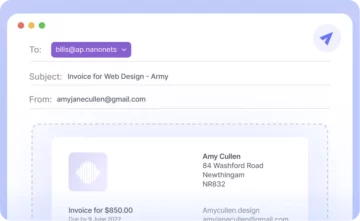
In questo articolo scoprirai vari metodi per convertire PDF in Fogli Google.
Imparerai anche come possono fare le Nanonet automatizza l'intero flusso di lavoro di conversione da PDF a Fogli Google on-line.
Prima di esaminare come convertire PDF in Fogli Google, diamo un'occhiata al motivo per cui è importante farlo.
Perché convertire i PDF in fogli Google?
Secondo questa Blog di Google post dalla pagina ufficiale del blog di Google, più di 5 milioni di aziende utilizzano la loro soluzione G Suite. Allo stesso tempo, un gran numero di aziende ha anche iniziato a utilizzare le integrazioni di Fogli Google per automatizzare le attività.
Consideriamo un caso d'uso tipico. Il tuo team di contabilità fornitori riceve una fattura, nel formato PDF standard. Qualcuno esamina manualmente la fattura e inserisce le informazioni richieste in un documento di Fogli Google prima di inoltrarlo alla sezione Finanza. La sezione Finanza paga il tuo fornitore e fa una registrazione nel libro mastro dell'azienda.
Oltre ad essere un processo lungo, questo è soggetto a errori e avrebbe molto più senso automatizzarlo semplicemente.
Ora che è chiara la necessità di convertire i PDF in un modulo di foglio di Google, diamo un'occhiata a come sono strutturati i documenti PDF e quali sono le difficoltà nell'analizzarli.
Vuoi convertire PDF i file Fogli Google ? Check-out Nanonets ' "gratis" Convertitore da PDF a CSV. Oppure scopri come automatizza l'intero flusso di lavoro da PDF a Fogli Google con Nanonets.
Sfide con l'analisi di un documento PDF
Il formato di documento portatile era un formato di file inizialmente sviluppato da Adobe e successivamente rilasciato come standard aperto. Da allora è stato ampiamente adottato in quanto è agnostico rispetto al sistema operativo sottostante.
Allora, perché è così difficile analizzare un PDF e convertirne il contenuto in un altro formato? Le immagini seguenti parlano più di mille parole e guideranno il punto a casa.
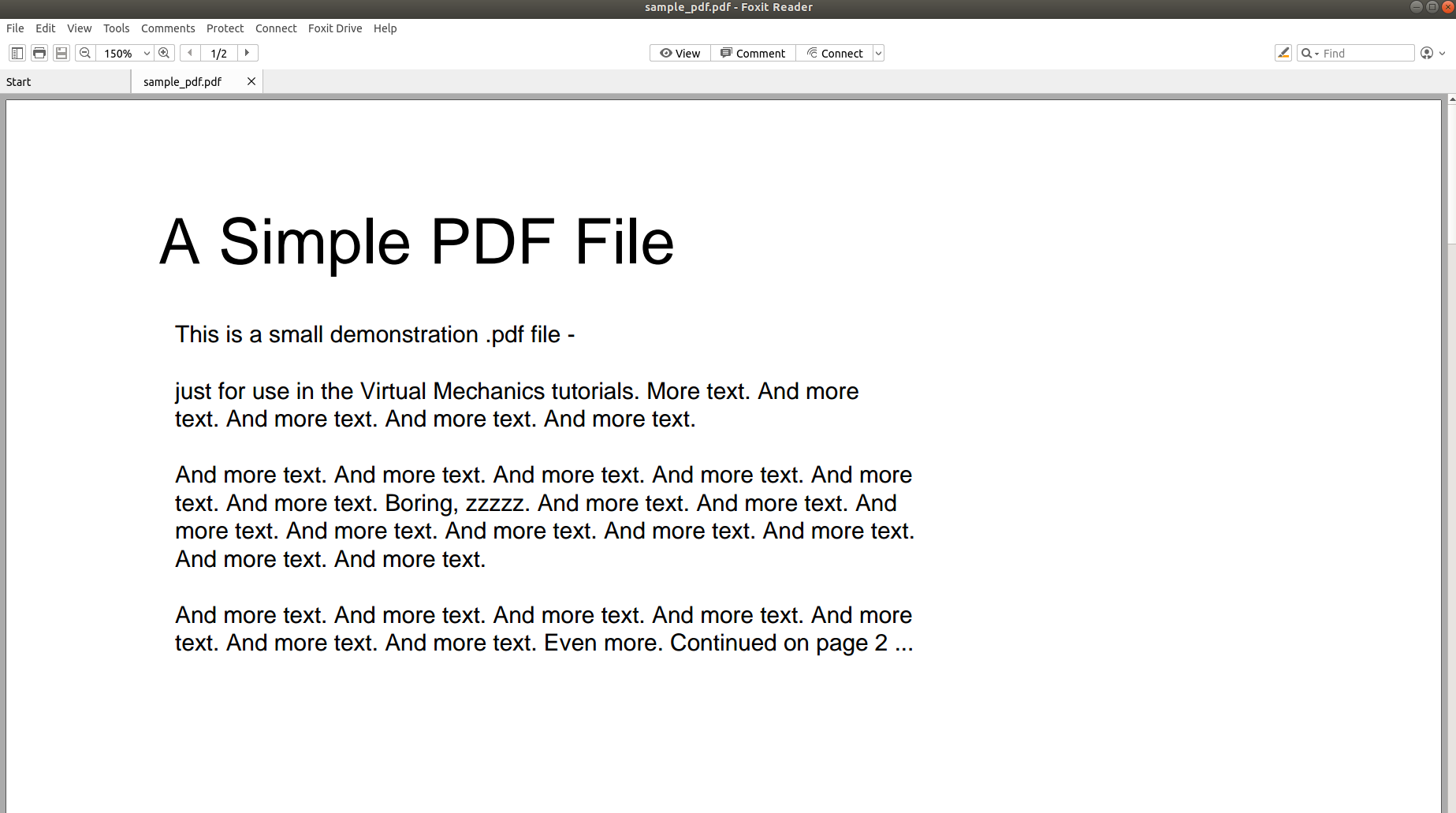
L'immagine sopra mostra lo screenshot di un documento PDF che viene aperto utilizzando un lettore PDF. Proviamo ad aprire lo stesso documento PDF utilizzando un editor di testo.
