Con l'uso del cloud computing, dei big data e di strumenti di machine learning (ML) come Amazzone Atena or Amazon Sage Maker sono diventati disponibili e utilizzabili da chiunque senza troppi sforzi nella creazione e nella manutenzione. Le aziende industriali guardano sempre più all’analisi dei dati e al processo decisionale basato sui dati per aumentare l’efficienza delle risorse nell’intero portafoglio, dalle operazioni all’esecuzione della manutenzione predittiva o della pianificazione.
A causa della velocità del cambiamento nell’IT, i clienti dei settori tradizionali si trovano ad affrontare un dilemma in termini di competenze. Da un lato, gli analisti e gli esperti del settore hanno una conoscenza molto approfondita dei dati in questione e della loro interpretazione, ma spesso non hanno accesso agli strumenti di data science e ai linguaggi di programmazione di alto livello come Python. D’altro canto, gli esperti di data science spesso non hanno l’esperienza necessaria per interpretare il contenuto dei dati della macchina e filtrarlo in base a ciò che è rilevante. Questo dilemma ostacola la creazione di modelli efficienti che utilizzano i dati per generare insight rilevanti per il business.
Tela di Amazon SageMaker affronta questo dilemma fornendo agli esperti del settore un'interfaccia senza codice per creare potenti modelli di analisi e ML, come previsioni, classificazione o modelli di regressione. Consente inoltre di distribuire e condividere questi modelli con specialisti ML e MLOps dopo la creazione.
In questo post ti mostriamo come utilizzare SageMaker Canvas per curare e selezionare le funzionalità giuste nei tuoi dati, quindi addestrare un modello di previsione per il rilevamento di anomalie, utilizzando la funzionalità senza codice di SageMaker Canvas per l'ottimizzazione del modello.
Rilevamento anomalie per l'industria manifatturiera
Al momento in cui scrivo, SageMaker Canvas si concentra su casi d'uso aziendali tipici, come previsione, regressione e classificazione. In questo post dimostriamo come queste funzionalità possano anche aiutare a rilevare punti dati anomali complessi. Questo caso d'uso è rilevante, ad esempio, per individuare malfunzionamenti o operazioni insolite di macchine industriali.
Il rilevamento delle anomalie è importante nel settore industriale, perché le macchine (dai treni alle turbine) sono normalmente molto affidabili, con tempi di guasto che durano anni. La maggior parte dei dati provenienti da queste macchine, come le letture dei sensori di temperatura o i messaggi di stato, descrivono il normale funzionamento e hanno un valore limitato per il processo decisionale. Gli ingegneri cercano dati anomali quando indagano sulle cause profonde di un guasto o come indicatori di allarme per guasti futuri, mentre i responsabili delle prestazioni esaminano i dati anomali per identificare potenziali miglioramenti. Pertanto, il primo passo tipico nel passaggio a un processo decisionale basato sui dati si basa sulla ricerca di dati rilevanti (anomali).
In questo post, utilizziamo SageMaker Canvas per curare e selezionare le funzionalità giuste nei dati, quindi addestrare un modello di previsione per il rilevamento delle anomalie, utilizzando la funzionalità senza codice di SageMaker Canvas per l'ottimizzazione del modello. Quindi distribuiamo il modello come endpoint SageMaker.
Panoramica della soluzione
Per il nostro caso d'uso di rilevamento di anomalie, addestriamo un modello di previsione per prevedere una caratteristica del normale funzionamento di una macchina, come la temperatura del motore indicata in un'auto, da caratteristiche che influenzano, come la velocità e la coppia recentemente applicata nell'auto . Per il rilevamento di anomalie su un nuovo campione di misurazioni, confrontiamo le previsioni del modello per la caratteristica con le osservazioni fornite.
Per l'esempio del motore dell'auto, un esperto del settore ottiene misurazioni della temperatura normale del motore, della coppia recente del motore, della temperatura ambiente e di altri potenziali fattori d'influenza. Questi consentono di addestrare un modello per prevedere la temperatura dalle altre funzionalità. Quindi possiamo utilizzare il modello per prevedere regolarmente la temperatura del motore. Quando la temperatura prevista per tali dati è simile alla temperatura osservata in tali dati, il motore funziona normalmente; una discrepanza indicherà un'anomalia, come un guasto al sistema di raffreddamento o un difetto nel motore.
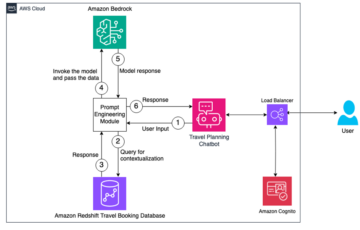
Il diagramma seguente illustra l'architettura della soluzione.
