Gartner, Inc. lo stima i dati errati costano organizzazioni una media di 12.9 milioni di dollari all'anno.
Ci occupiamo quotidianamente di petabyte di dati e i problemi di qualità dei dati sono comuni con volumi di dati così enormi. I dati errati costano alle organizzazioni denaro, reputazione e tempo. Quindi è molto importante monitorare e convalidare continuamente la qualità dei dati.
I dati errati includono informazioni imprecise, dati mancanti, informazioni errate, dati non conformi e dati duplicati. I dati errati si tradurranno in un'analisi dei dati errata, con conseguenti decisioni sbagliate e strategie inefficaci.
La qualità dei dati di Experian ha rilevato che l'azienda media perde il 12% dei suoi ricavi a causa di dati insufficienti. Oltre al denaro, le aziende subiscono anche perdite di tempo.
L'identificazione delle anomalie nei dati prima dell'elaborazione aiuterà le organizzazioni a ottenere informazioni più preziose sul comportamento dei clienti e contribuirà a ridurre i costi.
La libreria Grandi aspettative aiuta le organizzazioni a verificare e affermare tali anomalie nei dati con oltre 200 regole pronte all'uso prontamente disponibili.
Great Expectations è una libreria Python open source che ci aiuta nella convalida dei dati. Grandi aspettative fornire un insieme di metodi o funzioni a aiutare i data engineer convalidare rapidamente un determinato set di dati.
In questo articolo esamineremo i passaggi coinvolti nella convalida dei dati da parte della libreria Great Expectations.
GE è come unit test per i dati. GE fornisce asserzioni denominate Aspettative per applicare alcune regole ai dati sottoposti a test. Ad esempio, l'ID/numero di polizza non deve essere vuoto per un documento di polizza assicurativa. Per configurare ed eseguire GE, è necessario seguire i passaggi seguenti. Sebbene ci siano diversi modi per lavorare con GE (usando la sua CLI), spiegherò il modo programmatico di impostare le cose in questo articolo. Tutto il codice sorgente spiegato in questo articolo è disponibile in questo Repository GitHub.
Passaggio 1: impostare la configurazione dei dati
GE ha un concetto di negozi. Gli archivi non sono altro che la posizione fisica sul disco in cui è possibile archiviare le aspettative (regole/asserzioni), i dettagli di esecuzione, i dettagli del checkpoint, i risultati della convalida e i documenti di dati (versioni HTML statiche dei risultati della convalida). CLICCA QUI per saperne di più sui negozi.
GE supporta vari back-end del negozio. In questo articolo, utilizziamo il backend e le impostazioni predefinite dell'archivio file. GE supporta altri back-end del negozio come AWS (Amazon Web Services) S3, Azure Blob, PostgreSQL, ecc. Fare riferimento a saperne di più sui backend. Il frammento di codice seguente mostra una configurazione dei dati molto semplice:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
La configurazione precedente utilizza il back-end dell'archivio file con impostazioni predefinite. GE creerà automaticamente le cartelle necessarie per eseguire le aspettative. Aggiungeremo le origini dati nel passaggio successivo.
Passaggio 2: impostare la configurazione dell'origine dati
GE supporta tre tipi di origini dati:
- Pandas
- Scintilla
- SQLAlchemy
La configurazione dell'origine dati indica a GE di utilizzare un motore di esecuzione specifico per elaborare il set di dati fornito. Ad esempio, se si configura l'origine dati per utilizzare il motore di esecuzione Pandas, è necessario fornire a GE un frame di dati Pandas con i dati per soddisfare le aspettative. Di seguito è riportato un esempio per l'utilizzo di Panda come origine dati:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Si prega di fare riferimento a questa documentazione per ulteriori informazioni sulle origini dati.
Passaggio 3: crea una suite delle aspettative e aggiungi le aspettative
Questo passaggio è la parte cruciale. In questo passaggio, creeremo una suite e aggiungeremo le aspettative alla suite. Puoi considerare una suite come un gruppo di aspettative che verranno eseguite in batch. Le aspettative che creiamo qui sono per convalidare un rapporto di vendita di esempio. Puoi scaricare il vendite.csv file.
Lo snippet di codice seguente mostra come creare una suite e aggiungere aspettative. Aggiungeremo due aspettative alla nostra suite.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
La prima aspettativa, "expect_column_values_to_be_in_set", controlla se i valori della colonna (product_group) sono uguali a uno qualsiasi dei valori nel dato value_set. La seconda aspettativa verifica se i valori della colonna "id" sono univoci.
Una volta aggiunte e salvate le aspettative, ora possiamo eseguire queste aspettative su un set di dati che vedremo nel passaggio 4.
Passaggio 4: caricare e convalidare i dati
In questo passaggio, caricheremo il nostro file CSV in pandas.DataFrame e creeremo un checkpoint per eseguire le aspettative che abbiamo creato sopra.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Creiamo una richiesta batch per i nostri dati, fornendo il nome dell'origine dati, che dirà a GE di utilizzare un motore di esecuzione specifico, nel nostro caso Panda. Creiamo una configurazione del checkpoint e quindi convalidiamo la nostra richiesta batch rispetto al checkpoint. È possibile aggiungere più richieste batch se le aspettative si applicano ai dati nel batch in un singolo checkpoint. Il metodo `run_checkpoint` restituisce il risultato in formato JSON e può essere utilizzato per ulteriori elaborazioni o analisi.
Risultati
Dopo aver eseguito le aspettative sul nostro set di dati, GE crea un dashboard HTML statico con i risultati per il nostro checkpoint. I risultati contengono il numero di aspettative valutate, aspettative riuscite, aspettative non riuscite e percentuali di successo. Eventuali record che non corrispondono alle aspettative fornite verranno evidenziati nella pagina. Di seguito è riportato un esempio per l'esecuzione corretta:
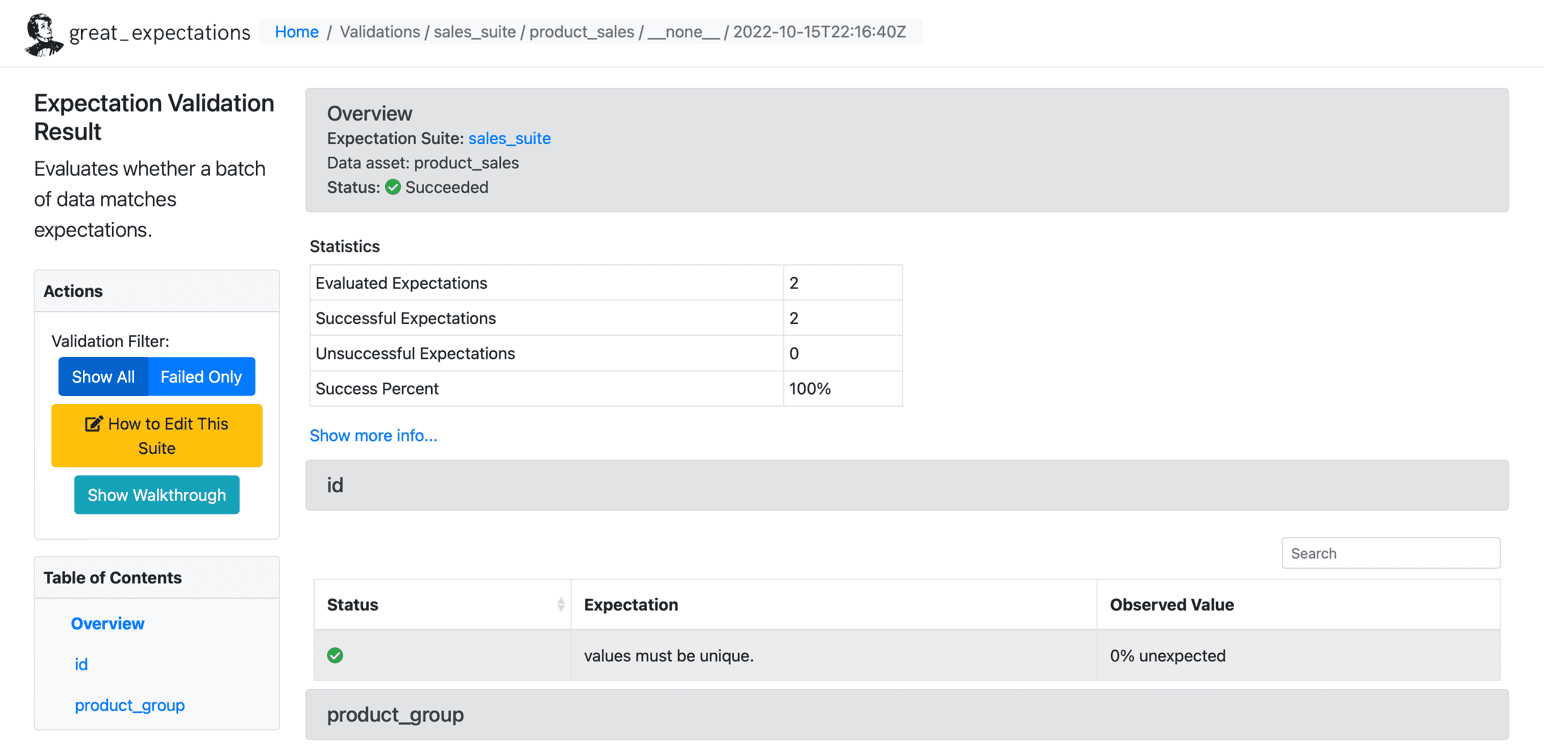
Fonte: grandi aspettative
Di seguito è riportato un esempio dell'aspettativa fallita:
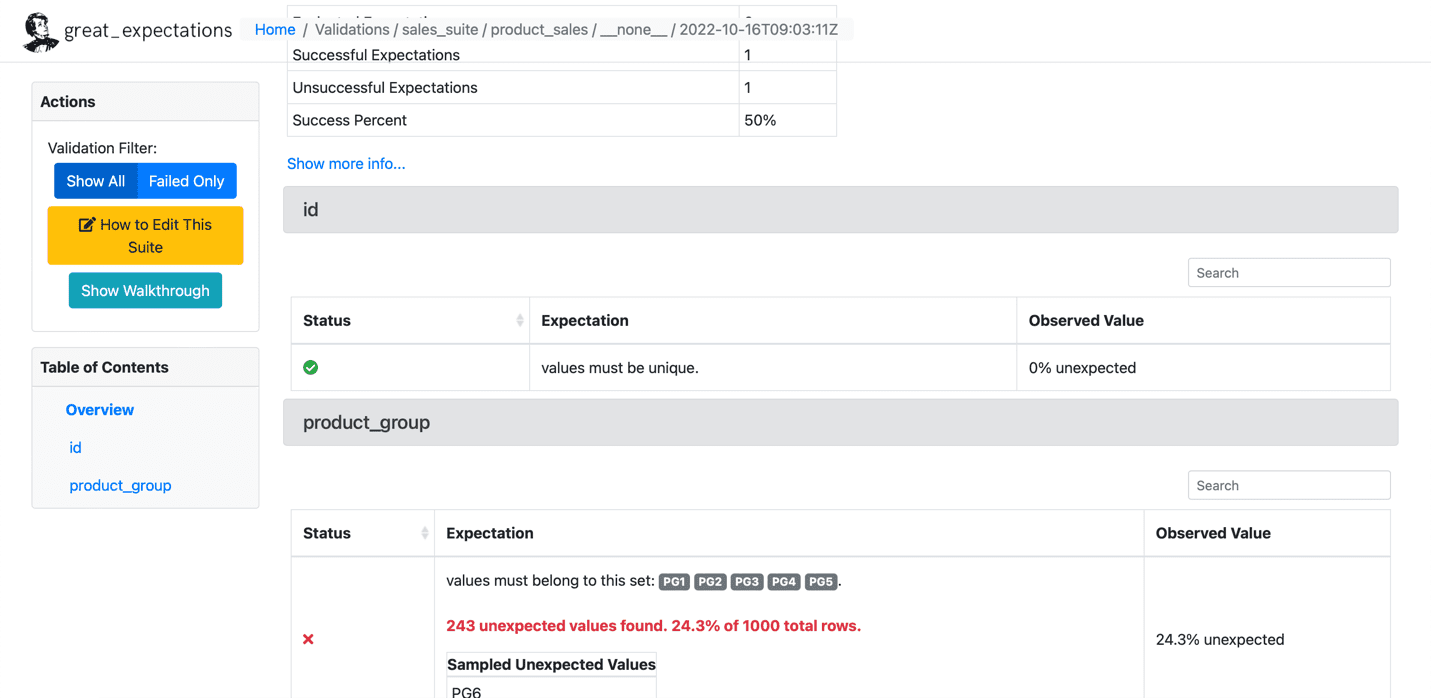
Fonte: grandi aspettative
Abbiamo impostato GE in quattro fasi e gestito con successo le aspettative su un determinato set di dati. GE ha funzionalità più avanzate come scrivere le tue aspettative personalizzate, che tratteremo in articoli futuri. Molte organizzazioni utilizzano ampiamente GE per personalizzare i requisiti dei propri clienti e scrivere aspettative personalizzate.
