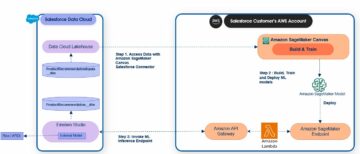
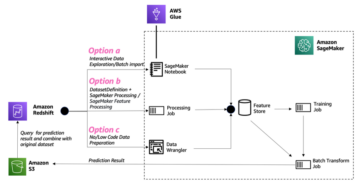
Gestore di dati di Amazon SageMaker riduce il tempo per aggregare e preparare i dati per il machine learning (ML) da settimane a minuti. Con Data Wrangler, puoi selezionare ed interrogare i dati con pochi clic, trasformare rapidamente i dati con oltre 300 trasformazioni di dati integrate e comprendere i tuoi dati con visualizzazioni integrate senza scrivere alcun codice.
Inoltre, puoi creare trasformazioni personalizzate unico per le vostre esigenze. Le trasformazioni personalizzate consentono di scrivere trasformazioni personalizzate utilizzando PySpark, Pandas o SQL.
Data Wrangler ora supporta una personalizzazione Funzione definita dall'utente di Panda (UDF) trasformata in grado di elaborare in modo efficiente set di dati di grandi dimensioni. Puoi scegliere tra due modalità UDF di Panda personalizzate: Panda e Python. Entrambe le modalità forniscono una soluzione efficiente per elaborare i set di dati e la modalità scelta dipende dalle tue preferenze.
In questo post, dimostriamo come utilizzare la nuova trasformazione UDF di Pandas in entrambe le modalità.
Panoramica della soluzione
Al momento della stesura di questo documento, puoi importare set di dati in Data Wrangler da Servizio di archiviazione semplice Amazon (Amazon S3), Amazzone Atena, Amazon RedShift, Databricks e Fiocco di neve. Per questo post, utilizziamo Amazon S3 per archiviare il 2014 Amazon recensioni set di dati.
I dati hanno una colonna chiamata reviewText contenente testo generato dall'utente. Il testo ne contiene anche diversi basta parole, che sono parole comuni che non forniscono molte informazioni, come "a", "an" e "the". La rimozione delle parole non significative è una fase di preelaborazione comune nelle pipeline di elaborazione del linguaggio naturale (NLP). Possiamo creare una funzione personalizzata per rimuovere le stop word dalle recensioni.
Crea una trasformazione UDF Pandas personalizzata
Esaminiamo il processo di creazione di due trasformazioni UDF Panda personalizzate di Data Wrangler utilizzando le modalità Panda e Python.
- Scarica la Set di dati delle recensioni di musica digitale e caricalo su Amazon S3.
- Apri Amazon Sage Maker Studio e creare un nuovo flusso di Data Wrangler.

- Sotto Importa le datescegli Amazon S3 e vai alla posizione del set di dati.
- Nel Tipo di filescegli jsonl.
Nella tabella dovrebbe essere visualizzata un'anteprima dei dati.
- Scegli Importare procedere.

- Dopo aver importato i dati, scegli il segno più accanto a Tipi di dati e scegli Aggiungi trasformazione.

- Scegli Trasformazione personalizzata.

- Nel menu a tendina, Python (funzione definita dall'utente).

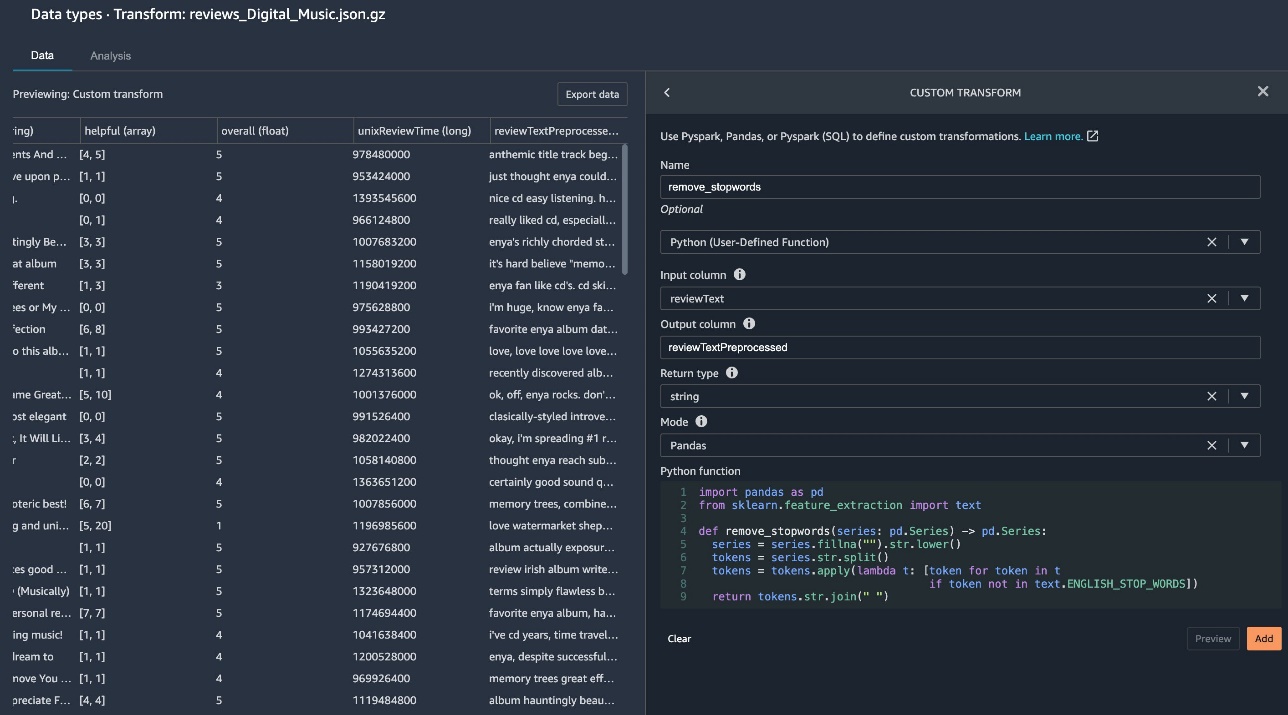
Ora creiamo la nostra trasformazione personalizzata per rimuovere le parole di arresto.
- Specifica la colonna di input, la colonna di output, il tipo restituito e la modalità.
L'esempio seguente usa la modalità Panda. Ciò significa che la funzione dovrebbe accettare e restituire una serie Panda della stessa lunghezza. Puoi pensare a una serie Pandas come a una colonna in una tabella o a un pezzo della colonna. Questa è la modalità UDF di Panda più performante perché Panda può vettorizzare le operazioni su batch di valori anziché uno alla volta. Il pd.Series i suggerimenti sul tipo sono richiesti in modalità Panda.
Se preferisci utilizzare Python puro anziché l'API Pandas, la modalità Python ti consente di specificare una funzione Python pura che accetta un singolo argomento e restituisce un singolo valore. L'esempio seguente è equivalente al codice Pandas precedente in termini di output. I suggerimenti sui tipi non sono richiesti in modalità Python.