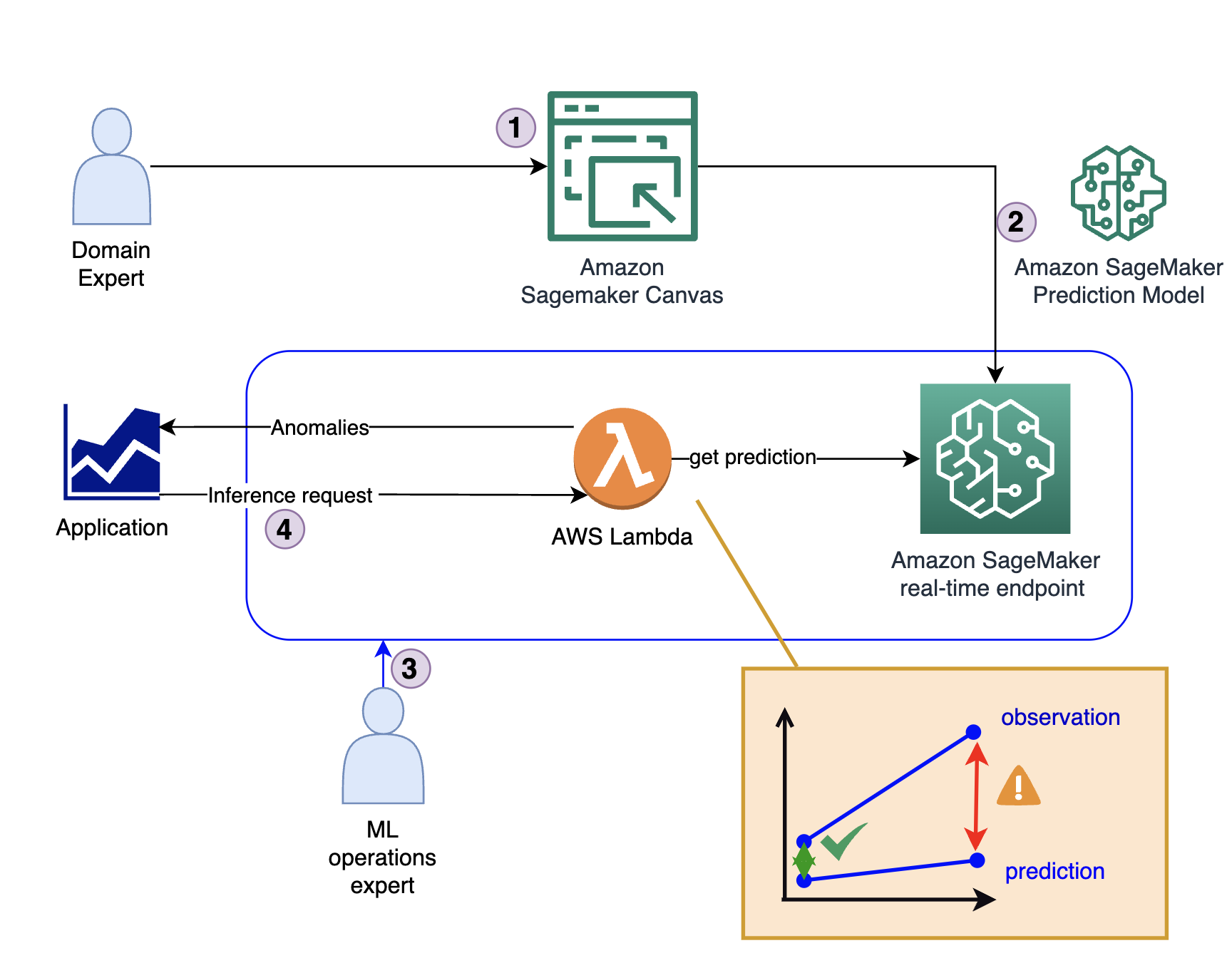
La soluzione si compone di quattro passaggi chiave:
- L'esperto del dominio crea il modello iniziale, inclusa l'analisi dei dati e la selezione delle funzionalità utilizzando SageMaker Canvas.
- L'esperto di dominio condivide il modello tramite il file Registro dei modelli di Amazon SageMaker oppure lo distribuisce direttamente come endpoint in tempo reale.
- Un esperto MLOps crea l'infrastruttura di inferenza e il codice che traduce l'output del modello da una previsione in un indicatore di anomalia. Questo codice viene generalmente eseguito all'interno di un file AWS Lambda funzione.
- Quando un'applicazione richiede il rilevamento di un'anomalia, chiama la funzione Lambda, che utilizza il modello per l'inferenza e fornisce la risposta (indipendentemente dal fatto che si tratti o meno di un'anomalia).
Prerequisiti
Per seguire questo post, è necessario soddisfare i seguenti prerequisiti:
Crea il modello utilizzando SageMaker
Il processo di creazione del modello segue i passaggi standard per creare un modello di regressione in SageMaker Canvas. Per ulteriori informazioni, fare riferimento a Iniziare con l'utilizzo di Amazon SageMaker Canvas.
Innanzitutto, l'esperto del dominio carica i dati rilevanti in SageMaker Canvas, come una serie temporale di misurazioni. Per questo post utilizziamo un file CSV contenente le misure (generate sinteticamente) di un motore elettrico. Per i dettagli, fare riferimento a Importa i dati in Canvas. I dati campione utilizzati sono disponibili per il download come file CSV.
