Amazon RedShift è un data warehouse veloce, scalabile, sicuro e completamente gestito che ti consente di analizzare tutti i tuoi dati utilizzando SQL standard in modo semplice ed economico. Spostamento rosso Amazon Condivisione dei dati consente ai clienti di condividere in modo sicuro dati live e transazionali coerenti in un cluster Amazon Redshift con un altro cluster Amazon Redshift tra account e regioni senza dover copiare o spostare i dati da un cluster all'altro.
La condivisione dei dati di Amazon Redshift è stata inizialmente lanciata nel Marzo 2021ed è stato aggiunto il supporto per la condivisione dei dati tra account agosto 2021. Il supporto interregionale è diventato generalmente disponibile in Febbraio 2022. Ciò fornisce piena flessibilità e agilità per condividere i dati tra cluster Redshift nello stesso account AWS, account diversi o regioni diverse.
Amazon Redshift Data Sharing viene utilizzato per ridefinire radicalmente le architetture di distribuzione di Amazon Redshift in un modello di mesh di dati hub-spoke per soddisfare meglio gli SLA sulle prestazioni, fornire l'isolamento del carico di lavoro, eseguire analisi tra gruppi, inserire facilmente nuovi casi d'uso e, soprattutto, eseguire tutte le questo senza la complessità del movimento dei dati e delle copie dei dati. Alcune delle domande più comuni poste durante l'implementazione della condivisione dei dati sono: "Quanto dovrebbero essere grandi i cluster consumer e i cluster producer?" e "Come posso ottenere le migliori prestazioni in termini di prezzo per l'isolamento del carico di lavoro?". Poiché le caratteristiche del carico di lavoro come la dimensione dei dati, la velocità di acquisizione, il modello di query e le attività di manutenzione possono influire sulle prestazioni di condivisione dei dati, è necessario implementare una strategia continua per dimensionare i cluster di consumatori e produttori per massimizzare le prestazioni e ridurre al minimo i costi. In questo post, forniamo un approccio passo-passo per aiutarti a determinare le dimensioni dei cluster di produttori e consumatori per ottenere il miglior rapporto prezzo-prestazioni in base al tuo carico di lavoro specifico.
Guida generica alle taglie dei consumatori
I passaggi seguenti mostrano la strategia generica per dimensionare i cluster producer e consumer. Puoi usarlo come punto di partenza e modificarlo di conseguenza per soddisfare il tuo specifico scenario di caso d'uso.
Dimensiona il tuo cluster di produttori
Dovresti sempre assicurarti di dimensionare correttamente il tuo cluster producer per ottenere le prestazioni di cui hai bisogno per soddisfare il tuo SLA. Puoi sfruttare il calcolatore di dimensionamento dalla console di Amazon Redshift per ottenere una raccomandazione per il cluster produttore in base alla dimensione dei dati e alle caratteristiche della query. Cercare Aiutami a scegliere sulla console nelle regioni AWS che supportano i tipi di nodo RA3 per utilizzare questo calcolatore di dimensionamento. Tieni presente che questa è solo una raccomandazione iniziale per iniziare e dovresti testare l'esecuzione del carico di lavoro completo sul cluster di dimensioni iniziali e ridimensionare elasticamente il cluster su e giù di conseguenza per ottenere le migliori prestazioni in termini di prezzo.
