Ogni giorno, i dispositivi Amazon elaborano e analizzano miliardi di transazioni dai team globali di spedizione, inventario, capacità, fornitura, vendite, marketing, produttori e assistenza clienti. Questi dati vengono utilizzati nell'approvvigionamento dell'inventario dei dispositivi per soddisfare le richieste dei clienti Amazon. Con i volumi di dati che mostrano un tasso di crescita percentuale a due cifre su base annua e la pandemia di COVID che ha sconvolto la logistica globale nel 2021, è diventato più critico scalare e generare dati quasi in tempo reale.
Questo post mostra come siamo migrati a un data lake serverless basato su AWS che utilizza automaticamente i dati da più fonti e formati diversi. Inoltre, ha creato ulteriori opportunità per i nostri data scientist e ingegneri di utilizzare servizi di intelligenza artificiale e machine learning (ML) per alimentare e analizzare continuamente i dati.
Sfide e problemi di progettazione
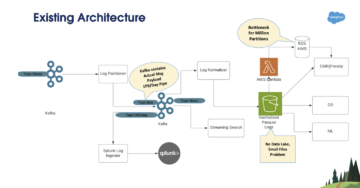
La nostra architettura legacy utilizzata principalmente Cloud di calcolo elastico di Amazon (Amazon EC2) per estrarre i dati da varie origini dati eterogenee interne e API REST con la combinazione di Servizio di archiviazione semplice Amazon (Amazon S3) per caricare i dati e Amazon RedShift per ulteriori analisi e generazione degli ordini di acquisto.
Abbiamo riscontrato che questo approccio ha comportato alcune carenze e quindi ha portato a miglioramenti nelle seguenti aree:
- Velocità dello sviluppatore – A causa della mancanza di unificazione e rilevamento dello schema, che sono le ragioni principali degli errori di runtime, gli sviluppatori spesso hanno dedicato del tempo a gestire problemi operativi e di manutenzione.
- Scalabilità – La maggior parte di questi set di dati è condivisa in tutto il mondo. Pertanto, dobbiamo rispettare i limiti di ridimensionamento durante l'interrogazione dei dati.
- Minima manutenzione dell'infrastruttura – Il processo corrente si estende su più elaborazioni a seconda dell'origine dati. Pertanto, la riduzione della manutenzione dell'infrastruttura è fondamentale.
- Reattività alle modifiche dell'origine dati – Il nostro attuale sistema ottiene i dati da vari data store e servizi eterogenei. Qualsiasi aggiornamento a tali servizi richiede mesi di cicli di sviluppo. I tempi di risposta per queste fonti di dati sono fondamentali per i nostri principali stakeholder. Pertanto, dobbiamo adottare un approccio basato sui dati per selezionare un'architettura ad alte prestazioni.
- Archiviazione e ridondanza – A causa degli archivi e dei modelli di dati eterogenei, è stato difficile archiviare i diversi set di dati dei vari team di stakeholder aziendali. Pertanto, il controllo delle versioni insieme ai dati incrementali e differenziali da confrontare fornirà una notevole capacità di generare piani più ottimizzati
- Fuggitivo e accessibilità – A causa della natura volatile della logistica, alcuni team di stakeholder aziendali hanno l'obbligo di analizzare i dati su richiesta e generare il piano ottimale quasi in tempo reale per gli ordini di acquisto. Ciò introduce la necessità sia del polling che del push dei dati per l'accesso e l'analisi quasi in tempo reale.
Strategia di attuazione
Sulla base di questi requisiti, abbiamo cambiato strategia e iniziato ad analizzare ogni problema per identificare la soluzione. Dal punto di vista dell'architettura, abbiamo scelto un modello serverless e la linea d'azione dell'architettura del data lake fa riferimento a tutte le lacune architettoniche e le funzionalità impegnative che abbiamo determinato facessero parte dei miglioramenti. Da un punto di vista operativo, abbiamo progettato un nuovo modello di responsabilità condivisa per l'inserimento dei dati utilizzando Colla AWS invece di servizi interni (API REST) progettati su Amazon EC2 per estrarre i dati. Abbiamo anche usato AWS Lambda per il trattamento dei dati. Poi abbiamo scelto Amazzone Atena come nostro servizio di interrogazione. Per ottimizzare e migliorare ulteriormente la velocità degli sviluppatori per i nostri consumatori di dati, abbiamo aggiunto Amazon DynamoDB come archivio di metadati per diverse origini dati che arrivano nel data lake. Queste due decisioni hanno guidato ogni decisione di progettazione e implementazione che abbiamo preso.
Il diagramma seguente illustra l'architettura

Nelle sezioni seguenti, esaminiamo ogni componente dell'architettura in modo più dettagliato mentre ci spostiamo nel flusso del processo.
Colla AWS per ETL
Per soddisfare la domanda dei clienti supportando al contempo la scala delle origini dati delle nuove aziende, era fondamentale per noi disporre di un elevato grado di agilità, scalabilità e reattività nell'interrogare varie origini dati.
AWS Glue è un servizio di integrazione dei dati serverless che consente agli utenti di analisi di scoprire, preparare, spostare e integrare facilmente i dati da più origini. Puoi usarlo per l'analisi, il machine learning e lo sviluppo di applicazioni. Include inoltre produttività aggiuntiva e strumenti DataOps per la creazione, l'esecuzione di lavori e l'implementazione di flussi di lavoro aziendali.
Con AWS Glue, puoi scoprire e connetterti a più di 70 origini dati diverse e gestire i tuoi dati in un catalogo dati centralizzato. Puoi creare, eseguire e monitorare visivamente le pipeline di estrazione, trasformazione e caricamento (ETL) per caricare i dati nei tuoi data lake. Inoltre, puoi cercare e interrogare immediatamente i dati catalogati utilizzando Athena, Amazon EMRe Spettro Amazon Redshift.
AWS Glue ci ha semplificato la connessione ai dati in vari datastore, la modifica e la pulizia dei dati secondo necessità e il caricamento dei dati in uno store fornito da AWS per una visualizzazione unificata. I lavori di AWS Glue possono essere pianificati o richiamati su richiesta per estrarre i dati dalla risorsa del cliente e dal data lake.
Alcune responsabilità di questi lavori sono le seguenti:
- Estrazione e conversione di un'entità di origine in un'entità di dati
- Arricchisci i dati per contenere anno, mese e giorno per una migliore catalogazione e includi un ID snapshot per una migliore query
- Esegui la convalida dell'input e la generazione del percorso per Amazon S3
- Associare i metadati accreditati in base al sistema di origine
L'interrogazione delle API REST dai servizi interni è una delle nostre sfide principali e, considerando l'infrastruttura minima, volevamo utilizzarle in questo progetto. I connettori AWS Glue ci hanno aiutato a rispettare i requisiti e l'obiettivo. Per interrogare i dati dalle API REST e da altre origini dati, abbiamo utilizzato i moduli PySpark e JDBC.
AWS Glue supporta un'ampia varietà di tipi di connessione. Per maggiori dettagli, fare riferimento a Tipi di connessione e opzioni per ETL in AWS Glue.
Benna S3 come zona di atterraggio
Abbiamo utilizzato un bucket S3 come zona di destinazione immediata dei dati estratti, che vengono ulteriormente elaborati e ottimizzati.
Lambda come trigger ETL di AWS Glue
Abbiamo abilitato le notifiche degli eventi S3 sul bucket S3 per attivare Lambda, che suddivide ulteriormente i nostri dati. I dati sono partizionati su InputDataSetName, Year, Month e Date. Qualsiasi processore di query in esecuzione su questi dati analizzerà solo un sottoinsieme di dati per una migliore ottimizzazione dei costi e delle prestazioni. I nostri dati possono essere archiviati in vari formati, come CSV, JSON e Parquet.
I dati grezzi non sono l'ideale per la maggior parte dei nostri casi d'uso per generare il piano ottimale perché spesso hanno duplicati o tipi di dati errati. Ancora più importante, i dati sono in più formati, ma li abbiamo rapidamente modificati e abbiamo osservato significativi miglioramenti delle prestazioni delle query grazie all'utilizzo del formato Parquet. Qui, abbiamo utilizzato uno dei suggerimenti sulle prestazioni in I 10 migliori suggerimenti per l'ottimizzazione delle prestazioni per Amazon Athena.
Lavori AWS Glue per ETL
Volevamo una migliore segregazione e accessibilità dei dati, quindi abbiamo scelto di avere un bucket S3 diverso per migliorare ulteriormente le prestazioni. Abbiamo utilizzato gli stessi lavori di AWS Glue per trasformare ulteriormente e caricare i dati nel bucket S3 richiesto e una parte dei metadati estratti in DynamoDB.
DynamoDB come archivio di metadati
Ora che abbiamo i dati, vari stakeholder aziendali li consumano ulteriormente. Questo ci lascia con due domande: quali dati di origine risiedono nel data lake e quale versione. Abbiamo scelto DynamoDB come archivio di metadati, che fornisce i dettagli più recenti ai consumatori per interrogare i dati in modo efficace. Ogni set di dati nel nostro sistema è identificato in modo univoco dall'ID dello snapshot, che possiamo cercare nel nostro archivio di metadati. I client accedono a questo archivio dati con un'API.
Amazon S3 come data lake
Per una migliore qualità dei dati, abbiamo estratto i dati arricchiti in un altro bucket S3 con lo stesso processo AWS Glue.
Crawler di colla AWS
I crawler sono la "salsa segreta" che ci consente di essere reattivi ai cambiamenti dello schema. Durante tutto il processo, abbiamo scelto di rendere ogni passaggio il più possibile indipendente dallo schema, il che consente a qualsiasi modifica dello schema di fluire fino a raggiungere AWS Glue. Con un crawler, potremmo mantenere le modifiche agnostiche che si verificano nello schema. Questo ci ha aiutato a eseguire automaticamente la scansione dei dati da Amazon S3 e a generare lo schema e le tabelle.
Catalogo dati di AWS Glue
Il catalogo dati ci ha aiutato a mantenere il catalogo come indice della posizione dei dati, dello schema e dei parametri di runtime in Amazon S3. Le informazioni nel Catalogo dati vengono archiviate come tabelle di metadati, in cui ogni tabella specifica un singolo archivio dati.
Athena per le query SQL
Athena è un servizio di query interattivo che semplifica l'analisi dei dati in Amazon S3 utilizzando SQL standard. Athena è serverless, quindi non c'è infrastruttura da gestire e paghi solo per le query che esegui. Abbiamo considerato la stabilità operativa e l'aumento della velocità degli sviluppatori come i nostri principali fattori di miglioramento.
Abbiamo ulteriormente ottimizzato il processo per interrogare Athena in modo che gli utenti possano collegare i valori e le query per ottenere dati da Athena creando quanto segue:
- An Kit di sviluppo cloud AWS (AWS CDK) per creare l'infrastruttura Athena e Gestione dell'identità e dell'accesso di AWS (IAM) per accedere ai bucket S3 del data lake e al Data Catalog da qualsiasi account
- Una libreria in modo che il client possa fornire un ruolo IAM, una query, un formato dei dati e un percorso di output per avviare una query Athena e ottenere lo stato e il risultato della query eseguita nel bucket di sua scelta.
Interrogare Athena è un processo in due fasi:
- Avvia esecuzione query – Questo avvia l'esecuzione della query e ottiene l'ID di esecuzione. Gli utenti possono fornire il percorso di output in cui verrà archiviato l'output della query.
- GetQueryExecution – Questo ottiene lo stato della query perché l'esecuzione è asincrona. In caso di successo, puoi interrogare l'output in un file S3 o tramite API.
Il metodo di supporto per avviare l'esecuzione della query e ottenere il risultato sarebbe nella libreria.
Servizio di metadati del data lake
Questo servizio è sviluppato su misura e interagisce con DynamoDB per ottenere i metadati (nome del set di dati, ID snapshot, stringa di partizione, timestamp e collegamento S3 dei dati) sotto forma di API REST. Quando lo schema viene rilevato, i client utilizzano Athena come query processor per eseguire query sui dati.
Poiché tutti i set di dati con un ID snapshot sono partizionati, la query di join non comporta una scansione completa della tabella ma solo una scansione della partizione su Amazon S3. Abbiamo utilizzato Athena come nostro processore di query per la sua facilità nel non gestire la nostra infrastruttura di query. Successivamente, se riteniamo di aver bisogno di qualcosa di più, possiamo utilizzare Redshift Spectrum o Amazon EMR.
Conclusione
I team di Amazon Devices hanno scoperto un valore significativo passando a un'architettura di data lake utilizzando AWS Glue, che ha consentito a più stakeholder aziendali globali di acquisire dati in modi più produttivi. Ciò ha consentito ai team di generare il piano ottimale per effettuare ordini di acquisto per i dispositivi analizzando i diversi set di dati quasi in tempo reale con la logica aziendale appropriata per risolvere i problemi della catena di approvvigionamento, della domanda e delle previsioni.
Dal punto di vista operativo, l'investimento ha già iniziato a dare i suoi frutti:
- Ha standardizzato i nostri meccanismi di acquisizione, archiviazione e recupero, risparmiando tempo per l'onboarding. Prima dell'implementazione di questo sistema, l'onboarding di un set di dati richiedeva 1 mese. Grazie alla nostra nuova architettura, siamo stati in grado di integrare 15 nuovi set di dati in meno di 2 mesi, il che ha migliorato la nostra agilità del 70%.
- Ha rimosso i colli di bottiglia del ridimensionamento, creando un sistema omogeneo in grado di scalare rapidamente fino a migliaia di esecuzioni.
- La soluzione ha aggiunto la convalida dello schema e della qualità dei dati prima di accettare qualsiasi input e rifiutarli se vengono rilevate violazioni della qualità dei dati.
- Ha semplificato il recupero dei set di dati supportando simulazioni future e casi d'uso di back tester che richiedono input con versione. Ciò semplificherà l'avvio e il test dei modelli.
- La soluzione ha creato un'infrastruttura comune che può essere facilmente estesa ad altri team in DIAL che hanno problemi simili con i casi d'uso di inserimento, archiviazione e recupero dei dati.
- I nostri costi operativi sono diminuiti di quasi il 90%.
- I nostri data scientist e ingegneri possono accedere in modo efficiente a questo data lake per eseguire altre analisi e avere un approccio predittivo come opportunità futura per generare piani accurati per gli ordini di acquisto.
I passaggi in questo post possono aiutarti a pianificare la creazione di una strategia di dati moderna simile utilizzando i servizi gestiti da AWS per importare dati da fonti diverse, creare automaticamente cataloghi di metadati, condividere i dati senza problemi tra il data lake e il data warehouse e creare avvisi nell'evento di un errore del flusso di lavoro dei dati orchestrato.
Circa gli autori
 Avinash Kolluri è Senior Solutions Architect presso AWS. Lavora su Amazon Alexa e dispositivi per progettare e progettare moderne soluzioni distribuite. La sua passione è creare soluzioni economiche e altamente scalabili su AWS. Nel tempo libero ama cucinare ricette fusion e viaggiare.
Avinash Kolluri è Senior Solutions Architect presso AWS. Lavora su Amazon Alexa e dispositivi per progettare e progettare moderne soluzioni distribuite. La sua passione è creare soluzioni economiche e altamente scalabili su AWS. Nel tempo libero ama cucinare ricette fusion e viaggiare.
 Vipul Verma è un Sr.Software Engineer presso Amazon.com. È in Amazon dal 2015, risolvendo le sfide del mondo reale attraverso la tecnologia che ha un impatto diretto e migliora la vita dei clienti Amazon. Nel tempo libero ama fare escursioni.
Vipul Verma è un Sr.Software Engineer presso Amazon.com. È in Amazon dal 2015, risolvendo le sfide del mondo reale attraverso la tecnologia che ha un impatto diretto e migliora la vita dei clienti Amazon. Nel tempo libero ama fare escursioni.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- capacità
- capace
- accesso
- accessibile
- accessibilità
- accreditato
- preciso
- operanti in
- Action
- aggiunto
- aggiuntivo
- AI
- Alexa
- Tutti
- consente
- già
- Amazon
- amazon alexa
- Amazon EC2
- Amazon EMR
- Amazon.com
- .
- analitica
- analizzare
- l'analisi
- ed
- Un altro
- api
- API
- Applicazioni
- Sviluppo di applicazioni
- approccio
- opportuno
- architettonico
- architettura
- aree
- autore
- automaticamente
- AWS
- Colla AWS
- precedente
- basato
- perché
- prima
- Meglio
- fra
- miliardi
- costruire
- costruito
- affari
- detto
- Ultra-Grande
- casi
- catalogo
- cataloghi
- centralizzata
- catena
- sfide
- impegnativo
- Modifiche
- scegliere
- ha scelto
- cliente
- clienti
- Cloud
- COM
- combinazione
- Uncommon
- confrontare
- componente
- Calcolare
- Connettiti
- veloce
- considerato
- considerando
- consumare
- Consumatori
- continuamente
- cucina
- Nucleo
- Costo
- costo effettivo
- Costi
- potuto
- Covidien
- crawler
- creare
- creato
- Creazione
- critico
- Corrente
- costume
- cliente
- Servizio clienti
- Clienti
- cicli
- dati
- integrazione dei dati
- Lago di dati
- elaborazione dati
- qualità dei dati
- strategia di dati
- data warehouse
- data-driven
- dataset
- Data
- giorno
- trattare
- decisione
- decisioni
- Laurea
- Richiesta
- richieste
- Dipendente
- Design
- progettato
- dettaglio
- dettagli
- determinato
- sviluppato
- Costruttori
- sviluppatori
- Mercato
- dispositivi
- diverso
- direttamente
- scopri
- scoperto
- scoperta
- distribuito
- paesaggio differenziato
- non
- duplicati
- ogni
- facilmente
- in maniera efficace
- in modo efficiente
- o
- abilitato
- Abilita
- ingegnere
- Ingegneri
- arricchito
- entità
- Etere (ETH)
- Evento
- Ogni
- estratto
- estrarre i dati
- Fattori
- Fallimento
- Caduto
- Caratteristiche
- pochi
- Compila il
- flusso
- i seguenti
- segue
- Previsione
- modulo
- formato
- essere trovato
- da
- pieno
- ulteriormente
- Inoltre
- fusione
- futuro
- Guadagni
- generare
- la generazione di
- ELETTRICA
- ottenere
- ottenere
- globali
- business globale
- globo
- scopo
- Crescita
- avendo
- Aiuto
- aiutato
- qui
- Alta
- Alte prestazioni
- vivamente
- escursionismo
- Come
- HTML
- HTTPS
- IAM
- ideale
- identificato
- identificare
- Identità
- immediato
- subito
- Impact
- implementazione
- Implementazione
- competenze
- migliorata
- miglioramento
- miglioramenti
- in
- includere
- inclusi
- crescente
- Index
- informazioni
- Infrastruttura
- ingresso
- invece
- integrare
- integrazione
- interattivo
- interagisce
- interno
- Introduce
- inventario
- investimento
- problema
- sicurezza
- IT
- Lavoro
- Offerte di lavoro
- join
- json
- Le
- Dipingere
- lago
- atterraggio
- con i più recenti
- lancio
- apprendimento
- Eredità
- Biblioteca
- Vita
- limiti
- linea
- LINK
- caricare
- località
- logistica
- Guarda
- macchina
- machine learning
- fatto
- mantenere
- manutenzione
- make
- FA
- gestire
- gestione
- Marketing
- Soddisfare
- Metadati
- metodo
- Metrica
- minimo
- ML
- modello
- modelli
- moderno
- modificato
- moduli
- Monitorare
- Mese
- mese
- Scopri di più
- maggior parte
- cambiano
- in movimento
- multiplo
- Nome
- Natura
- Bisogno
- di applicazione
- New
- notifiche
- Onboard
- Procedura di Onboarding
- ONE
- operativo
- operativa
- Opportunità
- Opportunità
- ottimale
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- Opzioni
- ordini
- Altro
- pandemia
- parte
- passione
- sentiero
- Paga le
- percentuale
- eseguire
- performance
- prospettiva
- posto
- piano
- piani
- Platone
- Platone Data Intelligence
- PlatoneDati
- possibile
- Post
- Preparare
- principalmente
- primario
- problemi
- processi
- lavorazione
- Processore
- Produttori
- produttivo
- della produttività
- progetto
- fornire
- fornisce
- Acquista
- spingendo
- qualità
- Domande
- rapidamente
- tasso
- Crudo
- dati grezzi
- raggiungere
- mondo reale
- tempo reale
- motivi
- Ricette
- riducendo
- si riferisce
- notevole
- rimosso
- necessario
- requisito
- Requisiti
- risorsa
- risposta
- responsabilità
- responsabilità
- di risposta
- REST
- colpevole
- Ruolo
- ruoli
- Correre
- running
- vendite
- stesso
- risparmio
- Scalabilità
- scalabile
- Scala
- scala
- scansione
- in programma
- scienziati
- senza soluzione di continuità
- Cerca
- sezioni
- anziano
- serverless
- servizio
- Servizi
- Condividi
- condiviso
- Spedizione
- Spettacoli
- significativa
- simile
- Un'espansione
- da
- singolo
- Istantanea
- So
- Software
- Software Engineer
- soluzione
- Soluzioni
- RISOLVERE
- Soluzione
- qualcosa
- Fonte
- fonti
- campate
- Spettro
- esaurito
- SQL
- Stabilità
- delle parti interessate
- stakeholder
- Standard
- inizia a
- iniziato
- Di partenza
- inizio
- Stato dei servizi
- step
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- strategie
- Strategia
- di successo
- tale
- fornire
- supply chain
- Supporto
- supporti
- sistema
- tavolo
- Fai
- prende
- le squadre
- Tecnologia
- modello
- Testing
- I
- L’ORIGINE
- loro
- perciò
- migliaia
- Attraverso
- per tutto
- tempo
- volte
- timestamp
- suggerimenti
- a
- top
- Le transazioni
- Trasformare
- Di viaggio
- innescare
- Tipi di
- unificato
- Aggiornamenti
- us
- uso
- utenti
- convalida
- APPREZZIAMO
- Valori
- varietà
- vario
- Velocità
- versione
- via
- Visualizza
- Violazioni
- volatile
- volumi
- ricercato
- Magazzino
- modi
- Che
- quale
- while
- largo
- volere
- flusso di lavoro
- flussi di lavoro
- lavori
- sarebbe
- anno
- Trasferimento da aeroporto a Sharm
- zefiro