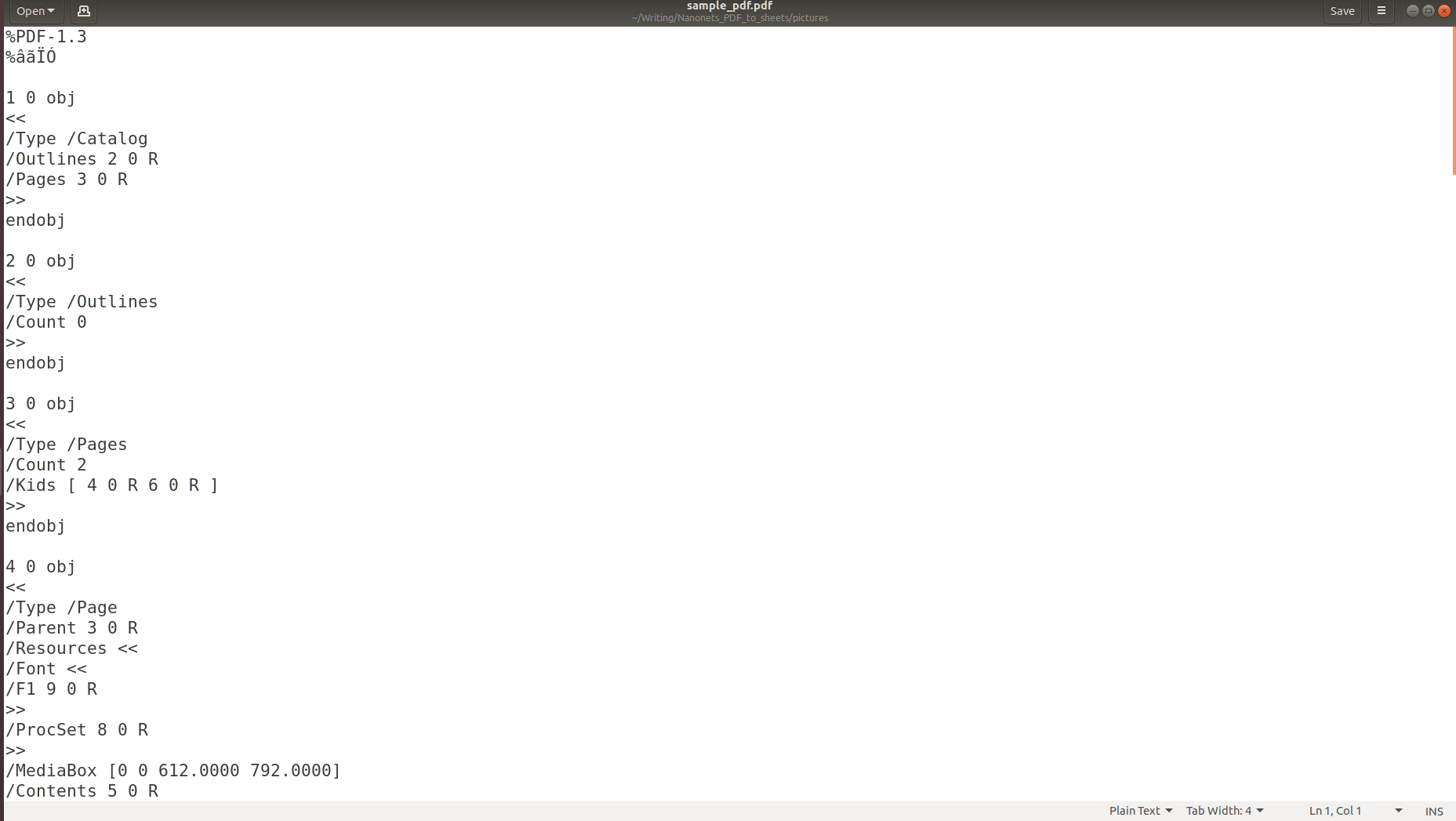
Le immagini di cui sopra chiariscono che quando le informazioni vengono archiviate in un PDF, la sua struttura originale viene completamente persa. Questo perché il formato PDF consiste semplicemente di istruzioni su come stampare/disegnare una sequenza di caratteri su una pagina.
Se ritieni che l'estrazione del testo sia difficile, estrarre i dati presenti nelle tabelle è ancora più impegnativo a causa dei formati tabulari ampiamente diversi che vengono utilizzati.
Si spera che tu sia convinto che convertire un documento PDF in un modulo di Fogli Google non sia una passeggiata nel parco. La sezione successiva parla dell'approccio adottato dalla maggior parte dei moderni parser PDF per riconoscere/analizzare le informazioni da un documento PDF.
L'approccio moderno all'analisi dei documenti PDF
La maggior parte dei parser PDF moderni utilizza il flusso descritto di seguito per analizzare i dati non strutturati dai documenti PDF.
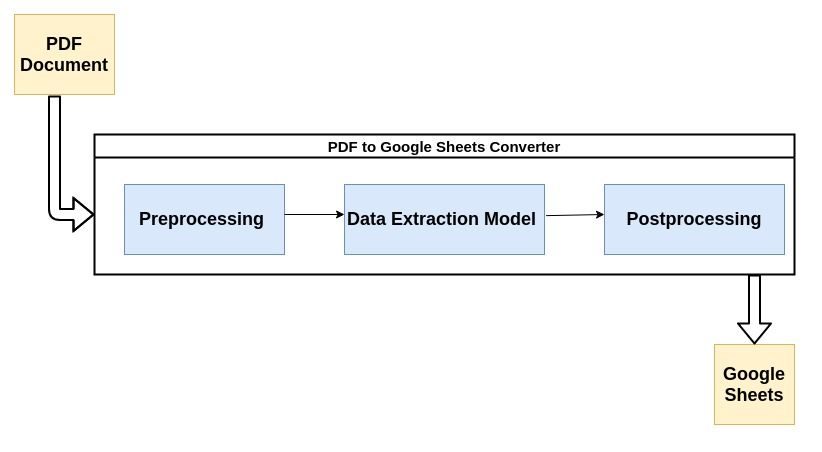
Esaminiamo brevemente ogni fase del processo:
1. Pre-elaborazione o pulizia dei dati:
Migliore è l'aspetto del tuo PDF, più facile sarà per il tuo modello di Machine Learning estrarre o acquisire dati da. Ad esempio, se il documento PDF è stato scansionato, è destinato a contenere alcuni artefatti di scansione che potrebbero influire sulle prestazioni del convertitore.
La rimozione del rumore mediante l'utilizzo di filtri appropriati, la binarizzazione, la correzione dell'inclinazione ecc. sono alcuni dei passaggi di pre-elaborazione più comuni. Il seguente post di Nanonets Nanonets Tesseract Post contiene alcuni grandi esempi di come i documenti possono essere pre-elaborati prima Riconoscimento ottico dei caratteri(OCR) viene eseguito su di essi.
È qui che avviene la maggior parte della magia. L'estrazione dei dati viene solitamente eseguita da un modello di Machine Learning (ML). La maggior parte dei modelli ML utilizzati per l'estrazione dei dati dai PDF contiene una combinazione di strumenti di riconoscimento ottico dei caratteri, strumenti di riconoscimento di testo e pattern, ecc.
