Questo post fornisce indicazioni su come creare soluzioni analitiche scalabili per i casi d'uso del settore dei giochi Amazon Redshift senza server. Descrive come utilizzare un'architettura concettuale e logica per alcuni dei casi d'uso più popolari del settore dei giochi come l'analisi degli eventi, i consigli sugli acquisti in-game, la misurazione della soddisfazione dei giocatori, l'analisi dei dati di telemetria e altro ancora. Questo post discute anche l'arte del possibile con le innovazioni più recenti nei servizi AWS in merito a streaming, machine learning (ML), condivisione dei dati e funzionalità serverless.
I nostri clienti di gioco ci dicono che i loro principali obiettivi aziendali includono quanto segue:
- Aumento delle entrate dagli acquisti in-app
- Entrate medie elevate per utente e lifetime value
- Appiccicosità migliorata con una migliore esperienza di gioco
- Maggiore produttività degli eventi e ROI elevato
I nostri clienti di gioco ci dicono anche che durante la creazione di soluzioni di analisi, desiderano quanto segue:
- Modello low-code o no-code – Le soluzioni pronte all'uso sono preferite alla creazione di soluzioni personalizzate.
- Disaccoppiato e scalabile – I servizi serverless, con scalabilità automatica e completamente gestiti sono preferiti ai servizi gestiti manualmente. Ogni servizio dovrebbe essere facilmente sostituibile, migliorato con poca o nessuna dipendenza. Le soluzioni dovrebbero essere flessibili per aumentare e diminuire.
- Portabilità su più canali – Le soluzioni dovrebbero essere compatibili con la maggior parte dei canali endpoint come PC, dispositivi mobili e piattaforme di gioco.
- Flessibile e facile da usare – Le soluzioni dovrebbero fornire dati meno restrittivi, di facile accesso e pronti all'uso. Dovrebbero anche fornire prestazioni ottimali con accordatura bassa o assente.
Architettura di riferimento dell'analisi per le organizzazioni di gioco
In questa sezione, discutiamo di come le organizzazioni di gioco possono utilizzare un'architettura di hub di dati per soddisfare le esigenze analitiche di un'azienda, che richiede gli stessi dati a più livelli di granularità e formati diversi ed è standardizzata per un consumo più rapido. UN hub dati è un centro di scambio di dati che costituisce un hub di archivi di dati ed è supportato da servizi di ingegneria dei dati, governance dei dati, sicurezza e monitoraggio.
Un data hub contiene dati a più livelli di granularità e spesso non è integrato. Si differenzia da un data lake offrendo dati pre-convalidati e standardizzati, consentendo un consumo più semplice da parte degli utenti. Data hub e data lake possono coesistere in un'organizzazione, completandosi a vicenda. Gli hub di dati sono più focalizzati sul consentire alle aziende di consumare dati standardizzati in modo rapido e semplice. I data lake sono più focalizzati sull'archiviazione e il mantenimento di tutti i dati in un'organizzazione in un unico posto. E a differenza dei data warehouse, che sono principalmente archivi analitici, un data hub è una combinazione di tutti i tipi di repository: servizi analitici, transazionali, operativi, di riferimento e I/O dei dati, insieme a processi di governance. Un data warehouse è uno dei componenti di un data hub.
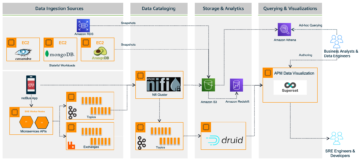
Il diagramma seguente è un'architettura di riferimento dell'hub dati di analisi concettuale. Questa architettura ricorda un approccio hub-and-spoke. I repository di dati rappresentano l'hub. I processi esterni sono i raggi che alimentano i dati da e verso l'hub. Questa architettura di riferimento combina in parte un data hub e un data lake per abilitare servizi di analisi completi.