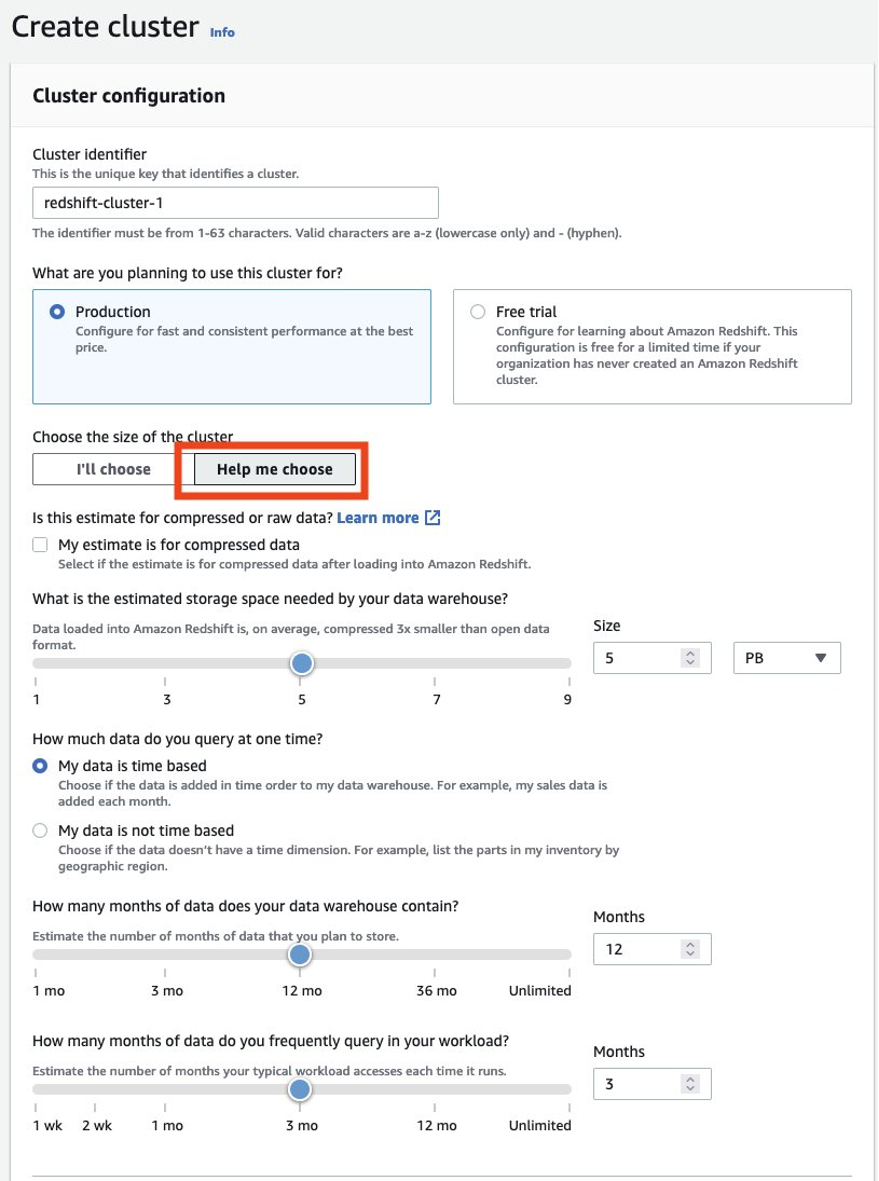
Dimensioni e configurazione del cluster di consumatori iniziale
Dovresti sempre dimensionare il tuo cluster consumer in base alle tue esigenze di calcolo. Un modo per iniziare è seguire la guida al dimensionamento del cluster generico simile al cluster produttore sopra.
Configura la condivisione dei dati di Amazon Redshift
Imposta la condivisione dei dati dal produttore al consumatore una volta che hai impostato sia il produttore che il cluster del consumatore. Fare riferimento a questo settimana per indicazioni su come configurare la condivisione dei dati.
Testare solo il carico di lavoro consumer sul cluster consumer iniziale
Testare solo il carico di lavoro consumer sul nuovo cluster consumer iniziale. Questa operazione può essere eseguita puntando le applicazioni consumer, ad esempio strumenti ETL, applicazioni BI e client SQL, al nuovo cluster consumer ed rieseguendo il carico di lavoro per valutare le prestazioni rispetto ai requisiti.
Testare solo il carico di lavoro consumer su diverse configurazioni di cluster consumer
Se il cluster di consumer di dimensioni iniziali soddisfa o supera i requisiti di prestazioni del carico di lavoro, puoi continuare a utilizzare questa configurazione del cluster o testare configurazioni più piccole per vedere se puoi ridurre ulteriormente i costi e ottenere comunque le prestazioni di cui hai bisogno.
D'altra parte, se il cluster consumer di dimensioni iniziali non soddisfa i requisiti di prestazioni del carico di lavoro, è possibile testare ulteriormente configurazioni più grandi per ottenere la configurazione che soddisfa il contratto di servizio.
Come regola generale, dimensiona il cluster consumer di 2 volte la configurazione iniziale del cluster in modo incrementale finché non soddisfa i requisiti del carico di lavoro.
Una volta pianificata la configurazione da testare, usa il ridimensionamento elastico per ridimensionare il cluster iniziale alla configurazione del cluster di destinazione. Dopo aver completato il ridimensionamento elastico, eseguire lo stesso test del carico di lavoro e valutare le prestazioni rispetto al contratto di servizio. Seleziona la configurazione che soddisfa il tuo obiettivo di rendimento dei prezzi.
Testare solo il carico di lavoro producer su diverse configurazioni del cluster producer
Dopo aver spostato il carico di lavoro del consumatore nel cluster del consumatore con il rapporto prezzo/prestazioni ottimale, potrebbe esserci l'opportunità di ridurre la risorsa di calcolo sul produttore per risparmiare sui costi.
Per raggiungere questo obiettivo, è possibile eseguire nuovamente il carico di lavoro del solo produttore su 1/2x della dimensione originale del produttore e valutare le prestazioni del carico di lavoro. Il ridimensionamento del cluster verso l'alto e verso il basso di conseguenza dipende dal risultato, quindi si seleziona la configurazione minima del produttore che soddisfa i requisiti di prestazioni del carico di lavoro.
Rivalutare dopo un carico di lavoro completo eseguito nel tempo
Man mano che Amazon Redshift continua a evolversi e ci sono continui miglioramenti delle prestazioni e della scalabilità, le prestazioni di condivisione dei dati continueranno a migliorare. Inoltre, numerose variabili potrebbero influire sulle prestazioni delle query di condivisione dei dati. I seguenti sono solo alcuni esempi:
- La velocità di importazione e la quantità di dati cambiano
- Modello e caratteristica della query
- Cambiamenti del carico di lavoro
- Concorrenza
- Attività di manutenzione, ad esempio vuoto, analisi e ATO
Questo è il motivo per cui è necessario rivalutare occasionalmente il dimensionamento del cluster producer e consumer utilizzando la strategia di cui sopra, in particolare dopo una distribuzione completa del carico di lavoro, per ottenere le nuove migliori prestazioni in termini di prezzo dalla configurazione del cluster.
Soluzioni di dimensionamento automatizzate
Se il tuo ambiente prevede un'architettura più complessa, ad esempio con più strumenti o applicazioni (BI, importazione o streaming, ETL, data science), potrebbe non essere possibile utilizzare il metodo manuale dalla guida generica precedente. Invece, puoi sfruttare le soluzioni in questa sezione per riprodurre automaticamente il carico di lavoro dal tuo cluster di produzione sui cluster consumer e producer di test per valutare le prestazioni.
Semplice utilità di riproduzione verrà sfruttato come soluzione automatizzata per guidarti attraverso il processo per ottenere la giusta dimensione dei cluster di produttori e consumatori per il miglior rapporto qualità-prezzo.
Simple Replay è uno strumento per condurre un'analisi what-if e valutare le prestazioni del carico di lavoro in diversi scenari. Ad esempio, puoi utilizzare lo strumento per confrontare il tuo carico di lavoro effettivo su un nuovo tipo di istanza come RA3, valutare una nuova funzionalità o valutare diverse configurazioni del cluster. Include inoltre un supporto avanzato per la riproduzione di pipeline di importazione ed esportazione di dati con le istruzioni COPY e UNLOAD. Per iniziare e riprodurre i tuoi carichi di lavoro, scarica lo strumento dal Repository GitHub di Amazon Redshift.
Qui esaminiamo i passaggi per estrarre i log del carico di lavoro dal cluster di produzione di origine e riprodurli in un ambiente isolato. Ciò ti consente di eseguire un confronto diretto tra questi cluster Amazon Redshift senza soluzione di continuità e di selezionare la configurazione dei cluster che meglio soddisfa il tuo obiettivo di prezzo/prestazioni.
Il diagramma seguente mostra l'architettura della soluzione.
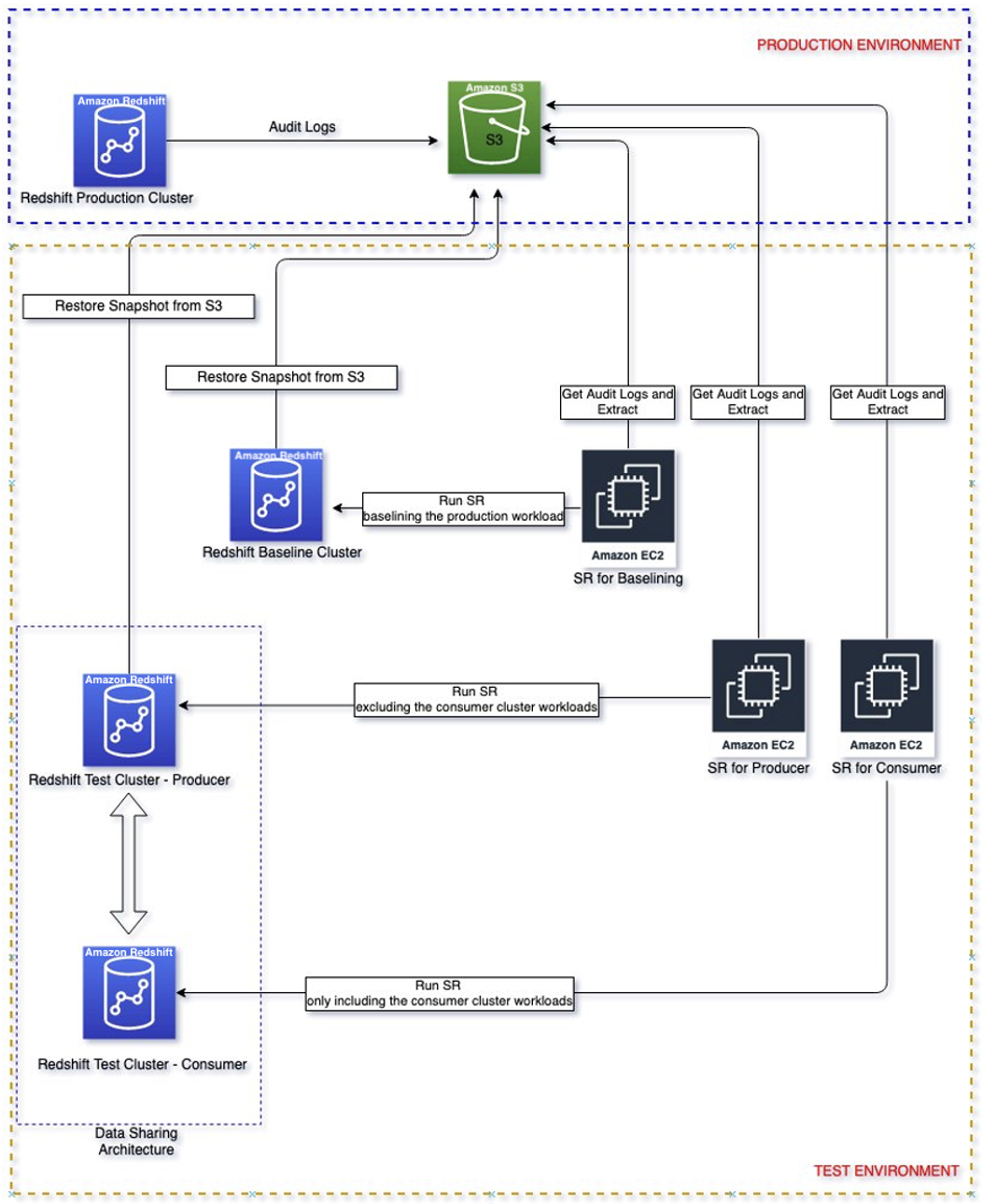
Soluzione dettagliata
Segui questi passaggi per passare attraverso la soluzione per dimensionare i tuoi cluster di consumatori e produttori.
Dimensiona il tuo cluster di produzione
Dovresti sempre assicurarti di dimensionare correttamente il tuo cluster di produzione esistente per ottenere le prestazioni necessarie per soddisfare i requisiti del tuo carico di lavoro. Puoi sfruttare il calcolatore di dimensionamento dalla console di Amazon Redshift per ottenere una raccomandazione sul cluster di produzione in base alla dimensione dei dati e alle caratteristiche della query. Cercare Aiutami a scegliere sulla console nelle regioni AWS che supportano i tipi di nodo RA3 per utilizzare questo calcolatore di dimensionamento. Tieni presente che questa è solo una raccomandazione iniziale per iniziare. È necessario testare l'esecuzione del carico di lavoro completo sul cluster di dimensioni iniziali e ridimensionare elasticamente il cluster su e giù di conseguenza per ottenere le migliori prestazioni in termini di prezzo.
Identificare il carico di lavoro da isolare
Potresti avere diversi carichi di lavoro in esecuzione sul tuo cluster originale, ma il primo passaggio consiste nell'identificare il carico di lavoro più critico per l'azienda che desideriamo isolare. Questo perché vogliamo assicurarci che la nuova architettura possa soddisfare i requisiti del tuo carico di lavoro. Questo settimana è un buon riferimento su un caso d'uso di isolamento del carico di lavoro per la condivisione dei dati che può aiutarti a decidere quale carico di lavoro può essere isolato.
Imposta la riproduzione semplice
Una volta che conosci il tuo carico di lavoro critico, devi farlo abilitare la registrazione di controllo nel cluster di produzione in cui è in esecuzione il carico di lavoro critico identificato in precedenza per acquisire le attività di query e memorizzarle Amazon Simple Storage Service (Amazon S3). Tieni presente che potrebbero essere necessarie fino a tre ore per la consegna dei log di controllo ad Amazon S3. Una volta che il registro di controllo è disponibile, procedere a impostare Replay semplice e poi estratto il carico di lavoro critico dal registro di controllo. Tieni presente che start_time e end_time possono essere utilizzati come parametri per filtrare il carico di lavoro critico se tali carichi di lavoro vengono eseguiti in determinati periodi di tempo, ad esempio dalle 9:11 alle XNUMX:XNUMX. Altrimenti estrarrà tutte le attività registrate.
Carico di lavoro di base
Crea un cluster di base con la stessa configurazione del cluster producer eseguendo il ripristino dallo snapshot di produzione. Lo scopo di iniziare con la stessa configurazione è basare le prestazioni con un ambiente isolato.
Una volta che il cluster di base sarà disponibile, ripetere il carico di lavoro estratto nel cluster di base. L'output di questo replay sarà la linea di base utilizzata per il confronto con i successivi replay su diverse configurazioni dei consumatori.
Configurare i cluster di test produttore e consumatore iniziali
Crea un cluster produttore con la stessa configurazione del cluster di produzione eseguendo il ripristino dallo snapshot di produzione. Crea un cluster di consumatori con la dimensione del consumatore iniziale consigliata dalla guida precedente. Inoltre, imposta la condivisione dei dati tra il produttore e il consumatore.
Riproduci il carico di lavoro sul produttore e sul consumatore iniziali
Replay solo il carico di lavoro producer sul cluster producer di dimensioni iniziali. Ciò può essere ottenuto utilizzando il parametro del filtro "Escludi" per escludere le query dei consumatori, ad esempio l'utente che esegue le query dei consumatori.
Replay solo il carico di lavoro consumer sul cluster consumer di dimensione iniziale. Ciò può essere ottenuto utilizzando il parametro del filtro "Includi" per escludere le query dei consumatori, ad esempio l'utente che esegue le query dei consumatori.
Valuta le prestazioni di questi replay rispetto ai requisiti di prestazioni di base e del carico di lavoro.
Riproduci il carico di lavoro del consumatore su diverse configurazioni
Se il cluster di consumer di dimensioni iniziali soddisfa o supera i requisiti di prestazioni del carico di lavoro, puoi utilizzare questa configurazione del cluster oppure puoi seguire questi passaggi per testare configurazioni più piccole per vedere se puoi ridurre ulteriormente i costi e ottenere comunque le prestazioni di cui hai bisogno.
Confronta i risultati iniziali delle prestazioni del consumatore con i requisiti del tuo carico di lavoro:
- Se il risultato supera i requisiti di prestazioni del tuo carico di lavoro, puoi ridurre la dimensione del cluster consumer in modo incrementale, a partire da 1/2x, riprovare la riproduzione e valutare le prestazioni, quindi ridimensionare verso l'alto o verso il basso di conseguenza in base al risultato finché non soddisfa il tuo carico di lavoro requisiti. Lo scopo è quello di ottenere un punto debole in cui ti senti a tuo agio con i requisiti di prestazione e ottenere il prezzo più basso possibile.
- Se il risultato non soddisfa i requisiti delle prestazioni del carico di lavoro, è possibile aumentare la dimensione del cluster in modo incrementale, iniziando con il doppio della dimensione originale, riprovare la riproduzione e valutare le prestazioni fino a quando non soddisfa i requisiti delle prestazioni del carico di lavoro.
Riproduci il carico di lavoro del produttore su diverse configurazioni
Dopo aver suddiviso i carichi di lavoro in cluster consumer, il carico sul cluster producer dovrebbe essere ridotto e dovresti valutare le prestazioni del carico di lavoro del tuo cluster producer per cercare l'opportunità di ridurre le dimensioni per risparmiare sui costi.
I passaggi sono simili al replay del consumatore. Elastic ridimensiona il cluster producer in modo incrementale a partire da 1/2 volte la dimensione originale, riproduci solo il carico di lavoro producer e valuta le prestazioni, quindi ridimensiona ulteriormente verso l'alto o verso il basso finché non soddisfa i requisiti di prestazioni del carico di lavoro. Lo scopo è ottenere un punto ottimale in cui ti senti a tuo agio con i requisiti di prestazioni del carico di lavoro e ottenere il prezzo più basso possibile. Una volta ottenuta la configurazione del cluster produttore desiderata, riprova a riprodurre i carichi di lavoro del consumatore sul cluster consumatore per assicurarti che le prestazioni non siano state influenzate dalle modifiche alla configurazione del cluster produttore. Infine, dovresti riprodurre contemporaneamente sia i carichi di lavoro producer che consumer per assicurarti che le prestazioni vengano raggiunte in uno scenario di carico di lavoro completo.
Rivalutare dopo un carico di lavoro completo eseguito nel tempo
Analogamente alle linee guida generiche, è necessario rivalutare occasionalmente il dimensionamento dei cluster producer e consumer utilizzando la strategia precedente, in particolare dopo la distribuzione completa del carico di lavoro per ottenere le nuove migliori prestazioni in termini di prezzo dalla configurazione del cluster.
ripulire
L'esecuzione di questi test di dimensionamento nel tuo account AWS può avere implicazioni sui costi perché fornisce nuovi cluster Amazon Redshift, che possono essere addebitati come istanze on demand se non disponi di istanze riservate. Quando completi le valutazioni, ti consigliamo di eliminare i cluster Amazon Redshift per risparmiare sui costi. Ti consigliamo inoltre di mettere in pausa i cluster quando non sono in uso.
