Abbiamo recentemente ha annunciato supporto per Formazione AWS Lake politiche di controllo degli accessi a grana fine in Amazzone Atena query per i dati archiviati in qualsiasi formato di file supportato utilizzando formati di tabella come Apache Iceberg, Apache Hudi e Apache Hive. AWS Lake Formation consente di definire e applicare policy di accesso a livello di database, tabella e colonna per eseguire query sulle tabelle Iceberg archiviate in Amazon S3. Lake Formation fornisce un livello di autorizzazione e governance sui dati archiviati in Amazon S3. Questa funzionalità richiede l'aggiornamento a Motore Athena versione 3.
Le grandi organizzazioni hanno spesso linee di business (LoB) che operano in autonomia nella gestione dei propri dati aziendali. Rende la condivisione dei dati tra LoB non banale. Queste organizzazioni hanno adottato un modello federato, in cui ogni LoB ha l'autonomia di prendere decisioni sui propri dati. Usano il modello editore/consumatore con un livello di governance centralizzato utilizzato per applicare i controlli di accesso. Se sei interessato a saperne di più sull'architettura data mesh, visita Progetta un'architettura data mesh utilizzando AWS Lake Formation e AWS Glue. Con il motore Athena versione 3, i clienti possono utilizzare gli stessi controlli granulari per framework di dati aperti come Apache Iceberg, Apache Hudi e Apache Hive.
In questo post, approfondiamo un caso d'uso in cui si dispone di un modello produttore/consumatore con condivisione dei dati abilitata per fornire accesso limitato a una tabella Apache Iceberg che il consumatore può interrogare. Discuteremo il filtraggio delle colonne per limitare determinate righe, il filtraggio per limitare l'accesso a livello di colonna, l'evoluzione dello schema e il viaggio nel tempo.
Panoramica della soluzione
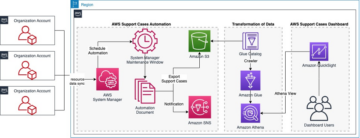
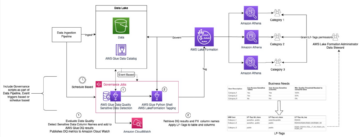
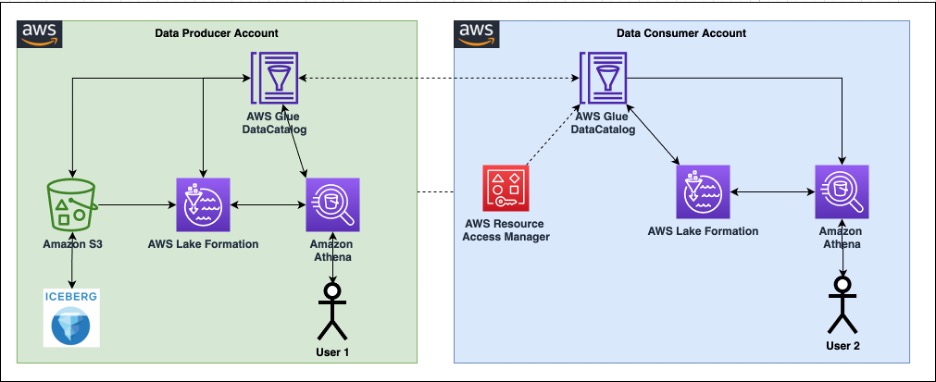
Per illustrare la funzionalità delle autorizzazioni dettagliate per le tabelle Apache Iceberg con Athena e Lake Formation, abbiamo impostato i seguenti componenti:
- Nell'account produttore:
- An Colla AWS Data Catalog per registrare lo schema di una tabella in formato Apache Iceberg
- Lake Formation per fornire un accesso granulare all'account del consumatore
- Athena per verificare i dati dall'account del produttore
- Nel conto del consumatore:
- Gestore dell'accesso alle risorse AWS (AWS RAM) per creare una stretta di mano tra il Data Catalog del produttore e il consumatore
- Lake Formation per fornire un accesso granulare all'account del consumatore
- Athena per verificare i dati dall'account del produttore
Il seguente diagramma illustra l'architettura.
Prerequisiti
Prima di iniziare, assicurati di avere quanto segue:
Configurazione del produttore di dati
In questa sezione, presentiamo i passaggi per configurare il produttore di dati.
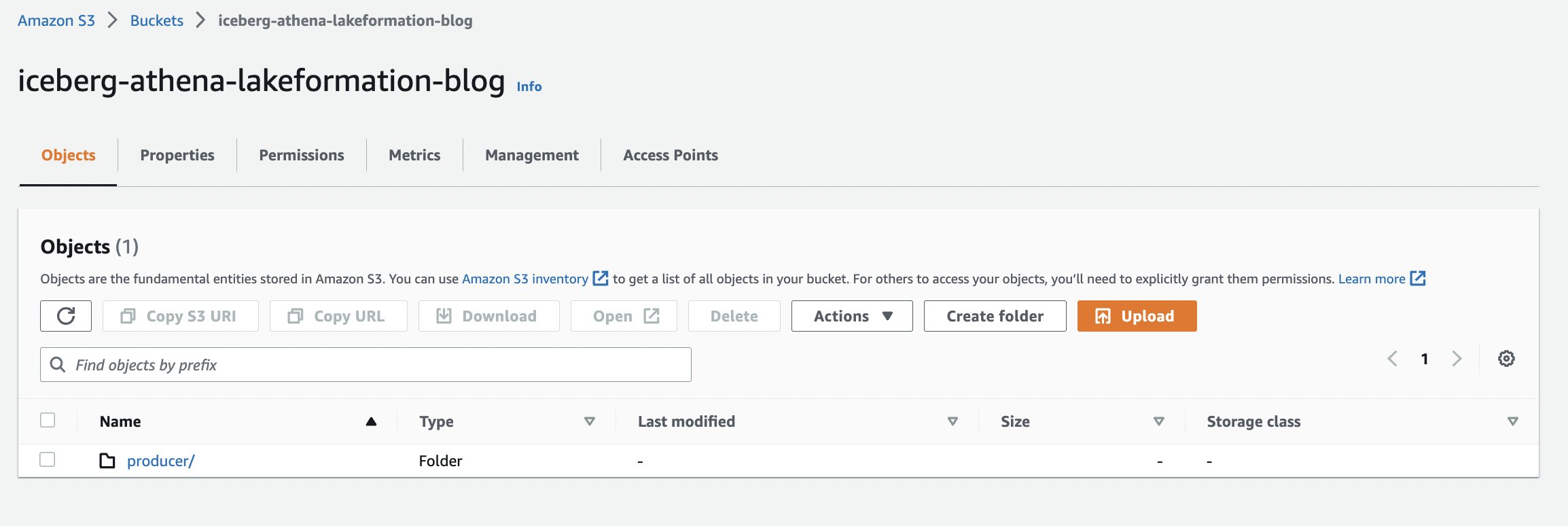
Crea un bucket S3 per archiviare i dati della tabella
Creiamo un nuovo bucket S3 per salvare i dati per la tabella:
- Sulla console Amazon S3, crea un bucket S3 con un nome univoco (per questo post, usiamo
iceberg-athena-lakeformation-blog). - Crea la cartella producer all'interno del bucket da utilizzare per la tabella.
Registrare il percorso S3 memorizzando la tabella utilizzando Lake Formation
Registriamo il percorso completo S3 in Lake Formation:
- Passare alla console Lake Formation.
- Se accedi per la prima volta, ti verrà chiesto di creare un utente amministratore.
- Nel riquadro di navigazione, sotto Registrati e ingerisciscegli Posizioni del data lake.
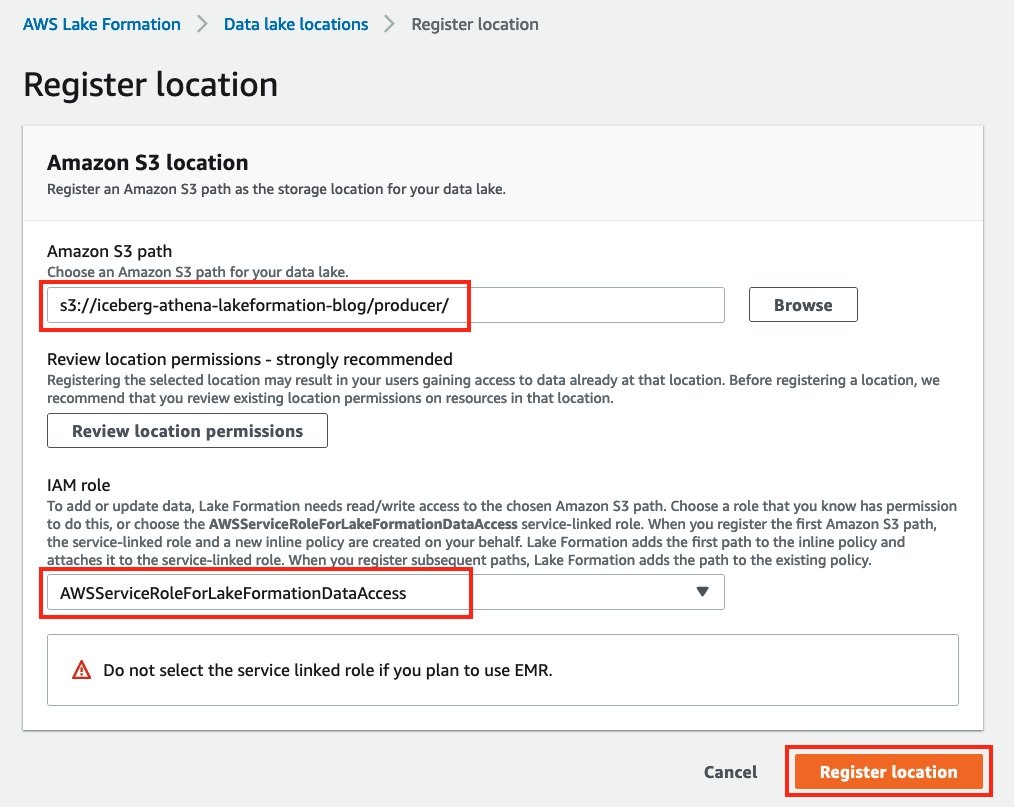
- Scegli Registra posizionee fornisci il percorso del bucket S3 che hai creato in precedenza.