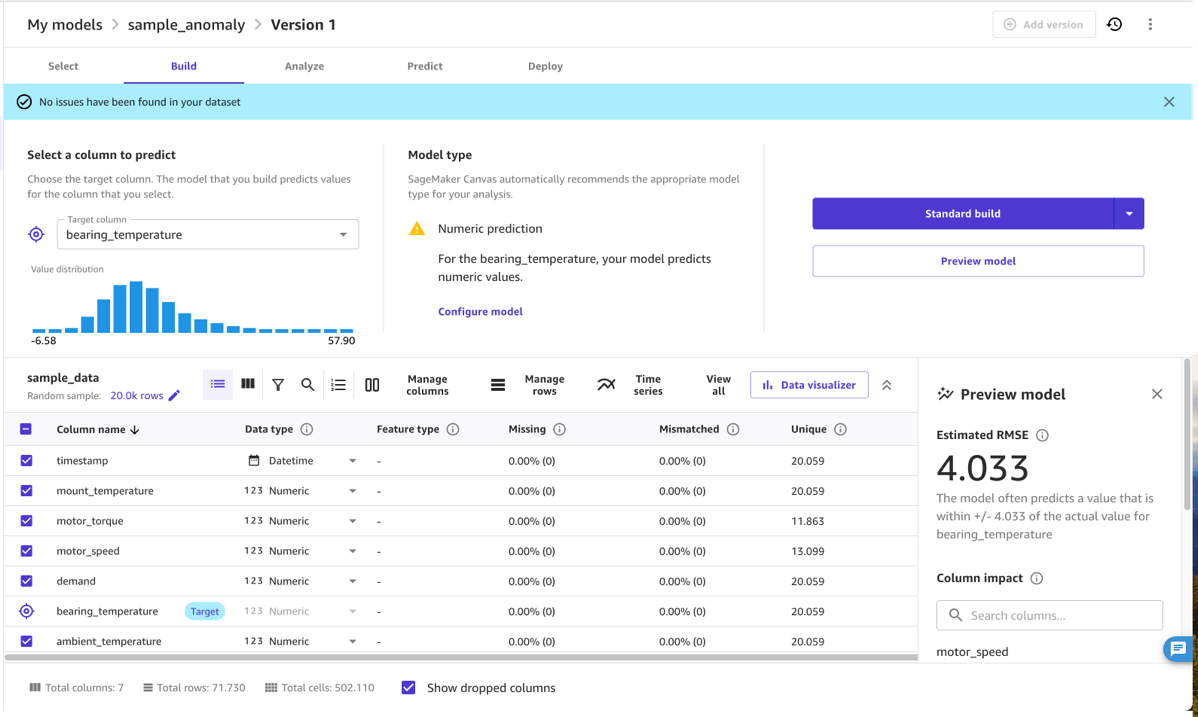
Cura i dati con SageMaker Canvas
Dopo che i dati sono stati caricati, l'esperto del dominio può utilizzare SageMaker Canvas per curare i dati utilizzati nel modello finale. Per questo, l'esperto seleziona quelle colonne che contengono misurazioni caratteristiche per il problema in questione. Più precisamente, l'esperto seleziona colonne che sono legate tra loro, ad esempio, da una relazione fisica come una curva pressione-temperatura, e dove un cambiamento in tale relazione rappresenta un'anomalia rilevante per il loro caso d'uso. Il modello di rilevamento delle anomalie apprenderà la normale relazione tra le colonne selezionate e indicherà quando i dati non sono conformi ad esso, ad esempio una temperatura del motore anormalmente elevata dato il carico corrente sul motore.
In pratica, l'esperto del dominio deve selezionare un insieme di colonne di input adeguate e una colonna di destinazione. Gli input sono in genere la raccolta di quantità (numeriche o categoriche) che determinano il comportamento di una macchina, dalle impostazioni della domanda, al carico, alla velocità o alla temperatura ambiente. L'output è in genere una quantità numerica che indica le prestazioni del funzionamento della macchina, ad esempio una temperatura che misura la dissipazione di energia o un'altra metrica delle prestazioni che cambia quando la macchina funziona in condizioni non ottimali.
Per illustrare il concetto di quali quantità selezionare per input e output, consideriamo alcuni esempi:
- Per le apparecchiature rotanti, come il modello che costruiamo in questo post, gli input tipici sono la velocità di rotazione, la coppia (corrente e storia) e la temperatura ambiente, e gli obiettivi sono le temperature risultanti dei cuscinetti o del motore che indicano buone condizioni operative delle rotazioni
- Per una turbina eolica, gli input tipici sono la storia attuale e recente della velocità del vento e le impostazioni delle pale del rotore, e la quantità target è la potenza prodotta o la velocità di rotazione
- Per un processo chimico, gli input tipici sono la percentuale dei diversi ingredienti e la temperatura ambiente, mentre gli obiettivi sono il calore prodotto o la viscosità del prodotto finale
- Per le apparecchiature in movimento come le porte scorrevoli, gli input tipici sono la potenza assorbita dai motori e il valore target è la velocità o il tempo di completamento del movimento
- Per un sistema HVAC, gli input tipici sono la differenza di temperatura raggiunta e le impostazioni di carico, mentre la quantità target è il consumo energetico misurato
In definitiva, gli input e gli obiettivi corretti per una determinata apparecchiatura dipenderanno dal caso d'uso e dal comportamento anomalo da rilevare e sono meglio conosciuti da un esperto del settore che abbia familiarità con le complessità del set di dati specifico.
