Questo è un guest post scritto insieme a Raghu Boppanna di Vanguard.
At Avanguardia, la linea di business Consulenza aziendale migliora i risultati degli investitori attraverso l'accesso digitale a una consulenza finanziaria superiore, personalizzata e conveniente. Lo hanno reso possibile, in parte, promuovendo economie di scala in tutto il mondo per gli investitori con una piattaforma tecnica altamente resiliente ed efficiente. Vanguard ha optato per un'architettura multi-regione per questo carico di lavoro per aiutare a proteggere dai problemi dei servizi regionali. Per motivi di disponibilità elevata, è necessario rendere disponibili i dati utilizzati dal carico di lavoro non solo nella regione primaria, ma anche nella regione secondaria con un ritardo di replica minimo. In caso di compromissione del servizio nella regione primaria, la soluzione dovrebbe essere in grado di eseguire il failover nella regione secondaria con la minima perdita di dati possibile e la possibilità di riprendere l'inserimento dei dati.
Vanguard Cloud Technology Office e AWS hanno collaborato per creare una soluzione di infrastruttura su AWS che soddisfacesse i loro requisiti di resilienza. La soluzione multi-regione abilita un robusto meccanismo di failover, con osservabilità e ripristino integrati. La soluzione supporta anche lo streaming di dati da più origini a diversi flussi di dati Kinesis. La soluzione è attualmente in fase di implementazione alle diverse linee di team aziendali per migliorare la posizione di resilienza dei loro carichi di lavoro.
Il caso d'uso discusso qui richiede Change Data Capture (CDC) per lo streaming di dati da un'origine dati remota (mainframe DB2) a Flussi di dati di Amazon Kinesis, perché la capacità aziendale dipende da questi dati. Kinesis Data Streams è un servizio di streaming completamente gestito, altamente scalabile, duraturo ea basso costo che può acquisire e trasmettere continuamente grandi quantità di dati da più fonti e rende i dati disponibili per il consumo in pochi millisecondi. Il servizio è progettato per essere altamente resiliente e utilizza più zone di disponibilità per elaborare e archiviare i dati.
La soluzione discussa in questo post spiega come AWS e Vanguard hanno innovato per costruire un'architettura resiliente per raggiungere i loro obiettivi di alta disponibilità.
Panoramica della soluzione
La soluzione usa AWS Lambda per replicare i dati dai flussi di dati Kinesis nella regione primaria a una regione secondaria. In caso di problemi di servizio che incidono sulla pipeline CDC, il processo di failover promuove la regione secondaria a primaria per produttori e consumatori. Noi usiamo Tabelle globali di Amazon DynamoDB per i checkpoint di replica che consente di riprendere il flusso di dati dal checkpoint e mantiene anche un flag di configurazione della regione primaria che impedisce un ciclo di replica infinito degli stessi dati avanti e indietro.
La soluzione offre inoltre ai consumatori Kinesis Data Streams la flessibilità di utilizzare la regione primaria o qualsiasi regione secondaria all'interno dello stesso account AWS.
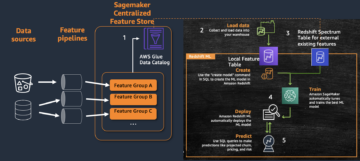
Il diagramma seguente illustra l'architettura di riferimento.