- Scegli
AWSServiceRoleForLakeFormationDataAccessper Ruolo IAM.
Per ulteriori informazioni sui ruoli, fare riferimento a Requisiti per i ruoli utilizzati per registrare le posizioni.
Se hai abilitato la crittografia del tuo bucket S3, devi fornire le autorizzazioni affinché Lake Formation esegua operazioni di crittografia e decrittografia. Fare riferimento a Registrazione di una posizione Amazon S3 crittografata per l'orientamento.
- Scegli Registra posizione.
Crea un tavolo Iceberg usando Athena
Ora creiamo la tabella utilizzando il formato Athena supportato dal formato Apache Iceberg:
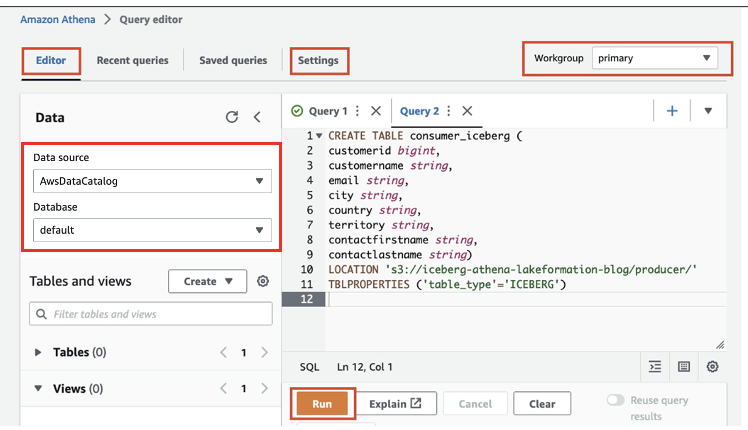
- Sulla console Athena, scegli Editor di query nel pannello di navigazione.
- Se stai usando Athena per la prima volta, sotto Impostazioni profiloscegli gestire e inserisci la posizione del bucket S3 che hai creato in precedenza (
iceberg-athena-lakeformation-blog/producer). - Scegli Risparmi.
- Nell'editor di query, inserisci la query seguente (sostituisci la posizione con il bucket S3 che hai registrato con Lake Formation). Si noti che utilizziamo il database predefinito, ma è possibile utilizzare qualsiasi altro database.
- Scegli Correre.
Condividi il tavolo con l'account consumatore
Per illustrare la funzionalità, implementiamo i seguenti scenari:
- Fornire l'accesso alle colonne selezionate
- Fornire l'accesso alle righe selezionate in base a un filtro
Completa i seguenti passi:
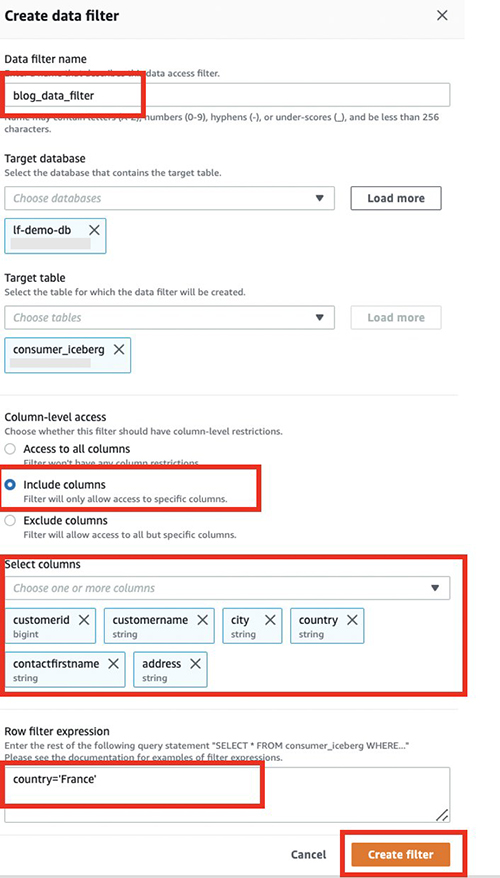
- Nella console Lake Formation, nel riquadro di navigazione sotto Catalogo datiscegli Filtri dati.
- Scegli Crea nuovo filtro.
- Nel Nome del filtro dati, accedere
blog_data_filter. - Nel Database di destinazione, accedere
lf-demo-db. - Nel Tabella di destinazione, accedere
consumer_iceberg. - Nel Accesso a livello di colonna, selezionare Includi colonne.
- Scegli le colonne da condividere con il consumatore:
country, address, contactfirstname, city, customerid,edcustomername. - Nel Espressione del filtro di riga, inserisci il filtro
country='France'. - Scegli Crea un filtro.
Ora concediamo l'accesso all'account consumatore su consumer_iceberg tabella.
- Nel pannello di navigazione, scegli tavoli.
- Seleziona la tabella consumer_iceberg e scegli Grant sul Azioni menu.
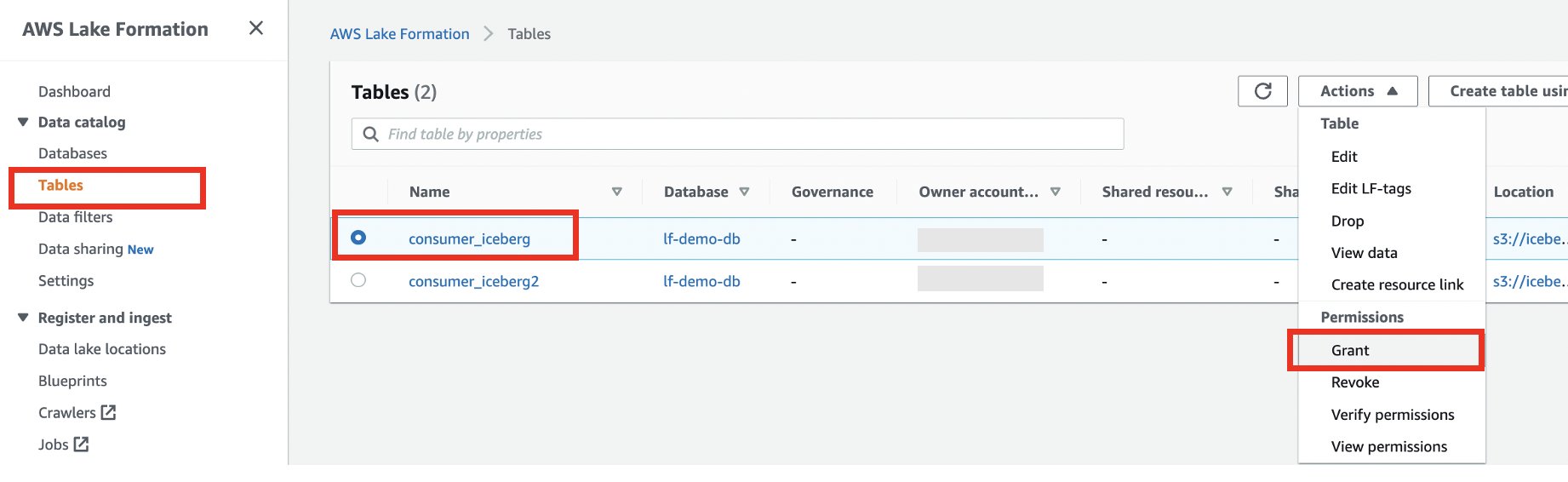
- Seleziona Conti esterni.
- Immettere l'ID dell'account esterno.
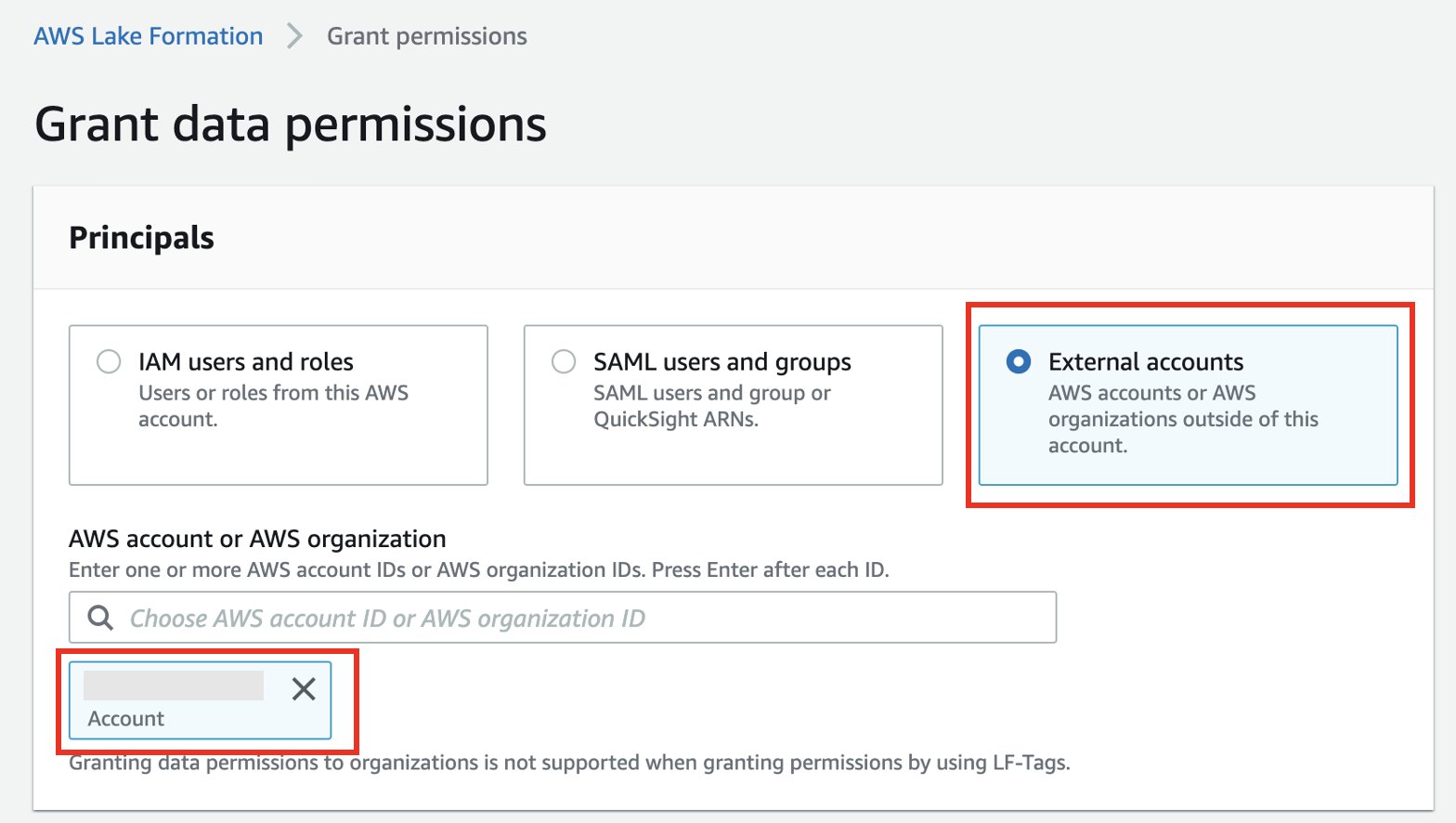
- Seleziona Risorse del catalogo dati con nome.
- Scegli il database e la tabella.
- Nel Filtri dati, scegli il filtro dati che hai creato.
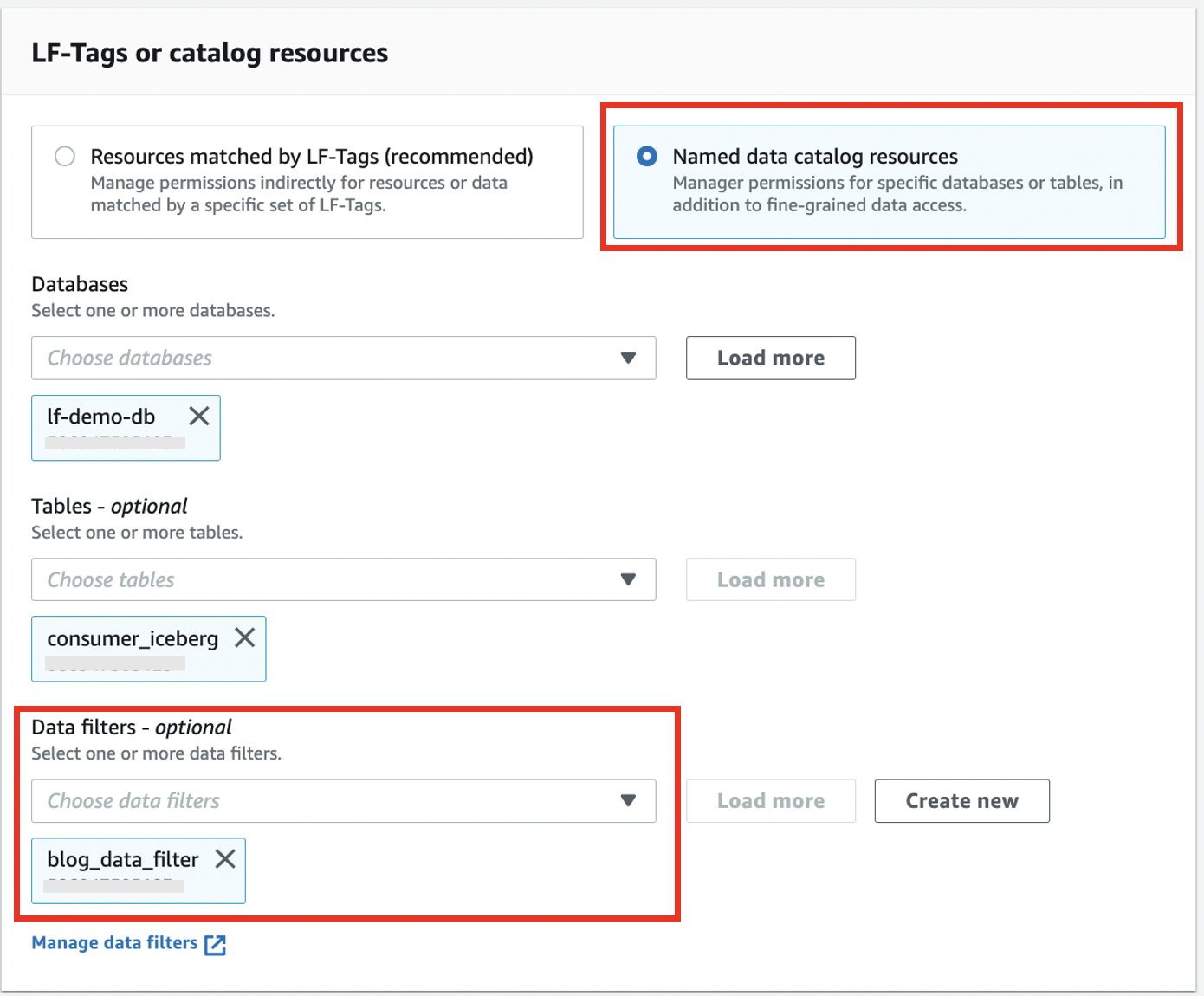
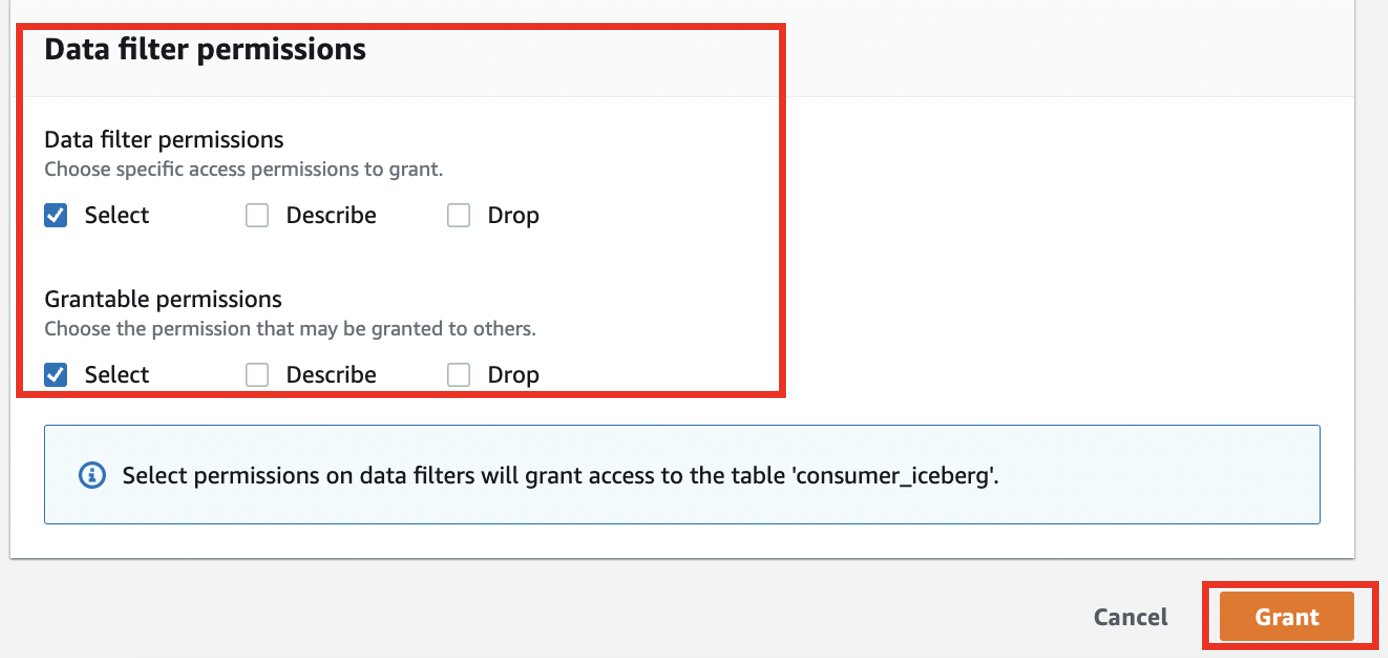
- Nel Autorizzazioni del filtro dati ed Autorizzazioni concedibili, selezionare Seleziona.
- Scegli Grant.
Configurazione del consumatore di dati
Per configurare il consumatore di dati, accettiamo la condivisione delle risorse e creiamo una tabella utilizzando AWS RAM e Lake Formation. Completa i seguenti passaggi:
- Accedi all'account consumer e vai alla console AWS RAM.
- Sotto Condiviso con me nel pannello di navigazione, scegli Condivisioni di risorse.
- Scegli la tua condivisione di risorse.
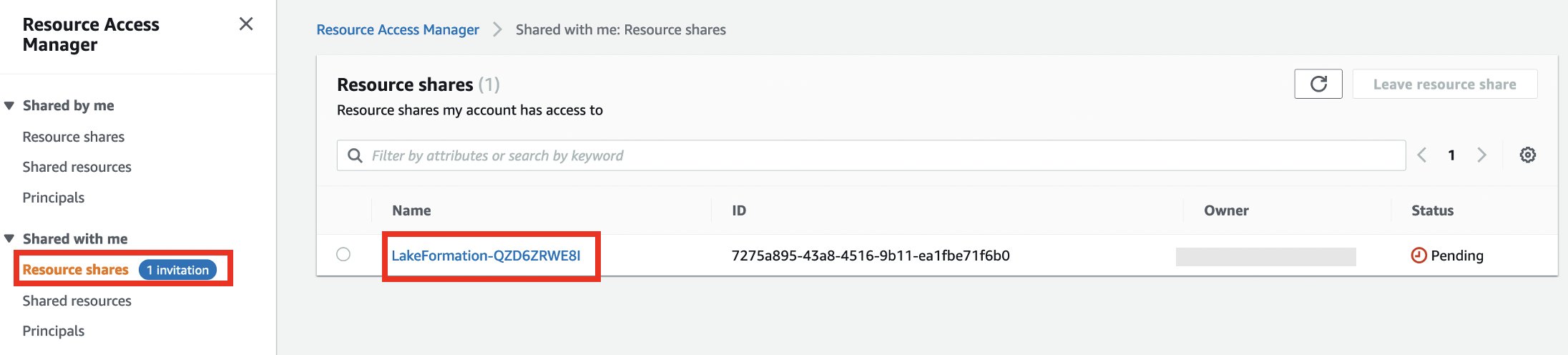
- Scegli Accetta la condivisione delle risorse.
- Prendere nota del nome della condivisione di risorse da utilizzare nei passaggi successivi.
