Questo post sul blog è co-autore di Guillermo Ribeiro, Sr. Data Scientist presso Cepsa.
L'apprendimento automatico (ML) si è rapidamente evoluto dall'essere una tendenza alla moda emergente dagli ambienti accademici e dai dipartimenti di innovazione a diventare un mezzo chiave per fornire valore alle aziende di ogni settore. Questa transizione dagli esperimenti in laboratorio alla risoluzione di problemi del mondo reale negli ambienti di produzione va di pari passo con MLOpo l'adattamento di DevOps al mondo ML.
MLOps aiuta a semplificare e automatizzare l'intero ciclo di vita di un modello ML, concentrandosi sui set di dati di origine, sulla riproducibilità degli esperimenti, sul codice dell'algoritmo ML e sulla qualità del modello.
At Cepsa, una società energetica globale, utilizziamo il ML per affrontare problemi complessi nelle nostre linee di attività, dalla manutenzione predittiva per le apparecchiature industriali al monitoraggio e al miglioramento dei processi petrolchimici nelle nostre raffinerie.
In questo post, discutiamo di come abbiamo costruito la nostra architettura di riferimento per MLOps utilizzando i seguenti servizi chiave AWS:
- Amazon Sage Maker, un servizio per creare, addestrare e distribuire modelli ML
- Funzioni AWS Step, un servizio di flusso di lavoro visivo a basso codice serverless utilizzato per orchestrare e automatizzare i processi
- Amazon EventBridge, un bus di eventi senza server
- AWS Lambda, un servizio di elaborazione serverless che consente di eseguire codice senza eseguire il provisioning o la gestione dei server
Spieghiamo anche come abbiamo applicato questa architettura di riferimento per avviare nuovi progetti ML nella nostra azienda.
La sfida
Negli ultimi 4 anni, più linee di business in Cepsa hanno dato il via a progetti di ML, ma presto hanno iniziato a sorgere alcuni problemi e limitazioni.
Non disponevamo di un'architettura di riferimento per ML, quindi ogni progetto ha seguito un percorso di implementazione diverso, eseguendo formazione e implementazione del modello ad hoc. Senza un metodo comune per gestire il codice e i parametri del progetto e senza un registro del modello ML o un sistema di controllo delle versioni, abbiamo perso la tracciabilità tra set di dati, codice e modelli.
Abbiamo anche rilevato margini di miglioramento nel modo in cui gestivamo i modelli in produzione, perché non monitoravamo i modelli distribuiti e quindi non disponevamo dei mezzi per monitorare le prestazioni del modello. Di conseguenza, di solito riqualificavamo i modelli in base a programmi temporali, perché mancavano le metriche giuste per prendere decisioni informate di riqualificazione.
La soluzione
Partendo dalle sfide che abbiamo dovuto superare, abbiamo progettato una soluzione generale che mirava a disaccoppiare la preparazione dei dati, l'addestramento del modello, l'inferenza e il monitoraggio del modello e prevedeva un registro dei modelli centralizzato. In questo modo, abbiamo semplificato la gestione degli ambienti su più account AWS, introducendo al contempo la tracciabilità centralizzata del modello.
I nostri data scientist e sviluppatori usano AWS Cloud9 (un IDE cloud per la scrittura, l'esecuzione e il debug del codice) per il data wrangling e la sperimentazione ML e GitHub come repository di codice Git.
Un flusso di lavoro di addestramento automatico utilizza il codice creato dal team di data science per modelli di treno su SageMaker e per registrare i modelli di output nel registro dei modelli.
Un flusso di lavoro diverso gestisce la distribuzione del modello: ottiene il riferimento dal registro del modello e crea un endpoint di inferenza utilizzando Funzionalità di hosting del modello SageMaker.
Abbiamo implementato sia il training del modello che i flussi di lavoro di distribuzione utilizzando Step Functions, perché ha fornito un framework flessibile che consente la creazione di flussi di lavoro specifici per ogni progetto e orchestra diversi servizi e componenti AWS in modo semplice.
Modello di consumo dei dati
In Cepsa, utilizziamo una serie di data lake per soddisfare diverse esigenze aziendali e tutti questi data lake condividono un modello comune di consumo dei dati che semplifica la ricerca e l'utilizzo dei dati necessari da parte di ingegneri e data scientist.
Per gestire facilmente i costi e le responsabilità, gli ambienti di data lake sono completamente separati dalle applicazioni di produttori e consumatori di dati e distribuiti in diversi account AWS appartenenti a un'organizzazione AWS comune.
I dati utilizzati per addestrare i modelli ML e i dati utilizzati come input di inferenza per i modelli addestrati sono resi disponibili dai diversi data lake tramite un set di API ben definite che utilizzano Gateway API Amazon, un servizio per creare, pubblicare, mantenere, monitorare e proteggere le API su larga scala. Il back-end dell'API utilizza Amazzone Atena (un servizio di query interattivo per analizzare i dati utilizzando SQL standard) per accedere ai dati già archiviati Servizio di archiviazione semplice Amazon (Amazon S3) e catalogato nel Colla AWS Catalogo dati.
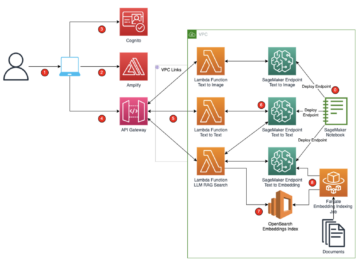
Il diagramma seguente fornisce una panoramica generale dell'architettura MLOps di Cepsa.

Allenamento modello
Il processo di formazione è indipendente per ciascun modello e gestito da a Passaggio Funzioni flusso di lavoro standard, che ci offre la flessibilità di modellare i processi in base ai diversi requisiti del progetto. Abbiamo un modello di base definito che riutilizziamo sulla maggior parte dei progetti, eseguendo piccoli aggiustamenti quando necessario. Ad esempio, alcuni proprietari di progetti hanno deciso di aggiungere porte manuali per approvare le implementazioni di nuovi modelli di produzione, mentre altri proprietari di progetti hanno implementato i propri meccanismi di rilevamento degli errori e tentativi.
Eseguiamo anche trasformazioni sui set di dati di input utilizzati per l'addestramento del modello. A tale scopo, utilizziamo funzioni Lambda integrate nei flussi di lavoro di formazione. In alcuni scenari in cui sono necessarie trasformazioni dei dati più complesse, eseguiamo il nostro codice Servizio di container elastici Amazon (Amazon ECS) su AWS Fargate, un motore di calcolo serverless per l'esecuzione di container.
Il nostro team di data science utilizza frequentemente algoritmi personalizzati, quindi sfruttiamo la possibilità di farlo utilizzare contenitori personalizzati nella formazione del modello SageMaker, contare su Registro dei contenitori Amazon Elastic (Amazon ECR), un registro di container completamente gestito che semplifica l'archiviazione, la gestione, la condivisione e la distribuzione di immagini di container.
La maggior parte dei nostri progetti ML si basa sulla libreria Scikit-learn, quindi abbiamo esteso lo standard Contenitore per l'apprendimento di SageMaker Scikit per includere le variabili di ambiente richieste per il progetto, come le informazioni sul repository Git e le opzioni di distribuzione.
Con questo approccio, i nostri data scientist devono solo concentrarsi sullo sviluppo dell'algoritmo di addestramento e specificare le librerie richieste dal progetto. Quando inviano modifiche al codice al repository Git, il nostro sistema CI/CD (Jenkins ospitato su AWS) costruisce il container con il codice di formazione e le librerie. Questo container viene inviato ad Amazon ECR e infine passato come parametro alla chiamata di addestramento SageMaker.
Al termine del processo di addestramento, il modello risultante viene archiviato in Amazon S3, viene aggiunto un riferimento nel registro del modello e tutte le informazioni e le metriche raccolte vengono salvate nel catalogo degli esperimenti. Ciò garantisce la piena riproducibilità perché il codice dell'algoritmo e le librerie sono collegati al modello addestrato insieme ai dati associati all'esperimento.
Il diagramma seguente illustra il processo di formazione e riqualificazione del modello.

Distribuzione del modello
L'architettura è flessibile e consente implementazioni sia automatiche che manuali dei modelli addestrati. Il flusso di lavoro di distribuzione del modello viene richiamato automaticamente tramite un evento che il training SageMaker pubblica in EventBridge al termine del training, ma può anche essere richiamato manualmente, se necessario, passando la versione del modello corretta dal registro del modello. Per ulteriori informazioni sulla chiamata automatica, vedere Automatizzare Amazon SageMaker con Amazon EventBridge.
Il flusso di lavoro di distribuzione del modello recupera le informazioni sul modello dal registro del modello e le utilizza AWS CloudFormazione, un'infrastruttura gestita come servizio di codice, per distribuire il modello su un endpoint di inferenza in tempo reale o eseguire l'inferenza batch con un set di dati di input archiviato, a seconda dei requisiti del progetto.
Ogni volta che un modello viene distribuito correttamente in qualsiasi ambiente, il registro del modello viene aggiornato con un nuovo tag che indica in quali ambienti è attualmente in esecuzione il modello. Ogni volta che un endpoint viene rimosso, anche il relativo tag viene eliminato dal registro del modello.
Il diagramma seguente mostra il flusso di lavoro per la distribuzione e l'inferenza del modello.

Esperimenti e registro dei modelli
L'archiviazione di ogni esperimento e versione del modello in un'unica posizione e la disponibilità di un repository di codice centralizzato ci consentono di disaccoppiare l'addestramento e la distribuzione del modello e di utilizzare account AWS diversi per ogni progetto e ambiente.
Tutte le voci dell'esperimento memorizzano l'ID di commit del codice di addestramento e di inferenza, quindi abbiamo una tracciabilità completa dell'intero processo di sperimentazione e siamo in grado di confrontare facilmente diversi esperimenti. Questo ci impedisce di eseguire lavori duplicati sulla fase di esplorazione scientifica per algoritmi e modelli e ci consente di distribuire i nostri modelli ovunque, indipendentemente dall'account e dall'ambiente in cui il modello è stato addestrato. Ciò vale anche per i modelli addestrati nel nostro ambiente di sperimentazione AWS Cloud9.
Tutto sommato, disponiamo di pipeline di addestramento e distribuzione del modello completamente automatizzate e abbiamo la flessibilità per eseguire distribuzioni manuali rapide del modello quando qualcosa non funziona correttamente o quando un team ha bisogno di un modello distribuito in un ambiente diverso a scopo di sperimentazione.
Un caso d'uso dettagliato: il progetto YET Dragon
Il progetto YET Dragon mira a migliorare le prestazioni produttive dell'impianto petrolchimico di Cepsa a Shanghai. Per raggiungere questo obiettivo, abbiamo studiato a fondo il processo produttivo, cercando i passaggi meno efficienti. Il nostro obiettivo era aumentare l'efficienza di rendimento dei processi mantenendo la concentrazione dei componenti esattamente al di sotto di una soglia.
Per simulare questo processo, abbiamo costruito quattro modelli additivi generalizzati o GAM, modelli lineari la cui risposta dipende da funzioni regolari di variabili predittive, per prevedere i risultati di due processi di ossidazione, un processo di concentrazione e la suddetta resa. Abbiamo anche costruito un ottimizzatore per elaborare i risultati dei quattro modelli GAM e trovare le migliori ottimizzazioni che potrebbero essere applicate nell'impianto.
Sebbene i nostri modelli siano addestrati con dati storici, l'impianto a volte può funzionare in circostanze che non sono state registrate nel set di dati di addestramento; prevediamo che i nostri modelli di simulazione non funzioneranno bene in questi scenari, quindi abbiamo anche costruito due modelli di rilevamento delle anomalie utilizzando algoritmi di Isolation Forests, che determinano quanto distano i punti dati dal resto dei dati per rilevare le anomalie. Questi modelli ci aiutano a rilevare tali situazioni per disabilitare i processi di ottimizzazione automatizzata ogni volta che ciò accade.
I processi chimici industriali sono molto variabili e i modelli ML devono essere ben allineati con il funzionamento dell'impianto, quindi è necessaria una frequente riqualificazione nonché la tracciabilità dei modelli implementati in ogni situazione. YET Dragon è stato il nostro primo progetto di ottimizzazione ML a presentare un registro del modello, la piena riproducibilità degli esperimenti e un processo di addestramento automatizzato completamente gestito.
Ora, la pipeline completa che porta un modello in produzione (trasformazione dei dati, training del modello, monitoraggio degli esperimenti, registro del modello e distribuzione del modello) è indipendente per ogni modello ML. Ciò ci consente di migliorare i modelli in modo iterativo (ad esempio aggiungendo nuove variabili o testando nuovi algoritmi) e di collegare le fasi di addestramento e distribuzione a diversi trigger.
I risultati ei miglioramenti futuri
Attualmente siamo in grado di addestrare, distribuire e tracciare automaticamente i sei modelli ML utilizzati nel progetto YET Dragon e abbiamo già distribuito oltre 30 versioni per ciascuno dei modelli di produzione. Questa architettura MLOps è stata estesa a centinaia di modelli ML in altri progetti all'interno dell'azienda.
Abbiamo in programma di continuare a lanciare nuovi progetti YET basati su questa architettura, che ha ridotto la durata media del progetto del 25%, grazie alla riduzione dei tempi di bootstrap e all'automazione delle pipeline ML. Abbiamo anche stimato un risparmio di circa 300,000 euro all'anno grazie all'aumento della resa e della concentrazione che è un risultato diretto del progetto YET Dragon.
L'evoluzione a breve termine di questa architettura MLOps è verso il monitoraggio del modello e il test automatizzato. Abbiamo in programma di testare automaticamente l'efficienza del modello rispetto a modelli precedentemente distribuiti prima che venga distribuito un nuovo modello. Stiamo anche lavorando all'implementazione del monitoraggio del modello e del monitoraggio della deriva dei dati di inferenza con Monitor modello Amazon SageMaker, al fine di automatizzare il riaddestramento del modello.
Conclusione
Le aziende stanno affrontando la sfida di portare in produzione i loro progetti ML in modo automatizzato ed efficiente. L'automazione dell'intero ciclo di vita del modello ML aiuta a ridurre i tempi di progetto e garantisce una migliore qualità del modello e implementazioni più rapide e frequenti nella produzione.
Sviluppando un'architettura MLOps standardizzata che è stata adottata da diverse aziende all'interno dell'azienda, noi di Cepsa siamo stati in grado di accelerare il bootstrap dei progetti ML e di migliorare la qualità del modello ML, fornendo un framework affidabile e automatizzato su cui i nostri team di data science possono innovare più velocemente .
Per ulteriori informazioni su MLOps su SageMaker, visitare Amazon SageMaker per MLOps e controlla altri casi d'uso dei clienti in Blog di apprendimento automatico AWS.
Circa gli autori
 Guillermo Ribeiro Jiménez è Sr Data Scientist presso Cepsa con un dottorato di ricerca. in Fisica Nucleare. Ha 6 anni di esperienza con progetti di data science, principalmente nel settore delle telecomunicazioni e dell'energia. Attualmente guida i team di data scientist nel dipartimento di trasformazione digitale di Cepsa, con particolare attenzione alla scalabilità e alla produzione di progetti di apprendimento automatico.
Guillermo Ribeiro Jiménez è Sr Data Scientist presso Cepsa con un dottorato di ricerca. in Fisica Nucleare. Ha 6 anni di esperienza con progetti di data science, principalmente nel settore delle telecomunicazioni e dell'energia. Attualmente guida i team di data scientist nel dipartimento di trasformazione digitale di Cepsa, con particolare attenzione alla scalabilità e alla produzione di progetti di apprendimento automatico.
 Guillermo Menéndez Corral è un Solutions Architect presso AWS Energy and Utilities. Vanta oltre 15 anni di esperienza nella progettazione e realizzazione di applicazioni SW e attualmente fornisce una guida architettonica ai clienti AWS nel settore energetico, con particolare attenzione all'analisi e all'apprendimento automatico.
Guillermo Menéndez Corral è un Solutions Architect presso AWS Energy and Utilities. Vanta oltre 15 anni di esperienza nella progettazione e realizzazione di applicazioni SW e attualmente fornisce una guida architettonica ai clienti AWS nel settore energetico, con particolare attenzione all'analisi e all'apprendimento automatico.
- Coinsmart. Il miglior scambio di bitcoin e criptovalute d'Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. ACCESSO LIBERO.
- Criptofalco. Radar Altcoin. Prova gratuita.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-cepsa-used-amazon-sagemaker-and-aws-step-functions-to-industrialize-their-ml-projects-and-operate- i loro modelli in scala/
- "
- 000
- 100
- 15 anni
- a
- capacità
- Chi siamo
- accesso
- Il mio account
- Raggiungere
- operanti in
- Ad
- aggiunto
- Vantaggio
- contro
- algoritmo
- Algoritmi
- Tutti
- consente
- già
- Amazon
- tra
- analitica
- analizzare
- ovunque
- api
- API
- applicazioni
- applicato
- approccio
- approvare
- architettonico
- architettura
- in giro
- associato
- automatizzare
- Automatizzata
- Automatico
- automaticamente
- Automatizzare
- Automazione
- disponibile
- AWS
- perché
- diventando
- prima
- essendo
- sotto
- MIGLIORE
- Blog
- costruire
- Costruzione
- costruisce
- affari
- aziende
- Custodie
- casi
- centralizzata
- certo
- Challenge
- sfide
- chimico
- Cloud
- codice
- commettere
- Uncommon
- azienda
- completamento di una
- completamente
- complesso
- componente
- componenti
- Calcolare
- concentrazione
- Connettiti
- consumare
- Consumer
- consumo
- Contenitore
- Tecnologie Container
- Costi
- potuto
- coprire
- creare
- crea
- creazione
- Attualmente
- costume
- cliente
- Clienti
- dati
- scienza dei dati
- scienziato di dati
- deciso
- decisioni
- Dipendente
- dipende
- schierare
- schierato
- deployment
- implementazioni
- progettato
- progettazione
- dettagliati
- rilevato
- rivelazione
- Determinare
- sviluppatori
- in via di sviluppo
- diverso
- digitale
- DIGITAL TRANSFORMATION
- dirette
- discutere
- Drago
- ogni
- facilmente
- efficienza
- efficiente
- emergenti del mondo
- Abilita
- endpoint
- energia
- motore
- Ingegneri
- Ambiente
- usate
- stimato
- Evento
- evoluzione
- di preciso
- esempio
- attenderti
- esperienza
- esperimento
- esplorazione
- di fronte
- FAST
- più veloce
- caratteristica
- In primo piano
- Infine
- Nome
- Flessibilità
- flessibile
- Focus
- i seguenti
- Contesto
- da
- pieno
- funzioni
- futuro
- Gates
- Generale
- Idiota
- GitHub
- globali
- scopo
- maniglia
- avendo
- Aiuto
- aiuta
- vivamente
- storico
- detiene
- ospitato
- di hosting
- Come
- HTTPS
- centinaia
- immagini
- implementazione
- implementato
- competenze
- miglioramento
- miglioramento
- In altre
- includere
- Aumento
- studente indipendente
- indipendentemente
- industriale
- industria
- informazioni
- informati
- Infrastruttura
- Innovazione
- ingresso
- integrato
- interattivo
- l'introduzione di
- da solo
- sicurezza
- IT
- mantenere
- conservazione
- Le
- lancio
- principale
- apprendimento
- Biblioteca
- Linee
- località
- cerca
- macchina
- machine learning
- fatto
- mantenere
- manutenzione
- make
- FA
- gestire
- gestito
- gestione
- modo
- Manuale
- manualmente
- si intende
- Metrica
- ML
- modello
- modelli
- Monitorare
- monitoraggio
- Scopri di più
- maggior parte
- multiplo
- esigenze
- operare
- operazione
- ottimizzazione
- Opzioni
- minimo
- organizzazione
- Altro
- proprio
- proprietari
- Di passaggio
- performance
- esecuzione
- fase
- Fisica
- punti
- predire
- problemi
- processi
- i processi
- produttore
- Produzione
- progetto
- progetti
- purché
- fornisce
- fornitura
- pubblicare
- scopo
- fini
- spinto
- qualità
- tempo reale
- ridurre
- registro
- registrato
- affidabile
- deposito
- necessario
- Requisiti
- risposta
- responsabilità
- REST
- risultante
- Risultati
- Correre
- running
- Scala
- scala
- Scienze
- Scienziato
- scienziati
- sicuro
- Serie
- serverless
- servizio
- Servizi
- set
- shanghai
- Condividi
- a breve scadenza
- Un'espansione
- simulazione
- singolo
- situazione
- SIX
- So
- soluzione
- Soluzioni
- alcuni
- qualcosa
- specifico
- velocità
- tappe
- Standard
- iniziato
- conservazione
- Tornare al suo account
- snellire
- Con successo
- sistema
- Target
- team
- le squadre
- Telco
- test
- Testing
- I
- L’ORIGINE
- perciò
- a fondo
- soglia
- Attraverso
- tempo
- volte
- verso
- Tracciabilità
- pista
- Tracking
- Training
- Trasformazione
- trasformazioni
- transizione
- per
- us
- uso
- generalmente
- utilità
- APPREZZIAMO
- versione
- ben definita
- while
- senza
- Lavora
- flussi di lavoro
- lavoro
- mondo
- scrittura
- anno
- anni
- dare la precedenza