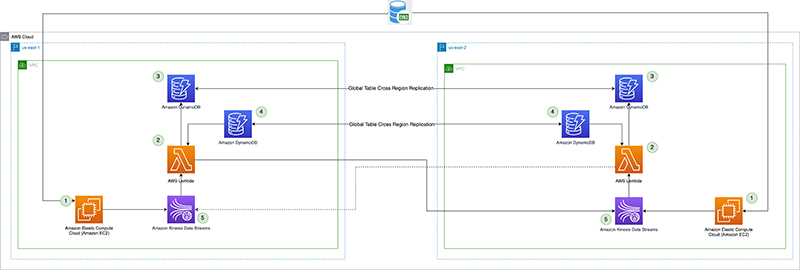
Vediamo nel dettaglio ogni componente:
- Processore CDC (produttore) – In questa architettura di riferimento, viene distribuito il producer Cloud di calcolo elastico di Amazon (Amazon EC2) sia nella regione primaria che in quella secondaria, ed è attivo nella regione primaria e in modalità standby nella regione secondaria. Cattura i dati CDC dall'origine dati esterna (come un database DB2 come mostrato nell'architettura precedente) e li trasmette a Kinesis Data Streams nella regione primaria. Vanguard usa un 3rd party tool Qlik Replicate come processore CDC. Produce un payload ben formato che include il timestamp del commit DB2 nel flusso di dati Kinesis, oltre ai dati di riga effettivi dall'origine dati remota. (
example-stream-1in questo esempio). Il codice seguente è un payload di esempio contenente solo la chiave primaria del record che è stato modificato e il timestamp del commit (per semplicità, il resto dei dati della riga della tabella non è mostrato di seguito):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Il valore decodificato Base64 di
Dataè come segue. Il record Kinesis effettivo conterrà i dati dell'intera riga della riga della tabella modificata, oltre alla chiave primaria e al timestamp del commit.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}I
CommitTimestampnelDataIl campo viene utilizzato nel punto di controllo della replica ed è fondamentale per tenere traccia con precisione della quantità di dati del flusso replicati nella regione secondaria. Il checkpoint può quindi essere utilizzato per facilitare un failover del processore CDC (produttore) e riprendere accuratamente la produzione di dati dal timestamp del checkpoint di replica in poi.L'alternativa all'utilizzo di un'origine dati remota
CommitTimestamp(se non disponibile) è utilizzare ilApproximateArrivalTimestamp(che è il timestamp in cui il record viene effettivamente scritto nel flusso di dati). - Funzione Lambda di replica in più regioni – La funzione viene implementata sia nelle regioni primarie che in quelle secondarie. È configurato con una mappatura dell'origine evento al flusso di dati contenente i dati CDC. La stessa funzione può essere utilizzata per replicare i dati di più flussi. Viene richiamato con un batch di record da Kinesis Data Streams e replica il batch in una regione di replica di destinazione (fornita tramite l'ambiente di configurazione Lambda). Per considerazioni sui costi, se i dati CDC vengono prodotti attivamente solo nella regione primaria, la simultaneità riservata della funzione nella regione secondaria può essere impostata su zero e modificata durante il failover regionale. La funzione ha Gestione dell'identità e dell'accesso di AWS Autorizzazioni del ruolo (IAM) per eseguire le seguenti operazioni:
- Leggi e scrivi nelle tabelle globali DynamoDB utilizzate in questa soluzione, all'interno dello stesso account.
- Leggi e scrivi su Kinesis Data Streams in entrambe le regioni all'interno dello stesso account.
- Pubblica metriche personalizzate in Amazon Cloud Watch in entrambe le Regioni all'interno dello stesso conto.
- Punto di controllo della replica – Il checkpoint di replica utilizza la tabella globale DynamoDB sia nella regione primaria che in quella secondaria. Viene utilizzato dalla funzione Lambda di replica tra regioni per mantenere il timestamp di commit dell'ultimo record di replica come checkpoint di replica per ogni flusso configurato per la replica. Per questo post, creiamo e utilizziamo una tabella globale chiamata
kdsReplicationCheckpoint. - Configurazione regione attiva – La regione attiva utilizza la tabella globale DynamoDB sia nella regione primaria che in quella secondaria. Utilizza la funzionalità di replica tra regioni nativa della tabella globale per replicare la configurazione. È prepopolato con dati su quale sia la regione primaria per un flusso, per impedire la replica nella regione primaria da parte della funzione Lambda nella regione di standby. Questa configurazione potrebbe non essere necessaria se la funzione Lambda nella regione di standby ha una concorrenza riservata impostata su zero, ma può fungere da controllo di sicurezza per evitare un ciclo di replica infinito dei dati. Per questo post, creiamo una tabella globale chiamata
kdsActiveRegionConfige inserire un elemento con i seguenti dati:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Flussi di dati Kinesis – Il flusso in cui il processore CDC produce i dati. Per questo post, utilizziamo uno stream chiamato
example-stream-1in entrambe le regioni, con la stessa configurazione dello shard e le stesse policy di accesso.
Sequenza di passaggi nella replica tra regioni
Diamo un'occhiata brevemente a come l'architettura viene esercitata usando il seguente diagramma di sequenza.
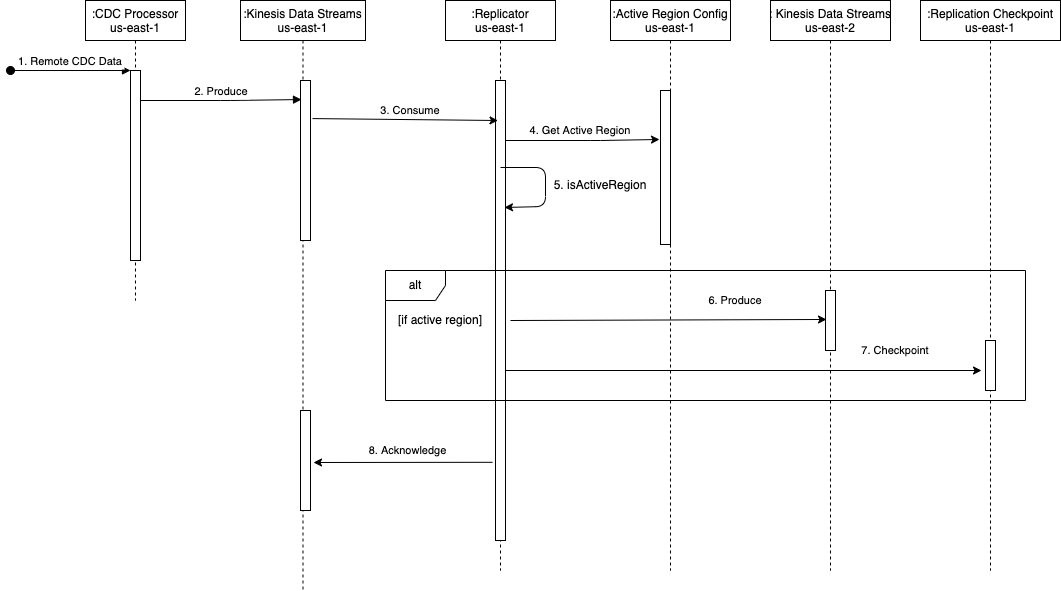
La sequenza è composta dai seguenti passaggi:
- Il processore CDC (in
us-east-1) legge i dati CDC dall'origine dati remota. - Il processore CDC (in
us-east-1) trasmette i dati CDC a Kinesis Data Streams (inus-east-1). - La funzione Lambda di replica tra regioni (in us-east-1) utilizza i dati dal flusso di dati (in
us-east-1). Il modello di fan-out avanzato è consigliato per una velocità effettiva dedicata e maggiore per la replica tra più regioni. - La funzione replicatore Lambda (in
us-east-1) convalida la sua regione corrente con la configurazione della regione attiva per il flusso in uso, con l'aiuto dikdsActiveRegionConfigTabella globale di DynamoDBIl seguente codice di esempio (in Java) può aiutare a illustrare la condizione valutata:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - La funzione valuta la risposta di DynamoDB con il seguente codice:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - A seconda della risposta, la funzione intraprende le seguenti azioni:
- Se la risposta è
true, la funzione replicatore produce i record in Kinesis Data Streams inus-east-2in modo sequenziale.- Se si verifica un errore, viene tracciato il numero di sequenza del record e l'iterazione viene interrotta. La funzione restituisce l'elenco dei numeri di sequenza non riusciti. Restituendo il numero di sequenza non riuscito, la soluzione utilizza la funzionalità di Punto di controllo lambda poter riprendere l'elaborazione di un batch di record con fallimenti parziali. Ciò è utile quando si gestiscono eventuali problemi di servizio, in cui la funzione tenta di replicare i dati tra le regioni per garantire la parità del flusso e nessuna perdita di dati.
- Se non ci sono errori, viene restituito un elenco vuoto, che indica che il batch ha avuto esito positivo.
- Se la risposta è
false, la funzione replicator viene restituita senza eseguire alcuna replica. Per ridurre il costo delle chiamate Lambda, puoi impostare la concorrenza riservata della funzione nella regione DR (us-east-2) a zero. Ciò impedirà l'invocazione della funzione. Quando si esegue il failover, è possibile aggiornare questo valore a un numero appropriato in base al throughput CDC e impostare la concorrenza riservata della funzione inus-east-1a zero per evitare che venga eseguito inutilmente.
- Se la risposta è
- Dopo che tutti i record sono stati prodotti in Kinesis Data Streams in
us-east-2, la funzione di replicatore esegue il checkpoint akdsReplicationCheckpointTabella globale DynamoDB (inus-east-1) con i seguenti dati:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - La funzione ritorna dopo aver elaborato correttamente il batch di record.