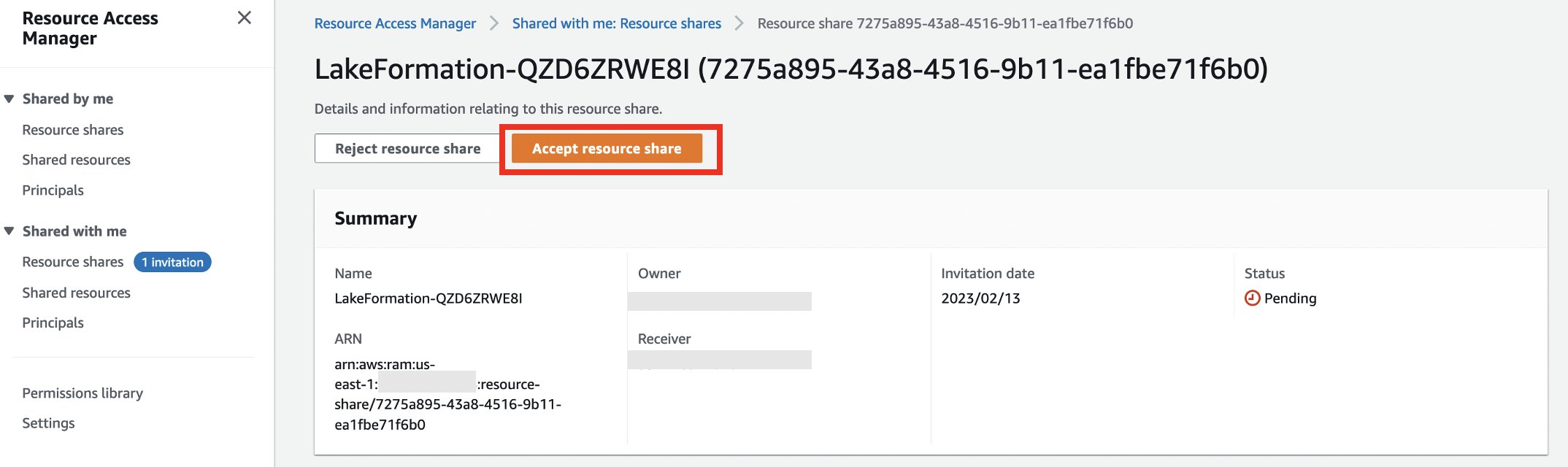
- Passare alla console Lake Formation.
- Se accedi per la prima volta, ti verrà chiesto di creare un utente amministratore.
- Scegli Database nel riquadro di navigazione, quindi scegli il tuo database.
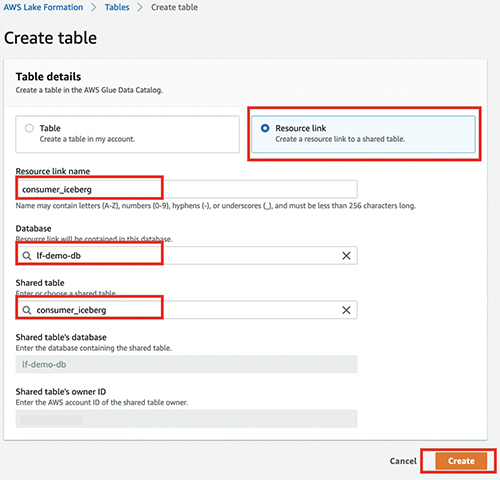
- Sulla Azioni menù, scegliere Crea collegamento alla risorsa.

- Nel Nome del collegamento alla risorsa, inserisci il nome del tuo collegamento alla risorsa (ad esempio,
consumer_iceberg). - Scegli il database e la tabella condivisa.
- Scegli Creare.
Convalida la soluzione
Ora possiamo eseguire diverse operazioni sulle tabelle per convalidare i controlli di accesso granulari.
Operazione di inserimento
Inseriamo i dati nel file consumer_iceberg nell'account produttore e verificare che il filtro dei dati funzioni come previsto nell'account consumatore.
- Accedi all'account produttore.
- Sulla console Athena, scegli Editor di query nel pannello di navigazione.
- Utilizzare il codice SQL seguente per scrivere e inserire dati nella tabella Iceberg. Utilizzare l'editor di query per eseguire una query alla volta. È possibile evidenziare/selezionare una query alla volta e fare clic su "Esegui"/"Esegui di nuovo:

- Utilizzare il seguente codice SQL per leggere e selezionare i dati nella tabella Iceberg:
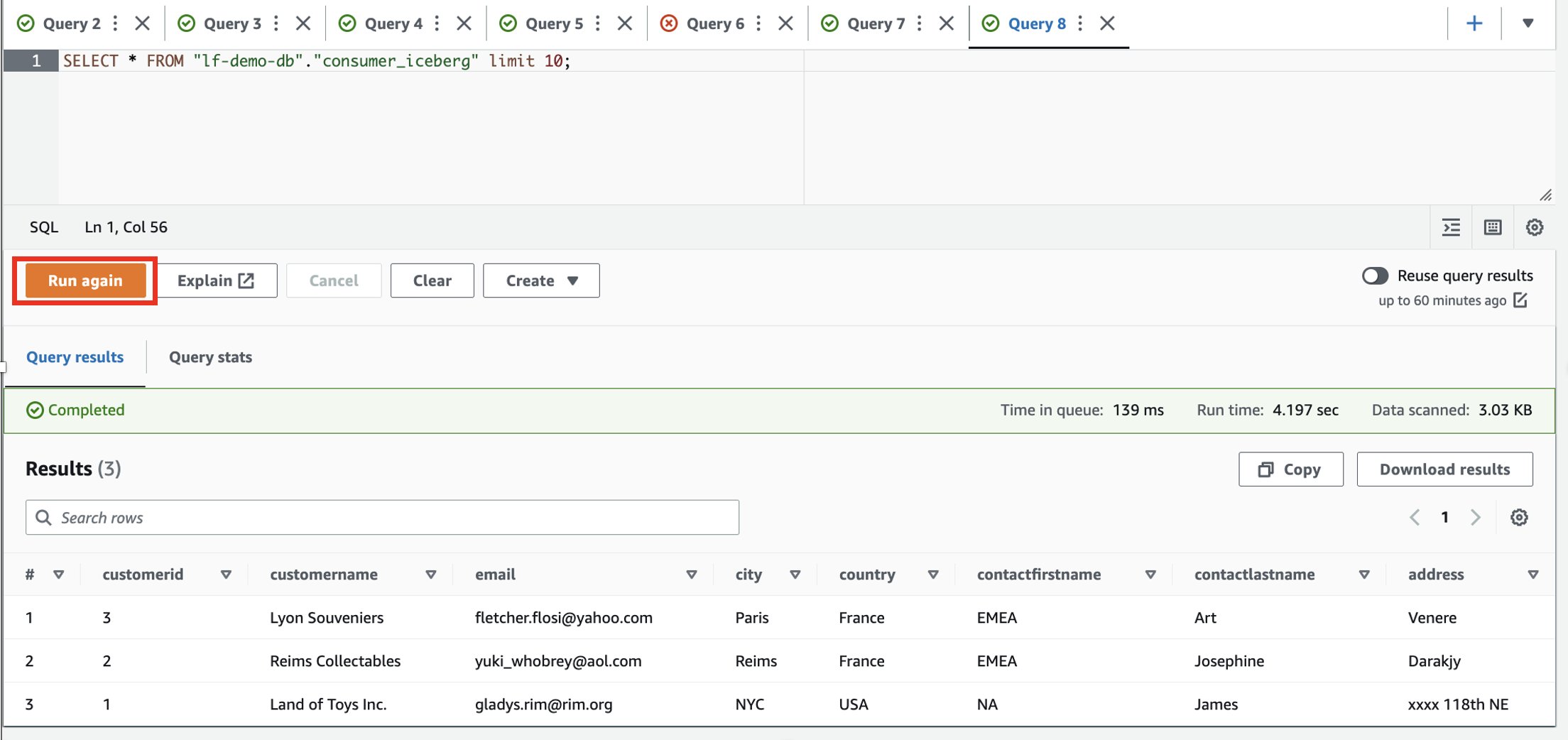
- Accedi all'account consumatore.
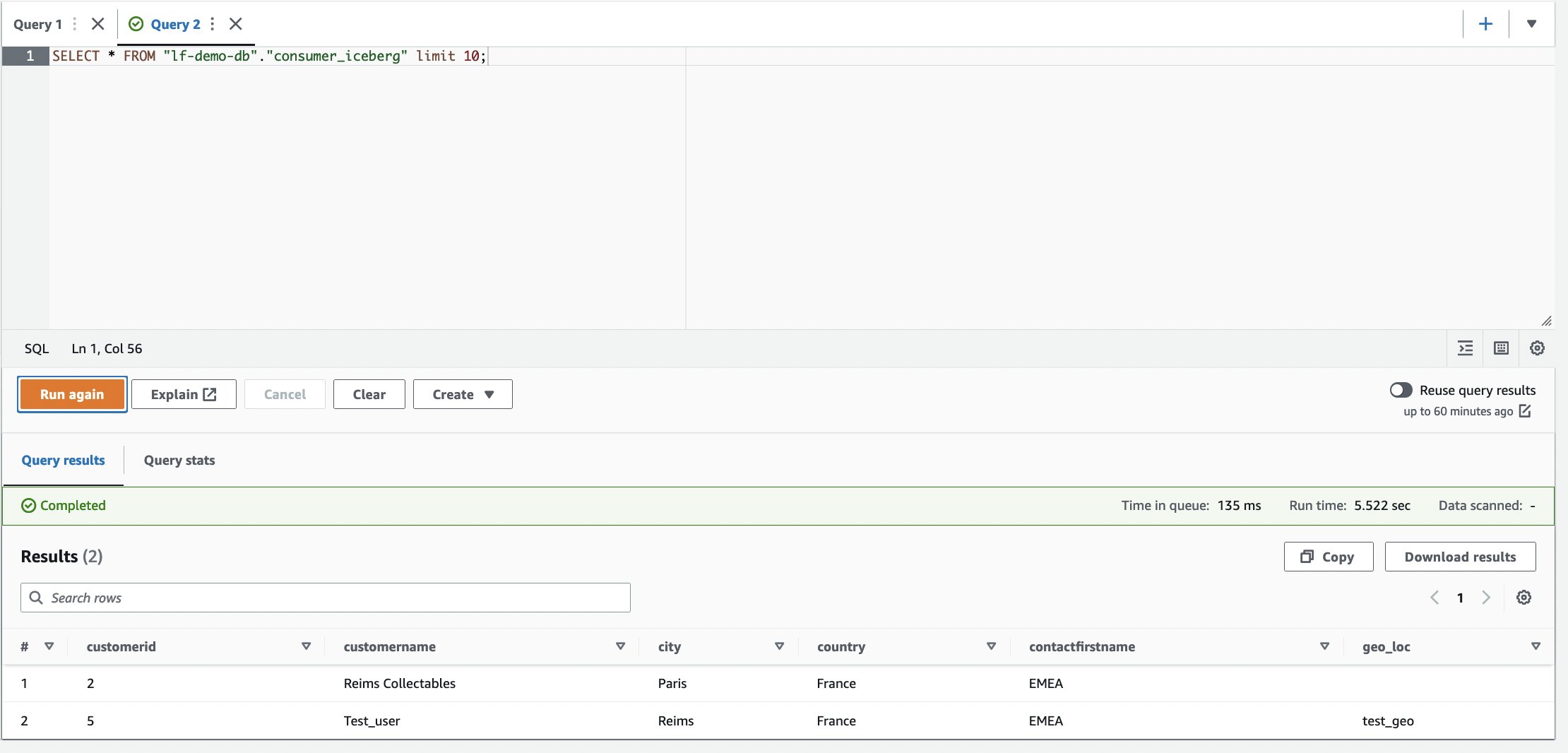
- Nell'editor di query Athena, esegui la seguente query SELECT sulla tabella condivisa:
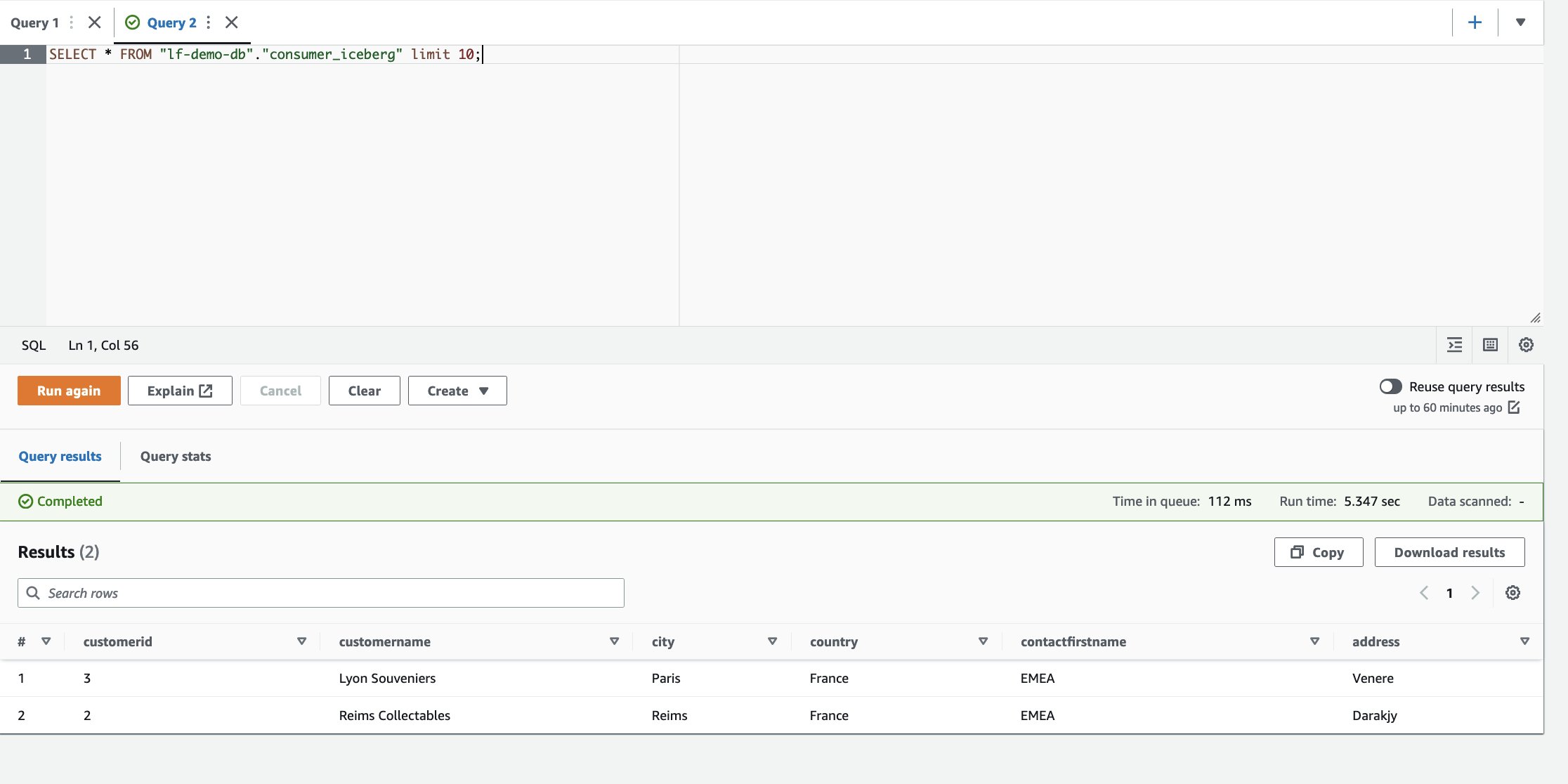
In base ai filtri, il consumatore ha visibilità su un sottoinsieme di colonne e righe in cui il paese è la Francia.
Operazioni di aggiornamento/eliminazione
Ora aggiorniamo una delle righe ed eliminiamone una dal set di dati condiviso con il consumatore.
- Accedi all'account produttore.
- Aggiornanento
city='Paris' WHERE city='Reims'ed elimina la rigacustomerid = 3;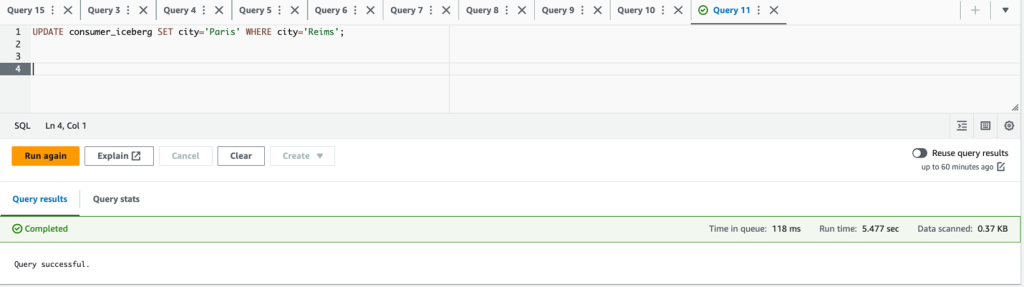

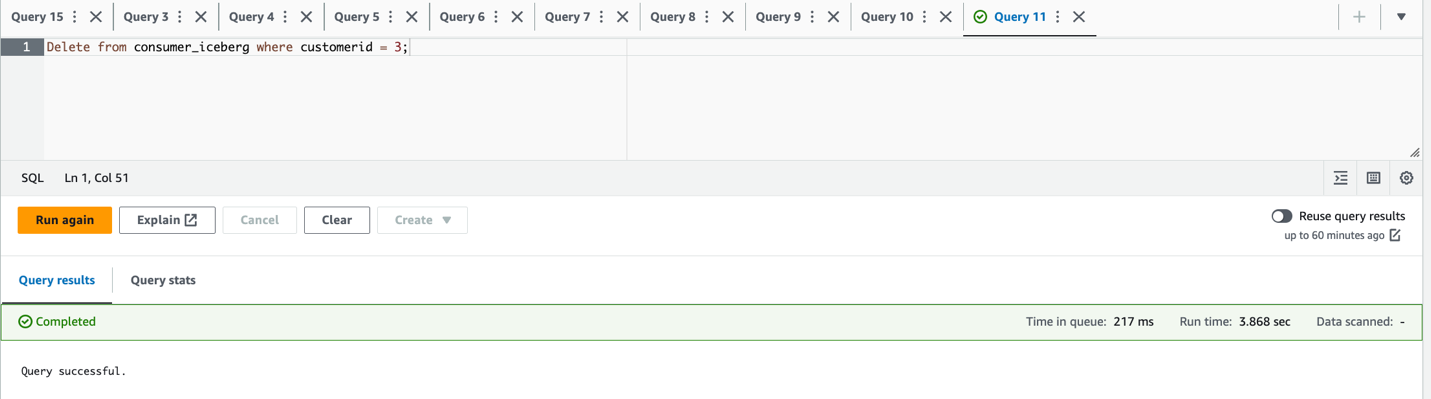
- Verificare il set di dati aggiornato ed eliminato:
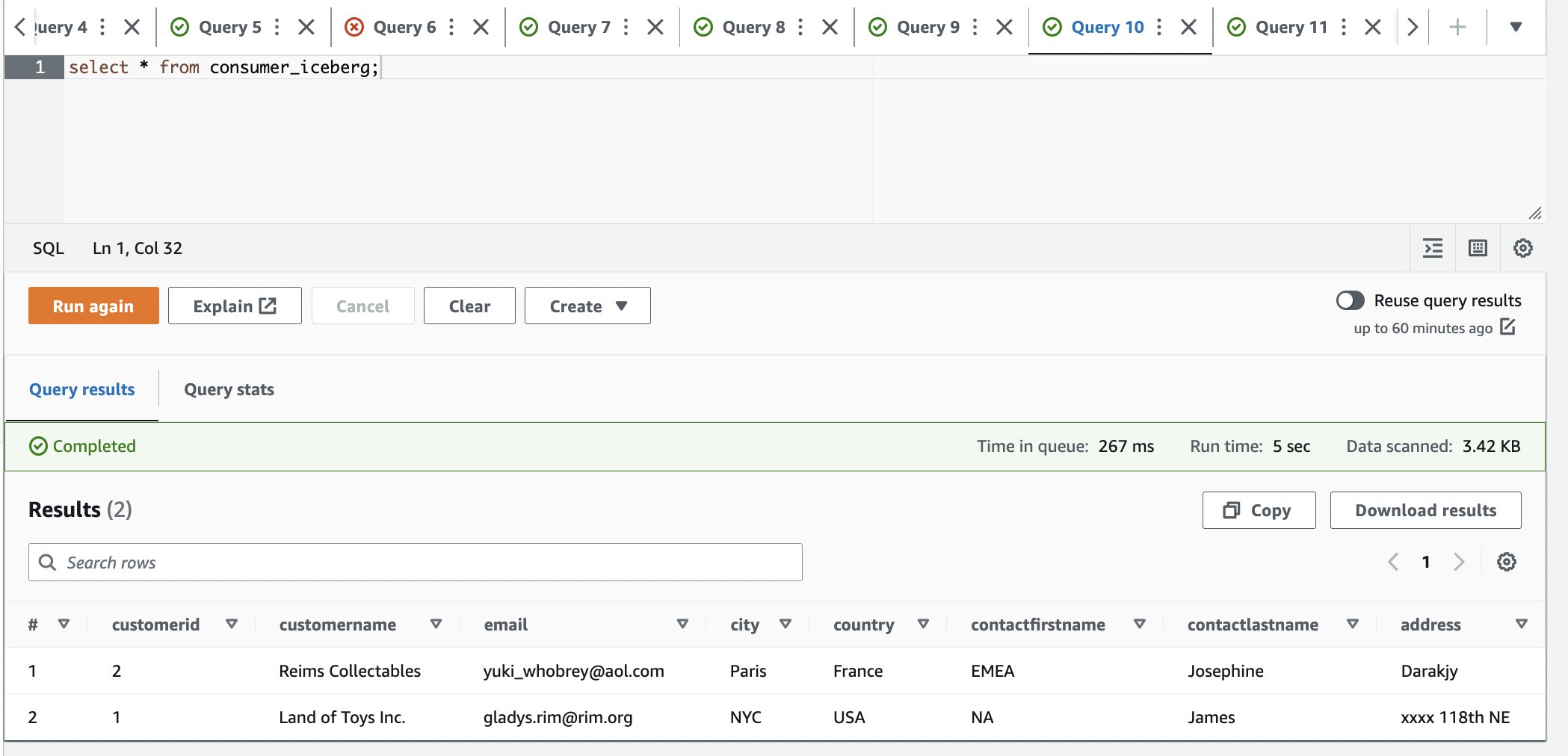
- Accedi all'account consumatore.
- Nell'editor di query Athena, esegui la seguente query SELECT sulla tabella condivisa:
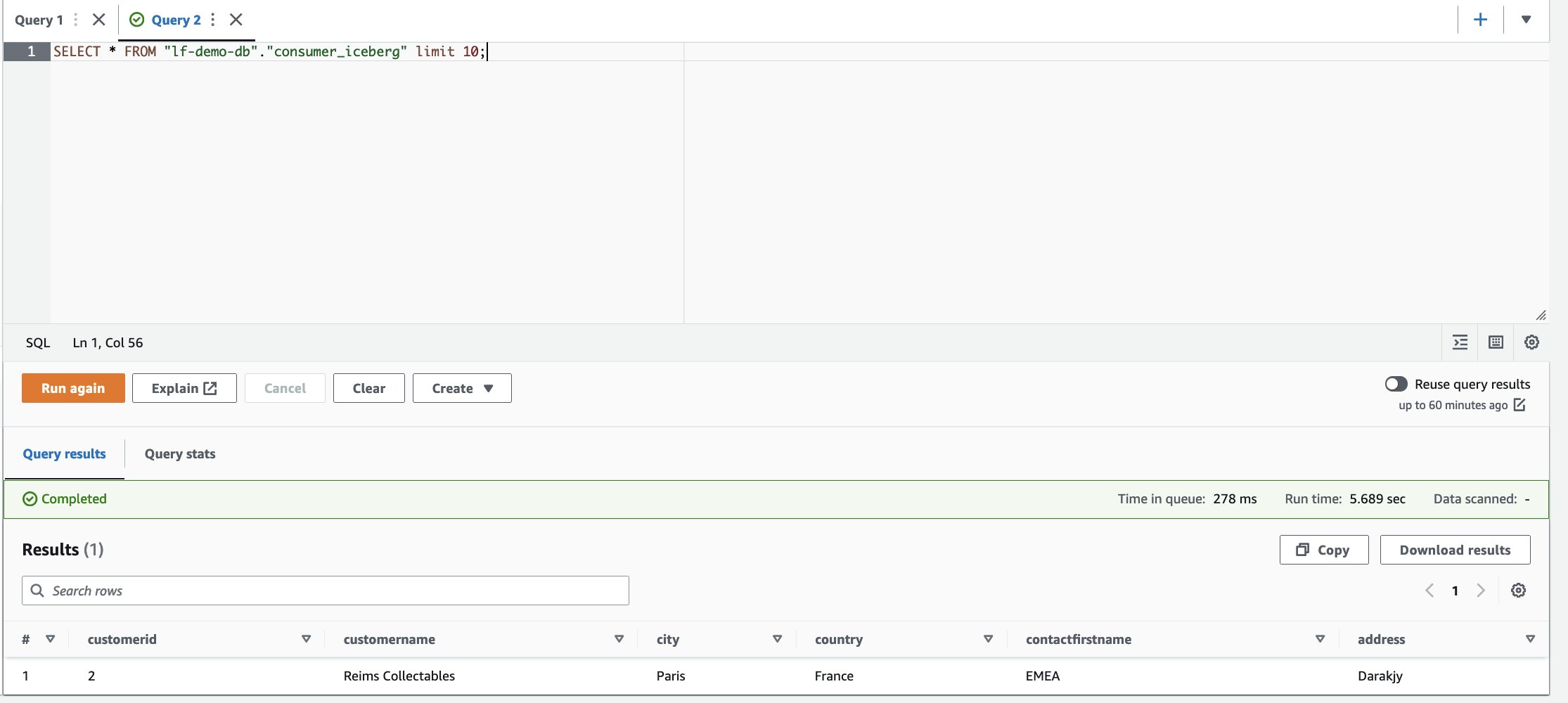
Possiamo osservare che è disponibile solo una riga e la città è aggiornata a Parigi.
Evoluzione dello schema: aggiungi una nuova colonna
Aggiorniamo una delle righe ed eliminiamone una dal set di dati condiviso con il consumatore.
- Accedi all'account produttore.
- Aggiungi una nuova colonna chiamata
geo_locnel tavolo Iceberg. Utilizzare l'editor di query per eseguire una query alla volta. È possibile evidenziare/selezionare una query alla volta e fare clic su "Esegui"/"Esegui di nuovo:
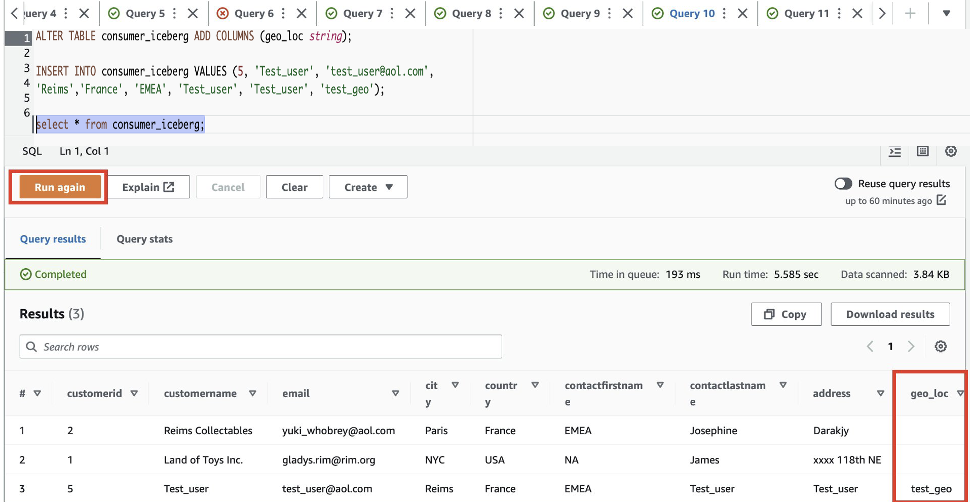
Per dare visibilità ai nuovi aggiunti geo_loc colonna, dobbiamo aggiornare il filtro dati Lake Formation.
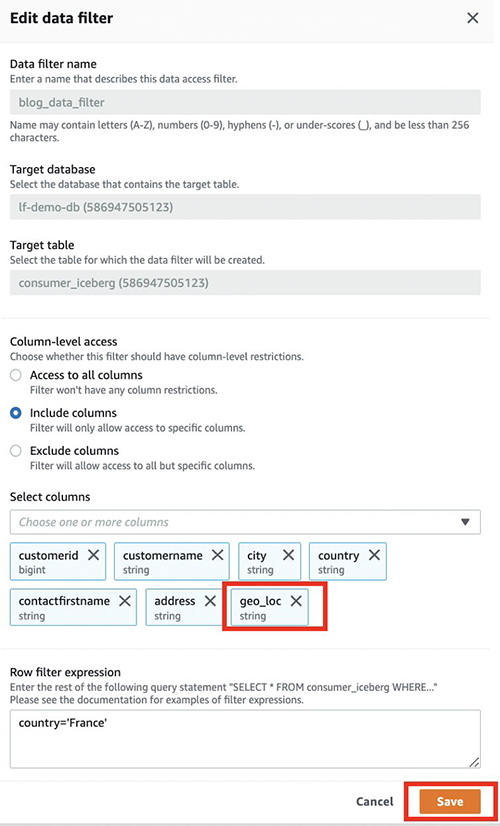
- Sulla console Lake Formation, scegli Filtri dati nel pannello di navigazione.
- Seleziona il filtro dati e scegli Modifica.

- Sotto Accesso a livello di colonna, aggiungi la nuova colonna (
geo_loc). - Scegli Risparmi.
- Accedi all'account consumatore.
- Nell'editor di query Athena, eseguire quanto segue
SELECTquery sulla tabella condivisa:
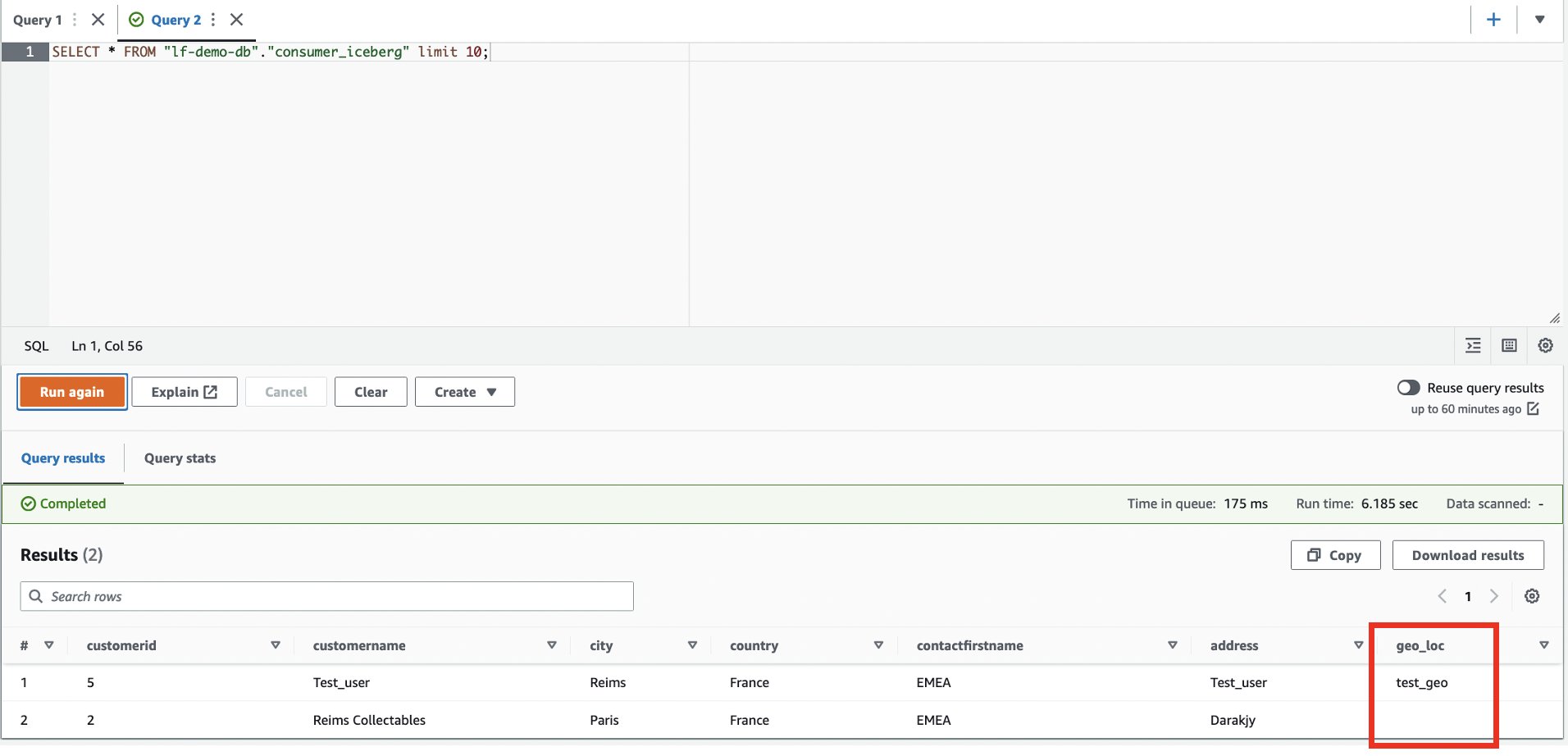
La nuova rubrica geo_loc è visibile e una riga aggiuntiva.
Evoluzione dello schema: Elimina colonna
Aggiorniamo una delle righe ed eliminiamone una dal set di dati condiviso con il consumatore.
- Accedi all'account produttore.
- Modificare la tabella per eliminare la colonna dell'indirizzo dalla tabella Iceberg. Utilizzare l'editor di query per eseguire una query alla volta. È possibile evidenziare/selezionare una query alla volta e fare clic su "Esegui"/"Esegui di nuovo:

Possiamo osservare che l'indirizzo di colonna non è presente nella tabella.
- Accedi all'account consumatore.
- Nell'editor di query Athena, esegui la seguente query SELECT sulla tabella condivisa:
L'indirizzo di colonna non è presente nella tabella.
Viaggio nel tempo
Ora abbiamo cambiato più volte la tabella Iceberg. La tabella Iceberg tiene traccia delle istantanee. Completa i seguenti passaggi per esplorare la funzionalità del viaggio nel tempo:
- Accedi all'account produttore.
- Interroga la tabella di sistema:
Possiamo osservare che abbiamo generato più istantanee.
- Annotare uno dei
committed_atvalori da utilizzare nei passaggi successivi (per questo esempio,2023-01-29 21:35:02.176 UTC).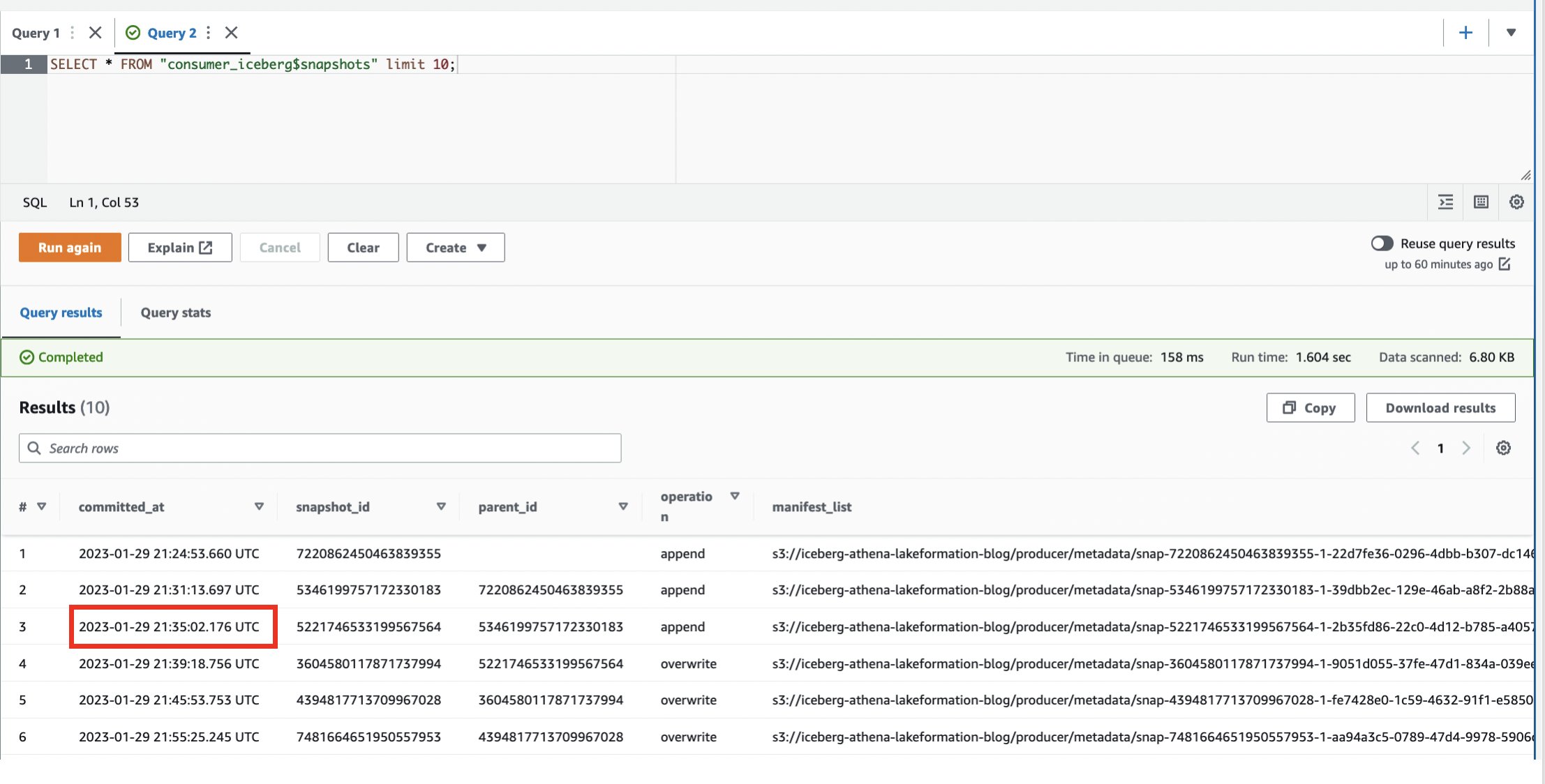
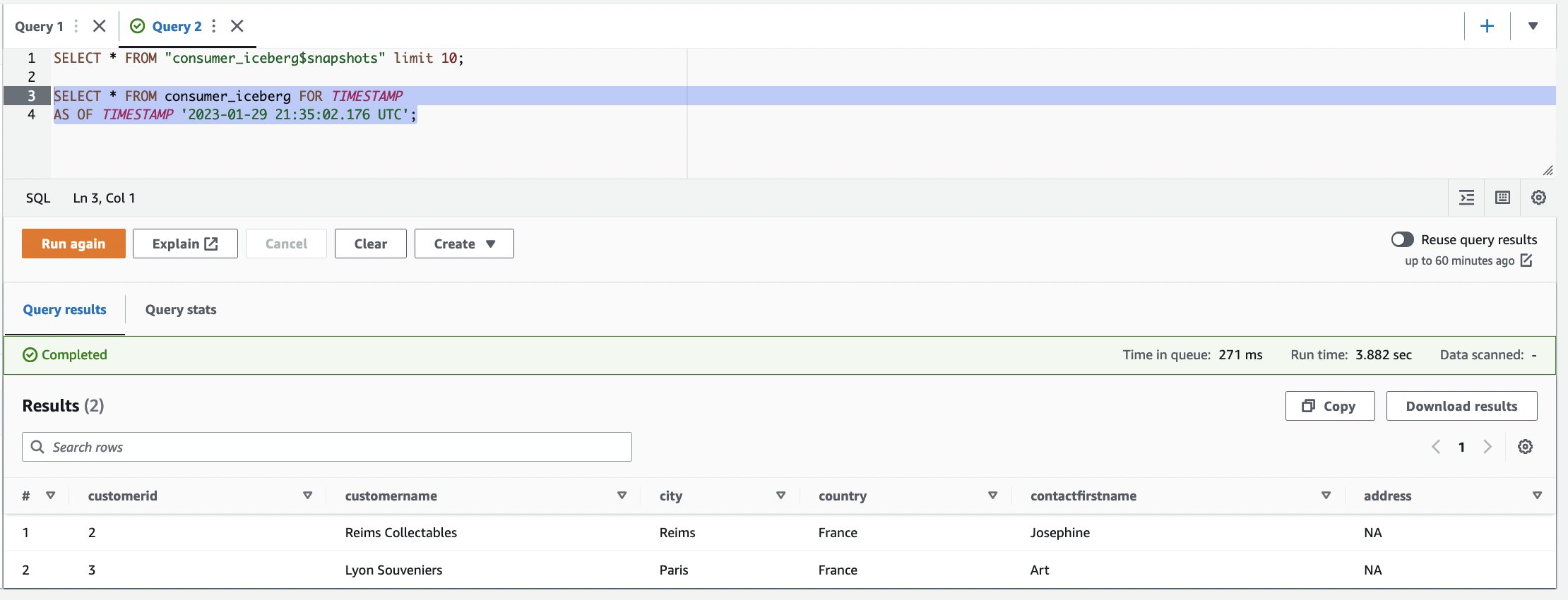
- Usa il viaggio nel tempo per trovare l'istantanea della tabella. Utilizzare l'editor di query per eseguire una query alla volta. È possibile evidenziare/selezionare una query alla volta e fare clic su "Esegui"/"Esegui di nuovo:
ripulire
Completare i seguenti passaggi per evitare di incorrere in futuri addebiti:
- Sulla console Amazon S3, elimina il bucket di archiviazione della tabella (per questo post, iceberg-athena-lakeformation-blog).
- Nell'account produttore sulla console Athena, esegui i seguenti comandi per eliminare le tabelle che hai creato:
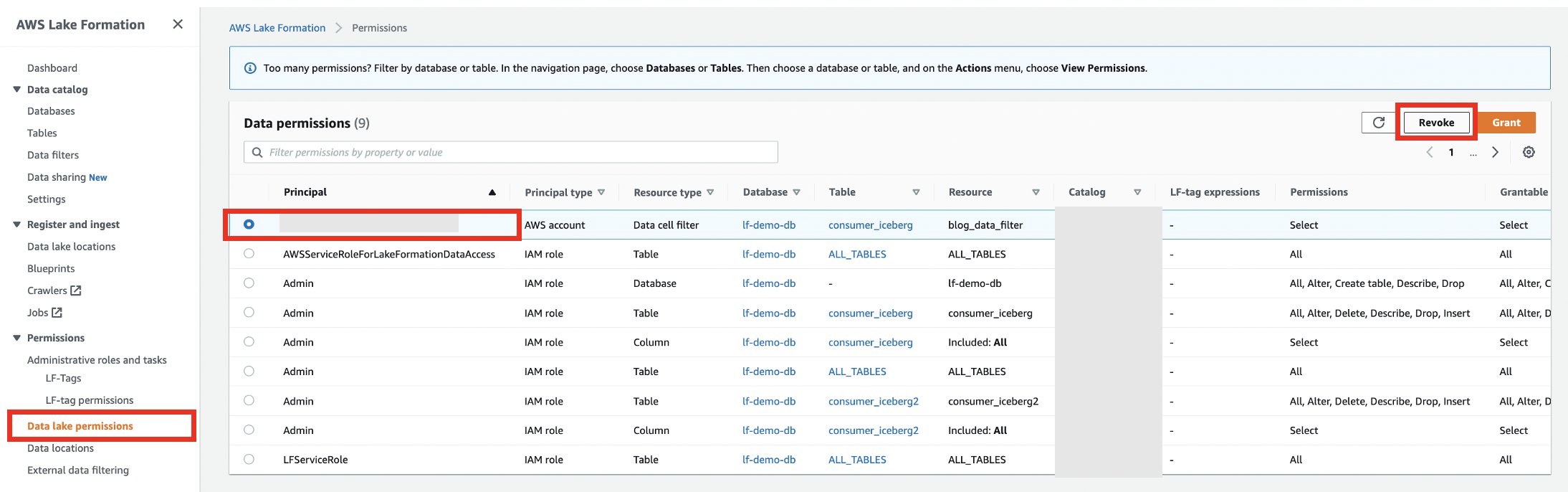
- Nell'account produttore sulla console Lake Formation, revocare le autorizzazioni all'account consumatore.
- Elimina il bucket S3 utilizzato per la posizione dei risultati della query Athena dall'account consumer.
Conclusione
Con il supporto di criteri di controllo degli accessi granulari per più account per formati come Iceberg, hai la flessibilità di lavorare con qualsiasi formato supportato da Athena. La capacità di eseguire operazioni CRUD sui dati nel tuo data lake S3 combinata con i controlli di accesso granulari di Lake Formation per tutte le tabelle e i formati supportati da Athena offre opportunità per innovare e semplificare la tua strategia di dati. Ci piacerebbe sentire il tuo feedback!
Circa gli autori
 Kishore Dhamodaran è Senior Solutions Architect presso AWS. Kishore aiuta i clienti strategici con la loro strategia aziendale cloud e il loro viaggio di migrazione, sfruttando i suoi anni di esperienza nel settore e nel cloud.
Kishore Dhamodaran è Senior Solutions Architect presso AWS. Kishore aiuta i clienti strategici con la loro strategia aziendale cloud e il loro viaggio di migrazione, sfruttando i suoi anni di esperienza nel settore e nel cloud.
 Jack Ye è un ingegnere informatico del team Athena Data Lake and Storage di AWS. È un Apache Iceberg Committer e membro PMC.
Jack Ye è un ingegnere informatico del team Athena Data Lake and Storage di AWS. È un Apache Iceberg Committer e membro PMC.
 Chris Olson è un ingegnere di sviluppo software presso AWS.
Chris Olson è un ingegnere di sviluppo software presso AWS.
 Xiaoxuan Li è un ingegnere di sviluppo software presso AWS.
Xiaoxuan Li è un ingegnere di sviluppo software presso AWS.
 Raul Sonawane è Principal Analytics Solutions Architect presso AWS con AI/ML e Analytics come sua area di specializzazione.
Raul Sonawane è Principal Analytics Solutions Architect presso AWS con AI/ML e Analytics come sua area di specializzazione.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/
- :È
- $ SU
- 1
- 10
- 100
- 7
- a
- capacità
- Chi siamo
- Accetta
- accesso
- Il mio account
- operanti in
- aggiunto
- aggiuntivo
- Informazioni aggiuntive
- indirizzo
- Admin
- adottato
- contro
- AI / ML
- Tutti
- consente
- Amazon
- Amazzone Atena
- analitica
- ed
- Apache
- architettura
- SONO
- RISERVATA
- Arte
- AS
- At
- autorizzazione
- disponibile
- evitare
- AWS
- Formazione AWS Lake
- Backed
- basato
- fra
- affari
- aziende
- by
- detto
- Materiale
- catalogo
- centralizzata
- certo
- il cambiamento
- oneri
- Scegli
- Città
- clicca
- Cloud
- Colonna
- colonne
- COM
- combinato
- completamento di una
- componenti
- consolle
- Consumer
- di controllo
- controlli
- nazione
- creare
- creato
- Creazione
- creazione
- Cross
- Clienti
- dati
- Lago di dati
- condivisione dei dati
- strategia di dati
- Banca Dati
- decisioni
- deep
- profonda immersione
- Predefinito
- Mercato
- diverso
- discutere
- giù
- Cadere
- ogni
- In precedenza
- editore
- abilitato
- crittografato
- crittografia
- motore
- ingegnere
- entrare
- Impresa
- Etere (ETH)
- evoluzione
- esempio
- previsto
- esperienza
- esplora
- esterno
- Compila il
- filtro
- filtraggio
- filtri
- Trovare
- Nome
- prima volta
- Flessibilità
- i seguenti
- Nel
- formato
- formazione
- quadri
- Francia
- da
- pieno
- funzionalità
- futuro
- generato
- ottenere
- Dare
- la governance
- concedere
- guida
- Avere
- avendo
- sentire
- aiuta
- Alveare
- HTML
- http
- HTTPS
- ID
- realizzare
- in
- Inc.
- industria
- informazioni
- innovare
- interagire
- interessato
- IT
- viaggio
- jpg
- lago
- Paese
- strato
- apprendimento
- Livello
- leveraging
- LIMITE
- Linee
- LINK
- località
- amore
- Lione
- make
- FA
- gestione
- membro
- Menu
- migrazione
- modello
- Scopri di più
- multiplo
- Nome
- Navigare
- Navigazione
- Bisogno
- New
- GENERAZIONE
- NYC
- osservare
- of
- on
- ONE
- aprire
- dati aperti
- operare
- Operazioni
- Opportunità
- organizzazioni
- Altro
- vetro
- Parigi
- sentiero
- eseguire
- permessi
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- Post
- presenti
- Direttore
- produttore
- fornire
- fornisce
- RAM
- Leggi
- recentemente
- riflette
- registro
- registrato
- sostituire
- richiede
- risorsa
- limitare
- limitato
- colpevole
- Ruolo
- ruoli
- RIGA
- Correre
- stesso
- Risparmi
- Scenari
- Sezione
- selezionato
- anziano
- set
- Condividi
- condiviso
- compartecipazione
- semplificare
- Istantanea
- Software
- lo sviluppo del software
- Software Engineer
- Soluzioni
- Specialità
- SQL
- iniziato
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- Strategico
- Strategia
- Corda
- tale
- supporto
- supportato
- sistema
- tavolo
- team
- che
- I
- loro
- Strumenti Bowman per analizzare le seguenti finiture:
- tempo
- tempo di percorrenza
- volte
- timestamp
- a
- pista
- viaggiare
- per
- unico
- Aggiornanento
- aggiornato
- upgrade
- USA
- uso
- Utente
- UTC
- CONVALIDARE
- Valori
- verificare
- versione
- visibilità
- visibile
- Visita
- con
- Lavora
- lavori
- scrivere
- anni
- Trasferimento da aeroporto a Sharm
- zefiro