Oggi siamo entusiasti di annunciare che il Guardia dei lama il modello è ora disponibile per i clienti che utilizzano JumpStart di Amazon SageMaker. Llama Guard fornisce protezioni di input e output nell'implementazione di modelli LLM (Large Language Model). È uno dei componenti di Purple Llama, l'iniziativa di Meta che presenta strumenti e valutazioni di fiducia e sicurezza aperte per aiutare gli sviluppatori a costruire in modo responsabile con modelli di intelligenza artificiale. Purple Llama riunisce strumenti e valutazioni per aiutare la comunità a costruire in modo responsabile con modelli di intelligenza artificiale generativa. La versione iniziale include un focus sulla sicurezza informatica e sulle garanzie di input e output LLM. I componenti all'interno del progetto Purple Llama, incluso il modello Llama Guard, sono concessi in licenza in modo permissivo, consentendo sia la ricerca che l'uso commerciale.
Ora puoi utilizzare il modello Llama Guard in SageMaker JumpStart. SageMaker JumpStart è l'hub di machine learning (ML) di Amazon Sage Maker che fornisce l'accesso ai modelli di base oltre agli algoritmi integrati e ai modelli di soluzione end-to-end per aiutarti a iniziare rapidamente con il machine learning.
In questo post, spieghiamo come implementare il modello Llama Guard e creare soluzioni di intelligenza artificiale generativa responsabile.
Modello Guardia Lama
Llama Guard è un nuovo modello di Meta che fornisce guardrail di ingresso e uscita per le implementazioni LLM. Llama Guard è un modello disponibile apertamente che funziona in modo competitivo su benchmark aperti comuni e fornisce agli sviluppatori un modello preaddestrato per aiutare a difendersi dalla generazione di output potenzialmente rischiosi. Questo modello è stato addestrato su un mix di set di dati disponibili pubblicamente per consentire il rilevamento di tipi comuni di contenuti potenzialmente rischiosi o in violazione che potrebbero essere rilevanti per una serie di casi d'uso degli sviluppatori. In definitiva, la visione del modello è quella di consentire agli sviluppatori di personalizzare questo modello per supportare casi d'uso rilevanti e per facilitare l'adozione delle migliori pratiche e il miglioramento dell'ecosistema aperto.
Llama Guard può essere utilizzato come strumento supplementare per gli sviluppatori da integrare nelle proprie strategie di mitigazione, ad esempio per chatbot, moderazione dei contenuti, servizio clienti, monitoraggio dei social media e formazione. Passando i contenuti generati dagli utenti tramite Llama Guard prima di pubblicarli o rispondere, gli sviluppatori possono segnalare linguaggio non sicuro o inappropriato e agire per mantenere un ambiente sicuro e rispettoso.
Esploriamo come utilizzare il modello Llama Guard in SageMaker JumpStart.
Modelli di fondazione in SageMaker
SageMaker JumpStart fornisce l'accesso a una gamma di modelli provenienti da hub di modelli popolari, tra cui Hugging Face, PyTorch Hub e TensorFlow Hub, che puoi utilizzare all'interno del flusso di lavoro di sviluppo ML in SageMaker. I recenti progressi nel machine learning hanno dato origine a una nuova classe di modelli noti come modelli di fondazione, che vengono generalmente addestrati su miliardi di parametri e sono adattabili a un'ampia categoria di casi d'uso, come il riepilogo del testo, la generazione di arte digitale e la traduzione linguistica. Poiché l'addestramento di questi modelli è costoso, i clienti desiderano utilizzare i modelli di base già addestrati esistenti e perfezionarli in base alle necessità, anziché addestrare questi modelli da soli. SageMaker fornisce un elenco curato di modelli tra cui puoi scegliere sulla console SageMaker.
