Questa serie in tre parti dimostra come utilizzare le reti neurali a grafo (GNN) e Amazon Nettuno per generare consigli sui film utilizzando il file IMDb e Box Office Mojo Film/TV/OTT pacchetto di dati con licenza, che fornisce un'ampia gamma di metadati di intrattenimento, tra cui oltre 1 miliardo di valutazioni degli utenti; crediti per oltre 11 milioni di membri del cast e della troupe; 9 milioni di titoli cinematografici, televisivi e di intrattenimento; e dati di reporting al botteghino globale di oltre 60 paesi. Molti clienti AWS nel settore dei media e dell'intrattenimento concedono in licenza i dati di IMDb Scambio di dati AWS per migliorare la scoperta dei contenuti e aumentare il coinvolgimento e la fidelizzazione dei clienti.
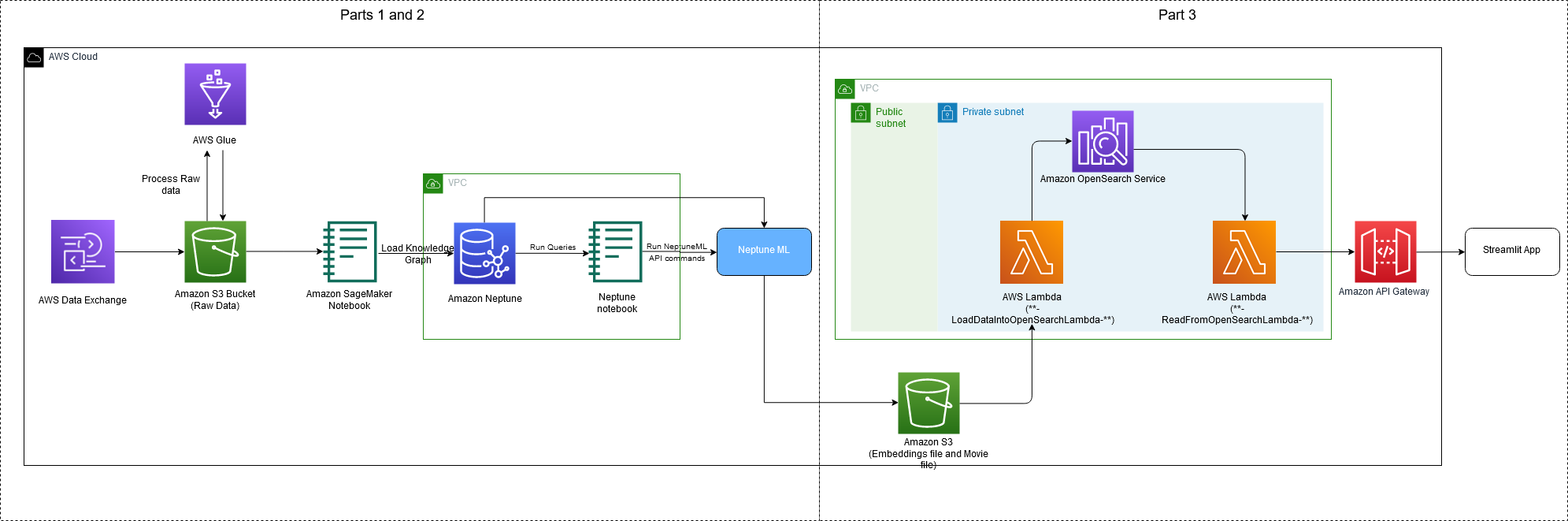
Il diagramma seguente illustra l'architettura completa implementata come parte di questa serie.
In Parte 1, abbiamo discusso delle applicazioni dei GNN e di come trasformare e preparare i nostri dati IMDb in un knowledge graph (KG). Abbiamo scaricato i dati da AWS Data Exchange e li abbiamo elaborati Colla AWS per generare file KG. I file KG sono stati archiviati in Servizio di archiviazione semplice Amazon (Amazon S3) e poi caricato Amazon Nettuno.
