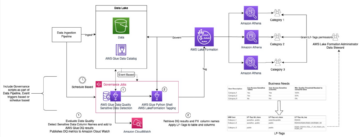
Oggi, centinaia di migliaia di clienti utilizzano i data lake per l'analisi e il machine learning. Tuttavia, i data engineer devono ripulire e preparare questi dati prima che possano essere utilizzati. I dati sottostanti devono essere accurati e recenti affinché il cliente possa prendere decisioni aziendali sicure. In caso contrario, i consumatori di dati perdono la fiducia nei dati e prendono decisioni non ottimali o errate. È un compito comune per i data engineer valutare se i dati sono accurati e recenti o meno. Oggi ci sono vari strumenti per la qualità dei dati. Tuttavia, gli strumenti comuni per la qualità dei dati di solito richiedono processi manuali per monitorare la qualità dei dati.
La qualità dei dati di AWS Glue è una funzionalità di anteprima di Colla AWS che misura e monitora la qualità dei dati di Servizio di archiviazione semplice Amazon (Amazon S3) data lake e processi di estrazione, trasformazione e caricamento (ETL) di AWS Glue. Questa è una funzione di anteprima aperta, quindi è già abilitata nel tuo account in Regioni disponibili. Puoi facilmente definire e misurare i controlli di qualità dei dati nella console AWS Glue Studio senza scrivere codici. Semplifica la tua esperienza di gestione della qualità dei dati.
Questo post è la seconda parte di una serie di quattro post per spiegare come funziona AWS Glue Data Quality. Dai un'occhiata al post precedente di questa serie:
In questo post, mostriamo come creare un processo AWS Glue che misura e monitora la qualità dei dati di una pipeline di dati. Mostriamo anche come agire in base ai risultati sulla qualità dei dati.
Panoramica della soluzione
Consideriamo un caso d'uso di esempio in cui un ingegnere di dati deve creare una pipeline di dati per importare i dati da una zona non elaborata a una zona curata in un data lake. In qualità di ingegnere dei dati, una delle tue responsabilità principali, insieme all'estrazione, alla trasformazione e al caricamento dei dati, è convalidare la qualità dei dati. L'identificazione anticipata dei problemi di qualità dei dati aiuta a prevenire l'inserimento di dati errati nella zona curata ed evitare gravi incidenti di danneggiamento dei dati.
In questo post imparerai come configurare facilmente incassato ed costume controlli di convalida dei dati nel processo AWS Glue per evitare che dati errati danneggino i dati downstream di alta qualità.
Il dataset utilizzato per questo post è generato sinteticamente; lo screenshot seguente mostra un esempio dei dati.

Configura le risorse con AWS CloudFormation
Questo post include un AWS CloudFormazione modello per una configurazione rapida. Puoi rivederlo e personalizzarlo in base alle tue esigenze.
Il modello CloudFormation genera le seguenti risorse:
- Un bucket Amazon Simple Storage Service (Amazon S3) (
gluedataqualitystudio-*). - I seguenti prefissi e oggetti nel bucket S3:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- Gestione dell'identità e dell'accesso di AWS (IAM) utenti, ruoli e policy. Il ruolo IAM (
GlueDataQualityStudio-*) dispone dell'autorizzazione per leggere e scrivere dal bucket S3. - AWS Lambda funzioni e policy IAM richieste da tali funzioni per creare ed eliminare questo stack.
Per creare le tue risorse, completa i seguenti passaggi:
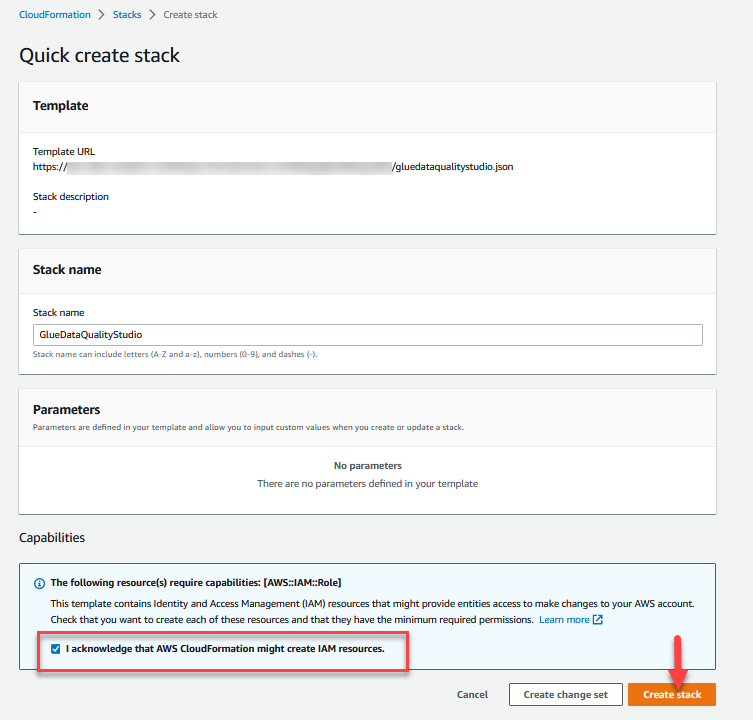
- Accedi al Console AWS CloudFormation nel
us-east-1Regione. - Scegli Avvia Stack:

- Seleziona Riconosco che AWS CloudFormation potrebbe creare risorse IAM.
- Scegli Crea stack e attendi il completamento della fase di creazione dello stack.
Implementa la soluzione
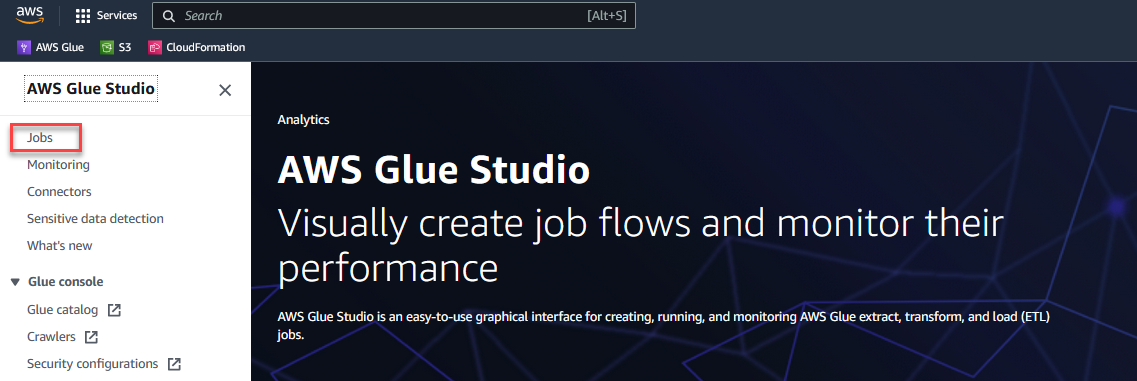
Per iniziare a configurare la tua soluzione, completa i seguenti passaggi:
- Sulla Console AWS Glue Studioscegli Offerte di lavoro nel pannello di navigazione.
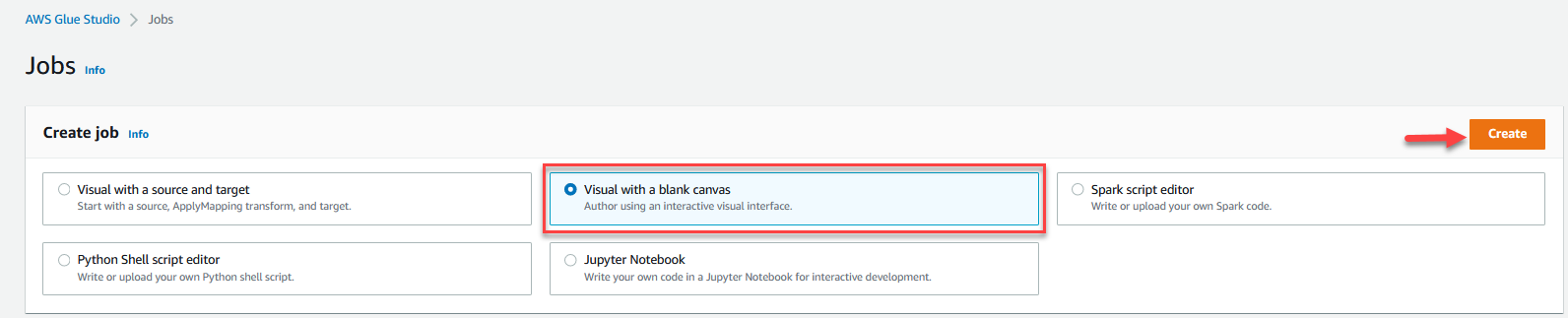
- Seleziona Visual con una tela bianca e scegli Creare.
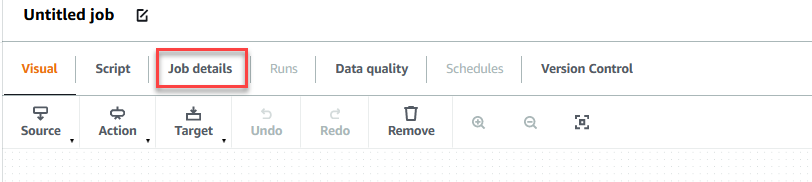
- Scegliere il Dettagli di lavoro scheda per configurare il lavoro.
- Nel Nome, accedere
GlueDataQualityStudio. - Nel Ruolo IAM, scegli il ruolo che inizia con
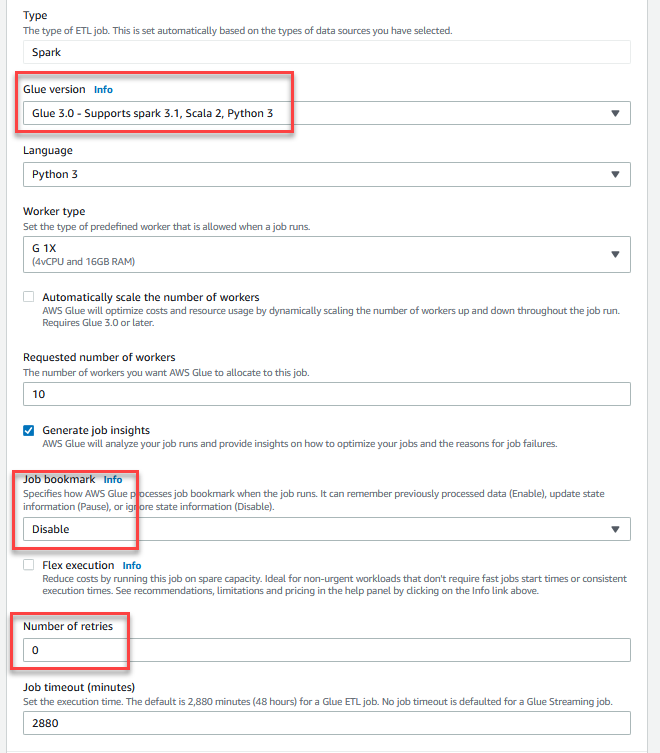
GlueDataQualityStudio-*. - Nel Versione a collascegli Colla 3.0.
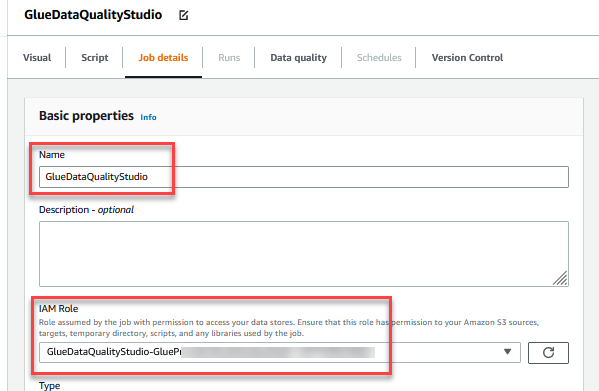
- Nel Segnalibro di lavoroscegli Disabilita. Ciò consente di eseguire questo processo più volte con lo stesso set di dati di input.
- Nel Numero di tentativi, accedere
0.
- Nel Proprietà avanzate sezione, fornire il bucket S3 creato dal modello CloudFormation (a partire da
gluedataqualitystudio-*).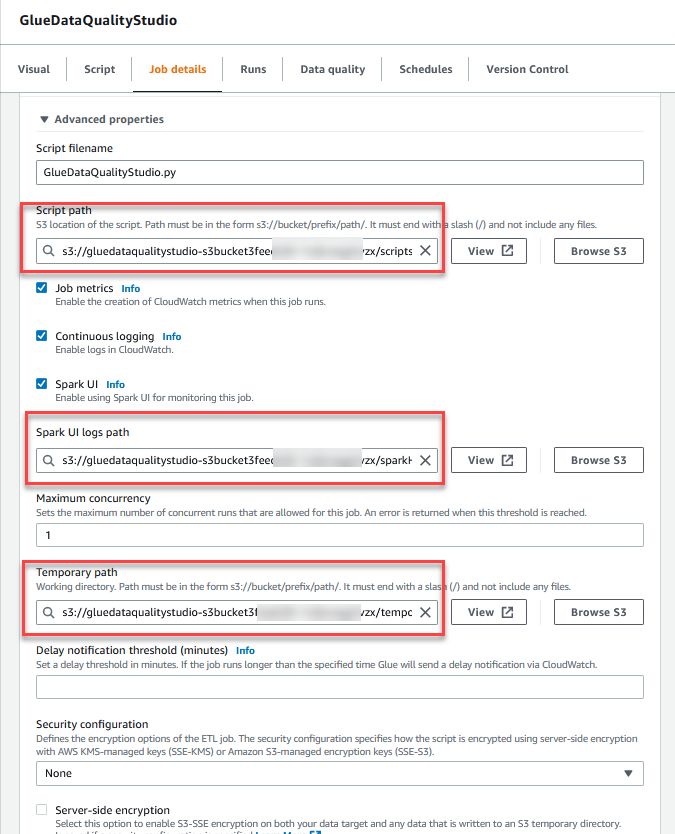
- Scegli Risparmi.
- Dopo aver salvato il lavoro, scegli il Visivo scheda e sul Fonte menù, scegliere Amazon S3.
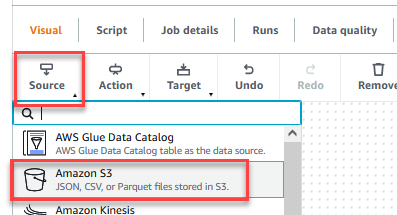
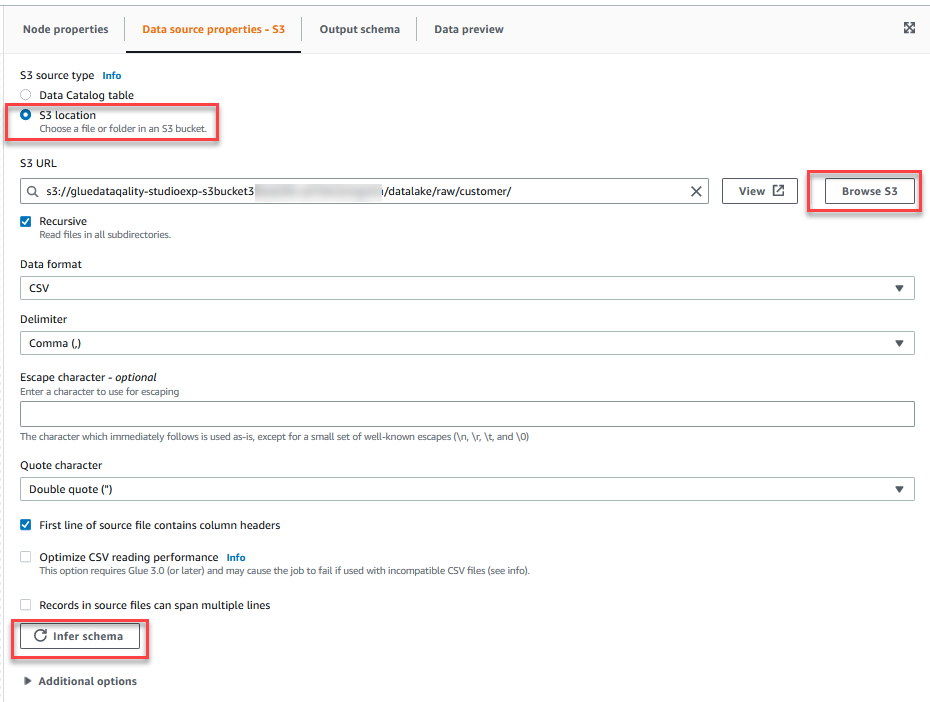
- Sulla Proprietà dell'origine dati - S3 scheda, per Tipo di sorgente S3, selezionare Posizione S3.
- Scegli Sfoglia S3 e vai al prefisso
/datalake/raw/customer/nel bucket S3 a partire dagluedataqualitystudio-*. - Scegli Deduci schema.
- Sulla Action menù, scegliere Valutare la qualità dei dati.
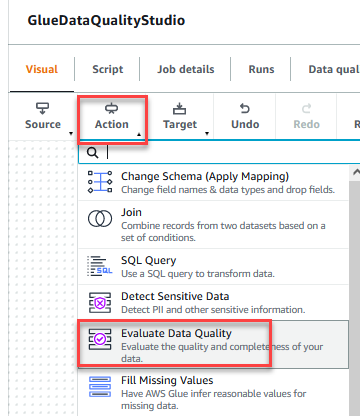
- Scegliere il Valutare la qualità dei dati nodo.
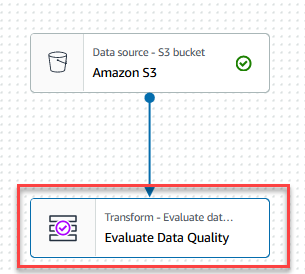
Sulla Trasformare scheda, ora puoi iniziare a creare regole di qualità dei dati. La prima regola che crei è controllare seCustomer_IDè univoco e non nullo utilizzando ilisPrimaryKeyregola. - Sulla Tipi di regole scheda del Generatore di regole DQDL, Cercare
isprimarykeye scegli il segno più.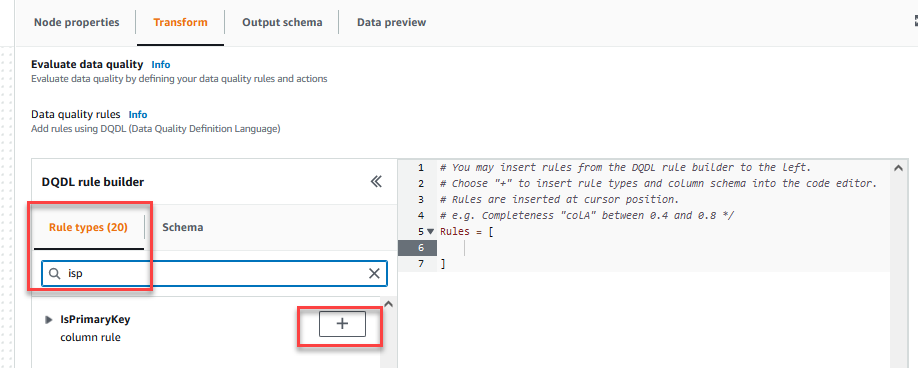
- Sulla Schema scheda del Generatore di regole DQDL, scegli il segno più accanto a
Customer_ID. - Nell'editor delle regole, elimina
id.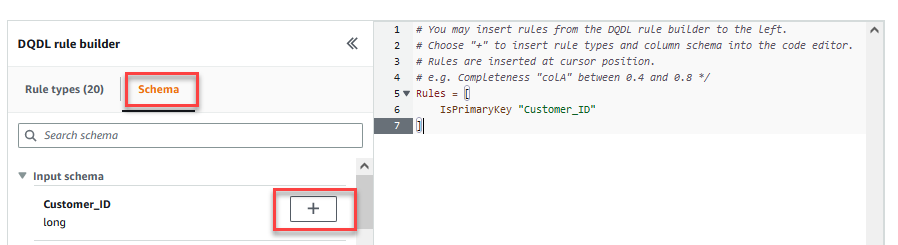
La prossima regola che aggiungiamo verifica che il fileFirst_Nameil valore della colonna è presente per tutte le righe. - Puoi anche inserire le regole sulla qualità dei dati direttamente nell'editor delle regole. Aggiungi una virgola (,) e inserisci
IsComplete "First_Name",dopo la prima regola.
Successivamente, aggiungi una regola personalizzata per verificare che non esista alcuna riga senzaTelephoneorEmail. - Inserisci la seguente regola personalizzata nell'editor delle regole:

La funzione Valuta la qualità dei dati fornisce azioni per gestire l'esito di un lavoro in base ai risultati della qualità del lavoro. - Per questo post, seleziona Fallire il lavoro quando la qualità dei dati fallisce e scegli Processo non riuscito senza caricare il target dati Azioni. Nel Impostazione dell'output della qualità dei dati sezione, scegliere Sfoglia S3 e vai al prefisso
dqresultsnel bucket S3 a partire dagluedataqualitystudio-*.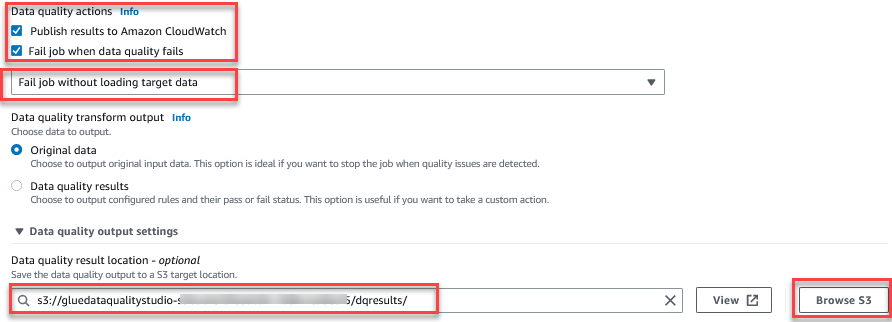
- Sulla Target menù, scegliere Amazon S3.
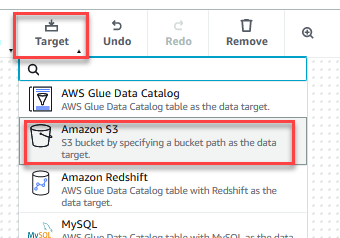
- Scegliere il Destinazione dati: bucket S3 nodo.
- Sulla Proprietà del target di dati - S3 scheda, per Formatoscegli Parquet, E per Tipo di compressionescegli Elegante.
- Nel S3 Posizione del bersaglioscegli Sfoglia S3 e vai al prefisso
/datalake/curated/customer/nel bucket S3 a partire dagluedataqualitystudio-*.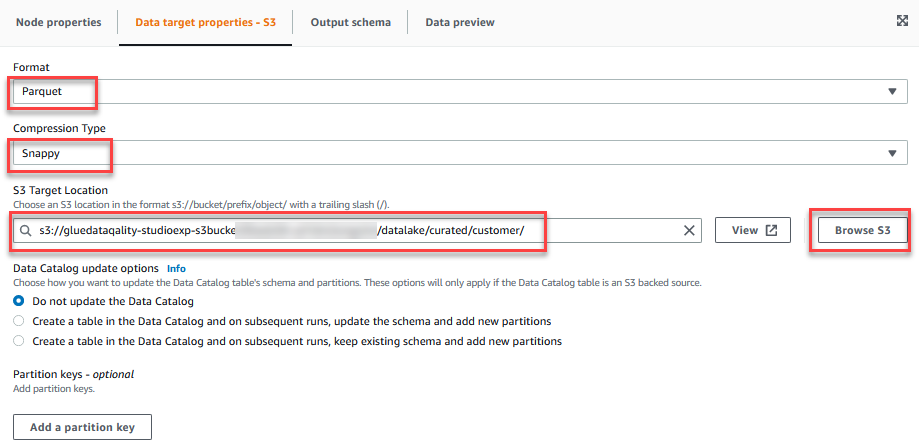
- Scegli Risparmi, Quindi scegliere Correre.
 È possibile visualizzare i dettagli dell'esecuzione del lavoro nella scheda Esecuzioni. Nel nostro esempio, il lavoro fallisce con il messaggio di errore "AssertionError: il lavoro non è riuscito a causa di regole DQ non riuscite per il nodo: .”
È possibile visualizzare i dettagli dell'esecuzione del lavoro nella scheda Esecuzioni. Nel nostro esempio, il lavoro fallisce con il messaggio di errore "AssertionError: il lavoro non è riuscito a causa di regole DQ non riuscite per il nodo: .”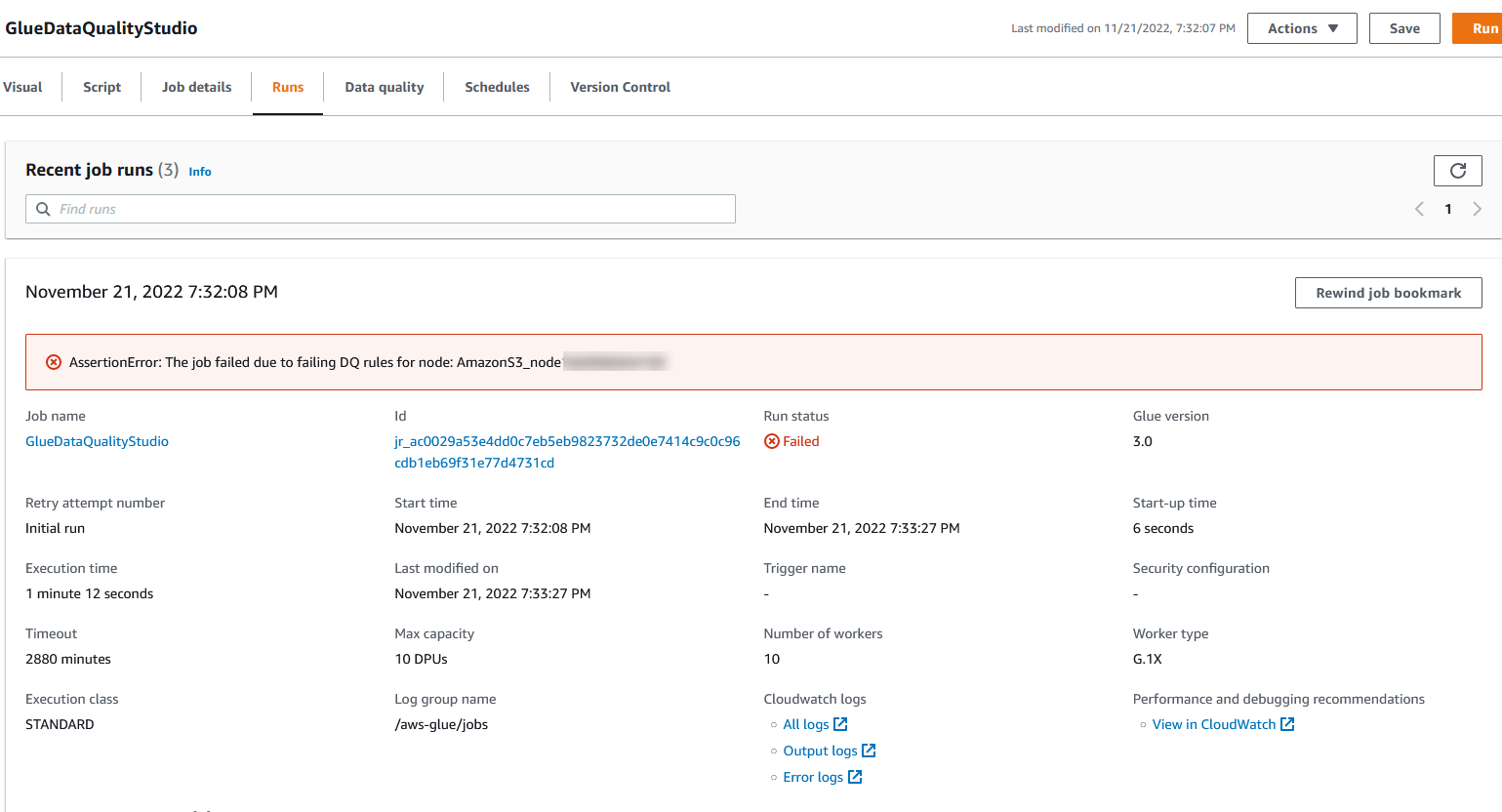 È possibile esaminare il risultato sulla qualità dei dati nella scheda Qualità dei dati. Nel nostro esempio, la convalida della qualità dei dati personalizzata non è riuscita perché una delle righe nel set di dati non aveva n
È possibile esaminare il risultato sulla qualità dei dati nella scheda Qualità dei dati. Nel nostro esempio, la convalida della qualità dei dati personalizzata non è riuscita perché una delle righe nel set di dati non aveva n TelephoneorEmailvalore. I risultati di Evaluate Data Quality vengono scritti anche nel bucket S3 in formato JSON in base al parametro di posizione dei risultati di qualità dei dati del nodo.
I risultati di Evaluate Data Quality vengono scritti anche nel bucket S3 in formato JSON in base al parametro di posizione dei risultati di qualità dei dati del nodo. - Spostarsi
dqresultsprefisso sotto l'inizio del bucket S3gluedataqualitystudio-*. Vedrai che il risultato della qualità dei dati è partizionato per data.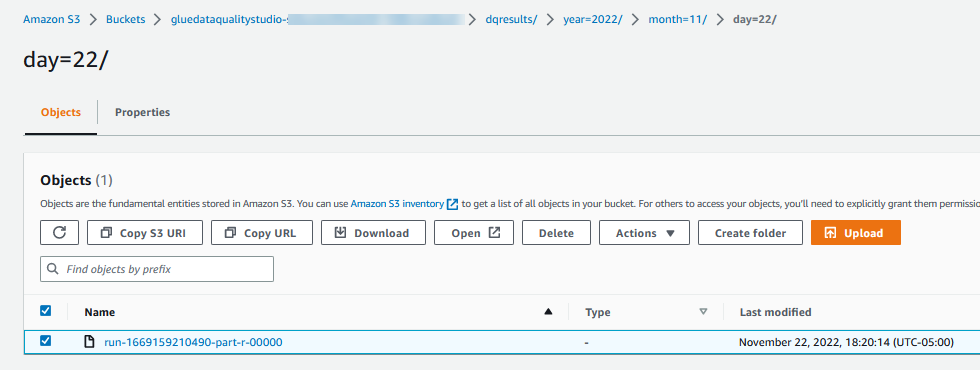
Di seguito è riportato l'output del file JSON. Puoi utilizzare questo output di file per creare dashboard di visualizzazione della qualità dei dati personalizzati.

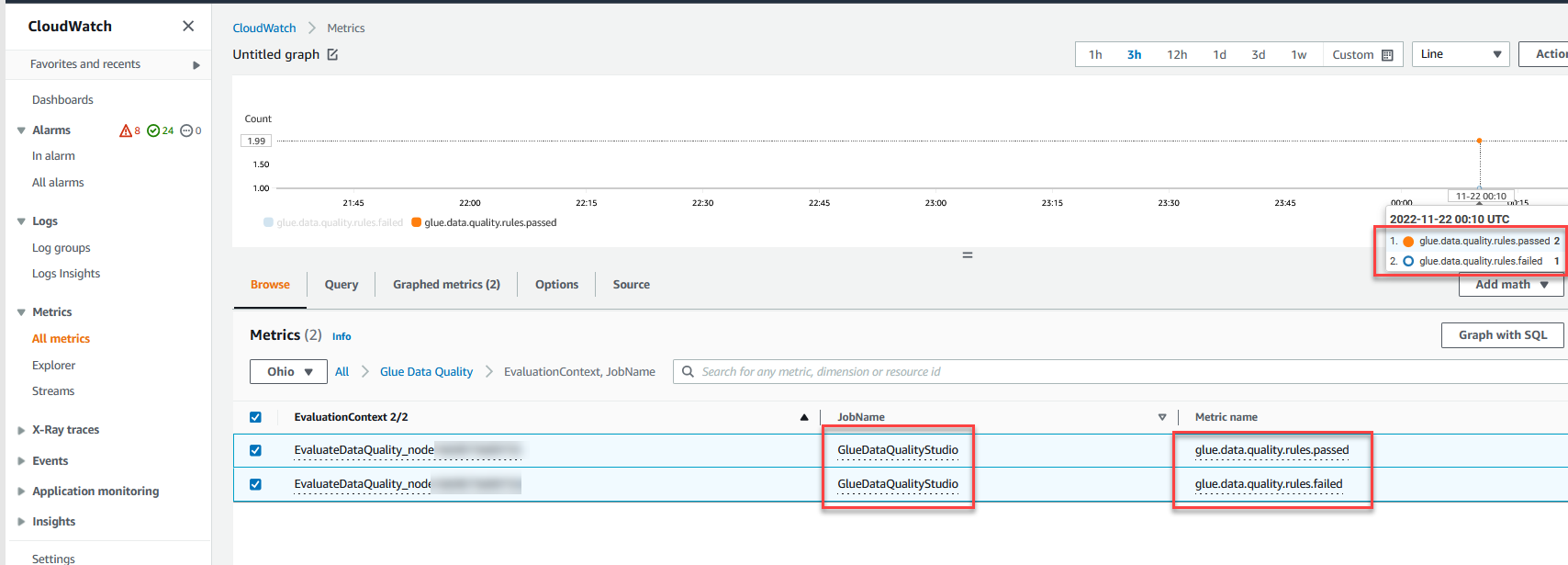
Puoi anche monitorare il Valutare la qualità dei dati nodo attraverso Amazon Cloud Watch metriche e impostare allarmi per inviare notifiche sui risultati della qualità dei dati. Per ulteriori informazioni su come configurare gli allarmi CloudWatch, fare riferimento a Utilizzo degli allarmi Amazon CloudWatch.
ripulire
Per evitare di incorrere in addebiti futuri e per ripulire ruoli e criteri inutilizzati, elimina le risorse che hai creato:
- Eliminare il
GlueDataQualityStudiolavoro che hai creato come parte di questo post. - Nella console AWS CloudFormation, elimina il file
GlueDataQualityStudiopila.
Conclusione
AWS Glue Data Quality offre un modo semplice per misurare e monitorare la qualità dei dati della tua pipeline ETL. In questo post, hai imparato come intraprendere le azioni necessarie in base ai risultati della qualità dei dati, che ti aiutano a mantenere standard di dati elevati e a prendere decisioni aziendali sicure.
Per ulteriori informazioni su AWS Glue Data Quality, consulta la documentazione:
Informazioni sugli autori
 Deenbandhu Prasad è un Senior Analytics Specialist presso AWS, specializzato in servizi di big data. È appassionato di aiutare i clienti a creare un'architettura di dati moderna su AWS Cloud. Ha aiutato clienti di tutte le dimensioni a implementare soluzioni di gestione dei dati, data warehouse e data lake.
Deenbandhu Prasad è un Senior Analytics Specialist presso AWS, specializzato in servizi di big data. È appassionato di aiutare i clienti a creare un'architettura di dati moderna su AWS Cloud. Ha aiutato clienti di tutte le dimensioni a implementare soluzioni di gestione dei dati, data warehouse e data lake.
 Yannis Mentekidis è un Senior Software Development Engineer nel team di AWS Glue.
Yannis Mentekidis è un Senior Software Development Engineer nel team di AWS Glue.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Chi siamo
- accesso
- Il mio account
- preciso
- riconoscere
- Action
- azioni
- Dopo shavasana, sedersi in silenzio; saluti;
- Tutti
- consente
- già
- Amazon
- analitica
- ed
- architettura
- AWS
- AWS CloudFormazione
- Colla AWS
- Vasca
- dati errati
- basato
- perché
- prima
- Big
- Big Data
- costruire
- Costruzione
- affari
- Custodie
- oneri
- dai un'occhiata
- Controlli
- Scegli
- Cloud
- Colonna
- Uncommon
- completamento di una
- fiducioso
- Prendere in considerazione
- consolle
- Consumatori
- Corruzione
- creare
- creato
- creazione
- a cura
- costume
- cliente
- Clienti
- personalizzare
- dati
- Lago di dati
- gestione dei dati
- Data
- decisioni
- dettagli
- Mercato
- direttamente
- documentazione
- facilmente
- editore
- ingegnere
- Ingegneri
- entrare
- errore
- Etere (ETH)
- valutare
- esempio
- esiste
- esperienza
- Spiegare
- estratto
- fallito
- fallisce
- caratteristica
- Compila il
- Nome
- i seguenti
- formato
- da
- funzioni
- futuro
- generato
- genera
- ottenere
- aiutato
- aiutare
- aiuta
- Alta
- alta qualità
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- centinaia
- identificazione
- Identità
- realizzare
- in
- inclusi
- ingresso
- sicurezza
- IT
- Lavoro
- Offerte di lavoro
- json
- Le
- lago
- IMPARARE
- imparato
- apprendimento
- caricare
- Caricamento in corso
- località
- perdere
- macchina
- machine learning
- mantenere
- make
- gestire
- gestione
- gestione
- Manuale
- misurare
- analisi
- Menu
- messaggio
- Metrica
- forza
- moderno
- Monitorare
- monitor
- Scopri di più
- multiplo
- Navigare
- Navigazione
- necessaria
- esigenze
- GENERAZIONE
- nodo
- notifiche
- oggetti
- Offerte
- ONE
- aprire
- altrimenti
- vetro
- parametro
- parte
- appassionato
- autorizzazione
- conduttura
- sistemazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- più
- Termini e Condizioni
- Post
- Preparare
- presenti
- prevenire
- Anteprima
- precedente
- primario
- i processi
- proprietà
- fornire
- fornisce
- qualità
- Presto
- Crudo
- Leggi
- recente
- regione
- richiedere
- necessario
- Risorse
- colpevole
- Risultati
- recensioni
- Ruolo
- ruoli
- RIGA
- Regola
- norme
- Correre
- stesso
- Cerca
- Sezione
- Serie
- servizio
- Servizi
- set
- regolazione
- flessibile.
- mostrare attraverso le sue creazioni
- Spettacoli
- segno
- Un'espansione
- Dimensioni
- So
- Software
- lo sviluppo del software
- soluzione
- Soluzioni
- Fonte
- specialista
- specializzata
- pila
- standard
- inizia a
- iniziato
- Di partenza
- step
- Passi
- conservazione
- studio
- Completo
- sinteticamente
- Fai
- Target
- Task
- team
- modello
- I
- migliaia
- Attraverso
- volte
- a
- oggi
- strumenti
- Trasformare
- trasformazione
- Affidati ad
- per
- sottostante
- unico
- non usato
- uso
- caso d'uso
- utenti
- generalmente
- CONVALIDARE
- convalida
- APPREZZIAMO
- vario
- Visualizza
- visualizzazione
- aspettare
- se
- quale
- volere
- senza
- lavori
- scrivere
- scrittura
- scritto
- Trasferimento da aeroporto a Sharm
- zefiro