Nella maggior parte dei casi, selezionare le quantità di input e di destinazione adeguate significa selezionare solo le colonne giuste e contrassegnare la colonna di destinazione (per questo esempio, bearing_temperature). Tuttavia, un esperto del settore può anche utilizzare le funzionalità senza codice di SageMaker Canvas per trasformare colonne e perfezionare o aggregare i dati. Ad esempio, puoi estrarre o filtrare date o timestamp specifici dai dati che non sono rilevanti. SageMaker Canvas supporta questo processo, mostrando statistiche sulle quantità selezionate, consentendoti di capire se una quantità presenta valori anomali e spread che potrebbero influenzare i risultati del modello.
Addestrare, mettere a punto e valutare il modello
Dopo che l'esperto del dominio ha selezionato le colonne adatte nel set di dati, può addestrare il modello per apprendere la relazione tra input e output. Più precisamente, il modello imparerà a prevedere il valore target selezionato dagli input.
Normalmente, puoi utilizzare SageMaker Canvas Anteprima del modello opzione. Ciò fornisce una rapida indicazione della qualità del modello prevista e consente di analizzare l'effetto che i diversi input hanno sulla metrica di output. Ad esempio, nello screenshot seguente, il modello è maggiormente influenzato da motor_speed ed ambient_temperature metriche durante la previsione bearing_temperature. Ciò è sensato perché queste temperature sono strettamente correlate. Allo stesso tempo, è probabile che un ulteriore attrito o altri mezzi di perdita di energia influiscano su questo.
Per la qualità del modello, l'RMSE del modello è un indicatore della capacità del modello di apprendere il comportamento normale nei dati di addestramento e riprodurre le relazioni tra le misure di input e di output. Ad esempio, nel modello seguente, il modello dovrebbe essere in grado di prevedere il risultato corretto motor_bearing temperatura entro 3.67 gradi Celsius, quindi possiamo considerare come un'anomalia una deviazione della temperatura reale dalla previsione del modello superiore, ad esempio, a 7.4 gradi. La soglia effettiva da utilizzare, tuttavia, dipenderà dalla sensibilità richiesta nello scenario di distribuzione.
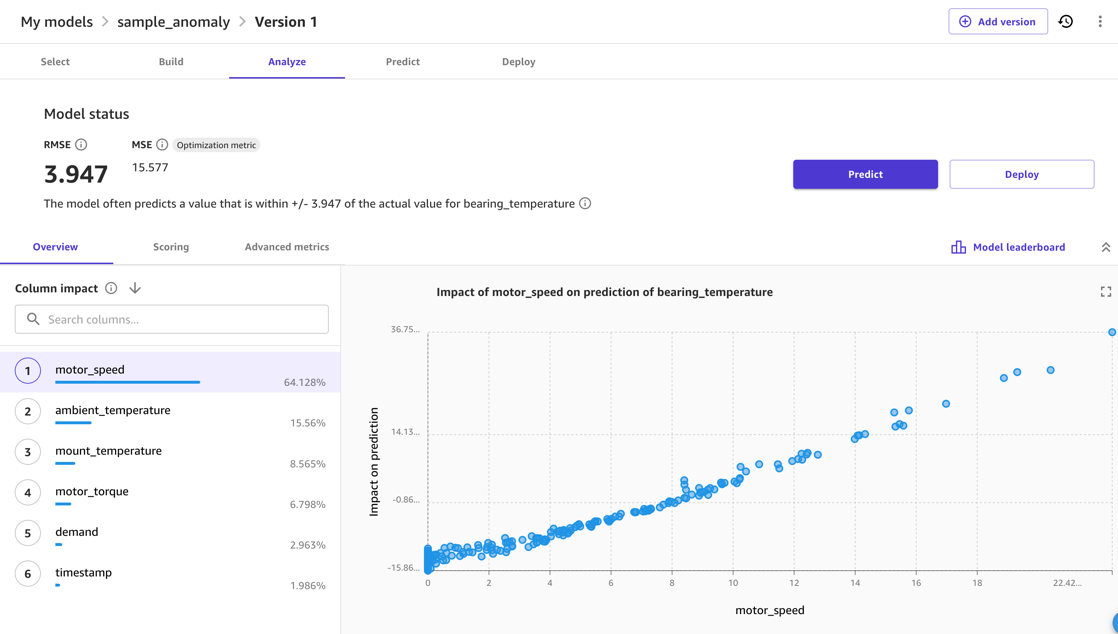
Infine, una volta terminata la valutazione e l'ottimizzazione del modello, è possibile avviare l'addestramento completo del modello che creerà il modello da utilizzare per l'inferenza.
Distribuire il modello
Sebbene SageMaker Canvas possa utilizzare un modello per l'inferenza, la distribuzione produttiva per il rilevamento di anomalie richiede la distribuzione del modello all'esterno di SageMaker Canvas. Più precisamente, dobbiamo distribuire il modello come endpoint.
In questo post e per semplicità, distribuiamo il modello come endpoint direttamente da SageMaker Canvas. Per istruzioni, fare riferimento a Distribuisci i tuoi modelli a un endpoint. Assicurati di prendere nota del nome della distribuzione e di considerare il prezzo del tipo di istanza su cui distribuisci (per questo post utilizziamo ml.m5.large). SageMaker Canvas creerà quindi un endpoint del modello che può essere chiamato per ottenere previsioni.
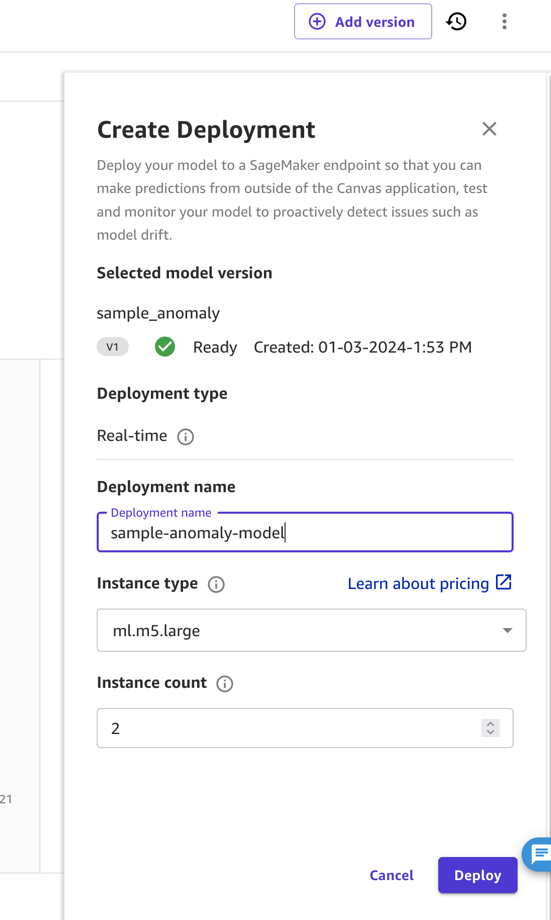
Negli ambienti industriali, un modello deve essere sottoposto a test approfonditi prima di poter essere implementato. Per questo, l'esperto del dominio non lo distribuirà, ma condividerà invece il modello nel registro dei modelli SageMaker. Qui può subentrare un esperto delle operazioni MLOps. In genere, l'esperto testerà l'endpoint del modello, valuterà la dimensione delle apparecchiature informatiche necessarie per l'applicazione di destinazione e determinerà la distribuzione più conveniente, come la distribuzione per l'inferenza serverless o l'inferenza batch. Questi passaggi sono normalmente automatizzati (ad esempio, utilizzando Pipeline di Amazon Sagemaker oppure SDK Amazon).
Utilizzare il modello per il rilevamento delle anomalie
Nel passaggio precedente, abbiamo creato una distribuzione del modello in SageMaker Canvas, chiamata canvas-sample-anomaly-model. Possiamo usarlo per ottenere previsioni di a bearing_temperature valore in base alle altre colonne nel set di dati. Ora vogliamo utilizzare questo endpoint per rilevare anomalie.
Per identificare dati anomali, il nostro modello utilizzerà l'endpoint del modello di previsione per ottenere il valore previsto della metrica di destinazione e quindi confrontare il valore previsto con il valore effettivo nei dati. Il valore previsto indica il valore previsto per la nostra metrica target in base ai dati di addestramento. La differenza di questo valore quindi è una metrica per l'anomalia dei dati effettivi osservati. Possiamo utilizzare il seguente codice:
Il codice precedente esegue le seguenti azioni:
- I dati di input vengono filtrati fino alle caratteristiche giuste (funzione “
input_transformer"). - L'endpoint del modello SageMaker viene richiamato con i dati filtrati (funzione "
do_inference"), dove gestiamo la formattazione di input e output in base al codice di esempio fornito all'apertura della pagina dei dettagli della nostra distribuzione in SageMaker Canvas. - Il risultato dell'invocazione viene unito ai dati di input originali e la differenza viene memorizzata nella colonna errori (funzione “
output_transform").
Trova anomalie e valuta eventi anomali
In una configurazione tipica, il codice per ottenere anomalie viene eseguito in una funzione Lambda. La funzione Lambda può essere chiamata da un'applicazione o Gateway API Amazon. La funzione principale restituisce un punteggio di anomalia per ogni riga di dati di input, in questo caso una serie temporale di un punteggio di anomalia.
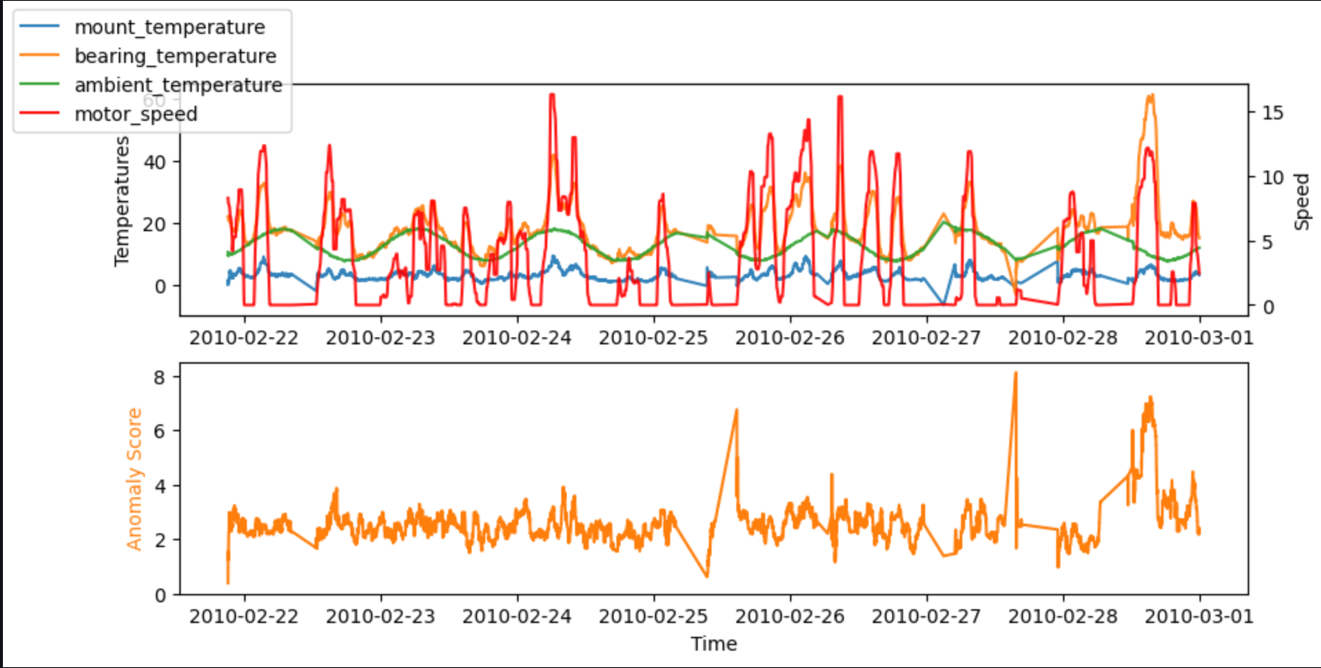
Per i test, possiamo anche eseguire il codice in un notebook SageMaker. I grafici seguenti mostrano gli input e l'output del nostro modello quando si utilizzano i dati di esempio. I picchi nella deviazione tra i valori previsti e quelli effettivi (punteggio di anomalia, mostrato nel grafico inferiore) indicano anomalie. Ad esempio, nel grafico, possiamo vedere tre picchi distinti in cui il punteggio di anomalia (differenza tra la temperatura prevista e quella reale) supera i 7 gradi Celsius: il primo dopo un lungo periodo di inattività, il secondo in corrispondenza di un forte calo di bearing_temperature, e l'ultimo dove bearing_temperature è elevato rispetto a motor_speed.
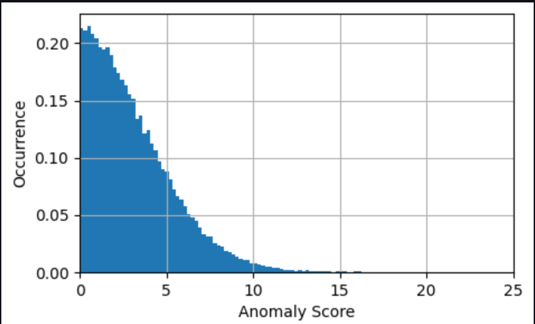
In molti casi conoscere la serie storica del punteggio di anomalia è già sufficiente; è possibile impostare una soglia entro la quale avvisare di un'anomalia significativa in base alla necessità di sensibilità del modello. Il punteggio attuale indica quindi che una macchina presenta uno stato anomalo che necessita di indagini. Ad esempio, per il nostro modello, il valore assoluto del punteggio di anomalia è distribuito come mostrato nel grafico seguente. Ciò conferma che la maggior parte dei punteggi di anomalia sono inferiori agli (2xRMS=)8 gradi riscontrati durante l'addestramento del modello come errore tipico. Il grafico può aiutarti a scegliere manualmente una soglia, in modo tale che la giusta percentuale dei campioni valutati venga contrassegnata come anomalia.
Se l'output desiderato sono eventi di anomalia, i punteggi di anomalia forniti dal modello richiedono un perfezionamento per essere rilevanti per l'uso aziendale. Per questo, l'esperto di ML aggiungerà in genere la postelaborazione per rimuovere rumore o picchi di grandi dimensioni nel punteggio dell'anomalia, ad esempio aggiungendo una media mobile. Inoltre, l'esperto valuterà tipicamente il punteggio di anomalia con una logica simile all'aumento di un Amazon Cloud Watch allarme, come il monitoraggio del superamento di una soglia per una durata specifica. Per ulteriori informazioni sull'impostazione degli allarmi, fare riferimento a Utilizzo degli allarmi Amazon CloudWatch. L'esecuzione di queste valutazioni nella funzione Lambda consente di inviare avvisi, ad esempio pubblicando un avviso su un file Servizio di notifica semplice Amazon Argomento (Amazon SNS).
ripulire
Dopo aver finito di utilizzare questa soluzione, dovresti ripulire per evitare costi inutili:
- In SageMaker Canvas, trova la distribuzione dell'endpoint del modello ed eliminala.
- Esci da SageMaker Canvas per evitare addebiti per il suo funzionamento inattivo.
Sommario
In questo post, abbiamo mostrato come un esperto di dominio può valutare i dati di input e creare un modello ML utilizzando SageMaker Canvas senza la necessità di scrivere codice. Successivamente abbiamo mostrato come utilizzare questo modello per eseguire il rilevamento di anomalie in tempo reale utilizzando SageMaker e Lambda attraverso un semplice flusso di lavoro. Questa combinazione consente agli esperti di dominio di utilizzare le proprie conoscenze per creare potenti modelli ML senza ulteriore formazione nella scienza dei dati e consente agli esperti MLOps di utilizzare questi modelli e renderli disponibili per l'inferenza in modo flessibile ed efficiente.
Per SageMaker Canvas è disponibile un livello gratuito di 2 mesi, dopodiché pagherai solo per ciò che utilizzi. Inizia a sperimentare oggi e aggiungi il machine learning per sfruttare al massimo i tuoi dati.
Circa l'autore
 Helge Aufderheide è un appassionato di rendere i dati utilizzabili nel mondo reale con una forte attenzione all'automazione, all'analisi e al machine learning nelle applicazioni industriali, come la produzione e la mobilità.
Helge Aufderheide è un appassionato di rendere i dati utilizzabili nel mondo reale con una forte attenzione all'automazione, all'analisi e al machine learning nelle applicazioni industriali, come la produzione e la mobilità.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/
- :ha
- :È
- :non
- :Dove
- $ SU
- 100
- 25
- 4
- 67
- 7
- a
- capace
- anormale
- anomalia
- Chi siamo
- Assoluta
- Accetta
- accessibile
- Secondo
- raggiunto
- operanti in
- azioni
- presenti
- aggiungere
- l'aggiunta di
- aggiunta
- aggiuntivo
- indirizzi
- influenzare
- influenzato
- Dopo shavasana, sedersi in silenzio; saluti;
- dopo
- contro
- aggregato
- allarme
- consentire
- Consentire
- consente
- lungo
- già
- anche
- Amazon
- Amazon Sage Maker
- Tela di Amazon SageMaker
- Amazon Web Services
- Ambientale
- an
- .
- Gli analisti
- analitica
- ed
- rilevamento anomalie
- Un altro
- chiunque
- api
- Applicazioni
- applicazioni
- applicato
- architettura
- SONO
- AS
- At
- Automatizzata
- Automazione
- disponibile
- evitare
- AWS
- AWS Lambda
- Axis
- basato
- base
- BE
- perché
- diventare
- prima
- comportamento
- sotto
- Segno di riferimento
- MIGLIORE
- fra
- Big
- Big Data
- LAMA
- stile di vita
- violazione
- costruire
- affari
- ma
- pulsante
- by
- detto
- Bandi
- Materiale
- tela
- funzionalità
- auto
- Custodie
- casi
- cause
- Centigrado
- il cambiamento
- cambiando
- caratteristica
- oneri
- chimico
- Scegli
- classificazione
- cavedano
- strettamente
- Cloud
- il cloud computing
- codice
- collezione
- Colonna
- colonne
- combinazione
- Aziende
- confrontare
- rispetto
- completamento di una
- completamento
- complesso
- informatica
- concetto
- condizioni
- Configurazione
- Prendere in considerazione
- consiste
- consumo
- contenere
- contenuto
- sistema di raffreddamento
- correggere
- Costo
- creare
- creato
- crea
- creazione
- curato
- curation
- Corrente
- curva
- Clienti
- dati
- analisi dei dati
- Dati Analytics
- punti dati
- scienza dei dati
- data-driven
- Date
- Decision Making
- diminuisce
- deep
- def
- delete
- Richiesta
- dimostrare
- dipendere
- schierare
- schierato
- deployment
- Distribuisce
- descrive
- desiderato
- dettagli
- individuare
- rivelazione
- Determinare
- deviazione
- diagramma
- differenza
- diverso
- direttamente
- discrepanza
- distinto
- distribuito
- non
- dominio
- porte
- giù
- scaricare
- Cadere
- durata
- durante
- ogni
- effetto
- efficienza
- efficiente
- in modo efficiente
- sforzo
- Potenzia
- Abilita
- fine
- endpoint
- energia
- Consumo di energia
- Ingegneri
- appassionato
- Intero
- usate
- errore
- Etere (ETH)
- valutare
- valutato
- valutazione
- valutazioni
- eventi
- esaminare
- esempio
- Esempi
- attenderti
- previsto
- esperienza
- sperimentazione
- esperto
- esperti
- Esposizione
- estratto
- di fronte
- Fattori
- in mancanza di
- fallimenti
- familiare
- guasto
- guasti
- caratteristica
- Caratteristiche
- pochi
- Compila il
- filtro
- finale
- Trovare
- ricerca
- Nome
- flessibilmente
- Focus
- si concentra
- seguire
- i seguenti
- segue
- Nel
- le previsioni
- essere trovato
- quattro
- Gratis
- attrito
- da
- function
- funzionalità
- futuro
- generare
- generato
- ottenere
- dato
- buono
- grafico
- grafici
- cura
- maniglia
- Manovrabilità
- Avere
- Aiuto
- qui
- Alta
- alto livello
- storia
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- hvac
- Sistema HVAC
- identificare
- Idle
- if
- illustrare
- illustra
- Immagine
- importare
- importante
- miglioramenti
- in
- Compreso
- Aumento
- sempre più
- Index
- indicare
- indicato
- indica
- indicando
- indicazione
- industriale
- industrie
- industria
- influenzare
- informazioni
- Infrastruttura
- ingredienti
- inizialmente
- ingresso
- Ingressi
- interno
- intuizioni
- esempio
- invece
- istruzioni
- Interfaccia
- interpretazione
- ai miglioramenti
- complessità
- indagare
- indagando
- indagine
- invocato
- IT
- SUO
- congiunto
- jpg
- json
- Le
- Conoscere
- conoscenze
- conosciuto
- Dipingere
- Le Lingue
- grandi
- superiore, se assunto singolarmente.
