Questo post è stato scritto in collaborazione con Mahima Agarwal, Machine Learning Engineer, e Deepak Mettem, Senior Engineering Manager, presso VMware Carbon Black
VMware nerofumo è una rinomata soluzione di sicurezza che offre protezione contro l'intero spettro dei moderni attacchi informatici. Con terabyte di dati generati dal prodotto, il team di analisi della sicurezza si concentra sulla creazione di soluzioni di machine learning (ML) per far emergere attacchi critici e mettere in luce le minacce emergenti dal rumore.
È fondamentale per il team VMware Carbon Black progettare e creare una pipeline MLOps end-to-end personalizzata che orchestra e automatizza i flussi di lavoro nel ciclo di vita ML e consente l'addestramento, le valutazioni e le distribuzioni dei modelli.
Esistono due scopi principali per la creazione di questa pipeline: supportare i data scientist per lo sviluppo del modello in fase avanzata e le previsioni del modello di superficie nel prodotto servendo modelli in volume elevato e nel traffico di produzione in tempo reale. Pertanto, VMware Carbon Black e AWS hanno scelto di creare una pipeline MLOps personalizzata utilizzando Amazon Sage Maker per la sua facilità d'uso, versatilità e infrastruttura completamente gestita. Orchestriamo le nostre pipeline di formazione e distribuzione ML utilizzando Flussi di lavoro gestiti da Amazon per Apache Airflow (Amazon MWAA), che ci consente di concentrarci maggiormente sulla creazione di flussi di lavoro e pipeline in modo programmatico senza doverci preoccupare del ridimensionamento automatico o della manutenzione dell'infrastruttura.
Con questa pipeline, quella che una volta era la ricerca ML basata su notebook Jupyter è ora un processo automatizzato che distribuisce modelli alla produzione con un intervento manuale minimo da parte dei data scientist. In precedenza, il processo di addestramento, valutazione e distribuzione di un modello poteva richiedere più di un giorno; con questa implementazione, tutto è a portata di trigger e ha ridotto il tempo complessivo a pochi minuti.
In questo post, gli architetti di VMware Carbon Black e AWS discutono di come abbiamo creato e gestito flussi di lavoro ML personalizzati utilizzando Gitlab, Amazon MWAA e SageMaker. Discutiamo di ciò che abbiamo ottenuto finora, di ulteriori miglioramenti alla pipeline e delle lezioni apprese lungo il percorso.
Panoramica della soluzione
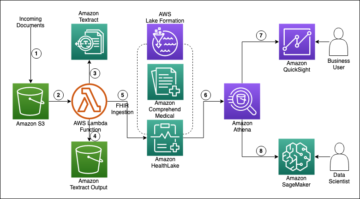
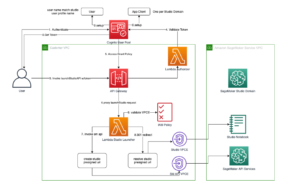
Il diagramma seguente illustra l'architettura della piattaforma ML.

Progettazione di soluzioni di alto livello
Questa piattaforma ML è stata concepita e progettata per essere utilizzata da diversi modelli in vari repository di codice. Il nostro team utilizza GitLab come strumento di gestione del codice sorgente per mantenere tutti i repository di codice. Eventuali modifiche al codice sorgente del repository di modelli vengono continuamente integrate utilizzando il file CI Gitlab, che richiama i flussi di lavoro successivi nella pipeline (addestramento del modello, valutazione e distribuzione).
Il seguente diagramma dell'architettura illustra il flusso di lavoro end-to-end e i componenti coinvolti nella nostra pipeline MLOps.

Flusso di lavoro end-to-end
Le pipeline di addestramento, valutazione e distribuzione del modello ML sono orchestrate utilizzando Amazon MWAA, denominato a Grafico aciclico diretto (DAG). Un DAG è una raccolta di attività insieme, organizzate con dipendenze e relazioni per indicare come devono essere eseguite.
