Novo Nordisk è un'azienda farmaceutica leader a livello mondiale, responsabile della produzione di farmaci salvavita che raggiungono più di 34 milioni di pazienti ogni giorno. Lo fanno seguendo la loro tripla linea di fondo: che devono sforzarsi di essere sostenibili dal punto di vista ambientale, socialmente sostenibili e finanziariamente sostenibili. La combinazione dell'utilizzo di AWS e dei dati supporta tutti questi obiettivi.
I dati sono pervasivi lungo l'intera catena del valore di Novo Nordisk. Dalla ricerca di base, alle linee di produzione, alle vendite e al marketing, agli studi clinici, alla farmacovigilanza, fino alle applicazioni guidate dai dati rivolte ai pazienti. Pertanto, ottenere le basi su come i dati vengono archiviati, salvaguardati e utilizzati in modo da fornire il massimo valore è uno dei driver centrali per il miglioramento dei risultati aziendali.
Insieme a Servizi professionali AWS, stiamo costruendo una soluzione di analisi e dati utilizzando un'architettura di dati moderna. La collaborazione tra Novo Nordisk e AWS Professional Services è uno stretto impegno strategico ea lungo termine, in cui gli sviluppatori di entrambe le organizzazioni hanno lavorato a stretto contatto per anni. Gli ambienti di dati e analisi sono costruiti attorno ai principi fondamentali della rete di dati: proprietà decentralizzata del dominio dei dati, dati come prodotto, infrastruttura di dati self-service e governance computazionale federata. Ciò consente agli utenti dell'ambiente di lavorare con i dati in modo da ottenere i migliori risultati di business. Abbiamo combinato questo con elementi di architetture evolutive che ci consentiranno di adattare diverse funzionalità man mano che AWS sviluppa continuamente nuovi servizi e capacità.
In questa serie di post imparerai come Novo Nordisk e AWS Professional Services hanno creato un ecosistema di dati e analisi per accelerare l'innovazione su scala petabyte:
- In questo primo post imparerai come il design complessivo ha permesso ai singoli componenti di riunirsi in modo modulare. Approfondiamo il modo in cui abbiamo creato una soluzione di gestione dei dati basata sull'architettura data mesh.
- Il secondo post illustra come abbiamo creato una rete di fiducia tra i sistemi che costituiscono l'intera soluzione. Mostriamo come utilizziamo le architetture guidate dagli eventi, insieme all'uso di controlli di accesso basati sugli attributi, per garantire che i limiti delle autorizzazioni siano rispettati su larga scala.
- Nel terzo post, mostriamo come gli utenti finali possono utilizzare i dati dal loro strumento preferito, senza compromettere la governance dei dati. Questo include come configurare Okta, Formazione AWS Lakee Microsoft Power BI per abilitare l'utilizzo federato basato su SAML di Amazzone Atena per un'attività di business intelligence (BI) aziendale.
Ambiente conforme alle norme farmaceutiche
In qualità di industria farmaceutica, la conformità GxP è un mandato per Novo Nordisk. GxP è un'abbreviazione generale per le linee guida e i regolamenti sulla qualità "Good x Practice" definiti da autorità di regolamentazione come l'Agenzia europea per i medicinali, la Food and Drug Administration degli Stati Uniti e altri. Queste linee guida sono concepite per garantire che i medicinali siano sicuri ed efficaci per l'uso previsto. Nel contesto di un ambiente di dati, la conformità GxP comporta l'implementazione di controlli di integrità per i dati utilizzati nel processo decisionale e nei processi e viene utilizzata per guidare il modo in cui i processi di gestione delle modifiche vengono implementati per garantire continuamente la conformità nel tempo.
Poiché questo ambiente di dati supporta i team di tutta l'organizzazione, ogni singolo proprietario di dati deve mantenere la responsabilità sui propri dati. Le funzionalità sono state progettate per fornire ai proprietari dei dati autonomia e trasparenza nella gestione dei propri dati, consentendo loro di assumersi questa responsabilità. Ciò include la capacità di gestire i dati delle informazioni di identificazione personale (PII) e altri carichi di lavoro sensibili. Per fornire la tracciabilità sull'ambiente, sono state aggiunte funzionalità di audit, che descriviamo più in dettaglio in questo post.
Panoramica della soluzione
La soluzione completa è un vasto panorama di servizi indipendenti che lavorano insieme per abilitare dati e analisi con un modello di governance dei dati decentralizzato su scala petabyte. Schematicamente, può essere rappresentato come nella figura seguente.

L'architettura è suddivisa in tre livelli indipendenti: gestione dei dati, virtualizzazione e consumo. L'utente finale si trova nel livello di consumo e lavora con il proprio strumento preferito. Ha lo scopo di astrarre la maggior parte delle risorse native di AWS alle primitive dell'applicazione. Il livello di consumo è integrato nel livello di virtualizzazione, che astrae l'accesso ai dati. Lo scopo del livello di virtualizzazione è tradurre tra consumo di dati e soluzioni di gestione dei dati. L'accesso ai dati è gestito da ciò che chiamiamo soluzioni di gestione dei dati. Discutiamo una delle nostre versatili soluzioni di gestione dei dati più avanti in questo post. Ogni livello in questa architettura è indipendente l'uno dall'altro e si basa invece solo su interfacce ben definite.
Fondamentale per questa architettura è che l'accesso è incapsulato in un file Gestione dell'identità e dell'accesso di AWS sessione del ruolo (IAM). Il livello di gestione dei dati si concentra sulla fornitura al ruolo IAM delle autorizzazioni e della governance corrette, il livello di virtualizzazione fornisce l'accesso al ruolo e il livello di consumo astrae l'uso dei ruoli negli strumenti scelti.