Ai fini di questo post, possiamo trattare il modello come una scatola nera che prende il tuo documento PDF come input e sputa le informazioni analizzate. Inoltre, poiché utilizza il machine learning al suo interno, può essere riqualificato con dati personalizzati per adattarsi al caso d'uso della tua azienda.
3. Post-elaborazione:
In questo passaggio, i dati estratti vengono convertiti nel formato richiesto come CSV, XML, JSON ecc. Inoltre, vengono aggiunte regole aggiuntive definite dall'utente oltre alle previsioni fatte dall'IA. Ciò potrebbe includere regole per la formattazione dell'output, vincoli aggiuntivi sulle informazioni estratte, ecc.
La sezione seguente esamina alcune metriche che potremmo utilizzare per misurare le prestazioni di un parser PDF.
Vuoi convertire PDF i file Fogli Google ? Check-out Nanonets ' "gratis" Convertitore da PDF a CSV. Scopri come automatizzare l'intero flusso di lavoro da PDF a Fogli Google con Nanonets.

Metriche per misurare le prestazioni di un convertitore PDF
Poiché la maggior parte dei convertitori PDF verrà utilizzata per l'elaborazione delle fatture o attività correlate, l'accuratezza e la velocità di estrazione della tabella da un documento PDF è un fattore critico nel giudicare le prestazioni del convertitore PDF.
2. Capacità multilingue:
La maggior parte delle grandi aziende è obbligata a ricevere fatture in diverse lingue. Il parser PDF dovrebbe supportare l'analisi multilingue pronta all'uso o dovrebbe fornire un'opzione con cui gli utenti possono addestrare il modello utilizzando dati personalizzati.
3. Integrazione con software di contabilità:
Il convertitore PDF ideale dovrebbe essere un modulo plug and play che può essere facilmente aggiunto a quello esistente flusso di lavoro del documento. Dovrebbe supportare l'integrazione con i software di contabilità più diffusi come QuickBooks, Xero, Wave ecc.
4. Facile e intuitivo:
Molto probabilmente lo strumento sarà utilizzato da utenti non tecnici. Sarebbe vantaggioso se può essere utilizzato con una conoscenza tecnica minima.
Vari metodi per convertire i PDF in fogli Google
1.Utilizzo di Google Documenti per convertire PDF in Fogli Google
Google Drive ha la capacità integrata di riconoscere tabelle e testo all'interno di semplici documenti PDF. Devi semplicemente:
-
Carica il tuo file PDF su Google Drive
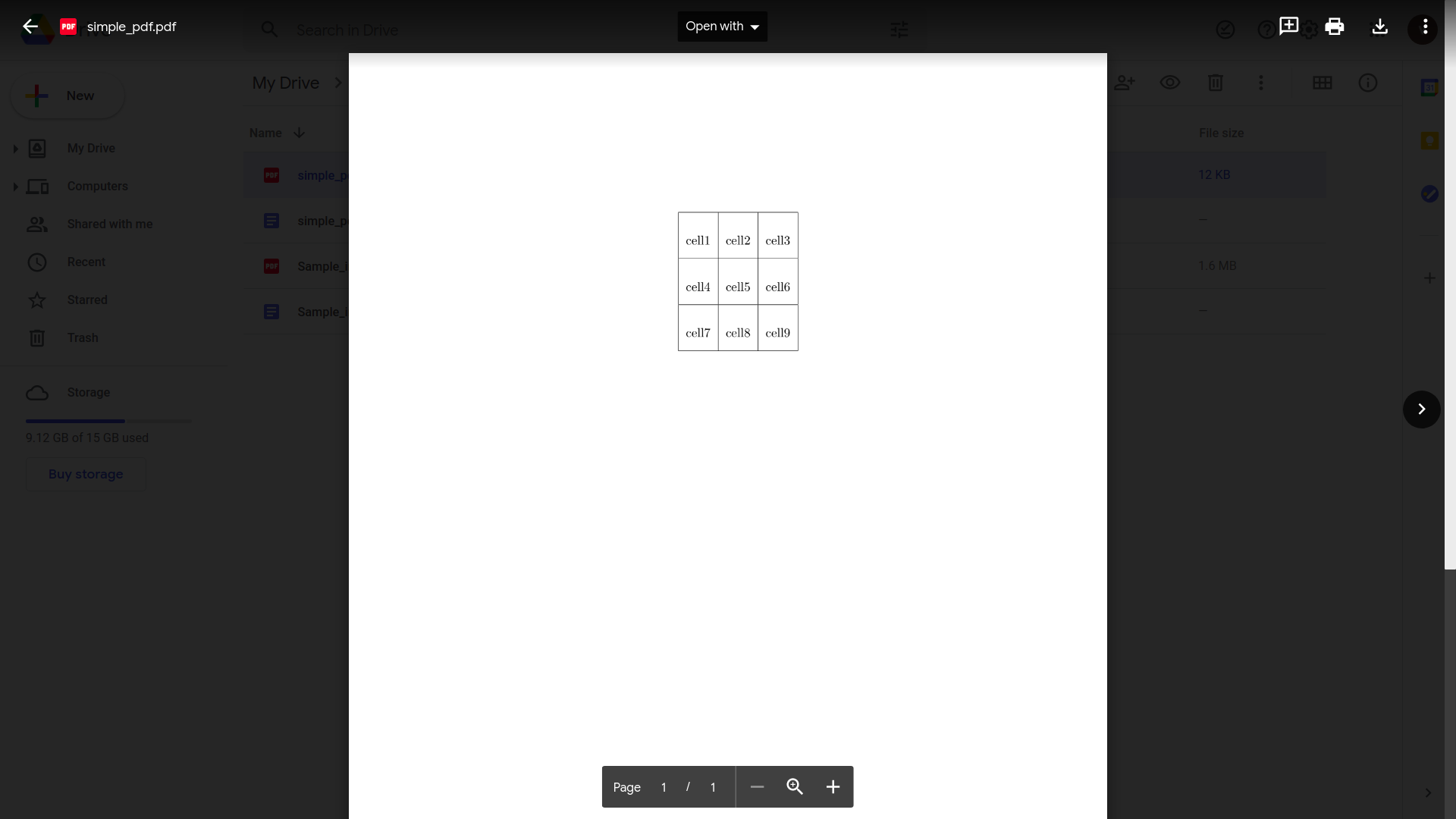
-
Fai clic su "Apri con Google Documenti"
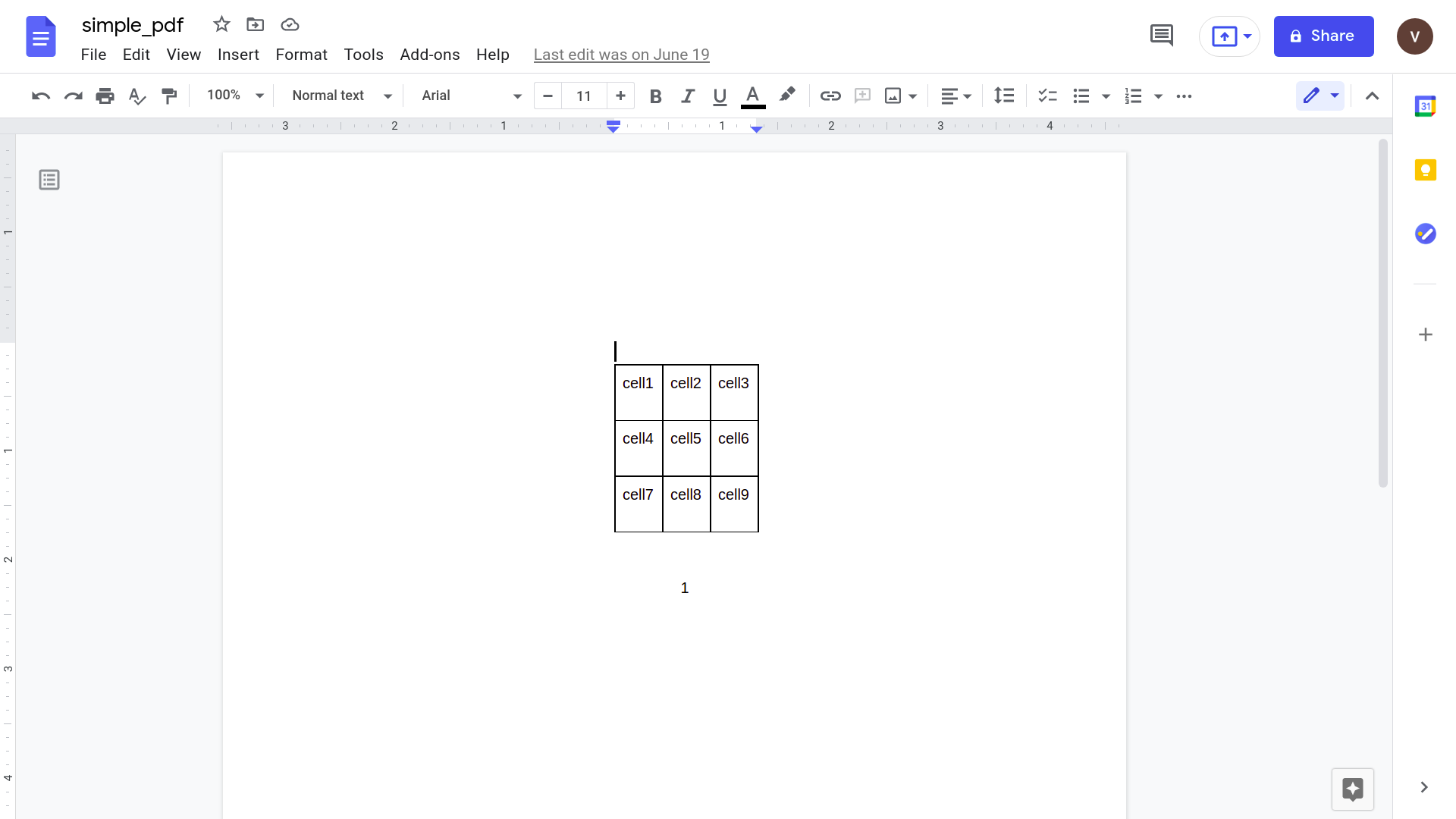
-
Copia i dati che desideri e incollali in Fogli Google
Anche se sembra funzionare bene, proviamo qualcosa di un po' più pratico. Considera questa semplice fattura.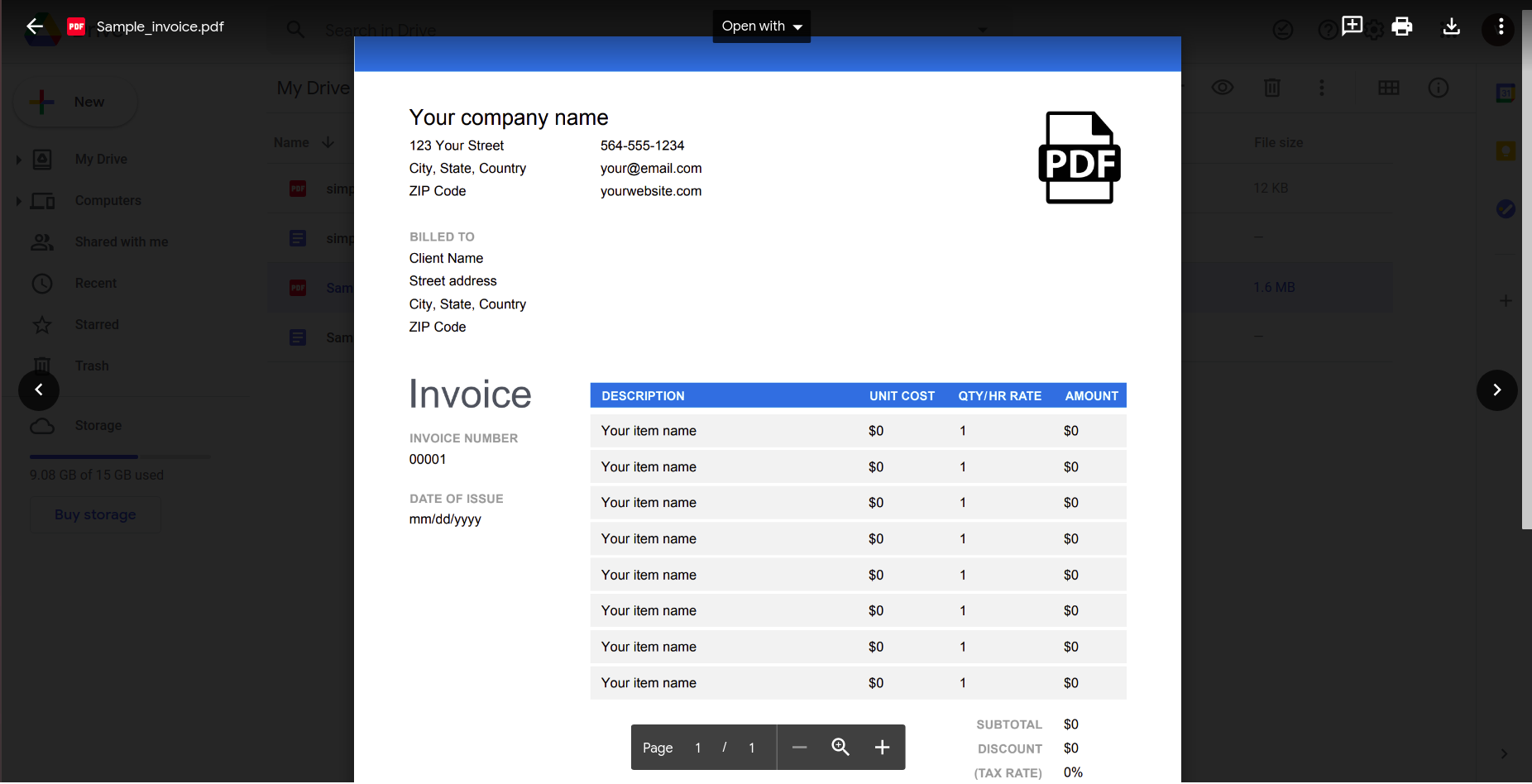
L'apertura di questo utilizzando l'applicazione Google Documenti dà il seguente risultato.
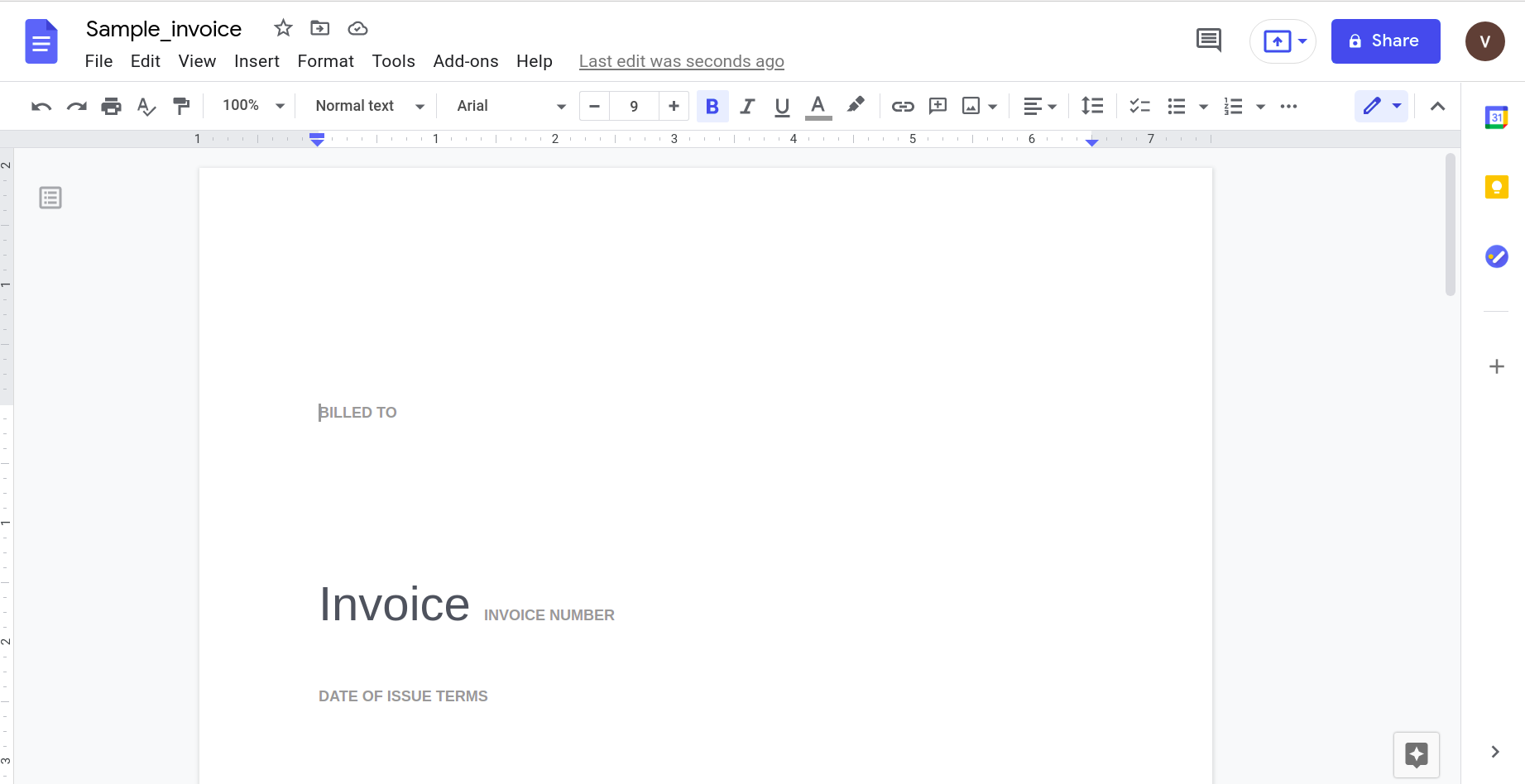
Chiaramente, all'aumentare della complessità del documento, occorre affidarsi a strumenti più sofisticati per il riconoscimento dei dati.
2. Utilizzo degli strumenti online:
Diversi strumenti online come l'estrattore di tabelle PDF, Online2PDF ecc., Si integrano direttamente con Google Drive e forniscono funzionalità pronte all'uso per convertire documenti PDF in Fogli Google.
Tuttavia, quando questi strumenti sono stati testati utilizzando il PDF della fattura di esempio mostrato sopra, nella maggior parte dei casi le tabelle non sono state rilevate.
Vuoi convertire PDF i file Fogli Google ? Check-out Nanonets ' "gratis" Convertitore da PDF a CSV. Scopri come automatizzare l'intero flusso di lavoro da PDF a Fogli Google con Nanonets, come mostrato di seguito.
Automatizzazione del processo di conversione da PDF a Fogli Google
Possiamo automatizzare completamente il processo di analisi del PDF ed estrazione dei dati in un modulo di Fogli Google utilizzando i seguenti strumenti.
1. Utilizzo dei webhook:
I webhook sono richieste HTTP personalizzate. Di solito vengono attivati su un evento, ovvero quando si verifica un evento, l'applicazione invia informazioni a un URL predefinito.
Come puoi usarlo per automatizzare il tuo flusso di lavoro? Consideriamo il caso d'uso tipico dell'elaborazione delle fatture. Ricevi una serie di fatture dai tuoi fornitori e le inserisci nel tuo convertitore da PDF a Fogli Google che risiede nel cloud. Come fai a sapere quando il modello ha terminato l'elaborazione dei documenti?
Invece di controllare manualmente se la conversione è stata completata, puoi semplicemente utilizzare un webhook che ti avvisa quando i dati nel PDF sono stati estratti in un documento di Fogli Google.
2. Utilizzo delle API
API è l'acronimo di Application Programming Interface. Utilizzando le chiamate API appropriate, convertire documenti PDF in Fogli Google potrebbe rivelarsi facile come scrivere le seguenti righe di codice:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Se la tua azienda ha già configurato l'integrazione con Webhooks, riceverai una notifica quando i tuoi documenti PDF sono stati convertiti con successo. Puoi quindi scaricare il modulo di Fogli Google utilizzando l'API mostrata di seguito.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
Da PDF a Fogli Google con Nanonet
Il parser PDF Nanonets rende l'analisi e la conversione facili e accurate. Il parser PDF è stato utilizzato per analizzare una fattura di esempio. Questa sezione dimostra la facilità d'uso e la precisione dello strumento. Piuttosto che parlare di quanto sia grande, le seguenti immagini illustrano appropriatamente il punto.
L'immagine mostrata di seguito è uno screenshot della fattura di esempio che è stata inviata al parser PDF Nanonets.
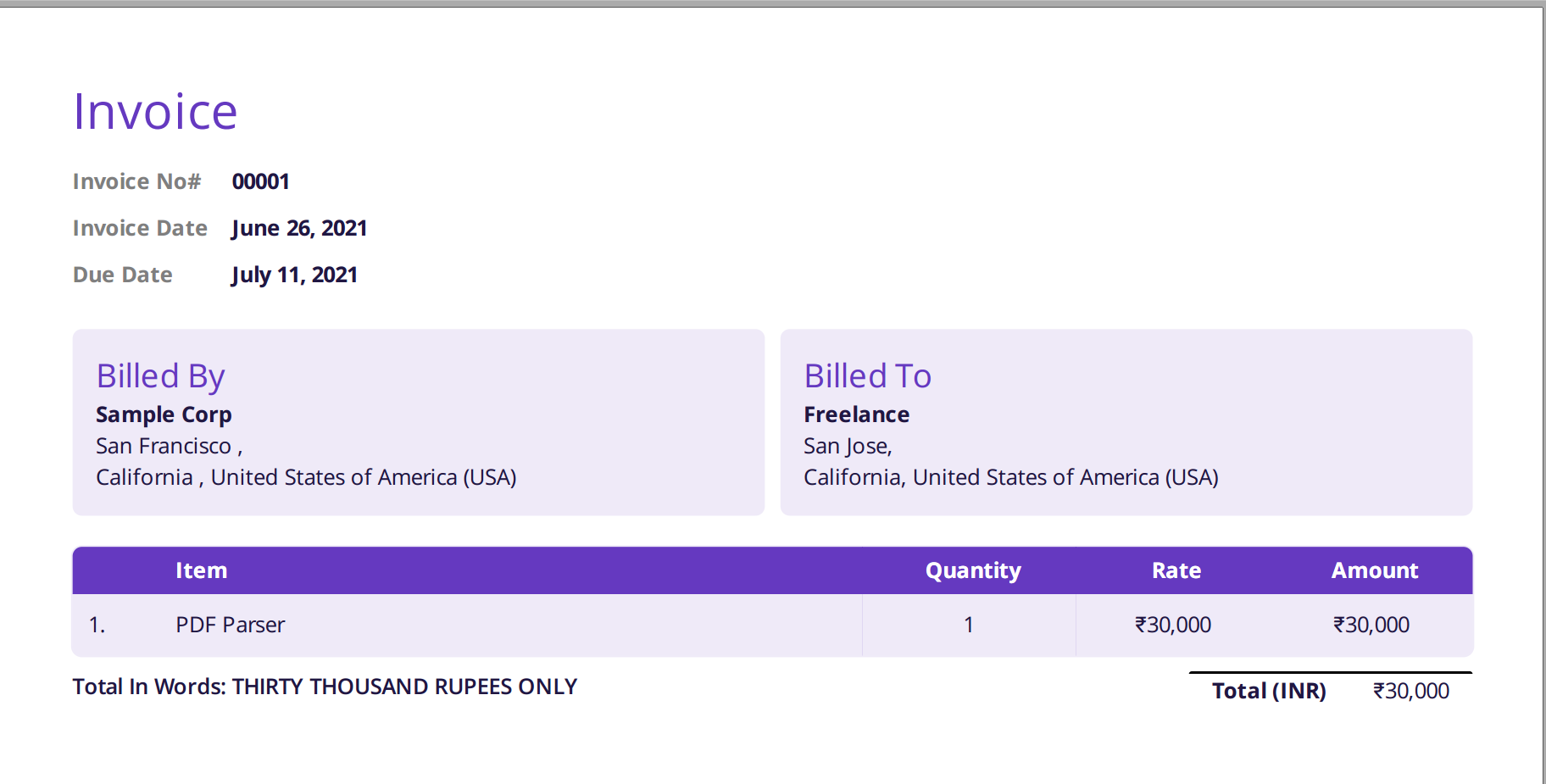
Accedi semplicemente al sito web di Nanonets e carica la fattura. La conversione richiede solo pochi secondi dopo i quali i dati analizzati possono essere scaricati in una varietà di formati come CSV, XLSX ecc. (controlla Nanonets' Convertitore da PDF a CSV)
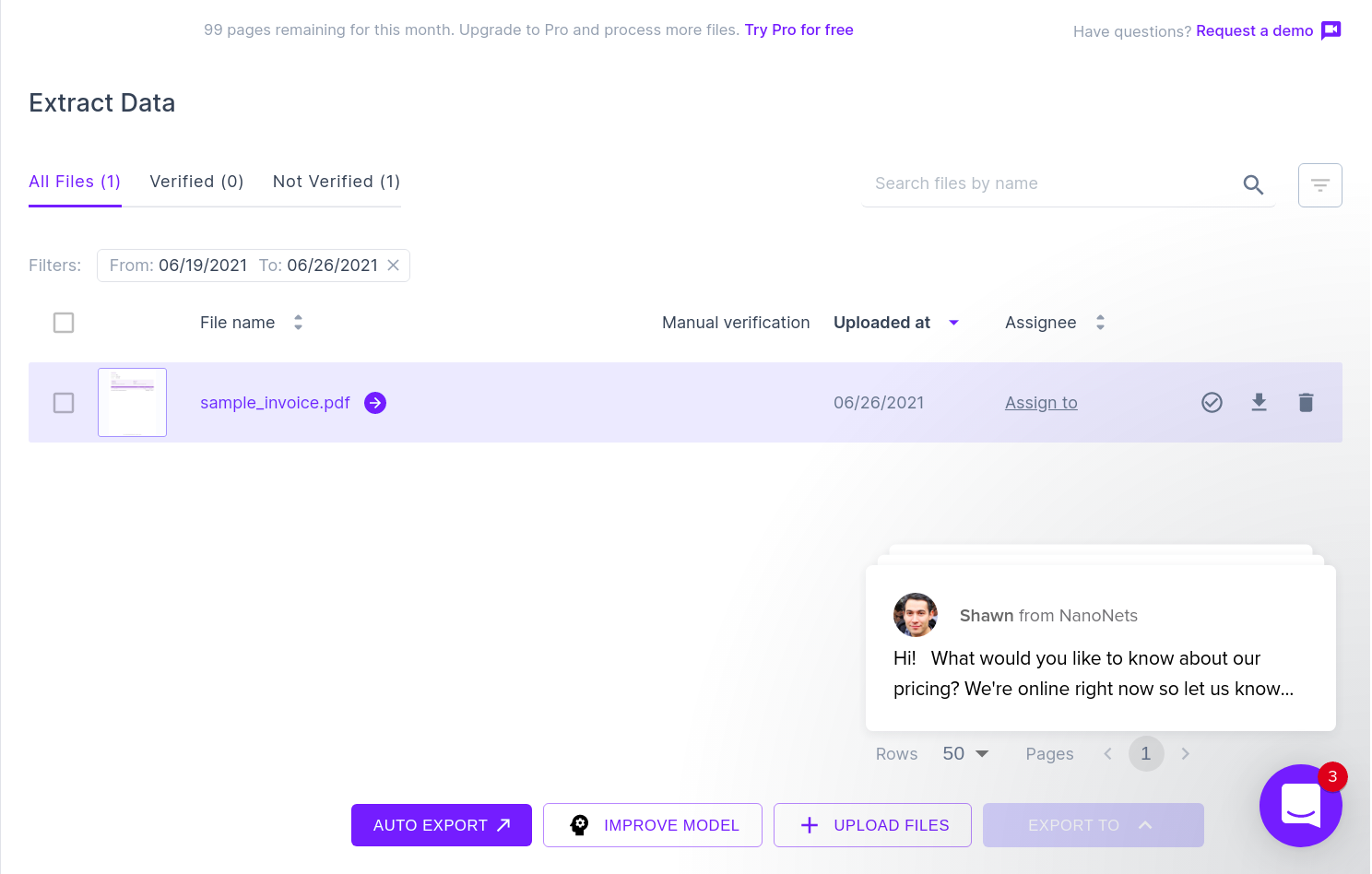
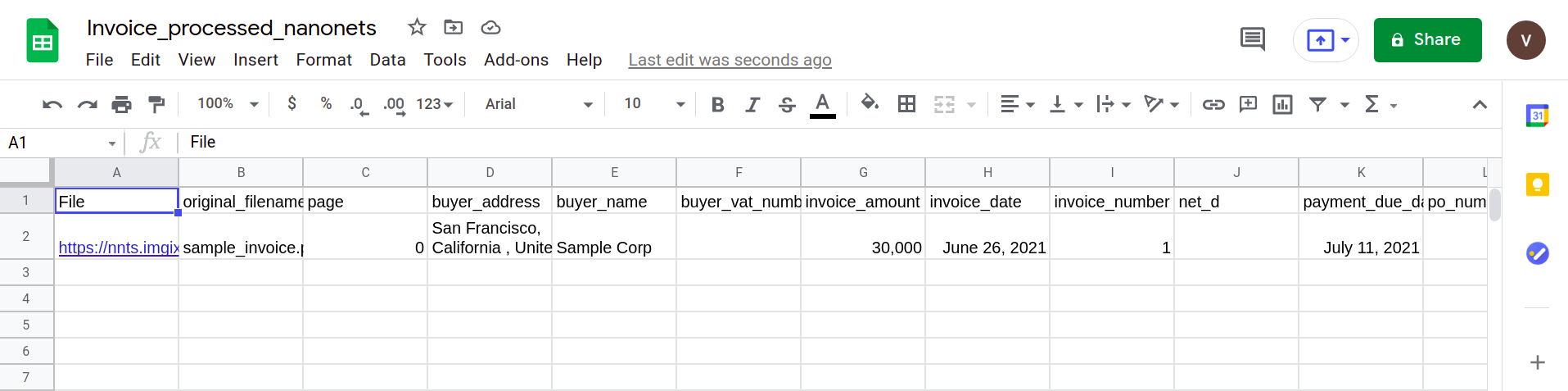
L'immagine successiva mostra uno screenshot del file CSV che contiene i dati analizzati dal documento PDF.

Infine, per convertire il file CSV in un modulo di fogli di Google, è semplicemente questione di caricare il file XLSX/CSV nel tuo Google Drive. Questo passaggio può essere automatizzato utilizzando le API di Google Drive.
La sezione seguente mostra come creare una semplice pipeline utilizzando il parser PDF Nanonets.
Vuoi estrarre informazioni da documenti PDF e convertirli/aggiungerli in un documento di Fogli Google? Dai un'occhiata ai nanonet™ per automatizzare l'esportazione di qualsiasi informazione da qualsiasi documento PDF in Fogli Google!
Creazione di una pipeline semplice
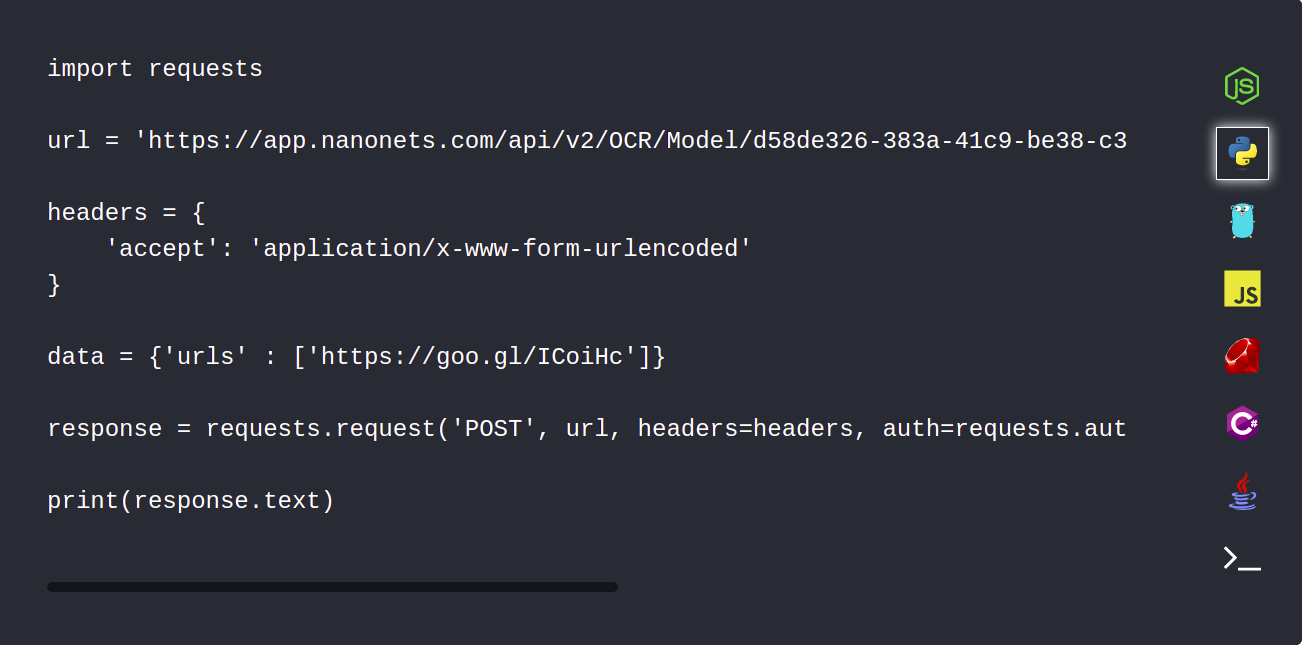
1. Carica automaticamente i tuoi documenti PDF utilizzando l'API Nanonets
L'API Nanonets ti consente di caricare automaticamente i tuoi documenti che devono essere analizzati. Il seguente frammento di codice mostra come questo può essere fatto usando python.
2. Utilizza l'integrazione dei webhook per ricevere una notifica al completamento dell'analisi
I webhook possono essere configurati per notificarti automaticamente una volta che i documenti sono stati analizzati.
3. Rivedi e carica su Fogli Google
Scarica ed esamina i file CSV per assicurarti che tutto sia in ordine e carica i dati su Fogli Google utilizzando l'API di Google Drive.
Il bordo delle nanonet
Ecco alcune caratteristiche del parser PDF Nanonets che lo rendono lo strumento ideale per la tua azienda.
1.Integrazioni esterne:
Il modello di nanonet può essere facilmente integrato con MySql, Quickbooks, Salesforce ecc. Ciò significa che il tuo flusso di lavoro attuale rimane indisturbato e il convertitore di nanonet può essere semplicemente collegato come modulo aggiuntivo.
2. Alta precisione e tempi di elaborazione ridotti:
Lo strumento parser PDF Nanonets ha una precisione di oltre il 95%+, che è molto più alta rispetto ai suoi concorrenti.
3. Fantastiche funzionalità di post-elaborazione:
Supponiamo che il tuo database sia stato integrato con il modello nanonets. Il modello compila automaticamente alcuni campi (con i dati del tuo database) in base ai dati estratti dal documento. Per esempio:
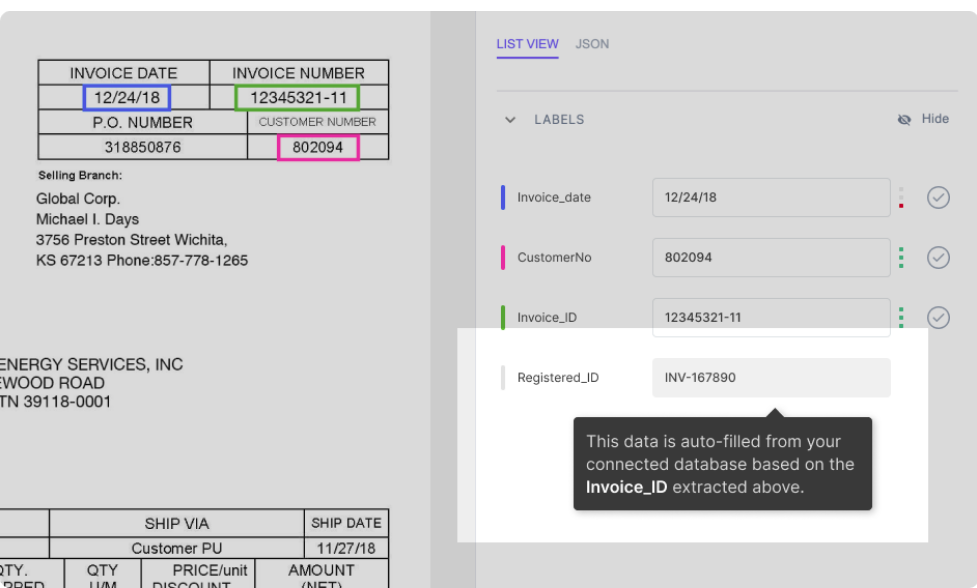
Come mostrato in figura, il campo Registered_ID viene compilato automaticamente (mediante una ricerca nel database) in base all'Invoice_ID che viene estratto dal PDF.
4. Interfaccia semplice e intuitiva
Sebbene questa funzione sia sottovalutata, ho trovato che l'interfaccia utente e l'esperienza utente fossero azzeccate. L'intero processo di registrazione, caricamento del documento e analisi dei dati ha richiesto meno di 5 minuti. È quasi uguale al tempo impiegato dal mio laptop per avviarsi!
5. Enorme base di clienti
Nel caso in cui hai ancora delle riserve sull'utilizzo di Nanonets per automatizzare il tuo flusso di lavoro, dai un'occhiata ad alcune delle aziende che utilizzano i loro servizi.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Vuoi estrarre informazioni da documenti PDF e convertirli/aggiungerli in un documento di Fogli Google? Dai un'occhiata ai nanonet™ per automatizzare l'esportazione di qualsiasi informazione da qualsiasi documento PDF in Fogli Google!
Conclusione
In questo post abbiamo esaminato come automatizzare il flusso di lavoro utilizzando un convertitore da PDF a Fogli Google. Inizialmente, abbiamo appreso della necessità di convertire documenti PDF in Fogli Google, seguite dalle sfide affrontate durante questo processo. Abbiamo quindi approfondito gli approcci adottati dai parser moderni per l'analisi dei documenti PDF e implementato anche alcuni degli approcci comuni. Abbiamo anche imparato come automatizzare completamente la conversione utilizzando integrazioni esterne come webhook e API. Infine, abbiamo utilizzato lo strumento Nanonets per analizzare una fattura di esempio, estraendo i dati in un modulo di Fogli Google e esplorando anche alcune delle sue fantastiche funzionalità di post-elaborazione.
Hai provato il modello Nanonets? In tal caso, lascia un commento qui sotto riguardo alla tua esperienza con lo strumento. In caso contrario, vai avanti e provalo. Potrebbe semplicemente rendere la tua giornata!
- AI
- AI e apprendimento automatico
- oh arte
- generatore d'arte
- un robot
- intelligenza artificiale
- certificazione di intelligenza artificiale
- intelligenza artificiale nel settore bancario
- robot di intelligenza artificiale
- robot di intelligenza artificiale
- software di intelligenza artificiale
- blockchain
- conferenza blockchain ai
- geniale
- intelligenza artificiale conversazionale
- criptoconferenza ai
- dall's
- apprendimento profondo
- google ai
- machine learning
- pdf a fogli google
- Platone
- platone ai
- Platone Data Intelligence
- Gioco di Platone
- PlatoneDati
- gioco di plato
- scala ai
- sintassi
- zefiro