Ora puoi trovare modelli di fondazione di diversi fornitori di modelli all'interno di SageMaker JumpStart, consentendoti di iniziare rapidamente con i modelli di fondazione. È possibile trovare modelli di base basati su attività o fornitori di modelli diversi ed esaminare facilmente le caratteristiche del modello e i termini di utilizzo. Puoi anche provare questi modelli utilizzando un widget dell'interfaccia utente di prova. Se desideri utilizzare un modello di base su larga scala, puoi farlo facilmente senza uscire da SageMaker utilizzando notebook predefiniti dei fornitori di modelli. Poiché i modelli sono ospitati e distribuiti su AWS, puoi essere certo che i tuoi dati, siano essi utilizzati per la valutazione o per l'utilizzo del modello su larga scala, non verranno mai condivisi con terze parti.
Esploriamo come utilizzare il modello Llama Guard in SageMaker JumpStart.
Scopri il modello Llama Guard in SageMaker JumpStart
Puoi accedere ai modelli base di Code Llama tramite SageMaker JumpStart nell'interfaccia utente di SageMaker Studio e SageMaker Python SDK. In questa sezione spieghiamo come scoprire i modelli in Amazon Sage Maker Studio.
SageMaker Studio è un ambiente di sviluppo integrato (IDE) che fornisce un'unica interfaccia visiva basata sul Web in cui è possibile accedere a strumenti specifici per eseguire tutte le fasi di sviluppo ML, dalla preparazione dei dati alla creazione, formazione e distribuzione dei modelli ML. Per ulteriori dettagli su come iniziare e configurare SageMaker Studio, fare riferimento a Amazon Sage Maker Studio.
In SageMaker Studio è possibile accedere a SageMaker JumpStart, che contiene modelli pre-addestrati, notebook e soluzioni predefinite, in Soluzioni predefinite e automatizzate.
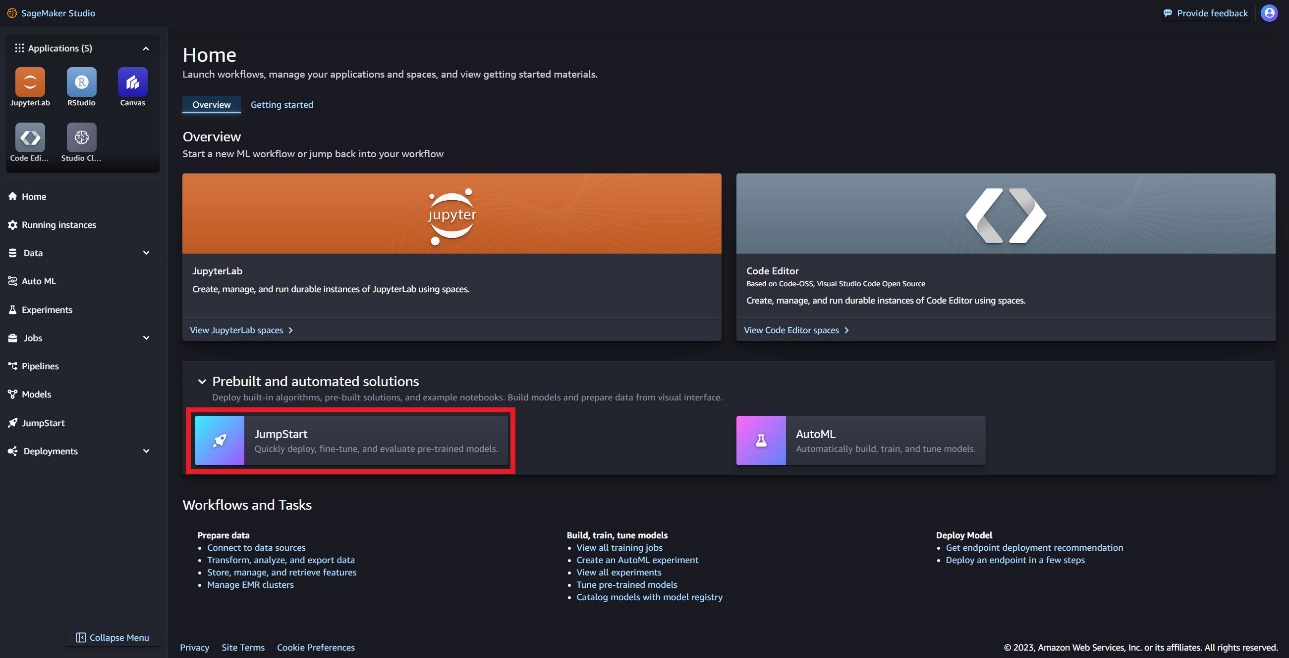
Nella pagina di destinazione JumpStart di SageMaker, puoi trovare il modello Llama Guard scegliendo l'hub Meta o cercando Llama Guard.

Puoi scegliere tra una varietà di varianti del modello Llama, tra cui Llama Guard, Llama-2 e Code Llama.

Puoi scegliere la scheda del modello per visualizzare i dettagli sul modello come licenza, dati utilizzati per l'addestramento e modalità di utilizzo. Troverai anche un Schierare opzione, che ti porterà a una pagina di destinazione in cui puoi testare l'inferenza con un payload di esempio.

Distribuisci il modello con SageMaker Python SDK
Puoi trovare il codice che mostra la distribuzione di Llama Guard su Amazon JumpStart e un esempio di come utilizzare il modello distribuito in questo Taccuino GitHub.
Nel codice seguente specifichiamo l'ID del modello dell'hub del modello SageMaker e la versione del modello da utilizzare durante la distribuzione di Llama Guard:
Ora puoi distribuire il modello utilizzando SageMaker JumpStart. Il codice seguente utilizza l'istanza predefinita ml.g5.2xlarge per l'endpoint di inferenza. Puoi distribuire il modello su altri tipi di istanza passando instance_type nel JumpStartModel classe. La distribuzione potrebbe richiedere alcuni minuti. Per una distribuzione corretta, è necessario modificare manualmente il file accept_eula argomento nel metodo di distribuzione del modello a True.
Questo modello viene distribuito utilizzando il contenitore di deep learning Text Generation Inference (TGI). Le richieste di inferenza supportano molti parametri, inclusi i seguenti:
- lunghezza massima – Il modello genera testo fino a raggiungere la lunghezza dell'output (che include la lunghezza del contesto di input).
max_length. Se specificato, deve essere un numero intero positivo. - max_new_tokens – Il modello genera testo fino al raggiungimento della lunghezza dell'output (esclusa la lunghezza del contesto di input).
max_new_tokens. Se specificato, deve essere un numero intero positivo. - num_raggi – Indica il numero di raggi utilizzati nella ricerca golosa. Se specificato, deve essere un numero intero maggiore o uguale a
num_return_sequences. - no_repeat_ngram_size – Il modello assicura che una sequenza di parole di
no_repeat_ngram_sizenon viene ripetuto nella sequenza di output. Se specificato, deve essere un numero intero positivo maggiore di 1. - temperatura – Questo parametro controlla la casualità nell'output. Un più alto
temperaturerisulta in una sequenza di output con parole a bassa probabilità e una più bassatemperaturerisulta in una sequenza di output con parole ad alta probabilità. Setemperatureè 0, il risultato è una decodifica avida. Se specificato, deve essere un float positivo. - early_stopping - Se
True, la generazione del testo termina quando tutte le ipotesi del fascio raggiungono la fine del token della frase. Se specificato, deve essere booleano. - do_campione - Se
True, il modello campiona la parola successiva in base alla probabilità. Se specificato, deve essere booleano. - top_k – In ogni passaggio della generazione del testo, il modello campiona solo da
top_kparole molto probabili. Se specificato, deve essere un numero intero positivo. - in alto_p – In ogni fase della generazione del testo, il modello campiona il più piccolo insieme possibile di parole con probabilità cumulativa
top_p. Se specificato, deve essere un float compreso tra 0 e 1. - return_full_text - Se
True, il testo in input farà parte del testo generato in output. Se specificato, deve essere booleano. Il valore predefinito èFalse. - Stop – Se specificato, deve essere un elenco di stringhe. La generazione del testo si interrompe se viene generata una qualsiasi delle stringhe specificate.