In Parte 2, abbiamo dimostrato come utilizzare Amazon Nettuno ML (in Amazon Sage Maker) per addestrare il KG e creare incorporamenti di KG.
In questo post, ti spieghiamo come applicare i nostri incorporamenti di KG addestrati in Amazon S3 a casi d'uso di ricerche fuori catalogo utilizzando Servizio Amazon OpenSearch ed AWS Lambda. Distribuisci anche un'app Web locale per un'esperienza di ricerca interattiva. Tutte le risorse utilizzate in questo post possono essere create utilizzando un singolo file Kit di sviluppo cloud AWS (AWS CDK) come descritto più avanti nel post.
sfondo
Hai mai cercato inavvertitamente un titolo di contenuto che non era disponibile in una piattaforma di streaming video? Se sì, scoprirai che invece di affrontare una pagina dei risultati di ricerca vuota, troverai un elenco di film dello stesso genere, con membri del cast o della troupe. Questa è un'esperienza di ricerca fuori catalogo!
Ricerca fuori catalogo (OOC) è quando si immette una query di ricerca che non ha corrispondenza diretta in un catalogo. Questo evento si verifica frequentemente nelle piattaforme di streaming video che acquistano costantemente una varietà di contenuti da più fornitori e società di produzione per un periodo di tempo limitato. L'assenza di pertinenza o mappatura dal catalogo di una società di streaming a grandi basi di conoscenza di film e spettacoli può comportare un'esperienza di ricerca scadente per i clienti che interrogano i contenuti OOC, riducendo così il tempo di interazione con la piattaforma. Questa mappatura può essere eseguita mappando manualmente le frequenti query OOC al contenuto del catalogo o può essere automatizzata utilizzando l'apprendimento automatico (ML).
In questo post, illustriamo come gestire OOC utilizzando la potenza del set di dati IMDb (la principale fonte di metadati di intrattenimento globale) e dei grafici della conoscenza.
Servizio OpenSearch è un servizio completamente gestito che semplifica l'esecuzione di analisi dei log interattive, il monitoraggio delle applicazioni in tempo reale, la ricerca di siti Web e altro ancora. OpenSearch è una suite di analisi e ricerca distribuita open source derivata da Elasticsearch. OpenSearch Service offre le versioni più recenti di OpenSearch, il supporto per 19 versioni di Elasticsearch (versioni da 1.5 a 7.10), nonché funzionalità di visualizzazione basate su OpenSearch Dashboards e Kibana (versioni da 1.5 a 7.10). OpenSearch Service ha attualmente decine di migliaia di clienti attivi con centinaia di migliaia di cluster in gestione che elaborano trilioni di richieste al mese. OpenSearch Service offre la ricerca kNN, che può migliorare la ricerca in casi d'uso come consigli sui prodotti, rilevamento di frodi e immagini, video e alcuni scenari semantici specifici come la somiglianza di documenti e query. Per ulteriori informazioni sulle funzionalità di ricerca basate sulla comprensione del linguaggio naturale di OpenSearch Service, fare riferimento a Creazione di un'applicazione di ricerca basata su NLU con Amazon SageMaker e la funzionalità KNN di Amazon OpenSearch Service.
Panoramica della soluzione
In questo post, presentiamo una soluzione per gestire le situazioni OOC attraverso la ricerca incorporata basata su knowledge graph utilizzando le funzionalità di ricerca k-nearest neighbor (kNN) di OpenSearch Service. I principali servizi AWS utilizzati per implementare questa soluzione sono OpenSearch Service, SageMaker, Lambda e Amazon S3.
Check out Parte 1 ed Parte 2 di questa serie per saperne di più sulla creazione di grafici della conoscenza e sull'incorporamento di GNN utilizzando Amazon Neptune ML.