Architettura tecnica
Ciascuno dei tre livelli dell'architettura complessiva ha una responsabilità distinta, ma nessuna singola implementazione. Pensa a loro come classi astratte. Possono essere implementati in classi concrete e nel nostro caso si basano su servizi e funzionalità AWS fondamentali. Esaminiamo ciascuno dei tre strati.
Livello di gestione dei dati
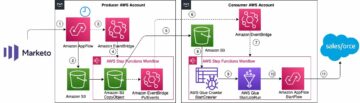
Il livello di gestione dei dati è responsabile di fornire l'accesso e la governance dei dati. Come illustrato nel diagramma seguente, un costrutto minimo nel livello di gestione dei dati è la combinazione di un Servizio di archiviazione semplice Amazon (Amazon S3) e un ruolo IAM che fornisce l'accesso al bucket S3. Questo costrutto può essere espanso per includere il permesso granulare con Lake Formation, auditing con AWS CloudTraile funzionalità di risposta di sicurezza da Hub di sicurezza AWS. Il diagramma seguente mostra anche che una singola soluzione di gestione dei dati non ha un singolo intervallo. Può incrociare molti account AWS ed essere composto da un numero qualsiasi di combinazioni di ruoli IAM.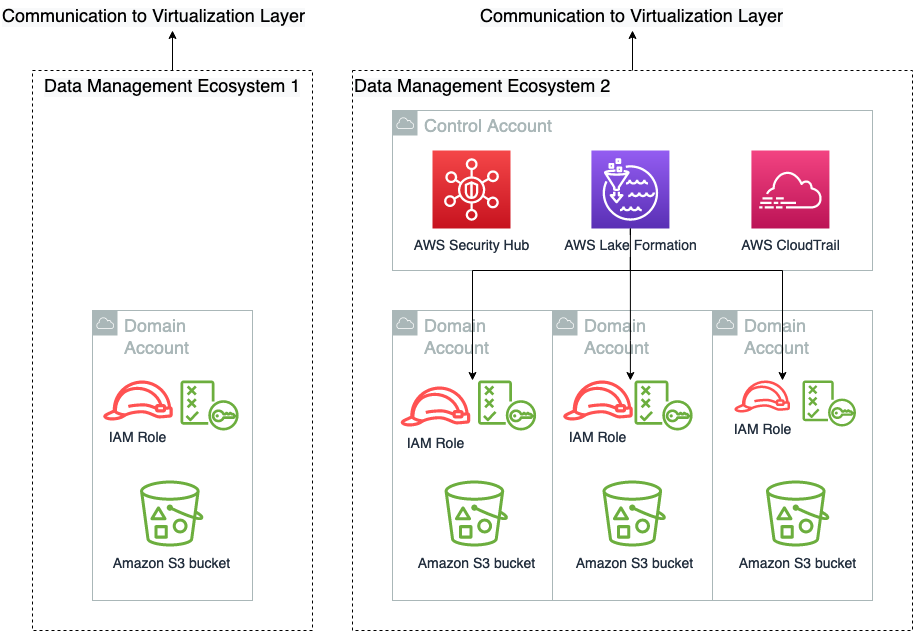
Non abbiamo volutamente illustrato la politica di fiducia di questi ruoli in questa figura, perché si tratta di una responsabilità collaborativa tra il livello di virtualizzazione e il livello di gestione dei dati. Entreremo nel dettaglio di come funziona nel prossimo post di questa serie. I professionisti dell'ingegneria dei dati spesso si interfacciano direttamente con il livello di gestione dei dati, dove curano e preparano i dati per il consumo.
Livello di virtualizzazione
Lo scopo del livello di virtualizzazione è tenere traccia di chi può fare cosa. Non ha alcuna capacità in sé, ma traduce i requisiti dagli ecosistemi di gestione dei dati ai livelli di consumo e viceversa. Consente agli utenti finali sul livello di consumo di accedere e manipolare i dati su uno o più ecosistemi di gestione dei dati, in base alle loro autorizzazioni. Questo livello estrae dagli utenti finali i dettagli tecnici sull'accesso ai dati, come il modello di autorizzazione, le ipotesi di ruolo e la posizione di archiviazione. Possiede le interfacce con gli altri livelli e applica la logica dell'astrazione. Nel contesto delle architetture esagonali (cfr Sviluppo di un'architettura evolutiva con AWS Lambda), il livello di interfaccia svolge il ruolo di logica di dominio, porte e adattatori. Gli altri due livelli sono attori. Il livello di gestione dei dati comunica lo stato del livello al livello di virtualizzazione e viceversa riceve informazioni sul panorama dei servizi di cui fidarsi. L'architettura del livello di virtualizzazione è illustrata nel diagramma seguente.

Strato di consumo
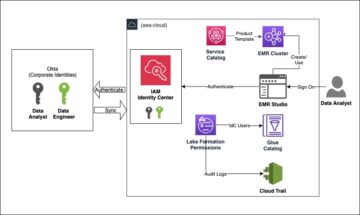
Il livello di consumo è dove si trovano gli utenti finali dei prodotti di dati. Può trattarsi di data scientist, analisti di business intelligence o qualsiasi terza parte che genera valore dal consumo dei dati. È importante per questo tipo di architettura che il livello di consumo disponga di un flusso di accesso basato su hook, in cui l'autorizzazione nell'applicazione può essere modificata al momento dell'accesso. Questo per tradurre il requisito specifico di AWS nelle applicazioni di destinazione. Dopo che la sessione nell'applicazione lato client è stata avviata correttamente, spetta all'applicazione stessa fornire strumenti per l'astrazione del livello dati, perché questa sarà specifica dell'applicazione. E questo è un altro importante disaccoppiamento, in cui una parte della responsabilità viene trasferita alle unità decentralizzate. Molte moderne applicazioni software come servizio (SaaS) supportano questi meccanismi integrati, ad esempio Databricks or Laboratorio dati Domino, mentre le applicazioni lato client più tradizionali come Server RStudio hanno un supporto nativo più limitato per questo. Nel caso in cui manchi il supporto nativo, è possibile eseguire una traduzione fino alla sessione utente del sistema operativo per abilitare l'astrazione. Il livello di consumo è mostrato schematicamente nel diagramma seguente.
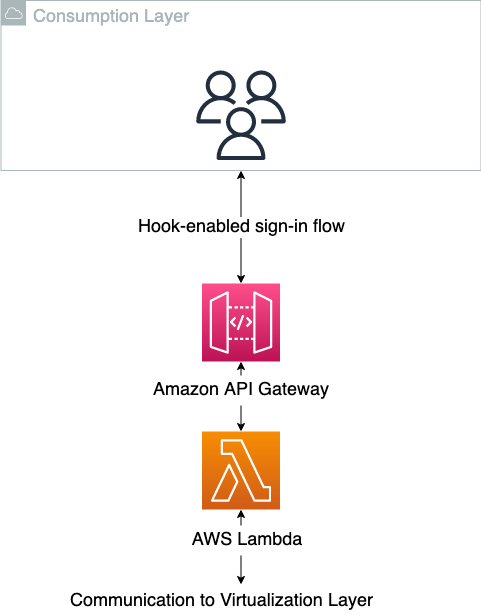
Quando si utilizza il livello di consumo come previsto, gli utenti non sanno che esiste il livello di virtualizzazione. Il diagramma seguente illustra i modelli di accesso ai dati.
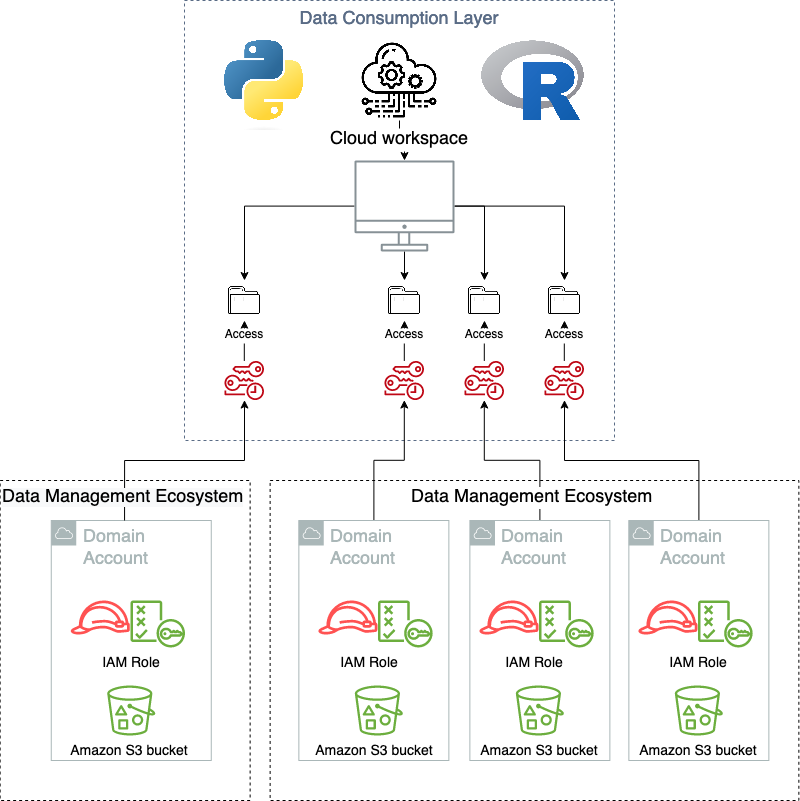
modularità
Uno dei principali vantaggi dell'adozione del modello di architettura esagonale e della delega sia del livello di consumo che del livello di gestione dei dati ad attori primari e secondari, significa che possono essere modificati o sostituiti man mano che vengono rilasciate nuove funzionalità che richiedono nuove soluzioni. Ciò fornisce un modello di tipo hub-and-spoke, in cui molti diversi tipi di sistemi di tipo produttore/consumatore possono essere collegati e lavorare simultaneamente in unione. Un esempio di ciò è che l'attuale soluzione in esecuzione in Novo Nordisk supporta più soluzioni di gestione dei dati simultanee e sono esposte in modo omogeneo nel livello di consumo. Ciò include sia un data lake, la soluzione data mesh presentata in questo post, sia diverse soluzioni indipendenti di gestione dei dati. E questi sono esposti a più tipi di applicazioni consumer, dalle applicazioni self-hosted gestite in modo personalizzato alle offerte SaaS.
Ecosistema di gestione dei dati
Per ridimensionare l'utilizzo dei dati e aumentare la libertà, Novo Nordisk, in collaborazione con AWS Professional Services, ha creato un ambiente di gestione e governance dei dati, denominato Novo Nordisk Enterprise DataHub (NNEDH). NNEDH implementa un'architettura dati distribuita decentralizzata e funzionalità di gestione dei dati come un catalogo di dati aziendali aziendali e un flusso di lavoro di condivisione dei dati. NNEDH è un esempio di un ecosistema di gestione dei dati nel quadro concettuale introdotto in precedenza.
Architettura decentralizzata: da un data lake centralizzato a un'architettura distribuita
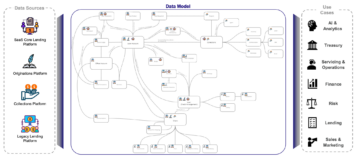
Il data lake centralizzato di Novo Nordisk è costituito da 2.3 PB di dati provenienti da oltre 30 domini di dati aziendali in tutto il mondo che servono oltre 2000 utenti interni lungo tutta la catena del valore. Funziona con successo da diversi anni. È uno degli ecosistemi di gestione dei dati attualmente supportati.
All'interno dell'architettura dei dati centralizzata, i dati di ciascun dominio di dati vengono copiati, archiviati ed elaborati in un'unica posizione centrale: un data lake centrale ospitato in un data storage. Questo modello presenta sfide su larga scala perché mantiene la proprietà dei dati con il team centrale. Su larga scala, questo modello rallenta il viaggio verso un'organizzazione basata sui dati, perché la proprietà dei dati non è sufficientemente ancorata ai professionisti più vicini al dominio.
L'architettura monolitica del data lake è illustrata nel diagramma seguente.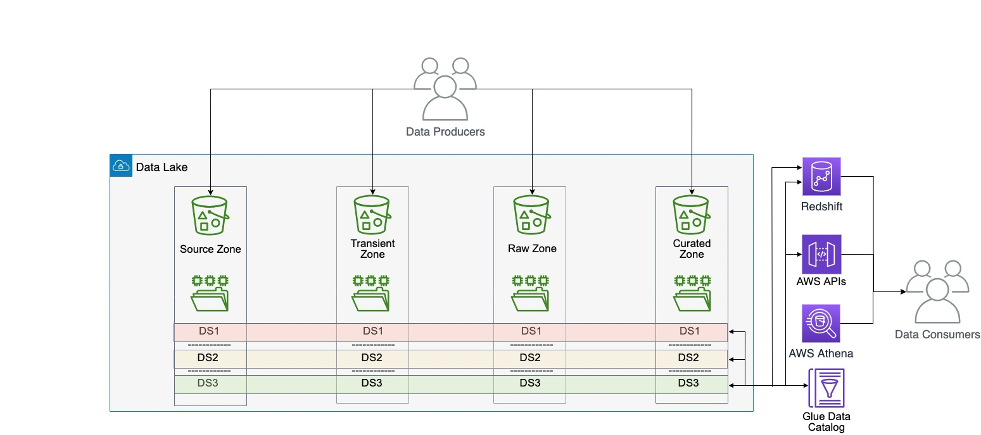
All'interno dell'architettura dati distribuita decentralizzata, i dati di ciascun dominio vengono conservati all'interno del dominio sul proprio account di archiviazione e calcolo dei dati. In questo caso, i dati vengono tenuti vicino agli esperti del dominio, perché sono quelli che conoscono meglio i propri dati e sono in definitiva i proprietari di qualsiasi prodotto di dati costruito attorno ai loro dati. Spesso lavorano a stretto contatto con gli analisti aziendali per costruire il prodotto di dati e quindi sanno cosa significano buoni dati per i consumatori dei loro prodotti di dati. In questo caso, anche la responsabilità dei dati è decentralizzata, dove ogni dominio ha il proprio proprietario dei dati, attribuendo la responsabilità ai veri proprietari dei dati. Tuttavia, questo modello potrebbe non funzionare su piccola scala, ad esempio un'organizzazione con una sola business unit e decine di utenti, perché introdurrebbe un sovraccarico maggiore per il team IT per la gestione dei dati dell'organizzazione. Si adatta meglio alle grandi organizzazioni o a quelle piccole e medie che vorrebbero crescere e ridimensionarsi.
L'architettura data mesh di Novo Nordisk è illustrata nel diagramma seguente.

Domini di dati e asset di dati
Per abilitare la scalabilità dei domini di dati all'interno dell'organizzazione, è obbligatorio disporre di un modello di autorizzazione standard e di un modello di accesso ai dati. Questo standard non deve essere troppo restrittivo in modo tale da poter essere un blocco per casi d'uso specifici, ma dovrebbe essere standardizzato in modo tale da utilizzare la stessa interfaccia tra i livelli di gestione dei dati e di virtualizzazione.
I domini di dati su NNEDH sono implementati da un costrutto chiamato an ambiente. Un ambiente è composto da almeno un account AWS e una regione AWS. È un luogo di lavoro in cui i team del dominio dei dati possono lavorare e collaborare per creare prodotti di dati. Collega il piano di controllo NNEDH agli account AWS in cui risiedono i dati e il calcolo del dominio. I permessi di accesso ai dati sono definiti anche a livello di ambiente, gestito dal proprietario del dominio dati. Gli ambienti hanno tre componenti principali: un livello di gestione e governance dei dati, asset di dati e progetti facoltativi per l'elaborazione dei dati.
Per la gestione e la governance dei dati, i domini dei dati si affidano a Lake Formation, Colla AWSe CloudTrail. Il metodo di distribuzione e la configurazione di questi componenti sono standardizzati nei domini di dati. In questo modo, il piano di controllo NNEDH può fornire connettività e gestione ai domini di dati in modo standardizzato.
Le risorse di dati di ciascun dominio che risiedono in un ambiente sono organizzate in un set di dati, che è una raccolta di dati correlati utilizzati per creare un prodotto di dati. Include metadati tecnici come il formato dei dati, le dimensioni e l'ora di creazione e metadati aziendali come il produttore, la classificazione dei dati e la definizione aziendale. Un prodotto dati può utilizzare uno o più set di dati. Viene implementato tramite bucket S3 gestiti e Catalogo dati di AWS Glue.
Il trattamento dei dati può essere attuato in diversi modi. NNEDH fornisce progetti per pipeline di dati con connettività predefinita alle risorse di dati per accelerare la consegna dei prodotti di dati. Gli utenti del dominio di dati hanno la libertà di utilizzare qualsiasi altra capacità di calcolo sul proprio dominio, ad esempio utilizzando servizi AWS non predefiniti nei blueprint o accedendo ai set di dati da altri strumenti di analisi implementati nel livello di consumo, come menzionato in precedenza in questo post.
Persone e ruoli del dominio dei dati
Su NNEDH, i livelli di autorizzazione sui domini di dati sono gestiti tramite persone predefinite, ad esempio proprietario dei dati, amministratori dei dati, sviluppatori e lettori. Ogni persona è associata a un ruolo IAM con un livello di autorizzazione predefinito. Queste autorizzazioni si basano sulle esigenze tipiche degli utenti con questi ruoli. Tuttavia, per dare maggiore flessibilità ai domini di dati, queste autorizzazioni possono essere personalizzate ed estese secondo necessità.
Le autorizzazioni associate a ciascuna persona sono correlate solo alle azioni consentite sull'account AWS del dominio di dati. Per la responsabilità sugli asset di dati, l'accesso ai dati agli asset è gestito da specifiche policy delle risorse invece che da ruoli IAM. Solo il proprietario di ciascun set di dati o gli amministratori dei dati delegati dal proprietario possono concedere o revocare l'accesso ai dati.
A livello di set di dati, una persona richiesta è il proprietario dei dati. In genere, lavorano a stretto contatto con uno o più data steward come responsabili dei prodotti dati. Il data steward è l'esperto in materia di dati del dominio del prodotto di dati, responsabile dell'interpretazione dei dati e dei metadati raccolti per ricavare approfondimenti aziendali e costruire il prodotto. Il data steward fa da ponte tra utenti aziendali e team tecnici su ogni dominio di dati.
Catalogo dei dati aziendali aziendali
Per consentire la libertà e rendere rilevabili le risorse di dati dell'organizzazione, viene implementato un catalogo di dati del portale basato sul Web. Indicizza in un unico repository i metadati provenienti da set di dati costruiti su domini di dati, rompendo i silos di dati all'interno dell'organizzazione. Il catalogo dei dati consente la ricerca e l'individuazione dei dati in diversi domini, nonché l'automazione e la governance sulla condivisione dei dati.
Il catalogo dei dati aziendali implementa i processi di governance dei dati all'interno dell'organizzazione. Garantisce la proprietà dei dati: qualcuno nell'organizzazione è responsabile dell'origine dei dati, della definizione, degli attributi aziendali, delle relazioni e delle dipendenze.
Il costrutto centrale di un catalogo di dati aziendali è un set di dati. È l'unità di ricerca all'interno del catalogo aziendale, con metadati sia tecnici che aziendali. Per raccogliere metadati tecnici da dati strutturati, si affida ai crawler di AWS Glue per riconoscere ed estrarre strutture di dati dai formati di dati più diffusi, tra cui CSV, JSON, Avro e Apache Parquet. Fornisce informazioni come il tipo di dati, la data di creazione e il formato. I metadati possono essere arricchiti dagli utenti aziendali aggiungendo una descrizione del contesto aziendale, tag e classificazione dei dati.
La definizione del set di dati e i relativi metadati sono archiviati in un file Amazon Aurora senza server database e Servizio Amazon OpenSearch, che consente di eseguire query testuali sul catalogo dati.
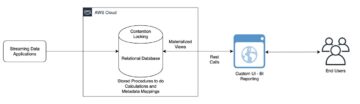
La condivisione dei dati
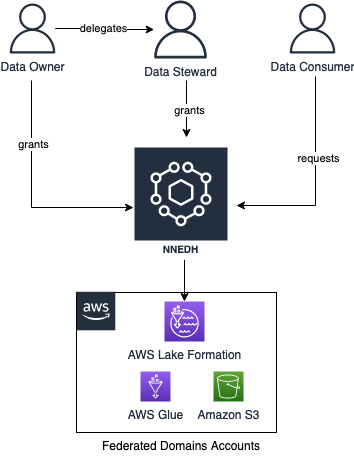
NNEDH implementa un flusso di lavoro di condivisione dei dati, consentendo la condivisione dei dati peer-to-peer tra gli account AWS utilizzando Lake Formation. Il flusso di lavoro è il seguente:
- Un consumatore di dati richiede l'accesso al set di dati.
- Il proprietario dei dati concede l'accesso approvando la richiesta di accesso. Possono delegare l'approvazione delle richieste di accesso al data steward.
- Dopo l'approvazione di una richiesta di accesso, viene aggiunta una nuova autorizzazione al set di dati specifico in Lake Formation dell'account produttore.
Il flusso di lavoro di condivisione dei dati è mostrato schematicamente nella figura seguente.
Sicurezza e controllo
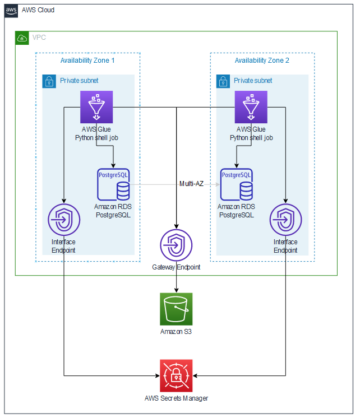
I dati nella rete di dati Novo Nordisk si trovano negli account AWS di proprietà degli account aziendali Novo Nordisk. La configurazione e gli stati della mesh di dati sono memorizzati in Servizio di database relazionale Amazon (Amazon RDS). L'architettura di sicurezza di Novo Nordisk è illustrata nella figura seguente.

L'accesso e le modifiche ai dati in NNEDH devono essere registrati a scopo di controllo. Dobbiamo essere in grado di dire chi ha modificato i dati, quando è avvenuta la modifica e quali modifiche sono state applicate. Inoltre, dobbiamo essere in grado di rispondere al motivo per cui la modifica è stata consentita da quella persona in quel momento.
Per soddisfare questi requisiti, utilizziamo i seguenti componenti:
- CloudTrail per registrare le chiamate API. Abilitiamo specificamente la registrazione degli eventi dei dati di CloudTrail per oggetti e bucket S3. Attivando la registrazione, possiamo ricondurre qualsiasi modifica a qualsiasi file nel data lake alla persona che ha apportato la modifica. Applichiamo l'uso di identità di origine per le sessioni del ruolo IAM per garantire la tracciabilità dell'utente.
- Utilizziamo Amazon RDS per archiviare la configurazione della rete di dati. Registriamo le query sul database RDS. Insieme a CloudTrail, questo registro ci consente di rispondere alla domanda sul perché sia possibile una modifica a un file in Amazon S3 in un momento specifico da parte di una persona specifica.
- Amazon Cloud Watch per registrare le attività attraverso la mesh.
Oltre a questi meccanismi di registrazione, i bucket S3 vengono creati utilizzando le seguenti proprietà:
- Il bucket viene crittografato utilizzando la crittografia lato server con Servizio di gestione delle chiavi AWS (AWS KMS) e chiavi gestite dal cliente
- Il controllo delle versioni di Amazon S3 è attivato per impostazione predefinita
L'accesso ai dati in NNEDH è controllato a livello di gruppo anziché di singoli utenti. Il gruppo corrisponde al gruppo definito nel gruppo di directory di Novo Nordisk. Per tenere traccia della persona che ha modificato i dati nei data lake, utilizziamo il meccanismo di identità della fonte spiegato nel post Come correlare l'attività del ruolo IAM all'identità aziendale.
Conclusione
In questo post, abbiamo mostrato come Novo Nordisk ha creato un'architettura dati moderna per accelerare la fornitura di casi d'uso basati sui dati. Include un'architettura di dati distribuita, per ridimensionare l'utilizzo su scala petabyte per oltre 2,000 utenti interni lungo tutta la catena del valore, nonché un'architettura di sicurezza e audit distribuita che gestisce la responsabilità e la tracciabilità dei dati nell'ambiente per soddisfare i loro requisiti di conformità.
Il post successivo di questa serie descrive l'implementazione della governance e del controllo dei dati distribuiti su larga scala della moderna architettura dei dati di Novo Nordisk.
Informazioni sugli autori
 Jonatan Selsing è un ex ricercatore con un dottorato in astrofisica che si è rivolto al cloud. Attualmente è Lead Cloud Engineer presso Novo Nordisk, dove abilita i carichi di lavoro di dati e analisi su larga scala. Con un'enfasi sulla riduzione del costo totale di proprietà dei carichi di lavoro basati su cloud, offrendo al contempo il massimo vantaggio dei vantaggi del cloud, progetta, costruisce e mantiene soluzioni che consentono la ricerca per i farmaci del futuro.
Jonatan Selsing è un ex ricercatore con un dottorato in astrofisica che si è rivolto al cloud. Attualmente è Lead Cloud Engineer presso Novo Nordisk, dove abilita i carichi di lavoro di dati e analisi su larga scala. Con un'enfasi sulla riduzione del costo totale di proprietà dei carichi di lavoro basati su cloud, offrendo al contempo il massimo vantaggio dei vantaggi del cloud, progetta, costruisce e mantiene soluzioni che consentono la ricerca per i farmaci del futuro.
 Hassen Riahi è Sr. Data Architect presso AWS Professional Services. Ha conseguito un dottorato di ricerca in matematica e informatica sulla gestione dei dati su larga scala. Lavora con i clienti AWS alla creazione di soluzioni basate sui dati.
Hassen Riahi è Sr. Data Architect presso AWS Professional Services. Ha conseguito un dottorato di ricerca in matematica e informatica sulla gestione dei dati su larga scala. Lavora con i clienti AWS alla creazione di soluzioni basate sui dati.
 Anwar Rizal è un consulente senior di Machine Learning con sede a Parigi. Lavora con i clienti AWS per sviluppare soluzioni di dati e intelligenza artificiale per far crescere in modo sostenibile il loro business.
Anwar Rizal è un consulente senior di Machine Learning con sede a Parigi. Lavora con i clienti AWS per sviluppare soluzioni di dati e intelligenza artificiale per far crescere in modo sostenibile il loro business.
 Mosè Artù proviene da un background di ricerca matematica e computazionale e ha conseguito un dottorato di ricerca in Computational Intelligence specializzato in Graph Mining. Attualmente è un ingegnere di prodotti cloud presso Novo Nordisk che costruisce data lake aziendali conformi a GxP e piattaforme di analisi per le fabbriche globali di Novo Nordisk che producono prodotti medicali digitalizzati.
Mosè Artù proviene da un background di ricerca matematica e computazionale e ha conseguito un dottorato di ricerca in Computational Intelligence specializzato in Graph Mining. Attualmente è un ingegnere di prodotti cloud presso Novo Nordisk che costruisce data lake aziendali conformi a GxP e piattaforme di analisi per le fabbriche globali di Novo Nordisk che producono prodotti medicali digitalizzati.
 Alessandro Fiore è Sr. Data Architect presso AWS Professional Services. Con oltre 10 anni di esperienza nella fornitura di soluzioni di dati e analisi, è appassionato di progettazione e costruzione di piattaforme di dati moderne e scalabili che accelerano le aziende per ottenere valore dai loro dati.
Alessandro Fiore è Sr. Data Architect presso AWS Professional Services. Con oltre 10 anni di esperienza nella fornitura di soluzioni di dati e analisi, è appassionato di progettazione e costruzione di piattaforme di dati moderne e scalabili che accelerano le aziende per ottenere valore dai loro dati.
 Kumari Ramar è un Senior Engagement Manager certificato Agile e certificato PMP presso AWS Professional Services. Fornisce soluzioni di dati e AI/ML che accelerano l'analisi tra sistemi e i modelli di apprendimento automatico, che consentono alle aziende di prendere decisioni basate sui dati e promuovere nuove innovazioni.
Kumari Ramar è un Senior Engagement Manager certificato Agile e certificato PMP presso AWS Professional Services. Fornisce soluzioni di dati e AI/ML che accelerano l'analisi tra sistemi e i modelli di apprendimento automatico, che consentono alle aziende di prendere decisioni basate sui dati e promuovere nuove innovazioni.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/
- 000
- 10
- 100
- a
- capace
- Chi siamo
- ABSTRACT
- abstract
- accelerare
- accesso
- Accesso ai dati
- Accedendo
- Secondo
- Il mio account
- responsabilità
- conti
- operanti in
- azioni
- attivazione
- attività
- attività
- adattare
- aggiunto
- aggiunta
- aggiuntivo
- amministrazione
- Adottando
- vantaggi
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- agenzia
- agile
- AI
- AI / ML
- Tutti
- consente
- Amazon
- Amazon RDS
- Gli analisti
- analitica
- ed
- rispondere
- Apache
- api
- Applicazioni
- specifico dell'applicazione
- applicazioni
- applicato
- approvazione
- architettura
- in giro
- Attività
- associato
- astrofisica
- gli attributi
- revisione
- revisione
- Aurora
- autorizzazione
- Automazione
- AWS
- Colla AWS
- Servizi professionali AWS
- precedente
- sfondo
- basato
- perché
- beneficio
- MIGLIORE
- Meglio
- fra
- Parte inferiore
- confini
- Rottura
- ponti
- costruire
- Costruzione
- costruisce
- costruito
- incassato
- affari
- business intelligence
- detto
- Bandi
- funzionalità
- Custodie
- casi
- catalogo
- centrale
- centralizzata
- Certificato
- catena
- sfide
- il cambiamento
- scegliere
- classi
- classificazione
- Info su
- test clinici
- Chiudi
- strettamente
- Cloud
- collaboreranno
- collaborazione
- collaborativo
- raccogliere
- collezione
- combinazione
- combinazioni
- combinato
- Venire
- Aziende
- azienda
- conformità
- componenti
- composto
- Compreso
- compromettendo
- Calcolare
- computer
- Informatica
- concettuale
- Configurazione
- collegato
- Connettività
- costruire
- consulente
- consumare
- Consumer
- Consumatori
- consumo
- contesto
- di controllo
- controllata
- controlli
- Nucleo
- Aziende
- corrisponde
- Costo
- accoppiato
- creato
- creazione
- Cross
- Corrente
- Attualmente
- costume
- cliente
- Clienti
- dati
- l'accesso ai dati
- infrastruttura dati
- Lago di dati
- gestione dei dati
- elaborazione dati
- condivisione dei dati
- memorizzazione dei dati
- data-driven
- Banca Dati
- Databricks
- dataset
- Data
- giorno
- decentrata
- decisione
- Decision Making
- decisioni
- deep
- consegna
- fornisce un monitoraggio
- consegna
- deployment
- descrivere
- descrizione
- Design
- progettato
- progettazione
- disegni
- dettaglio
- dettagli
- sviluppare
- sviluppatori
- sviluppa
- diverso
- direttamente
- scoperta
- discutere
- distinto
- distribuito
- non
- dominio
- domini
- Dont
- giù
- guidare
- driver
- droga
- ogni
- In precedenza
- ecosistema
- ecosistemi
- Efficace
- elementi
- enfasi
- enable
- abilitato
- Abilita
- consentendo
- incapsulato
- crittografato
- crittografia
- Fidanzamento
- ingegnere
- Ingegneria
- arricchito
- garantire
- assicura
- Impresa
- aziende
- Intero
- Ambiente
- l'ambiente
- ambienti
- Etere (ETH)
- europeo
- Evento
- esempio
- esiste
- ampliato
- esperienza
- esperto
- esperti
- ha spiegato
- esposto
- estratto
- fabbriche
- Caratteristiche
- figura
- Compila il
- File
- finanziariamente
- Nome
- Flessibilità
- flusso
- si concentra
- i seguenti
- segue
- cibo
- Food and Drug Administration
- formato
- formazione
- Ex
- Fondazione
- Contesto
- La libertà
- da
- pieno
- funzionalità
- futuro
- Generale
- genera
- ottenere
- ottenere
- Dare
- dà
- Dare
- globali
- Go
- buono
- la governance
- concedere
- borse di studio
- grafico
- Gruppo
- Crescere
- guida
- linee guida
- maniglia
- Manovrabilità
- successo
- avendo
- detiene
- ospitato
- Come
- Tutorial
- HTML
- HTTPS
- IAM
- Identità
- implementazione
- implementato
- Implementazione
- attrezzi
- importante
- migliorata
- in
- includere
- inclusi
- Compreso
- Aumento
- studente indipendente
- indici
- individuale
- industria
- informazioni
- Infrastruttura
- Innovazione
- innovazioni
- intuizioni
- invece
- strumento
- integrato
- interezza
- Intelligence
- Interfaccia
- interfacce
- interno
- introdurre
- introdotto
- IT
- stessa
- viaggio
- json
- mantenere
- Le
- Sapere
- lago
- paesaggio
- grandi
- larga scala
- strato
- galline ovaiole
- portare
- principale
- IMPARARE
- apprendimento
- Livello
- livelli
- Limitato
- Linee
- Collegamento
- località
- a lungo termine
- macchina
- machine learning
- fatto
- Principale
- mantiene
- make
- Fare
- gestire
- gestito
- gestione
- Soluzione di gestione
- direttore
- I gestori
- gestione
- Mandato
- obbligatorio
- consigliato per la
- molti
- Marketing
- matematica
- Importanza
- si intende
- meccanismo
- medicale
- medicinale
- medie
- Soddisfare
- menzionato
- Metadati
- metodo
- Microsoft
- forza
- milione
- minimo
- Siti di estrazione mineraria
- mancante
- modello
- modelli
- moderno
- modifiche
- modificato
- componibile
- Scopri di più
- maggior parte
- Più popolare
- multiplo
- Detto
- nativo
- Bisogno
- di applicazione
- esigenze
- Rete
- tuttavia
- New
- nuove soluzioni
- GENERAZIONE
- Nuovo
- Novo Nordisk
- numero
- oggetti
- offerte
- OTTA
- ONE
- organizzazione
- organizzazioni
- Organizzato
- Origin
- OS
- Altro
- Altri
- complessivo
- proprio
- Di proprietà
- proprietario
- proprietari
- proprietà
- possiede
- Parigi
- partito
- appassionato
- pazienti
- Cartamodello
- modelli
- peer to peer
- autorizzazione
- permessi
- persona
- Personalmente
- petabyte
- Pharmaceutical
- pii
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- politica
- Popolare
- Portale
- porte
- possibile
- Post
- Post
- energia
- Power BI
- Preparare
- presentata
- primario
- i processi
- lavorazione
- produttore
- Prodotto
- Prodotti
- professionale
- Scelto dai professionisti
- proprietà
- fornire
- fornisce
- fornitura
- scopo
- fini
- spinto
- Mettendo
- qualità
- domanda
- raggiungere
- lettori
- riceve
- riconoscere
- riducendo
- regione
- normativa
- Regolatori
- relazionato
- Relazioni
- rilasciato
- sostituito
- deposito
- rappresentato
- richiesta
- richieste
- richiedere
- necessario
- requisito
- Requisiti
- riparazioni
- risorsa
- Risorse
- rispettati
- risposta
- responsabilità
- responsabile
- restrittivo
- Ruolo
- ruoli
- Correre
- running
- SaaS
- sicura
- vendite
- stesso
- Scalabilità
- scalabile
- Scala
- Scienze
- Scienziato
- scienziati
- Cerca
- Secondo
- secondario
- problemi di
- Fai da te
- delicata
- Serie
- servizio
- Servizi
- servizio
- Sessione
- sessioni
- flessibile.
- alcuni
- compartecipazione
- dovrebbero
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- Un'espansione
- contemporaneamente
- singolo
- singolare
- Seduta
- Taglia
- rallenta
- piccole
- socialmente
- Software
- software come un servizio
- soluzione
- Soluzioni
- alcuni
- Fonte
- specializzata
- specifico
- in particolare
- velocità
- dividere
- Standard
- iniziato
- Regione / Stato
- stati
- conservazione
- Tornare al suo account
- memorizzati
- Strategico
- lottare
- strutturato
- soggetto
- Con successo
- tale
- supporto
- supportato
- supporti
- sostenibile
- SISTEMI DI TRATTAMENTO
- Fai
- Target
- obiettivi
- team
- le squadre
- Consulenza
- dogmi
- I
- L’ORIGINE
- Lo Stato
- loro
- perciò
- Terza
- tre
- Attraverso
- per tutto
- tempo
- a
- insieme
- pure
- strumenti
- Totale
- verso
- tracciare
- Tracciabilità
- pista
- tradizionale
- tradurre
- Traduzione
- Trasparenza
- studi clinici
- Triplicare
- vero
- Affidati ad
- Turned
- Tipi di
- tipico
- tipicamente
- noi
- in definitiva
- unione
- unità
- unità
- us
- Impiego
- uso
- Utente
- utenti
- APPREZZIAMO
- versatile
- modi
- Web-basata
- ben definita
- Che
- quale
- while
- OMS
- volere
- entro
- senza
- Lavora
- lavorare insieme
- lavorato
- flusso di lavoro
- Sul posto di lavoro
- lavori
- In tutto il mondo
- sarebbe
- X
- anni
- zefiro