Richiama un endpoint SageMaker
Puoi recuperare a livello di codice payload di esempio da JumpStartModel oggetto. Ciò ti aiuterà a iniziare rapidamente osservando le istruzioni preformattate che Llama Guard può acquisire. Vedere il seguente codice:
Dopo aver eseguito l'esempio precedente, puoi vedere come l'input e l'output verrebbero formattati da Llama Guard:
Similmente a Llama-2, Llama Guard utilizza gettoni speciali per indicare le istruzioni di sicurezza al modello. In generale, il payload dovrebbe seguire il formato seguente:
Richiesta utente mostrata come {user_prompt} sopra, può includere inoltre sezioni per le definizioni delle categorie di contenuti e le conversazioni, che assomigliano a quanto segue:
Nella sezione successiva verranno discussi i valori predefiniti consigliati per le definizioni di attività, categoria di contenuto e istruzioni. La conversazione dovrebbe alternarsi User ed Agent testo come segue:
Moderare una conversazione con Llama-2 Chat
Ora puoi distribuire un endpoint del modello Llama-2 7B Chat per la chat conversazionale e quindi utilizzare Llama Guard per moderare il testo di input e output proveniente da Llama-2 7B Chat.
Ti mostriamo l'esempio dell'input e dell'output del modello di chat Llama-2 7B moderati tramite Llama Guard, ma puoi utilizzare Llama Guard per la moderazione con qualsiasi LLM di tua scelta.
Distribuisci il modello con il seguente codice:
Ora puoi definire il modello di attività Llama Guard. Le categorie di contenuti non sicuri possono essere modificate come desiderato per il tuo caso d'uso specifico. È possibile definire in testo semplice il significato di ciascuna categoria di contenuto, incluso quale contenuto deve essere contrassegnato come non sicuro e quale contenuto deve essere consentito come sicuro. Vedere il seguente codice:
Successivamente, definiamo le funzioni di supporto format_chat_messages ed format_guard_messages per formattare il prompt per il modello di chat e per il modello Llama Guard che richiedeva token speciali:
Puoi quindi utilizzare queste funzioni di supporto su un prompt di input del messaggio di esempio per eseguire l'input di esempio tramite Llama Guard per determinare se il contenuto del messaggio è sicuro:
L'output seguente indica che il messaggio è sicuro. Potresti notare che il messaggio include parole che potrebbero essere associate alla violenza, ma, in questo caso, Llama Guard è in grado di comprendere il contesto rispetto alle istruzioni e alle definizioni di categorie non sicure fornite in precedenza e determinare che si tratta di un messaggio sicuro e non legati alla violenza.
Ora che hai confermato che il testo immesso è considerato sicuro rispetto alle categorie di contenuti di Llama Guard, puoi passare questo carico utile al modello Llama-2 7B distribuito per generare testo:
Quella che segue è la risposta del modello:
Infine, potresti voler confermare che il testo della risposta del modello contiene contenuti sicuri. Qui, estendi la risposta di output LLM ai messaggi di input ed esegui l'intera conversazione tramite Llama Guard per garantire che la conversazione sia sicura per la tua applicazione:
Potresti visualizzare il seguente output, che indica che la risposta dal modello di chat è sicura:
ripulire
Dopo aver testato gli endpoint, assicurati di eliminare gli endpoint di inferenza SageMaker e il modello per evitare di incorrere in addebiti.
Conclusione
In questo post, ti abbiamo mostrato come moderare input e output utilizzando Llama Guard e inserire guardrail per input e output da LLM in SageMaker JumpStart.
Poiché l’intelligenza artificiale continua ad avanzare, è fondamentale dare priorità allo sviluppo e all’implementazione responsabili. Strumenti come CyberSecEval e Llama Guard di Purple Llama sono determinanti nel promuovere l’innovazione sicura, offrendo l’identificazione precoce dei rischi e una guida alla mitigazione per i modelli linguistici. Questi dovrebbero essere integrati nel processo di progettazione dell’intelligenza artificiale per sfruttare eticamente tutto il potenziale degli LLM fin dal primo giorno.
Prova oggi stesso Llama Guard e altri modelli di base in SageMaker JumpStart e facci sapere il tuo feedback!
Questa guida è solo a scopo informativo. Dovresti comunque eseguire la tua valutazione indipendente e adottare misure per garantire il rispetto delle tue pratiche e standard specifici di controllo della qualità e delle norme, leggi, regolamenti, licenze e termini di utilizzo locali che si applicano a te, ai tuoi contenuti, e il modello di terze parti a cui si fa riferimento nella presente guida. AWS non ha alcun controllo o autorità sul modello di terze parti a cui si fa riferimento in queste linee guida e non rilascia alcuna dichiarazione o garanzia che il modello di terze parti sia sicuro, privo di virus, operativo o compatibile con l'ambiente e gli standard di produzione. AWS non rilascia alcuna dichiarazione o garanzia che qualsiasi informazione contenuta in questa guida comporterà un risultato o un risultato particolare.
Circa gli autori
 Dottor Kyle Ulrich è uno scienziato applicato con il Algoritmi integrati di Amazon SageMaker squadra. I suoi interessi di ricerca includono algoritmi di machine learning scalabili, visione artificiale, serie storiche, bayesiani non parametrici e processi gaussiani. Il suo dottorato di ricerca è presso la Duke University e ha pubblicato articoli su NeurIPS, Cell e Neuron.
Dottor Kyle Ulrich è uno scienziato applicato con il Algoritmi integrati di Amazon SageMaker squadra. I suoi interessi di ricerca includono algoritmi di machine learning scalabili, visione artificiale, serie storiche, bayesiani non parametrici e processi gaussiani. Il suo dottorato di ricerca è presso la Duke University e ha pubblicato articoli su NeurIPS, Cell e Neuron.
 Evan Kravitz è un ingegnere informatico presso Amazon Web Services e lavora su SageMaker JumpStart. È interessato alla confluenza dell'apprendimento automatico con il cloud computing. Evan ha conseguito la laurea presso la Cornell University e un master presso l'Università della California, Berkeley. Nel 2021, ha presentato un documento sulle reti neurali avversarie alla conferenza dell'ICLR. Nel tempo libero, Evan ama cucinare, viaggiare e andare a correre a New York City.
Evan Kravitz è un ingegnere informatico presso Amazon Web Services e lavora su SageMaker JumpStart. È interessato alla confluenza dell'apprendimento automatico con il cloud computing. Evan ha conseguito la laurea presso la Cornell University e un master presso l'Università della California, Berkeley. Nel 2021, ha presentato un documento sulle reti neurali avversarie alla conferenza dell'ICLR. Nel tempo libero, Evan ama cucinare, viaggiare e andare a correre a New York City.
 Rachna Chada è Principal Solution Architect AI/ML in Strategic Accounts presso AWS. Rachna è un'ottimista che crede che l'uso etico e responsabile dell'IA possa migliorare la società in futuro e portare prosperità economica e sociale. Nel tempo libero, a Rachna piace passare il tempo con la sua famiglia, fare escursioni e ascoltare musica.
Rachna Chada è Principal Solution Architect AI/ML in Strategic Accounts presso AWS. Rachna è un'ottimista che crede che l'uso etico e responsabile dell'IA possa migliorare la società in futuro e portare prosperità economica e sociale. Nel tempo libero, a Rachna piace passare il tempo con la sua famiglia, fare escursioni e ascoltare musica.
 Dottor Ashish Khetan è un Senior Applied Scientist con algoritmi integrati di Amazon SageMaker e aiuta a sviluppare algoritmi di machine learning. Ha conseguito il dottorato di ricerca presso l'Università dell'Illinois Urbana-Champaign. È un ricercatore attivo nell'apprendimento automatico e nell'inferenza statistica e ha pubblicato numerosi articoli nelle conferenze NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dottor Ashish Khetan è un Senior Applied Scientist con algoritmi integrati di Amazon SageMaker e aiuta a sviluppare algoritmi di machine learning. Ha conseguito il dottorato di ricerca presso l'Università dell'Illinois Urbana-Champaign. È un ricercatore attivo nell'apprendimento automatico e nell'inferenza statistica e ha pubblicato numerosi articoli nelle conferenze NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 Carlo Albertsen guida prodotti, ingegneria e scienza per Amazon SageMaker Algorithms e JumpStart, l'hub di machine learning di SageMaker. È appassionato di applicare l'apprendimento automatico per sbloccare il valore aziendale.
Carlo Albertsen guida prodotti, ingegneria e scienza per Amazon SageMaker Algorithms e JumpStart, l'hub di machine learning di SageMaker. È appassionato di applicare l'apprendimento automatico per sbloccare il valore aziendale.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- capace
- Chi siamo
- sopra
- Accetta
- accesso
- Secondo
- conti
- Legge
- Action
- azioni
- attivo
- attività
- presenti
- aggiunta
- Rettificato
- adottare
- avanzare
- avanzamenti
- contraddittorio
- consigli
- contro
- Agente
- AI
- Modelli AI
- AI / ML
- alcol
- Algoritmi
- Tutti
- anche
- Amazon
- Amazon Sage Maker
- JumpStart di Amazon SageMaker
- Amazon Web Services
- an
- ed
- Annunciare
- rispondere
- in qualsiasi
- Applicazioni
- applicato
- APPLICA
- AMMISSIONE
- opportuno
- SONO
- argomento
- argomenti
- Arte
- AS
- valutazione
- assistere
- Assistant
- associato
- assicurato
- At
- autorità
- Automatizzata
- disponibile
- evitare
- AWS
- basato
- basic
- bayesiano
- BE
- Larghezza
- perché
- stato
- prima
- iniziare
- comportamento
- crede
- sotto
- parametri di riferimento
- Berkeley
- MIGLIORE
- best practice
- fra
- miliardi
- stile di vita
- entrambi
- portare
- Porta
- costruire
- Costruzione
- incassato
- affari
- ma
- by
- California
- Materiale
- canapa
- carta
- Custodie
- casi
- categoria
- Categoria
- cella
- sfide
- possibilità
- il cambiamento
- caratteristiche
- oneri
- chatbots
- dai un'occhiata
- chimico
- scegliere
- Scegli
- la scelta
- Città
- classe
- cavedano
- Cloud
- il cloud computing
- codice
- colore
- arrivo
- impegnata
- Uncommon
- comunità
- compatibile
- ottemperare
- componenti
- composizione
- computer
- Visione computerizzata
- informatica
- Convegno
- conferenze
- Confermare
- CONFERMATO
- confluenza
- consolle
- consumo
- contenere
- Contenitore
- contiene
- contenuto
- moderazione dei contenuti
- contesto
- continua
- di controllo
- controllata
- controlli
- Conversazione
- discorsivo
- Conversazioni
- cucina
- cornell
- potuto
- creare
- creazione
- crimini
- Azione Penale
- critico
- a cura
- cliente
- Servizio clienti
- Clienti
- personalizzare
- Cyber
- sicurezza informatica
- ciclo
- dati
- dataset
- giorno
- Decodifica
- deep
- apprendimento profondo
- Predefinito
- definire
- definizioni
- Laurea
- schierare
- schierato
- distribuzione
- deployment
- implementazioni
- Design
- processo di progettazione
- desiderio
- desiderato
- dettagliati
- dettagli
- rivelazione
- Determinare
- determinato
- sviluppare
- Costruttori
- sviluppatori
- Mercato
- DITT
- diverso
- digitale
- Arte digitale
- Invalidità
- scopri
- Discriminazione
- discutere
- do
- effettua
- farmaci
- Duca
- Università del Duca
- e
- ogni
- In precedenza
- Presto
- facilmente
- Economico
- ecosistema
- Istruzione
- effetti
- senza sforzo
- enable
- consentendo
- incoraggiare
- fine
- da un capo all'altro
- endpoint
- endpoint
- impegnarsi
- ingegnere
- Ingegneria
- garantire
- assicura
- Ambiente
- pari
- particolarmente
- Etere (ETH)
- etico
- la valutazione
- valutazioni
- evan
- eventi
- esempio
- Tranne
- eccezione
- eccitato
- esclusa
- esecuzione
- esistente
- costoso
- esplora
- esprimere
- estendere
- Faccia
- di fronte
- falso
- famiglia
- Grazie
- pochi
- finanziario
- reati finanziari
- Trovare
- armi da fuoco
- Nome
- contrassegnato
- galleggiante
- Focus
- seguire
- seguito
- i seguenti
- segue
- Nel
- formato
- promozione
- Fondazione
- Gratis
- da
- pieno
- funzioni
- ulteriormente
- futuro
- Sesso
- Generale
- generare
- generato
- genera
- la generazione di
- ELETTRICA
- generativo
- AI generativa
- ottenere
- GitHub
- dato
- Dare
- Go
- andando
- ha ottenuto
- maggiore
- Avido
- garanzie
- Guardia
- guida
- PISTOLE
- nuocere
- cintura da arrampicata
- odio
- Avere
- he
- Salute e benessere
- Aiuto
- aiuta
- suo
- qui
- superiore
- escursionismo
- il suo
- storico
- ospitato
- Come
- Tutorial
- HTML
- HTTPS
- Hub
- mozzi
- i
- ICLR
- ID
- Identificazione
- Identità
- if
- Illegale
- Illinois
- subito
- importare
- competenze
- in
- includere
- inclusi
- Compreso
- studente indipendente
- indicare
- indica
- indicando
- informazioni
- Informativo
- radicato
- inizialmente
- iniziativa
- Innovazione
- ingresso
- Ingressi
- esempio
- istruzioni
- strumentale
- integrare
- integrato
- interessato
- interessi
- Interfaccia
- ai miglioramenti
- coinvolgendo
- IT
- SUO
- jpg
- Uccidere
- Sapere
- conosciuto
- kyle
- atterraggio
- pagina di destinazione
- Lingua
- grandi
- Cognome
- Legislazione
- Leads
- apprendimento
- partenza
- Lunghezza
- lasciare
- Licenza
- Autorizzato
- licenze
- piace
- probabilità
- probabile
- piace
- Limitato
- linea
- linux
- Lista
- Ascolto
- Lama
- locale
- SEMBRA
- inferiore
- macchina
- machine learning
- mantenere
- make
- manualmente
- manufatto
- molti
- master
- Maggio..
- significato
- analisi
- Media
- mentale
- Salute mentale
- messaggio
- messaggi
- Meta
- metodo
- metodi
- forza
- verbale
- attenuazione
- scelta
- ML
- modello
- modelli
- moderata
- moderazione
- monitoraggio
- Scopri di più
- maggior parte
- Musica
- devono obbligatoriamente:
- Devi leggere
- il
- di applicazione
- reti
- Neurale
- reti neurali
- NeuIPS
- mai
- New
- New York
- New York City
- GENERAZIONE
- no
- taccuino
- computer portatili
- Avviso..
- adesso
- numero
- oggetto
- osservare
- of
- offerta
- on
- ONE
- esclusivamente
- aprire
- apertamente
- operativa
- Opzione
- Opzioni
- or
- Origin
- Altro
- nostro
- su
- Risultato
- produzione
- uscite
- ancora
- proprio
- proprietà
- pagina
- Carta
- documenti
- parametro
- parametri
- parte
- particolare
- parti
- passare
- Di passaggio
- appassionato
- Persone
- per
- eseguire
- esegue
- persona
- cronologia
- phd
- pianura
- piano
- pianificazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- politica
- Popolare
- positivo
- possibile
- Post
- potenziale
- potenzialmente
- pratiche
- Predictor
- preparazione
- presentata
- prevenire
- Direttore
- Dare priorità
- probabilità
- processi
- i processi
- Prodotto
- Produzione
- progetto
- istruzioni
- prosperità
- fornire
- purché
- fornitori
- fornisce
- pubblicamente
- pubblicato
- editoriale
- fini
- metti
- Python
- pytorch
- qualità
- rapidamente
- Gara
- casualità
- gamma
- piuttosto
- raggiungere
- raggiunge
- Leggi
- ricevuto
- recente
- raccomandato
- riferimento
- per quanto riguarda
- regolamentati
- normativa
- relazionato
- rilasciare
- pertinente
- religione
- ripetuto
- sostituire
- richieste
- necessario
- riparazioni
- ricercatore
- Risorse
- rispetto
- risponde
- risposta
- responsabile
- in modo responsabile
- REST
- colpevole
- Risultati
- ritorno
- recensioni
- Aumento
- Rischio
- Rischioso
- tabella di marcia
- Ruolo
- ruoli
- norme
- Correre
- corre
- sicura
- garanzie
- Sicurezza
- sagemaker
- Inferenza di SageMaker
- scalabile
- Scala
- Scienze
- Scienziato
- sdk
- Cerca
- ricerca
- Secondo
- Sezione
- sezioni
- sicuro
- problemi di
- vedere
- select
- anziano
- delicata
- condanna
- sentimenti
- Sequenza
- Serie
- servizio
- Servizi
- set
- Sessuale
- condiviso
- dovrebbero
- mostrare attraverso le sue creazioni
- ha mostrato
- mostra
- mostrato
- singolo
- minore
- So
- Social
- Social Media
- Società
- Software
- Software Engineer
- soluzione
- Soluzioni
- la nostra speciale
- specifico
- specificato
- Spendere
- standard
- iniziato
- Di partenza
- statistiche
- statistica
- step
- Passi
- Ancora
- Interrompe
- Strategico
- strategie
- studio
- di successo
- tale
- Suicidio
- supporto
- supporti
- sicuro
- sintassi
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- Task
- task
- team
- modello
- modelli
- tensorflow
- condizioni
- test
- testato
- testo
- generazione di testo
- di
- che
- I
- Il futuro
- le informazioni
- furto
- loro
- Li
- si
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- Terza
- terzi
- di parti terze standard
- questo
- quelli
- Attraverso
- tempo
- Serie storiche
- a
- tabacco
- oggi
- insieme
- token
- Tokens
- strumenti
- Argomenti
- traffico
- Treni
- allenato
- Training
- Traduzione
- Di viaggio
- vero
- Affidati ad
- prova
- TURNO
- Tipi di
- tipicamente
- ui
- in definitiva
- per
- capire
- Università
- University of California
- sbloccare
- fino a quando
- us
- Impiego
- uso
- caso d'uso
- utilizzato
- Utente
- usa
- utilizzando
- APPREZZIAMO
- Valori
- varietà
- versione
- Visualizza
- violato
- Violare
- violenza
- visione
- visivo
- camminare
- volere
- Modo..
- we
- Armi
- sito web
- servizi web
- Web-basata
- Che
- quando
- se
- quale
- OMS
- tutto
- largo
- widget di
- volere
- desiderio
- con
- entro
- senza
- Word
- parole
- Lavora
- flusso di lavoro
- lavoro
- sarebbe
- York
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro