Nome
- Naturale
- Linguaggio naturale
- Generazione del linguaggio naturale
- Comprensione del linguaggio naturale
- Natura
- Navigazione
- Bisogno
- esigenze
- Rete
- New
- GENERAZIONE
- NLG
- NLU
- nodo
- computer portatili
- adesso
- numero
- of
- Offerte
- on
- ONE
- in corso
- esclusivamente
- open source
- Software open source
- apre
- or
- minimo
- organizzazione
- i
- Altro
- nostro
- produzione
- ancora
- panoramica
- proprio
- pacchetto
- pagina
- vetro
- paradigma
- parametro
- parametri
- partner
- partner
- Di passaggio
- eseguire
- fase
- telefono
- immagine
- piano
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- possibilità
- Post
- potenziale
- alimentato
- potente
- prerequisiti
- Stampa
- Precedente
- un bagno
- Problema
- Produzione
- Programmazione
- linguaggi di programmazione
- progetto
- progetti
- fornire
- fornisce
- la percezione
- cloud pubblico
- pubblicamente
- Python
- query
- rapidamente
- gamma
- veloce
- rapidamente
- pronto
- recentemente
- di cui
- per quanto riguarda
- regione
- relazionato
- deposito
- necessario
- Requisiti
- risorsa
- Risorse
- quelli
- recensioni
- rivoluzionando
- destra
- Ruolo
- radice
- Correre
- running
- sagemaker
- vendite
- stesso
- Scala
- fantascienza
- Scienze
- graffiare
- sdk
- Secondo
- secondo
- Sezione
- problemi di
- vedere
- semi
- AUTO
- anziano
- sentimento
- Seoul
- serverless
- Server
- servizio
- Servizi
- set
- flessibile.
- Condividi
- spostamento
- dovrebbero
- mostrare attraverso le sue creazioni
- ha mostrato
- mostrato
- Spettacoli
- Un'espansione
- da
- Singapore
- Taglia
- piccole
- EMS
- So
- Software
- lo sviluppo del software
- soluzione
- Soluzioni
- alcuni
- Fonte
- lo spazio
- specialista
- specifico
- specificato
- stabile
- pila
- Stacks
- Standard
- iniziato
- startup
- Startup
- step
- Passi
- Fermare
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- Storie
- Strategia
- La struttura
- sottorete
- supporto
- sicuro
- SISTEMI DI TRATTAMENTO
- prende
- Task
- task
- team
- Consulenza
- tecniche
- Tecnologie
- Tecnologia
- dice
- modelli
- test
- test
- generazione di testo
- che
- I
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- Attraverso
- tempo
- titano
- a
- toolkit
- strumenti
- tradizione
- tradizionale
- Treni
- allenato
- Training
- Trasformare
- tendenze
- vero
- veramente
- TURNO
- lezione
- seconda
- Digitare
- Tipi di
- tipico
- tipicamente
- per
- e una comprensione reciproca
- svelato
- aggiornamento
- upgrade
- uso
- caso d'uso
- utilizzato
- Utente
- Interfaccia utente
- utilizzando
- utilizzare
- vario
- Fisso
- verificare
- versione
- via
- Video
- Visualizza
- virtuale
- potenzialmente
- Visita
- volere
- Prima
- guardare
- Modo..
- we
- sito web
- applicazione web
- servizi web
- WELL
- quale
- while
- largo
- Vasta gamma
- molto diffuso
- wikipedia
- volere
- finestre
- con
- senza
- Lavora
- lavorato
- flussi di lavoro
- stazione di lavoro
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zone