La nostra soluzione OOC presuppone che tu abbia un KG combinato ottenuto unendo una società di streaming KG e IMDb KG. Questo può essere fatto attraverso semplici tecniche di elaborazione del testo che abbinano i titoli al tipo di titolo (film, serie, documentario), cast e troupe. Inoltre, questo grafo di conoscenza congiunto deve essere addestrato per generare incorporamenti di grafi di conoscenza attraverso le pipeline menzionate in Parte 1 ed Parte 2. Il diagramma seguente illustra una vista semplificata del KG combinato.

Per dimostrare la funzionalità di ricerca OOC con un semplice esempio, abbiamo suddiviso il grafico della conoscenza di IMDb in catalogo cliente e fuori catalogo cliente. Contrassegniamo i titoli che contengono "Toy Story" come risorsa del catalogo fuori dal cliente e il resto del grafico della conoscenza di IMDb come catalogo del cliente. In uno scenario in cui il catalogo del cliente non viene migliorato o unito a database esterni, una ricerca per "toy story" restituirebbe qualsiasi titolo che contenga le parole "toy" o "story" nei suoi metadati, con la ricerca di testo OpenSearch. Se il catalogo del cliente fosse mappato su IMDb, sarebbe più facile capire che la query "toy story" non esiste nel catalogo e che le corrispondenze principali in IMDb sono "Toy Story", "Toy Story 2", "Toy Story" Story 3", "Toy Story 4" e "Charlie: Toy Story" in ordine decrescente di pertinenza con corrispondenza di testo. Per ottenere risultati all'interno del catalogo per ciascuna di queste corrispondenze, possiamo generare cinque filmati più vicini nella somiglianza dell'incorporamento kNN basato sul catalogo del cliente (del KG congiunto) tramite il servizio OpenSearch.
Una tipica esperienza OOC segue il flusso illustrato nella figura seguente.

Il seguente video mostra i primi cinque risultati OOC (numero di hit) per la query "toy story" e le corrispondenze pertinenti nel catalogo clienti (numero di raccomandazioni).
Qui, la query viene abbinata al grafico della conoscenza utilizzando la ricerca di testo in OpenSearch Service. Quindi mappiamo gli incorporamenti della corrispondenza di testo ai titoli del catalogo del cliente utilizzando l'indice kNN del servizio OpenSearch. Poiché la query dell'utente non può essere mappata direttamente alle entità del grafico della conoscenza, usiamo un approccio in due passaggi per trovare prima le somiglianze di query basate sul titolo e quindi gli elementi simili al titolo utilizzando gli incorporamenti del grafico della conoscenza. Nelle sezioni seguenti, esaminiamo il processo di configurazione di un cluster OpenSearch Service, creazione e caricamento degli indici del grafico della conoscenza e distribuzione della soluzione come applicazione web.
Prerequisiti
Per implementare questa soluzione, dovresti avere un file Account AWS, familiarità con OpenSearch Service, SageMaker, Lambda e AWS CloudFormazionee hai completato i passaggi in Parte 1 ed Parte 2 di questa serie.
Avvia le risorse della soluzione
Il seguente diagramma dell'architettura mostra il flusso di lavoro fuori catalogo.
Utilizzerai AWS Cloud Development Kit (CDK) per eseguire il provisioning delle risorse necessarie per le applicazioni di ricerca OOC. Il codice per avviare queste risorse esegue le seguenti operazioni:
- Crea un VPC per le risorse.
- Crea un dominio del servizio OpenSearch per l'applicazione di ricerca.
- Crea una funzione Lambda per elaborare e caricare i metadati e gli incorporamenti del film negli indici del servizio OpenSearch (
**-ReadFromOpenSearchLambda-**). - Crea una funzione Lambda che accetta come input la query dell'utente da un'app Web e restituisce titoli pertinenti da OpenSearch (
**-LoadDataIntoOpenSearchLambda-**). - Crea un gateway API che aggiunge un ulteriore livello di sicurezza tra l'interfaccia utente dell'app Web e Lambda.
Per iniziare, completare i seguenti passi:
- Esegui il codice e i notebook da Parte 1 ed Parte 2.
- Passare alla
part3-out-of-catalogcartella nel repository di codice.

- Avvia l'AWS CDK dal terminale con il comando
bash launch_stack.sh. - Fornisci i due percorsi file S3 creati nella Parte 2 come input:
- Il percorso S3 del file CSV di incorporamento del film.
- Il percorso S3 del file del nodo del film.

- Attendere fino a quando lo script esegue il provisioning di tutte le risorse richieste e termina l'esecuzione.
- Copia l'URL del gateway API che lo script AWS CDK stampa e salvalo. (Usiamo questo per l'app Streamlit in seguito).

Crea un dominio del servizio OpenSearch
A scopo illustrativo, crei un dominio di ricerca su una zona di disponibilità in un'istanza r6g.large.search all'interno di un VPC e una sottorete sicuri. Tieni presente che la best practice consiste nell'impostare tre zone di disponibilità con un'istanza primaria e due di replica.
Crea un indice di OpenSearch Service e carica i dati
Puoi utilizzare le funzioni Lambda (create utilizzando il comando AWS CDK launch stack) per creare gli indici del servizio OpenSearch. Per avviare la creazione dell'indice, completare i seguenti passaggi:
- Sulla console Lambda, apri il file
LoadDataIntoOpenSearchLambdaFunzione lambda.
- Sulla Test scheda, scegliere Test per creare e importare dati nell'indice di OpenSearch Service.

Il codice seguente per questa funzione Lambda è disponibile in part3-out-of-catalog/cdk/ooc/lambdas/LoadDataIntoOpenSearchLambda/lambda_handler.py:
La funzione svolge le seguenti attività:
- Carica il file del nodo del film IMDB KG che contiene i metadati del film e gli incorporamenti associati dai percorsi del file S3 che sono stati passati al file di creazione dello stack
launch_stack.sh. - Unisce i due file di input per creare un singolo dataframe per la creazione dell'indice.
- Inizializza il client del servizio OpenSearch usando la libreria Boto3 Python.
- Crea due indici per il testo (
ooc_text) e ricerca di incorporamento kNN (ooc_knn) e carica in blocco i dati dal dataframe combinato attraverso il fileingest_data_into_opsfunzione.
Questo processo di acquisizione dei dati richiede 5-10 minuti e può essere monitorato tramite il Amazon Cloud Watch accede al Controllo scheda della funzione Lambda.
Si creano due indici per abilitare la ricerca basata sul testo e la ricerca basata sull'incorporamento di kNN. La ricerca testuale associa la query in formato libero che l'utente immette ai titoli del film. La ricerca di incorporamento kNN trova i k film più vicini alla migliore corrispondenza di testo dallo spazio latente KG da restituire come output.
Distribuisci la soluzione come applicazione Web locale
Ora che disponi di una ricerca di testo funzionante e di un indice kNN su OpenSearch Service, sei pronto per creare un'app Web basata su ML.
Usiamo il streamlit Pacchetto Python per creare un'illustrazione front-end per questa applicazione. Il IMDb-Knowledge-Graph-Blog/part3-out-of-catalog/run_imdb_demo.py Python file nel nostro Repository GitHub dispone del codice necessario per avviare un'app Web locale per esplorare questa funzionalità.
Per eseguire il codice, completare i seguenti passaggi:
- installare il
streamlitedaws_requests_authPacchetto Python nel tuo ambiente Python virtuale locale tramite i seguenti comandi nel tuo terminale:
- Sostituisci il segnaposto per l'URL del gateway API nel codice come segue con quello creato da AWS CDK:
api = '<ENTER URL OF THE API GATEWAY HERE>/opensearch-lambda?q={query_text}&numMovies={num_movies}&numRecs={num_recs}'
- Avvia l'app Web con il comando
streamlit run run_imdb_demo.pydal tuo terminale
Questo script avvia un'app Web Streamlit a cui è possibile accedere nel browser Web. L'URL dell'app Web può essere recuperato dall'output dello script, come mostrato nello screenshot seguente.

L'app accetta nuove stringhe di ricerca, numero di risultati e numero di consigli. Il numero di risultati corrisponde a quanti titoli OOC corrispondenti dovremmo recuperare dal catalogo esterno (IMDb). Il numero di consigli corrisponde al numero di vicini più vicini che dovremmo recuperare dal catalogo clienti in base alla ricerca di incorporamento kNN. Vedere il seguente codice:
Questo input (query, numero di hit e consigli) viene passato al **-ReadFromOpenSearchLambda-** Funzione Lambda creata da AWS CDK tramite la richiesta API Gateway. Questo viene fatto nella seguente funzione:
I risultati di output della funzione Lambda da OpenSearch Service vengono passati ad API Gateway e vengono visualizzati nell'app Streamlit.
ripulire
Puoi eliminare tutte le risorse create da AWS CDK tramite il comando npx cdk destroy –app “python3 appy.py” --all nella stessa istanza (all'interno del cdk cartella) utilizzata per avviare lo stack (vedere la schermata seguente).
Conclusione
In questo post, ti abbiamo mostrato come creare una soluzione per la ricerca OOC utilizzando la ricerca basata su testo e kNN utilizzando SageMaker e OpenSearch Service. Hai utilizzato gli incorporamenti personalizzati del modello di grafico della conoscenza per trovare i vicini più vicini nel tuo catalogo a quello dei titoli IMDb. Ora puoi, ad esempio, cercare "The Rings of Power", una serie fantasy sviluppata da Amazon Prime Video, su altre piattaforme di streaming e ragionare su come avrebbero potuto ottimizzare il risultato della ricerca.
Per ulteriori informazioni sull'esempio di codice in questo post, vedere il Repository GitHub. Per ulteriori informazioni sulla collaborazione con Amazon ML Solutions Lab per creare applicazioni ML all'avanguardia simili, consulta Lab di Amazon Machine Learning Solutions. Per ulteriori informazioni sulla licenza dei set di dati IMDb, visitare sviluppatore.imdb.com.
Informazioni sugli autori
 Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso l'Amazon ML Solutions Lab, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
Divya Bhargavi è Data Scientist e Media and Entertainment Vertical Lead presso l'Amazon ML Solutions Lab, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando Machine Learning. Si occupa di comprensione di immagini/video, sistemi di raccomandazione di grafici di conoscenza, casi d'uso di pubblicità predittiva.
 Gaurav Relé è un Data Scientist presso Amazon ML Solution Lab, dove lavora con i clienti AWS in diversi settori verticali per accelerare il loro utilizzo del machine learning e dei servizi cloud AWS per risolvere le loro sfide aziendali.
Gaurav Relé è un Data Scientist presso Amazon ML Solution Lab, dove lavora con i clienti AWS in diversi settori verticali per accelerare il loro utilizzo del machine learning e dei servizi cloud AWS per risolvere le loro sfide aziendali.
 Matteo Rodi è un Data Scientist che lavora nell'Amazon ML Solutions Lab. È specializzato nella creazione di pipeline di Machine Learning che coinvolgono concetti come l'elaborazione del linguaggio naturale e la visione artificiale.
Matteo Rodi è un Data Scientist che lavora nell'Amazon ML Solutions Lab. È specializzato nella creazione di pipeline di Machine Learning che coinvolgono concetti come l'elaborazione del linguaggio naturale e la visione artificiale.
 Karan Sindwani è un Data Scientist presso Amazon ML Solutions Lab, dove crea e distribuisce modelli di deep learning. È specializzato nel campo della visione artificiale. Nel tempo libero ama fare escursioni.
Karan Sindwani è un Data Scientist presso Amazon ML Solutions Lab, dove crea e distribuisce modelli di deep learning. È specializzato nel campo della visione artificiale. Nel tempo libero ama fare escursioni.
 Soji Adishina è uno scienziato applicato presso AWS, dove sviluppa modelli basati su reti neurali a grafo per l'apprendimento automatico su attività grafiche con applicazioni a frodi e abusi, grafi della conoscenza, sistemi di raccomandazione e scienze della vita. Nel tempo libero ama leggere e cucinare.
Soji Adishina è uno scienziato applicato presso AWS, dove sviluppa modelli basati su reti neurali a grafo per l'apprendimento automatico su attività grafiche con applicazioni a frodi e abusi, grafi della conoscenza, sistemi di raccomandazione e scienze della vita. Nel tempo libero ama leggere e cucinare.
 Vidya Sagar Ravipati è un manager presso l'Amazon ML Solutions Lab, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'IA e del cloud.
Vidya Sagar Ravipati è un manager presso l'Amazon ML Solutions Lab, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'IA e del cloud.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/power-recommendations-and-search-using-an-imdb-knowledge-graph-part-3/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- WRI
- abuso
- accelerare
- accetta
- accessibile
- operanti in
- attivo
- aggiuntivo
- Inoltre
- Aggiunge
- Adozione
- Pubblicità
- AI
- Tutti
- Amazon
- Laboratorio di soluzioni Amazon ML
- Amazon Nettuno
- Amazon Sage Maker
- analitica
- ed
- api
- App
- Applicazioni
- applicazioni
- applicato
- APPLICA
- approccio
- architettura
- RISERVATA
- associato
- Automatizzata
- disponibilità
- disponibile
- AWS
- basato
- perché
- MIGLIORE
- fra
- Miliardo
- Scatola
- botteghino
- del browser
- costruire
- Costruzione
- costruisce
- affari
- funzionalità
- casi
- catalogo
- sfide
- Scegli
- cliente
- Cloud
- adozione del cloud
- servizi cloud
- Cluster
- codice
- collaborando
- combinato
- Aziende
- azienda
- Società
- completamento di una
- Completato
- computer
- Visione computerizzata
- concetti
- consolle
- costantemente
- contiene
- contenuto
- cucina
- corrisponde
- potuto
- paesi
- creare
- creato
- Creazione
- creazione
- Crediti
- Corrente
- Attualmente
- costume
- cliente
- Il coinvolgimento del cliente
- Clienti
- dati
- Scambio di dati
- scienziato di dati
- banche dati
- dataset
- deep
- apprendimento profondo
- dimostrare
- dimostrato
- schierare
- distribuzione
- Distribuisce
- derivato
- descritta
- distruggere
- rivelazione
- sviluppato
- Mercato
- sviluppa
- diverso
- dirette
- direttamente
- scoperta
- discusso
- distribuito
- sistemi distribuiti
- documento
- documentario
- non
- dominio
- ogni
- più facile
- elasticsearch
- enable
- Fidanzamento
- migliorata
- entrare
- entra
- Intrattenimento
- entità
- Ambiente
- Etere (ETH)
- Evento
- EVER
- esempio
- exchange
- esperienza
- esplora
- esterno
- extra
- di fronte
- Familiarità
- FANTASIA
- figura
- Compila il
- File
- Trovate
- trova
- Nome
- flusso
- i seguenti
- segue
- essere trovato
- frode
- rilevazione di frodi
- frequente
- frequentemente
- da
- completamente
- function
- funzionalità
- funzionalità
- funzioni
- porta
- generare
- ottenere
- globali
- grafico
- reti neurali grafiche
- grafici
- maniglia
- intestazioni
- Aiuto
- escursionismo
- Colpire
- Visualizzazioni
- Come
- Tutorial
- HTML
- HTTPS
- centinaia
- Immagine
- realizzare
- implementato
- competenze
- in
- Compreso
- Aumento
- Index
- indici
- Indici
- industria
- informazioni
- ingresso
- install
- esempio
- invece
- interazione
- interattivo
- Interfaccia
- coinvolgere
- IT
- elementi
- Le
- kit
- conoscenze
- laboratorio
- Lingua
- grandi
- larga scala
- con i più recenti
- lanciare
- lancia
- strato
- portare
- IMPARARE
- apprendimento
- leveraggi
- Biblioteca
- Licenza
- Licenze
- Vita
- Life Sciences
- Limitato
- Lista
- caricare
- locale
- macchina
- machine learning
- FA
- gestito
- gestione
- direttore
- manualmente
- molti
- carta geografica
- mappatura
- Maps
- marchio
- partita
- corrispondenza
- Media
- Utenti
- menzionato
- fusione
- Metadati
- milione
- verbale
- ML
- modello
- modelli
- mojo
- monitorati
- monitoraggio
- Mese
- Scopri di più
- film
- Film
- multiplo
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- di applicazione
- vicinato
- Nettuno
- basato sulla rete
- reti
- Neurale
- reti neurali
- New
- nodo
- computer portatili
- numero
- ottenuto
- Offerte
- Office
- ONE
- aprire
- open source
- Operazioni
- ottimizzati
- minimo
- OS
- Altro
- pacchetto
- parte
- Passato
- passione
- sentiero
- eseguire
- esegue
- segnaposto
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- Post
- energia
- alimentato
- pratica
- premier
- Preparare
- presenti
- primario
- premio
- stampe
- problemi
- processi
- lavorazione
- Prodotto
- Produzione
- fornisce
- fornitura
- Acquista
- fini
- Python
- gamma
- valutazioni
- Lettura
- pronto
- tempo reale
- ragione
- Consigli
- raccomandazioni
- rilevanza
- pertinente
- replica
- Reportistica
- deposito
- richiesta
- richieste
- necessario
- risorsa
- Risorse
- risposta
- REST
- colpevole
- Risultati
- ritenzione
- ritorno
- problemi
- Correre
- running
- sagemaker
- stesso
- Risparmi
- Scenari
- SCIENZE
- Scienziato
- Cerca
- sezioni
- sicuro
- problemi di
- Serie
- servizio
- Servizi
- set
- regolazione
- impostazioni
- dovrebbero
- mostrato
- Spettacoli
- simile
- somiglianze
- Un'espansione
- semplificata
- singolo
- situazioni
- soluzione
- Soluzioni
- RISOLVERE
- risolve
- alcuni
- Fonte
- lo spazio
- specializzata
- specifico
- dividere
- pila
- inizia a
- iniziato
- state-of-the-art
- Passi
- conservazione
- memorizzati
- Storia
- Streaming
- sottorete
- tale
- suite
- supporto
- SISTEMI DI TRATTAMENTO
- Fai
- prende
- task
- tecniche
- terminal
- Il
- L'area
- il giunto
- loro
- in tal modo
- migliaia
- tre
- Attraverso
- tempo
- Titolo
- titoli
- a
- top
- giocattolo
- Treni
- allenato
- Trasformare
- triliardi
- tv
- tipico
- per
- e una comprensione reciproca
- Caricamento
- URL
- uso
- Utente
- Interfaccia utente
- Utilizzando
- varietà
- Fisso
- fornitori
- verticali
- Video
- Visualizza
- virtuale
- visione
- visualizzazione
- sito web
- applicazione web
- browser web
- Sito web
- quale
- largo
- Vasta gamma
- volere
- entro
- Word
- parole
- flusso di lavoro
- lavoro
- lavori
- sarebbe
- Trasferimento da aeroporto a Sharm
- zefiro
- zone