Amazon RedShift è un popolare data warehouse sul cloud che offre un servizio basato sul cloud completamente gestito che si integra perfettamente con quello di un'organizzazione Servizio di archiviazione semplice Amazon (Amazon S3), flussi di dati in tempo reale, flussi di lavoro di machine learning (ML), flussi di lavoro transazionali e molto altro ancora, il tutto fornendo un rapporto prezzo/prestazioni fino a 7.9 volte migliore rispetto ad altri data warehouse su cloud.
Come tutti i servizi AWS, Amazon Redshift è un servizio ossessionato dal cliente che riconosce che non esiste un modello di dati valido per tutti i clienti, motivo per cui Amazon Redshift supporta più modelli di dati come Star Schemas , Schemi Snowflake e Data Vault. Questo post illustra le best practice per la progettazione di Data Vault di livello aziendale su scala variabile utilizzando Amazon Redshift; IL secondo post in questa serie in due parti vengono discusse le esigenze più urgenti durante la progettazione di un Data Vault di livello aziendale e il modo in cui tali esigenze vengono soddisfatte da Amazon Redshift.
Che si tratti del desiderio di conservare facilmente la derivazione dei dati direttamente all'interno del data warehouse, di stabilire un modello di dati indipendente dal sistema di origine all'interno del data warehouse o di conformarsi più facilmente alle normative GDPR, i clienti che implementano un modello Data Vault trarranno vantaggio dalla discussione di questo post su considerazioni, best practice e funzionalità di Amazon Redshift rilevanti per la creazione di Data Vault di livello aziendale. Costruire una versione iniziale di qualsiasi cosa può spesso essere semplice, ma costruire qualcosa con scalabilità, sicurezza, resilienza e prestazioni di livello aziendale richiede in genere la conoscenza e l'adesione a best practice testate sul campo e l'utilizzo degli strumenti e delle funzionalità giusti nel giusto scenario .
Panoramica dell'archivio dati
Esaminiamo innanzitutto brevemente la premessa e i concetti principali di Data Vault. I modelli di dati forniscono una struttura su come i dati in un data warehouse dovrebbero essere organizzati in tabelle di database. Amazon Redshift supporta numerosi modelli di dati e alcuni dei modelli di dati più popolari includono Schemi STELLA e archivio dati.
Data Vault non è solo una metodologia di modellazione, è anche un framework supponente che ti dice come risolvere determinati problemi nel tuo ecosistema di dati. Un framework supponente fornisce una serie di linee guida e convenzioni che gli sviluppatori dovrebbero seguire, anziché lasciare tutte le decisioni allo sviluppatore. Puoi confrontare questo risultato con ciò che fanno i framework di grandi aziende come Spring o Micronauts quando sviluppano applicazioni su scala aziendale. Ciò è incredibilmente utile soprattutto nei progetti di data warehouse di grandi dimensioni, perché struttura la pipeline di estrazione, caricamento e trasformazione (ELT) e indica chiaramente come risolvere determinati problemi nei contesti di dati e pipeline. Ciò consente anche un elevato grado di automazione.
Data Vault 2.0 consente quanto segue:
- Sviluppo agile di data warehouse
- Inserimento dati parallelo
- Un approccio scalabile per gestire più origini dati anche sulla stessa entità
- Un elevato livello di automazione
- Storicizzazione
- Supporto completo del lignaggio
Tuttavia, Data Vault 2.0 comporta anche dei costi e vi sono casi d'uso in cui non è adatto, come i seguenti:
- Hai solo poche origini dati senza dati correlati o sovrapposti (ad esempio, una banca con un sistema single core)
- Hai un reporting semplice con modifiche poco frequenti
- Disponi di risorse e conoscenze limitate di Data Vault
Data Vault organizza in genere i dati di un'organizzazione in una pipeline di quattro livelli: staging, raw, business e presentazione. Il livello di staging rappresenta l'acquisizione dei dati e le trasformazioni e i miglioramenti leggeri dei dati che si verificano prima che i dati raggiungano il loro luogo di riposo più permanente, il Raw Data Vault (RDV).
L'RDV conserva la copia storicizzata di tutti i dati provenienti da più sistemi di origine. Viene definito grezzo perché a questo punto non si sono verificati filtri o trasformazioni aziendali ad eccezione dell'archiviazione dei dati in destinazioni indipendenti dal sistema di origine. L'RDV organizza i dati in tre tipi principali di tabelle:
- Mozzi – Questo tipo di tabella rappresenta un'entità aziendale principale come un cliente. Ogni record in una tabella hub è abbinato a metadati che identificano l'ora di creazione del record, il sistema di origine di origine e la chiave aziendale univoca.
- Attacchi – Questo tipo di tabella definisce una relazione tra due o più hub, ad esempio il modo in cui l'hub del cliente e l'hub degli ordini devono essere uniti.
- satelliti – Questo tipo di tabella registra i dati di riferimento storicizzati su hub o collegamenti, come ad esempio
product_infoedcustomer_info
L'RDV viene utilizzato per inserire i dati nel Data Vault (BDV) aziendale, che è responsabile della riorganizzazione, denormalizzazione e aggregazione dei dati per un consumo ottimizzato da parte del mercato di presentazione. I mart di presentazione, noti anche come livello data mart, riorganizzano ulteriormente i dati per un consumo ottimizzato da parte dei client a valle, come i dashboard aziendali. I mart di presentazione possono, ad esempio, riorganizzare i dati in uno schema STAR.
Per una panoramica più dettagliata di Data Vault insieme a una discussione sulla sua applicabilità nel contesto di casi d'uso molto interessanti, fare riferimento a quanto segue:
Come si inserisce Data Vault in un'architettura dati moderna?
Attualmente, il paradigma della casa sul lago sta diventando un modello importante nella progettazione del data warehouse, anche come parte di un'architettura data mesh. Ciò segue lo schema dei data Lake che si avvicinano a ciò che può fare un data warehouse e viceversa. Per competere con la flessibilità di un data Lake, Data Vault è una buona scelta. In questo modo, il data warehouse non diventa un collo di bottiglia e puoi ottenere agilità, flessibilità, scalabilità e adattabilità simili durante l'acquisizione e l'onboarding di nuovi dati.
Flessibilità della piattaforma
In questa sezione verranno discusse alcune configurazioni Redshift consigliate per Data Vault di varia scala. Come accennato in precedenza, i livelli all'interno di una piattaforma Data Vault sono ben noti. In genere vediamo un flusso dal livello di staging al RDV, al BDV e infine al mercato di presentazione.
Amazon Redshift è estremamente flessibile nel supportare Data Vault sia modesti che su larga scala, offrendo funzionalità come le seguenti:
Depositi di dati modesti o su larga scala
Amazon Redshift è flessibile nel modo in cui decidi di strutturare questi livelli. Per depositi di dati modesti, un singolo warehouse Redshift con un database con più schemi funzionerà perfettamente.
Per archivi di dati di grandi dimensioni con trasformazioni più complesse, prenderemo in considerazione più warehouse, ciascuno con il proprio schema di dati master che rappresentano uno o più livelli. Il motivo per utilizzare più warehouse è sfruttare la flessibilità dell'architettura Amazon Redshift per implementare implementazioni di data vault su larga scala, come l'utilizzo di nodi Redshift RA3 e Redshift Serverless per separare il livello di elaborazione dal livello di storage dei dati e l'utilizzo della condivisione dei dati Redshift per condividere i dati tra diversi magazzini Redshift. Ciò consente di ridimensionare la capacità di elaborazione in modo indipendente a ciascun livello a seconda della complessità dell'elaborazione. Il livello di staging, ad esempio, può essere un livello all'interno del tuo data Lake (storage Amazon S3) o uno schema all'interno di un database Redshift.
utilizzando Integrazioni zero-ETL di Amazon Aurora con Amazon Redshift, è possibile creare un'implementazione del data vault con un livello di gestione temporanea in un file Amazon Aurora database che si occuperà dell'elaborazione delle transazioni in tempo reale e sposterà automaticamente i dati su Amazon Redshift per l'ulteriore elaborazione nell'implementazione di Data Vault senza creare pipeline ETL complesse. In questo modo, puoi utilizzare Amazon Aurora per le transazioni e Amazon Redshift per l'analisi. Le risorse di calcolo sono isolate per gli stessi dati e stai utilizzando gli strumenti più efficienti per elaborarli.
Depositi di dati su larga scala
Per le piattaforme Data Vault più grandi, la concorrenza e la potenza di elaborazione diventano importanti per elaborare sia il caricamento dei dati che qualsiasi trasformazione aziendale. Amazon Redshift offre flessibilità per aumentare la capacità di elaborazione sia orizzontalmente tramite ridimensionamento della concorrenza e verticalmente tramite ridimensionamento del cluster e anche tramite architetture diverse per ciascun livello di Data Vault.
Strato di stadiazione
È possibile creare un data warehouse per il livello di staging ed eseguire qui l'elaborazione di regole aziendali complesse, incluso il calcolo delle chiavi hash, delle differenze hash e l'aggiunta di colonne di metadati tecnici. Se i dati non vengono caricati 24 ore su 7, XNUMX giorni su XNUMX, prendere in considerazione la possibilità di mettere in pausa/riprendere oppure a Gruppo di lavoro Redshift Serverless.
Livello Archivio dati grezzi
Per Raw Data Vault (RDV), si consiglia di creare un magazzino Redshift per l'intero RDV o un magazzino Redshift per una o più aree tematiche all'interno dell'RDV. Ad esempio, se il volume dei dati e il numero di tabelle normalizzate all'interno dell'RDV per una particolare area tematica è elevato (o il livello dei dati grezzi ha così tante tabelle da esaurire limite massimo della tabella su Amazon Redshift o il vantaggio dell'isolamento del carico di lavoro all'interno di un singolo magazzino Redshift supera il sovraccarico di prestazioni e gestione), quest'area tematica all'interno dell'RDV può essere eseguita e padroneggiata sul proprio magazzino Redshift.
L'RDV viene in genere caricato 24 ore su 7, XNUMX giorni su XNUMX, quindi un data warehouse Redshift con provisioning potrebbe essere più adatto in questo caso per sfruttare i prezzi delle istanze riservate.
Livello dell'archivio dati aziendale
Per creare un data warehouse per il livello BDV (Data Vault) aziendale, questo potrebbe essere di dimensioni maggiori rispetto ai data warehouse precedenti a causa della natura dell'elaborazione BDV, in genere la denormalizzazione dei dati da un numero elevato di tabelle RDV di origine.
