Questa serie in tre parti dimostra come utilizzare le reti neurali a grafo (GNN) e Amazon Nettuno per generare consigli sui film utilizzando il file IMDb e Box Office Mojo Film/TV/OTT pacchetto di dati con licenza, che fornisce un'ampia gamma di metadati di intrattenimento, tra cui oltre 1 miliardo di valutazioni degli utenti; crediti per oltre 11 milioni di membri del cast e della troupe; 9 milioni di titoli cinematografici, televisivi e di intrattenimento; e dati di reporting al botteghino globale di oltre 60 paesi. Molti clienti AWS nel settore dei media e dell'intrattenimento concedono in licenza i dati di IMDb Scambio di dati AWS per migliorare la scoperta dei contenuti e aumentare il coinvolgimento e la fidelizzazione dei clienti.
In Parte 1, abbiamo discusso delle applicazioni dei GNN e di come trasformare e preparare i nostri dati IMDb per l'interrogazione. In questo post, discutiamo il processo di utilizzo di Nettuno per generare incorporamenti utilizzati per condurre la nostra ricerca fuori catalogo nella Parte 3. Andiamo anche oltre Amazon Nettuno ML, la funzionalità di machine learning (ML) di Neptune e il codice che utilizziamo nel nostro processo di sviluppo. Nella parte 3 , esaminiamo come applicare i nostri incorporamenti di grafi di conoscenza a un caso d'uso di ricerca fuori catalogo.
Panoramica della soluzione
I grandi set di dati connessi spesso contengono informazioni preziose che possono essere difficili da estrarre utilizzando query basate solo sull'intuizione umana. Le tecniche ML possono aiutare a trovare correlazioni nascoste nei grafici con miliardi di relazioni. Queste correlazioni possono essere utili per consigliare prodotti, prevedere l'affidabilità creditizia, identificare frodi e molti altri casi d'uso.
Neptune ML consente di creare e addestrare utili modelli ML su grafici di grandi dimensioni in ore anziché in settimane. Per fare ciò, Neptune ML utilizza la tecnologia GNN alimentata da Amazon Sage Maker e la Libreria Deep Graph (DGL) (che è open-source). I GNN sono un campo emergente nell'intelligenza artificiale (per un esempio, vedi Un'indagine completa sulle reti neurali a grafo). Per un tutorial pratico sull'utilizzo dei GNN con il DGL, vedere Apprendimento delle reti neurali a grafo con Deep Graph Library.
In questo post, mostriamo come utilizzare Neptune nella nostra pipeline per generare incorporamenti.
Il diagramma seguente illustra il flusso complessivo dei dati di IMDb dal download alla generazione dell'incorporamento.
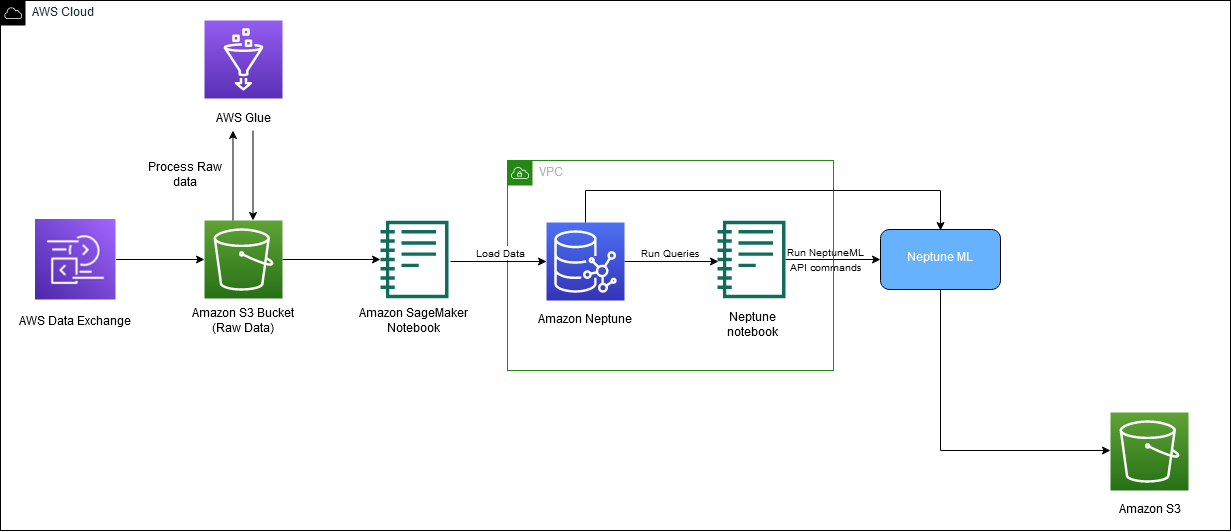
Utilizziamo i seguenti servizi AWS per implementare la soluzione:
In questo post, ti guidiamo attraverso i seguenti passaggi di alto livello:
- Imposta le variabili di ambiente
- Crea un lavoro di esportazione.
- Creare un processo di elaborazione dati.
- Invia un lavoro di formazione.
- Scarica incorporamenti.
Codice per i comandi Neptune ML
Utilizziamo i seguenti comandi come parte dell'implementazione di questa soluzione:
Usiamo neptune_ml export per verificare lo stato o avviare un processo di esportazione Neptune ML e neptune_ml training per avviare e controllare lo stato di un processo di addestramento del modello Neptune ML.
Per ulteriori informazioni su questi e altri comandi, fare riferimento a Usando le magie del banco di lavoro di Nettuno nei tuoi taccuini.
Prerequisiti
Per seguire questo post, dovresti avere quanto segue:
- An Account AWS
- Familiarità con SageMaker, Amazon S3 e AWS CloudFormation
- Dati grafici caricati nell'ammasso Neptune (vedi Parte 1 per maggiori informazioni)
Imposta le variabili di ambiente
Prima di iniziare, dovrai configurare il tuo ambiente impostando le seguenti variabili: s3_bucket_uri ed processed_folder. s3_bucket_uri è il nome del secchio utilizzato nella Parte 1 e processed_folder è la posizione Amazon S3 per l'output del processo di esportazione.
Crea un lavoro di esportazione
Nella Parte 1, abbiamo creato un notebook SageMaker e un servizio di esportazione per esportare i nostri dati dal cluster Neptune DB ad Amazon S3 nel formato richiesto.
Ora che i nostri dati sono caricati e il servizio di esportazione è stato creato, dobbiamo creare un lavoro di esportazione avviarlo. Per fare questo, usiamo NeptuneExportApiUri e creare i parametri per il lavoro di esportazione. Nel codice seguente, utilizziamo le variabili expo ed export_params. Impostato expo alla tua NeptuneExportApiUri valore, che puoi trovare sul Uscite scheda del tuo stack CloudFormation. Per export_params, utilizziamo l'endpoint del cluster Neptune e forniamo il valore per outputS3path, che è la posizione Amazon S3 per l'output del processo di esportazione.
Per inviare il lavoro di esportazione utilizzare il seguente comando:
Per verificare lo stato del lavoro di esportazione utilizzare il seguente comando:
Al termine del lavoro, impostare il file processed_folder variabile per fornire la posizione Amazon S3 dei risultati elaborati:
Creare un processo di elaborazione dati
Ora che l'esportazione è terminata, creiamo un processo di elaborazione dati per preparare i dati per il processo di addestramento di Neptune ML. Questo può essere fatto in diversi modi. Per questo passaggio, puoi modificare il file job_name ed modelType variabili, ma tutti gli altri parametri devono rimanere gli stessi. La parte principale di questo codice è il file modelType parametro, che può essere un modello grafico eterogeneo (heterogeneous) o grafici della conoscenza (kge).
Il lavoro di esportazione include anche training-data-configuration.json. Utilizza questo file per aggiungere o rimuovere eventuali nodi o bordi che non desideri fornire per l'addestramento (ad esempio, se desideri prevedere il collegamento tra due nodi, puoi rimuovere tale collegamento in questo file di configurazione). Per questo post sul blog utilizziamo il file di configurazione originale. Per ulteriori informazioni, cfr Modifica di un file di configurazione dell'addestramento.
Crea il tuo lavoro di elaborazione dati con il seguente codice:
Per verificare lo stato del lavoro di esportazione utilizzare il seguente comando:
Invia un lavoro di formazione
Dopo che il lavoro di elaborazione è stato completato, possiamo iniziare il nostro lavoro di formazione, che è dove creiamo i nostri incorporamenti. Consigliamo un tipo di istanza ml.m5.24xlarge, ma puoi modificarlo in base alle tue esigenze di elaborazione. Vedere il seguente codice:
Stampiamo la variabile training_results per ottenere l'ID per il lavoro di formazione. Usa il seguente comando per controllare lo stato del tuo lavoro:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Scarica incorporamenti
Dopo aver completato il lavoro di formazione, l'ultimo passaggio consiste nel scaricare i tuoi incorporamenti non elaborati. I passaggi seguenti mostrano come scaricare gli incorporamenti creati utilizzando KGE (è possibile utilizzare lo stesso processo per RGCN).
Nel codice seguente, usiamo neptune_ml.get_mapping() ed get_embeddings() per scaricare il file di mappatura (mapping.info) e il file di incorporamento non elaborato (entity.npy). Quindi dobbiamo mappare gli incorporamenti appropriati ai loro ID corrispondenti.
Per scaricare gli RGCN, seguire la stessa procedura con un nuovo nome del processo di addestramento elaborando i dati con il parametro modelType impostato su heterogeneous, quindi addestrare il modello con il parametro modelName impostato su rgcn vedere qui per ulteriori dettagli. Una volta terminato, chiama il get_mapping ed get_embeddings funzioni per scaricare il tuo nuovo mappatura.info ed entità.npy File. Dopo aver ottenuto l'entità e i file di mappatura, il processo per creare il file CSV è identico.
Infine, carica i tuoi incorporamenti nella posizione Amazon S3 desiderata:
Assicurati di ricordare questa posizione S3, dovrai usarla nella Parte 3.
ripulire
Quando hai finito di utilizzare la soluzione, assicurati di ripulire tutte le risorse per evitare addebiti continui.
Conclusione
In questo post, abbiamo discusso su come utilizzare Neptune ML per addestrare gli incorporamenti GNN dai dati di IMDb.
Alcune applicazioni correlate dell'incorporamento dei grafici della conoscenza sono concetti come la ricerca fuori catalogo, i consigli sui contenuti, la pubblicità mirata, la previsione dei collegamenti mancanti, la ricerca generale e l'analisi di coorte. La ricerca fuori dal catalogo è il processo di ricerca di contenuto che non si possiede e di ricerca o suggerimento di contenuto presente nel catalogo che sia il più vicino possibile a ciò che l'utente ha cercato. Approfondiremo la ricerca fuori catalogo nella Parte 3.
Informazioni sugli autori
 Matteo Rodi è un Data Scientist che lavora nell'Amazon ML Solutions Lab. È specializzato nella creazione di pipeline di Machine Learning che coinvolgono concetti come l'elaborazione del linguaggio naturale e la visione artificiale.
Matteo Rodi è un Data Scientist che lavora nell'Amazon ML Solutions Lab. È specializzato nella creazione di pipeline di Machine Learning che coinvolgono concetti come l'elaborazione del linguaggio naturale e la visione artificiale.
 Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso l'Amazon ML Solutions Lab, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso l'Amazon ML Solutions Lab, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
 Gaurav Relé è un Data Scientist presso Amazon ML Solution Lab, dove lavora con i clienti AWS in diversi settori verticali per accelerare il loro utilizzo del machine learning e dei servizi cloud AWS per risolvere le loro sfide aziendali.
Gaurav Relé è un Data Scientist presso Amazon ML Solution Lab, dove lavora con i clienti AWS in diversi settori verticali per accelerare il loro utilizzo del machine learning e dei servizi cloud AWS per risolvere le loro sfide aziendali.
 Karan Sindwani è un Data Scientist presso Amazon ML Solutions Lab, dove crea e distribuisce modelli di deep learning. È specializzato nel campo della visione artificiale. Nel tempo libero ama fare escursioni.
Karan Sindwani è un Data Scientist presso Amazon ML Solutions Lab, dove crea e distribuisce modelli di deep learning. È specializzato nel campo della visione artificiale. Nel tempo libero ama fare escursioni.
 Soji Adishina è uno scienziato applicato presso AWS, dove sviluppa modelli basati su reti neurali a grafo per l'apprendimento automatico su attività grafiche con applicazioni a frodi e abusi, grafi della conoscenza, sistemi di raccomandazione e scienze della vita. Nel tempo libero ama leggere e cucinare.
Soji Adishina è uno scienziato applicato presso AWS, dove sviluppa modelli basati su reti neurali a grafo per l'apprendimento automatico su attività grafiche con applicazioni a frodi e abusi, grafi della conoscenza, sistemi di raccomandazione e scienze della vita. Nel tempo libero ama leggere e cucinare.
 Vidya Sagar Ravipati è un manager presso l'Amazon ML Solutions Lab, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'IA e del cloud.
Vidya Sagar Ravipati è un manager presso l'Amazon ML Solutions Lab, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'IA e del cloud.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Chi siamo
- abuso
- accelerare
- operanti in
- aggiuntivo
- Informazioni aggiuntive
- Adozione
- Pubblicità
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- Tutti
- da solo
- Amazon
- Laboratorio di soluzioni Amazon ML
- .
- ed
- applicazioni
- applicato
- APPLICA
- opportuno
- RISERVATA
- artificiale
- intelligenza artificiale
- AWS
- basato
- fra
- Miliardo
- miliardi
- Blog
- Scatola
- botteghino
- costruire
- Costruzione
- costruisce
- affari
- chiamata
- Custodie
- casi
- catalogo
- sfide
- il cambiamento
- oneri
- dai un'occhiata
- Chiudi
- Cloud
- adozione del cloud
- servizi cloud
- Cluster
- codice
- Coorte
- completamento di una
- globale
- computer
- Visione computerizzata
- informatica
- concetti
- Segui il codice di Condotta
- Configurazione
- collegato
- contenuto
- Corrispondente
- paesi
- creare
- creato
- credito
- Crediti
- cliente
- Il coinvolgimento del cliente
- Clienti
- dati
- elaborazione dati
- scienziato di dati
- dataset
- deep
- apprendimento profondo
- più profondo
- Distribuisce
- dettagli
- Mercato
- sviluppa
- Piace
- diverso
- scoperta
- discutere
- discusso
- distribuito
- sistemi distribuiti
- Dont
- scaricare
- o
- emergenti del mondo
- endpoint
- Fidanzamento
- Intrattenimento
- entità
- Ambiente
- Etere (ETH)
- esempio
- esperienza
- export
- estratto
- caratteristica
- pochi
- campo
- Compila il
- File
- Trovare
- ricerca
- flusso
- seguire
- i seguenti
- formato
- frode
- da
- pieno
- funzioni
- Generale
- generare
- ELETTRICA
- ottenere
- globali
- Go
- grafico
- grafici
- mani su
- Hard
- Aiuto
- utile
- nascosto
- alto livello
- ORE
- Come
- Tutorial
- HTML
- HTTPS
- umano
- identico
- identificazione
- realizzare
- Implementazione
- competenze
- in
- inclusi
- Compreso
- Aumento
- Index
- industria
- info
- informazioni
- esempio
- invece
- Intelligence
- coinvolgere
- IT
- Lavoro
- json
- Le
- conoscenze
- laboratorio
- Lingua
- grandi
- larga scala
- Cognome
- portare
- apprendimento
- leveraggi
- Biblioteca
- Licenza
- Vita
- Life Sciences
- LINK
- Collegamento
- località
- macchina
- machine learning
- Principale
- FA
- direttore
- molti
- carta geografica
- mappatura
- Media
- medie
- Utenti
- Metadati
- milione
- mancante
- ML
- modello
- modelli
- Scopri di più
- film
- Nome
- Naturale
- Elaborazione del linguaggio naturale
- Bisogno
- esigenze
- Nettuno
- basato sulla rete
- reti
- reti neurali
- New
- nodi
- taccuino
- Office
- in corso
- i
- Altro
- complessivo
- proprio
- pacchetto
- parametro
- parametri
- parte
- passione
- conduttura
- Platone
- Platone Data Intelligence
- PlatoneDati
- possibile
- Post
- energia
- alimentato
- predire
- previsione
- Preparare
- Stampa
- problemi
- processi
- lavorazione
- Prodotti
- Profilo
- fornire
- fornisce
- gamma
- valutazioni
- Crudo
- Lettura
- raccomandare
- Consigli
- raccomandazioni
- raccomandando
- relazionato
- Relazioni
- rimanere
- ricorda
- rimuovere
- Reportistica
- necessario
- Risorse
- Risultati
- ritenzione
- sagemaker
- stesso
- SCIENZE
- Scienziato
- Cerca
- ricerca
- Serie
- servizio
- Servizi
- set
- regolazione
- dovrebbero
- mostrare attraverso le sue creazioni
- soluzione
- Soluzioni
- RISOLVERE
- risolve
- specializzata
- pila
- inizia a
- Stato dei servizi
- step
- Passi
- Tornare al suo account
- inviare
- tale
- Completo
- Indagine
- SISTEMI DI TRATTAMENTO
- mirata
- task
- tecniche
- Tecnologia
- I
- L'area
- loro
- Attraverso
- tempo
- titoli
- a
- Treni
- Training
- Trasformare
- vero
- lezione
- tv
- e una comprensione reciproca
- uso
- caso d'uso
- Utente
- Prezioso
- APPREZZIAMO
- Fisso
- versione
- verticali
- visione
- modi
- Settimane
- Che
- quale
- largo
- Vasta gamma
- volere
- lavoro
- lavori
- Trasferimento da aeroporto a Sharm
- zefiro