Ad alto livello, l'architettura della soluzione comprende tre componenti principali:
- Repository del codice della pipeline ML
- Pipeline di formazione e valutazione del modello ML
- Pipeline di distribuzione del modello ML
Parliamo di come vengono gestiti questi diversi componenti e di come interagiscono tra loro.
Repository del codice della pipeline ML
Dopo che il repository del modello ha integrato il repository MLOps come pipeline a valle e un data scientist ha eseguito il commit del codice nel repository del modello, un runner GitLab esegue la convalida e il test del codice standard definito in quel repository e attiva la pipeline MLOps in base alle modifiche al codice. Utilizziamo la pipeline multi-progetto di Gitlab per abilitare questo trigger su diversi repository.
La pipeline MLOps GitLab esegue un determinato set di fasi. Esegue la convalida del codice di base utilizzando pylint, impacchetta il codice di addestramento e inferenza del modello all'interno dell'immagine Docker e pubblica l'immagine del contenitore su Registro dei contenitori Amazon Elastic (Amazon ECR). Amazon ECR è un registro di container completamente gestito che offre hosting ad alte prestazioni, in modo da poter distribuire in modo affidabile immagini e artefatti dell'applicazione ovunque.
Pipeline di formazione e valutazione del modello ML
Dopo che l'immagine è stata pubblicata, attiva la formazione e la valutazione Flusso d'aria Apache conduttura attraverso il AWS Lambda funzione. Lambda è un servizio di elaborazione basato su eventi senza server che consente di eseguire codice praticamente per qualsiasi tipo di applicazione o servizio di back-end senza eseguire il provisioning o la gestione dei server.
Dopo che la pipeline è stata attivata correttamente, esegue il DAG di addestramento e valutazione, che a sua volta avvia l'addestramento del modello in SageMaker. Al termine di questa pipeline di addestramento, il gruppo di utenti identificato riceve tramite e-mail una notifica con i risultati dell'addestramento e della valutazione del modello Servizio di notifica semplice Amazon (Amazon SNS) e Slack. Amazon SNS è un servizio pub/sub completamente gestito per la messaggistica A2A e A2P.
Dopo un'analisi meticolosa dei risultati della valutazione, il data scientist o l'ingegnere ML può distribuire il nuovo modello se le prestazioni del modello appena addestrato sono migliori rispetto alla versione precedente. Le prestazioni dei modelli vengono valutate in base alle metriche specifiche del modello (come punteggio F1, MSE o matrice di confusione).
Pipeline di distribuzione del modello ML
Per avviare la distribuzione, l'utente avvia il processo GitLab che attiva il DAG di distribuzione tramite la stessa funzione Lambda. Dopo che la pipeline è stata eseguita correttamente, crea o aggiorna l'endpoint SageMaker con il nuovo modello. Questo invia anche una notifica con i dettagli dell'endpoint tramite e-mail utilizzando Amazon SNS e Slack.
In caso di guasto in una delle pipeline, gli utenti vengono avvisati tramite gli stessi canali di comunicazione.
SageMaker offre inferenza in tempo reale ideale per carichi di lavoro di inferenza con bassa latenza e requisiti di throughput elevato. Questi endpoint sono completamente gestiti, con bilanciamento del carico e ridimensionamento automatico e possono essere distribuiti su più zone di disponibilità per un'elevata disponibilità. La nostra pipeline crea un endpoint di questo tipo per un modello dopo che è stato eseguito correttamente.
Nelle sezioni seguenti, espandiamo i diversi componenti e ci immergiamo nei dettagli.
GitLab: modelli di pacchetti e pipeline di trigger
Utilizziamo GitLab come repository di codice e per la pipeline per impacchettare il codice del modello e attivare DAG Airflow a valle.
Pipeline multiprogetto
La funzionalità della pipeline GitLab multi-progetto viene usata dove la pipeline padre (a monte) è un repository modello e la pipeline figlio (a valle) è il repository MLOps. Ogni repository mantiene un file .gitlab-ci.yml e il seguente blocco di codice abilitato nella pipeline upstream attiva la pipeline MLOps downstream.