Considerazioni sulle prestazioni
Le aspettative prestazionali della soluzione devono essere comprese rispetto ai seguenti fattori:
- Selezione della regione – La latenza di replica è direttamente proporzionale alla distanza percorsa dai dati, quindi è necessario comprendere la selezione della regione
- Velocità – La velocità in entrata dei dati o il volume dei dati replicati
- Dimensioni del carico utile – La dimensione del payload replicato
Monitorare la replica in più regioni
Si consiglia di tenere traccia e osservare la replica in tempo reale. Puoi personalizzare la funzione Lambda per pubblicare parametri personalizzati in CloudWatch con i seguenti parametri alla fine di ogni chiamata. La pubblicazione di queste metriche sia nella regione primaria che in quella secondaria aiuta a proteggersi da problemi che incidono sull'osservabilità nella regione primaria.
- Throughput – La dimensione del batch di chiamata Lambda corrente
- ReplicationLagSeconds – La differenza tra il timestamp corrente (dopo l'elaborazione di tutti i record) e il
ApproximateArrivalTimestampdell'ultimo record che è stato replicato
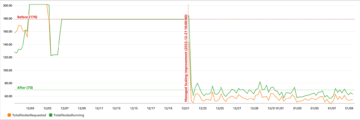
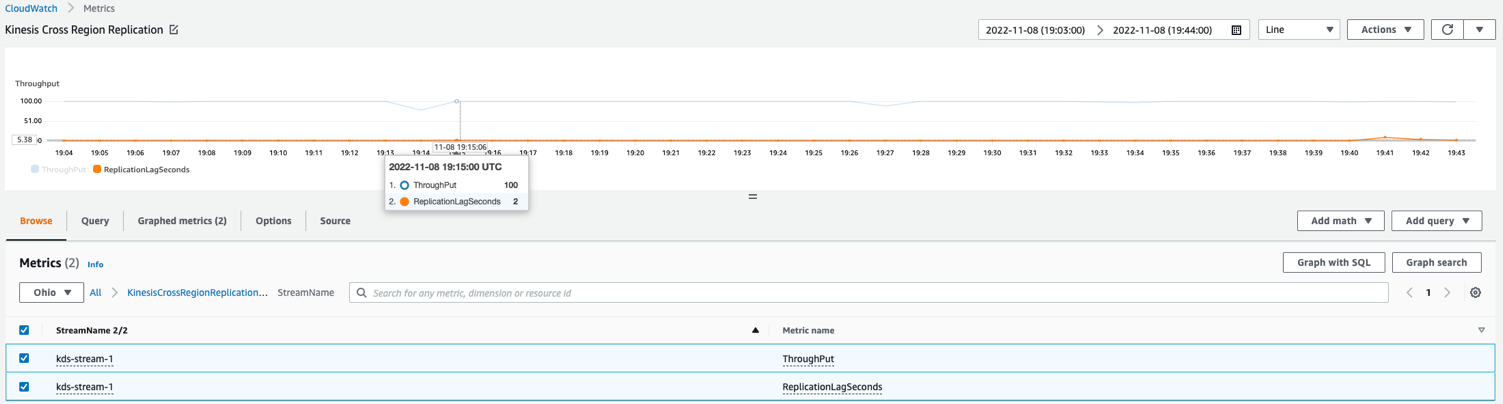
Il seguente grafico dei parametri di CloudWatch di esempio mostra che il ritardo di replica medio è stato di 2 secondi con un throughput di 100 record replicati da us-east-1 a us-east-2.
Strategia di failover comune
Durante eventuali problemi che incidono sulla pipeline CDC nella regione primaria, la continuità aziendale o le esigenze di ripristino di emergenza possono imporre un failover della pipeline nella regione secondaria (in standby). Ciò significa che un paio di cose devono essere fatte come parte di questo processo di failover:
- Se possibile, interrompere tutte le attività CDC nello strumento del processore CDC in
us-east-1. - Il processore CDC deve essere sottoposto a failover nella regione secondaria, in modo che possa leggere i dati CDC dall'origine dati remota durante il funzionamento al di fuori della regione di standby.
- I
kdsActiveRegionConfigLa tabella globale di DynamoDB deve essere aggiornata. Ad esempio, per lo streamexample-stream-1utilizzato nel nostro esempio, la regione attiva viene modificata inus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Tutti i checkpoint del flusso devono essere letti dal file
kdsReplicationCheckpointTabella globale DynamoDB (inus-east-2) e i timestamp di ciascuno dei checkpoint vengono utilizzati per avviare le attività CDC nello strumento producer inus-east-2Regione. Ciò riduce al minimo le possibilità di perdita di dati e riprende accuratamente lo streaming dei dati CDC dall'origine dati remota dal timestamp del checkpoint in poi. - Se utilizzi la concorrenza riservata per controllare le chiamate Lambda, imposta il valore su zero nella regione primaria(
us-east-1) e ad un opportuno valore diverso da zero nella Regione secondaria(us-east-2).
La strategia di failover in più passaggi di Vanguard
Alcuni degli strumenti di terze parti utilizzati da Vanguard dispongono di un processo CDC in due passaggi per lo streaming dei dati da un'origine dati remota a una destinazione. Lo strumento scelto da Vanguard per il proprio processore CDC segue questo approccio in due fasi:
- Il primo passaggio prevede la configurazione di un'attività del flusso di log che legge i dati dall'origine dati remota e persiste in una posizione di gestione temporanea.
- Il secondo passaggio prevede l'impostazione di singole attività consumer che leggono i dati dalla posizione di gestione temporanea, che potrebbe essere attiva File system elastico Amazon (Amazon EFS) o AmazonFSx, ad esempio, e trasmetterlo alla destinazione. La flessibilità qui è che ciascuna di queste attività del consumatore può essere attivata per lo streaming da diversi timestamp di commit. L'attività del flusso di log in genere inizia a leggere i dati dal minimo di tutti i timestamp di commit utilizzati dalle attività del consumatore.
Diamo un'occhiata a un esempio per spiegare lo scenario:
- L'attività del consumatore A sta trasmettendo i dati da un timestamp di commit 2022-07-19T20:00:00 in poi a
example-stream-1. - L'attività del consumatore B esegue lo streaming dei dati da un timestamp di commit 2022-07-19T21:00:00 in poi a
example-stream-2. - In questa situazione, il flusso di log dovrebbe leggere i dati dall'origine dati remota dal minimo dei timestamp utilizzati dalle attività consumer, ovvero 2022-07-19T20:00:00.
Il diagramma di sequenza seguente illustra i passaggi esatti da eseguire durante un failover in us-east-2 (la regione di attesa).
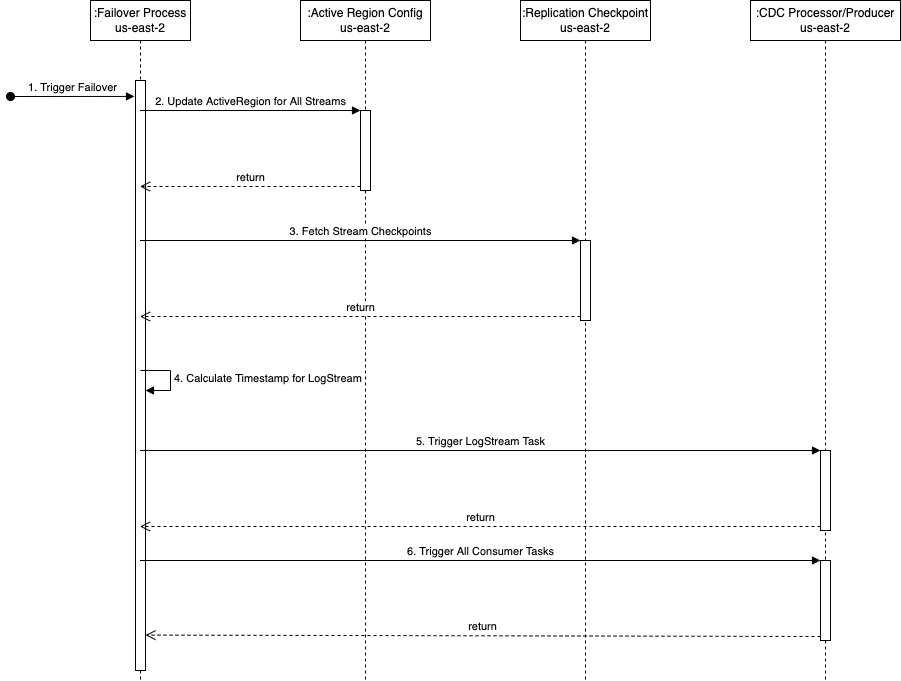
I passi sono come segue:
- Il processo di failover viene attivato nella regione di standby (
us-east-2in questo esempio) quando richiesto. Tieni presente che il trigger può essere automatizzato utilizzando controlli di integrità completi della pipeline nella regione primaria. - Il processo di failover aggiorna la tabella globale kdsActiveRegionConfig DynamoDB con il nuovo valore per Region as
us-east-2per tutti i nomi di stream. - Il passaggio successivo consiste nel recuperare tutti i checkpoint del flusso dal file
kdsReplicationCheckpointTabella globale DynamoDB (inus-east-2). - Dopo che le informazioni sul checkpoint sono state lette, il processo di failover trova il minimo di tutti i file
lastReplicatedTimestamp. - L'attività del flusso di log nello strumento del processore CDC viene avviata in
us-east-2con il timestamp trovato nel passaggio 4. Inizia a leggere i dati CDC dall'origine dati remota da questo timestamp in poi e li persiste nella posizione di staging su AWS. - Il passaggio successivo consiste nell'avviare tutte le attività del consumatore per leggere i dati dalla posizione di gestione temporanea e trasmetterli al flusso di dati di destinazione. Qui è dove ogni attività del consumatore viene fornita con il timestamp appropriato dal file
kdsReplicationCheckpointtavola secondo ilstreamNamea cui l'attività trasmette i dati.
Dopo che tutte le attività del consumatore sono state avviate, i dati vengono prodotti nei flussi di dati Kinesis in us-east-2. Da lì in poi, il processo di replica tra regioni è lo stesso descritto in precedenza: la funzione Lambda di replica in us-east-2 inizia a replicare i dati nel flusso di dati in us-east-1.
Le applicazioni consumer che leggono i dati dai flussi dovrebbero essere idempotenti per essere in grado di gestire i duplicati. I duplicati possono essere introdotti nello stream per molti motivi, alcuni dei quali sono indicati di seguito.
- Il produttore o il processore CDC introduce duplicati nel flusso durante la riproduzione dei dati CDC durante un failover
- DynamoDB Global Table utilizza la replica asincrona dei dati tra regioni e se il
kdsReplicationCheckpointi dati della tabella hanno un ritardo di replica, il processo di failover potrebbe potenzialmente utilizzare un timestamp del checkpoint precedente per riprodurre i dati CDC.
Inoltre, le applicazioni consumer devono eseguire il checkpoint del CommitTimestamp dell'ultimo record consumato. Questo per facilitare un migliore monitoraggio e recupero.
Percorso verso la maturità: ripristino automatico
Lo stato ideale è automatizzare completamente il processo di failover, riducendo i tempi di ripristino e soddisfacendo lo SLO (Service Level Objective) di resilienza. Tuttavia, nella maggior parte delle organizzazioni, la decisione di eseguire il failover, eseguire il failback e attivare il failover richiede un intervento manuale per valutare la situazione e decidere il risultato. La creazione di un'automazione con script per eseguire il failover che può essere eseguito da un essere umano è un buon punto di partenza.
Vanguard ha automatizzato tutti i passaggi del failover, ma sono ancora gli umani a prendere la decisione su quando invocarlo. È possibile personalizzare la soluzione in base alle proprie esigenze e in base allo strumento del processore CDC utilizzato nel proprio ambiente.
Conclusione
In questo post, abbiamo descritto come Vanguard ha innovato e creato una soluzione per la replica dei dati tra le regioni in Kinesis Data Streams per rendere i dati altamente disponibili. Abbiamo anche dimostrato una solida strategia di checkpoint per facilitare un failover regionale del processo di replica quando necessario. La soluzione ha anche illustrato come utilizzare le tabelle globali di DynamoDB per tenere traccia dei checkpoint e della configurazione della replica. Con questa architettura, Vanguard è stata in grado di distribuire carichi di lavoro a seconda dei dati CDC in più regioni per soddisfare le esigenze aziendali di elevata disponibilità a fronte di problemi di servizio che incidono sulle pipeline CDC nella regione primaria.
Se hai commenti, lascia un commento nella sezione Commenti qui sotto.
Circa gli autori
 Raghu Boppanna lavora come Enterprise Architect presso il Chief Technology Office di Vanguard. Raghu è specializzato in analisi dei dati, migrazione/replicazione dei dati, incluse pipeline CDC, ripristino di emergenza e database. Ha conseguito diverse certificazioni AWS, tra cui AWS Certified Security – Specialty e AWS Certified Data Analytics – Specialty.
Raghu Boppanna lavora come Enterprise Architect presso il Chief Technology Office di Vanguard. Raghu è specializzato in analisi dei dati, migrazione/replicazione dei dati, incluse pipeline CDC, ripristino di emergenza e database. Ha conseguito diverse certificazioni AWS, tra cui AWS Certified Security – Specialty e AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan è un Senior Cloud Resilience Architect con Amazon Web Services. Aiuta le grandi aziende a raggiungere gli obiettivi aziendali progettando e costruendo soluzioni scalabili e resilienti nel cloud AWS.
Parameswaran V Vaidyanathan è un Senior Cloud Resilience Architect con Amazon Web Services. Aiuta le grandi aziende a raggiungere gli obiettivi aziendali progettando e costruendo soluzioni scalabili e resilienti nel cloud AWS.
 Rich Kaul è un leader senior nelle soluzioni per i clienti al servizio dei clienti dei servizi finanziari. Ha sede a New York. Ha una vasta esperienza nella trasformazione del cloud su larga scala, nell'eccellenza dei dipendenti e nelle soluzioni digitali di prossima generazione. Lei e il suo team si concentrano sull'ottimizzazione del valore del cloud creando soluzioni performanti, resilienti e agili. A Richa piacciono i multisport come il triathlon, la musica e l'apprendimento delle nuove tecnologie.
Rich Kaul è un leader senior nelle soluzioni per i clienti al servizio dei clienti dei servizi finanziari. Ha sede a New York. Ha una vasta esperienza nella trasformazione del cloud su larga scala, nell'eccellenza dei dipendenti e nelle soluzioni digitali di prossima generazione. Lei e il suo team si concentrano sull'ottimizzazione del valore del cloud creando soluzioni performanti, resilienti e agili. A Richa piacciono i multisport come il triathlon, la musica e l'apprendimento delle nuove tecnologie.
 Mithil Prasad è Principal Customer Solutions Manager con Amazon Web Services. Nel suo ruolo, Mithil lavora con i clienti per guidare la realizzazione del valore del cloud, fornire leadership di pensiero per aiutare le aziende a raggiungere velocità, agilità e innovazione.
Mithil Prasad è Principal Customer Solutions Manager con Amazon Web Services. Nel suo ruolo, Mithil lavora con i clienti per guidare la realizzazione del valore del cloud, fornire leadership di pensiero per aiutare le aziende a raggiungere velocità, agilità e innovazione.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- capacità
- capace
- Chi siamo
- sopra
- accesso
- Secondo
- Il mio account
- con precisione
- Raggiungere
- operanti in
- azioni
- attivo
- attivamente
- effettivamente
- aggiunta
- consigli
- che interessano
- conveniente
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- agile
- Tutti
- consente
- alternativa
- Amazon
- Amazon EC2
- Cinesi amazzonica
- Amazon Web Services
- importi
- analitica
- ed
- applicazioni
- approccio
- opportuno
- architettura
- automatizzare
- Automatizzata
- Automazione
- disponibilità
- disponibile
- media
- evitare
- AWS
- Certificato AWS
- precedente
- basato
- perché
- essendo
- sotto
- Meglio
- fra
- brevemente
- Rotto
- costruire
- Costruzione
- costruito
- incassato
- affari
- business continuity
- aziende
- detto
- catturare
- cattura
- Custodie
- CDC
- certificazioni
- Certificato
- probabilità
- il cambiamento
- dai un'occhiata
- Controlli
- capo
- scegliere
- Cloud
- TECNOLOGIA NUVOLA
- codice
- commento
- Commenti
- commettere
- componente
- globale
- Calcolare
- condizione
- Configurazione
- Considerazioni
- consumato
- Consumer
- Consumatori
- consumo
- continuamente
- di controllo
- Costo
- potuto
- Coppia
- creare
- Creazione
- critico
- Corrente
- Attualmente
- costume
- cliente
- Soluzioni per i clienti
- Clienti
- personalizzare
- dati
- Dati Analytics
- Perdita di dati
- Banca Dati
- banche dati
- Decidere
- decisione
- dedicato
- dimostrato
- dimostra
- Dipendente
- dipende
- schierare
- schierato
- descritta
- destinazione
- dettaglio
- differenza
- diverso
- digitale
- direttamente
- disastro
- discusso
- distanza
- guidare
- guida
- duplicati
- durante
- ogni
- In precedenza
- guadagnato
- economie
- Economie di scala
- efficiente
- Dipendente
- Abilita
- migliorata
- garantire
- Impresa
- aziende
- Intero
- Ambiente
- Etere (ETH)
- valutare
- valutato
- Evento
- Ogni
- esempio
- Eccellenza
- esecuzione
- le aspettative
- previsto
- esperienza
- Spiegare
- Spiega
- estensivo
- esterno
- Faccia
- facilitare
- Fattori
- FAIL
- fallito
- Fallimento
- caratteristica
- feedback
- campo
- Compila il
- finanziario
- servizi finanziari
- trova
- Nome
- Flessibilità
- Focus
- i seguenti
- segue
- per gli investitori
- essere trovato
- da
- completamente
- function
- ELETTRICA
- globali
- globo
- Obiettivi
- buono
- grafico
- GUEST
- Ospite Messaggio
- maniglia
- Manovrabilità
- accade
- Salute e benessere
- Aiuto
- aiuta
- qui
- Alta
- vivamente
- Come
- Tutorial
- Tuttavia
- HTTPS
- umano
- Gli esseri umani
- IAM
- ideale
- Identità
- menomazione
- competenze
- migliora
- in
- Compreso
- In arrivo
- è aumentato
- indica
- individuale
- informazioni
- Infrastruttura
- Innovazione
- esempio
- intervento
- introdotto
- Introduce
- investitore
- Investitori
- comporta
- IT
- iterazione
- Java
- Luglio
- Le
- Flussi di dati Kinesis
- grandi
- Cognome
- Latenza
- leader
- Leadership
- apprendimento
- Lasciare
- Livello
- linea
- Linee
- Lista
- piccolo
- località
- Guarda
- spento
- fatto
- mantiene
- make
- FA
- gestito
- direttore
- modo
- Manuale
- molti
- mappatura
- massicciamente
- maturità
- si intende
- meccanismo
- Soddisfare
- incontro
- metrico
- Metrica
- minimo
- ordine
- Moda
- modificato
- monitoraggio
- maggior parte
- Multi
- multiplo
- Musica
- Nome
- nomi
- nativo
- Bisogno
- di applicazione
- esigenze
- New
- Nuove tecnologie
- New York
- GENERAZIONE
- numero
- numeri
- obiettivo
- osservare
- Office
- operativo
- ottimizzazione
- organizzazioni
- Risultato
- parità
- parte
- collaborato
- partito
- Cartamodello
- eseguire
- performance
- esecuzione
- permessi
- persiste
- Personalizzata
- conduttura
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- Termini e Condizioni
- possibile
- Post
- potenzialmente
- prevenire
- primario
- Direttore
- processi
- lavorazione
- Processore
- Prodotto
- produttore
- Produttori
- promuove
- protegge
- fornire
- purché
- fornisce
- pubblicare
- editoriale
- fini
- metti
- Leggi
- Lettura
- realizzazione
- motivi
- raccomandato
- record
- record
- Recuperare
- recupero
- ridurre
- riducendo
- regione
- regionale
- regioni
- a distanza
- replicato
- replica
- replicazione
- necessario
- Requisiti
- richiede
- riservato
- elasticità
- elastico
- risposta
- REST
- curriculum vitae
- ritorno
- di ritorno
- problemi
- robusto
- Ruolo
- Arrotolato
- RIGA
- Correre
- Sicurezza
- stesso
- scalabile
- Scala
- scenario
- Secondo
- secondario
- secondo
- Sezione
- problemi di
- anziano
- Sequenza
- servire
- servizio
- Servizi
- servizio
- set
- regolazione
- alcuni
- dovrebbero
- mostrato
- Spettacoli
- semplicità
- situazione
- Taglia
- So
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- specializzata
- Specialità
- velocità
- Sports
- messa in scena
- inizia a
- iniziato
- inizio
- Regione / Stato
- step
- Passi
- Ancora
- Fermare
- Tornare al suo account
- Strategia
- ruscello
- Streaming
- servizio di streaming
- flussi
- di successo
- Con successo
- adatto
- superiore
- in dotazione
- supporti
- sistema
- tavolo
- prende
- Target
- Task
- task
- team
- le squadre
- Consulenza
- Tecnologie
- Tecnologia
- I
- loro
- cose
- di parti terze standard
- pensiero
- leadership di pensiero
- Attraverso
- portata
- tempo
- timestamp
- a
- strumenti
- pista
- Tracking
- Trasformazione
- viaggiato
- innescare
- innescato
- capire
- inteso
- inutilmente
- Aggiornanento
- aggiornato
- Aggiornamenti
- uso
- caso d'uso
- generalmente
- UTC
- APPREZZIAMO
- Avanguardia
- Velocità
- via
- volume
- sito web
- servizi web
- quale
- while
- volere
- entro
- senza
- lavori
- sarebbe
- scrivere
- scritto
- Trasferimento da aeroporto a Sharm
- te stesso
- zefiro
- zero
- zone