- Cognome
- IMPARARE
- apprendimento
- piace
- probabile
- Limitato
- lineare
- Linee
- caricare
- carichi
- logica
- Lunghi
- Guarda
- spento
- inferiore
- macchina
- machine learning
- macchine
- Principale
- manutenzione
- make
- Fare
- malfunzionamenti
- I gestori
- manualmente
- consigliato per la
- molti
- segnato
- marcatura
- Maggio..
- significare
- si intende
- misurazioni
- analisi
- di misura
- Soddisfare
- messaggi
- metrico
- Metrica
- ML
- MLOp
- mobilità
- modello
- modelli
- monitoraggio
- Scopri di più
- maggior parte
- Il motore
- motori
- in movimento
- molti
- devono obbligatoriamente:
- my
- Nome
- Bisogno
- esigenze
- New
- Rumore
- normale
- normalmente
- Nota
- taccuino
- notifica
- adesso
- osservazioni
- osservato
- ottenere
- ottiene
- evento
- of
- di frequente
- on
- ONE
- esclusivamente
- apertura
- operazione
- operativa
- Operazioni
- Opzione
- or
- i
- Altro
- nostro
- su
- produzione
- uscite
- al di fuori
- ancora
- panoramica
- pagina
- panda
- Paga le
- percentuale
- eseguire
- performance
- esecuzione
- esegue
- Fisico
- immagine
- pianificazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- punti
- lavori
- Post
- potenziale
- energia
- potente
- pratica
- precisamente
- predire
- previsto
- previsione
- predizione
- Previsioni
- predittiva
- Preparare
- prerequisiti
- precedente
- prezzi
- Problema
- processi
- Prodotto
- produttivo
- Programmazione
- linguaggi di programmazione
- fornire
- purché
- fornisce
- fornitura
- editoriale
- Python
- qualità
- quantità
- domanda
- Presto
- raccolta
- Leggi
- di rose
- mondo reale
- tempo reale
- recente
- riferimento
- raffinare
- registro
- regressione
- Basic
- relazionato
- rapporto
- Relazioni
- pertinente
- affidabile
- rimuovere
- richiedere
- necessario
- richiede
- risorsa
- risposta
- colpevole
- risultante
- Risultati
- ritorno
- problemi
- destra
- rotolamento
- radice
- RIGA
- Correre
- running
- corre
- sagemaker
- stesso
- campione
- scenario
- Scienze
- Punto
- punteggi
- Secondo
- vedere
- select
- selezionato
- Selezione
- inviare
- Sensibilità
- Serie
- serverless
- Servizi
- set
- regolazione
- impostazioni
- flessibile.
- Condividi
- azioni
- dovrebbero
- mostrare attraverso le sue creazioni
- ha mostrato
- mostra
- mostrato
- Spettacoli
- significativa
- simile
- Un'espansione
- semplicità
- Taglia
- insieme di abilità
- scorrevole
- So
- soluzione
- alcuni
- tensione
- specialisti
- specifico
- velocità
- velocità
- diffondere
- Standard
- inizia a
- iniziato
- Regione / Stato
- statistica
- Stato dei servizi
- step
- Passi
- memorizzati
- forte
- subottimale
- tale
- sufficiente
- adatto
- supporti
- sicuro
- supera
- sinteticamente
- sistema
- Fai
- Target
- obiettivi
- test
- Testing
- di
- che
- Il
- Il grafo
- loro
- Li
- poi
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- completo
- quelli
- tre
- soglia
- Attraverso
- fila
- tempo
- Serie storiche
- volte
- a
- oggi
- strumenti
- top
- argomento
- verso
- tradizionale
- Treni
- Training
- forma
- Trasformare
- sintonizzare
- sintonia
- turbina
- seconda
- Digitare
- tipico
- tipicamente
- per
- subire
- capire
- inutile
- insolito
- utilizzabile
- uso
- caso d'uso
- utilizzato
- usa
- utilizzando
- APPREZZIAMO
- Valori
- Velocità
- molto
- via
- volere
- identificazione dei warning
- Prima
- we
- sito web
- servizi web
- WELL
- Che
- Che cosa è l'
- quando
- se
- quale
- OMS
- volere
- vento
- turbina eolica
- finestra
- con
- entro
- senza
- flusso di lavoro
- lavoro
- mondo
- sarebbe
- scrivere
- scrivere codice
- scrittura
- anni
- ancora
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro