Questo post sul blog è stato scritto in collaborazione con Chaoyang He e Salman Avestimehr di FedML.
L'analisi dei dati sanitari e delle scienze della vita (HCLS) del mondo reale pone diverse sfide pratiche, come silos di dati distribuiti, mancanza di dati sufficienti in un unico sito per eventi rari, linee guida normative che vietano la condivisione dei dati, requisiti infrastrutturali e costi sostenuti per la creazione un archivio dati centralizzato. Poiché si trovano in un dominio altamente regolamentato, i partner ei clienti di HCLS cercano meccanismi di tutela della privacy per gestire e analizzare dati sensibili, distribuiti e su larga scala.
Per mitigare queste sfide, proponiamo un framework di apprendimento federato (FL), basato su FedML open source su AWS, che consente l'analisi di dati HCLS sensibili. Implica l'addestramento di un modello globale di machine learning (ML) da dati sanitari distribuiti conservati localmente in diversi siti. Non richiede lo spostamento o la condivisione dei dati tra i siti o con un server centralizzato durante il processo di addestramento del modello.
La distribuzione di un framework FL nel cloud presenta diverse sfide. L'automazione dell'infrastruttura client-server per supportare più account o cloud privati virtuali (VPC) richiede il peering VPC e una comunicazione efficiente tra VPC e istanze. In un carico di lavoro di produzione, è necessaria una pipeline di distribuzione stabile per aggiungere e rimuovere facilmente i client e aggiornare le loro configurazioni senza molto sovraccarico. Inoltre, in una configurazione eterogenea, i client possono avere requisiti diversi per elaborazione, rete e archiviazione. In questa architettura decentralizzata, la registrazione e il debug degli errori tra i client possono essere difficili. Infine, determinare l'approccio ottimale per aggregare i parametri del modello, mantenere le prestazioni del modello, garantire la privacy dei dati e migliorare l'efficienza della comunicazione è un compito arduo. In questo post, affrontiamo queste sfide fornendo un modello FLOps (Federated Learning Operations) che ospita una soluzione HCLS. La soluzione è indipendente dai casi d'uso, il che significa che puoi adattarla ai tuoi casi d'uso modificando il modello e i dati.
In questa serie in due parti, dimostriamo come distribuire un framework FL basato su cloud su AWS. Nel primo post, abbiamo descritto i concetti FL e il framework FedML. In questa seconda parte, presentiamo un caso d'uso di assistenza sanitaria e scienze della vita proof-of-concept da un set di dati del mondo reale eICU. Questo set di dati comprende un database di terapia intensiva multicentrico raccolto da oltre 200 ospedali, che lo rende ideale per testare i nostri esperimenti FL.
Caso d'uso HCLS
A scopo dimostrativo, abbiamo costruito un modello FL su un set di dati pubblicamente disponibile per gestire i pazienti in condizioni critiche. Abbiamo usato il Banca dati di ricerca collaborativa eICU, un database di unità di terapia intensiva (ICU) multicentrico, che comprende 200,859 incontri di unità di pazienti per 139,367 pazienti unici. Sono stati ricoverati in una delle 335 unità di 208 ospedali dislocati negli Stati Uniti tra il 2014 e il 2015. A causa dell'eterogeneità sottostante e della natura distribuita dei dati, fornisce un esempio reale ideale per testare questo framework FL. Il set di dati include misurazioni di laboratorio, segni vitali, informazioni sul piano di assistenza, farmaci, anamnesi del paziente, diagnosi di ricovero, diagnosi con data e ora da un elenco di problemi strutturato e trattamenti scelti in modo simile. È disponibile come set di file CSV, che possono essere caricati in qualsiasi sistema di database relazionale. Le tabelle sono anonimizzate per soddisfare i requisiti normativi del US Health Insurance Portability and Accountability Act (HIPAA). È possibile accedere ai dati tramite un repository PhysioNet e i dettagli del processo di accesso ai dati sono disponibili qui [1].
I dati eICU sono ideali per sviluppare algoritmi ML, strumenti di supporto decisionale e far progredire la ricerca clinica. Per l'analisi di riferimento, abbiamo considerato il compito di prevedere la mortalità intraospedaliera dei pazienti [2]. L'abbiamo definita come un'attività di classificazione binaria, in cui ogni campione di dati copre una finestra di 1 ora. Per creare una coorte per questo compito, abbiamo selezionato pazienti con uno stato di dimissione ospedaliera nella cartella del paziente e una durata della degenza di almeno 48 ore, perché ci concentriamo sulla previsione della mortalità durante le prime 24 e 48 ore. Ciò ha creato una coorte di 30,680 pazienti contenente 1,164,966 record. Abbiamo adottato la preelaborazione dei dati specifica del dominio e i metodi descritti in [3] per la previsione della mortalità. Ciò ha portato a un set di dati aggregato comprendente diverse colonne per paziente per record, come mostrato nella figura seguente. La seguente tabella fornisce un record del paziente in un'interfaccia in stile tabulare con il tempo nelle colonne (5 intervalli in 48 ore) e le osservazioni dei segni vitali nelle righe. Ogni riga rappresenta una variabile fisiologica e ogni colonna rappresenta il suo valore registrato in una finestra temporale di 48 ore per un paziente.
| Parametro fisiologico | Grafico_Tempo_0 | Grafico_Tempo_1 | Grafico_Tempo_2 | Grafico_Tempo_3 | Grafico_Tempo_4 |
| Glasgow Coma Punteggio Occhi | 4 | 4 | 4 | 4 | 4 |
| FiO2 | 15 | 15 | 15 | 15 | 15 |
| Glasgow Coma Punteggio Occhi | 15 | 15 | 15 | 15 | 15 |
| Frequenza cardiaca | 101 | 100 | 98 | 99 | 94 |
| PA diastolica invasiva | 73 | 68 | 60 | 64 | 61 |
| PA sistolica invasiva | 124 | 122 | 111 | 105 | 116 |
| Pressione arteriosa media (mmHg) | 77 | 77 | 77 | 77 | 77 |
| Motore del punteggio del coma di Glasgow | 6 | 6 | 6 | 6 | 6 |
| 02 Saturazione | 97 | 97 | 97 | 97 | 97 |
| Frequenza respiratoria | 19 | 19 | 19 | 19 | 19 |
| Temperatura (C) | 36 | 36 | 36 | 36 | 36 |
| Glasgow Coma Punteggio verbale | 5 | 5 | 5 | 5 | 5 |
| altezza di ammissione | 162 | 162 | 162 | 162 | 162 |
| peso di ammissione | 96 | 96 | 96 | 96 | 96 |
| 72 | 72 | 72 | 72 | 72 | |
| apaheadmissiondx | 143 | 143 | 143 | 143 | 143 |
| etnia | 3 | 3 | 3 | 3 | 3 |
| genere | 1 | 1 | 1 | 1 | 1 |
| glucosio | 128 | 128 | 128 | 128 | 128 |
| hospitalammitoffset | all'436 ottobre | all'436 ottobre | all'436 ottobre | all'436 ottobre | all'436 ottobre |
| stato di dimissione ospedaliera | 0 | 0 | 0 | 0 | 0 |
| itemoffset | -6 | -1 | 0 | 1 | 2 |
| pH | 7 | 7 | 7 | 7 | 7 |
| pazienteunitàstayid | 2918620 | 2918620 | 2918620 | 2918620 | 2918620 |
| offset di scarico dell'unità | 1466 | 1466 | 1466 | 1466 | 1466 |
| stato di scarico dell'unità | 0 | 0 | 0 | 0 | 0 |
Abbiamo utilizzato caratteristiche sia numeriche che categoriche e abbiamo raggruppato tutti i record di ciascun paziente per appiattirli in una serie temporale a record singolo. Le sette caratteristiche categoriche (Diagnosi di ammissione, Etnia, Sesso, Glasgow Coma Score Total, Glasgow Coma Score Eyes, Glasgow Coma Score Motor e Glasgow Coma Score Verbal sono state convertite in vettori di codifica one-hot) contenevano 429 valori univoci e sono state convertite in uno - incorporamenti a caldo. Per evitare perdite di dati tra i server dei nodi di addestramento, abbiamo suddiviso i dati per ID ospedalieri e conservato tutti i record di un ospedale su un singolo nodo.
Panoramica della soluzione
Il diagramma seguente mostra l'architettura della distribuzione multi-account di FedML su AWS. Ciò include due client (Partecipante A e Partecipante B) e un aggregatore di modelli.
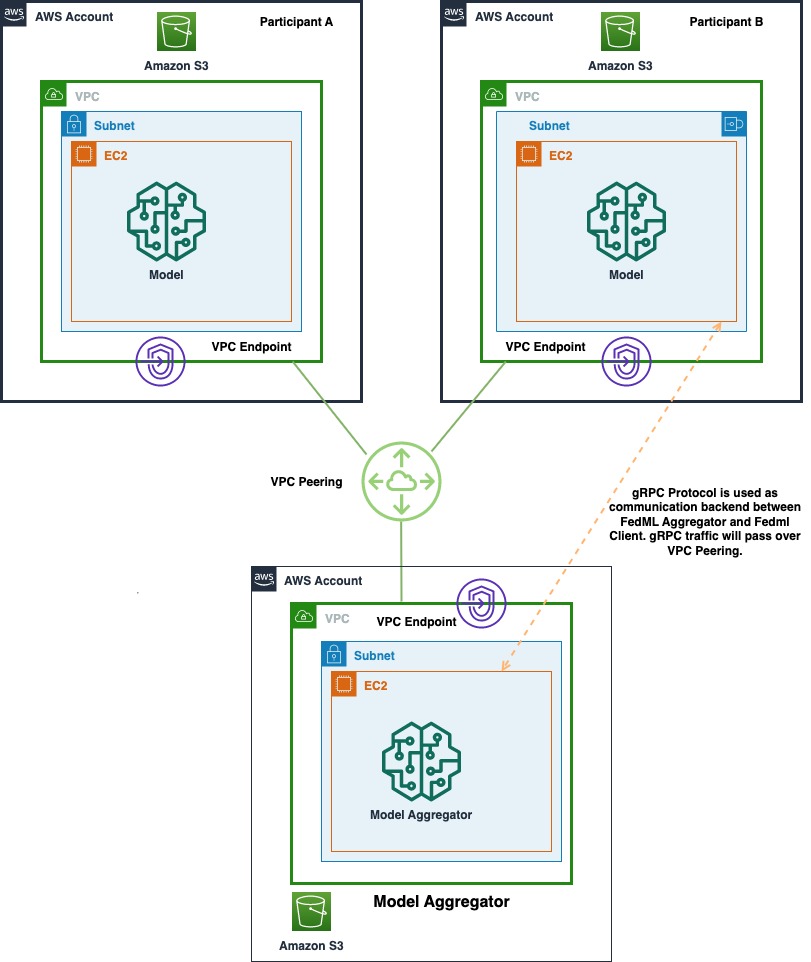
L'architettura è composta da tre distinti Cloud di calcolo elastico di Amazon (Amazon EC2) in esecuzione nel proprio account AWS. Ognuna delle prime due istanze è di proprietà di un client e la terza istanza è di proprietà dell'aggregatore di modelli. Gli account sono collegati tramite peering VPC per consentire lo scambio di modelli e pesi ML tra i client e l'aggregatore. gRPC viene utilizzato come backend di comunicazione per la comunicazione tra l'aggregatore di modelli e i client. Abbiamo testato una singola configurazione di elaborazione distribuita basata su account con un server e due nodi client. Ognuna di queste istanze è stata creata utilizzando un'AMI Amazon EC2 personalizzata con dipendenze FedML installate come da Guida all'installazione di FedML.ai.
Configura il peering VPC
Dopo aver avviato le tre istanze nei rispettivi account AWS, stabilisci il peering VPC tra gli account tramite Cloud privato virtuale di Amazon (Amazon VPC). Per configurare una connessione peering VPC, crea prima una richiesta di peering con un altro VPC. Puoi richiedere una connessione peering VPC con un altro VPC nel tuo account o con un VPC in un altro account AWS. Per attivare la richiesta, il proprietario del VPC deve accettare la richiesta. Ai fini di questa dimostrazione, abbiamo impostato la connessione di peering tra VPC in account diversi ma nella stessa regione. Per altre configurazioni del peering VPC, fare riferimento a Crea una connessione peering VPC.
Prima di iniziare, assicurati di disporre del numero di account AWS e dell'ID VPC del VPC con cui eseguire il peering.
Richiedi una connessione peering VPC
Per creare la connessione peering VPC, completa i seguenti passaggi:
- Nella console Amazon VPC, nel riquadro di navigazione, scegli Connessioni di peering.
- Scegli Crea connessione di peering.
- Nel Etichetta nome connessione peering, puoi facoltativamente assegnare un nome alla tua connessione peering VPC. In questo modo viene creato un tag con una chiave del nome e un valore che specifichi. Questo tag è visibile solo a te; il proprietario del VPC peer può creare i propri tag per la connessione peering VPC.
- Nel VPC (richiedente), scegli il VPC nel tuo account per creare la connessione di peering.
- Nel Il mio accountscegli Un altro account.
- Nel Account ID, inserisci l'ID account AWS del proprietario del VPC accettante.
- Nel VPC (accettatore), immetti l'ID VPC con cui creare la connessione peering VPC.
- Nella finestra di dialogo di conferma, scegli OK.
- Scegli Crea connessione di peering.
Accetta una connessione peering VPC
Come accennato in precedenza, la connessione peering VPC deve essere accettata dal proprietario del VPC a cui è stata inviata la richiesta di connessione. Completare i passaggi seguenti per accettare la richiesta di connessione peering:
- Sulla console Amazon VPC, utilizza il selettore di regione per scegliere la regione del VPC accettante.
- Nel pannello di navigazione, scegli Connessioni di peering.
- Seleziona la connessione peering VPC in attesa (lo stato è
pending-acceptance), e sul Azioni menù, scegliere Richiesta accettata. - Nella finestra di dialogo di conferma, scegli Sì, Accetta.
- Nella seconda finestra di dialogo di conferma, scegli Modifica le mie tabelle di percorso ora per andare direttamente alla pagina delle tabelle dei percorsi, oppure scegliere Chiudi farlo più tardi.
Aggiorna le tabelle di instradamento
Per abilitare il traffico IPv4 privato tra le istanze nei VPC in peering, aggiungi un instradamento alle tabelle di instradamento associate alle sottoreti per entrambe le istanze. La destinazione del percorso è il blocco CIDR (o parte del blocco CIDR) del VPC peer e la destinazione è l'ID della connessione peering VPC. Per ulteriori informazioni, vedere Configura tabelle di instradamento.
Aggiorna i tuoi gruppi di sicurezza per fare riferimento a gruppi VPC peer
Aggiorna le regole in entrata o in uscita per i tuoi gruppi di sicurezza VPC in modo che facciano riferimento ai gruppi di sicurezza nel VPC con peering. Ciò consente il flusso del traffico tra le istanze associate al gruppo di sicurezza di riferimento nel VPC con peering. Per ulteriori dettagli sull'impostazione dei gruppi di sicurezza, fare riferimento a Aggiorna i tuoi gruppi di sicurezza per fare riferimento ai gruppi di sicurezza peer.
Configura FedML
Dopo aver eseguito le tre istanze EC2, connettiti a ciascuna di esse ed esegui i seguenti passaggi:
- Clona il file Repository FedML.
- Fornisci i dati sulla topologia della tua rete nel file di configurazione
grpc_ipconfig.csv.
Questo file può essere trovato su FedML/fedml_experiments/distributed/fedavg nel repository FedML. Il file include i dati sul server e sui client e la relativa mappatura dei nodi designati, ad esempio FL Server – Nodo 0, FL Client 1 – Nodo 1 e FL Client 2 – Nodo2.
- Definire il file di configurazione della mappatura della GPU.
Questo file può essere trovato su FedML/fedml_experiments/distributed/fedavg nel repository FedML. Il file gpu_mapping.yaml è costituito dai dati di configurazione per il mapping del server client alla GPU corrispondente, come mostrato nel frammento di codice seguente.
Dopo aver definito queste configurazioni, sei pronto per eseguire i client. Si noti che i client devono essere eseguiti prima di avviare il server. Prima di farlo, impostiamo i caricatori di dati per gli esperimenti.
Personalizza FedML per eICU
Per personalizzare il repository FedML per il set di dati eICU, apportare le seguenti modifiche ai dati e al caricatore di dati.
Dati
Aggiungere i dati alla cartella dei dati preassegnata, come mostrato nello screenshot seguente. È possibile inserire i dati in qualsiasi cartella di propria scelta, purché il percorso sia costantemente referenziato nello script di training e l'accesso sia abilitato. Per seguire uno scenario HCLS del mondo reale, in cui i dati locali non sono condivisi tra i siti, suddividere e campionare i dati in modo che non vi siano sovrapposizioni di ID ospedalieri tra i due client. Ciò garantisce che i dati di un ospedale siano ospitati sul proprio server. Abbiamo anche applicato lo stesso vincolo per suddividere i dati in set di addestramento/test all'interno di ciascun client. Ciascuno dei set di addestramento/test tra i clienti aveva un rapporto 1:10 di etichette positive e negative, con circa 27,000 campioni in addestramento e 3,000 campioni in prova. Gestiamo lo squilibrio dei dati nell'addestramento del modello con una funzione di perdita ponderata.
Caricatore dati
Ognuno dei client FedML carica i dati e li converte in tensori PyTorch per un addestramento efficiente sulla GPU. Estendi la nomenclatura FedML esistente per aggiungere una cartella per i dati eICU nel file data_processing cartella.

Il seguente frammento di codice carica i dati dall'origine dati. Preelabora i dati e restituisce un elemento alla volta attraverso il file __getitem__ funzione.
L'addestramento dei modelli ML con un singolo punto dati alla volta è noioso e richiede tempo. L'addestramento del modello viene in genere eseguito su un batch di punti dati in ciascun client. Per implementare ciò, il caricatore di dati nel file data_loader.py script converte gli array NumPy in tensori Torch, come mostrato nel seguente frammento di codice. Si noti che FedML fornisce dataset.py ed data_loader.py script per dati sia strutturati che non strutturati che puoi utilizzare per modifiche specifiche dei dati, come in qualsiasi progetto PyTorch.
Importa il caricatore di dati nello script di addestramento
Dopo aver creato il caricatore di dati, importalo nel codice FedML per l'addestramento del modello ML. Come qualsiasi altro set di dati (ad esempio, CIFAR-10 e CIFAR-100), caricare i dati eICU nel main_fedavg.py script nel percorso FedML/fedml_experiments/distributed/fedavg/. Qui, abbiamo utilizzato la media federata (fedavg) funzione di aggregazione. Puoi seguire un metodo simile per impostare il file main file per qualsiasi altra funzione di aggregazione.
Chiamiamo la funzione data loader per i dati eICU con il seguente codice:
Definisci il modello
FedML supporta diversi algoritmi di deep learning pronti all'uso per vari tipi di dati, come dati tabulari, di testo, immagini, grafici e Internet of Things (IoT). Carica il modello specifico per eICU con dimensioni di input e output definite in base al set di dati. Per questo sviluppo di proof of concept, abbiamo utilizzato un modello di regressione logistica per addestrare e prevedere il tasso di mortalità dei pazienti con configurazioni predefinite. Il seguente frammento di codice mostra gli aggiornamenti che abbiamo apportato al file main_fedavg.py copione. Tieni presente che puoi anche utilizzare modelli PyTorch personalizzati con FedML e importarli nel file main_fedavg.py script.
Esegui e monitora la formazione FedML su AWS
Il video seguente mostra il processo di formazione inizializzato in ciascuno dei client. Dopo che entrambi i client sono stati elencati per il server, creare il processo di addestramento del server che esegue l'aggregazione federata dei modelli.
Per configurare il server e i client FL, completare i seguenti passaggi:
- Eseguire il client 1 e il client 2.
Per eseguire un client, immetti il comando seguente con l'ID del nodo corrispondente. Ad esempio, per eseguire il client 1 con ID nodo 1, eseguire dalla riga di comando:
- Dopo che entrambe le istanze client sono state avviate, avviare l'istanza del server utilizzando lo stesso comando e l'ID nodo appropriato per la propria configurazione nel file
grpc_ipconfig.csv file. Puoi vedere i pesi del modello passati al server dalle istanze del client.
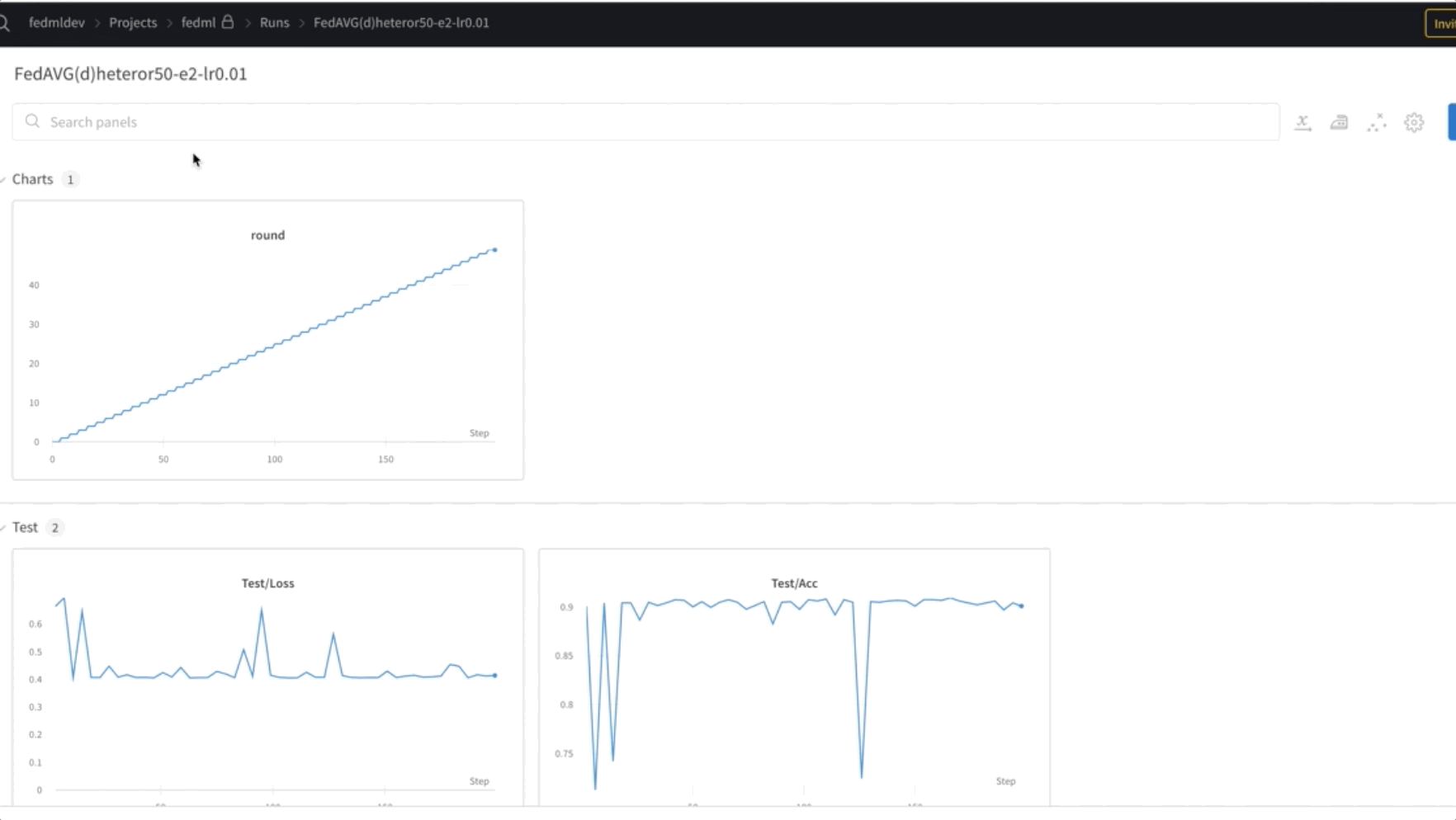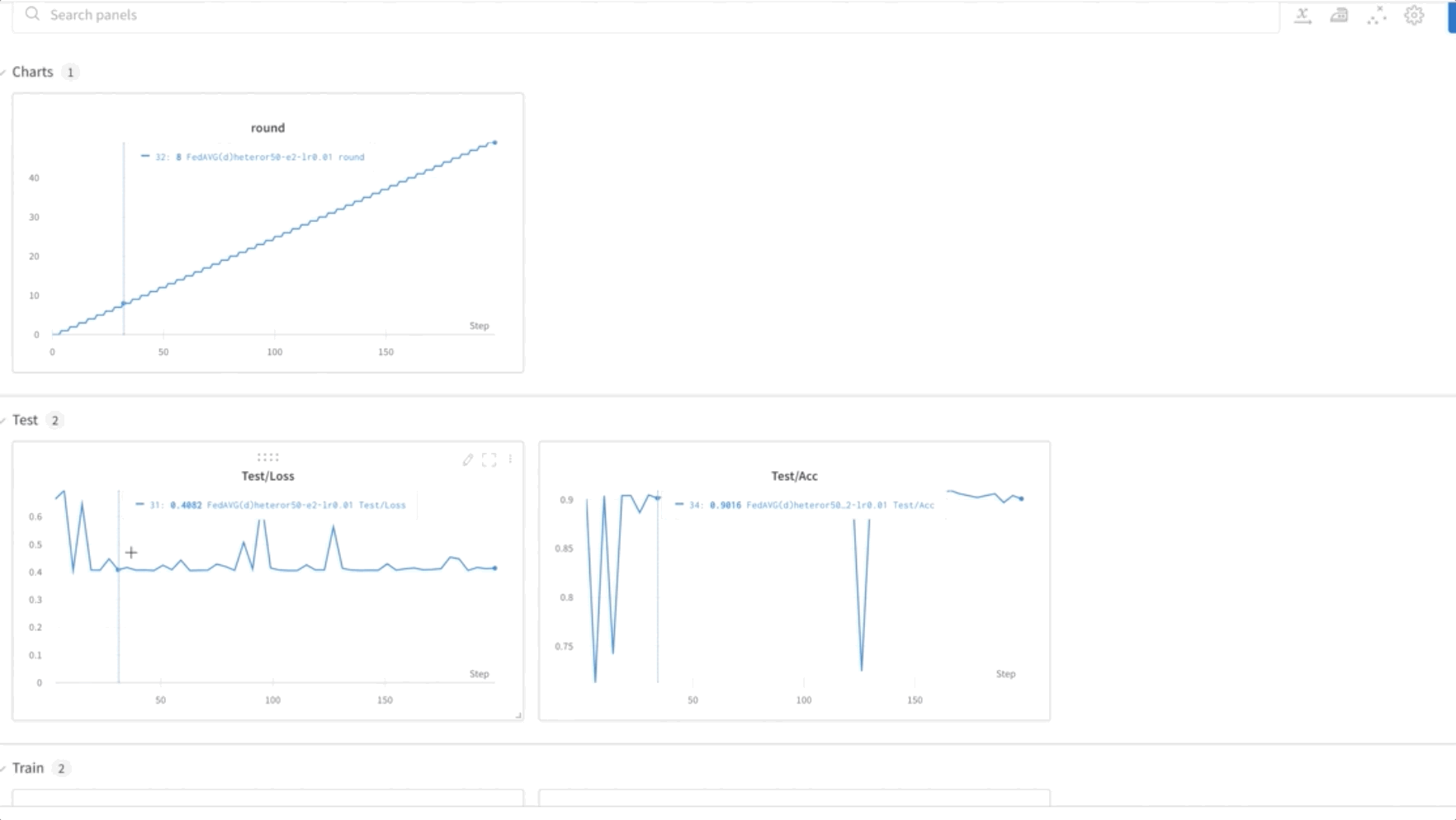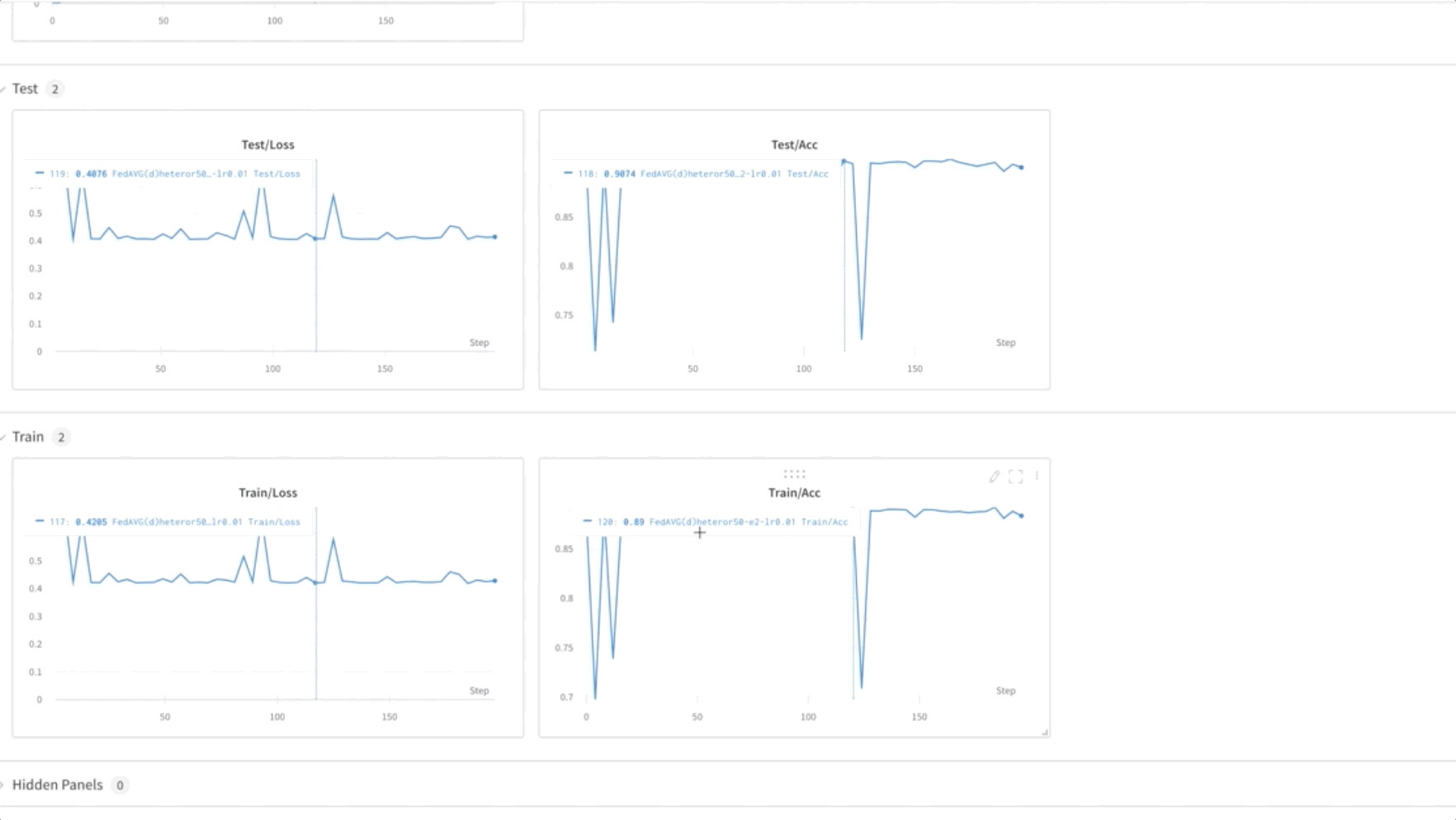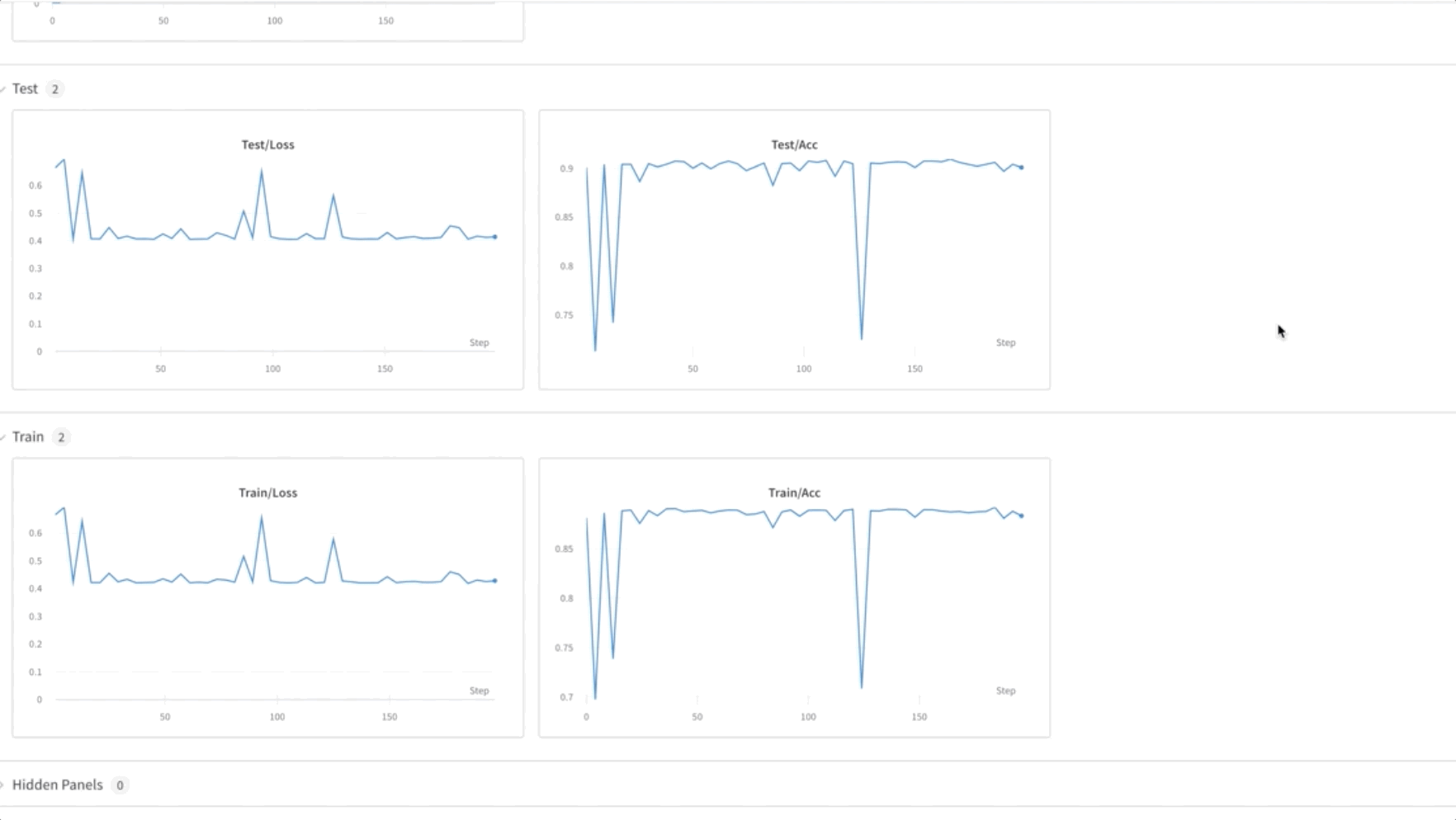
- Addestriamo il modello FL per 50 epoche. Come puoi vedere nel video qui sotto, i pesi vengono trasferiti tra i nodi 0, 1 e 2, indicando che la formazione sta procedendo come previsto in modo federato.
- Infine, monitora e monitora la progressione dell'addestramento del modello FL tra i diversi nodi del cluster utilizzando il file pesi e pregiudizi (wandb), come mostrato nello screenshot seguente. Si prega di seguire i passaggi elencati qui per installare wandb e configurare il monitoraggio per questa soluzione.
Il seguente video cattura tutti questi passaggi per fornire una dimostrazione end-to-end di FL su AWS utilizzando FedML:
Conclusione
In questo post, abbiamo mostrato come distribuire un framework FL, basato su FedML open source, su AWS. Ti consente di addestrare un modello ML su dati distribuiti, senza la necessità di condividerlo o spostarlo. Abbiamo creato un'architettura multi-account, in cui in uno scenario reale, gli ospedali o le organizzazioni sanitarie possono unirsi all'ecosistema per beneficiare dell'apprendimento collaborativo mantenendo la governance dei dati. Abbiamo utilizzato il set di dati eICU multi-ospedaliero per testare questa implementazione. Questo framework può essere applicato anche ad altri casi d'uso e domini. Continueremo a estendere questo lavoro automatizzando la distribuzione attraverso l'infrastruttura come codice (utilizzando AWS CloudFormazione), incorporando ulteriormente meccanismi di tutela della vita privata e migliorando l'interpretazione e l'equità dei modelli FL.
Si prega di rivedere la presentazione a re:MARS 2022 incentrata su "Managed Federated Learning su AWS: un caso di studio per l'assistenza sanitaria” per una procedura dettagliata di questa soluzione.
Riferimento
[1] Pollard, Tom J., et al. "The eICU Collaborative Research Database, un database multicentrico disponibile gratuitamente per la ricerca in terapia intensiva". Dati scientifici 5.1 (2018): 1-13.
[2] Yin, X., Zhu, Y. e Hu, J., 2021. Un'indagine completa sull'apprendimento federato che preserva la privacy: una tassonomia, revisione e direzioni future. Sondaggi informatici ACM (CSUR), 54(6), pp.1-36.
[3] Sheikhalishahi, Seyedmostafa, Vevake Balaraman e Venet Osmani. "Benchmarking di modelli di apprendimento automatico su set di dati di terapia intensiva eICU multicentrico". Plos uno 15.7 (2020): e0235424.
Informazioni sugli autori
 Vidya Sagar Ravipati è Manager presso il Laboratorio di soluzioni Amazon ML, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per il machine learning per aiutare i clienti AWS in diversi settori verticali ad accelerare la loro adozione di intelligenza artificiale e cloud. In precedenza, era un ingegnere di machine learning nei servizi di connettività presso Amazon che ha contribuito a creare piattaforme di personalizzazione e manutenzione predittiva.
Vidya Sagar Ravipati è Manager presso il Laboratorio di soluzioni Amazon ML, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per il machine learning per aiutare i clienti AWS in diversi settori verticali ad accelerare la loro adozione di intelligenza artificiale e cloud. In precedenza, era un ingegnere di machine learning nei servizi di connettività presso Amazon che ha contribuito a creare piattaforme di personalizzazione e manutenzione predittiva.
 Olivia Choudhury, PhD, è Senior Partner Solutions Architect presso AWS. Aiuta i partner, nel settore Healthcare e Life Sciences, a progettare, sviluppare e scalare soluzioni all'avanguardia sfruttando AWS. Ha un background in genomica, analisi sanitaria, apprendimento federato e apprendimento automatico per la tutela della privacy. Al di fuori del lavoro, gioca a giochi da tavolo, dipinge paesaggi e colleziona manga.
Olivia Choudhury, PhD, è Senior Partner Solutions Architect presso AWS. Aiuta i partner, nel settore Healthcare e Life Sciences, a progettare, sviluppare e scalare soluzioni all'avanguardia sfruttando AWS. Ha un background in genomica, analisi sanitaria, apprendimento federato e apprendimento automatico per la tutela della privacy. Al di fuori del lavoro, gioca a giochi da tavolo, dipinge paesaggi e colleziona manga.
 Wajahat Aziz è Principal Machine Learning e HPC Solutions Architect presso AWS, dove si concentra sull'aiutare i clienti del settore sanitario e delle scienze della vita a sfruttare le tecnologie AWS per lo sviluppo di soluzioni ML e HPC all'avanguardia per un'ampia varietà di casi d'uso come lo sviluppo di farmaci, Sperimentazioni cliniche e apprendimento automatico a tutela della privacy. Al di fuori del lavoro, a Wajahat piace esplorare la natura, fare escursioni e leggere.
Wajahat Aziz è Principal Machine Learning e HPC Solutions Architect presso AWS, dove si concentra sull'aiutare i clienti del settore sanitario e delle scienze della vita a sfruttare le tecnologie AWS per lo sviluppo di soluzioni ML e HPC all'avanguardia per un'ampia varietà di casi d'uso come lo sviluppo di farmaci, Sperimentazioni cliniche e apprendimento automatico a tutela della privacy. Al di fuori del lavoro, a Wajahat piace esplorare la natura, fare escursioni e leggere.
 Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso il Laboratorio di soluzioni Amazon ML, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso il Laboratorio di soluzioni Amazon ML, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
 Ujjwal Ratan è il leader per AI/ML e Data Science nella Business Unit AWS Healthcare and Life Science ed è anche Principal AI/ML Solutions Architect. Nel corso degli anni, Ujjwal è stato un leader di pensiero nel settore sanitario e delle scienze della vita, aiutando diverse organizzazioni Global Fortune 500 a raggiungere i propri obiettivi di innovazione adottando l'apprendimento automatico. Il suo lavoro che coinvolge l'analisi dell'imaging medico, del testo clinico non strutturato e della genomica ha aiutato AWS a creare prodotti e servizi che forniscono diagnostica e terapeutica altamente personalizzate e mirate. Nel tempo libero ama ascoltare (e suonare) musica e fare viaggi imprevisti con la sua famiglia.
Ujjwal Ratan è il leader per AI/ML e Data Science nella Business Unit AWS Healthcare and Life Science ed è anche Principal AI/ML Solutions Architect. Nel corso degli anni, Ujjwal è stato un leader di pensiero nel settore sanitario e delle scienze della vita, aiutando diverse organizzazioni Global Fortune 500 a raggiungere i propri obiettivi di innovazione adottando l'apprendimento automatico. Il suo lavoro che coinvolge l'analisi dell'imaging medico, del testo clinico non strutturato e della genomica ha aiutato AWS a creare prodotti e servizi che forniscono diagnostica e terapeutica altamente personalizzate e mirate. Nel tempo libero ama ascoltare (e suonare) musica e fare viaggi imprevisti con la sua famiglia.
 Chaoyang He è co-fondatore e CTO di FedML, Inc., una startup in corsa per una comunità che costruisce un'IA aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. La sua ricerca si concentra su algoritmi, sistemi e applicazioni di machine learning distribuiti/federati. Ha conseguito il dottorato di ricerca. in Informatica dal University of Southern California, Los Angeles, Stati Uniti.
Chaoyang He è co-fondatore e CTO di FedML, Inc., una startup in corsa per una comunità che costruisce un'IA aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. La sua ricerca si concentra su algoritmi, sistemi e applicazioni di machine learning distribuiti/federati. Ha conseguito il dottorato di ricerca. in Informatica dal University of Southern California, Los Angeles, Stati Uniti.
 Salman Avestimehr è co-fondatore e CEO di FedML, Inc., una startup in corsa per una comunità che costruisce un'intelligenza artificiale aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. Salman Avestimehr è un esperto di fama mondiale nell'apprendimento federato con oltre 20 anni di leadership nella ricerca e sviluppo sia nel mondo accademico che nell'industria. È Dean's Professor e direttore inaugurale dell'USC-Amazon Center on Trustworthy Machine Learning presso la University of Southern California. È stato anche Amazon Scholar in Amazon. È un vincitore del premio presidenziale degli Stati Uniti per i suoi profondi contributi nella tecnologia dell'informazione e un membro dell'IEEE.
Salman Avestimehr è co-fondatore e CEO di FedML, Inc., una startup in corsa per una comunità che costruisce un'intelligenza artificiale aperta e collaborativa da qualsiasi luogo e su qualsiasi scala. Salman Avestimehr è un esperto di fama mondiale nell'apprendimento federato con oltre 20 anni di leadership nella ricerca e sviluppo sia nel mondo accademico che nell'industria. È Dean's Professor e direttore inaugurale dell'USC-Amazon Center on Trustworthy Machine Learning presso la University of Southern California. È stato anche Amazon Scholar in Amazon. È un vincitore del premio presidenziale degli Stati Uniti per i suoi profondi contributi nella tecnologia dell'informazione e un membro dell'IEEE.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/part-2-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/
- 000
- 1
- 10
- 100
- 20 anni
- 2018
- 2020
- 2021
- 2022
- 28
- 7
- 9
- a
- Chi siamo
- sopra
- Accademia
- accelerare
- Accetta
- accesso
- accessibile
- Il mio account
- responsabilità
- conti
- Raggiungere
- operanti in
- Legge
- adattare
- indirizzo
- ammesso
- adottato
- Adottando
- Adozione
- Pubblicità
- Dopo shavasana, sedersi in silenzio; saluti;
- aggregazione
- Aggregator
- AI
- AI / ML
- Algoritmi
- Tutti
- consente
- Amazon
- Amazon EC2
- .
- analitica
- analizzare
- l'analisi
- ed
- Angeles
- Un altro
- ovunque
- applicazioni
- applicato
- approccio
- opportuno
- architettura
- associato
- Automatizzare
- disponibile
- premio
- AWS
- BACKEND
- sfondo
- basato
- perché
- prima
- essendo
- sotto
- Segno di riferimento
- beneficio
- fra
- Bloccare
- Blog
- tavola
- Giochi da tavolo
- Scatola
- BP
- costruire
- Costruzione
- costruito
- affari
- California
- chiamata
- cattura
- che
- Custodie
- caso di studio
- casi
- centro
- centralizzata
- ceo
- sfide
- Modifiche
- cambiando
- scegliere
- Scegli
- scelto
- classe
- classificazione
- cliente
- clienti
- Info su
- test clinici
- Cloud
- adozione del cloud
- Cluster
- Co-fondatore
- codice
- Coorte
- collaborativo
- raccoglie
- Colonna
- colonne
- Coma
- Comunicazione
- comunità
- costruzione della comunità
- completamento di una
- globale
- Calcolare
- computer
- Informatica
- informatica
- concetto
- concetti
- Configurazione
- Connettiti
- collegato
- veloce
- Connettività
- considerato
- consolle
- continua
- contributi
- convertito
- Corrispondente
- Costo
- creare
- creato
- crea
- Creazione
- critico
- CTO
- costume
- Clienti
- personalizzare
- dati
- l'accesso ai dati
- perdita di dati
- punti dati
- privacy dei dati
- scienza dei dati
- scienziato di dati
- condivisione dei dati
- Banca Dati
- decentrata
- decisione
- deep
- apprendimento profondo
- Predefinito
- dimostrare
- schierare
- deployment
- descritta
- Design
- destinazione
- dettagliati
- dettagli
- determinazione
- sviluppare
- in via di sviluppo
- Mercato
- dialogo
- diverso
- difficile
- dimensioni
- direttamente
- Direttore
- distribuito
- calcolo distribuito
- sistemi distribuiti
- distribuzione
- non
- fare
- dominio
- domini
- droga
- sviluppo di farmaci
- durante
- ogni
- In precedenza
- ecosistema
- efficienza
- efficiente
- enable
- abilitato
- Abilita
- da un capo all'altro
- ingegnere
- garantire
- assicura
- entrare
- Intrattenimento
- epoche
- errori
- stabilire
- Etere (ETH)
- eventi
- esempio
- esistente
- previsto
- esperienza
- esperto
- esplora
- estendere
- Occhi
- equità
- famiglia
- Caratteristiche
- compagno
- figura
- Compila il
- File
- Infine
- Nome
- flusso
- Focus
- concentrato
- si concentra
- seguire
- i seguenti
- Fortune
- essere trovato
- Contesto
- Gratis
- da
- function
- funzioni
- ulteriormente
- Inoltre
- futuro
- Giochi
- Sesso
- genomica
- gif
- globali
- Go
- Obiettivi
- la governance
- GPU
- grafico
- grafici
- Gruppo
- Gruppo
- linee guida
- maniglia
- Salute e benessere
- assicurazione sanitaria
- assistenza sanitaria
- Eroe
- Aiuto
- aiutato
- aiutare
- aiuta
- qui
- vivamente
- escursionismo
- storia
- Ospedale
- ospedali
- ospitato
- ORE
- Come
- hpc
- HTML
- HTTPS
- ideale
- IEEE
- Immagine
- Imaging
- squilibrio
- realizzare
- importare
- competenze
- miglioramento
- in
- Inaugurale
- Inc.
- inclusi
- incorporando
- Index
- industria
- informazioni
- Infrastruttura
- Innovazione
- ingresso
- install
- esempio
- assicurazione
- Interfaccia
- Internet
- Internet delle cose
- IoT
- IT
- join
- Le
- conoscenze
- per il tuo brand
- di laboratorio
- Dipingere
- larga scala
- lanciare
- portare
- leader
- Leadership
- apprendimento
- Lunghezza
- Leva
- leveraggi
- leveraging
- Vita
- Scienze della Vita
- Life Sciences
- linea
- Lista
- elencati
- Ascolto
- caricare
- caricatore
- carichi
- locale
- a livello locale
- collocato
- Lunghi
- dei
- Los Angeles
- spento
- macchina
- machine learning
- fatto
- mantenere
- manutenzione
- make
- FA
- gestire
- direttore
- modo
- mappatura
- marzo
- si intende
- misurazioni
- Media
- medicale
- imaging medicale
- Soddisfare
- menzionato
- metodo
- metodi
- CON
- Ridurre la perdita dienergia con una
- ML
- Algoritmi ML
- modello
- modelli
- Monitorare
- monitoraggio
- Scopri di più
- Il motore
- cambiano
- in movimento
- multiplo
- Musica
- Nome
- Natura
- Navigazione
- Bisogno
- di applicazione
- esigenze
- negativo.
- Rete
- nodo
- nodi
- numero
- numpy
- ONE
- aprire
- open source
- Operazioni
- ottimale
- organizzazioni
- Altro
- al di fuori
- proprio
- Di proprietà
- proprietario
- vetro
- parametri
- parte
- partner
- partner
- Passato
- passione
- sentiero
- paziente
- pazienti
- pera
- eseguire
- performance
- esegue
- personalizzazione
- Personalizzata
- conduttura
- posto
- piano
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- per favore
- punto
- punti
- pone
- positivo
- Post
- Pratico
- precisamente
- predire
- previsione
- predizione
- presenti
- presentazione
- presidenziale
- pressione
- prevenire
- in precedenza
- Direttore
- Privacy
- un bagno
- Problema
- problemi
- processi
- Produzione
- Prodotti
- Prodotti e Servizi
- Insegnante
- progredendo
- progressione
- vietare
- progetto
- prova
- prova del concetto
- offre
- fornire
- fornisce
- fornitura
- pubblicamente
- scopo
- pytorch
- R&D
- casuale
- RARO
- tasso
- rapporto
- RE
- Lettura
- pronto
- mondo reale
- ricevuto
- Consigli
- record
- registrato
- record
- regione
- regressione
- regolamentati
- normativo
- rimuovere
- deposito
- rappresenta
- richiesta
- richiedere
- requisito
- Requisiti
- richiede
- riparazioni
- quelli
- ritorno
- problemi
- recensioni
- strada
- approssimativamente
- strada
- RIGA
- norme
- Correre
- running
- stesso
- Scala
- Scienze
- SCIENZE
- Scienziato
- script
- senza soluzione di continuità
- Secondo
- problemi di
- Cercare
- selezionato
- AUTO
- anziano
- delicata
- Serie
- Servizi
- set
- Set
- regolazione
- flessibile.
- Sette
- alcuni
- Condividi
- condiviso
- compartecipazione
- mostrato
- Spettacoli
- segno
- Segni
- simile
- Allo stesso modo
- singolo
- site
- Siti
- So
- soluzione
- Soluzioni
- risolve
- Fonte
- Meridionale
- campate
- specifico
- dividere
- stabile
- Standard
- inizia a
- iniziato
- startup
- state-of-the-art
- stati
- Stato dei servizi
- soggiorno
- Passi
- conservazione
- strutturato
- dati strutturati e non strutturati
- Studio
- style
- sottoreti
- tale
- sufficiente
- supporto
- supporti
- Indagine
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- TAG
- presa
- Target
- mirata
- Task
- tassonomia
- Tecnologie
- Tecnologia
- modello
- test
- I
- loro
- terapeutica
- cose
- Terza
- pensiero
- tre
- Attraverso
- per tutto
- tempo
- Serie storiche
- richiede tempo
- a
- strumenti
- torcia
- Torciavisione
- Totale
- pista
- traffico
- Treni
- Training
- trasferito
- studi clinici
- affidabili sul mercato
- Tipi di
- tipicamente
- sottostante
- e una comprensione reciproca
- unico
- unità
- Unito
- Stati Uniti
- unità
- Università
- University of Southern California
- Aggiornanento
- Aggiornamenti
- us
- USA
- uso
- caso d'uso
- APPREZZIAMO
- Valori
- varietà
- vario
- Fisso
- verticali
- via
- Video
- virtuale
- visibile
- importantissima
- walkthrough
- quale
- while
- OMS
- largo
- volere
- entro
- senza
- Lavora
- lavori
- di fama mondiale
- X
- anni
- Trasferimento da aeroporto a Sharm
- zefiro