- Scegli Aggiungi per aggiungere la tua trasformazione personalizzata.
Conclusione
Data Wrangler ha oltre 300 trasformazioni integrate e puoi anche aggiungere trasformazioni personalizzate uniche per le tue esigenze. In questo post, abbiamo dimostrato come elaborare i set di dati con la nuova trasformazione UDF Pandas personalizzata di Data Wrangler, utilizzando sia le modalità Panda che Python. Puoi utilizzare entrambe le modalità in base alle tue preferenze. Per ulteriori informazioni su Data Wrangler, fare riferimento a Creare e utilizzare un flusso di Data Wrangler.
Informazioni sugli autori
 Ben Harris è un ingegnere del software con esperienza nella progettazione, distribuzione e manutenzione di pipeline di dati scalabili e soluzioni di machine learning in una varietà di domini. Ben ha creato sistemi per la raccolta e l'etichettatura dei dati, la classificazione di immagini e testo, la modellazione da sequenza a sequenza, l'incorporamento e il raggruppamento, tra gli altri.
Ben Harris è un ingegnere del software con esperienza nella progettazione, distribuzione e manutenzione di pipeline di dati scalabili e soluzioni di machine learning in una varietà di domini. Ben ha creato sistemi per la raccolta e l'etichettatura dei dati, la classificazione di immagini e testo, la modellazione da sequenza a sequenza, l'incorporamento e il raggruppamento, tra gli altri.
 Haider Naqvi è un Solutions Architect presso AWS. Ha una vasta esperienza di sviluppo software e architettura aziendale. Si concentra sul consentire ai clienti di ottenere risultati di business con AWS. Ha sede a New York.
Haider Naqvi è un Solutions Architect presso AWS. Ha una vasta esperienza di sviluppo software e architettura aziendale. Si concentra sul consentire ai clienti di ottenere risultati di business con AWS. Ha sede a New York.
 Vishal Srivastava è un Technical Account Manager presso AWS. Con un background in sviluppo software e analisi, lavora principalmente con il settore dei servizi finanziari e clienti business nativi digitali e supporta il loro viaggio nel cloud. Nel tempo libero ama viaggiare con la sua famiglia.
Vishal Srivastava è un Technical Account Manager presso AWS. Con un background in sviluppo software e analisi, lavora principalmente con il settore dei servizi finanziari e clienti business nativi digitali e supporta il loro viaggio nel cloud. Nel tempo libero ama viaggiare con la sua famiglia.
- Coinsmart. Il miglior scambio di bitcoin e criptovalute d'Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. ACCESSO LIBERO.
- Criptofalco. Radar Altcoin. Prova gratuita.
- Fonte: https://aws.amazon.com/blogs/machine-learning/pandas-user-defined-functions-are-now-available-in-amazon-sagemaker-data-wrangler/
- "
- 10
- 100
- 9
- Chi siamo
- Il mio account
- operanti in
- Amazon
- tra
- analitica
- api
- architettura
- disponibile
- AWS
- sfondo
- incassato
- affari
- Scegli
- classificazione
- Cloud
- codice
- collezione
- Colonna
- Uncommon
- contiene
- creare
- Creazione
- costume
- Clienti
- dati
- dimostrare
- dimostrato
- dipende
- distribuzione
- progettazione
- Mercato
- digitale
- domini
- efficiente
- in modo efficiente
- consentendo
- ingegnere
- Impresa
- esempio
- esperienza
- estensivo
- famiglia
- finanziario
- servizi finanziari
- flusso
- si concentra
- i seguenti
- Gratis
- function
- Come
- Tutorial
- HTTPS
- Immagine
- informazioni
- ingresso
- IT
- Entra a far parte
- etichettatura
- Lingua
- grandi
- IMPARARE
- apprendimento
- località
- macchina
- machine learning
- direttore
- partita
- ML
- Scopri di più
- maggior parte
- Musica
- Naturale
- New York
- Operazioni
- Preparare
- Anteprima
- processi
- lavorazione
- fornire
- Presto
- rapidamente
- necessario
- Requisiti
- ritorno
- problemi
- Recensioni
- scalabile
- settore
- Serie
- Servizi
- Un'espansione
- Software
- lo sviluppo del software
- Software Engineer
- soluzione
- Soluzioni
- spazi
- conservazione
- Tornare al suo account
- supporti
- SISTEMI DI TRATTAMENTO
- Consulenza
- Attraverso
- tempo
- token
- Tokens
- Trasformare
- viaggiare
- capire
- unico
- uso
- APPREZZIAMO
- varietà
- senza
- parole
- lavori
- scrittura