Alcuni clienti eseguono l'elaborazione BDV una volta al giorno, quindi una finestra di pausa/ripresa per il cluster fornito da Redshift potrebbe essere vantaggiosa in termini di costi in questo caso. Puoi anche eseguire l'elaborazione BDV su un magazzino Amazon Redshift Serverless che verrà automaticamente sospeso al completamento dei carichi di lavoro e riprenderà quando i carichi di lavoro riprenderanno l'elaborazione.
Livello Data Mart di presentazione
Per creare warehouse Redshift (con provisioning o serverless) per uno o più data mart, gli schemi all'interno di questi mart contengono in genere viste o viste materializzate, quindi verrà impostata una condivisione dati Redshift tra i data mart e i livelli precedenti.
Dobbiamo garantire che ci sia abbastanza concorrenza per far fronte all'aumento del traffico di lettura a questo livello. Ciò si ottiene tramite più warehouse di sola lettura con a condivisione dei dati o l'uso del ridimensionamento della concorrenza per il ridimensionamento automatico.
Architetture di esempio
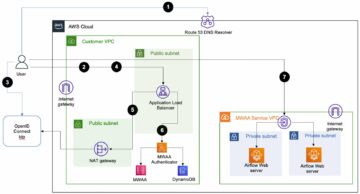
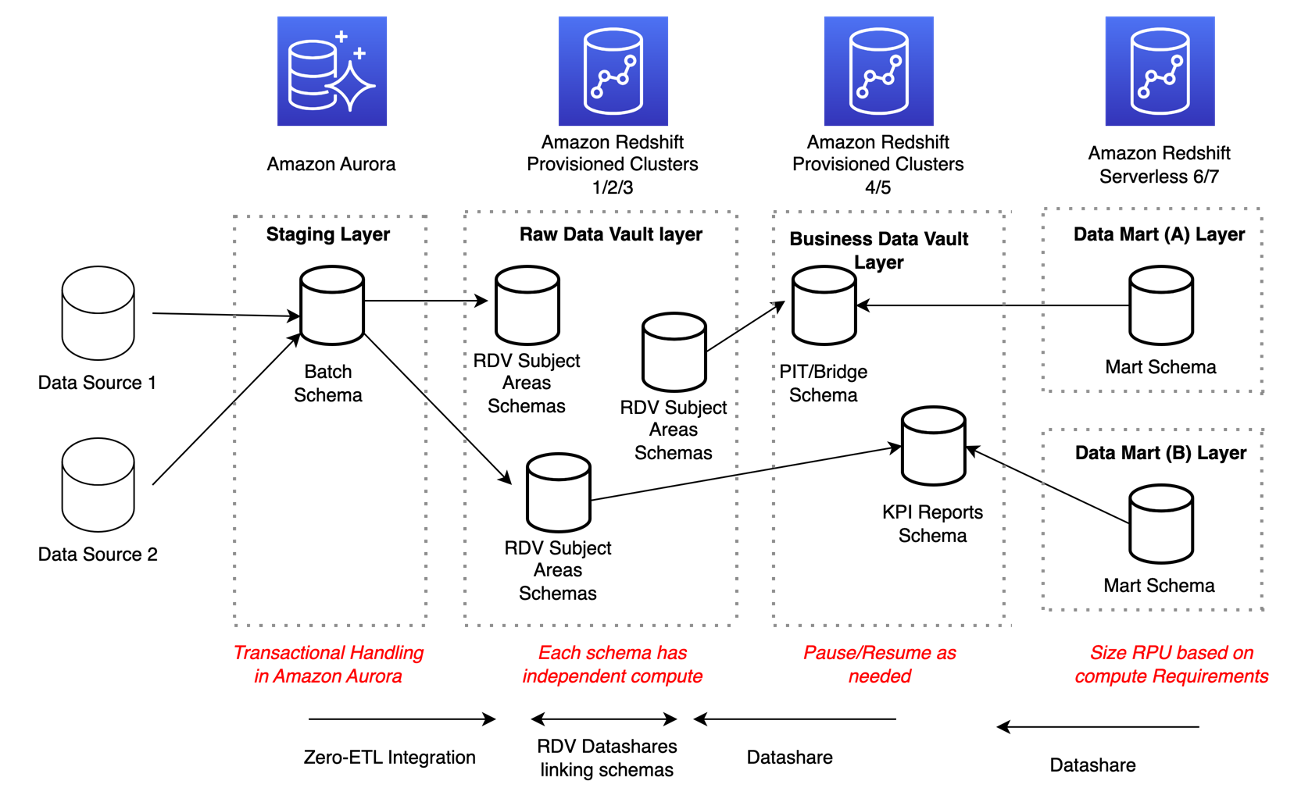
Il diagramma seguente illustra una piattaforma di esempio per un modello Data Vault modesto.