Saisyam Dampuri viene fornito con oltre 18 anni di esperienza nello sviluppo di software ed è appassionato di esplorare nuove tecnologie e strumenti. Attualmente lavora come Sr. Cloud Architect presso Anblicks, TX, USA. Pur non programmando, sarà impegnato con la fotografia, la cucina e i viaggi.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18+
- 9
- a
- Chi siamo
- sopra
- aggiunto
- Avanzate
- contro
- Tutti
- Amazon
- Amazon Web Services
- .
- analitica
- ed
- a parte
- APPLICA
- articolo
- news
- automaticamente
- disponibile
- media
- AWS
- azzurro
- BACKEND
- Vasca
- dati errati
- prima
- sotto
- detto
- Custodie
- Controlli
- clienti
- Cloud
- codice
- codifica
- Colonna
- Uncommon
- Aziende
- azienda
- concetto
- Configurazione
- Prendere in considerazione
- contesto
- cucina
- Costi
- coprire
- creare
- creato
- crea
- cruciale
- Attualmente
- costume
- cliente
- comportamento del cliente
- personalizzare
- alle lezioni
- cruscotto
- dati
- analisi dei dati
- qualità dei dati
- set di dati
- affare
- decisioni
- defaults
- dettagli
- Mercato
- documento
- scaricare
- motore
- stime
- eccetera
- Etere (ETH)
- valutato
- esempio
- eseguire
- esecuzione
- aspettativa
- le aspettative
- esperienza
- Spiegare
- ha spiegato
- Esplorare
- fallito
- Caratteristiche
- Compila il
- Nome
- seguire
- Forbes
- formato
- essere trovato
- TELAIO
- da
- funzioni
- ulteriormente
- futuro
- Guadagno
- ge
- dato
- grande
- Gruppo
- Aiuto
- aiuta
- qui
- Evidenziato
- Come
- Tutorial
- HTML
- HTTPS
- Enorme
- importante
- in
- impreciso
- Inc.
- inclusi
- informazioni
- intuizioni
- assicurazione
- coinvolto
- sicurezza
- IT
- json
- KDnuggets
- IMPARARE
- Biblioteca
- caricare
- località
- Guarda
- Perde
- spento
- molti
- partita
- metodo
- metodi
- milione
- mancante
- soldi
- Monitorare
- Scopri di più
- multiplo
- Nome
- necessaria
- Bisogno
- di applicazione
- New
- Nuove tecnologie
- GENERAZIONE
- numero
- open source
- organizzazioni
- Altro
- Superare
- panda
- parte
- appassionato
- fotografia
- Fisico
- Platone
- Platone Data Intelligence
- PlatoneDati
- politica
- Postgresql
- processi
- lavorazione
- programmatica
- fornire
- purché
- fornisce
- fornitura
- Python
- qualità
- rapidamente
- record
- Ridotto
- rapporto
- reputazione
- richiesta
- richieste
- Requisiti
- colpevole
- risultante
- Risultati
- problemi
- Le vendite
- norme
- Correre
- vendite
- Secondo
- Servizi
- set
- regolazione
- dovrebbero
- Spettacoli
- Un'espansione
- singolo
- Software
- lo sviluppo del software
- alcuni
- Fonte
- codice sorgente
- fonti
- specifico
- step
- Passi
- Tornare al suo account
- negozi
- strategie
- il successo
- di successo
- Con successo
- tale
- suite
- supporti
- Tecnologie
- dice
- test
- test
- I
- L’ORIGINE
- loro
- cose
- tre
- tempo
- a
- strumenti
- Di viaggio
- TX
- Tipi di
- per
- unico
- unità
- us
- USD
- uso
- CONVALIDARE
- convalida
- Prezioso
- Valori
- vario
- verificare
- volumi
- modi
- sito web
- servizi web
- se
- quale
- while
- volere
- Lavora
- lavoro
- scrivere
- scrittura
- anni
- Trasferimento da aeroporto a Sharm
- zefiro

![Come velocizzare le query SQL utilizzando gli indici [Python Edition] - KDnuggets](https://platoaistream.net/wp-content/uploads/2023/08/how-to-speed-up-sql-queries-using-indexes-python-edition-kdnuggets-360x203.png)





