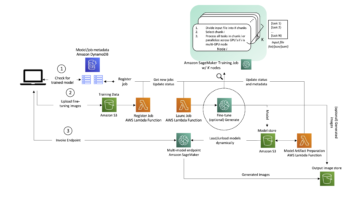
I grandi modelli di trasformatori basati sull'attenzione hanno ottenuto enormi guadagni sull'elaborazione del linguaggio naturale (NLP). Tuttavia, l'addestramento da zero di queste gigantesche reti richiede un'enorme quantità di dati e di calcolo. Per i set di dati NLP più piccoli, una strategia semplice ma efficace consiste nell'utilizzare un trasformatore pre-addestrato, solitamente addestrato in modo non supervisionato su set di dati molto grandi, e metterlo a punto sul set di dati di interesse. Abbracciare il viso mantiene un grande zoo modello di questi trasformatori pre-addestrati e li rende facilmente accessibili anche agli utenti inesperti.
Tuttavia, la messa a punto di questi modelli richiede comunque conoscenze specialistiche, poiché sono piuttosto sensibili ai relativi iperparametri, come la velocità di apprendimento o la dimensione del batch. In questo post, mostriamo come ottimizzare questi iperparametri con il framework open-source Sintonizzazione per l'ottimizzazione degli iperparametri distribuiti (HPO). Syne Tune ci consente di trovare una migliore configurazione dell'iperparametro che ottiene un miglioramento relativo compreso tra l'1 e il 4% rispetto agli iperparametri predefiniti sui popolari COLLA set di dati di riferimento. Anche la scelta del modello pre-addestrato stesso può essere considerata un iperparametro e quindi essere selezionata automaticamente da Syne Tune. Su un problema di classificazione del testo, ciò porta a un ulteriore aumento della precisione di circa il 5% rispetto al modello predefinito. Tuttavia, possiamo automatizzare più decisioni che un utente deve prendere; lo dimostriamo esponendo anche il tipo di istanza come un iperparametro che utilizzeremo in seguito per distribuire il modello. Selezionando il giusto tipo di istanza, possiamo trovare configurazioni che bilanciano in modo ottimale costi e latenza.
Per un'introduzione a Syne Tune, fare riferimento a Esegui lavori di ottimizzazione di iperparametri distribuiti e architettura neurale con Syne Tune.
Ottimizzazione degli iperparametri con Syne Tune
Useremo il COLLA suite di benchmark, composta da nove set di dati per attività di comprensione del linguaggio naturale, come il riconoscimento dell'implicazione testuale o l'analisi del sentimento. Per questo, adattiamo Hugging Face's run_glue.py copione di formazione. I set di dati GLUE sono dotati di un set di formazione e valutazione predefinito con etichette, nonché di un set di test di resistenza senza etichette. Pertanto, dividiamo il set di addestramento in set di addestramento e convalida (divisione 70%/30%) e utilizziamo il set di valutazione come set di dati del test di controllo. Inoltre, aggiungiamo un'altra funzione di callback all'API Trainer di Hugging Face che riporta le prestazioni di convalida dopo ogni epoca a Syne Tune. Vedere il codice seguente:
Iniziamo con l'ottimizzazione dei tipici iperparametri di addestramento: la velocità di apprendimento, il rapporto di riscaldamento per aumentare la velocità di apprendimento e la dimensione del batch per la messa a punto di un BERT preaddestrato (bert-base-cased), che è il modello predefinito nell'esempio Hugging Face. Vedere il codice seguente:
Come nostro metodo HPO, utilizziamo ASHA, che campiona le configurazioni degli iperparametri in modo uniforme in modo casuale e interrompe in modo iterativo la valutazione delle configurazioni con prestazioni scadenti. Sebbene metodi più sofisticati utilizzino un modello probabilistico della funzione obiettivo, come BO o MoBster, utilizziamo ASHA per questo post perché viene fornito senza alcuna ipotesi sullo spazio di ricerca.
Nella figura seguente, confrontiamo il miglioramento relativo dell'errore di test rispetto alla configurazione dell'iperparametro predefinito di Hugging Faces.
![]()
Per semplicità, limitiamo il confronto a MRPC, COLA e STSB, ma osserviamo anche miglioramenti simili anche per altri set di dati GLUE. Per ogni set di dati, eseguiamo ASHA su un singolo ml.g4dn.xlarge Amazon Sage Maker istanza con un budget di runtime di 1,800 secondi, che corrisponde rispettivamente a circa 13, 7 e 9 valutazioni di funzioni complete su questi set di dati. Per tenere conto della casualità intrinseca del processo di addestramento, ad esempio causata dal campionamento mini-batch, eseguiamo sia ASHA che la configurazione predefinita per cinque ripetizioni con un seme indipendente per il generatore di numeri casuali e riportiamo la deviazione media e standard del miglioramento relativo attraverso le ripetizioni. Possiamo vedere che, in tutti i set di dati, possiamo effettivamente migliorare le prestazioni predittive dell'1-3% rispetto alle prestazioni della configurazione predefinita accuratamente selezionata.
Automatizza la selezione del modello pre-addestrato
Possiamo usare HPO non solo per trovare gli iperparametri, ma anche per selezionare automaticamente il giusto modello pre-addestrato. Perché vogliamo farlo? Poiché nessun singolo modello ha prestazioni migliori in tutti i set di dati, dobbiamo selezionare il modello giusto per un set di dati specifico. Per dimostrarlo, valutiamo una gamma di popolari modelli di trasformatori di Hugging Face. Per ogni set di dati, classifichiamo ciascun modello in base alle prestazioni del test. La classifica tra i set di dati (vedere la figura seguente) cambia e non un singolo modello che ottiene il punteggio più alto su ogni set di dati. Come riferimento, mostriamo anche le prestazioni di test assolute di ciascun modello e set di dati nella figura seguente.
Per selezionare automaticamente il modello giusto, possiamo eseguire il cast della scelta del modello come parametri categoriali e aggiungerlo al nostro spazio di ricerca iperparametro:
Sebbene lo spazio di ricerca sia ora più ampio, ciò non significa necessariamente che sia più difficile da ottimizzare. La figura seguente mostra l'errore di test della configurazione meglio osservata (basata sull'errore di convalida) sul set di dati MRPC di ASHA nel tempo quando cerchiamo nello spazio originale (linea blu) (con un modello pre-addestrato basato su BERT ) o nel nuovo spazio di ricerca aumentato (linea arancione). A parità di budget, ASHA è in grado di trovare una configurazione iperparametrica con prestazioni molto migliori nello spazio di ricerca esteso rispetto allo spazio più piccolo.
![]()
Automatizza la selezione del tipo di istanza
In pratica, potremmo non interessarci solo all'ottimizzazione delle prestazioni predittive. Potremmo anche interessarci di altri obiettivi, come tempo di formazione, costo (in dollari), latenza o metriche di equità. Abbiamo anche bisogno di fare altre scelte oltre agli iperparametri del modello, ad esempio selezionando il tipo di istanza.
Sebbene il tipo di istanza non influisca sulle prestazioni predittive, ha un forte impatto sul costo (in dollari), sul runtime di formazione e sulla latenza. Quest'ultimo diventa particolarmente importante quando il modello viene distribuito. Possiamo definire l'HPO come un problema di ottimizzazione multi-obiettivo, in cui miriamo a ottimizzare più obiettivi contemporaneamente. Tuttavia, nessuna singola soluzione ottimizza tutte le metriche contemporaneamente. Invece, miriamo a trovare un insieme di configurazioni che scambino in modo ottimale un obiettivo rispetto all'altro. Questo è chiamato il insieme di Pareto.
Per analizzare ulteriormente questa impostazione, aggiungiamo la scelta del tipo di istanza come iperparametro categoriale aggiuntivo al nostro spazio di ricerca:
Usiamo MO-ASHA, che adatta l'ASHA allo scenario multi-obiettivo utilizzando l'ordinamento non dominato. In ogni iterazione, MO-ASHA seleziona anche per ogni configurazione anche il tipo di istanza su cui vogliamo valutarla. Per eseguire HPO su un insieme eterogeneo di istanze, Syne Tune fornisce il backend SageMaker. Con questo back-end, ogni prova viene valutata come un lavoro di formazione SageMaker indipendente sulla propria istanza. Il numero di lavoratori definisce quanti lavori SageMaker eseguiamo in parallelo in un dato momento. L'ottimizzatore stesso, nel nostro caso MO-ASHA, viene eseguito sulla macchina locale, su un notebook Sagemaker o su un lavoro di formazione SageMaker separato. Vedere il codice seguente:
Le figure seguenti mostrano la latenza rispetto all'errore di test a sinistra e la latenza rispetto al costo a destra per le configurazioni casuali campionate da MO-ASHA (limitiamo l'asse per la visibilità) sul set di dati MRPC dopo averlo eseguito per 10,800 secondi su quattro lavoratori. Il colore indica il tipo di istanza. La linea nera tratteggiata rappresenta l'insieme di Pareto, ovvero l'insieme di punti che dominano tutti gli altri punti in almeno un obiettivo.
Possiamo osservare un compromesso tra latenza ed errore di test, il che significa che la migliore configurazione con l'errore di test più basso non raggiunge la latenza più bassa. In base alle tue preferenze, puoi selezionare una configurazione di iperparametri che sacrifica le prestazioni dei test ma ha una latenza inferiore. Vediamo anche il compromesso tra latenza e costo. Utilizzando un'istanza ml.g4dn.xlarge più piccola, ad esempio, aumentiamo solo marginalmente la latenza, ma paghiamo un quarto del costo di un'istanza ml.g4dn.8xlarge.
Conclusione
In questo post, abbiamo discusso dell'ottimizzazione degli iperparametri per la messa a punto di modelli di trasformatori pre-addestrati da Hugging Face basati su Syne Tune. Abbiamo visto che ottimizzando gli iperparametri come la velocità di apprendimento, la dimensione del batch e il rapporto di riscaldamento, possiamo migliorare la configurazione predefinita accuratamente scelta. Possiamo anche estenderlo selezionando automaticamente il modello pre-addestrato tramite l'ottimizzazione dell'iperparametro.
Con l'aiuto del backend SageMaker di Syne Tune, possiamo trattare il tipo di istanza come un iperparametro. Sebbene il tipo di istanza non influisca sulle prestazioni, ha un impatto significativo sulla latenza e sui costi. Pertanto, lanciando l'HPO come un problema di ottimizzazione multi-obiettivo, siamo in grado di trovare un insieme di configurazioni che scambiano in modo ottimale un obiettivo rispetto all'altro. Se vuoi provarlo tu stesso, dai un'occhiata al nostro quaderno di esempio.
Informazioni sugli autori
![]() Aaron Klein è uno scienziato applicato presso AWS.
Aaron Klein è uno scienziato applicato presso AWS.
![]() Mattia Seeger è un Principal Applied Scientist presso AWS.
Mattia Seeger è un Principal Applied Scientist presso AWS.
![]() David salinas è Sr Applied Scientist presso AWS.
David salinas è Sr Applied Scientist presso AWS.
![]() Emilia Webber si è unito ad AWS subito dopo il lancio di SageMaker e da allora ha cercato di parlarne al mondo! Oltre a creare nuove esperienze ML per i clienti, Emily ama meditare e studiare il buddismo tibetano.
Emilia Webber si è unito ad AWS subito dopo il lancio di SageMaker e da allora ha cercato di parlarne al mondo! Oltre a creare nuove esperienze ML per i clienti, Emily ama meditare e studiare il buddismo tibetano.
![]() Cédric Archambeau è Principal Applied Scientist presso AWS e Fellow dell'European Lab for Learning and Intelligent Systems.
Cédric Archambeau è Principal Applied Scientist presso AWS e Fellow dell'European Lab for Learning and Intelligent Systems.
- Coinsmart. Il miglior scambio di bitcoin e criptovalute d'Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. ACCESSO LIBERO.
- Criptofalco. Radar Altcoin. Prova gratuita.
- Fonte: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- Chi siamo
- Assoluta
- accessibile
- Il mio account
- Raggiungere
- operanti in
- aggiuntivo
- influenzare
- Tutti
- consente
- Sebbene il
- Amazon
- quantità
- .
- analizzare
- Un altro
- api
- applicato
- circa
- architettura
- aumentata
- automatizzare
- automaticamente
- media
- AWS
- Axis
- perché
- Segno di riferimento
- MIGLIORE
- Meglio
- fra
- Al di là di
- Nero
- perno
- Incremento
- budget limitato.
- Costruzione
- che
- Custodie
- ha causato
- scegliere
- scelte
- scelto
- classe
- classificazione
- codice
- Venire
- rispetto
- Calcolare
- Configurazione
- di controllo
- Clienti
- dati
- decisioni
- dimostrare
- schierare
- schierato
- distribuito
- non
- Dollaro
- ogni
- facilmente
- Efficace
- europeo
- valutare
- valutazione
- esempio
- Esperienze
- esperto
- estendere
- Faccia
- Moda
- figura
- i seguenti
- Contesto
- da
- pieno
- function
- ulteriormente
- Inoltre
- generatore
- Aiuto
- qui
- Come
- Tutorial
- Tuttavia
- HTTPS
- Impact
- importante
- competenze
- miglioramento
- Aumento
- studente indipendente
- influenza
- esempio
- Intelligente
- interesse
- IT
- stessa
- Lavoro
- Offerte di lavoro
- congiunto
- conoscenze
- laboratorio
- per il tuo brand
- Lingua
- grandi
- superiore, se assunto singolarmente.
- lanciato
- Leads
- apprendimento
- LIMITE
- linea
- locale
- macchina
- make
- FA
- massiccio
- significato
- metodi
- Metrica
- forza
- ML
- modello
- modelli
- Scopri di più
- multiplo
- Naturale
- necessariamente
- esigenze
- reti
- taccuino
- numero
- Obiettivi d'Esame
- ottenuto
- ottimizzazione
- OTTIMIZZA
- ottimizzazione
- i
- Altro
- proprio
- particolarmente
- Paga le
- performance
- esecuzione
- per favore
- punti
- Popolare
- pratica
- Direttore
- Problema
- processi
- lavorazione
- fornisce
- gamma
- Posizione
- rapporto
- reporter
- Report
- rappresenta
- richiede
- Risultati
- Correre
- running
- stesso
- Scienziato
- Cerca
- secondo
- seme
- selezionato
- sentimento
- set
- regolazione
- mostrare attraverso le sue creazioni
- significativa
- simile
- Un'espansione
- singolo
- Taglia
- soluzione
- sofisticato
- lo spazio
- specifico
- dividere
- Standard
- inizia a
- Regione / Stato
- Ancora
- Strategia
- SISTEMI DI TRATTAMENTO
- task
- test
- I
- il mondo
- perciò
- tempo
- commercio
- Training
- trattare
- enorme
- prova
- e una comprensione reciproca
- us
- uso
- utenti
- generalmente
- utilizzare
- convalida
- visibilità
- wikipedia
- senza
- lavoratori
- mondo
- Trasferimento da aeroporto a Sharm