La pipeline upstream invia il codice del modello alla pipeline downstream dove vengono attivati i processi CI di creazione pacchetti e pubblicazione. Il codice per containerizzare il codice del modello e pubblicarlo in Amazon ECR viene mantenuto e gestito dalla pipeline MLOps. Invia le variabili come ACCESS_TOKEN (può essere creato sotto Impostazioni profilo, accesso a), JOB_ID (per accedere agli artefatti upstream) e $CI_PROJECT_ID (l'ID progetto del repository del modello), in modo che la pipeline MLOps possa accedere ai file di codice del modello. Con il artefatti del lavoro feature da Gitlab, il repository downstream accede agli artefatti remoti utilizzando il seguente comando:
Il repository del modello può consumare pipeline a valle per più modelli dallo stesso repository estendendo la fase che lo attiva utilizzando il si estende parola chiave da GitLab, che consente di riutilizzare la stessa configurazione in diverse fasi.
Dopo aver pubblicato l'immagine del modello in Amazon ECR, la pipeline MLOps attiva la pipeline di addestramento Amazon MWAA utilizzando Lambda. Dopo l'approvazione dell'utente, attiva anche la pipeline di distribuzione del modello Amazon MWAA utilizzando la stessa funzione Lambda.
Versioning semantico e passaggio di versioni a valle
Abbiamo sviluppato un codice personalizzato per la versione delle immagini ECR e dei modelli SageMaker. La pipeline MLOps gestisce la logica di versioning semantico per immagini e modelli come parte della fase in cui il codice del modello viene containerizzato e passa le versioni alle fasi successive come artefatti.
Riqualificazione
Poiché la riqualificazione è un aspetto cruciale di un ciclo di vita ML, abbiamo implementato funzionalità di riqualificazione come parte della nostra pipeline. Utilizziamo l'API list-models di SageMaker per identificare se si tratta di riaddestramento in base al numero di versione e al timestamp del riaddestramento del modello.
Gestiamo il programma giornaliero della pipeline di riqualificazione utilizzando Pipeline di pianificazione di GitLab.
Terraform: configurazione dell'infrastruttura
Oltre a un cluster Amazon MWAA, repository ECR, funzioni Lambda e argomento SNS, questa soluzione utilizza anche Gestione dell'identità e dell'accesso di AWS (IAM) ruoli, utenti e policy; Servizio di archiviazione semplice Amazon (Amazon S3) e un Amazon Cloud Watch spedizioniere di registri.
Per semplificare la configurazione e la manutenzione dell'infrastruttura per i servizi coinvolti in tutta la nostra pipeline, utilizziamo Terraform per implementare l'infrastruttura come codice. Ogni volta che sono richiesti aggiornamenti infra, le modifiche al codice attivano una pipeline CI GitLab che impostiamo, che convalida e distribuisce le modifiche in vari ambienti (ad esempio, aggiungendo un'autorizzazione a una policy IAM negli account dev, stage e prod).
Amazon ECR, Amazon S3 e Lambda: facilitazione della pipeline
Utilizziamo i seguenti servizi chiave per facilitare la nostra pipeline:
- Amazon ECR – Per mantenere e consentire recuperi convenienti delle immagini del contenitore del modello, le contrassegniamo con versioni semantiche e le carichiamo nei repository ECR impostati per
${project_name}/${model_name}tramite Terraforma. Ciò consente un buon livello di isolamento tra diversi modelli e ci consente di utilizzare algoritmi personalizzati e di formattare le richieste e le risposte di inferenza per includere le informazioni desiderate sul manifesto del modello (nome del modello, versione, percorso dei dati di addestramento e così via). - Amazon S3 – Utilizziamo i bucket S3 per rendere persistenti i dati di addestramento del modello, gli artefatti del modello addestrato per modello, i DAG Airflow e altre informazioni aggiuntive richieste dalle pipeline.
- Lambda – Poiché il nostro cluster Airflow è distribuito in un VPC separato per motivi di sicurezza, non è possibile accedere direttamente ai DAG. Pertanto, utilizziamo una funzione Lambda, anch'essa gestita con Terraform, per attivare qualsiasi DAG specificato dal nome del DAG. Con una configurazione IAM corretta, il processo GitLab CI attiva la funzione Lambda, che passa attraverso le configurazioni fino ai DAG di addestramento o distribuzione richiesti.
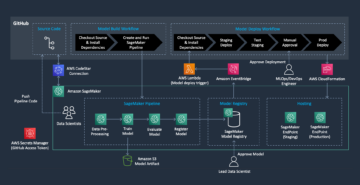
Amazon MWAA: pipeline di formazione e distribuzione
Come accennato in precedenza, utilizziamo Amazon MWAA per orchestrare le pipeline di addestramento e distribuzione. Utilizziamo gli operatori SageMaker disponibili in Pacchetto provider Amazon per Airflow da integrare con SageMaker (per evitare il template jinja).
Utilizziamo i seguenti operatori in questa pipeline di formazione (mostrata nel seguente diagramma del flusso di lavoro):

Pipeline di formazione MWAA
Utilizziamo i seguenti operatori nella pipeline di distribuzione (mostrata nel seguente diagramma del flusso di lavoro):

Pipeline di distribuzione del modello
Utilizziamo Slack e Amazon SNS per pubblicare i messaggi di errore/esito positivo e i risultati della valutazione in entrambe le pipeline. Slack offre una vasta gamma di opzioni per personalizzare i messaggi, tra cui:
- Operatore SnsPublish - Noi usiamo Operatore SnsPublish per inviare notifiche di successo/fallimento alle e-mail degli utenti
- API debole – Abbiamo creato il URL del webhook in entrata per ricevere le notifiche della pipeline sul canale desiderato
CloudWatch e VMware Wavefront: monitoraggio e registrazione
Utilizziamo un dashboard CloudWatch per configurare il monitoraggio e la registrazione degli endpoint. Aiuta a visualizzare e tenere traccia di varie metriche operative e delle prestazioni del modello specifiche per ciascun progetto. Oltre ai criteri di ridimensionamento automatico impostati per tenere traccia di alcuni di essi, monitoriamo continuamente i cambiamenti nell'utilizzo della CPU e della memoria, le richieste al secondo, le latenze di risposta e le metriche del modello.
CloudWatch è persino integrato con un dashboard VMware Tanzu Wavefront in modo che possa visualizzare le metriche per gli endpoint del modello e altri servizi a livello di progetto.
Vantaggi aziendali e prospettive
Le pipeline ML sono fondamentali per i servizi e le funzionalità ML. In questo post, abbiamo discusso un caso d'uso ML end-to-end utilizzando le funzionalità di AWS. Abbiamo creato una pipeline personalizzata utilizzando SageMaker e Amazon MWAA, che possiamo riutilizzare in progetti e modelli, e automatizzato il ciclo di vita ML, che ha ridotto il tempo dall'addestramento del modello alla distribuzione della produzione a soli 10 minuti.
Con lo spostamento dell'onere del ciclo di vita ML su SageMaker, ha fornito un'infrastruttura ottimizzata e scalabile per l'addestramento e l'implementazione del modello. Il servizio di modelli con SageMaker ci ha aiutato a fare previsioni in tempo reale con latenze di millisecondi e capacità di monitoraggio. Abbiamo utilizzato Terraform per la facilità di installazione e per gestire l'infrastruttura.
I passaggi successivi per questa pipeline sarebbero migliorare la pipeline di addestramento del modello con funzionalità di riaddestramento pianificate o basate sul rilevamento della deriva del modello, supporto della distribuzione shadow o test A/B per una distribuzione del modello più rapida e qualificata e tracciamento della derivazione ML. Abbiamo anche in programma di valutare Pipeline di Amazon SageMaker perché l'integrazione con GitLab è ora supportata.
Le lezioni apprese
Come parte della creazione di questa soluzione, abbiamo appreso che dovresti generalizzare presto, ma non generalizzare eccessivamente. Quando abbiamo terminato per la prima volta la progettazione dell'architettura, abbiamo cercato di creare e applicare modelli di codice per il codice del modello come best practice. Tuttavia, era così presto nel processo di sviluppo che i modelli erano troppo generalizzati o troppo dettagliati per essere riutilizzabili per modelli futuri.
Dopo aver consegnato il primo modello attraverso la pipeline, i modelli sono usciti naturalmente sulla base delle intuizioni del nostro lavoro precedente. Una pipeline non può fare tutto dal primo giorno.
La sperimentazione e la produzione del modello hanno spesso requisiti molto diversi (o talvolta anche contrastanti). È fondamentale bilanciare questi requisiti fin dall'inizio come squadra e stabilire le priorità di conseguenza.
Inoltre, potresti non aver bisogno di tutte le funzionalità di un servizio. L'utilizzo delle funzionalità essenziali di un servizio e il design modulare sono fondamentali per uno sviluppo più efficiente e una pipeline flessibile.
Conclusione
In questo post, abbiamo mostrato come abbiamo creato una soluzione MLOps utilizzando SageMaker e Amazon MWAA che ha automatizzato il processo di distribuzione dei modelli alla produzione, con un intervento manuale minimo da parte dei data scientist. Ti invitiamo a valutare vari servizi AWS come SageMaker, Amazon MWAA, Amazon S3 e Amazon ECR per creare una soluzione MLOps completa.
*Apache, Apache Airflow e Airflow sono marchi o marchi registrati di Apache Software Foundation negli Stati Uniti e/o in altri paesi.
Informazioni sugli autori
 Deepak Mettem è Senior Engineering Manager in VMware, Carbon Black Unit. Lui e il suo team lavorano alla creazione di applicazioni e servizi basati sullo streaming altamente disponibili, scalabili e resilienti per offrire ai clienti soluzioni basate sull'apprendimento automatico in tempo reale. Lui e il suo team sono anche responsabili della creazione degli strumenti necessari ai data scientist per creare, addestrare, distribuire e convalidare i loro modelli ML in produzione.
Deepak Mettem è Senior Engineering Manager in VMware, Carbon Black Unit. Lui e il suo team lavorano alla creazione di applicazioni e servizi basati sullo streaming altamente disponibili, scalabili e resilienti per offrire ai clienti soluzioni basate sull'apprendimento automatico in tempo reale. Lui e il suo team sono anche responsabili della creazione degli strumenti necessari ai data scientist per creare, addestrare, distribuire e convalidare i loro modelli ML in produzione.
 Mahima Agarwal è un Machine Learning Engineer in VMware, Carbon Black Unit.
Mahima Agarwal è un Machine Learning Engineer in VMware, Carbon Black Unit.
Lavora alla progettazione, costruzione e sviluppo dei componenti principali e dell'architettura della piattaforma di machine learning per la SBU CB di VMware.
 Vamshi Krishna Enabothala è Sr. Applied AI Specialist Architect presso AWS. Lavora con clienti di diversi settori per accelerare iniziative di dati, analisi e apprendimento automatico ad alto impatto. È appassionato di sistemi di raccomandazione, PNL e aree di visione artificiale in AI e ML. Al di fuori del lavoro, Vamshi è un appassionato di RC, costruisce attrezzature RC (aerei, automobili e droni) e ama anche il giardinaggio.
Vamshi Krishna Enabothala è Sr. Applied AI Specialist Architect presso AWS. Lavora con clienti di diversi settori per accelerare iniziative di dati, analisi e apprendimento automatico ad alto impatto. È appassionato di sistemi di raccomandazione, PNL e aree di visione artificiale in AI e ML. Al di fuori del lavoro, Vamshi è un appassionato di RC, costruisce attrezzature RC (aerei, automobili e droni) e ama anche il giardinaggio.
 Sahil Thapar è un Enterprise Solutions Architect. Lavora con i clienti per aiutarli a creare applicazioni altamente disponibili, scalabili e resilienti nel cloud AWS. Attualmente si occupa di container e soluzioni di machine learning.
Sahil Thapar è un Enterprise Solutions Architect. Lavora con i clienti per aiutarli a creare applicazioni altamente disponibili, scalabili e resilienti nel cloud AWS. Attualmente si occupa di container e soluzioni di machine learning.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :È
- $ SU
- 1
- 10
- 100
- 7
- 8
- a
- Chi siamo
- accelerare
- accesso
- accessibile
- di conseguenza
- conti
- raggiunto
- operanti in
- aciclico
- aggiunta
- aggiuntivo
- Informazioni aggiuntive
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- AI
- Algoritmi
- Tutti
- consente
- Amazon
- Amazon Sage Maker
- .
- analitica
- ed
- ovunque
- Apache
- api
- Applicazioni
- applicazioni
- applicato
- AI applicata
- approvazione
- architettura
- SONO
- aree
- AS
- aspetto
- At
- attacchi
- autore
- auto
- Automatizzata
- automatizza
- disponibilità
- disponibile
- evitare
- AWS
- BACKEND
- Equilibrio
- basato
- basic
- BE
- perché
- Inizio
- vantaggi
- MIGLIORE
- Meglio
- fra
- Nero
- Bloccare
- Branch di società
- portare
- costruire
- Costruzione
- costruito
- onere
- by
- Materiale
- non può
- funzionalità
- carbonio
- auto
- Custodie
- CB
- certo
- Modifiche
- canali
- bambino
- ha scelto
- Cloud
- Cluster
- codice
- collezione
- Comunicazione
- rispetto
- completamento di una
- componenti
- Calcolare
- computer
- Visione computerizzata
- comportamenti
- Configurazione
- configurazioni
- Conflitto
- confusione
- Considerazioni
- consumare
- consumato
- Contenitore
- Tecnologie Container
- continuamente
- Comodo
- Nucleo
- potuto
- paesi
- CPU
- creare
- creato
- crea
- Creazione
- critico
- cruciale
- Attualmente
- costume
- Clienti
- personalizzare
- attacchi informatici
- GIORNO
- alle lezioni
- cruscotto
- dati
- scienziato di dati
- giorno
- definito
- consegna
- schierare
- schierato
- distribuzione
- deployment
- implementazioni
- Distribuisce
- Design
- progettato
- progettazione
- dettagliati
- dettagli
- rivelazione
- Dev
- sviluppato
- in via di sviluppo
- Mercato
- diverso
- direttamente
- discutere
- discusso
- docker
- Dont
- giù
- Droni
- ogni
- In precedenza
- Presto
- facilità d'uso
- efficiente
- o
- emergenti del mondo
- enable
- abilitato
- Abilita
- incoraggiare
- da un capo all'altro
- endpoint
- ingegnere
- Ingegneria
- Impresa
- Enterprise Solutions
- appassionato
- ambienti
- usate
- essential
- Etere (ETH)
- valutare
- valutato
- la valutazione
- valutazione
- valutazioni
- Anche
- Evento
- Ogni
- qualunque cosa
- esempio
- Espandere
- estendendo
- f1
- facilitare
- Fallimento
- lontano
- più veloce
- caratteristica
- Caratteristiche
- pochi
- File
- Nome
- flessibile
- Focus
- concentrato
- si concentra
- i seguenti
- Nel
- formato
- da
- pieno
- spettro completo
- completamente
- function
- funzioni
- ulteriormente
- futuro
- generato
- ottenere
- buono
- Gruppo
- Avere
- avendo
- Aiuto
- aiutato
- aiuta
- Alta
- Alte prestazioni
- vivamente
- di hosting
- Come
- Tuttavia
- HTML
- http
- HTTPS
- IAM
- ID
- ideale
- identificato
- identificare
- Identità
- Immagine
- immagini
- realizzare
- implementazione
- implementato
- in
- includere
- inclusi
- Compreso
- informazioni
- Infrastruttura
- iniziative
- intuizioni
- integrare
- integrato
- Integra
- integrazione
- interagire
- intervento
- invoca
- coinvolto
- da solo
- IT
- SUO
- Lavoro
- Offerte di lavoro
- jpg
- mantenere
- Le
- Tasti
- Latenza
- strato
- imparato
- apprendimento
- Lezioni
- Lezioni apprese
- Consente di
- Livello
- ciclo di vita
- piace
- piccolo
- caricare
- Basso
- macchina
- machine learning
- Principale
- mantenere
- mantiene
- manutenzione
- make
- gestire
- gestito
- gestione
- direttore
- gestisce
- gestione
- Manuale
- Matrice
- Memorie
- menzionato
- messaggi
- di messaggistica
- Metrica
- forza
- millisecondo
- verbale
- ML
- MLOp
- modello
- modelli
- moderno
- Monitorare
- monitoraggio
- Scopri di più
- più efficiente
- multiplo
- Nome
- naturalmente
- necessaria
- Bisogno
- New
- GENERAZIONE
- nlp
- Rumore
- notifica
- notifiche
- numero
- of
- offerta
- Offerte
- on
- ONE
- operativa
- Operatori
- ottimizzati
- Opzioni
- orchestrato
- Organizzato
- Altro
- al di fuori
- complessivo
- pacchetto
- Packages
- imballaggio
- parte
- Passi
- Di passaggio
- appassionato
- sentiero
- performance
- autorizzazione
- conduttura
- piano
- Planes
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- politica
- Post
- pratica
- Previsioni
- precedente
- Dare priorità
- processi
- Prodotto
- Produzione
- progetto
- progetti
- corretto
- protezione
- purché
- fornitore
- fornisce
- pubblicare
- pubblicato
- Pubblica
- editoriale
- fini
- qualificato
- gamma
- tempo reale
- Consigli
- Ridotto
- di cui
- registrato
- registro
- Relazioni
- a distanza
- Rinomato
- deposito
- richiesto
- richieste
- necessario
- Requisiti
- riparazioni
- elastico
- risposta
- responsabile
- Risultati
- riqualificazione
- riutilizzabile
- ruoli
- Correre
- corridore
- sagemaker
- stesso
- scalabile
- scala
- programma
- in programma
- Scienziato
- scienziati
- Secondo
- sezioni
- Settori
- problemi di
- anziano
- separato
- serverless
- Server
- servizio
- Servizi
- servizio
- set
- flessibile.
- Shadow
- MUTEVOLE
- dovrebbero
- mostrato
- Un'espansione
- allentato
- So
- finora
- Software
- soluzione
- Soluzioni
- alcuni
- Fonte
- codice sorgente
- specialista
- specifico
- specificato
- Spettro
- Riflettore
- Stage
- tappe
- Standard
- inizia a
- inizio
- stati
- Passi
- conservazione
- Strategia
- Streaming
- snellire
- successivo
- Con successo
- tale
- supporto
- supportato
- superficie
- SISTEMI DI TRATTAMENTO
- TAG
- Fai
- task
- team
- modelli
- Terraform
- Testing
- che
- I
- loro
- Li
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- minacce
- tre
- Attraverso
- per tutto
- portata
- tempo
- timestamp
- a
- insieme
- pure
- strumenti
- top
- argomento
- pista
- Tracking
- marchi
- traffico
- Treni
- allenato
- Training
- innescare
- innescato
- TURNO
- per
- unità
- Unito
- Stati Uniti
- Aggiornamenti
- us
- Impiego
- uso
- caso d'uso
- Utente
- utenti
- CONVALIDARE
- convalida
- variabili
- vario
- versione
- potenzialmente
- visione
- visualizzare
- vmware
- volume
- Modo..
- WELL
- Che
- se
- quale
- largo
- Vasta gamma
- con
- entro
- senza
- Lavora
- flusso di lavoro
- flussi di lavoro
- lavori
- sarebbe
- zefiro
- Codice postale
- zone