Applicazione di Amazon Redshift e best practice per la condivisione dei dati
Il corretto dimensionamento dei tuoi cluster producer e consumer ti darà un buon inizio per ottenere il miglior rapporto prezzo/prestazioni dalla tua distribuzione Amazon Redshift. Tuttavia, il dimensionamento non è l'unico fattore che può massimizzare le tue prestazioni. In questo caso, la comprensione e il rispetto delle migliori pratiche sono ugualmente importanti.
Le best practice generali per l'ottimizzazione delle prestazioni di Amazon Redshift sono applicabili alla distribuzione della condivisione dei dati. Assicurati che la tua distribuzione segua questi best practice.
Esistono numerosi dati che condividono best practice specifiche che dovresti seguire per assicurarti di massimizzare le prestazioni. Fare riferimento a questo settimana per ulteriori dettagli.
Sommario
Non esiste una raccomandazione valida per tutti sulle dimensioni dei cluster di produttori e consumatori. Varia in base ai carichi di lavoro e al contratto di servizio sulle prestazioni. Lo scopo di questo post è fornire indicazioni su come valutare le prestazioni del carico di lavoro di condivisione dei dati specifici per determinare le dimensioni dei cluster di consumatori e produttori per ottenere le migliori prestazioni in termini di prezzo. Prendi in considerazione la possibilità di testare i tuoi carichi di lavoro su produttore e consumatore utilizzando un semplice replay prima di adottarlo in produzione per ottenere il miglior rapporto prezzo/prestazioni.
Informazioni sugli autori
 BP Yau è Senior Product Manager presso AWS. È appassionato di aiutare i clienti a progettare soluzioni per big data per elaborare i dati su larga scala. Prima di AWS, ha aiutato Amazon.com Supply Chain Optimization Technologies a migrare il suo data warehouse Oracle su Amazon Redshift e costruire la sua piattaforma di analisi dei big data di nuova generazione utilizzando le tecnologie AWS.
BP Yau è Senior Product Manager presso AWS. È appassionato di aiutare i clienti a progettare soluzioni per big data per elaborare i dati su larga scala. Prima di AWS, ha aiutato Amazon.com Supply Chain Optimization Technologies a migrare il suo data warehouse Oracle su Amazon Redshift e costruire la sua piattaforma di analisi dei big data di nuova generazione utilizzando le tecnologie AWS.
 Sidhanth Muralidhar è Principal Technical Account Manager presso AWS. Lavora con grandi clienti aziendali che eseguono i loro carichi di lavoro su AWS. È appassionato di lavorare con i clienti e di aiutarli a progettare carichi di lavoro per costi, affidabilità, prestazioni ed eccellenza operativa su larga scala nel loro percorso verso il cloud. Ha anche un vivo interesse per l'analisi dei dati.
Sidhanth Muralidhar è Principal Technical Account Manager presso AWS. Lavora con grandi clienti aziendali che eseguono i loro carichi di lavoro su AWS. È appassionato di lavorare con i clienti e di aiutarli a progettare carichi di lavoro per costi, affidabilità, prestazioni ed eccellenza operativa su larga scala nel loro percorso verso il cloud. Ha anche un vivo interesse per l'analisi dei dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Chi siamo
- sopra
- di conseguenza
- Il mio account
- conti
- Raggiungere
- raggiunto
- operanti in
- attività
- aggiunto
- Adottando
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- Tutti
- consente
- sempre
- Amazon
- Amazon.com
- quantità
- .
- analitica
- analizzare
- ed
- Un altro
- applicabile
- applicazioni
- approccio
- architettura
- revisione
- Automatizzata
- automaticamente
- disponibile
- AWS
- basato
- Linea di base
- perché
- prima
- Segno di riferimento
- MIGLIORE
- best practice
- Meglio
- fra
- Big
- Big Data
- costruire
- affari
- catturare
- Custodie
- casi
- certo
- catena
- Modifiche
- caratteristica
- caratteristiche
- carico
- clienti
- Cloud
- Cluster
- COM
- confortevole
- Uncommon
- confrontare
- confronto
- completamento di una
- Completato
- complesso
- complessità
- Calcolare
- conduzione
- Configurazione
- Prendere in considerazione
- coerente
- consolle
- Consumer
- continua
- continua
- continuo
- Costo
- Costi
- potuto
- creare
- critico
- Clienti
- dati
- Dati Analytics
- scienza dei dati
- condivisione dei dati
- consegnato
- dipende
- deployment
- dettagli
- Determinare
- diverso
- dirette
- Dont
- giù
- scaricare
- durante
- facilmente
- o
- Abilita
- migliorata
- Impresa
- Ambiente
- Allo stesso modo
- particolarmente
- Etere (ETH)
- valutare
- valutazioni
- evoluzione
- esempio
- Esempi
- supera
- Eccellenza
- esistente
- export
- estratto
- fallisce
- FAST
- fattibile
- caratteristica
- filtro
- Infine
- Nome
- Flessibilità
- seguire
- i seguenti
- segue
- da
- pieno
- fondamentalmente
- ulteriormente
- Inoltre
- Guadagno
- generalmente
- ELETTRICA
- ottenere
- ottenere
- GitHub
- Dare
- Go
- buono
- guida
- Aiuto
- aiutato
- aiutare
- ORE
- Come
- Tutorial
- Tuttavia
- HTTPS
- identificato
- identificare
- Impact
- impattato
- implementato
- implicazioni
- importante
- miglioramento
- miglioramento
- in
- inclusi
- Aumento
- inizialmente
- inizialmente
- esempio
- invece
- interesse
- coinvolto
- isolato
- da solo
- IT
- viaggio
- Acuto
- Sapere
- grandi
- superiore, se assunto singolarmente.
- lanciato
- Consente di
- Leva
- vivere
- caricare
- Guarda
- manutenzione
- make
- direttore
- Manuale
- Massimizzare
- Soddisfare
- Soddisfa
- metodo
- forza
- migrare
- ordine
- modello
- Scopri di più
- maggior parte
- cambiano
- movimento
- multiplo
- Bisogno
- che necessitano di
- esigenze
- New
- GENERAZIONE
- nodo
- numerose
- occasione
- Onboard
- ONE
- operativa
- Opportunità
- ottimizzazione
- ottimale
- oracolo
- i
- Altro
- altrimenti
- parametro
- parametri
- appassionato
- Cartamodello
- eseguire
- performance
- esegue
- periodi
- piano
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- possibile
- Post
- pratiche
- precedente
- prezzo
- Direttore
- processi
- produttore
- Prodotto
- product manager
- Produzione
- propriamente
- fornire
- fornisce
- scopo
- Domande
- tasso
- raccomandare
- Consigli
- raccomandato
- ridurre
- Ridotto
- regioni
- Uscite
- problemi di
- Requisiti
- riservato
- risorsa
- il ripristino
- colpevole
- Risultati
- Regola
- Correre
- running
- stesso
- Risparmi
- Scalabilità
- scalabile
- Scala
- Scenari
- Scienze
- senza soluzione di continuità
- Sezione
- sicuro
- in modo sicuro
- Cercare
- servizio
- flessibile.
- Condividi
- compartecipazione
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- simile
- Un'espansione
- Taglia
- Dimensioni
- inferiore
- Istantanea
- soluzione
- Soluzioni
- alcuni
- Fonte
- specifico
- dividere
- Spot
- Standard
- inizia a
- iniziato
- Di partenza
- dichiarazioni
- step
- Passi
- Ancora
- conservazione
- Tornare al suo account
- Strategia
- Streaming
- successivo
- fornire
- supply chain
- Ottimizzazione della catena di fornitura
- supporto
- dolce
- Fai
- Target
- Consulenza
- Tecnologie
- test
- Testing
- test
- I
- L’ORIGINE
- loro
- tre
- Attraverso
- tempo
- a
- strumenti
- Tipi di
- e una comprensione reciproca
- uso
- caso d'uso
- Utente
- Vuoto
- Che
- quale
- OMS
- volere
- senza
- lavoro
- lavori
- Trasferimento da aeroporto a Sharm
- zefiro