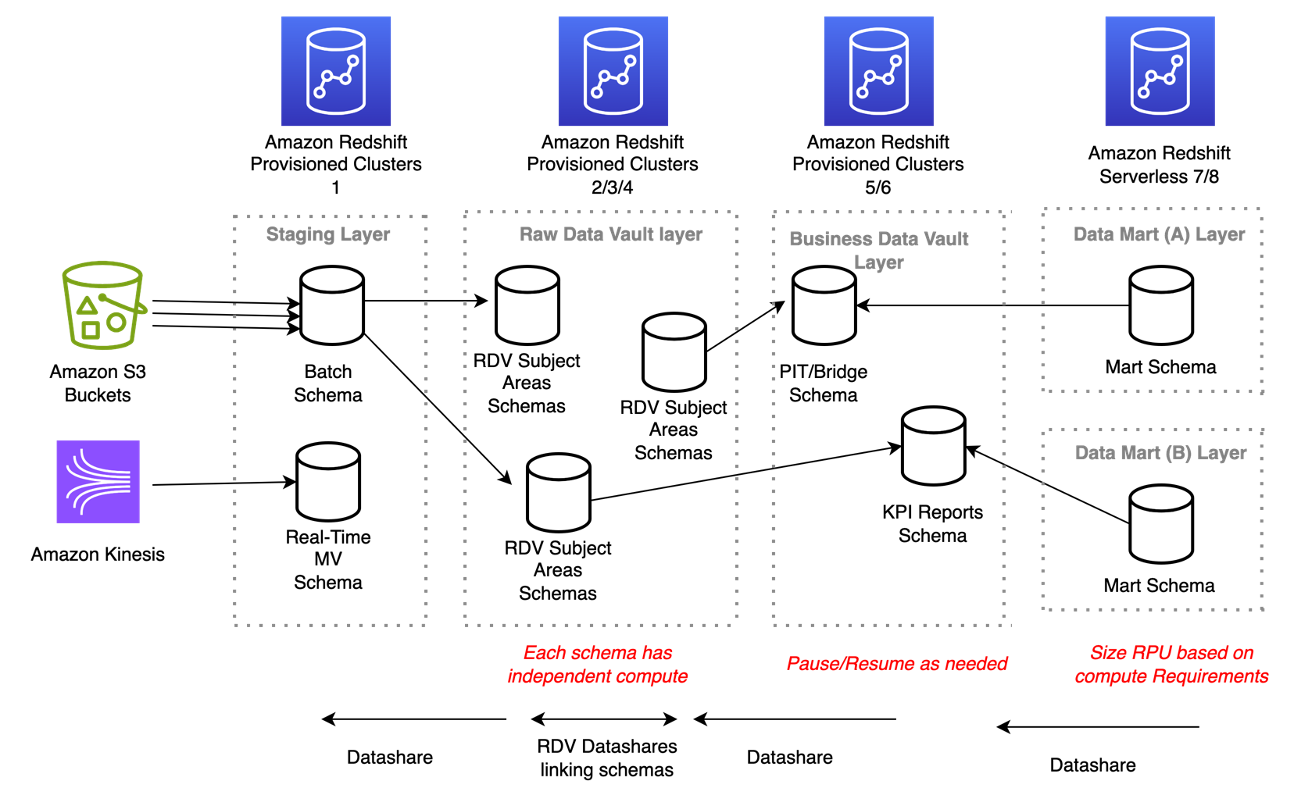
Il diagramma seguente illustra l'architettura per un modello Data Vault su larga scala.
Principi guida del modello dati di Data Vault
In questa sezione verranno discussi alcuni principi di progettazione consigliati per unire e filtrare l'accesso alle tabelle all'interno di un'implementazione di Data Vault. Questi principi guida riguardano diverse combinazioni di accesso per tipo di entità, ma dovrebbero essere testati per verificarne l'idoneità al caso d'uso particolare di ciascun cliente.
Cominciamo con un breve ripasso stili di distribuzione delle tabelle in Amazon Redshift. Esistono quattro modi in cui i dati di una tabella possono essere distribuiti tra i diversi nodi di calcolo in un cluster Redshift: ALL, KEY, EVEN e AUTO.
Lo stile di distribuzione ALL garantisce che venga mantenuta una copia completa della tabella su ciascun nodo di calcolo per eliminare la necessità di comunicazione di rete tra nodi durante l'esecuzione del carico di lavoro. Questo stile di distribuzione è ideale per le tabelle di dimensioni relativamente piccole (ad esempio, meno di 5 milioni di righe) e che non presentano modifiche frequenti.
Lo stile di distribuzione KEY utilizza un approccio basato su hash per rendere persistenti le righe di una tabella nel cluster. Una colonna chiave di distribuzione viene definita come una delle colonne nella riga e il valore di tale colonna viene sottoposto ad hashing per determinare su quale nodo di calcolo la riga verrà mantenuta. Il tipo di nodo RA3 dell'attuale generazione è basato sul sistema AWS Nitro con storage gestito che utilizza SSD ad alte prestazioni per i dati hot e Amazon S3 per i dati cold, offrendo facilità d'uso, storage conveniente e prestazioni di query veloci. L'archiviazione gestita significa che questa mappatura della riga al nodo di calcolo è più in termini di metadati e proprietà del nodo di calcolo piuttosto che di persistenza effettiva. Questo stile di distribuzione è ideale per tabelle di grandi dimensioni con modelli di join noti e frequenti nella colonna della chiave di distribuzione.
Lo stile di distribuzione EVEN utilizza un approccio round-robin per individuare la riga di una tabella. In poche parole, le righe della tabella vengono fatte scorrere attraverso i diversi nodi di calcolo e quando viene raggiunto l'ultimo nodo di calcolo nel cluster, il ciclo ricomincia con la permanenza della riga successiva nel primo nodo di calcolo nel cluster. Questo stile di distribuzione è ideale per tabelle di grandi dimensioni che presentano scansioni frequenti della tabella.
Infine, lo stile di distribuzione delle tabelle predefinito in Amazon Redshift è AUTO, che consente ad Amazon Redshift di monitorare il modo in cui viene utilizzata una tabella e modificare lo stile di distribuzione della tabella in qualsiasi momento del ciclo di vita della tabella per ottenere prestazioni migliori con i carichi di lavoro. Tuttavia, hai anche la possibilità di dichiarare esplicitamente un particolare stile di distribuzione in qualsiasi momento se hai una buona conoscenza di come la tabella verrà utilizzata dai carichi di lavoro.
Hub e satelliti hub
Hub e satelliti hub sono spesso uniti insieme, quindi è meglio collocare questi set di dati in base alla chiave primaria dell'hub, che farà anche parte della chiave composta di ciascun satellite. Come accennato in precedenza, per volumi più piccoli (in genere meno di 5-7 milioni di righe) utilizzare lo stile di distribuzione ALL e per volumi più grandi utilizzare lo stile di distribuzione KEY (con lo stile _PK colonna come colonna KEY di distribuzione).
Collegare e collegare i satelliti
I collegamenti e i satelliti di collegamento sono spesso uniti, quindi è meglio collocare questi set di dati in base alla chiave primaria del collegamento, che farà anche parte della chiave composta di ciascun satellite di collegamento. Questi in genere comportano volumi di dati più grandi, quindi guarda uno stile di distribuzione KEY (con il file _PK colonna come colonna KEY di distribuzione).
Punto nel tempo e satelliti
Puoi decidere di denormalizzare gli attributi satellite chiave aggiungendoli alle tabelle PIT (point in time) con l'obiettivo di ridurre o eliminare i join di runtime. Poiché la denormalizzazione dei dati aiuta a ridurre o eliminare la necessità di join di runtime, le tabelle PIT denormalizzate possono essere definite con uno stile di distribuzione EVEN per ottimizzare le scansioni delle tabelle.
Tuttavia, se si decide di non denormalizzare, i volumi più piccoli dovrebbero utilizzare lo stile di distribuzione ALL e i volumi più grandi dovrebbero utilizzare lo stile di distribuzione KEY (con lo stile di distribuzione _PK colonna come colonna KEY di distribuzione). Inoltre, assicurati di definire la colonna chiave aziendale come chiave di ordinamento nella tabella PIT per un filtraggio ottimizzato.
Collegare e collegare i satelliti
Analogamente alle tabelle PIT, puoi decidere di denormalizzare gli attributi satellite chiave aggiungendoli alle tabelle bridge con l'obiettivo di ridurre o eliminare i join di runtime. Sebbene la denormalizzazione dei dati aiuti a ridurre o eliminare la necessità di join in fase di esecuzione, le tabelle bridge denormalizzate sono ancora in genere più grandi nel volume di dati e comportano join frequenti, quindi lo stile di distribuzione KEY (con il _PK come colonna KEY della distribuzione) sarebbe lo stile di distribuzione consigliato. Inoltre, assicurati di definire il bridge delle colonne chiave aziendali dominanti come chiavi di ordinamento per un filtraggio ottimizzato.
KPI e reporting
I KPI e le tabelle di reporting sono progettati per soddisfare le esigenze specifiche di ciascun cliente, quindi la flessibilità della loro struttura è fondamentale in questo caso. Si tratta spesso di tabelle autonome che presentano più tipi di interazioni, quindi lo stile di distribuzione EVEN potrebbe essere lo stile di distribuzione delle tabelle migliore per distribuire uniformemente i carichi di lavoro di scansione.
Assicurati di scegliere una chiave di ordinamento basata su clausole WHERE comuni come a date[time] elemento o una chiave aziendale comune. Inoltre, è possibile creare una tabella di serie temporali per set di dati molto grandi che vengono sempre suddivisi in base a un attributo temporale per ottimizzare i carichi di lavoro che in genere interagiscono con una porzione di tempo. Tratteremo questo argomento in modo più approfondito più avanti nel post.
Principi di progettazione non funzionale
In questa sezione verranno discusse le potenziali dimensioni dei dati aggiuntive che spesso vengono create e abbinate ai dati aziendali per soddisfare requisiti non funzionali. Nel modello di dati fisici, queste dimensioni di dati aggiuntive assumono la forma di colonne tecniche aggiunte a ciascuna riga per consentire il monitoraggio dei requisiti non funzionali. Molte di queste colonne tecniche verranno popolate dal framework Data Vault. La tabella seguente elenca alcune delle colonne tecniche comuni, ma è possibile estendere l'elenco in base alle esigenze.
| Nome colonna | Si applica alla tabella | Descrizione |
| CARICO_DTS | Tutti | Una registrazione con timestamp di quando è stata inserita questa riga. Questa è una colonna di chiave primaria per obiettivi storicizzati (link, satelliti, riferimento) e una colonna di chiave non primaria per collegamenti e hub transazionali. |
| BATCH_ID | Tutti | Un ID processo univoco che identifica l'esecuzione del codice ETL che ha popolato la riga. |
| NOME DEL LAVORO | Tutti | Il nome del processo dal framework ETL. Questo potrebbe essere un sottoprocesso all'interno di un processo più ampio. |
| CD_SISTEMA_SORGENTE | Tutti | Il sistema da cui sono stati scoperti questi dati. |
| HASH_DIFF | Satellitare | Un metodo in Data Vault per eseguire modifiche CDC (Change Data Capture). |
| RECORD_ID | Satellitare Link Riferimento |
Un identificatore univoco acquisito dal framework del codice per ogni riga. |
| EFFICACE_DTS | Link | Date di validità aziendale per registrare la validità aziendale della riga. È impostato su LOAD_DTS se nessuna data lavorativa è presente o necessaria. |
| DQ_AUDIT | Satellitare Link Riferimento |
Avvisi ed errori rilevati durante la gestione temporanea per questa riga, legati a RECORD_ID. |
Ottimizzazioni e linee guida avanzate
In questa sezione vengono discusse le potenziali ottimizzazioni che possono essere implementate all'inizio o in una fase successiva nel ciclo di vita dell'implementazione di Data Vault.
Tabelle delle serie temporali
Iniziamo con un breve ripasso sulle tabelle delle serie temporali come modello. Le tabelle delle serie temporali richiedono di prendere una tabella di grandi dimensioni e di segmentarla in più tabelle identiche che contengono una parte delle righe della tabella originale con un limite temporale. Uno scenario comune consiste nel dividere una tabella vendite monolitica in versioni mensili o annuali della tabella vendite (ad esempio sales_jan,sales_feb, e così via). Ad esempio, supponiamo di voler conservare i dati per un periodo di tempo continuo utilizzando una serie di tabelle, come illustrato nel diagramma seguente.

Con ogni nuovo trimestre di calendario creiamo una nuova tabella per contenere i dati per il nuovo trimestre ed eliminiamo la tabella più vecchia della serie. Inoltre, se le righe della tabella arrivano in un ordine naturale (come la data di vendita), non è necessario alcun lavoro per ordinare i dati della tabella, con il risultato di saltare la costosa operazione VACUUM SORT sulla tabella.
Le tabelle delle serie temporali possono aiutare a ottimizzare in modo significativo i carichi di lavoro che spesso necessitano di analizzare queste tabelle di grandi dimensioni ma entro un determinato intervallo di tempo. Inoltre, segmentando i dati in tabelle che rappresentano i trimestri di calendario, siamo in grado di eliminare i dati obsoleti con un singolo comando DROP. Se avessimo provato a eseguire la stessa operazione DELETE su una struttura di tabella monolitica utilizzando il comando DELETE, ad esempio, sarebbe stata un'operazione di eliminazione più costosa che avrebbe lasciato la tabella in uno stato non ottimale richiedendo la deframmentazione e anche il salvataggio per eseguire una successiva Processo VACUUM per recuperare spazio.
Se un carico di lavoro dovesse mai dover eseguire query sull'intero intervallo di tempo, puoi utilizzare visualizzazioni standard o materializzate utilizzando un'operazione UNION ALL all'interno di Amazon Redshift per ricucire facilmente tutte le tabelle dei componenti nel set di dati unificato. Le visualizzazioni materializzate possono essere utilizzate anche per astrarre la segmentazione della tabella dagli utenti a valle.
Nel contesto di Data Vault, le tabelle delle serie temporali possono essere utili per archiviare righe all'interno di tabelle satellite, PIT e bridge che non vengono utilizzate spesso. Le tabelle delle serie temporali possono quindi essere utilizzate per distribuire le restanti righe attive (righe aggiunte di recente o a cui si fa spesso riferimento) con proprietà di tabella più aggressive.
Conclusione
In questo post, abbiamo discusso una serie di aree mature per l'ottimizzazione e l'automazione per implementare con successo un sistema Data Vault 2.0 su larga scala e le funzionalità di Amazon Redshift che puoi utilizzare per soddisfare i relativi requisiti. Esistono molte altre funzionalità e caratteristiche di Amazon Redshift che torneranno sicuramente utili e incoraggiamo vivamente i clienti attuali e potenziali a contattare noi o altri colleghi AWS per approfondire Data Vault con Amazon Redshift.
Informazioni sugli autori
 Asser Mustafa è Principal Analytics Specialist Solutions Architect presso AWS con sede a Dallas, Texas. Fornisce consulenza ai clienti a livello globale sulle architetture, sulle migrazioni e sulle visioni di Amazon Redshift e data Lake, in tutte le fasi del ciclo di vita dell'ecosistema dei dati, a partire dalla fase POC fino all'effettiva distribuzione della produzione e alla crescita post-produzione.
Asser Mustafa è Principal Analytics Specialist Solutions Architect presso AWS con sede a Dallas, Texas. Fornisce consulenza ai clienti a livello globale sulle architetture, sulle migrazioni e sulle visioni di Amazon Redshift e data Lake, in tutte le fasi del ciclo di vita dell'ecosistema dei dati, a partire dalla fase POC fino all'effettiva distribuzione della produzione e alla crescita post-produzione.
 Filippo Klose è un Global Solutions Architect presso AWS con sede a Monaco. Lavora con i clienti aziendali FSI e li aiuta a risolvere i problemi aziendali progettando piattaforme serverless. In questo tempo libero, Philipp trascorre del tempo con la sua famiglia e si dedica a tutti gli hobby geek possibili.
Filippo Klose è un Global Solutions Architect presso AWS con sede a Monaco. Lavora con i clienti aziendali FSI e li aiuta a risolvere i problemi aziendali progettando piattaforme serverless. In questo tempo libero, Philipp trascorre del tempo con la sua famiglia e si dedica a tutti gli hobby geek possibili.
 Saman Irfan è Specialist Solutions Architect presso Amazon Web Services. Si concentra sull'aiutare i clienti di vari settori a creare soluzioni di analisi scalabili e ad alte prestazioni. Al di fuori del lavoro, le piace passare il tempo con la sua famiglia, guardare serie TV e apprendere nuove tecnologie.
Saman Irfan è Specialist Solutions Architect presso Amazon Web Services. Si concentra sull'aiutare i clienti di vari settori a creare soluzioni di analisi scalabili e ad alte prestazioni. Al di fuori del lavoro, le piace passare il tempo con la sua famiglia, guardare serie TV e apprendere nuove tecnologie.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/power-enterprise-grade-data-vaults-with-amazon-redshift-part-1/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 100
- 11
- 7
- a
- capace
- WRI
- ABSTRACT
- accesso
- Raggiungere
- raggiunto
- operanti in
- presenti
- adattabilità
- aggiunto
- l'aggiunta di
- aggiunta
- aggiuntivo
- indirizzo
- indirizzata
- aderenza
- Vantaggio
- ancora
- contro
- anni
- aggressivo
- Tutti
- consente
- lungo
- anche
- Sebbene il
- sempre
- Amazon
- Amazon Web Services
- tra
- an
- analitica
- ed
- annuale
- in qualsiasi
- nulla
- applicazioni
- approccio
- architettura
- SONO
- RISERVATA
- aree
- AS
- assumere
- At
- gli attributi
- Aurora
- auto
- automaticamente
- Automazione
- AWS
- precedente
- Banca
- basato
- BE
- perché
- diventare
- diventando
- stato
- prima
- iniziare
- essendo
- benefico
- beneficio
- MIGLIORE
- best practice
- Meglio
- fra
- Big
- entrambi
- BRIDGE
- brevemente
- costruire
- Costruzione
- costruito
- affari
- ma
- by
- calcolo
- Calendario
- Materiale
- funzionalità
- Ultra-Grande
- catturare
- catturato
- che
- Custodie
- casi
- CDC
- certo
- il cambiamento
- Modifiche
- scegliere
- Scegli
- chiaramente
- clienti
- più vicino
- Cloud
- Cluster
- codice
- freddo
- colleghi
- Colonna
- colonne
- combinazioni
- Venire
- viene
- Uncommon
- Comunicazione
- confrontare
- competere
- completamento di una
- complesso
- complessità
- ottemperare
- componente
- Compound
- Calcolare
- concetti
- configurazioni
- Prendere in considerazione
- Considerazioni
- consumo
- contenere
- contesto
- contesti
- convenzioni
- Nucleo
- Costo
- costo effettivo
- Costi
- potuto
- creare
- creato
- Creazione
- creazione
- Corrente
- cliente
- Clienti
- ciclo
- Dallas
- cruscotti
- dati
- Lago di dati
- condivisione dei dati
- memorizzazione dei dati
- data warehouse
- data warehouse
- Banca Dati
- dataset
- Data
- Date
- giorno
- decide
- decisioni
- più profondo
- Predefinito
- definire
- definito
- definisce
- Laurea
- scavare
- Dipendente
- schierato
- deployment
- Design
- Principi di progettazione
- progettato
- progettazione
- desiderio
- dettaglio
- dettagliati
- Determinare
- Costruttori
- sviluppatori
- in via di sviluppo
- diverso
- dimensioni
- direttamente
- scoperto
- discutere
- discusso
- discute
- discussione
- distribuire
- distribuito
- distribuzione
- dividere
- do
- effettua
- non
- dominante
- Dont
- Cadere
- dovuto
- durante
- ogni
- In precedenza
- alleviare
- facilità d'uso
- facilmente
- ecosistema
- Efficace
- efficiente
- o
- elemento
- eliminato
- eliminando
- il potere
- Potenzia
- enable
- Abilita
- incoraggiare
- miglioramenti
- abbastanza
- garantire
- assicura
- Impresa
- di livello enterprise
- Intero
- entità
- errori
- particolarmente
- stabilire
- Etere (ETH)
- Anche
- ugualmente
- EVER
- Ogni
- esempio
- Tranne
- mostra
- previsto
- costoso
- espressamente
- estendere
- estratto
- famiglia
- FAST
- Caratteristiche
- pochi
- meno
- filtraggio
- filtri
- Infine
- sottile
- Nome
- in forma
- Flessibilità
- flessibile
- flusso
- si concentra
- seguire
- i seguenti
- segue
- Nel
- modulo
- essere trovato
- quattro
- Contesto
- quadri
- Gratis
- frequente
- da
- pieno
- completamente
- ulteriormente
- Inoltre
- GDPR
- Geek
- ELETTRICA
- ottenere
- globali
- Globalmente
- scopo
- buono
- maggiore
- Crescita
- linee guida
- ha avuto
- maniglia
- a portata di mano
- Hard
- hash
- hash
- Avere
- he
- Aiuto
- utile
- aiutare
- aiuta
- suo
- qui
- Alta
- vivamente
- il suo
- tenere
- detiene
- HOT
- Casa
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- Hub
- mozzi
- ID
- ideale
- identico
- identificatore
- identifica
- identificazione
- if
- illustra
- realizzare
- implementazione
- implementazioni
- Implementazione
- importante
- in
- includere
- Compreso
- Aumento
- è aumentato
- incredibilmente
- studente indipendente
- indipendentemente
- industrie
- esempio
- Integra
- integrazioni
- interagire
- interazioni
- interessante
- ai miglioramenti
- coinvolgere
- coinvolto
- isolato
- da solo
- IT
- SUO
- join
- congiunto
- accoppiamento
- Entra a far parte
- ad appena
- Le
- Tasti
- conoscenze
- conosciuto
- lago
- laghi
- grandi
- larga scala
- superiore, se assunto singolarmente.
- Cognome
- dopo
- strato
- galline ovaiole
- apprendimento
- partenza
- a sinistra
- Livello
- ciclo di vita
- leggera
- piace
- LIMITE
- Limitato
- lignaggio
- LINK
- Collegamento
- Lista
- elenchi
- caricare
- Caricamento in corso
- posizionamento
- Guarda
- macchina
- machine learning
- mantenere
- maggiore
- gestito
- gestione
- molti
- mappatura
- Maggio..
- si intende
- Soddisfare
- menzionato
- maglia
- Metadati
- metodo
- Metodologia
- milione
- ML
- modello
- modellismo
- modelli
- moderno
- modesto
- Monitorare
- Monolitico
- mensile
- Scopri di più
- maggior parte
- Più popolare
- cambiano
- molti
- multiplo
- Monaco
- Nome
- naturalmente
- Natura
- Bisogno
- di applicazione
- esigenze
- Rete
- New
- Nuove tecnologie
- GENERAZIONE
- Nitro
- no
- nodo
- nodi
- numero
- verificarsi
- si è verificato
- of
- offerta
- Offerte
- di frequente
- il più vecchio
- on
- Procedura di Onboarding
- una volta
- ONE
- esclusivamente
- operazione
- Supponente
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- or
- minimo
- Organizzato
- organizza
- i
- originario
- Altro
- su
- al di fuori
- panoramica
- proprio
- proprietà
- paradigma
- parte
- particolare
- Cartamodello
- modelli
- pausa
- eseguire
- performance
- esecuzione
- periodo
- permanente
- persistenza
- Fisico
- conduttura
- PIT
- posto
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- PoC
- punto
- Popolare
- popolata
- possibile
- Post
- potenziale
- energia
- pratiche
- presenti
- presentazione
- premendo
- precedente
- prezzi
- primario
- Direttore
- principi
- problemi
- processi
- lavorazione
- Produzione
- progetti
- proprietà
- potenziale
- fornire
- fornisce
- fornitura
- metti
- Trimestre
- gamma
- piuttosto
- Crudo
- dati grezzi
- raggiungere
- a raggiunto
- Leggi
- tempo reale
- ragione
- recentemente
- riconosce
- raccomandato
- record
- registrazione
- record
- ridurre
- riducendo
- riferimento
- riferimento
- di cui
- normativa
- relazionato
- rapporto
- relativamente
- pertinente
- rimanente
- riorganizzazione
- Reportistica
- rappresentare
- che rappresenta
- rappresenta
- Requisiti
- richiede
- riservato
- Risorse
- responsabile
- riposo
- risultante
- curriculum vitae
- conservare
- recensioni
- destra
- rotolamento
- RIGA
- norme
- Correre
- corre
- runtime
- vendite
- stesso
- satellitare
- satelliti
- Scalabilità
- scalabile
- Scala
- scala
- scansione
- scansioni
- scenario
- senza soluzione di continuità
- Sezione
- problemi di
- vedere
- segmentazione
- separazione
- Serie
- serverless
- servizio
- Servizi
- set
- Condividi
- compartecipazione
- lei
- dovrebbero
- significativamente
- simile
- Un'espansione
- semplicemente
- singolo
- Taglia
- Taglia
- piccole
- inferiore
- So
- Soluzioni
- RISOLVERE
- alcuni
- qualcosa
- Fonte
- fonti
- lo spazio
- specialista
- specifico
- Spendere
- diffondere
- primavera
- Stage
- tappe
- messa in scena
- standalone
- Standard
- Stella
- inizia a
- Regione / Stato
- Ancora
- conservazione
- lineare
- flussi
- fortemente
- La struttura
- strutture
- style
- soggetto
- successivo
- Con successo
- tale
- convenienza
- adatto
- Supporto
- supporti
- sicuro
- certamente
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- presa
- obiettivi
- Consulenza
- Tecnologie
- dice
- condizioni
- testato
- Texas
- di
- che
- Il
- l'hub
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- quelli
- tre
- Attraverso
- Legato
- tempo
- Serie storiche
- timestamp
- a
- insieme
- strumenti
- Tracking
- traffico
- delle transazioni
- transazionale
- Le transazioni
- Trasformare
- trasformazioni
- provato
- tv
- Serie TV
- seconda
- Digitare
- Tipi di
- tipicamente
- e una comprensione reciproca
- unificato
- unione
- unico
- us
- uso
- caso d'uso
- utilizzato
- utile
- utenti
- usa
- utilizzando
- Vuoto
- validità
- APPREZZIAMO
- vario
- variando
- Volta
- volte
- versione
- versioni
- verticalmente
- molto
- via
- vice
- visualizzazioni
- volume
- volumi
- vs
- volere
- Magazzino
- Prima
- guardare
- Modo..
- modi
- we
- sito web
- servizi web
- WELL
- noto
- Che
- quando
- quale
- while
- tutto
- perché
- volere
- finestra
- con
- entro
- senza
- Lavora
- flussi di lavoro
- Gruppo di lavoro
- lavori
- sarebbe
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro