Hai mai aspettato quel pacco costoso che mostra "spedito", ma non hai idea di dove sia? La cronologia di monitoraggio ha smesso di aggiornarsi cinque giorni fa e hai quasi perso la speranza. Ma aspetta, 11 giorni dopo, ce l'hai a portata di mano. Avresti voluto che la tracciabilità potesse essere migliore per sollevarti da tutte le ansiose attese. È qui che entra in gioco la "osservabilità".
In un panorama tecnico, vorresti evitare che ciò accada al tuo software o ai tuoi sistemi di dati. E quindi, adotti strumenti di monitoraggio, che raccolgono i log e le metriche dei tuoi sistemi e ti informano sul loro stato interno. Il monitoraggio funziona al meglio quando desideri che i tuoi sistemi ti informino su qual è l'errore, dove e quando si è verificato, ma non ti dice come risolverlo.
Più di un decennio fa, gli strumenti di monitoraggio mancavano del contesto e della previsione dei problemi di sistema sottostanti e i team si limitavano a eseguire il debug degli errori operativi quotidiani. Oggi lavoriamo e viviamo in un mondo distribuito di microservizi e pipeline di dati; anche l'utilizzo di più strumenti di monitoraggio non ti aiuterà a rispondere alle tue domande aziendali come "Perché la mia applicazione è sempre lenta?" o "In quale fase si è verificato il problema e quanto è profondo nello stack?" o "Come posso migliorare le prestazioni complessive dell'ambiente?" Diventa necessario essere proattivi nel prendere queste decisioni e avere una visibilità complessiva dei propri sistemi, applicazioni e dati.
La sezione post sul blog di Etsy è stato pubblicato un decennio fa, e afferma proprio il fatto nel secondo paragrafo:
“Le metriche dell'applicazione sono solitamente le più difficili, ma anche le più importanti, delle tre. Sono molto specifici per la tua attività e cambiano man mano che cambiano le tue applicazioni (ed Etsy cambia molto)."
Quindi, come misuriamo tutto e niente? Partiamo dall'osservabilità.
Cos'è l'osservabilità?
Il termine “osservabilità” era coniato da Rudolf Emil Kálmán nel 1960 nel suo articolo di ingegneria per descrivere i sistemi di controllo matematico. Lo ha definito come una misura di quanto bene gli stati interni di un sistema possono essere dedotti dalla conoscenza dei suoi output esterni. Ma non suona come il monitoraggio? Fondamentalmente, sì, sta monitorando.
In questi giorni, l'osservabilità è diventata un argomento piuttosto caldo. Secondo diverse indagini di mercato si tratta di una piattaforma da un miliardo di dollari. Molte organizzazioni hanno adottato il concetto e lo hanno utilizzato come framework per la visibilità end-to-end dei loro sistemi e pipeline distribuiti. Tuttavia, l'osservabilità è confusa con il monitoraggio. Per ora, posso dire che il monitoraggio è un sottoinsieme dell'osservabilità, dove l'osservabilità è un grande termine generico.
L'osservabilità consente la traccia distribuita attraverso la raccolta e l'aggregazione di tracce, registri e metriche. Vediamo cosa ne deducono:
- Tracce: Quando un sistema riceve una richiesta, le tracce indicano come tale richiesta fluisce, durante il suo ciclo di vita, dall'origine alla destinazione. Le tracce sono rappresentate da "campate". Una traccia è un albero di span e uno span è una singola operazione all'interno di una traccia. Ti aiutano a individuare errori, latenza o colli di bottiglia nel sistema.
- logs: Si tratta di eventi con timestamp generati dalla macchina che ti informano sulle operazioni o sui cambiamenti avvenuti nel sistema. I registri vengono spesso utilizzati per interrogare questi errori o modifiche nel sistema.
- Metrica: Questi forniscono approfondimenti quantitativi su CPU, memoria, utilizzo del disco e sulle prestazioni del sistema in un periodo di tempo.
Questi attributi migliorano il quadro di monitoraggio con la tracciabilità. La tracciabilità ti fornisce gli obiettivi per tracciare una richiesta che effettua una chiamata al tuo sistema, quanto tempo impiega per passare da un componente all'altro, quali altri servizi invoca, genera errori, quali registri produce, quale stato si trova, quando è iniziato e quando è finito, qual è la sequenza temporale in cui è rimasto nel tuo sistema, ecc. Quando raccogli, aggreghi e analizzi queste tracce, sei in grado di prendere preziose decisioni informate come la cronologia del cliente su un sito Web di e-commerce , quanto tempo hanno impiegato per cercare un prodotto, per quanto tempo hanno visualizzato il prodotto, la pagina HTML ha caricato i dettagli completi come immagini o video incorporati, quanto tempo ha impiegato il sistema per autenticare ed elaborare il pagamento, ecc.
Cosa otteniamo con l'osservabilità in un ambiente distribuito?
L'evoluzione dei sistemi distribuiti è iniziata quando le organizzazioni hanno iniziato a spostarsi dalla loro architettura monolitica centralizzata a un'architettura di microservizi distribuita e decentralizzata. E questo è ancora un lavoro in corso in cui molte organizzazioni stanno abbracciando la natura dei microservizi di sistemi e applicazioni. E tutto questo può essere attribuito a Big Data e ridimensionamento. La gestione di un ambiente distribuito richiede apprendimento continuo, forza lavoro aggiuntiva, modifiche a framework e policy, gestione IT e così via. È davvero un grande cambiamento.
In precedenza, nell'ambiente monolitico limitato, hardware, software, dati e database vivevano tutti sotto un unico tetto. Con l'avvento dei big data negli anni 2000, i sistemi di monitoraggio e ridimensionamento hanno iniziato a diventare una grande preoccupazione. Spesso le organizzazioni hanno utilizzato diversi strumenti di monitoraggio per soddisfare le esigenze delle varie applicazioni. Di conseguenza, è diventato presto un sovraccarico operativo con scarsa resilienza, visibilità e affidabilità.
Tutti questi problemi hanno dato luogo all'adozione dell'osservabilità. Oggi esistono più strumenti di osservabilità per pipeline di sicurezza, rete, applicazioni e dati per il tracciamento distribuito in un ambiente complesso. Coesistono con il loro cugino, gli strumenti di monitoraggio, e fanno leva per raccogliere le informazioni dal loro cugino e aggregare con informazioni aggiuntive dai propri dati di traccia.
Ci sono molti componenti in movimento in tutti questi sistemi, le cui tracce, una volta catturate, possono illustrare la storia delle 5 W: quando, dove, perché, cosa e come. Ad esempio, vai sul sito web di DATAVERSITY alle 1:43 per leggere alcuni post del blog. Quando si accede a dataversity.net, la richiesta HTTP viene registrata nel sistema. Inizi a cercare un post sul blog e vai a un post sulla governance dei dati, dove trascorri 17 minuti a leggere quel post e poi chiudi la scheda alle 2:00
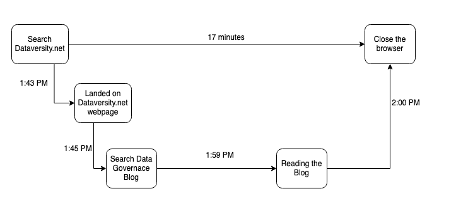
Ci saranno anche altre chiamate effettuate al sistema di rete per l'acquisizione dei pacchetti di rete. Gli strumenti di osservabilità raccolgono tutti gli intervalli e li unificano in una o più tracce, consentendo di vedere il percorso che ha formato durante il suo ciclo di vita. Se hai un problema come la latenza di rete o un difetto di sistema, ora è più facile sezionare (sbucciare la cipolla) ed eseguire il debug del problema (errore in quale livello).
Ora in un grande ambiente distribuito, quando le tue applicazioni ricevono milioni di richieste, i dati di traccia crescono in un volume enorme. La raccolta e l'analisi di queste tracce è costosa per il consumo di spazio di archiviazione e il trasferimento dei dati. Quindi, per risparmiare sui costi, i dati di traccia vengono campionati, perché nella maggior parte dei casi, i team di ingegneri hanno bisogno solo di alcuni dei pezzi per indagare su cosa è andato storto o qual è il modello di errore.
Con questo piccolo esempio, comprendiamo che otteniamo informazioni molto più approfondite sui nostri sistemi. Pertanto, considerando una scala più ampia di sistemi, i team di ingegneri possono acquisire e lavorare sui dati campionati per migliorare l'attuale struttura del sistema, applicare o ritirare nuovi componenti, aggiungere un altro livello di sicurezza, rimuovere i colli di bottiglia e così via.
Le organizzazioni dovrebbero scegliere l'osservabilità?
Dovremmo tutti capire che gli obiettivi finali sono una migliore esperienza utente e una maggiore soddisfazione degli utenti. E il percorso per raggiungere questi obiettivi può essere semplificato con un framework di osservabilità automatizzato e proattivo. Stabilire una cultura di miglioramento continuo e ottimizzazione è considerato l'approccio aziendale e di leadership ottimale.
In questa era di trasformazione digitale, l'osservabilità è diventata un must per un'azienda per avere successo nel suo viaggio digitale. Fornendoti tracce approfondite, l'osservabilità ti manovra anche per essere informato sui dati piuttosto che solo guidato dai dati.
Conclusione
Sebbene abbiamo usato i termini monitoraggio e osservabilità in modo intercambiabile, abbiamo visto che mentre il monitoraggio ti aiuta con informazioni sullo stato di salute del sistema e sugli eventi che si verificano su di esso, l'osservabilità ti facilita a fare inferenze basate su prove raccolte da strati più profondi di un fine- ambiente to-end.
L'osservabilità è e può anche essere percepita come una componente del framework di Data Governance. In questa generazione, in cui il volume di dati in continua crescita risiede su una rete di hardware di base, è fondamentale mantenere le architetture il più semplici possibile. Ed evidentemente diventa un compito impossibile gestire l'ambiente in futuro. Pertanto, l'implementazione di policy e regole di governance appropriate e automatizzate per mantenere ordinata la tua vasta rete di sistemi, pipeline e dati richiede l'azione il prima possibile.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- capace
- Chi siamo
- Secondo
- Raggiungere
- il raggiungimento
- Action
- aggiuntivo
- Informazioni aggiuntive
- adottare
- adottato
- Adozione
- Avvento
- Tutti
- consente
- sempre
- analizzare
- l'analisi
- ed
- Un altro
- rispondere
- Applicazioni
- applicazioni
- APPLICA
- approccio
- opportuno
- architettura
- gli attributi
- autenticare
- Automatizzata
- evitare
- basato
- fondamentalmente
- perché
- diventare
- diventa
- ha iniziato
- MIGLIORE
- Meglio
- Big
- Big Data
- Blog
- Post di Blog
- strozzature
- affari
- chiamata
- Bandi
- catturare
- casi
- centralizzata
- il cambiamento
- Modifiche
- Scegli
- Chiudi
- raccogliere
- Raccolta
- merce
- completamento di una
- complesso
- componente
- componenti
- concetto
- Problemi della Pelle
- confuso
- considerato
- considerando
- consumo
- contesto
- continuo
- di controllo
- Costi
- potuto
- CPU
- Cultura
- Corrente
- cliente
- dati
- data-driven
- banche dati
- VERSITÀ DEI DATI
- giorno per giorno
- Giorni
- decennio
- decentrata
- decisioni
- deep
- più profondo
- definito
- descrivere
- destinazione
- dettagli
- DID
- diverso
- digitale
- DIGITAL TRANSFORMATION
- distribuito
- sistemi distribuiti
- non
- giù
- durante
- e-commerce
- più facile
- incorporato
- abbracciando
- consentendo
- da un capo all'altro
- Ingegneria
- Ambiente
- errore
- errori
- stabilire
- eccetera
- Anche
- eventi
- EVER
- sempre crescente
- qualunque cosa
- prova
- evoluzione
- esempio
- costoso
- esperienza
- esterno
- facilita
- flussi
- formato
- Contesto
- quadri
- da
- ELETTRICA
- ottenere
- Go
- Obiettivi
- la governance
- maggiore
- cresce
- successo
- Happening
- Hardware
- Salute e benessere
- Aiuto
- aiuta
- storia
- Colpire
- speranza
- HOT
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- Enorme
- immagini
- Implementazione
- importante
- impossibile
- competenze
- miglioramento
- in
- informazioni
- informati
- intuizioni
- interno
- indagare
- invoca
- problema
- sicurezza
- IT
- Gestione dell’IT
- viaggio
- mantenere
- conoscenze
- paesaggio
- grandi
- superiore, se assunto singolarmente.
- Latenza
- strato
- galline ovaiole
- Leadership
- apprendimento
- lenti
- Leva
- ciclo di vita
- Limitato
- linea
- vivere
- caricare
- Lunghi
- lotto
- fatto
- make
- FA
- Fare
- gestire
- gestione
- gestione
- molti
- Rappresentanza
- matematico
- max-width
- misurare
- Memorie
- Metrica
- microservices
- milioni
- verbale
- monitoraggio
- Monolitico
- maggior parte
- cambiano
- in movimento
- multiplo
- Must-have
- Natura
- necessaria
- Bisogno
- esigenze
- rete
- Rete
- sistema di rete
- New
- ONE
- operazione
- operativa
- Operazioni
- ottimale
- ottimizzazione
- organizzazioni
- Altro
- complessivo
- proprio
- Carta
- sentiero
- Cartamodello
- Pagamento
- percepito
- performance
- esecuzione
- periodo
- pezzi
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- Termini e Condizioni
- povero
- possibile
- Post
- Post
- Proactive
- Problema
- processi
- Prodotto
- Progressi
- fornire
- fornisce
- fornitura
- pubblicato
- quantitativo
- Domande
- piuttosto
- Leggi
- Lettura
- ricevere
- riceve
- problemi di
- rimuovere
- rappresentato
- richiesta
- richieste
- richiede
- elasticità
- limitato
- colpevole
- Aumento
- tetto
- norme
- soddisfazione
- Risparmi
- Scala
- scala
- Cerca
- ricerca
- Secondo
- problemi di
- Servizi
- alcuni
- dovrebbero
- Spettacoli
- Un'espansione
- singolo
- rallentare
- piccole
- So
- Software
- RISOLVERE
- alcuni
- Arrivo
- Suono
- Fonte
- campate
- specifico
- spendere
- pila
- Stage
- inizia a
- iniziato
- Regione / Stato
- stati
- rimasto
- Ancora
- fermato
- conservazione
- Storia
- La struttura
- di successo
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- prende
- Task
- le squadre
- Consulenza
- condizioni
- I
- le informazioni
- L’ORIGINE
- loro
- in tal modo
- tre
- Attraverso
- per tutto
- tempo
- time line
- a
- oggi
- strumenti
- argomento
- tracciare
- Tracciabilità
- Tracciato
- Tracking
- trasferimento
- Trasformazione
- ombrello
- per
- sottostante
- capire
- aggiornamento
- Impiego
- Utente
- Esperienza da Utente
- generalmente
- Prezioso
- vario
- Video
- visibilità
- importantissima
- volume
- aspettare
- In attesa
- Sito web
- Che
- Che cosa è l'
- quale
- while
- volere
- entro
- Lavora
- Forza lavoro
- lavori
- mondo
- sarebbe
- Wrong
- Trasferimento da aeroporto a Sharm
- zefiro