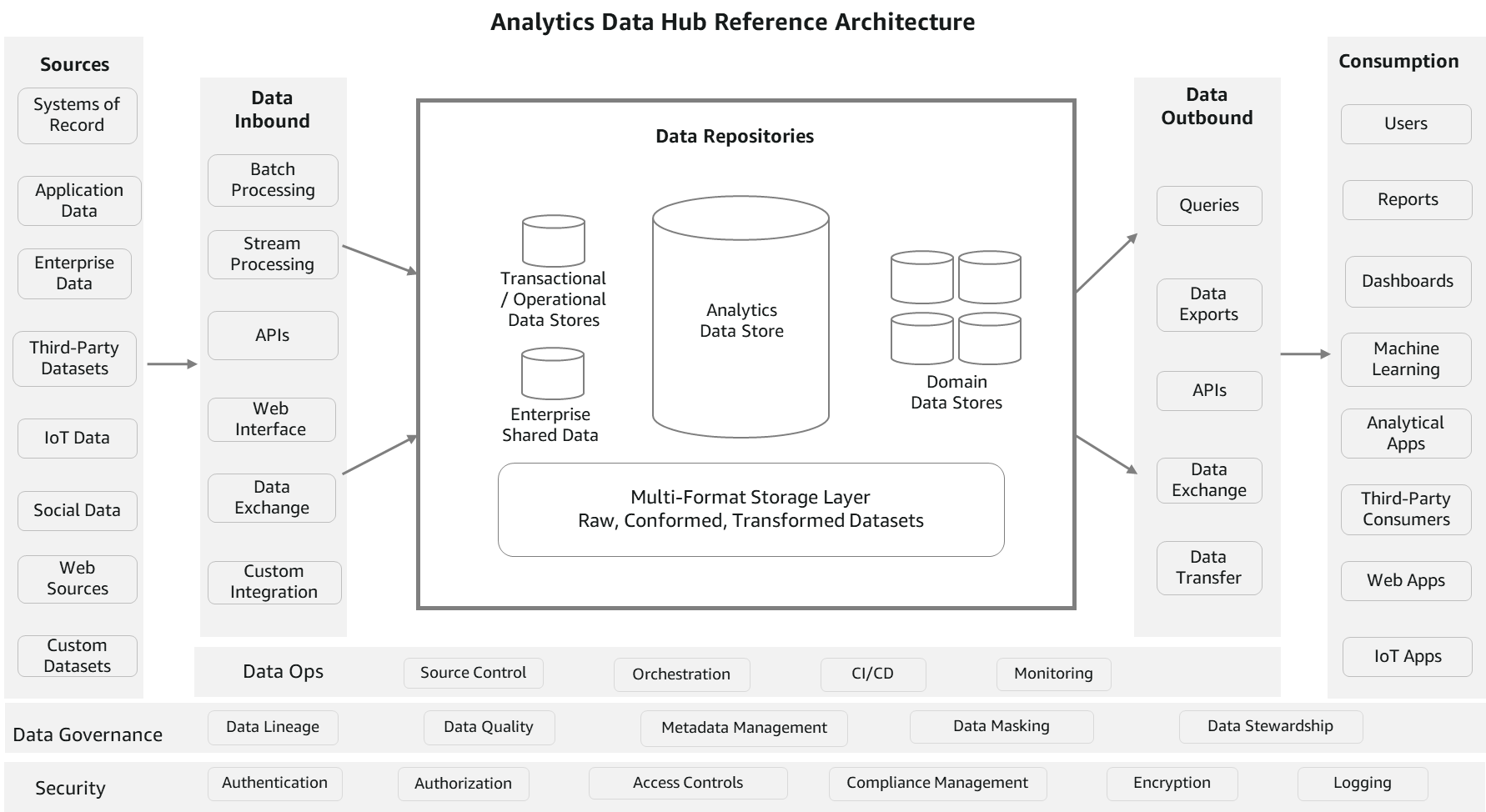
Diamo un'occhiata ai componenti dell'architettura in modo più dettagliato.
fonti
I dati possono essere caricati da più fonti, come sistemi di registrazione, dati generati da applicazioni, data store operativi, dati e metadati di riferimento a livello aziendale, dati di fornitori e partner, dati generati da macchine, fonti social e fonti web. I dati di origine sono solitamente in formati strutturati o semi-strutturati, che sono rispettivamente altamente e liberamente formattati.
Dati in entrata
Questa sezione è costituita da componenti per elaborare e caricare i dati da più origini nei repository di dati. Può essere in modalità batch, continua, pub/sub o qualsiasi altra
integrazione personalizzata. Le tecnologie ETL (estrazione, trasformazione e caricamento), i servizi di streaming, le API e le interfacce di scambio dati sono i componenti principali di questo pilastro. A differenza dei processi di acquisizione, i dati possono essere trasformati in base alle regole aziendali prima del caricamento. Puoi applicare regole di qualità dei dati tecnici o aziendali e caricare anche dati grezzi. Essenzialmente, fornisce la flessibilità necessaria per inserire i dati nei repository nella loro forma più utilizzabile.
Archivi di dati
Questa sezione è costituita da un gruppo di archivi di dati, che include data warehouse, archivi di dati transazionali o operativi, archivi di dati di riferimento, archivi di dati di dominio che ospitano viste aziendali appositamente create e set di dati aziendali (archiviazione di file). Il componente di archiviazione file è in genere un componente comune tra un data hub e un data lake per evitare la duplicazione dei dati e fornire completezza. I dati possono anche essere condivisi tra tutti questi repository senza spostarsi fisicamente con funzionalità come la condivisione dei dati e le query federate. Tuttavia, la copia e la duplicazione dei dati è consentita considerando le diverse esigenze di consumo in termini di formati e latenza.
Dati in uscita
I dati vengono spesso consumati utilizzando query strutturate per esigenze analitiche. Inoltre, è possibile accedere ai set di dati per esigenze di ML, esportazione di dati e pubblicazione. Questa sezione è costituita da componenti per interrogare i dati, l'esportazione, lo scambio e le API. In termini di implementazione, le stesse tecnologie possono essere utilizzate sia per l'inbound che per l'outbound, ma le funzioni sono diverse. Tuttavia, non è obbligatorio utilizzare le stesse tecnologie. Questi processi non richiedono trasformazioni pesanti perché i dati sono già standardizzati e quasi pronti per essere consumati. L'attenzione è rivolta alla facilità di consumo e all'integrazione con i servizi di consumo.
Consumo
Questo pilastro è costituito da vari canali di consumo per le esigenze analitiche aziendali. Include utenti di business intelligence (BI), report predefiniti e interattivi, dashboard, carichi di lavoro di data science, Internet of Things (IoT), app Web e consumatori di dati di terze parti. Le entità di consumo più diffuse in molte organizzazioni sono query, report e carichi di lavoro di data science. Poiché esistono più archivi dati che mantengono i dati con granularità e formati diversi per soddisfare le esigenze dei consumatori, questi componenti di consumo dipendono dai cataloghi di dati per trovare la fonte giusta.
Governance dei dati
La governance dei dati è la chiave per il successo di un'architettura di riferimento dell'hub dati. Costituisce componenti come la gestione dei metadati, la qualità dei dati, il lignaggio, il mascheramento e la gestione, che sono necessari per la manutenzione organizzata dell'hub di dati. La gestione dei metadati aiuta a organizzare il catalogo dei metadati tecnici e aziendali e i consumatori possono fare riferimento a questo catalogo per sapere quali dati sono disponibili in quale repository e con quale granularità, formato, proprietari, frequenza di aggiornamento e così via. Insieme alla gestione dei metadati, la qualità dei dati è importante per aumentare la fiducia dei consumatori. Ciò include la pulizia dei dati, la convalida, la conformità e i controlli dei dati.
Sicurezza e monitoraggio
Gli utenti e l'accesso alle applicazioni devono essere controllati a più livelli. Inizia con l'autenticazione, quindi autorizzando chi e cosa dovrebbe essere accessibile, la gestione delle policy, la crittografia e l'applicazione delle regole di conformità dei dati. Include anche componenti di monitoraggio per registrare l'attività per il controllo e l'analisi.
Architettura della soluzione dell'hub di dati di analisi su AWS
La seguente architettura di riferimento fornisce uno stack AWS per i componenti della soluzione.
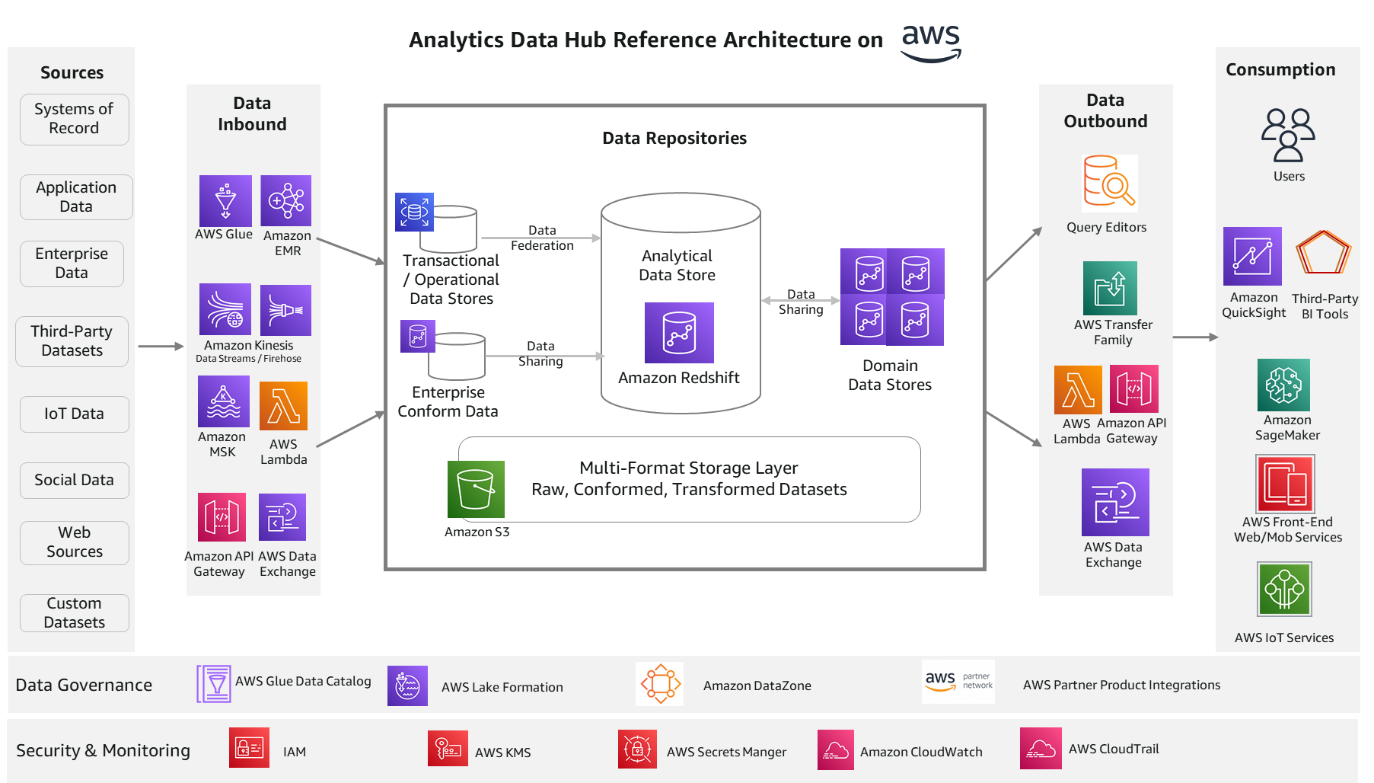
Diamo un'occhiata di nuovo a ciascun componente e ai relativi servizi AWS.
Servizi in entrata dati
Colla AWS ed Amazon EMR i servizi sono ideali per l'elaborazione in batch. Si ridimensionano automaticamente e sono in grado di elaborare la maggior parte dei formati di dati standard del settore. Flussi di dati di Amazon Kinesis, Firehose dati Amazon Kinesise Streaming gestito da Amazon per Apache Kafka (Amazon MSK) consente di creare applicazioni di processo di streaming. Questi servizi di streaming si integrano bene con il Streaming di Amazon Redshift caratteristica. Questo ti aiuta a elaborare fonti in tempo reale, dati IoT e dati da canali online. Puoi anche importare dati con strumenti di terze parti come Informatica, dbt e Matallion.
Puoi creare API RESTful e API WebSocket utilizzando Gateway API Amazon ed AWS Lambda, che consentirà la comunicazione bidirezionale in tempo reale con fonti Web, social e IoT. Scambio di dati AWS aiuta con la sottoscrizione di dati di terze parti in AWS Marketplace. L'abbonamento e l'accesso ai dati sono completamente gestiti con questo servizio. Fare riferimento alla rispettiva documentazione di servizio per ulteriori dettagli.
Servizi di deposito dati
Amazon RedShift è il servizio di archiviazione dei dati consigliato per i carichi di lavoro OLAP (Online Analytical Processing) come data warehouse su cloud, data mart e altri archivi di dati analitici. Questo servizio è il fulcro di questa architettura di riferimento su AWS e può soddisfare la maggior parte delle esigenze analitiche fuori dagli schemi. Puoi utilizzare SQL semplice per analizzare dati strutturati e semi-strutturati in data warehouse, data mart, database operativi e data lake per offrire il miglior rapporto prezzo/prestazioni su qualsiasi scala. IL Condivisione dei dati di Amazon Redshift offre un accesso istantaneo, granulare e ad alte prestazioni senza copie e spostamenti dei dati tra più data warehouse di Amazon Redshift nello stesso o in diversi account AWS e tra regioni.
Per facilità d'uso, Amazon Redshift offre un'opzione senza server. Amazon Redshift senza server esegue automaticamente il provisioning e ridimensiona in modo intelligente la capacità del data warehouse per fornire prestazioni rapide anche per i carichi di lavoro più impegnativi e imprevedibili, e paghi solo per ciò che usi. Carica i tuoi dati e inizia subito a eseguire query nell'editor di query di Amazon Redshift o nel tuo strumento di BI preferito e continua a usufruire del miglior rapporto qualità-prezzo e delle funzionalità SQL familiari in un ambiente di facile utilizzo e senza amministrazione.
Servizio di database relazionale Amazon (Amazon RDS) è un servizio completamente gestito per la creazione di data store operativi e transazionali. Puoi scegliere tra molti motori popolari come MySQL, PostgreSQL, MariaDB, Oracle e SQL Server. Con Amazon Redshift interrogazione federata caratteristica, è possibile eseguire query sui dati transazionali e operativi senza spostare i dati. La funzione di query federata attualmente supporta Amazon RDS per PostgreSQL, Edizione compatibile con Amazon Aurora PostgreSQL, Amazon RDS per MySQLe Edizione compatibile con Amazon Aurora MySQL.
Servizio di archiviazione semplice Amazon (Amazon S3) è il servizio consigliato per i livelli di archiviazione multiformato nell'architettura. Offre scalabilità, disponibilità dei dati, sicurezza e prestazioni leader del settore. Le organizzazioni in genere archiviano i dati in Amazon S3 utilizzando formati di file aperti. I formati di file aperti consentono l'analisi degli stessi dati Amazon S3 utilizzando più componenti del livello di elaborazione e consumo. I dati in Amazon S3 possono essere facilmente interrogati sul posto utilizzando SQL con Spettro Amazon Redshift. Ti aiuta a interrogare e recuperare dati strutturati e semi-strutturati dai file in Amazon S3 senza dover caricare i dati. Più data warehouse di Amazon Redshift possono eseguire query contemporaneamente sugli stessi set di dati in Amazon S3 senza la necessità di eseguire copie dei dati per ciascun data warehouse.
Servizi in uscita dati
Amazon Redshift viene fornito con il workbench di analisi basato sul Web Editor di query V2.0, che ti aiuta a eseguire query, esplorare dati, creare notebook SQL e collaborare sui dati con i tuoi team in SQL tramite un'interfaccia comune. Famiglia AWS Transfer aiuta a trasferire in modo sicuro i file utilizzando i protocolli SFTP, FTPS, FTP e AS2. Supporta migliaia di utenti simultanei ed è un servizio low-code completamente gestito. Simile ai processi in entrata, puoi utilizzare Gateway API Amazon ed AWS Lambda per il pull dei dati utilizzando il API dati Amazon Redshift. E Scambio di dati AWS aiuta a pubblicare i tuoi dati a terze parti per il consumo tramite AWS Marketplace.
Servizi di consumo
Amazon QuickSight è il servizio consigliato per la creazione di report e dashboard. Ti consente di creare dashboard interattivi, visualizzazioni e analisi avanzate con approfondimenti ML. Amazon Sage Maker è la piattaforma ML per tutte le esigenze relative ai carichi di lavoro di data science. Ti aiuta a creare, addestrare e distribuire modelli che utilizzano i dati dai repository nell'hub dati. Puoi usare Amazon front-end web e mobile servizi e AWSIoT servizi per creare applicazioni endpoint Web, mobili e IoT per consumare dati dall'hub dati.
Servizi di governance dei dati
I Catalogo dati di AWS Glue ed Formazione AWS Lake sono i principali servizi di governance dei dati attualmente offerti da AWS. Questi servizi aiutano a gestire i metadati centralmente per tutti i repository di dati e gestire i controlli di accesso. Aiutano anche con la classificazione dei dati e possono gestire automaticamente le modifiche allo schema. Puoi usare Amazon DataZone per scoprire e condividere i dati su larga scala oltre i confini dell'organizzazione con governance integrata e controlli degli accessi. AWS sta investendo in questo spazio per fornire un'esperienza più unificata per i servizi AWS. Esistono molti prodotti partner come Collibra, Alation, Amorphic, Informatica e altri, che puoi utilizzare anche per le funzioni di governance dei dati con i servizi AWS.
Servizi di sicurezza e monitoraggio
Gestione dell'identità e dell'accesso di AWS (AWS IAM) gestisce le identità per i servizi e le risorse AWS. Puoi definire utenti, gruppi, ruoli e criteri per una gestione granulare degli accessi della forza lavoro e dei carichi di lavoro. Servizio di gestione delle chiavi AWS (AWS KMS) gestisce le chiavi AWS o le chiavi gestite dal cliente per le tue applicazioni. Amazon Cloud Watch ed AWS CloudTrail aiutano a fornire funzionalità di monitoraggio e controllo. Puoi raccogliere metriche ed eventi e analizzarli per l'efficienza operativa.
In questo post, abbiamo discusso i servizi AWS più comuni per i rispettivi componenti della soluzione. Tuttavia, non sei limitato solo a questi servizi. Esistono molti altri servizi AWS per casi d'uso specifici che potrebbero essere più appropriati per le tue esigenze rispetto a quanto discusso qui. Puoi contattare gli AWS Analytics Solutions Architects per una guida appropriata.
Esempi di architetture per casi d'uso di gioco
In questa sezione, discutiamo architetture di esempio per due casi d'uso di gioco.
Analisi degli eventi di gioco
Gli eventi in-game (chiamati anche eventi a tempo o dal vivo) incoraggiano il coinvolgimento dei giocatori attraverso l'eccitazione e l'attesa. Gli eventi invitano i giocatori a interagire con il gioco, aumentando la soddisfazione dei giocatori e le entrate con gli acquisti in-game. Gli eventi sono diventati sempre più importanti, soprattutto quando i giochi passano dall'essere elementi di intrattenimento statici da giocare così come sono all'offerta di contenuti dinamici e mutevoli attraverso l'uso di servizi che utilizzano le informazioni per prendere decisioni sul gioco mentre il gioco viene giocato. Ciò consente ai giochi di cambiare mentre i giocatori giocano e influenzano ciò che funziona e cosa no, e conferisce a qualsiasi gioco una durata potenzialmente infinita.
Questa capacità degli eventi in-game di offrire nuovi contenuti e attività all'interno di un quadro familiare è il modo in cui mantieni i giocatori impegnati e giocano per mesi o anni. I giocatori possono godere di nuove esperienze e sfide all'interno della struttura familiare o del mondo che hanno imparato ad amare.
L'esempio seguente mostra come potrebbe apparire un'architettura di questo tipo, incluse le modifiche per supportare varie sezioni del processo come la suddivisione dei dati in contenitori separati per adattarsi a scalabilità, chargeback e proprietà.
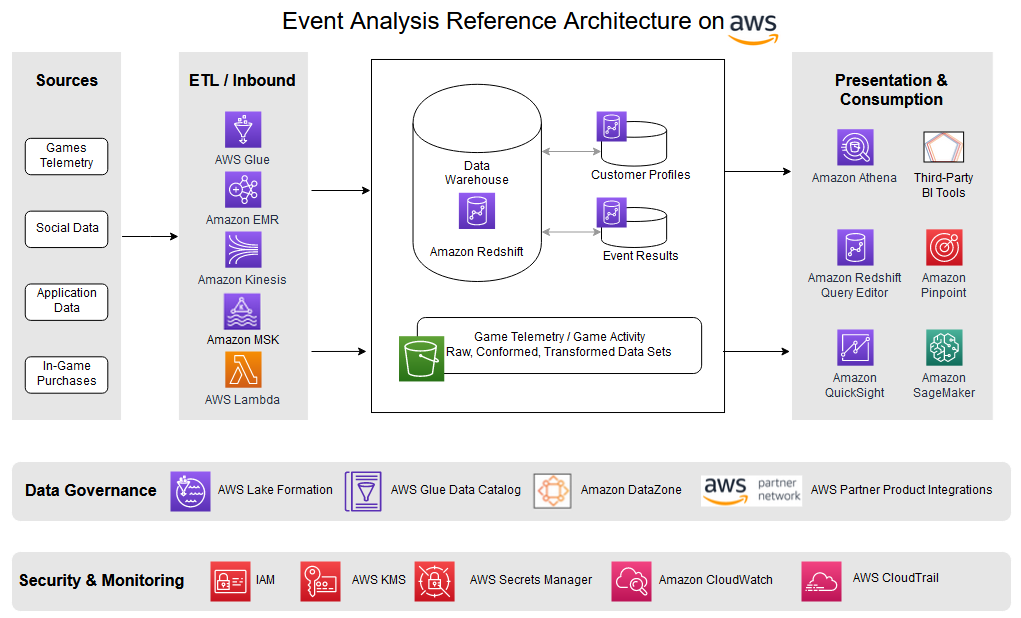
Per comprendere appieno come gli eventi vengono visti dai giocatori e prendere decisioni sugli eventi futuri, sono necessarie informazioni su come è stato effettivamente eseguito l'ultimo evento. Ciò significa raccogliere molti dati mentre i giocatori giocano per costruire indicatori chiave di prestazione (KPI) che misurino l'efficacia e la soddisfazione dei giocatori per ogni evento. Ciò richiede analisi che misurino in modo specifico ogni evento e acquisiscano, analizzino, riferiscano e misurino l'esperienza del giocatore per ogni evento. Questi KPI includono quanto segue:
- Interazioni iniziali del flusso utente – Quali azioni intraprendono gli utenti dopo aver ricevuto o scaricato per la prima volta un aggiornamento dell'evento in un gioco. Ci sono chiari punti di abbandono o colli di bottiglia che allontanano le persone dall'evento?
- monetazione – Quando, cosa e dove gli utenti spendono soldi nell'evento, sia che si tratti di acquistare valute di gioco, rispondere ad annunci, offerte speciali e così via.
- Economia del gioco – In che modo gli utenti possono guadagnare e spendere valute o beni virtuali durante un evento, utilizzando denaro di gioco, scambi o baratto.
- Attività di gioco - Vittorie, sconfitte, passaggi di livello, vittorie in competizioni o risultati dei giocatori all'interno dell'evento.
- Interazioni da utente a utente – Inviti, regali, chat (private e di gruppo), sfide e così via durante un evento.
Questi sono solo alcuni dei KPI e delle metriche che sono fondamentali per la modellazione predittiva degli eventi man mano che il gioco acquisisce nuovi giocatori mantenendo gli utenti esistenti coinvolti, coinvolti e giocando.
Analisi dell'attività di gioco
L'analisi delle attività di gioco esamina essenzialmente qualsiasi attività significativa e mirata che il giocatore potrebbe mostrare, con l'obiettivo di cercare di capire quali azioni vengono intraprese, i loro tempi e i risultati. Ciò include informazioni situazionali sui giocatori, incluso dove stanno giocando (sia geografico che culturale), quanto spesso, per quanto tempo, cosa intraprendono ad ogni accesso e altre attività.
L'esempio seguente mostra come potrebbe apparire un'architettura di questo tipo, incluse le modifiche per supportare varie sezioni del processo come la suddivisione dei dati in data warehouse separati. L'approccio al magazzino multi-cluster aiuta a ridimensionare il carico di lavoro in modo indipendente, offre flessibilità al modello di riaddebito implementato e supporta la proprietà decentralizzata dei dati.

La soluzione essenzialmente registra le informazioni per aiutare a comprendere il comportamento dei tuoi giocatori, il che può portare a approfondimenti che aumentano la fidelizzazione dei giocatori esistenti e l'acquisizione di nuovi. Questo può fornire la possibilità di fare quanto segue:
- Fornisci consigli sugli acquisti in-game
- Misura le tendenze dei giocatori a breve termine e nel tempo
- Pianifica gli eventi in cui i giocatori si impegneranno
- Cerca di capire quali parti del tuo gioco hanno più successo e quali meno
Puoi utilizzare questa comprensione per prendere decisioni sui futuri aggiornamenti del gioco, formulare raccomandazioni per l'acquisto in-game, determinare quando e come potrebbe essere necessario bilanciare la tua economia di gioco e persino consentire ai giocatori di cambiare il proprio personaggio o giocare man mano che il gioco procede iniettando questo informazioni e decisioni di accompagnamento nel gioco.
Conclusione
Questa architettura di riferimento, pur mostrando esempi solo di pochi tipi di analisi, fornisce un percorso tecnologico più rapido per abilitare le applicazioni di analisi dei giochi. L'approccio disaccoppiato hub/spoke offre l'agilità e la flessibilità necessarie per implementare diversi approcci all'analisi e alla comprensione delle prestazioni delle applicazioni di gioco. I servizi AWS appositamente creati descritti in questa architettura forniscono funzionalità complete per raccogliere, archiviare, misurare, analizzare e segnalare facilmente le metriche di giochi ed eventi. Questo ti aiuta a eseguire in modo efficiente analisi di gioco, analisi degli eventi, misurare la soddisfazione dei giocatori e fornire consigli su misura ai giocatori, organizzare in modo efficiente gli eventi e aumentare i tassi di fidelizzazione.
Grazie per aver letto il post. Se hai commenti o domande, lasciali nei commenti.
Circa gli autori
 Satesh Sonti è un Sr. Analytics Specialist Solutions Architect con sede ad Atlanta, specializzato nella creazione di piattaforme di dati aziendali, data warehousing e soluzioni di analisi. Ha oltre 16 anni di esperienza nella creazione di asset di dati e nella guida di programmi di piattaforme dati complessi per clienti bancari e assicurativi in tutto il mondo.
Satesh Sonti è un Sr. Analytics Specialist Solutions Architect con sede ad Atlanta, specializzato nella creazione di piattaforme di dati aziendali, data warehousing e soluzioni di analisi. Ha oltre 16 anni di esperienza nella creazione di asset di dati e nella guida di programmi di piattaforme dati complessi per clienti bancari e assicurativi in tutto il mondo.
 Tanya Rodi è un Senior Solutions Architect con sede a San Francisco, focalizzato sui clienti di giochi con particolare attenzione all'analisi, al ridimensionamento e al miglioramento delle prestazioni dei giochi e dei sistemi di supporto. Ha oltre 25 anni di esperienza nell'architettura aziendale e delle soluzioni, specializzata in organizzazioni aziendali di grandi dimensioni in più linee di business, tra cui giochi, banche, sanità, istruzione superiore e governi statali.
Tanya Rodi è un Senior Solutions Architect con sede a San Francisco, focalizzato sui clienti di giochi con particolare attenzione all'analisi, al ridimensionamento e al miglioramento delle prestazioni dei giochi e dei sistemi di supporto. Ha oltre 25 anni di esperienza nell'architettura aziendale e delle soluzioni, specializzata in organizzazioni aziendali di grandi dimensioni in più linee di business, tra cui giochi, banche, sanità, istruzione superiore e governi statali.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-gaming-companies-can-use-amazon-redshift-serverless-to-build-scalable-analytical-applications-faster-and-easier/
- :È
- $ SU
- 100
- a
- capacità
- capace
- Chi siamo
- accesso
- gestione degli accessi
- accessibile
- ospitare
- conti
- realizzazioni
- Acquisisce
- acquisizione
- operanti in
- azioni
- attività
- attività
- effettivamente
- indirizzo
- amministrazione
- Ads - Annunci
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- Tutti
- Consentire
- già
- Amazon
- Amazon RDS
- tra
- .
- Analitico
- analitica
- analizzare
- ed
- anticipazione
- Apache
- api
- API
- apparire
- Applicazioni
- applicazioni
- APPLICA
- AMMISSIONE
- approccio
- approcci
- opportuno
- applicazioni
- architettura
- SONO
- in giro
- Arte
- AS
- Attività
- At
- Atlanta
- revisione
- Aurora
- Autenticazione
- auto
- automaticamente
- disponibilità
- disponibile
- media
- evitare
- AWS
- Mercato AWS
- precedente
- Settore bancario
- basato
- BE
- perché
- diventare
- prima
- essendo
- MIGLIORE
- Meglio
- fra
- strozzature
- confini
- Scatola
- Rottura
- Porta
- costruire
- Costruzione
- incassato
- affari
- business intelligence
- aziende
- Acquisto
- by
- detto
- Materiale
- funzionalità
- Ultra-Grande
- catturare
- casi
- catalogo
- cataloghi
- centro
- sfide
- il cambiamento
- Modifiche
- cambiando
- canali
- carattere
- Scegli
- classificazione
- pulire campo
- clienti
- Cloud
- collaboreranno
- raccogliere
- combinazione
- combina
- Commenti
- Uncommon
- Comunicazione
- Aziende
- compatibile
- concorrenza
- complesso
- conformità
- componente
- componenti
- globale
- concettuale
- concorrente
- fiducia
- considerando
- consumare
- consumato
- Consumer
- Consumatori
- consumo
- Tecnologie Container
- contiene
- contenuto
- continua
- continuo
- controllata
- controlli
- Nucleo
- copre
- creare
- Creazione
- la cultura della
- valute
- Attualmente
- cliente
- Clienti
- personalizzate
- dati
- analisi dei dati
- Scambio di dati
- Lago di dati
- Piattaforma dati
- qualità dei dati
- scienza dei dati
- condivisione dei dati
- memorizzazione dei dati
- data warehouse
- data warehouse
- Banca Dati
- banche dati
- dataset
- decentrata
- decisioni
- consegnare
- esigente
- Dipendenza
- schierare
- descritta
- dettaglio
- dettagli
- Determinare
- diverso
- scopri
- discutere
- discusso
- documentazione
- non
- dominio
- giù
- scaricare
- durante
- dinamico
- ogni
- guadagnare
- facilità d'uso
- più facile
- facilmente
- facile
- facile da usare
- economia
- editore
- Istruzione
- efficacia
- efficienza
- in modo efficiente
- o
- enfasi
- enable
- Abilita
- consentendo
- incoraggiare
- crittografia
- endpoint
- impegnarsi
- impegnato
- Fidanzamento
- Ingegneria
- Motori
- migliorata
- godere
- Impresa
- Intrattenimento
- entità
- Ambiente
- particolarmente
- essenzialmente
- Etere (ETH)
- Anche
- Evento
- eventi
- esempio
- Esempi
- exchange
- Eccitazione
- esistente
- esperienza
- Esperienze
- esplora
- export
- esterno
- estratto
- familiare
- FAST
- più veloce
- preferito
- caratteristica
- Caratteristiche
- feedback
- alimentazione
- pochi
- Compila il
- File
- ricerca
- Nome
- Flessibilità
- flessibile
- flusso
- Focus
- concentrato
- i seguenti
- Nel
- Per i consumatori
- modulo
- formato
- Contesto
- Francisco
- Frequenza
- fresco
- da
- completamente
- funzioni
- ulteriormente
- futuro
- gioco futuro
- gioco
- Giochi
- gaming
- Industria del gioco
- raccolta
- generato
- geografico
- ottenere
- dà
- globo
- scopo
- merce
- la governance
- I governi
- Gruppo
- Gruppo
- cresciuto
- guida
- maniglia
- Avere
- avendo
- assistenza sanitaria
- pesante
- Aiuto
- aiuta
- qui
- Alta
- Alte prestazioni
- superiore
- Istruzione superiore
- vivamente
- alloggiamento
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- Hub
- IAM
- ideale
- identità
- Identità
- realizzare
- implementazione
- implementato
- importante
- in
- in-game
- includere
- inclusi
- Compreso
- Aumento
- crescente
- indipendentemente
- industria
- leader del settore
- influenza
- informazioni
- innovazioni
- intuizioni
- immediato
- assicurazione
- integrare
- integrato
- integrazione
- Intelligence
- interagire
- interattivo
- Interfaccia
- interfacce
- Internet
- Internet delle cose
- investire
- coinvolto
- IoT
- IT
- SUO
- jpg
- mantenere
- conservazione
- Le
- Tasti
- Sapere
- lago
- grandi
- Latenza
- con i più recenti
- strato
- galline ovaiole
- portare
- principale
- apprendimento
- Lasciare
- livelli
- durata
- tutta la vita
- piace
- Limitato
- Linee
- piccolo
- vivere
- Eventi live
- caricare
- Caricamento in corso
- logico
- Lunghi
- Guarda
- SEMBRA
- perdite
- lotto
- amore
- Basso
- macchina
- machine learning
- manutenzione
- make
- gestire
- gestito
- gestione
- gestisce
- obbligatorio
- manualmente
- molti
- mercato
- significativo
- si intende
- misurare
- di misura
- Metadati
- Metrica
- forza
- ML
- Mobile
- Moda
- modello
- modellismo
- modelli
- soldi
- monitoraggio
- mese
- Scopri di più
- maggior parte
- Più popolare
- movimento
- in movimento
- multiplo
- MySQL
- Bisogno
- esigenze
- New
- computer portatili
- Obiettivi d'Esame
- of
- offrire
- offerta
- Offerte
- on
- ONE
- online
- aprire
- operativa
- ottimale
- Opzione
- oracolo
- organizzazione
- organizzativa
- organizzazioni
- Organizzato
- Altro
- proprietari
- proprietà
- parti
- partner
- partner
- Ricambi
- sentiero
- Paga le
- PC
- Persone
- eseguire
- performance
- Fisicamente
- pezzi
- Pilastro
- posto
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- giocato
- giocatore
- giocatori
- gioco
- per favore
- punti
- Termini e Condizioni
- politica
- Popolare
- possibile
- Post
- Postgresql
- potenzialmente
- preferito
- prezzo
- principalmente
- un bagno
- processi
- i processi
- lavorazione
- della produttività
- Prodotti
- Programmi
- protocolli
- fornire
- fornisce
- pubblicare
- editoriale
- Acquista
- acquisti
- qualità
- Domande
- rapidamente
- Crudo
- dati grezzi
- raggiungere
- Lettura
- pronto
- tempo reale
- ricevere
- raccomandazioni
- raccomandato
- record
- regioni
- pertinente
- rapporto
- Report
- deposito
- rappresentare
- necessario
- richiede
- assomiglia
- Risorse
- quelli
- restrittivo
- ritenzione
- Le vendite
- ruoli
- norme
- Correre
- stesso
- San
- San Francisco
- soddisfazione
- Scalabilità
- scalabile
- Scala
- bilancia
- scala
- Scienze
- Sezione
- sezioni
- in modo sicuro
- problemi di
- anziano
- separato
- serverless
- servizio
- Servizi
- Condividi
- condiviso
- compartecipazione
- spostamento
- Corti
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- simile
- Un'espansione
- So
- Social
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- lo spazio
- specialista
- specializzata
- specializzata
- specifico
- in particolare
- spendere
- Spendere
- spendendo denaro
- SQL
- pila
- Standard
- inizia a
- inizio
- Regione / Stato
- amministrazione
- conservazione
- Tornare al suo account
- negozi
- Streaming
- servizi di streaming
- strutturato
- sottoscrizione
- il successo
- di successo
- tale
- supporto
- supportato
- Supporto
- supporti
- SISTEMI DI TRATTAMENTO
- presa
- le squadre
- Consulenza
- Tecnologie
- Tecnologia
- condizioni
- che
- I
- l'hub
- L’ORIGINE
- loro
- Li
- Strumenti Bowman per analizzare le seguenti finiture:
- cose
- Terza
- terzi
- di parti terze standard
- migliaia
- Attraverso
- Timed
- sincronizzazione
- a
- strumenti
- mestieri
- Treni
- transazionale
- trasferimento
- Trasformare
- Trasformazione
- trasformato
- tendenze
- Svolta
- Tipi di
- tipicamente
- capire
- e una comprensione reciproca
- unificato
- imprevedibile
- Aggiornanento
- Aggiornamenti
- us
- uso
- Utente
- utenti
- generalmente
- utilizzare
- convalida
- vario
- fornitori
- visualizzazioni
- virtuale
- valute virtuali
- Magazzino
- Magazzinaggio
- sito web
- Web-basata
- presa web
- WELL
- Che
- se
- quale
- while
- OMS
- volere
- vittorie
- con
- entro
- senza
- Forza lavoro
- lavori
- mondo
- anni
- Trasferimento da aeroporto a Sharm
- zefiro
- zero